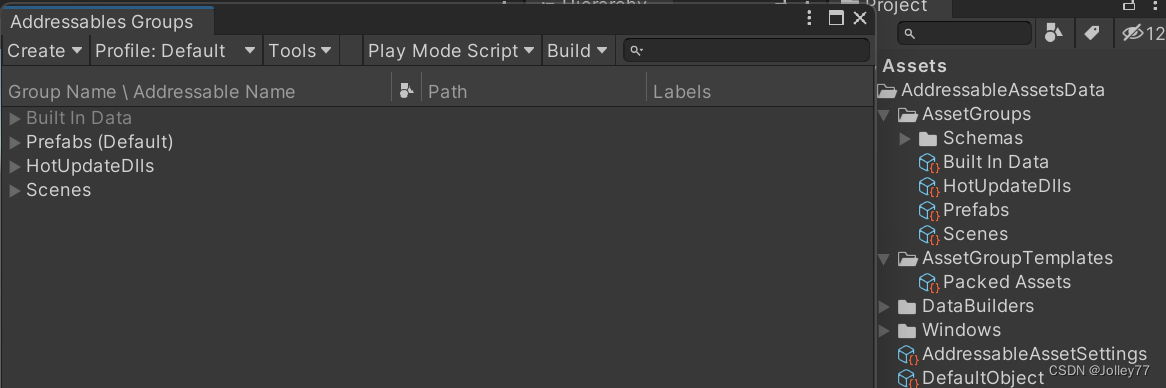
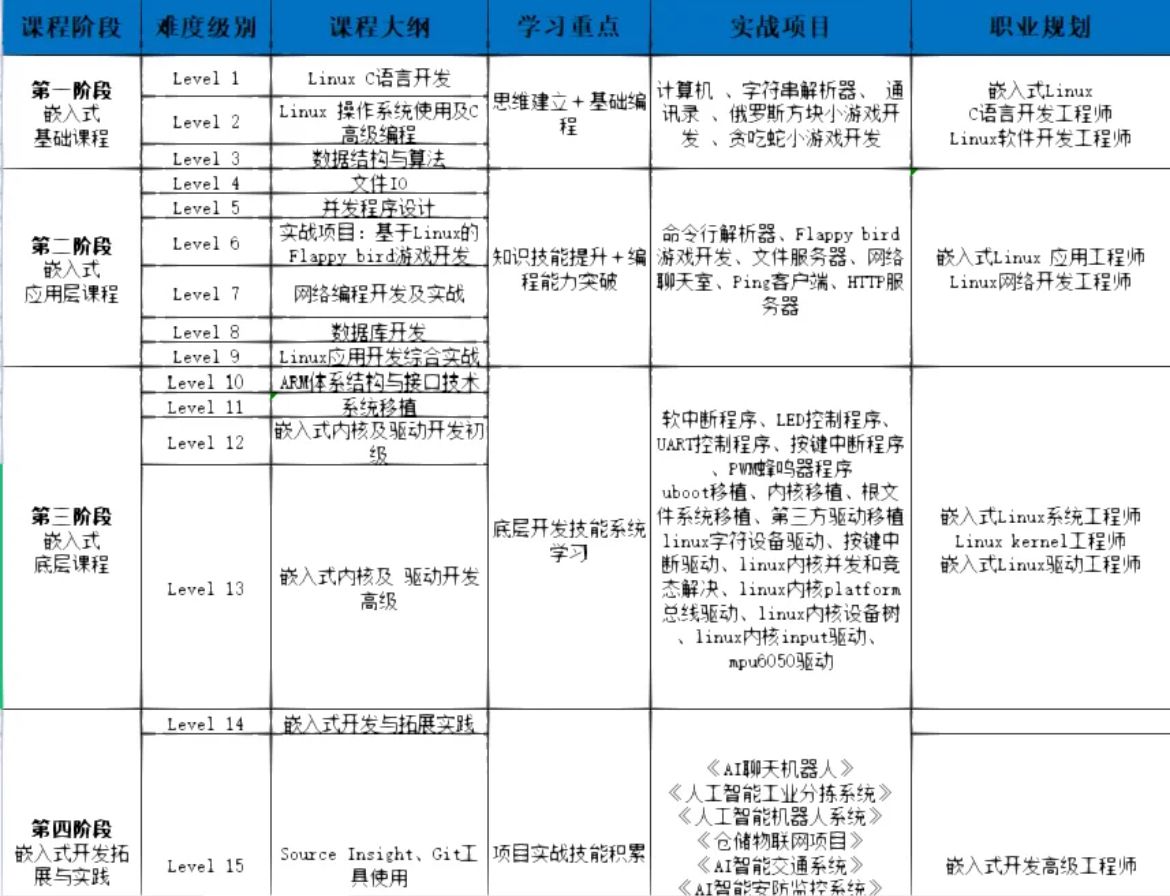
概览:

在内部,子系统可以配置为实现多达8个独立的物理DMA引擎(最多4个H2C和4个C2H)。这些DMA引擎可以映射到单独的AXI4Stream接口,也可以将共享的AXI4内存映射(MM)接口映射到用户应用程序。在axis4 MM接口上,PCI Express®的DMA/桥接子系统生成请求和预期完成。axis4 - stream接口仅支持数据
H2C (Host-to-Card)通道向PCIe发出读请求,并向用户应用提供数据或生成写请求。
卡到主机(C2H)通道要么在用户端等待数据,要么在用户端生成一个读请求,然后生成一个写请求,其中包含收到的数据到PCIe
PCIe的DMA/桥接子系统也使主机能够访问用户逻辑。到达PCIe到DMA旁路基址寄存器(BAR)的写请求由DMA处理。来自写请求的数据通过PL逻辑的NoC接口转发给用户应用程序。PCIe的DMA/桥接子系统也使主机能够访问用户逻辑。到达PCIe到DMA旁路基址寄存器(BAR)的写请求由DMA处理。来自写请求的数据通过PL逻辑的NoC接口转发给用户应用程序。
BAR是什么意思??
H2C通道 的数量在AMD Vivado™集成设计环境(IDE)中配置。H2C通道处理从主机到卡的DMA传输。它负责根据最大读请求大小和可用的内部资源拆分读请求。DMA通道根据rnum_rid保持最大未完成请求数,rnum_rid是未完成的H2C通道请求ID参数的数量。读请求的每次拆分(如果有的话)都会消耗一个额外的读请求条目。当DMA通道收到用户界面上按顺序完成写操作的确认时,向PCIe RQ块发出读操作后,请求是未完成的。在传输完成后,DMA通道发出回写或中断来通知主机。H2C通道也在其读和写接口上分割事务。在到主机的读接口上,事务被分割以满足配置的最大读请求大小,并基于可用的Data FIFO空间。数据FIFO空间在读取请求时分配,以确保读取完成的空间。PCIe RC块将完成数据返回到分配的数据缓冲区位置。为了最小化延迟,在接收到任何完成数据后,H2C通道开始向用户界面发出写请求。它还将写请求分解为最大有效负载大小。在AXI4-Stream用户界面上,这种分割是透明的。当启用多个通道时,axis4 Master接口上的事务(就是请求??)在所有选定的通道之间交错进行。采用简单轮询协议服务所有通道。事务粒度取决于主机最大有效负载大小(MPS)、页面大小和其他主机设置。
C2H通道处理从卡到主机的DMA传输。C2H通道的实例化数量在AMD Vivado™IDE中控制。类似地,未完成传输的数量是通过wnum_rid配置的,它是C2H通道请求id的数量。在AXI4-Stream配置中,DMA传输的细节是在AXI4-Stream接口上接收数据之前设置的。这通常是通过接收DMA描述符来完成的。在准备好请求ID并启用通道之后,通道的AXI4Stream接口可以接收数据并对主机执行DMA。在AXI4 MM接口配置中,请求id是在发出对AXI4 MM接口的读请求时分配的。与H2C通道类似,在写请求完成之前,给定的请求ID是未完成的。对于C2H通道,写请求完成是指PCIe IP指示的写请求已经发出。当启用多个通道时,axis4 Master接口上的事务在所有选定的通道之间交错进行。采用简单轮询协议服务所有通道。事务粒度取决于主机的MaxPayload Size (MPS)、页面大小和其他主机设置。
AXI4-Lite Master该模块实现了axis4 - lite主总线协议。主机可以通过该接口向用户逻辑生成32位读、32位写请求。读或写请求通过PCIe接收到AXI4-Lite主BAR。读完成数据通过目标桥通过PCIe IP CC总线返回给主机
AXI4-Lite Slave该模块实现了AXI4-Lite从总线协议。用户逻辑只能掌握在DMA内部寄存器上的32位读或写操作。不能通过该接口访问PCIe集成块寄存器。该接口不生成对主机的请求。
Host-to-Card Bypass Master到达PCIe到DMA旁路BAR的主机请求被发送到该模块。旁路主端口是一个ax4mm接口,支持读写访问
IRQ模块从用户逻辑接收可配置数量的中断线,从每个DMA通道接收一条中断线。该模块负责通过PCIe产生中断。可以在IP配置期间指定对MSI- x、MSI和遗留中断的支持。注意:在IP配置期间,主机可以从指定的支持中断列表中启用一种或多种中断类型。IP在给定时间只生成一种中断类型,即使有多个中断类型被启用。MSI- x中断优先于MSI中断,MSI中断优先于Legacy中断。主机软件不能切换(启用或禁用)中断类型,而有一个中断断言或挂起。



配置模块,DMA寄存器空间,包含PCIe®解决方案IP配置信息和DMA控制寄存器,存储与PCIe的DMA/Bridge子系统相关的PCIe IP配置信息。该配置信息可以通过寄存器读取读取到配置模块中适当的寄存器偏移量
PCIe DMA引擎只是将数据移到或移出PCIe地址位置。在典型的操作中,主机中的应用程序在FPGA和主机内存之间移动数据。为了完成这种传输,主机在系统内存中设置缓冲空间,并创建DMA引擎用来移动数据的描述符。描述符的内容将取决于许多因素,包括为DMA引擎选择哪个用户界面。如果选择了AXI4-Stream接口,则C2H传输不使用源地址字段,H2C字段不使用目的地址。这是因为AXI4-Stream接口是一个不使用地址的FIFO类型接口。如果选择了AXI内存映射接口,则C2H传输的源地址为AXI地址,目的地址为PCIe地址。对于H2C传输,源地址是PCIe地址,目的地址是AXI地址。数据传输流程:pg195 p20-23
描述符:像链表一样,前一个描述符包含指向下一个描述符的信息,知道最后一个描述符。DMA具有Bit_width * 512深度FIFO来保存描述符引擎中的所有描述符。这个描述符FIFO与所有选定的通道共享,并且仅在内部模式下使用(而不是在描述符旁路模式下使用)。•对于具有2H2C和2C2H设计的Gen3x8, AXI位宽度为256位。FIFO深度为256位* 512 = 32b * 512 = 16kb(512个描述符)。这个FIFO由4个DMA引擎共享。//描述符获取引擎可以通过AMD Vivado™IDE参数在每个通道的基础上绕过。启用了描述符旁路的通道从其各自的c2h_dsc_byp或h2c_dsc_byp总线接受描述符。在通道接受描述符之前,必须设置控制寄存器运行位。当绕过描述符时,不使用NextDescriptorAddress和NextAdjacentCount以及Magic描述符字段。控制寄存器位中的ie_descriptor_stopped位不会阻止用户逻辑写入额外的描述符。所有写入通道的描述符都会被处理,除非在通道缓冲区已满时写入新的描述符//(大概的意思就是bypass是接收描述符的通路,当启用的bypass,描述符就从bypass上传输)??//每个引擎都能够将完成的描述符计数写回主机内存。这允许驱动程序轮询主机内存以确定DMA何时完成,而不是等待中断。
DMA H2C Stream:
对于主机到卡的传输,从源地址处的主机读取数据,但描述符中的目标地址是未使用的。数据包可以跨越多个描述符。包的终止由EOP控制位表示。带有EOP位的描述符在数据的最后一个节拍上断言AXI4-Stream用户界面上的tlast。
交付给axis4 - stream接口的数据将为每个描述符打包。如果Tkeep不是数据路径宽度的倍数,则除了描述符数据传输的最后一个周期外,Tkeep都是1s。DMA不会跨多个描述符打包数据。(就是说 stream模式下不适用目的地址,只是用带有EOP的描述符,当EOP出现的时候,tlast拉高,表示不再接收数据)
DMA C2H Stream:
对于卡到主机的传输,从AXI4-Stream接口接收数据并将其写入目标地址。数据包可以跨越多个描述符。C2H通道在启用时接受数据,并具有有效的描述符。当接收到数据时,它按顺序填充描述符。当描述符被完全填充或由于接口上的数据包结束而关闭时,C2H通道将信息用预定义的WB Magic值16'h52b4(表10:C2H流回写字段)回写到主机上的回写地址,并根据需要更新EOP和长度。对于C2H AXI4-Stream接口上的有效数据周期,与给定数据包关联的所有数据必须是连续的(就是说 接收数据填充描述符,描述符就像计数器一样,当描述符满了的时候,stream会向主机回写一个信息。)C2H流描述符的长度(目标缓冲区的大小)必须始终是64字节的倍数。
端口描述:用于PCI Express®的AMD DMA/Bridge子系统直接连接到用于PCIe的集成块。PCIe集成块IP的数据路径接口有64、128、256或512位宽,根据IP配置的不同,接口的工作频率最高可达250mhz。数据路径宽度适用于除AXI4-Lite接口以外的所有数据接口。AXI4-Lite接口固定为32位宽。

7系列Gen2和Virtex 7 Gen3: PCIe参考时钟。应该从参考时钟IBUFDS_GTE2的O端口驱动。
![]()
从PCIe边缘连接器复位信号复位
![]()
PCIe派生时钟输出m_axi*和s_axi*接口。ax_aclk是从GT块的TXOUTCLK引脚派生出来的时钟;在断言axi_aresetn时,不期望它连续运行。
![]() 输输出 Active-High标识 连接到主机设备
输输出 Active-High标识 连接到主机设备
内部信号在手册31-43页
寄存器空间,有关寄存器的描述核定义在手册43-75页
Clocking and Resets:
axi_aclk输出是用于所有AXI接口的时钟,应该驱动所有相应的AXI Interconnect ack信号。
对于在AXI桥接模式下的PCIe的DMA/桥接子系统,有一个可选的dma_bridge_resetn输入引脚,它允许您重置所有内部桥接引擎和寄存器以及由ax_aresetn引脚驱动的所有AXI外设。
Lane Width: The subsystem requires the selection of the initial lane width
带宽:子系统要求选择初始车道宽度
Maximum Link Speed: The subsystem requires the selection of the PCIe Gen speed.
最大链路速度:子系统需要选择PCIe Gen速度。
参考时钟频率:默认为100mhz,也支持125mhz和250mhz
复位:您可以在User Reset和Phy ready之间选择。一旦链路建立,用户复位来自PCIe核心。当PCIe链路断开时,断言User Reset, XDMA进入复位模式。当链接恢复时,用户重置被解除。当选择Phy ready选项时,XDMA不受PCIe链路状态的影响。
GT DRP时钟选择:选择内部时钟(默认)或外部时钟。
GT Selection, Enable GT Quad Selection:选择0号通道所在的Quad。
AXI地址宽度:目前只支持64位宽度。
AXI数据宽度:选择64、128、256位或512位(仅适用于UltraScale+)。该子系统允许您选择接口宽度
AXI时钟频率:根据通道宽度/速度选择62.5 MHz、125 MHz或250 MHz。
DMA接口选项:选择AXI4内存映射和AXI4- stream
数据保护:默认禁用奇偶校验,当启用Check Parity时,XDMA会对从PCIe读数据进行奇偶校验,并对写入PCIe的数据进行奇偶校验,当“传播奇偶校验”被启用时,XDMA将奇偶校验传播到用户AXI接口。用户负责在用户AXI接口上检查和生成奇偶校验。
PCIe ID Tab:启用PCIe-ID接口:通过启用此选项,PCIe_ID端口作为输入端口,您希望连接到所需的适当值。
在Endpoint配置中,核心最多支持6个32位BAR或3个64位BAR,以及扩展只读存储器(ROM) BAR。bar有两种大小:
约束:PCI Express®的DMA/桥接子系统需要定时和其他物理实现约束的规范,以满足PCI Express的指定性能要求。这些约束在Xilinx Design constraints (XDC)文件中提供。生成的XDC中的引脚和层次结构名称对应于所提供的示例设计
示例设计:

当启用axis4 - stream接口时,每个H2C流通道都被循环回C2H通道。如下图所示,示例设计给出了axis4流的环回设计。限制是您需要选择相同数量的H2C和C2H通道才能正常运行。这个示例设计还显示了PCIe到DMA旁路接口和PCIe到axis - lite Master的选择。
User IRQ Example Design:
用户IRQ示例设计使主机能够连接到axis4 - lite Master接口以及用于PCI Express®示例设计的默认DMA/Bridge子系统。在示例设计中,用户中断生成器模块和外部块RAM集成在这个AXI4-Lite接口上。主机可以使用该接口通过写入用户中断生成器模块的寄存器空间来生成用户IRQ,也可以对外部1K块RAM进行读写。下图显示了示例设计。

设置驱动程序:p123,暂时还没看