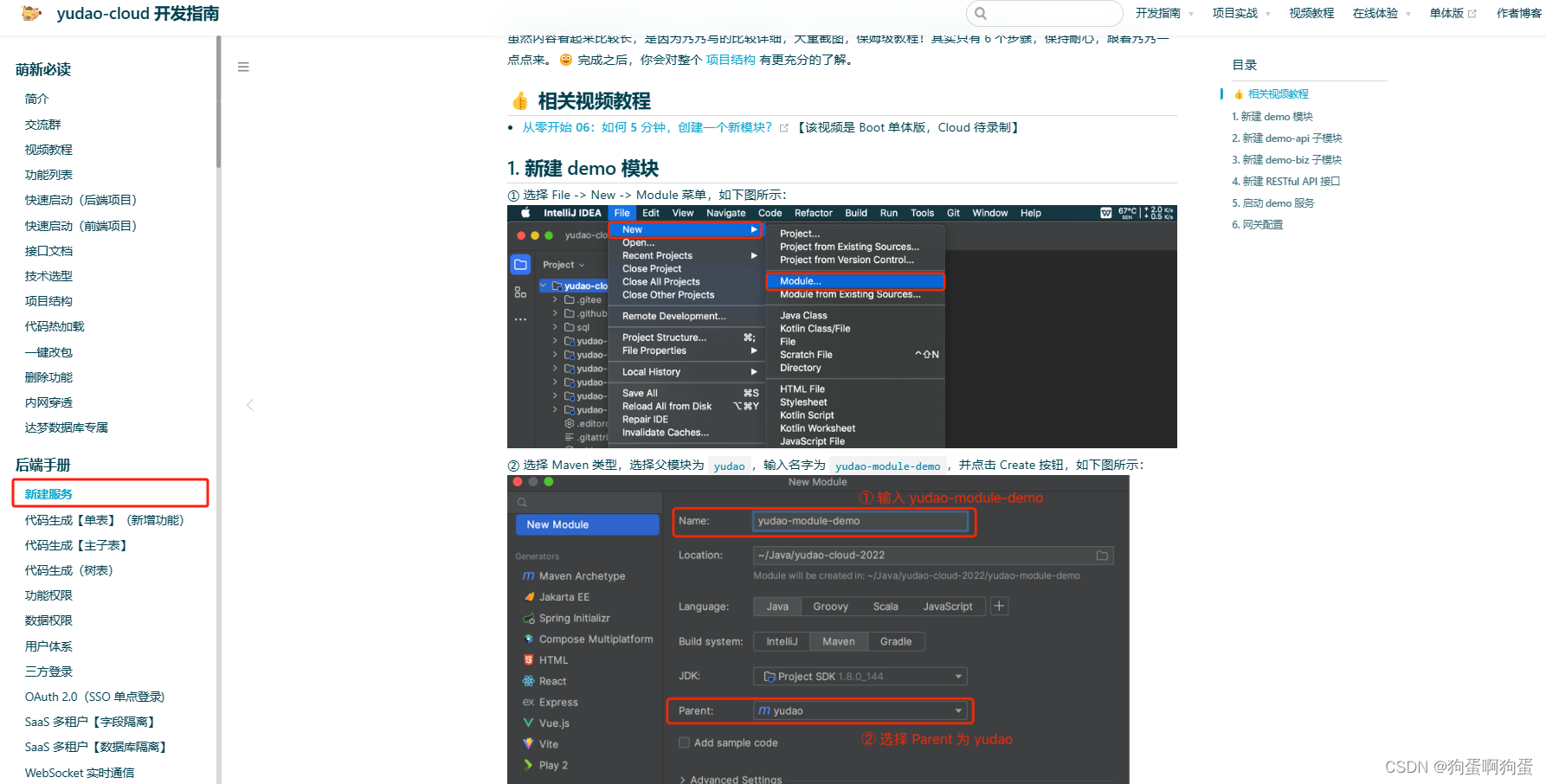
在自然语言处理和序列建模中,Transformer模型因其在处理长距离依赖关系上的卓越性能而被广泛使用。传统的Transformer模型在处理长序列时,计算和存储的开销较大,而流式帧级别Transformer通过引入KV Cache(键值缓存)来有效地缓解这一问题。
本文将介绍如何基于KV Cache构建流式帧级别Transformer,并实现自回归解码。通过实际代码示例,详细解释其工作原理和实现细节。

流式帧级别Transformer简介
流式帧级别Transformer是一种特殊的Transformer变体,设计用于流式输入处理。这种模型可以在序列的每个时间步处理输入,并且利用KV Cache存储历史的键和值,避免重复计算,从而提高效率。自回归解码则意味着模型在生成下一个输出时依赖于之前的输出。
代码实现
我们将实现一个包含编码器和解码器的流式帧级别Transformer模型。编码器和解码器分别利用KV Cache存储和更新历史信息,以实现高效的序列建模和生成。
编码器
首先,定义编码器类StreamSelfAttentionEncoder:
import torch
import torch.nn as nn
import math
class StreamSelfAttentionEncoder(nn.Module):
def __init__(self, model_dim, self_attention_size):
super(StreamSelfAttentionEncoder, self).__init__()
self.model_dim = model_dim
self.self_attention_size = self_attention_size
self.Q = nn.Linear(model_dim, model_dim)
self.K = nn.Linear(model_dim, model_dim)
self.V = nn.Linear(model_dim, model_dim)
self.softmax = nn.Softmax(dim=-1)
# FFN
self.ffn = nn.Sequential(
nn.Linear(model_dim, model_dim * 4),
nn.ReLU(),
nn.Linear(model_dim * 4, model_dim)
)
def forward(self, x, k_cache=None, v_cache=None, pos=None):
# Ensure positional encoding is on the same device as x
if pos is not None:
pos_enc = self.get_positional_encoding(pos, self.model_dim, x.device)
x = x + pos_enc.unsqueeze(0).unsqueeze(1) # (N, 1, model_dim)
# Project inputs to Q, K, V
q = self.Q(x) # (N, 1, model_dim)
k = self.K(x) # (N, 1, model_dim)
v = self.V(x) # (N, 1, model_dim)
batch_size = x.size(0)
# Initialize k_cache and v_cache if not provided
if k_cache is None:
k_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device)
v_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device)
# Concatenate past K, V with current K, V
k_cache = torch.cat([k_cache, k], dim=1) # (N, seq_len + 1, model_dim)
v_cache = torch.cat([v_cache, v], dim=1) # (N, seq_len + 1, model_dim)
# Compute attention scores
attn_scores = torch.matmul(q, k_cache[:, -self.self_attention_size:].transpose(-2, -1)) / math.sqrt(self.model_dim)
attn_weights = self.softmax(attn_scores)
# Compute attention output
attn_output = torch.matmul(attn_weights, v_cache[:, -self.self_attention_size:])
# Apply skip connection and FFN
attn_output = attn_output + x
ffn_output = self.ffn(attn_output)
output = ffn_output + attn_output
return output, k_cache, v_cache
def get_positional_encoding(self, pos, model_dim, device):
pe = torch.zeros(model_dim, device=device)
div_term = torch.exp(torch.arange(0, model_dim, 2, device=device).float() * (-math.log(10000.0) / model_dim))
pe[0::2] = torch.sin(pos * div_term)
pe[1::2] = torch.cos(pos * div_term)
return pe
在这个编码器中,我们通过以下步骤来处理输入数据:
-
位置编码(Positional Encoding):
if pos is not None: pos_enc = self.get_positional_encoding(pos, self.model_dim, x.device) x = x + pos_enc.unsqueeze(0).unsqueeze(1) # (N, 1, model_dim)这里我们为输入
x添加位置编码,以保留序列信息。 -
投影(Projection):
q = self.Q(x) # (N, 1, model_dim) k = self.K(x) # (N, 1, model_dim) v = self.V(x) # (N, 1, model_dim)将输入
x投影到查询(Query)、键(Key)和值(Value)空间。 -
KV缓存初始化和更新(KV Cache Initialization and Update):
if k_cache is None: k_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device) v_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device) k_cache = torch.cat([k_cache, k], dim=1) # (N, seq_len + 1, model_dim) v_cache = torch.cat([v_cache, v], dim=1) # (N, seq_len + 1, model_dim)初始化并更新KV缓存,将当前的
k和v值拼接到缓存中。 -
注意力计算(Attention Calculation):
attn_scores = torch.matmul(q, k_cache[:, -self.self_attention_size:].transpose(-2, -1)) / math.sqrt(self.model_dim) attn_weights = self.softmax(attn_scores) attn_output = torch.matmul(attn_weights, v_cache[:, -self.self_attention_size:])计算查询与缓存中键的点积,然后通过softmax获得注意力权重,再将权重应用到缓存中的值上,得到注意力输出。
-
前馈网络(Feed-Forward Network)和跳跃连接(Skip Connection):
attn_output = attn_output + x ffn_output = self.ffn(attn_output) output = ffn_output + attn_output最后,将注意力输出与输入相加,再经过前馈网络和跳跃连接得到最终输出。
解码器
接下来,定义解码器类StreamSelfAttentionDecoder:
class StreamSelfAttentionDecoder(nn.Module):
def __init__(self, model_dim, self_attention_size, cross_attention_size):
super(StreamSelfAttentionDecoder, self).__init__()
self.model_dim = model_dim
self.self_attention_size = self_attention_size
self.cross_attention_size = cross_attention_size
self.Qe = nn.Linear(model_dim, model_dim)
self.Qd = nn.Linear(model_dim, model_dim)
self.Kd = nn.Linear(model_dim, model_dim)
self.Vd = nn.Linear(model_dim, model_dim)
self.softmax = nn.Softmax(dim=-1)
# FFN
self.ffn = nn.Sequential(
nn.Linear(model_dim, model_dim * 4),
nn.ReLU(),
nn.Linear(model_dim * 4, model_dim)
)
def forward(self, x,
encoder_k_cache,
encoder_v_cache,
decoder_k_cache=None,
decoder_v_cache=None,
pos=None):
batch_size = x.size(0)
# Ensure positional encoding is on the same device as x
if pos is not None:
pos_enc = self.get_positional_encoding(pos, self.model_dim, x.device)
x = x + pos_enc.unsqueeze(0).unsqueeze(1) # (N, 1, model_dim)
# Initialize caches if not provided
if decoder_k_cache is None:
decoder_k_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device)
decoder_v_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device)
# Decoder self-attention
qd = self.Qd(x) # (N, 1, model_dim)
kd = self.Kd(x) # (N, 1, model_dim)
vd = self.Vd(x) # (N, 1, model_dim)
# Concatenate past K, V with current K, V
decoder_k_cache = torch.cat([decoder_k_cache, kd], dim=1) # (N, seq_len + 1, model_dim)
decoder_v_cache = torch.cat([decoder_v_cache, vd], dim=1) # (N, seq_len + 1
, model_dim)
# Compute self-attention scores
attn_self_scores = torch.matmul(qd, decoder_k_cache[:, -self.self_attention_size:].transpose(-2, -1)) / math.sqrt(self.model_dim)
attn_self_weights = self.softmax(attn_self_scores)
attn_self_output = torch.matmul(attn_self_weights, decoder_v_cache[:, -self.self_attention_size:])
attn_self_output = attn_self_output + x
# Encoder-decoder cross-attention
qe = self.Qe(attn_self_output)
attn_cross_scores = torch.matmul(qe, encoder_k_cache[:, -self.cross_attention_size:].transpose(-2, -1)) / math.sqrt(self.model_dim)
attn_cross_weights = self.softmax(attn_cross_scores)
attn_cross_output = torch.matmul(attn_cross_weights, encoder_v_cache[:, -self.cross_attention_size:])
attn_cross_output = attn_cross_output + attn_self_output
# Apply skip connection and FFN
ffn_output = self.ffn(attn_cross_output)
output = ffn_output + attn_cross_output
return output, decoder_k_cache, decoder_v_cache
def get_positional_encoding(self, pos, model_dim, device):
pe = torch.zeros(model_dim, device=device)
div_term = torch.exp(torch.arange(0, model_dim, 2, device=device).float() * (-math.log(10000.0) / model_dim))
pe[0::2] = torch.sin(pos * div_term)
pe[1::2] = torch.cos(pos * div_term)
return pe
在这个解码器中,我们通过以下步骤来处理输入数据:
-
位置编码(Positional Encoding):
if pos is not None: pos_enc = self.get_positional_encoding(pos, self.model_dim, x.device) x = x + pos_enc.unsqueeze(0).unsqueeze(1) # (N, 1, model_dim)这里我们为输入
x添加位置编码,以保留序列信息。 -
投影(Projection):
qd = self.Qd(x) # (N, 1, model_dim) kd = self.Kd(x) # (N, 1, model_dim) vd = self.Vd(x) # (N, 1, model_dim)将输入
x投影到查询(Query)、键(Key)和值(Value)空间。 -
KV缓存初始化和更新(KV Cache Initialization and Update):
if decoder_k_cache is None: decoder_k_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device) decoder_v_cache = torch.zeros((batch_size, 0, self.model_dim), device=x.device) decoder_k_cache = torch.cat([decoder_k_cache, kd], dim=1) # (N, seq_len + 1, model_dim) decoder_v_cache = torch.cat([decoder_v_cache, vd], dim=1) # (N, seq_len + 1, model_dim)初始化并更新解码器的KV缓存,将当前的
kd和vd值拼接到缓存中。 -
自注意力计算(Self-Attention Calculation):
attn_self_scores = torch.matmul(qd, decoder_k_cache[:, -self.self_attention_size:].transpose(-2, -1)) / math.sqrt(self.model_dim) attn_self_weights = self.softmax(attn_self_scores) attn_self_output = torch.matmul(attn_self_weights, decoder_v_cache[:, -self.self_attention_size:]) attn_self_output = attn_self_output + x计算查询与解码器缓存中键的点积,然后通过softmax获得注意力权重,再将权重应用到缓存中的值上,得到自注意力输出。
-
交叉注意力计算(Cross-Attention Calculation):
qe = self.Qe(attn_self_output) attn_cross_scores = torch.matmul(qe, encoder_k_cache[:, -self.cross_attention_size:].transpose(-2, -1)) / math.sqrt(self.model_dim) attn_cross_weights = self.softmax(attn_cross_scores) attn_cross_output = torch.matmul(attn_cross_weights, encoder_v_cache[:, -self.cross_attention_size:]) attn_cross_output = attn_cross_output + attn_self_output计算自注意力输出与编码器缓存中键的点积,然后通过softmax获得注意力权重,再将权重应用到编码器缓存中的值上,得到交叉注意力输出。
-
前馈网络(Feed-Forward Network)和跳跃连接(Skip Connection):
ffn_output = self.ffn(attn_cross_output) output = ffn_output + attn_cross_output最后,将交叉注意力输出与输入相加,再经过前馈网络和跳跃连接得到最终输出。
示例代码
以下代码展示了如何实例化编码器和解码器,并进行前向传播:
if __name__ == "__main__":
batch_size = 2
model_dim = 64
attention_size = 10
self_attention_size = 8
cross_attention_size = 6
seq_len = 1
decoder_step = 4
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Instantiate the self-attention encoder and decoder
encoder = StreamSelfAttentionEncoder(model_dim, attention_size).to(device)
decoder = StreamSelfAttentionDecoder(model_dim, self_attention_size, cross_attention_size).to(device)
encoder_k_cache = encoder_v_cache = None
decoder_k_cache = decoder_v_cache = None
for t in range(100):
x = torch.rand(batch_size, seq_len, model_dim).to(device) # (N, 1, model_dim)
pos = t # Current position
# Encoder forward pass
encoder_output, encoder_k_cache, encoder_v_cache = encoder(x, encoder_k_cache, encoder_v_cache, pos)
print(f"Encoder Output shape at time step {t}: {encoder_output.shape}") # (N, 1, model_dim)
print(f"Encoder k_cache shape: {encoder_k_cache.shape}") # (N, seq_len + 1, model_dim)
print(f"Encoder v_cache shape: {encoder_v_cache.shape}") # (N, seq_len + 1, model_dim)
print()
if t % decoder_step == 0:
# Decoder forward pass
decoder_output, decoder_k_cache, decoder_v_cache = decoder(encoder_output, encoder_k_cache, encoder_v_cache, decoder_k_cache, decoder_v_cache, pos)
print(f"Decoder Output shape at time step {t}: {decoder_output.shape}") # (N, 1, model_dim)
print(f"Decoder k_cache shape: {decoder_k_cache.shape}") # (N, seq_len + 1, model_dim)
print(f"Decoder v_cache shape: {decoder_v_cache.shape}") # (N, seq_len + 1, model_dim)
print()
运行结果如下(对解码器进行跳帧处理)

结论
通过本文的介绍和示例代码,我们详细阐述了如何基于KV Cache构建流式帧级别Transformer并实现自回归解码。这种方法不仅能有效处理长序列数据,还能显著提升计算效率。希望这篇文章能帮助读者更好地理解和应用流式帧级别Transformer模型。
通过实践和调整参数,读者可以进一步优化模型性能,以满足不同任务的需求。流式帧级别Transformer的应用前景广泛,无论是在自然语言处理、语音识别还是其他序列数据处理领域,都有很大的潜力。