Linux服务器常用的命令:find、grep、xargs、sort、uniq、tr、cut、paste、wc、sed、awk;提供的例子和参数都是最常用和最为实用的。
1.find 文件查找
-
查找txt和pdf文件
find . \( -name "*.txt" -o -name "*.pdf" \) -print -
正则方式查找.txt和pdf
find . -regex ".*\(\.txt|\.pdf\)$"-iregex: 忽略大小写的正则
-
否定参数
查找所有非txt文本find . ! -name "*.txt" -print -
指定搜索深度
打印出当前目录的文件(深度为1)find . -maxdepth 1 -type f
1.1定制搜索
-
按类型搜索:
find . -type d -print //只列出所有目录-type f 文件 / l 符号链接
-
按时间搜索:
-atime 访问时间 (单位是天,分钟单位则是-amin,以下类似)
-mtime 修改时间 (内容被修改)
-ctime 变化时间 (元数据或权限变化)
最近7天被访问过的所有文件:find . -atime 7 -type f -print -
按大小搜索:
w字 k M G
寻找大于2k的文件find . -type f -size +2k按权限查找:
find . -type f -perm 644 -print //找具有可执行权限的所有文件按用户查找:
find . -type f -user weber -print// 找用户weber所拥有的文件
1.2找到后的后续动作
-
删除:
删除当前目录下所有的swp文件:find . -type f -name "*.swp" -delete -
执行动作(强大的exec)
find . -type f -user root -exec chown weber {} \; //将当前目录下的所有权变更为weber注:{}是一个特殊的字符串,对于每一个匹配的文件,{}会被替换成相应的文件名;
eg:将找到的文件全都copy到另一个目录:find . -type f -mtime +10 -name "*.txt" -exec cp {} OLD \; -
结合多个命令
tips: 如果需要后续执行多个命令,可以将多个命令写成一个脚本。然后 -exec 调用时执行脚本即可;-exec ./commands.sh {} \;
1.3-print的定界符
默认使用'\n'作为文件的定界符;
-print0 使用'\0'作为文件的定界符,这样就可以搜索包含空格的文件;
2.grep 文本搜索
grep match_patten file // 默认访问匹配行
-
常用参数
-o 只输出匹配的文本行 VS -v 只输出没有匹配的文本行
-c 统计文件中包含文本的次数grep -c "text" filename-n 打印匹配的行号
-i 搜索时忽略大小写
-l 只打印文件名 -
在多级目录中对文本递归搜索(程序员搜代码的最爱):
grep "class" . -R -n - 匹配多个模式
grep -e "class" -e "vitural" file - grep输出以\0作为结尾符的文件名:(-z)
grep "test" file* -lZ| xargs -0 rm
3.xargs 命令行参数转换
xargs 能够将输入数据转化为特定命令的命令行参数;这样,可以配合很多命令来组合使用。比如grep,比如find;
-
将多行输出转化为单行输出
cat file.txt| xargs
\n 是多行文本间的定界符 -
将单行转化为多行输出
cat single.txt | xargs -n 3
-n:指定每行显示的字段数
3.1 xargs参数说明
-d 定义定界符 (默认为空格 多行的定界符为 \n)
-n 指定输出为多行
-I {} 指定替换字符串,这个字符串在xargs扩展时会被替换掉,用于待执行的命令需要多个参数时
eg:
cat file.txt | xargs -I {} ./command.sh -p {} -1-0:指定\0为输入定界符
eg:统计程序行数
find source_dir/ -type f -name "*.cpp" -print0 |xargs -0 wc -l3.2 sort 排序
字段说明:
-n 按数字进行排序 VS -d 按字典序进行排序
-r 逆序排序
-k N 指定按第N列排序
eg:
sort -nrk 1 data.txt
sort -bd data // 忽略像空格之类的前导空白字符3.3 uniq 消除重复行
- 消除重复行
sort unsort.txt | uniq - 统计各行在文件中出现的次数
sort unsort.txt | uniq -c - 找出重复行
可指定每行中需要比较的重复内容:-s 开始位置 -w 比较字符数sort unsort.txt | uniq -d
4.用tr进行转换
-
通用用法
echo 12345 | tr '0-9' '9876543210' //加解密转换,替换对应字符 cat text| tr '\t' ' ' //制表符转空格 -
tr删除字符
cat file | tr -d '0-9' // 删除所有数字-c 求补集
cat file | tr -c '0-9' //获取文件中所有数字 cat file | tr -d -c '0-9 \n' //删除非数字数据 -
tr压缩字符
tr -s 压缩文本中出现的重复字符;最常用于压缩多余的空格cat file | tr -s ' ' -
字符类
tr中可用各种字符类:
alnum:字母和数字
alpha:字母
digit:数字
space:空白字符
lower:小写
upper:大写
cntrl:控制(非可打印)字符
print:可打印字符
使用方法:tr [:class:] [:class:]eg: tr '[:lower:]' '[:upper:]'
5.cut 按列切分文本
- 截取文件的第2列和第4列:
cut -f2,4 filename - 去文件除第3列的所有列:
cut -f3 --complement filename - -d 指定定界符:
cat -f2 -d";" filename - cut 取的范围
N- 第N个字段到结尾
-M 第1个字段为M
N-M N到M个字段 - cut 取的单位
-b 以字节为单位
-c 以字符为单位
-f 以字段为单位(使用定界符) - eg:
cut -c1-5 file //打印第一到5个字符 cut -c-2 file //打印前2个字符
6. paste 按列拼接文本
将两个文本按列拼接到一起;
cat file1
1
2
cat file2
colin
book
paste file1 file2
1 colin
2 book 默认的定界符是制表符,可以用-d指明定界符
paste file1 file2 -d ","
1,colin
2,book
7. wc 统计行和字符的工具
wc -l file // 统计行数
wc -w file // 统计单词数
wc -c file // 统计字符数
8. sed 文本替换利器
- 首处替换
seg 's/text/replace_text/' file //替换每一行的第一处匹配的text -
全局替换
seg 's/text/replace_text/g' file默认替换后,输出替换后的内容,如果需要直接替换原文件,使用-i:
seg -i 's/text/repalce_text/g' file -
移除空白行:
sed '/^$/d' file -
变量转换
已匹配的字符串通过标记&来引用.echo this is en example | seg 's/\w+/[&]/g' $>[this] [is] [en] [example] -
子串匹配标记
第一个匹配的括号内容使用标记 \1 来引用sed 's/hello\([0-9]\)/\1/' -
双引号求值
sed通常用单引号来引用;也可使用双引号,使用双引号后,双引号会对表达式求值:sed 's/$var/HLLOE/'当使用双引号时,我们可以在sed样式和替换字符串中指定变量;
eg: p=patten r=replaced echo "line con a patten" | sed "s/$p/$r/g" $>line con a replaced -
其它示例
字符串插入字符:将文本中每行内容(PEKSHA) 转换为 PEK/SHAsed 's/^.\{3\}/&\//g' file
9. awk 数据流处理工具
-
awk脚本结构
awk ' BEGIN{ statements } statements2 END{ statements } ' -
工作方式
1.执行begin中语句块;
2.从文件或stdin中读入一行,然后执行statements2,重复这个过程,直到文件全部被读取完毕;
3.执行end语句块;
9.1 print 打印当前行
-
使用不带参数的print时,会打印当前行;
echo -e "line1\nline2" | awk 'BEGIN{print "start"} {print } END{ print "End" }' -
print 以逗号分割时,参数以空格定界;
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; \ print var1, var2 , var3; }' $>v1 V2 v3 - 使用-拼接符的方式(""作为拼接符);
echo | awk ' {var1 = "v1" ; var2 = "V2"; var3="v3"; \ print var1"-"var2"-"var3; }' $>v1-V2-v3
9.2 特殊变量: NR NF $0 $1 $2
NR:表示记录数量,在执行过程中对应当前行号;
NF:表示字段数量,在执行过程总对应当前行的字段数;
$0:这个变量包含执行过程中当前行的文本内容;
$1:第一个字段的文本内容;
$2:第二个字段的文本内容;
echo -e "line1 f2 f3\n line2 \n line 3" | awk '{print NR":"$0"-"$1"-"$2}'- 打印每一行的第二和第三个字段:
awk '{print $2, $3}' file -
统计文件的行数:
awk ' END {print NR}' file -
累加每一行的第一个字段:
echo -e "1\n 2\n 3\n 4\n" | awk 'BEGIN{num = 0 ; print "begin";} {sum += $1;} END {print "=="; print sum }'
9.3 传递外部变量
var=1000
echo | awk '{print vara}' vara=$var # 输入来自stdin
awk '{print vara}' vara=$var file # 输入来自文件9.4 用样式对awk处理的行进行过滤
awk 'NR < 5' #行号小于5
awk 'NR==1,NR==4 {print}' file #行号等于1和4的打印出来
awk '/linux/' #包含linux文本的行(可以用正则表达式来指定,超级强大)
awk '!/linux/' #不包含linux文本的行
9.5 设置定界符
使用-F来设置定界符(默认为空格)
awk -F: '{print $NF}' /etc/passwd
9.6 读取命令输出
使用getline,将外部shell命令的输出读入到变量cmdout中;
echo | awk '{"grep root /etc/passwd" | getline cmdout; print cmdout }' 9.7 在awk中使用循环
for(i=0;i<10;i++){print $i;}
for(i in array){print array[i];}
eg:
以逆序的形式打印行:(tac命令的实现)
seq 9| \
awk '{lifo[NR] = $0; lno=NR} \
END{ for(;lno>-1;lno--){print lifo[lno];}
} '9.8 awk实现head、tail命令
-
head:
awk 'NR<=10{print}' filename -
tail:
awk '{buffer[NR%10] = $0;} END{for(i=0;i<11;i++){ \ print buffer[i %10]} } ' filename
9.9 打印指定列
- awk方式实现:
ls -lrt | awk '{print $6}' - cut方式实现
ls -lrt | cut -f6
9.10 打印指定文本区域
- 确定行号
seq 100| awk 'NR==4,NR==6{print}' - 确定文本
打印处于start_pattern 和end_pattern之间的文本;
eg:awk '/start_pattern/, /end_pattern/' filenameseq 100 | awk '/13/,/15/' cat /etc/passwd| awk '/mai.*mail/,/news.*news/'
9.11 awk常用内建函数
index(string,search_string):返回search_string在string中出现的位置
sub(regex,replacement_str,string):将正则匹配到的第一处内容替换为replacement_str;
match(regex,string):检查正则表达式是否能够匹配字符串;
length(string):返回字符串长度
echo | awk '{"grep root /etc/passwd" | getline cmdout; print length(cmdout) }' printf 类似c语言中的printf,对输出进行格式化
eg:
seq 10 | awk '{printf "->%4s\n", $1}'10. 迭代文件中的行、单词和字符
10.1 迭代文件中的每一行
-
while 循环法
while read line; do echo $line; done < file.txt 改成子shell: cat file.txt | (while read line;do echo $line;done) -
awk法:
cat file.txt| awk '{print}'
10.2 迭代一行中的每一个单词
for word in $line;
do
echo $word;
done10.3 迭代每一个字符
${string:start_pos:num_of_chars}:从字符串中提取一个字符;(bash文本切片)
${#word}:返回变量word的长度
for((i=0;i<${#word};i++))
do
echo ${word:i:1);
done实用命令和脚本:
1、查看端口占用情况
# 查看该端口是否被占用 | |
netstat -lnp|grep 5000 | |
# 查看端口是否被占用 | |
lsof -i:'5000' | |
# 杀死端口占用进程,根据进程号杀死 | |
kill -9 28533 | |
# 再次查看,如果查看时候提示命令不存在 : | |
# 需要先安装一下命令 | |
yum -y install net-tools | |
# 最常见的还有防火墙 | |
yum install firewalld |
2、查看空间磁盘使用情况、CPU信息
# 查看空间使用情况 | |
df -h | |
# 查看当前目录下空间使用情况 | |
du -lh --max-depth=1 | |
# 或 | |
du -sh * |
CPU信息查看
# 查看CPU信息 | |
lscpu |
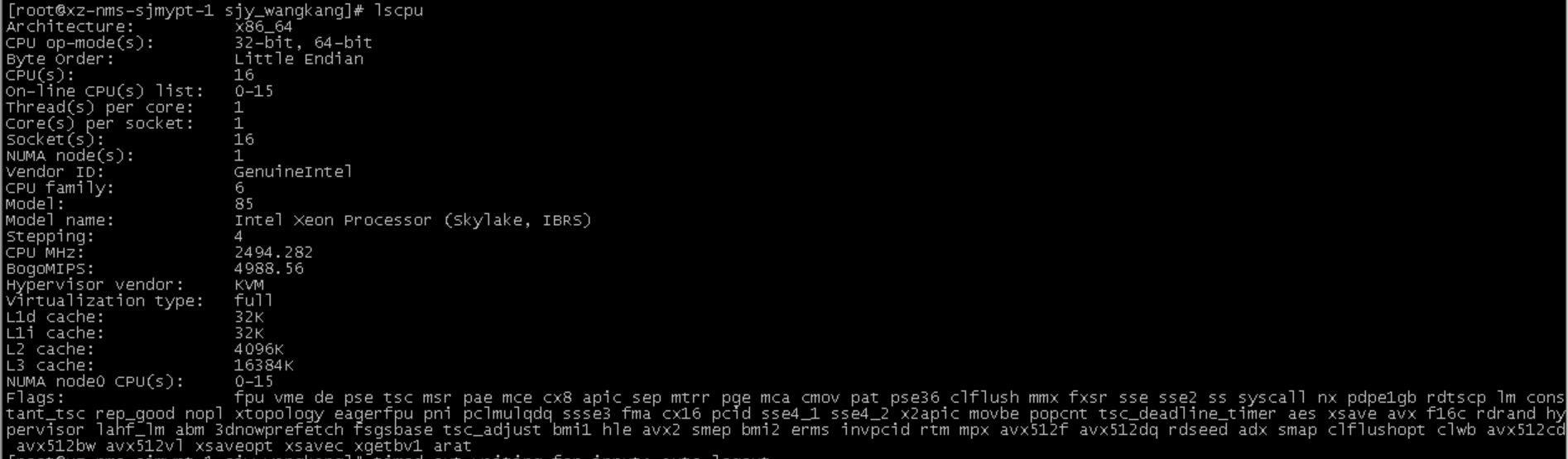
从上述信息中,我们可以得到如下几个重要的参数:
CPU(s):4 表示系统中可用的CPU数量为4个。
On-line CPU(s) list:0-3 表示在线CPU的编号为0、1、2、3,如果有CPU处于离线状态,则不会出现在这个列表中。
Thread(s) per core:2 表示每个CPU内核有2个线程。
Core(s) per socket:2 表示每个CPU插槽有2个内核。
Socket(s): 1 表示系统中有1个CPU插槽。
Model name:cpu所属品牌:因特尔或AMD或其他
3、按时间批量删除文件
需要根据时间删除这个目录下的文件,/home/lifeccp/dicom/studies,清理掉20天之前的无效数据。
find /home/lifeccp/dicom/studies -mtime +21 -name "*.*" -exec rm -Rf {} \; |
简要解释该Shell命令
- /home/lifeccp/dicom/studies :准备要进行清理的任意目录
- -mtime:标准语句写法
- +10:查找10天前的文件,这里用数字代表天数,+30表示查找30天前的文件
- "*.*":希望查找的数据类型,"*.jpg"表示查找扩展名为jpg的所有文件,"*"表示查找所有文件
- -exec:固定写法
- rm -rf:强制删除文件,包括目录
- {} \; :固定写法,一对大括号+空格+/+;
注意:在我本人使用的时候,发现可能会存在1-2天的延后误差,比如:删除10天前的,可能删除了12天前的,大家执行完可以检查一下
4、scp远程拷贝命令详解
1.命令格式:scp [参数] [原路径] [目标路径]
2.命令功能:
scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录。
3.命令参数:
-1 强制scp命令使用协议ssh1
-2 强制scp命令使用协议ssh2
-4 强制scp命令只使用IPv4寻址
-6 强制scp命令只使用IPv6寻址
-B 使用批处理模式(传输过程中不询问传输口令或短语)
-C 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
-p 保留原文件的修改时间,访问时间和访问权限。
-q 不显示传输进度条。
-r 递归复制整个目录。
-v 详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
-c cipher 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
-F ssh_config 指定一个替代的ssh配置文件,此参数直接传递给ssh。
-i identity_file 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
-l limit 限定用户所能使用的带宽,以Kbit/s为单位。
-o ssh_option 如果习惯于使用ssh_config(5)中的参数传递方式,
-P port 注意是大写的P, port是指定数据传输用到的端口号
-S program 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。
4、常用示例:
4.1、从本地复制到远程
scp -r /root/lk root@43.224.34.73:/home/lk/cpfile
在本地服务器上将/root/lk目录下所有的文件传输到服务器43.224.34.73的/home/lk/cpfile目录下
4.2、从远程复制到本地
scp -r root@43.224.34.73:/home/lk /root
在本地服务器上操作,将服务器43.224.34.73上/home/lk/目录下所有的文件全部复制到本地的/root目录下
原文链接:scp命令详解-CSDN博客
5、按时间查找文件
根据日期查找相关文件
# /recordings/ 查找的目录 ,默认当前目录 | |
ls --full-time /recordings/ | sed -n '/2018-03-21/p' |
按照日期范围查找相关文件
find images/ -newermt '2021-01-01' ! -newermt '2021-01-31' | |
# 按时间范围拷贝文件到另一台服务器(内网) | |
scp -p ssh端口(22)'文件路径' '目标主机账号'@'IP':'存放到目标路径' |
统计文件个数
# wc -l 统计文件个数 | |
ls --full-time /recordings/ | sed -n '/2018-03-21/p' | wc -l |
6、文件、文件夹统计
6.1、个数统计
Linux 中可以通过 ls -l 或者 find -type f 来统计文件、文件夹的个数,具体操作如下。 | |
查看某文件夹下文件的个数: | |
ls -l | grep "^-" | wc -l | |
# ls -l 列出文件及文件夹 | |
# "^-" 以-开头的行 文件以-开头 文件夹以d开头 | |
# wc -l 统计行数 | |
或者可以: | |
find ./ -type f | wc -l | |
# ./ 在当前目录查找 | |
# -type f 文件类型 -name "*.conf*" 根据文件后缀查找 | |
# wc -l 统计行数 | |
查看某文件夹下文件的个数,包括子文件夹: | |
ls -lR | grep "^-" | wc -l | |
# -R 递归列出子目录的文件 | |
查看某文件夹下文件夹的个数,包括子文件夹: | |
ls -lR | grep "^d" | wc -l | |
# "^d" 以d开头的行 |
6.2、系统文件及内存大小统计
使用 du、df、free 进行统计,详细见下
1、du详解
2.1 du 详解 | |
Linux du 命令用于显示目录或文件的大小。 | |
du 会显示指定的目录或文件所占用的磁盘空间。 | |
语法: | |
du [-abcDhHklmsSx] [目录或文件] | |
参数说明: | |
-a 或 -all:显示目录中文件的大小,单位 KB | |
-b:显示目录中文件的大小,以字节 byte 为单位 | |
-c:显示目录中文件的大小,同时显示总和,单位 KB | |
-k:显示目录中文件的大小,单位 KB | |
-m:显示目录中文件的大小,单位 MB | |
-s:仅显示目录的总值,单位 KB | |
-h:--human-readable 以K,M,G为单位,提高信息的可读性。 | |
-x:以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。 | |
-H:--si 与 -h参数相同,但是 K、M、G是以1000为换算单位 | |
--max-depth = 1 :遍历深度 | |
实例: | |
du -h * # 显示当前目录下文件的大小 | |
du -sh # 查看当前文件夹大小 | |
du -sh * | sort -nr # 统计当前文件夹(目录)大小,并按文件大小排序 -- 加了-h之后排序有问题 | |
du -sk filename # 查看指定文件大小 | |
使用 sort 的参数 -nr 表示要以数字排序法进行反向排序,因为我们要对目录大小做排序,所以不可以使用 human-readable 的大小输出,不然目录大小中会有 K、M 等字样,会造成排序不正确。 | |
如果有一个进程在打开一个大文件的时候,这个大文件直接被 rm 或者mv 掉,则 du 会更新统计数值,df 不会更新统计数值,还是认为空间没有释放。直到这个打开大文件的进程被Kill掉。 |
2、df详解
2.2 df 详解 | |
Linux df 命令显示磁盘分区上可以使用的磁盘空间。 | |
df 可以查看一级文件夹大小、使用比例、档案系统及其挂入点,但对文件却无能为力。 | |
du可以查看文件及文件夹的大小。 | |
两者配合使用,非常有效。 | |
比如用 df 查看哪个一级目录过大,然后用 du 查看文件夹或文件的大小,如此便可迅速确定症结。 | |
语法: | |
df [选项] [file] | |
参数说明: | |
-a: --all 包含所有的具有 0 Blocks 的文件系统,单位默认 KB | |
-h:使用 -h 选项以 KB、MB、GB 的单位来显示,可读性高~~~(最常用) | |
-i:查看目前档案系统 inode 的使用情形 | |
有的时候虽然档案系统还有空间,但若没有足够的 inode 来存放档案的信息,一样会不能增加新的档案。 | |
所谓的 inode 是用来存放档案及目录的基本信息 (metadata),包含时间、档名、使用者及群组等。在分割扇区时,系统会先做出一堆 inode 以供以后使用,inode 的数量关系着系统中可以建立的档案及目录总数。如果要存的档案大部分都很小,则同样大小的硬盘中会有较多的档案,也就是说需要较多的 inode 来挂档案及目录。 | |
实例: | |
df -h | |
Filesystem Size Used Avail Use% Mounted on | |
/dev/sda1 3.9G 300M 3.4G 8% / | |
/dev/sda7 100G 188M 95G 1% /data0 | |
/dev/sdb1 133G 80G 47G 64% /data1 | |
/dev/sda6 7.8G 218M 7.2G 3% /var | |
/dev/sda5 7.8G 166M 7.2G 3% /tmp | |
/dev/sda3 9.7G 2.5G 6.8G 27% /usr | |
tmpfs 2.0G 0 2.0G 0% /dev/shm | |
Filesystem -- 档案系统 | |
Mounted on -- 挂入点 | |
size -- 分区容量 | |
Used -- 已使用的大小 | |
Avail -- 剩下的大小 | |
Use% -- 使用的百分比 | |
FreeBSD下,当硬盘容量已满时,可能会看到已使用的百分比超过 100%,因为 FreeBSD 会留一些空间给 root,让 root 在档案系统满时,还是可以写东西到该档案系统中,以进行管理。 |
3、free详解
2.3 free 详解 | |
Linux free 命令可以显示 Linux 系统中空闲的、已用的物理内存及交互区内存(swap),及被内核使用的 buffer(内核缓冲区内存)。共享内存将被忽略。 | |
语法: | |
free [参数] | |
total used free shared buffers cached | |
Mem: 32948032 32767416 180616 0 139960 29878896 | |
-/+ buffers/cache: 2748560 30199472 | |
Swap: 8193140 664956 7528184 | |
参数说明: | |
-b:以 Byte 为单位显示内存使用情况 | |
-k:以 KB 为单位显示内存使用情况 | |
-m:以 MB 为单位显示内存使用情况 | |
-g:以 GB 为单位显示内存使用情况 | |
-s'秒': 每xx秒更新一次内存情况 例如:-s5,每5秒更新一次 | |
-t:显示内存综合列 |
7、查看系统信息
查看内核版本
# 查看内核 | |
uname -r |
查看系统信息
# 查看系统信息 | |
lsb_release -a | |
# 没有以上的命令,可使用一下命令查看 XX为发行版名称。如 centos-release | |
cat /etc/xxx-release |
查看内核和操作系统相关信息
# 查看操作系统相关信息 | |
uname -a | |
# 查看宽带实时使用率 | |
nload |
7.1、查看进程详细信息
- 格式
top [-] [d delay] [q] [c] [S] [s] [i] [n] - 主要参数
d:指定更新的间隔,以秒计算。
q:没有任何延迟的更新。如果使用者有超级用户,则top命令将会以最高的优先序执行。
c:显示进程完整的路径与名称。
S:累积模式,会将己完成或消失的子行程的CPU时间累积起来。
s:安全模式。
i:不显示任何闲置(Idle)或无用(Zombie)的行程。
n:显示更新的次数,完成后将会退出top。
在Liunx系统下执行top命令显示如下:
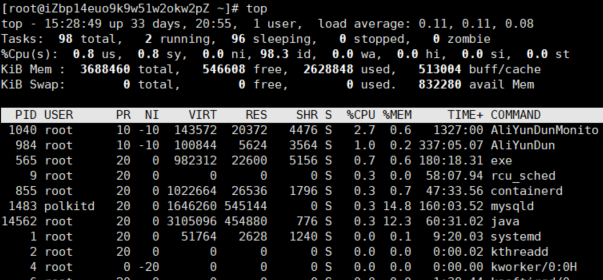
第一行表示的依次为当前时间、系统运行时间、当前系统登录用户数目、1/5/10分钟系统平均负载(一般来说,这个负载值应该不太可能超过 1 才对,除非您的系统很忙碌。 如果持续高于 5 的话,那么…..仔细的看看到底是那个程序在影响整体系统吧!)。
第二行显示的是所有启动的进程、目前运行、挂起 (Sleeping)的和无用(Zombie)的进程。(比较需要注意的是最后的 zombie 那个数值,如果不是 0 ,嘿嘿!好好看看到底是那个 process 变成疆尸了吧?!)(stop模式:与sleep进程应区别,sleep会主动放弃cpu,而stop是被动放弃cpu ,例单步跟踪,stop(暂停)的进程是无法自己回到运行状态的)
第三行显示的是目前CPU的使用情况,包括us用户空间占用CPU百分比、sy 内核空间占用CPU百分比、ni 用户进程空间内改变过优先级的进程占用CPU百分比(中断处理占用)、id 空闲CPU百分比、wa 等待输入输出的CPU时间百分比、hi,si,st 三者的意思目录还不清楚 :)
第四行显示物理内存的使用情况,包括总的可以使用的内存、已用内存、空闲内存、缓冲区占用的内存。
第五行显示交换分区使用情况,包括总的交换分区、使用的、空闲的和用于高速缓存的大小。
第六行显示的项目最多,下面列出了详细解释:
PID(Process ID):进程标示号 ( 每个 process 的 ID )
USER:进程所有者的用户名 ( 该 process 所属的使用者 )
PR:进程的优先级别 ( Priority 的简写,程序的优先执行顺序,越小越早被执行 )
NI:进程的优先级别数值 ( Nice 的简写,与 Priority 有关,也是越小越早被执行 )
VIRT:进程占用的虚拟内存值。
RES:进程占用的物理内存值。
SHR:进程使用的共享内存值。
S:进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值是负数。
%CPU:该进程占用的CPU使用率。
%MEM:该进程占用的物理内存和总内存的百分比。
TIME+:该进程启动后占用的总的CPU时间 ( CPU 使用时间的累加 )
Command:进程启动的启动命令名称,如果这一行显示不下,进程会有一个完整的命令行。
top命令使用过程中,还可以使用一些交互的命令来完成其它参数的功能。这些命令是通过快捷键启动的。
<空格>:立刻刷新。
P:根据CPU使用大小进行排序。
T:根据时间、累计时间排序。
q:退出top命令。
m:切换显示内存信息。
t:切换显示进程和CPU状态信息。
c:切换显示命令名称和完整命令行。
M:根据使用内存大小进行排序。
W:将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
查看某进程的详细情况
top -d 1 -p 'pid'-d:指定更新的间隔,以秒计算;-p:指定查看的进程 条件:进程号
top命令是一个功能十分强大的监控系统的工具,它的缺点是会消耗很多系统资源。
7.2、时区/时间设置
# 1、读取时间 | |
timedatectl | |
# 2、设置时间 | |
timedatectl set-time “YYYY-MM-DD HH:MM:SS” | |
# 3、列出所有时区 | |
timedatectl list-timezones | |
# 4、设置时区 可以通过tab键补全 | |
timedatectl set-timezone Asia/Shanghai | |
# 5、是否NTP服务器同步 yes或者no | |
timedatectl set-ntp yes | |
# 6、将硬件时钟调整为与本地时钟一致 | |
timedatectl set-local-rtc 1 | |
# 与上面命令效果一致 | |
hwclock --systohc --localtime |

7.3、网络时间同步
安装工具 | |
yum -y install ntp ntpdate | |
同步网络时间 | |
ntpdate cn.pool.ntp.org |
8、开放及查看端口
查看已开放端口
# 查看开放端口 | |
firewall-cmd --list-ports |
开放及关闭端口(开放后需要要重启防火墙才生效)
# 开放单个端口 | |
firewall-cmd --zone=public --add-port=8080/tcp --permanent | |
# 开放多个端口 | |
firewall-cmd --zone=public --add-port=20000-29999/tcp --permanent | |
# 关闭端口 | |
firewall-cmd --zone=public --remove-port=8080/tcp --permanent | |
# 重启防火墙 | |
firewall-cmd --reload |
(--permanent 为永久生效,不加为单次有效(重启失效))
防火墙操作
# 查看防火墙状态 | |
systemctl status firewalld | |
# 开启防火墙 | |
systemctl start firewalld | |
# 关闭防火墙 | |
systemctl stop firewalld | |
# 重启防火墙 | |
systemctl restart firewalld | |
# 开机自启 | |
systemctl enable firewalld | |
# 开机禁用 | |
systemctl disable firewalld |
9、文件夹或文件属组、属主、权限赋予
更改文件属组
chgrp [-R] 属组名 文件夹/文件名 |
更改文件属组、属主
chown [-R] 属主名 文件夹/文件名 | |
chown [-R] 属主名:属组名 文件夹/文件名 |
-R:递归更改文件属组,就是在更改某个目录文件的属组时,如果加上-R的参数,那么该目录下的所有
文件的属组都会更改。
更改文件权限
给.sh文件赋予可执行权限
chmod +x 文件名 | |
# 示例 | |
chmod +x test.sh |
9.1、符号类型修改法
我们把九个权限分别是 user,group,others三种身份,借由u、g、o来代表,采用a表示所有权限,其余的r、w、x分别代表读、写、执行权限。使用如下表的方法

比如我们要对一个文件权限为“-rwxr-xr–”修改为“-rwxrwxr-x”,则需要对用户组身份的权限追加w权限,对其他用户追加x 权限,所以这样执行:
chmod g+w, o+x filename 或者 chmod g=rwx, o=rx filename
10、扩展命令
10.1、命令间隔执行
# 单条命令间隔执行 | |
# -d 高亮显示本次刷新和上次刷新不同的地方 如:-d "date" | |
# -t 可执行复合命令 如: "ps -ef | grep ps" | |
watch -n 1 'ls' | |
# 更多帮助 | |
watch --help |
10.2、历史命令
# 历史命令 | |
history | |
# 清除本次登陆执行过的历史命令,不清空历史记录文件只清空内存 | |
history -c | |
# -c:清空内存中的命令历史,不会清空历史文件中的记录 | |
# -d:删除制定命令历史记录,不会清空历史文件中的记录 | |
# -r:从历史命令文件中读取历史命令到内存中 | |
# -w:将内存中历史命令追加至历史命令文件中 | |
# 历史命令是存在于当前用户根目录下的./bash_history文件。 |
10.3、查看路由信息
route |
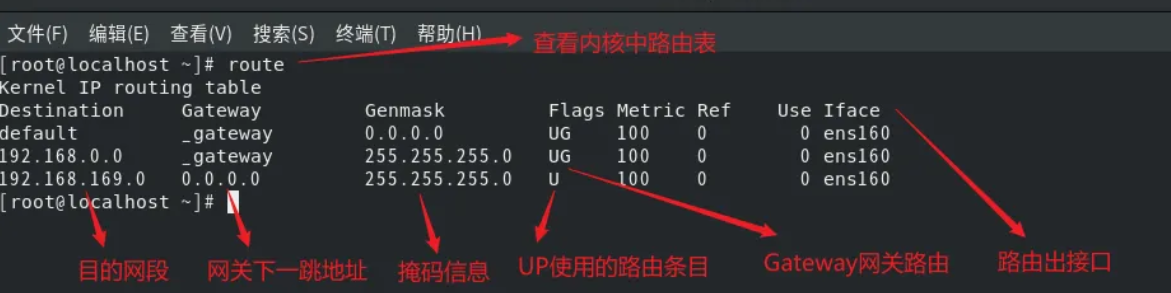
具体route使用 可参考博客:route command_linux route命令-CSDN博客
10.3.1、路由跟踪
traceroute:检测发出数据包的主机到目标主机之间所经过的网关数量的工具
常用命令:traceroute -T -p [port] [目标IP]
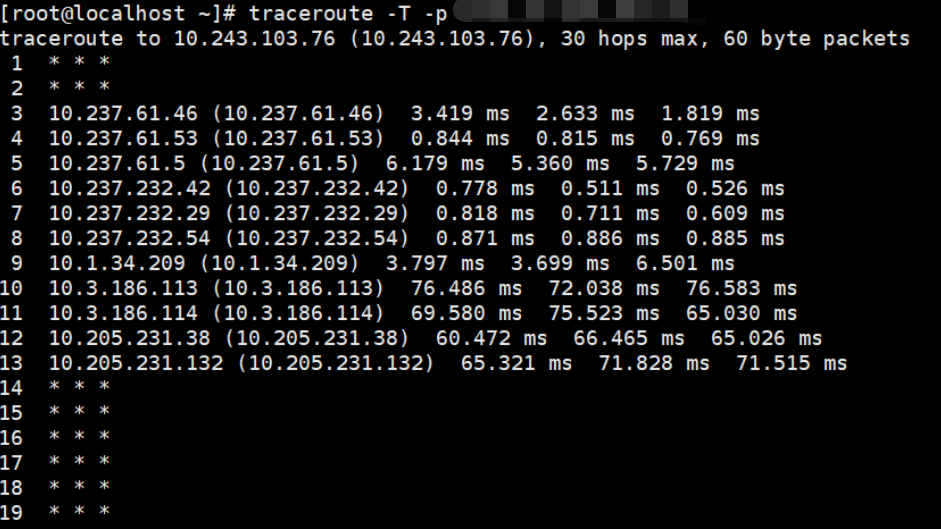
可参考博客:Linux命令:traceroute命令(路由跟踪)_traceroute -t-CSDN博客
10.4、crontab(定时任务)
利用5个* 进行周期控制,执行命令需要指定exe程序和文件位置
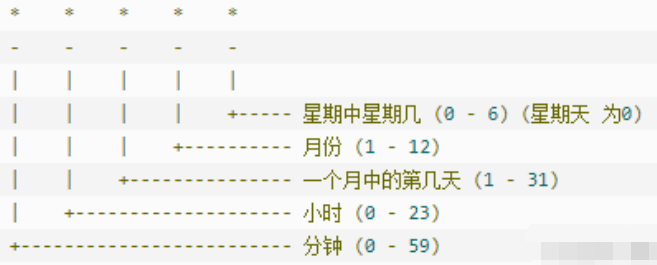
示例:00 2 * * * command表示每日凌晨2点执行命令
编辑crontab任务
crontab -e
输入i,即进行insert编辑
Esc 退出编辑模式
:wq保存并退出
启动/停止任务
service crond start | |
service crond restart | |
service crond stop |
查看任务是否执行
日志记录:/var/log/cron、/var/spool/mail/root更详细
查看状态:如显示active(running)即正在执行
crontab -l #查看定时任务列表 | |
service crond status |
10.5、Linux挂载
命令格式:mount [-t vfstype] [-o options] device dir
例子:mount -t iso9660 -o ro /dev/cdrom /mnt/cdrom/
-t vfstype 指定文件系统的类型,通常不必指定,mount 会自动选择正确的类型。
光盘或光盘镜像:iso9660
DOS fat16文件系统:msdos
Windows 9x fat32文件系统:vfat
Windows NT ntfs文件系统:ntfs
Mount Windows文件网络共享:smbfs
UNIX(LINUX) 文件网络共享:nfs
-o options 主要用来描述设备或档案的挂接方式。
loop:用来把一个文件当成硬盘分区挂接上系统
ro:采用只读方式挂接设备
rw:采用读写方式挂接设备
iocharset:指定访问文件系统所用字符集
device 要挂接(mount)的设备。
dir设备在系统上的挂接点(mount point)。
卸载挂载:umount /mnt/cdrom
可参考挂载博客:Linux挂载-CSDN博客
10.6、大文件内容快速替换
# 编辑文件 | |
vim /data/demo.csv | |
# 按下Esc退出键 输入: 后面跟上%s/@/|/g表示将表中@符号替换为|分隔符 | |
%s/@/|/g |

10.7、用户密码有效期设置
查看某用户密码过期时间等信息:chage -l 用户名
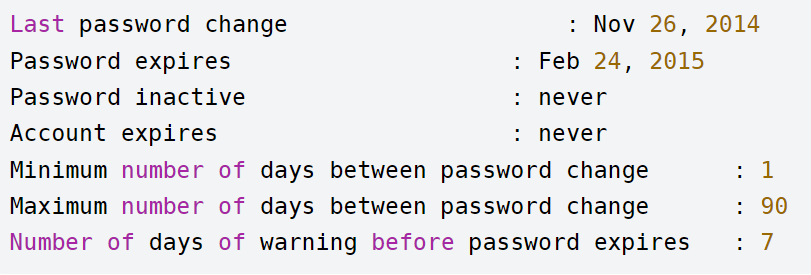
修改某用户密码过期时间:chage -M 99999 用户名 / usermod -e '具体过期日期'