本文结构:
一、引言
二、代码分享
三、问题总结
引言
这两天因为一些需求,研究了一下如何爬取京东商品数据。最开始还是常规地使用selenium库进行商品页的商品抓取,后来因为想要获取优惠信息,只能进入到商品详情页进行抓取,想着用selenium库模拟浏览器行为进行页面抓取速度有点慢,就改用了requests库直接发送请求,然后问题就来了:明明在页面看到了优惠满减字段,抓取的结果却是空白的。
百度研究了一番,总算找到了原因。最后因为商品抓取量不大,所以还是乖乖的使用了selenium库进行爬虫。
代码分享
爬虫代码如下:
# -*- coding: utf-8 -*-
"""
爬取京东商品排行榜商品信息
"""
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
import re
import time
##京东排行榜地址:https://top.jd.com/
writer=pd.ExcelWriter(r"D:\python学习\京东排行榜商品.xlsx")##数据写入的文件
##使用selenium模拟浏览器登陆
#需要下载安装chromedriver
driver = webdriver.Chrome(r"C:\chromedriver.exe")
driver.set_page_load_timeout(60)#设置页面最大加载等待时间
category = ["手机","平板电脑"]#需要爬取的品类
category_url = ["https://top.jd.com/sale?cateId=653","https://top.jd.com/sale?cateId=2694"]#爬取品类的网页
for ci,c in enumerate(category_url,start=0):
driver.get(c)#发送请求
time.sleep(3)
#################################获取排行榜信息###############################333
info_name =[] #商品信息
tag1 = [] #标签一:x天最低
tag2 = [] #标签二:自营/包邮/促销/赠品
tag3 = [] #标签三:好评率
price = [] #商品价格
link = [] #商品详情页
bs = BeautifulSoup(driver.page_source,"html.parser")
sale_list = bs.findAll("li",class_=re.compile('saleitem'))
for s in sale_list:
info_name.append(s.find("p",class_ = "saleitem_info_name").get_text())
t = s.find("li",class_ = "top_mod_tag_item top_mod_tag_dj")
if t is not None:
tag1.append(t.get_text())
else:
tag1.append("")
t = s.find("li",class_ = re.compile("top_mod_tag_item top_mod_tag_[^(dj)]"))
if t is not None:
tag2.append(t.get_text())
else:
tag2.append("")
t = s.find("li",class_ = "top_mod_tag_item",text=re.compile("好评率.*"))
if t is not None:
tag3.append(t.get_text())
else:
tag3.append("")
price.append(s.find('p',class_ = "saleitem_info_price").get_text())
link.append(s.find('a',class_ = "saleitem_link").get("href"))
#################进入商品详情页,获取商品的优惠券########################
coupon = []
for i,l in enumerate(link, start=1):
driver.get(r"https:" + l)
time.sleep(3)
bs = BeautifulSoup(driver.page_source,"html.parser")
try:
coupon.append(bs.find("div",class_="summary").find("div",id = "summary-quan").find("span",class_ = "text").get_text())
except:
coupon.append("")
print("抓取品类:%s,第%d个商品优惠券信息完成" %(category[ci],i))
time.sleep(3)
data = pd.DataFrame({"商品信息":info_name,"标签一(x天最低)":tag1,"标签二(自营/包邮/促销/赠品)":tag2,"标签三(好评率)":tag3,"价格":price,"商品详情页":link,"优惠券":coupon})
data.to_excel(writer,sheet_name=category[ci],index=False)
driver.close()
爬虫的步骤很简单。直接使用selenium库webdriver访问需要抓取的网址,然后进行html标签定位,使用Beautifulsoup库进行数据提取,之后使用pandas写入excel文件保存。
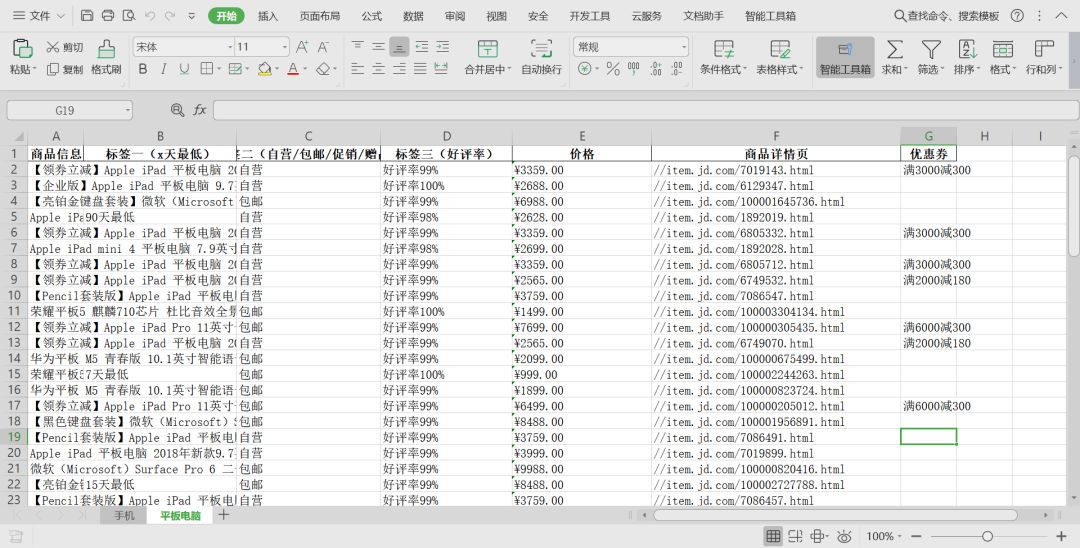
抓取结果如下:
问题总结
最开始的问题出在哪儿呢?为什么如果直接使用requests库get请求,结果抓取不到价格数据?
简单代码尝试了一下
import requests
from bs4 import BeautifulSoup
response = requests.get("https://item.jd.com/27009615825.html")
bs = BeautifulSoup(response.content,"html.parser")
print(bs.find("div",class_="summary").find("div",id = "summary-quan").find("span",class_ = "text"))
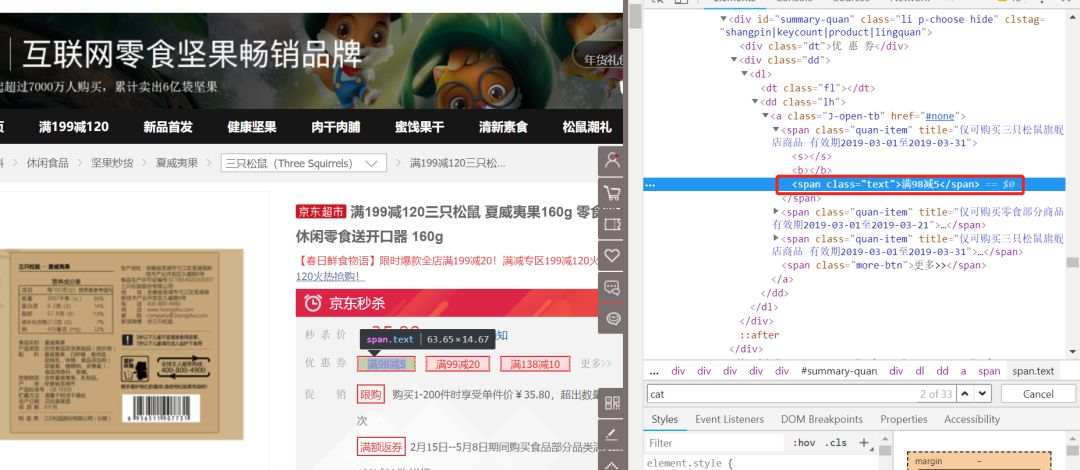
明明打开浏览器的开发者工具可以看到优惠信息就存放在class属性值为 ‘text’的span标签下,但是抓取到的结果却为空。
输出结果如下:
In[1]: print(bs.find("div",class_="summary").find("div",id = "summary-quan").find("span",class_ = "text"))None
百度了解到的原因是,京东网页中价格等信息并不是存放在静态网页中的,我们使用requests获取到网页源码,进行html解析,只会获取到空值。京东会采取js动态加载数据。那些商品价格、优惠券信息等等,并不是放在静态网页中的。每次加载页面,js脚本都会对数据接口进行调用请求数据,然后返回到页面上。所以,对于动态页面的抓取,一种办法就是借助工具找到js脚本请求的数据接口,使用requests库直接访问该接口获取数据。如价格信息就放在:
https://p.3.cn/prices/mgets?callback=jQuery6775278&skuids=J_(skuid)
其中链接最后括号里存放商品的sku id,比如:
https://p.3.cn/prices/mgets?callback=jQuery6775278&skuids=J_27009615825
商品的sku id可以在商品详情页的html抓取到。
关于京东的数据抓取,网上能百度到有完整的项目,有兴趣的可以了解一下:
CSDN地址:
https://blog.csdn.net/Kandy_Ye/article/details/70183110
Github代码:
https://github.com/KandyYe/JDSpider
另外,更加简单的一种办法就是使用selenium库进行数据采集了。selenium模拟浏览器行为,等到页面加载完成后,再获取完整的数据源码,所以在处理数据的时候就不需要担心我们抓取不到啦。但是有点小缺陷就是,selenium库比requests要慢。
据说还有一个两者的结合体——requestium,或许可以有更好