1.4.7、字符串函数
1.4.7.1、ascii
select ascii('a');
1.4.7.2、base64-->Hive0.12.0
select base64(cast('abcd' as binary));
1.4.7.3、character_length-->Hive2.2.0
1.4.7.4、chr-->Hive1.3.0
1.4.7.5、concat
select concat(1,'1','2','a'),concat(1,'a',null);
1.4.7.6、context_ngrams
1.4.7.7、concat_ws
--该拼接函数仅支持字符串类型或者字符串数组类型
select concat_ws('-','1','2','3'),concat_ws('-',array('1','2','3'));
1.4.7.8、decode -->Hive0.12.0
select decode(cast('abc' as binary),'ISO-8859-1');
1.4.7.9、elt
--返回指定索引处的字符串
SELECT elt(2,'hello','world'),elt(1,'jello','world');
1.4.7.10、encode -->Hive0.12.0
select encode('abc1233424asfsd','UTF-16LE');
1.4.7.11、field
--返回指定字符串所在的索引处,如world字符串在第3个位置上
select field('world','say','hello','world')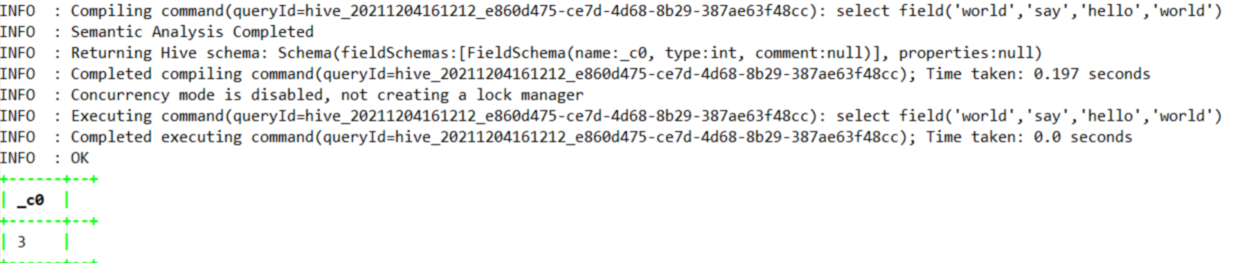
1.4.7.12、find_in_set
--返回 'abc,b,ab,c,def' 中第一次出现的 ab ,其中 'abc,b,ab,c,def' 是逗号分隔的字符串。如果任一参数为 null,则返回 null。如果第一个参数包含任何逗号,则返回 0
select find_in_set('ab', 'abc,b,ab,c,def') ;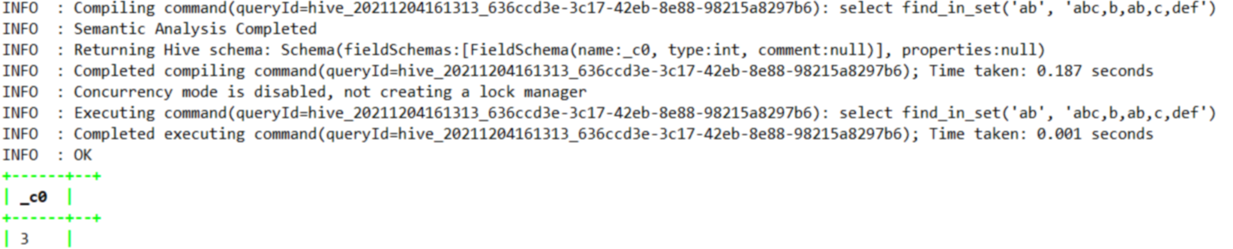
1.4.7.13、format_number-->Hive0.10.0
select format_number(2,1),format_number(2,2),format_number(2,3);
1.4.7.14、get_json_object
select get_json_object('{"a":2,"b":1}','$.a');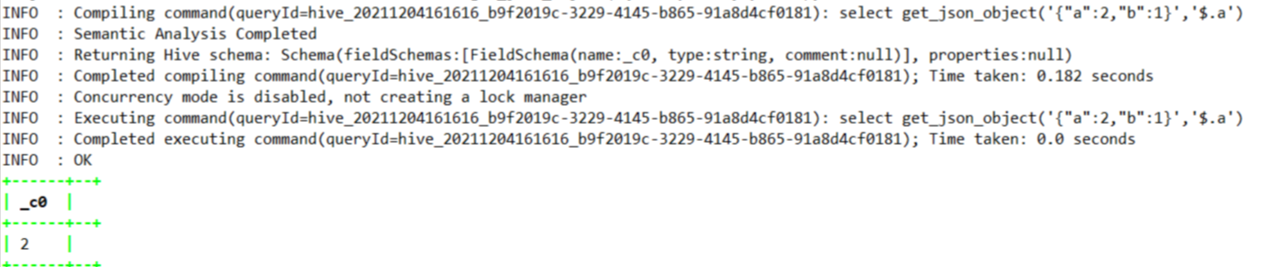
1.4.7.15、in_file
1.4.7.16、instr
select instr('asfdsarsrsf234','6'),instr('asfdsarsrsf234','a');
1.4.7.17、length
select length('asfdsarsrsf234');
1.4.7.18、locate
select locate('a','asfdsarsrsf234'),locate('6','asfdsarsrsf234');
1.4.7.19、lower
select lower('AWFDSFDS');
1.4.7.20、lpad
--返回10位长度的字符串,如果不原始字符串不足10位,则用*在左位填充
select lpad('sdfsd',10,'*');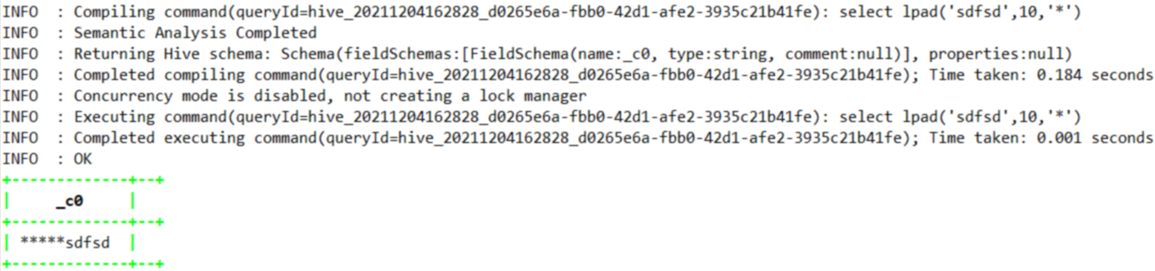
1.4.7.21、ltrim
select ltrim('safdsf '),length(ltrim('safdsf ')),length('safdsf ');
1.4.7.22、ngrams
1.4.7.23、octet_length -->Hive2.2.0
1.4.7.24、parse_url
-- 可以指定HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, 和 USERINFO
select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST');
1.4.7.25、printf -->0.9.0
SELECT printf("His Name is%s, Age Is %d","Jetty",100);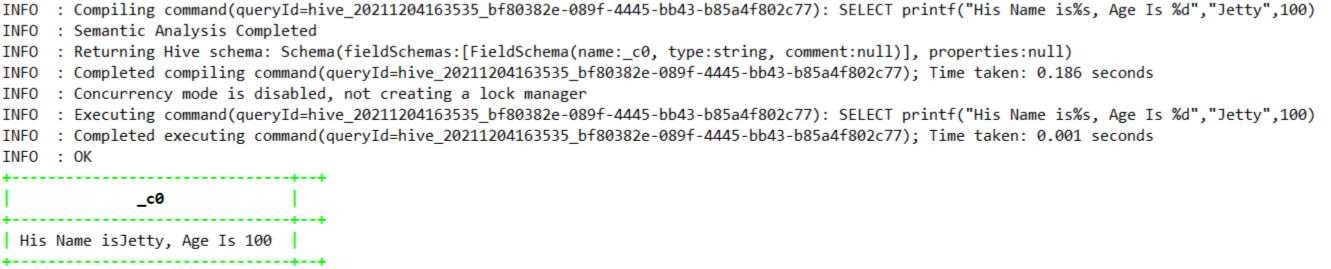
1.4.7.26、regexp_extract
SELECT regexp_extract('foothebar', 'foo(.*?)(bar)', 2) ;
1.4.7.27、regexp_replace
select regexp_replace("foobar", "oo|ar", "");
1.4.7.28、repeat
SELECT repeat('a',3);
1.4.7.29、replace-->HIve1.3.0
1.4.7.30、reverse
select reverse("abcde");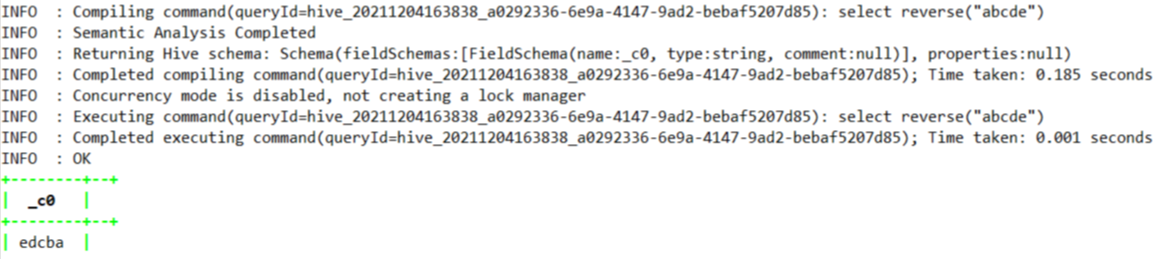
1.4.7.31、rpad
select rpad('ancd',10,'*');
1.4.7.32、rtrim
select rtrim(' safdsf '),length(rtrim(' safdsf ')),length(' safdsf ');
1.4.7.33、sentences
select sentences('Hello there! How are you?');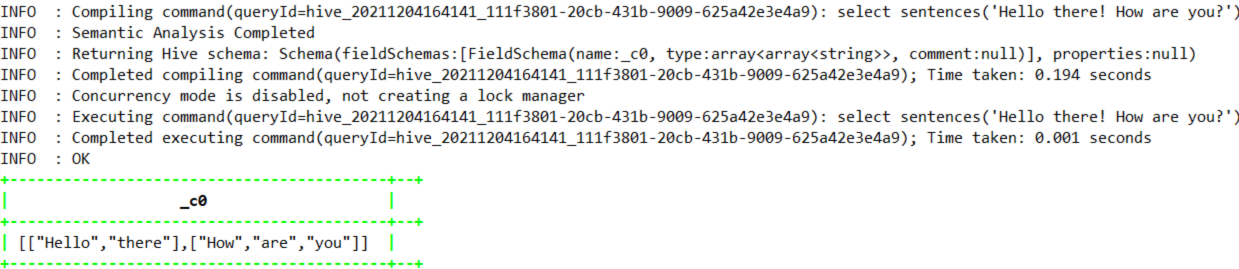
1.4.7.34、space
select space(3),length(space(3));
1.4.7.35、split
select split('ansdasdfc','a');
1.4.7.36、str_to_map
select str_to_map('a-1,b-2,c-3',',','-');
1.4.7.37、substr
select substr('foobar', 4), substr('foobar', 4, 1);
1.4.7.38、substring_index -->Hive1.3.0
1.4.7.39、translate-->Hive0.14.0
select translate('asefsda12313asdf','123','*');
1.4.7.40、trim
select trim(' safdsf '),length(trim(' safdsf ')),length(' safdsf ');
1.4.7.41、unbase64 -->Hive0.12.0
select unbase64('wwewe.csdf');
1.4.7.42、upper
select upper('fOoBaR') ;
1.4.7.43、initcap-->Hive1.1.0
select initcap('asdfcasd');
1.4.7.44、levenshtein -->Hive1.2.0
levenshtein('kitten', 'sitting');
1.4.7.45、soundex -->Hive1.2.0
select soundex('Miller');
支持版本 | 返回值类型 | 函数名称 | 功能描述 |
int | ascii(string str) | 返回 str 的第一个字符的数值。 | |
Hive0.12.0 | string | base64(binary bin) | 将参数从二进制转换为 base 64 字符串(从 Hive 0.12.0 开始) |
Hive2.2.0 | int | character_length(string str) | 返回 str 中包含的 UTF-8 字符数(从 Hive 2.2.0 开始)。函数 char_length 是该函数的简写。 |
Hive1.3.0 | string | chr(bigint|double A) | 返回二进制等同于 A 的 ASCII 字符(从 Hive 1.3.0 和 2.1.0 开始)。如果 A 大于 256,则结果等同于 chr(A % 256)。示例:选择 chr(88);返回“X”。 |
string | concat(string|binary A, string|binary B...) | 返回按顺序连接作为参数传入的字符串或字节所产生的字符串或字节。例如, concat('foo', 'bar') 结果为 'foobar'。请注意,此函数可以接受任意数量的输入字符串。 | |
array<struct<string,double>> | context_ngrams(array<array<string>>, array<string>, int K, int pf) | 给定一串“上下文”,从一组标记化的句子中返回前 k 个上下文 N-gram。 | |
string | concat_ws(string SEP, string A, string B...) | 与上面的 concat() 类似,但使用自定义分隔符 SEP | |
string | concat_ws(string SEP, array<string>) | 与上面的 concat_ws() 类似,但采用字符串数组。 (从 Hive 0.9.0 开始) | |
Hive0.12.0 | string | decode(binary bin, string charset) | 使用提供的字符集('US-ASCII'、'ISO-8859-1'、'UTF-8'、'UTF-16BE'、'UTF-16LE'、'UTF- 16')。如果任一参数为空,则结果也将为空。 (从 Hive 0.12.0 开始。) |
string | elt(N int,str1 string,str2 string,str3 string,...) | 返回索引号处的字符串。例如 elt(2,'hello','world') 返回 'world'。如果 N 小于 1 或大于参数数量,则返回 NULL。 | |
Hive0.12.0 | binary | encode(string src, string charset) | 使用提供的字符集('US-ASCII'、'ISO-8859-1'、'UTF-8'、'UTF-16BE'、'UTF-16LE'、'UTF- 16')。如果任一参数为空,则结果也将为空。 (从 Hive 0.12.0 开始。) |
int | field(val T,val1 T,val2 T,val3 T,...) | 返回 val1,val2,val3,... 列表中 val 的索引,如果未找到则返回 0。例如 field('world','say','hello','world') 返回 3。支持所有原始类型,使用 str.equals(x) 比较参数。如果 val 为 NULL,则返回值为 0。 | |
int | find_in_set(string str, string strList) | 返回 strList 中第一次出现的 str ,其中 strList 是逗号分隔的字符串。如果任一参数为 null,则返回 null。如果第一个参数包含任何逗号,则返回 0。例如, find_in_set('ab', 'abc,b,ab,c,def') 返回 3 | |
Hive0.10.0 | string | format_number(number x, int d) | 将数字 X 格式化为类似 '#,###,###.##' 的格式,四舍五入到 D 位小数,并将结果作为字符串返回。如果 D 为 0,则结果没有小数点或小数部分。 (从 Hive 0.10.0 开始;在 Hive 0.14.0 中修复了浮点类型的错误,在 Hive 0.14.0 中添加了十进制类型支持) |
string | get_json_object(string json_string, string path) | 根据指定的json路径从json字符串中提取json对象,并返回提取的json对象的json字符串。如果输入的 json 字符串无效,它将返回 null。注意:json 路径只能包含字符 [0-9a-z_],即不能包含大写或特殊字符。此外,键不能以数字开头。这是由于对 Hive 列名称的限制 | |
boolean | in_file(string str, string filename) | 如果字符串 str 在文件名中显示为整行,则返回 true。 | |
int | instr(string str, string substr) | 返回 substr 在 str 中第一次出现的位置。如果任一参数为 null,则返回 null,如果在 str 中找不到 substr,则返回 0。请注意,这不是基于零的。 str 中的第一个字符的索引为 1 | |
int | length(string A) | 返回字符串的长度 | |
int | locate(string substr, string str[, int pos]) | 返回位置 pos 之后 str 中第一次出现 substr 的位置。 | |
string | lower(string A) lcase(string A) | 返回将 B 的所有字符转换为小写的字符串。例如,lower('fOoBaR') 结果是 'foobar' | |
string | lpad(string str, int len, string pad) | 返回 str,用 pad 左填充,长度为 len。如果 str 比 len 长,则返回值将缩短为 len 个字符。如果填充字符串为空,则返回值为空 | |
string | ltrim(string A) | 返回从 A 的开头(左侧)修剪空格产生的字符串。例如, ltrim(' foobar ') 结果为 'foobar ' | |
array<struct<string,double>> | ngrams(array<array<string>>, int N, int K, int pf) | 返回一组标记化的句子中的top-k N-grams,例如由sentences()UDAF返回的那些 | |
Hive2.2.0 | int | octet_length(string str) | 返回以 UTF-8 编码保存字符串 str 所需的八位字节数(自 Hive 2.2.0)。请注意,octet_length(str) 可以大于 character_length(str)。 |
string | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 从 URL 返回指定的部分。 partToExtract 的有效值包括 HOST、PATH、QUERY、REF、PROTOCOL、AUTHORITY、FILE 和 USERINFO。例如, parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') 返回 'facebook.com'。还可以通过提供键作为第三个参数来提取 QUERY 中特定键的值,例如, parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY', 'k1') 返回 'v1'。 | |
Hive0.9.0 | string | printf(String format, Obj... args) | 返回按照printf风格的格式字符串格式化的输入(从Hive 0.9.0开始) |
string | quote(String text) | 返回带引号的字符串(包括任何单引号 HIVE-4.0.0 的转义字符) | |
string | regexp_extract(string subject, string pattern, int index) | 返回使用模式提取的字符串。例如,regexp_extract('foothebar', 'foo(.*?)(bar)', 2) 返回 'bar.'请注意,在使用预定义字符类时需要小心:使用 '\s' 作为第二个参数将匹配字母 s; '\\s' 是匹配空格等所必需的。'index' 参数是 Java 正则表达式 Matcher group() 方法索引 | |
string | regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) | 返回将 INITIAL_STRING 中与 PATTERN 中定义的 java 正则表达式语法匹配的所有子字符串替换为 REPLACEMENT 实例所产生的字符串。例如,regexp_replace("foobar", "oo|ar", "") 返回 'fb.'。请注意,在使用预定义字符类时需要小心:使用 '\s' 作为第二个参数将匹配字母 s; '\\s' 是匹配空格等所必需的。 | |
string | repeat(string str, int n) | 重复 str n 次。 | |
Hive1.3.0 | string | replace(string A, string OLD, string NEW) | 返回所有非重叠出现的OLD被替换为NEW的字符串A(从Hive 1.3.0和2.1.0起). 例如:选择 replace("ababab", "abab", "Z"); 返回 "Zab" |
string | reverse(string A) | 返回反转的字符串 | |
string | rpad(string str, int len, string pad) | 返回 str,用 pad 右填充,长度为 len。如果 str 比 len 长,则返回值将缩短为 len 个字符。如果填充字符串为空,则返回值为空。 | |
string | rtrim(string A) | 返回从 A 的末尾(右侧)修剪空格产生的字符串。例如, rtrim(' foobar ') 结果为 ' foobar' | |
array<array<string>> | sentences(string str, string lang, string locale) | 将一串自然语言文本标记为单词和句子,其中每个句子在适当的句子边界处断开并作为单词数组返回。 'lang' 和 'locale' 是可选参数。例如,句子('Hello there! How are you?') 返回 ( ("Hello", "there"), ("How", "are", "you") ) | |
string | space(int n) | 返回一个包含 n 个空格的字符串 | |
array | split(string str, string pat) | 在 pat 周围拆分 str (pat 是一个正则表达式) | |
map<string,string> | str_to_map(text[, delimiter1, delimiter2]) | 使用两个分隔符将文本拆分为键值对。 Delimiter1 将文本分成 K-V 对,Delimiter2 拆分每个 K-V 对。默认分隔符是“,”用于 delimiter1,“:”用于 delimiter2。 | |
string | substr(string|binary A, int start) substring(string|binary A, int start) | 返回 A 的字节数组的子字符串或切片,从起始位置到字符串 A 的结尾。例如, substr('foobar', 4) 结果为 'bar | |
string | substr(string|binary A, int start, int len) substring(string|binary A, int start, int len) | 返回 A 的字节数组的子字符串或切片,从起始位置开始,长度为 len。例如, substr('foobar', 4, 1) 结果为 'b' | |
Hive1.3.0 | string | substring_index(string A, string delim, int count) | 在分隔符 delim 出现计数之前返回字符串 A 中的子字符串(从 Hive 1.3.0 开始))。如果 count 为正数,则返回最终分隔符左侧的所有内容(从左侧开始计数)。如果计数为负,则返回最终分隔符右侧的所有内容(从右侧开始计数)。 Substring_index 在搜索 delim 时执行区分大小写的匹配。示例:substring_index('www.apache.org', '.', 2) = 'www.apache' |
Hive0.14.0 | string | translate(string|char|varchar input, string|char|varchar from, string|char|varchar to) | 通过用 to 字符串中的相应字符替换 from 字符串中存在的字符来翻译输入字符串。这类似于 PostgreSQL 中的 translate 函数。如果此 UDF 的任何参数为 NULL,则结果也为 NULL。 (从 Hive 0.10.0 开始可用,用于字符串类型)。从 Hive 0.14.0 开始添加 Char/varchar 支持 |
string | trim(string A) | 返回从 A 的两端修剪空格产生的字符串。例如,trim(' foobar ') 结果为 'foobar' | |
Hive0.12.0 | binary | unbase64(string str) | 将参数从 base 64 字符串转换为 BINARY。 (从 Hive 0.12.0 开始。) |
string | upper(string A) ucase(string A) | 返回将 A 的所有字符转换为大写的字符串。例如, upper('fOoBaR') 结果为 'FOOBAR' | |
Hive1.1.0 | string | initcap(string A) | 返回字符串,每个单词的第一个字母大写,所有其他字母小写。单词由空格分隔。 (截至 Hive 1.1.0.) |
Hive1.2.0 | int | levenshtein(string A, string B) | 返回两个字符串之间的 Levenshtein 距离(从 Hive 1.2.0)。例如, levenshtein('kitten', 'sitting') 结果为 3 |
Hive1.2.0 | string | soundex(string A) | 返回字符串的 soundex 代码(从 Hive 1.2.0 开始)。例如, soundex('Miller') 结果为 M460 |