目录
一、堆
1.概念
2.堆的存储方式
3.性质
4.模拟实现堆(以小根堆为例)
(1).堆的调整
(2).堆的创建
(3).建堆的时间复杂度
(4).堆的插入和删除
5.堆的应用
(1).PriorityQueue的实现
(2).堆排序
(3).Top-k问题
二、优先级队列
1.概念
2.PriorityQueue详解
(1).常用接口
(2).PriorityQueue的构造方法
(3).常用函数
(4).扩容
(5).注意
三、优先队列(PriorityQueue)和堆(Heap)的区别

一、堆
1.概念
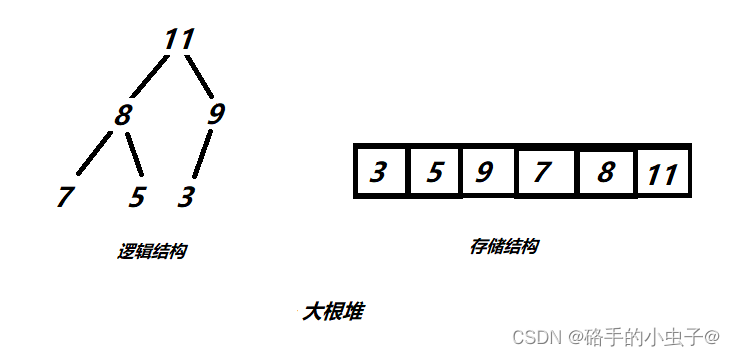
一堆元素集合k={k0,k1...k(n-1)},把所有元素按照完全二叉树的顺序存储方式,存储在一个一维数组中,并且满足ki<=k(2i+1)且ki<=k(2i+2),则称为小堆(反之则为大堆)。
因此在堆的数据结构中,我们将根节点最大的堆称为大根堆或最大堆,将根节点最小的堆称为小根堆或最小堆 。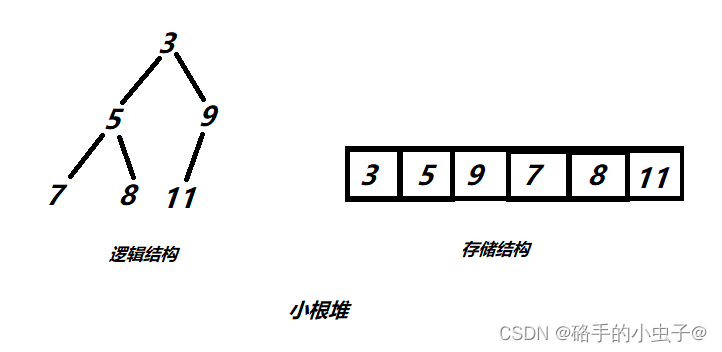
2.堆的存储方式
堆是一棵完全二叉树,因此可以像层序遍历一样采用顺序存储的方式来存储,更加高效。
注意:对于非完全二叉树则不适合使用顺序存储的方式。在还原二叉树时,空间中需要存储空节点,这会导致空间利用率降低
3.性质
(1).小根堆中某个节点的值总是不小于其父节点的值,大根堆中某个节点的值总是不大于其父节点的值。
(2).堆总是一棵完全二叉树。
4.模拟实现堆(以小根堆为例)
(1).堆的调整
【1】.向下调整
1.让parent标记需要调整的节点,child标记parent的左孩子(注意:parent如果有孩子一定先是有左孩子)
2.如果parent的左孩子存在(child<size),则进行以下操作直到parent的左孩子不存在
(1).parent右孩子是否存在,存在找到左右孩子中的最小值,让child进行标记
(2).将parent与较小的孩子child进行比较
【1】.parent小于较小的孩子child时,结束调整
【2】.parent大于较小的孩子child时,交换parent与child的值。此时可能并不正确,因此需要继续向下调整,即parent=child;child=parent*2+1;然后重复上述过程
public void shiftDown(int parent,int len){
int child=2*parent+1;
while(child<size){
if(child+1<size&&elem[child+1]<elem[child]){
child+=1;
}
if(elem[parent]<=elem[child]){
break;
}else{
int tmp=elem[parent];
elem[parent]=elem[child];
elem[child]=tmp;
parent=child;
child=parent*2+1;
}
}
}注意:在整个向下调整的过程中时间复杂度为O (log2N).
【2】.向上调整
1.让child标记需要调整的节点,然后找到child的双亲节点parent。
2.如果双亲节点parent存在(chid>0),则进行以下操作直到双亲节点不存在
(1).将双亲节点与孩子节点进行交换
【1】.如果双亲节点比孩子节点小,parent满足堆的性质,调整结束
【2】.双亲节点大于孩子节点时,交换parent与child的值。此时可能并不正确,因此需要继续向上调整,即child=parent; parent=(child-1)/2; 然后重复上述过程。
public void shiftUp(int child){
int parent =(child-1)/2;
while(child>0){
if(elem[parent]>elem[child]){
break;
}else{
int tmp=elem[parent];
elem[parent]=elem[child];
elem[child]=tmp;
child=parent;
parent=(child-1)/2;
}
}
}注意:在整个向上调整的过程中时间复杂度为O (N).
(2).堆的创建
public class Heap{
public int[] elem;
public int usedSize;
public Heap(){
this.elem=new int[10];
}
public void initElem(int[] arr){
for(int i=0;i<arr.length;i++){
elem[i]=arr[i];
usedSize++;
}
}
public void createHeap(){
for(int parent=(usedSize-1-1)/2;parent>=0;parent--){
shiftDown(parent,usedSize);
}
}
}(3).建堆的时间复杂度
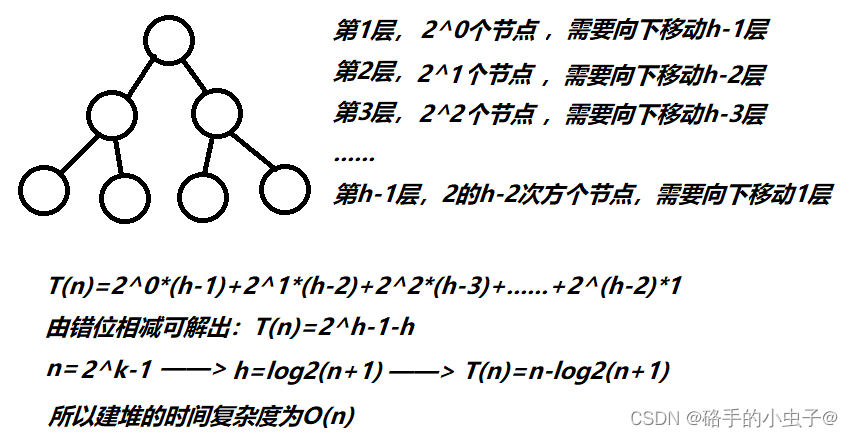
注意:因为堆是完全二叉树,而满二叉树也是完全二叉树,因此简化为满二叉树来证明。
(4).堆的插入和删除
注意:堆的插入和删除时间复杂度均为O(log2N)
【1】.堆的插入
步骤:
1.将元素放到最后一个元素后边,空间不够时需要扩容。
2.将最后新插入的节点向上调整,直到满足要求。
public void push(int val){
if(isFull()){
elem=Arrays.copyOf(elem,2*elem.length);
}
elem[usedSize++]=val;
shiftUp(usedSize-1);
}
public boolean isFull(){
return usedSize==elem.length;
}【2】.堆的删除
步骤:
1.将堆顶元素与堆中最后一个元素交换。
2.将堆中元素有效数据个数减少一个。
3.对堆顶元素进行向下调整。
public void pop(){
if(isEmpty()){
return;
}
int tmp=elem[0];
elem[0]=elem[usedSize-1];
elem[usedSize-1]=tmp;
usedSize--;
shiftDown(0,usedSize);
}
public boolean isEmpty(){
return usedSize==0;
}5.堆的应用
(1).PriorityQueue的实现
用堆作为底层结构封装优先级队列
(2).堆排序
堆排序是利用堆的思想进行排序,首先需要建一个堆,升序排序建大堆,降序排序建小堆;其次利用堆删除思想来进行排序
public void HeapSort(){
int end=usdSize-1;
while(end>0){
swap(elem,0,end);
shiftDown(0,end);
end--;
}
}(3).Top-k问题
求数据集合中前K个最大的元素或最小的元素,一般情况下数据量比较大,普通排序就不可取,因此我们就需要用到堆来排序。
首先用数据集合中前K个元素建堆(求K个最大元素:建小堆;求K个最小元素:建大堆);然后用剩余的N-K个元素依次与堆顶元素比较,堆顶元素不满足则替换。
二、优先级队列
1.概念
队列是一种先进先出的数据结构,但有时操作的数据会带有优先级,所以在出队列时可能需要优先级较高的的元素先出队列。因此数据结构需要提供:返回最高优先级对象和添加新对象这两个基本操作,这种数据结构就是优先级队列。
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列。PriorityQueue是线程不安全的,而PriorityBlockingQueue是线程安全的,本文重点讲解PriorityQueue。
2.PriorityQueue详解
(1).常用接口
(2).PriorityQueue的构造方法
【1】.PriorityQueue():创建一个空的优先级队列,默认容量是11
PriorityQueue<Integer> priorityqueue = new PriorityQueue<>();【2】.PriorityQueue(int initialCapacity):创建一个初始容量为initialCapacity的优先级队列,注意:initialCapacity不能小于1,否则会抛出IllegalArgumentException异常
PriorityQueue<Integer> priorityqueue = new PriorityQueue<>(100);【3】.PriorityQueue(Collection<?extends E> c) 用一个集合来创建优先级队列
ArrayList<Integer> arraylist = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
PriorityQueue<Integer> priorityqueue = new PriorityQueue<>(arraylist);(3).常用函数
boolean offer(E e)
插入元素e,插入成功返回true,如果e对象为空,抛出NullPointerException异常,时间复杂度 ,注意:空间不够时候会进行扩容。
E peek()
获取优先级最高的元素,如果优先级队列为空,返回null
E poll()
移除优先级最高的元素并返回,如果优先级队列为空,返回null
int size()
获取有效元素的个数
void clear()
清空
boolean isEmpty()
检测优先级队列是否为空,空返回true
(4).扩容
如果容量小于64时,是按照oldCapacity的2倍方式扩容的。
如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的。
如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容。
(5).注意
【1】.PriorityQueue中放置的元素必须要能比较大小,不能插入无法比较大小的,否则会抛出ClassCastException异常
【2】.不能插入null对象,否则会抛出NullPointerException
【3】.没有容量限制,可以插入任意多个元素,其内部可以自动扩容
【4】.插入和删除元素的时间复杂度为O(log2N)
【5】.PriorityQueue底层使用了堆数据结构
【6】.PriorityQueue默认是小堆,如果需要大堆需要用户提供比较器
// 自定义比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可
class IntCmp implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
}三、优先队列(PriorityQueue)和堆(Heap)的区别
优先队列:是一种特殊的队列
堆:是一个很大的概念并不一定是完全二叉树,在前文中使用完全二叉树是因为这个很容易被数组储存,所以大部分我们用完全二叉树(数组)来储存堆,但是除了这种二叉堆之外我们还有二项堆、 斐波那契堆等这些堆就不属于二叉树。
优先对列和堆有什么区别呢?这里说的堆默认是我们最常使用的二叉堆,而二叉堆只是优先队列的一种是实现方式而已。而优先队列还有二项堆、平衡树、线段树等来实现。所以说优先队列和堆不是一个概念,如果非要说他们之间的关系就是:二叉堆只是优先队列的一种实现方式,而java的PriorityQueue也是基于这个实现的。