标准扩散模型(standard diffusion)和潜在(latent diffusion)扩散模型的关键区别、对潜在扩散模型的认识
1.两者的关键区别
潜在扩散模型通过在低维潜在空间的扩散过程,可以减少内存和计算的复杂性。而standard diffusion是在像素级别的空间(actual pixel space)进行扩散.
2.latent diffusion model的具体讲解
其有三个主要的组成部分:
1.一个autoencoder(VAE)
2.一个U-Net模型
3.一个文本编码器,CLIP的文本编码器(text-encoder,CLIP’s Text Encoder)
1.The autoencoder (VAE)
VAE模型由两个部分组成,即编码器和解码器。编码器用于将图像转换为低维潜在表示,该表示将作为U-Net模型的输入。相反,解码器将潜在表示转换回图像。
在潜在扩散训练过程中,编码器用于获取图像的潜在表示(潜在变量)进行前向扩散过程,该过程在每一步逐渐应用更多噪声。在推断过程中,通过逆扩散过程生成的去噪潜在变量被转换回图像,使用VAE解码器。在推断过程中,我们只需要VAE解码器。
2.The U-Net
U-Net有编码器部分和解码器部分,均由ResNet块组成。编码器将图像表示压缩为较低分辨率的图像表示,解码器将较低分辨率的图像表示重新解码为原始更高分辨率的图像表示。更具体地说,U-Net的输出预测了噪声残差,可以用来计算预测去噪图像表示。
为了防止U-Net在卷积时丢失重要信息,通常会在编码器的降采样ResNets和解码器的升采样ResNets之间添加残差连接。此外,稳定扩散U-Net能够通过交叉注意力层将输出条件化于文本嵌入。交叉注意力层通常添加在U-Net的编码器和解码器部分之间的ResNet块之间。
3. The Text-encoder
文本编码器负责将输入提示(例如“一名骑马的宇航员”)转换为可以被 U-Net 理解的嵌入空间。通常使用基于变换器的简单编码器,将一系列输入标记映射到一系列潜在文本嵌入中。
受 Imagen 启发,稳定扩散在训练时不训练文本编码器,而是简单地使用已经训练好的 CLIP 文本编码器 CLIPTextModel。
3.为什么潜在扩散快速而有效率?
由于潜在扩散是在低维空间上运行的,与像素空间扩散模型相比,它极大地降低了内存和计算要求。例如,稳定扩散中使用的自编码器具有8倍的缩减因子。这意味着形状为(3, 512, 512)的图像在潜在空间中变为(3, 64, 64),这样需要的内存就减少了8 × 8 = 64倍。这也是其与标准扩散模型的一个关键的区别。
4.推理过程图
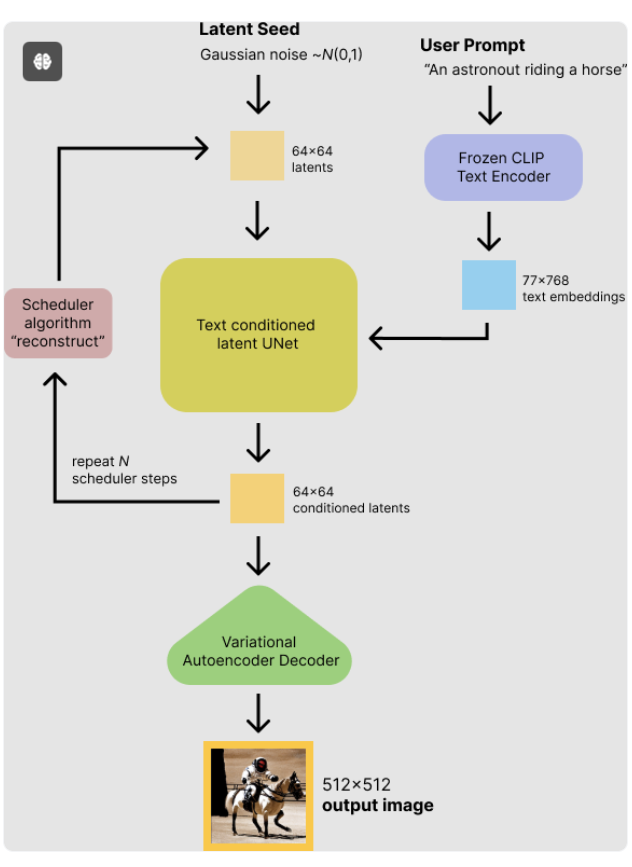
首先,稳定扩散模型将潜在种子和文本提示作为输入。然后,使用潜在种子生成尺寸为64×64的随机潜在图像表示,而文本提示则通过CLIP的文本编码器转换为尺寸为77×768的文本嵌入。
接下来,U-Net 在文本嵌入的条件下,迭代去噪随机潜在图像表示。U-Net 的输出是噪声残差,通过调度算法用于计算去噪后的潜在图像表示。可以使用许多不同的调度算法进行这种计算,每种都有其优缺点。对于 Stable Diffusion,建议使用的如下所示:
1.PNDM scheduler
2.DDIM scheduler
3.K-LMS scheduler
如果想要了解更多详细的信息可以参考下面:
Elucidating the Design Space of Diffusion-Based Generative Models
参考链接:
1.Stable Diffusion with 🧨 Diffusers (huggingface.co)
ce.co/blog/stable_diffusion#how-does-stable-diffusion-work)
2.[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models (arxiv.org)