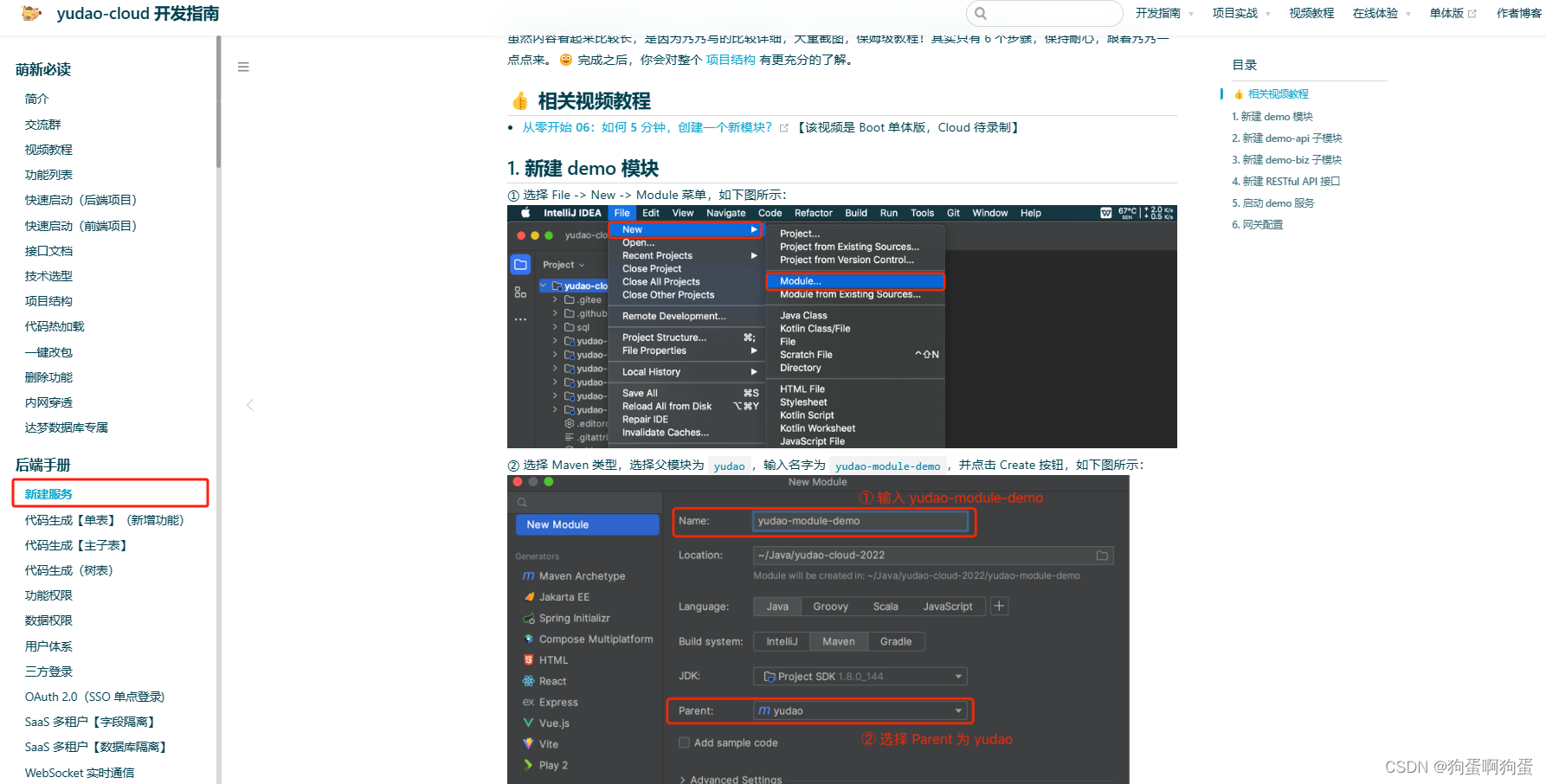
参考:《深入浅出DPDK》&前人的各种博客
SR-IOV全称Single Root IO Virtualization,单根虚拟化(多么高大上的名字>.<),是 Intel 在 2007年提出的一种基于硬件的虚拟化解决方案。
虚拟化背景
那什么又是虚拟化呢?抽象来说,虚拟化是资源的逻辑表示,虚拟化层将下层的资源抽象成另一种形式的资源,提供给上层调用。通过空间上分割(你用一部分我用一部分),时间上的分时(你用一秒我用一秒)以及模拟,虚拟化可以将一份资源抽象成多份。反过来说,虚拟化也可以将多份资源抽象成一份,比如说,通过对CPU、内存和I/O设备的虚拟化,可以为一个虚拟机提供完整的硬件能力的支持。
总的来说,虚拟化抽象了硬件层,允许多种不同的负载能共享一组资源。
虚拟化的优点非常明显,他可以显著提高服务器的使用率,能够进行动态分配,管理资源和负载的相互隔离,并提供高安全性和自动化。虚拟化还可以提供按需的服务配置和软件定义的资源编排,可以根据实际业务需求在云平台上扩展某类业务。
大致也可以看出俩,虚拟化实现主要有三部分的实现:
- CPU虚拟化
- 内存虚拟化
- I/O虚拟化
CPU虚拟化和内存虚拟化,这里不大关注,我们可以重点看一下I/O虚拟化。
I/O虚拟化
I/O虚拟化包括管理虚拟设备和共享的物理硬件之间的IO请求的路由选择。实现方式有
- I/O全虚拟化
- I/O半虚拟化
- I/O透传
区别在于处理客户机和宿主机通信以及宿主机和宿主机架构上分别采用了不同的处理方式。

I/O全虚拟化
如图所示,该方法可以模拟一些真实设备,一个设备的所有功能或总线结构(中断、DMA等)都可以在宿主机中模拟。客户机所能看到的就是一组统一的IO设备。宿主机截获客户机对IO设备的访问请求,通过软件模拟真实的硬件。
这种方式对客户急非常透明,无需考虑底层硬件的情况,不需要修改操作系统。但宿主机必须从硬件设备的最底层开始模拟,客户机完全感受不到这是在一个模拟的环境中,但这种效率比较低。
I/O半虚拟化
半虚拟化的意思是说,客户机操作系统能感知到自己时虚拟机,如上图所示,IO半虚拟化系统通过前端驱动/后端驱动实现的。客户机的驱动程序为前端,宿主机提供的与客户机通信的驱动程序为后端。
前端驱动将客户机的请求通过与宿主机间的特殊通信机制发送给后端驱动,后端驱动在处理完请求再发送给物理驱动。比如,DPDK支持半虚拟化的前端virtio和后端vhost。
半虚拟化虽然和全虚拟化一样,都是使用软件完成虚拟化工作,但是机制不同。在全虚拟化中,所有对模拟IO设备的访问都会造成VM-Exit(虚拟机暂停运行,并将控制权交还给VMM或hypervisor),而在半虚拟化场景中,通过亲啊后端驱动程序的协商,使得数据传输中对共享内存的读写操作不会VM-Exit。
这种方式比较简单,软件处理起来也不会太慢,性能还算可以,但仍然达不到物理硬件的速度
I/O透传
这非常好理解,直接把物理设备分配给虚拟机使用,比如直接分配一个硬盘或者网卡给虚拟机(咋感觉这种处理已经偏离虚拟化了…),如上图所示。这种方式需要硬件平台具备IO透传技术,也就是网卡直通(passthough, 又是一个非常高大上的词)比如,Intel VT-d技术,这种方式允许客户操作系统通过 IOMMU 与 PCI 设备通信,而虚拟机管理程序完全忽略该卡获得近乎本地的性能,并且CPU开销不高。
这种方式优缺点很明显:
- 高性能
- 由于Intel VT-d的技术支持,其执行/O操作是大量减少,甚至避免VM-Exit
缺点: - x86平台上的PCI和PCI-e设备有限,大量使用VT-d独立分配设备给客户机,会显著增加硬件成本(硬件厂商狂喜)
- PCI/PCI-e透传的设备,动态迁移功能(从一台物理服务器迁移到另一台服务器上)受限。因为宿主机无法感知透传设备的内部状态。
其实说白了,一台物理机上可用的物理网卡有限,该如何实现实现水平扩展呢,于是乎,SR-IOV技术应运而生。
PCI-e SRIOV
SR-IOV是一组硬件标准,允许一个PCIe设备(如网络接口卡)在硬件层面虚拟化,分割成多个虚拟功能(Virtual Functions, VFs),每个虚拟功能可以独立地被虚拟机使用。
理解起来还是比较简单的,它的工作方式是,SRIOV 依靠两个驱动程序,一个由 VM 系列管理,称为 VF(Virtual Function 虚拟功能),另一个由主机(虚拟机管理程序)管理,称为 PF(Physical Function物理功能),如图:

图片来源:https://knowledgebase.paloaltonetworks.com/KCSArticleDetail?id=kA14u000000HAixCAG&lang=en_US%E2%80%A9
简而言之,虽然只有有限的PCIe设备资源,但是可以通过一个PCIe设备资源的PF去创建不同的虚拟化资源(VF)供虚拟机使用。
但是很多人都会陷入一个误区:PF就是物理网卡。但PF并不是真实的物理网卡。PF仅代表物理网络接口卡(NIC)上的一个完整功能的实例。PF提供了完整的PCIe功能集,可以管理和控制该物理网卡。物理网卡上,可以有一个或多个PF。每个PF可以创建多个VF,让虚拟机独立使用这些VF。
启用SRIOV之后,物理NIC将通过VF与虚拟机(VF driver)进行数据交互,反之亦然。那么这样一来即可跳过中间的虚拟化堆栈(即VMM层),以达到近乎于纯物理环境的性能,完美的实现了I/O透传的优点,避免了其缺点。
但但但,它真就那么完美吗,它就没有缺点吗???那肯定不至于,毕竟现在SRIOV并没有占据所有市场,我们可以来简单的挑挑刺儿
- VF虚拟机不能在线迁移,这在云网络的环境中是硬伤
- SRIOV从物理网卡接收到的数据包将直接到达客户机的接收队列,或者从客户机发送队列发出的包将直接到达其他客户机(如同一个PF的VF)的接收队列,或者直接从物理网卡发出,绕过了宿主机的参与。但在很多场景,有需求要求网络包必须先经过宿主机的处理(如防火墙、负载均衡等)
- 可扩展性差,由于VF是通过BDF(bus device function)号进行隔离的,所以每个VF都需要各自的配置空间,产生的额外开销较大,一些intel网卡中最大支持数量只有256。
由于这些局限,才有了后来Intel的scalable IOV和Nvida Mellnox的Scalale function(看看~大佬们的起名都这么相似)以及I/O半虚拟化的发展,感兴趣的可以去搜一搜。
- 参考
https://blog.csdn.net/wangdd_199326/article/details/90476728
https://knowledgebase.paloaltonetworks.com/KCSArticleDetail?id=kA14u000000HAixCAG&lang=en_US%E2%80%A9
https://blog.csdn.net/weixin_60043341/article/details/126467233
https://docs.nvidia.com/networking/display/bluefielddpuosv385/scalable+functions