结构化与非结构化数据的读取方法
文章目录
- 结构化与非结构化数据的读取方法
- 1. 结构化数据的读取
- 1.1 pandas 读取 excel 文件
- 1.2 pandas 读取 csv 文件
- 1.3 pandas 读取 txt 文件
- 1.4 利用 scipy 读取 mat 格式文件数据
- 1.5 利用 numpy 存储和读取 npz 格式文件
- 2. python 读取图像的常用方式
- 2.1 利用 Pillow 库实现图像的输入、输出及保存
- 2.2 使用 scikit-image 输入输出、图像及保存图像
- 3.3 使用 matplotlib 读取、保存和现实图像
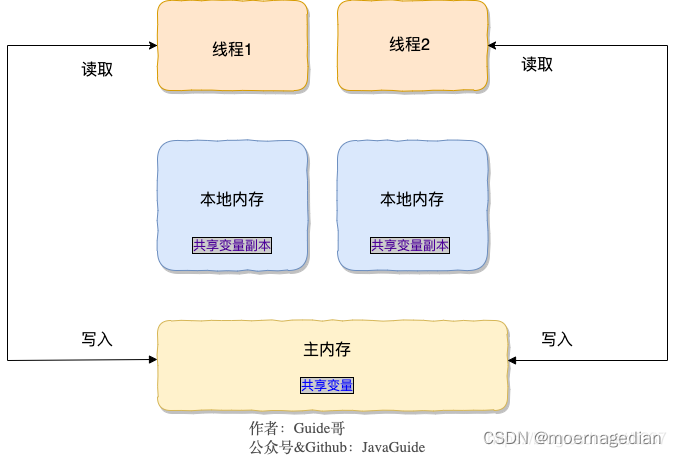
数据的表现格式有两种: 一种是结构化数据; 另一种是非结构化数据. 结构化数据指的是具有明确含义的行列结构存储形式, 如常见的excel格式中, 行表示样本点, 每一列表示各自的特征(如身高、体重等). 非结构化数据存储时虽有行和列的结构,但是没有明确的含义, 如图像, 行只是表示第几行, 列只是表示第几列, 而行或者列之间并没有意义上的区别. 下面将介绍两种存储方式的 python 读取方法, 因为数据只有读入内存才能进行处理.
1. 结构化数据的读取
本文的数据可通过链接下载, 该数据中的两个数据由《python大数据分析与应用实战》提供, 数据链接:: https://pan.baidu.com/s/149b4Z1Hp2xRUTxdopklu-A 提取码: brij, 下载数据后放在代码同级目录下的data文件夹中即可
1.1 pandas 读取 excel 文件

import numpy as np
import pandas as pd
#读取疫情数据、数据格式变换
df = pd.read_excel('data/01感染人数分布数据.xlsx',sheet_name='各地区确诊')#读取历史疫情数据
df.index = df['日期'] #修改索引值为日期
df1 = df.drop(['日期'], axis=1)#删除多余日期列
df1

1.2 pandas 读取 csv 文件
import pandas as pd
df = pd.read_csv('data/sanya12345.csv',index_col=0)#读取数据
print(df.info())
‘’‘
<class 'pandas.core.frame.DataFrame'>
Int64Index: 184568 entries, 125282 to 127953
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 orderAll 184568 non-null float64
1 order 184568 non-null float64
2 工单编号 184568 non-null int64
3 工单分类 184567 non-null object
4 工单来源 184567 non-null object
5 来电时间 184567 non-null object
6 来电类型 184567 non-null object
7 工单标题 184567 non-null object
8 工单内容 184567 non-null object
9 工单状态 184567 non-null object
10 是否延期 184568 non-null object
11 序号 183977 non-null float64
12 处理时间 184567 non-null object
13 处理环节 184567 non-null object
14 处理单位 184179 non-null object
15 处理描述 184567 non-null object
16 extractAddress 131264 non-null object
17 lon84 126785 non-null float64
18 lat84 126785 non-null float64
19 cluster 184568 non-null int64
dtypes: float64(5), int64(2), object(13)
memory usage: 29.6+ MB
None
’‘’
1.3 pandas 读取 txt 文件
pandas 读取的数据类型为 DataFrame (或 Series),可通过 .values 操作提取 ndarray 形式.
import numpy as np
import pandas as pd
mat = pd.read_table('data/matrix_data.txt',header=None,sep=',')
print('读入数据为:\n',mat)
print('\n\n转化为 ndarray 类型: \n',mat.values)
'''
读入数据为:
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
转化为 ndarray 类型:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
'''
1.4 利用 scipy 读取 mat 格式文件数据
Matlab 常用的数据格式为 .mat 格式, python 中可通过 scipy.io 函数库进行读取, 但是读取格式不是一个矩阵,而是一个字典类型, 需要通过字典中的键-值进行提取
import scipy.io as sio
gt_mat = sio.loadmat('data/data.mat') # 读取的数据格式为字典类型
gt_mat
‘’‘
{'__header__': b'MATLAB 5.0 MAT-file, Platform: MACI64, Created on: \xe4\xba\x8c 11 15 18:53:59 2022',
'__version__': '1.0',
'__globals__': [],
'A': array([[-1.3076883 , 3.57839694, 3.03492347, 0.7147429 , 1.48969761],
[-0.43359202, 2.76943703, 0.72540422, -0.20496606, 1.40903449],
[ 0.34262447, -1.34988694, -0.06305487, -0.12414435, 1.41719241]])}
’‘’
gt_mat.keys() # 查看字典的键
‘’‘
dict_keys(['__header__', '__version__', '__globals__', 'A'])
’‘’
gt_mat['A'] # 通过字典的键提取字典相应的值,即可显示为 adarray 格式的矩阵
‘’‘
array([[-1.3076883 , 3.57839694, 3.03492347, 0.7147429 , 1.48969761],
[-0.43359202, 2.76943703, 0.72540422, -0.20496606, 1.40903449],
[ 0.34262447, -1.34988694, -0.06305487, -0.12414435, 1.41719241]])
’‘’
1.5 利用 numpy 存储和读取 npz 格式文件
npz 格式的文件存储和读取需要借助 numpy 库, 可以通过 numpy.savez() 对 array 对象或者列表进行直接存储.
import numpy as np
x = np.array([1,2,3,4,5,6,7,8,9,10])
np.savez('data.npz',x)
读取 npz 格式的文件需要用到 numpy.load() 函数, 读取的数据格式不是原有存贮的格式, 而是一个 NpzFile 对象, 需要通过对象函数 .files 进行提取, 提取出的数据是一个列表, 还需要对数据列表进一步提取.
import numpy as np
y = np.load('data.npz')
print(type(y))
print(y.files)
data = y['arr_0']
data
'''
<class 'numpy.lib.npyio.NpzFile'>
['arr_0']
Out[52]:
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
'''
2. python 读取图像的常用方式
图像的读取与保存是图像处理或计算机视觉领域中最基本的操作,python中有众多的库支持图像的读取、显示与存储,常用的库包括 matplotlib、skimage 和 Pillow 库。使用时,首先测试测试是否安装了 skimage 和 PIL 库。如果没有安装,可以通过 Anaconda-prompt-pip install pillow 和 pip install scikit-image 进行安装。
本部分内容所用的数据放在百度网盘:
链接: https://pan.baidu.com/s/1DXKTofRWufhVpP_HEQKk9A 提取码: pl5u。
下载到本地,置于代码文件同级目录的新建文件夹“images”即可。

2.1 利用 Pillow 库实现图像的输入、输出及保存
Pillow 是 Python 中较为基础的图像处理库,主要用于图像的基本处理,比如裁剪图像、调整图像大小和图像颜色处理等。与 Pillow 相比,OpenCV 和 Scikit-image 的功能更为丰富,所以使用起来也更为复杂,主要应用于机器视觉、图像分析等领域,比如众所周知的“人脸识别”应用 。
from PIL import Image
import matplotlib.pylab as plt
# 图像的读入
im = Image.open("images/parrot.png")
# 显示图像的宽和高,以及图像的颜色通道
print(im.width, im.height, im.mode, im.format, type(im))
plt.axis('off')
plt.imshow(im)
图片进入到内存中,参与运算的主要是矩阵。Pillow 库读取的图像对象无法直接进行数字运算,需要先将图像对象转化成 ndarray形式。图像像素值有两种取值范围,一种是0~255,一种是0~1.
import numpy as np
mat = np.array(im).astype('float')# 转化为 ndarray 形式(像素值为 uint8 类型),且像素值更改为浮点数
mat[0:10,0:10,0]
输出结果
array([[67., 68., 67., 67., 68., 67., 68., 68., 68., 68.],
[69., 68., 68., 68., 68., 68., 69., 68., 68., 68.],
[70., 71., 69., 67., 67., 69., 71., 71., 71., 69.],
[71., 71., 68., 66., 67., 70., 71., 72., 72., 71.],
[70., 69., 68., 67., 66., 69., 70., 71., 72., 71.],
[67., 69., 68., 68., 68., 69., 69., 70., 71., 71.],
[69., 70., 70., 70., 69., 68., 67., 69., 70., 70.],
[69., 69., 69., 70., 70., 68., 67., 67., 68., 68.],
[69., 69., 69., 69., 70., 68., 67., 67., 68., 70.],
[69., 69., 69., 69., 70., 70., 68., 68., 69., 72.]])
我们也可以将 ndarray 格式的矩阵转化成图像对象, 在对图像放缩的时候只有图像格式的数据才能操作, 通过自动插值的方式获得, 而矩阵很难轻松地进行放缩. 这种格式的转换需要用的 PIL.Image.fromarray() 完成此操作.
2.2 使用 scikit-image 输入输出、图像及保存图像
from skimage.io import imread
import matplotlib.pylab as plt
im = imread("images/parrot.png")
print(im.shape, im.dtype, type(im))
plt.figure(figsize=(10,10))
plt.imshow(im)
plt.axis('off')
plt.show()
sk-image 库读取的图像对象同样无法直接进行数字运算,需要先将图像对象转化成 ndarray形式。
import numpy as np
mat = np.array(im).astype('float')# 转化为 ndarray 形式(像素值为 uint8 类型),且像素值更改为浮点数
mat[0:10,0:10,0]
输出
array([[67., 68., 67., 67., 68., 67., 68., 68., 68., 68.],
[69., 68., 68., 68., 68., 68., 69., 68., 68., 68.],
[70., 71., 69., 67., 67., 69., 71., 71., 71., 69.],
[71., 71., 68., 66., 67., 70., 71., 72., 72., 71.],
[70., 69., 68., 67., 66., 69., 70., 71., 72., 71.],
[67., 69., 68., 68., 68., 69., 69., 70., 71., 71.],
[69., 70., 70., 70., 69., 68., 67., 69., 70., 70.],
[69., 69., 69., 70., 70., 68., 67., 67., 68., 68.],
[69., 69., 69., 69., 70., 68., 67., 67., 68., 70.],
[69., 69., 69., 69., 70., 70., 68., 68., 69., 72.]])
3.3 使用 matplotlib 读取、保存和现实图像
matplotlib.image 库中的 imread() 函数可以读取浮点 numpy ndarray 中的图像,像素值表示为 [0,1] 中的真值。
import matplotlib.pylab as plt
import matplotlib.image as mpimg
im = mpimg.imread("images/parrot.png")
print(im.shape,im.dtype,type(im))# 读入的图像包含R、G、B、alpha 四个通道,可通过 convert 进行其它格式的转换不能直接imshow输出
plt.figure(figsize=(10,10))
plt.imshow(im)
plt.axis('off')
plt.show()
利用 matplotlib.image 库读的图片本身就是 ndarray 类型,且像素点格式为浮点数,因此,无需额外进行数字格式的转换。
im[0:5,0:5,0]
输入结果
array([[0.2627451 , 0.26666668, 0.2627451 , 0.2627451 , 0.26666668],
[0.27058825, 0.26666668, 0.26666668, 0.26666668, 0.26666668],
[0.27450982, 0.2784314 , 0.27058825, 0.2627451 , 0.2627451 ],
[0.2784314 , 0.2784314 , 0.26666668, 0.25882354, 0.2627451 ],
[0.27450982, 0.27058825, 0.26666668, 0.2627451 , 0.25882354]],
dtype=float32)
注意:如需将图像保存在本地,可添加代码:im.save(‘本地文件夹路径’)即可,如im.save(“images/parrot_save.jpg”)