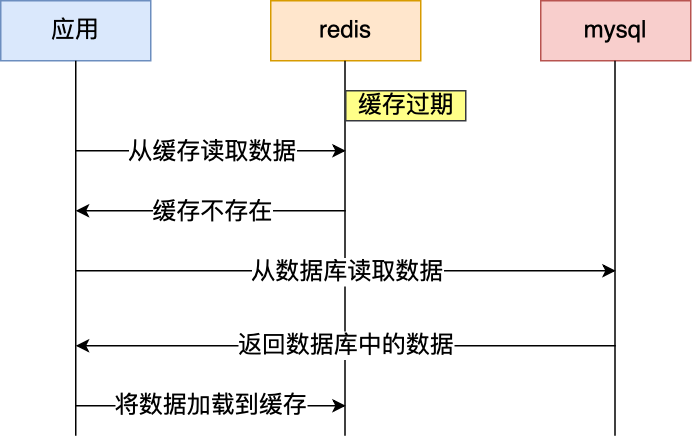
2.1 从多臂赌博机到马尔可夫决策过程
如图2-1,图中A为多臂赌博机,B为一堆鸳鸯,其中左上角为雄性鸳鸯,右上角为雌性鸳鸯,B展示的任务是雄性鸳鸯绕过障碍物找到词性鸳鸯。跟多臂赌博机不同的是,雄性鸳鸯经过一次运动后会运动到另外一个位置,即系统B的状态发生了变化,而多臂赌博机经过一次动作后,其状态仍然是原来的状态。(这里假设每次运动后,多臂赌博机所有的元素都不会发生变化)

多臂学习机通过强化学习算法学到了在固定不变的状态下最优的动作。那么,对于动作后状态发生变化的系统,如何学习到最优的动作呢?
我们仔细分析这类问题。如图2-2.

我们将鸳鸯系统的整个状态空间离散为只包含100各状态的状态空间,雄性鸳鸯在每个状态都有四个可行的动作,即向东、南、西、北四个方向移动。跟多臂赌博机不同的是,雄性鸳鸯需要做一系列的最优动作才能找到雌性鸳鸯。所以,雄性鸳鸯找到雌性鸳鸯是一个序贯决策问题。
然后,强化学习不是万能的,他不能解决所有的序贯决策问题,只能解决建模为马尔可夫决策过程(MDP)过程的序贯决策问题。
马尔可夫决策可以用一个五元组(S,A,P,R,)来描述。其中S为状态空间,A为动作空间,P为状态转移概率,R为回报函数,
为折扣因子。
(1)状态S
在解决实际问题时,最关键的是如何表示要解决问题的状态。一个准则是,状态的表示因该使得状态满足马尔可夫性。(系统的下一个状态只与当前状态有关,与之前的状态无关)
例1:如图2-3为经典的基于DQN解决雅达利游戏Breakthrough的例子。在该例子中,状态的表示为连续的4帧图像=[
],其中
为t时刻的游戏画面帧。这样表示,是为了让其满足马尔可夫性。

例2:在图2-2中,我们将鸳鸯的整个运动空间离散成拥有100个状态的状态空间,每个状态表示一个位置。状态空间S={0,1,...,99}.
对于许多实际问题,我们往往并不能精确地或者人为地表示出状态,而仅仅能得到观测历史和动作历史,即
,这个时候,我们往往可以用机器学习的方法将状态空间的学习表示出来。即

对于有些问题,我们无法知道整个系统的真实状态s,只能知道部分信息。比如游戏地图,我们只知道当前的地图,而不是全部地图。此类问题,称之为部分可观马尔可夫决策。
(2)动作空间A
动作空间是指智能空间可以采取的所有动作的集合。动作空间可以是离散也可以是连续空间。比如雅丽达游戏,动作可以分为17个离散动作;19x19的围棋动作空间为362个离散动作;32自由度机器人的动作空间为32维的连续空间。
智能体的策略定义在动作集上。策略==在给定状态处可行动作空间的动作分布==在状态处,智能体选择每个可行动作的概率或者概率密度。
常用的策略分离散策略和连续策略。
① 离散策略

其中为行为值函数。
②-greedy策略:

③玻尔兹曼策略:

④连续策略:

(3)状态转移概率P
状态转移概率是指给定当前状态St和动作,转移到状态
的概率分布,即

这里的状态转移概率P==系统模型,强化学习算法常常分为无模型和有模型,其中的模型是指状态转移概率P.
(4)回报函数R
R是给定状态 ,采取动作
后,智能体得到的回报,即 r=R(
).
一般来讲,回报是人为设定的回报。比如,雅达利游戏中,回报R来自游戏的得分。R也可以来自某些得分函数。
强化学习算法往往对回报函数R非常敏感,不同的回报函数对于收敛性和学习速度影响非常大。稀疏回报的问题,强化学习算法的效率很低。因此,实际中常用Reward Shaping技术将稀疏回报变为稠密回报。
当拥有专家数据,并且回报函数R未知时,可以通过逆向强化学习的方法从专家数据中学习回报函数。当回报无法人为给出时,可以利用机器学习的方法利用数据进行学习。
(5)折扣因子
折扣因子是衰减未来的回报对当前状态值的贡献,取值常为0~1。一般,完成一次任务需要的步数越多,折扣因子
的取值越接近1.
那么,如何用马尔可夫决策过程来描述一个序贯决策?
如图2-4所示为机器人找金币的例子。在该例子中,机器人并不知道金币在哪里,只能通过与网络环境进行交互找到最优策略。

下面用马尔可夫决策过程的5个元素来描述机器人找金币问题。
(1)状态空间S
S={1,2,3,4,5,6,7,8}
(2)动作空间A
A={'e','s','w','n'}
(3)状态转移概率P
机器人的运动规则,即碰到网格边界仍然保持原来的位置,否则按照运动学更新位置。
(4)回报函数R
机器人每走一格回报为0;遇到金币的回报为1,游戏结束;进入死亡区6或者8的回报为-1,游戏结束。
(5)折扣因子
可以取0-1,这里取0.85。
那么,如何利用马尔可夫决策过程进行学习得到最优策略呢?
所有的学习算法都从数据中进行学习,强化学习也不例外。强化学习从马尔可夫链数据中进行学习。马尔可夫链数据==一个马尔可夫决策过程序列数据。比如在图2-4给出的机器人找金币的例子中,马尔可夫链数据为:

该数据链是机器人在状态1时采取往东的动作,得到回报0,并进入状态2;在状态2时采取往东的动作,得到回报0,进入状态3;在状态3时采取往南的动作,得到回报1,并进入终止状态,游戏结束。
那如何从这个数据链中学习?
强化学习的目标==找到每个状态s处的最优策略。
用来表示策略,那如何说一个策略
比另一个策略
更优?--->值函数的定义。在相同的状态
下,比较两个策略的值函数
,值函数大的策略更优。该值函数反映了整个序贯决策。
最常用的值函数的定义为折扣累积回报的期望:

其中折扣累积回报为

用同样的方法可以定义行为值函数:

①行为值函数(s,a):衡量的是在状态s处,采取动作a后转移到状态s',并从状态s'开始执行策略
所得到的折扣累积回报的期望。可以评估在后继状态策略为
的情况下,当前状态处每个动作的好坏。
②值函数(
):衡量的是在状态s处便开始执行策略
所得到的折扣累积回报的期望。可以评估在当前状态下直接采取策略
的好坏。
如果我们定义一个量 :动作a的优势函数A(s,a)=(s,a)-
(
),那么它的物理意义是当智能体在状态s采取动作a所得到的折扣累计回报的期望比采取策略
所得到的折扣累积回报的期望高多少;差值>0,说明在该状态处采取动作a比执行策略
好。
如何从马尔可夫决策链数据中学习最优的策略?(给出值函数和行为值函数之后)-->如何从马尔可夫决策链数据中学习值函数最大的策略?
①最优值函数的定义:为所有策略中值最大的状态值函数

②最优行为值函数:为所有策略中行为值函数最大的。

智能体决策系统可以利用马尔科夫决策过程(S,A,P,R,)来描述,智能体在策略Π下产生的马尔可夫决策数据链表示为

对应折扣累积回报G(St),在随机策略Π下,马尔可夫决策数据链产生的概率为p(
)强化学习如何通过学习的方法找到最优的策略并使得如下值函数最大?

对于(2-10)有很多种强化学习方法,最主要的分为两类:①利用值函数②利用直接策略搜索,两者可以融合,形成表演家-评论家(AC)的方法。
强化学习中的典型问题:
①状态表示问题
复杂时,利用深度神经网络进行自动特征提取是目前长常用的方法之一。
②置信分配问题
③探索与利用平衡问题
④策略梯度的方差与偏差平衡问题
在直接策略搜索算法中,最常用的是策略梯度的方法。然而,由于无模型,策略的梯度只能从数据中通过估计得到,这便涉及到策略梯度估计方法的偏差和方差问题。偏差和方差。
⑤on-policy和off-policy问题当然越小越好,但有时两者确实矛盾的。
on-policy:同策略==指智能体从当前策略产生的数据中进行学习,可以使智能体的学习稳定。缺点:只向当前策略产生的数据进行学习,因此学习效率和样本利用率低。
off-policy:异策略=指智能体从其他策略产生的数据进行学习。可以向任何策略产生的数据进行学习,也可以向智能体过去已经产生的数据进行学习,因此学习效率和样本利用率高。缺点:容易产生误差,学习不稳定。
2.2 马尔科夫决策过程代码实现
在本节中,要实现的是下图的鸳鸯系统。

①为了渲染出图2-5的图像,使用pygame包。
pip install pygame
加载pygame库后,引入pygame库中的函数,同时在程序中用到的包还有包random、数值计算包numpy。
②加载完必要的包后,声明一个鸳鸯类YuanYangEnv来构建鸳鸯环境。包括成员函数:
初始化__init__()、重置环境reset、状态转换为像素坐标state_to_position、像素坐标转换为状态position_to_state、状态转移transform、游戏结束控制gameover、游戏渲染render、雄鸟碰撞检测collide和雄鸟是否找到雌鸟find。
__init__中定义马尔可夫决策过程的几个元素(S,A,P,R,),其中状态空间S由一个元组states来表示,元组中的元素为0,1,2,...,99,表示雄鸟的100个状态。动作空间A由元组actions组成,折扣因子为gamma,可设为0.8。由值函数的定义,每个状态处都有一个对应的值函数,因此值函数v可以用一个10x10的表格value来表示,由于开始并不知道值函数的大小,因此初始值都为0.马尔可夫决策过程中的状态转移概率P由子函数transforn来描述。
类YuanYangEnv初始化函数下面的代码主要设置渲染属性。用viewer来表示一个渲染窗口,screen_size表示窗口大小,bird_position表示雄鸟当前的位置坐标,雄鸟在x方向每动作一次行走的像素距离为120,在y方向每动作一次行走的像素为90;每个障碍物的大小为120*90。在该环境中,一共有两堵障碍物墙,分别用obstacle1和obstacle2来表示,每堵障碍物墙由8个小的障碍物构成。雄鸟的初始位置bird_male_ini_position,和当前位置bird_male_position都为【0,0】,雌鸟的初始位置为bird_female_position=[1080,0].
③碰撞检测函数collide()
用标志flag、flag1、flag2分别表示是否与障碍物、障碍物墙1、障碍物墙2进行碰撞。
先检测雄鸟是否与第1堵障碍物墙发生碰撞,检测的算法为找到雄鸟与第1堵墙所有障碍物x方向和y方向最近的障碍物的坐标差,并判断最近的坐标差是否大于一个最小运动距离,如果>=,那么就不会发生碰撞。再检测第2堵墙,最后检测雄鸟是否超出了边界,如果超出了,也判定为碰撞。最后返回碰撞标志位。
④雄鸟找到雌鸟的判断子函数 find()
设置标志flag,判断雄鸟当前位置和雌鸟位置的坐标差,当该值<最小运动距离时判断为找到。
⑤状态到像素坐标变换的函数state_to_position()
在马尔可夫决策过程中用的是状态描述,因此需要转换。
⑥像素坐标到状态转换的函数position_to_state()
⑦环境重置函数reset()
随机产生一个合法的初始位置,该位置不能再障碍物处,也不能在此雌鸟的位置,因此用一个while循环来产生一个符合条件的初始位置。
⑧状态转移概率模型P和回报函数 transform
在transform()函数中,首先判断当前坐标是否与障碍物碰撞或者是否是终点,如果是,那么结束本次转换。如果当前没有与障碍物碰撞或者没有在雌鸟的位置,那么根据运动学进行像素位置坐标的转换。最后判断下一个状态是否与障碍物发生碰撞,以及是否找到雌鸟。
回报函数的设置为如果没找到雌鸟,立即回报为0;如果与障碍物碰撞,回报为-1;如果找到雌鸟立即回报为1。
⑨游戏结束函数gameover()和环境渲染函数render()
为了将游戏很直观地呈现出来,我们调用pygame包进行游戏的控制。
里面的图像下载如何用load.py来进行下载
⑩主函数
声明一个鸳鸯环境的实例yy,然后调用渲染函数将系统绘制出来,最后调用循环语句检查是否要结束游戏渲染。
如下图
生成的太大,电脑上没有完整显示。需要后面调整一下。

有了仿真训练环境,后面章节将会介绍如何通过强化学习使得雄鸟找到雌鸟。
代码如下:
mdp.py
# 导入必要的包
import pygame
from load import *
import random
import numpy as np
# 鸳鸯环境类
class YuanYangEnv:
def __init__(self):
# 初始化
self.states=[]
for i in range(0,100):
self.states.append(i)
self.actions=['e','s','w','n']
self.gamma=0.8
self.value=np.zeros((10,10))
#设置渲染属性
self.viewer=None
self.FPSCLOCK=pygame.time.Clock()
#屏幕大小
self.screen_size=(1200,900)
self.bird_position=(0,0)
self.limit_distance_x=120
self.limit_distance_y=90
self.obstacle_size=[120,90]
self.obstacle1_x=[]
self.obstacle1_y=[]
self.obstacle2_x=[]
self.obstacle2_y=[]
for i in range(8):
#第一个障碍物
self.obstacle1_x.append(360)
if i<=3:
self.obstacle1_y.append(90*i)
else:
self.obstacle1_y.append(90*(i+2))
#第二个障碍物
self.obstacle2_x.append(720)
if i<=4:
self.obstacle2_y.append(90*i)
else:
self.obstacle2_y.append(90*(i+2))
self.bird_male_init_position=[0.0,0.0] #雄鸟初始位置
self.bird_male_position=[0,0] #雄鸟当前位置
self.bird_female_init_position=[1080,0] #雌鸟初始位置
#碰撞检测函数
def collide(self,state_position):
flag=1
flag1=1
flag2=2
#判断第1个障碍物
dx=[]
dy=[]
for i in range(8):
dx1=abs(self.obstacle1_x[i]-state_position[0])
dx.append()
dy1=abs(self.obstacle1_y[i]-state_position[1])
dy.append()
mindx=min(dx)
mindy=min(dy)
if mindx>=self.limit_distance_x or mindy>=self.limit_distance_y:
flag1=0
#判断第2个障碍物
second_dx=[]
second_dy=[]
for i in range(8):
dx2=abs(self.obstacle2_x[i]-state_position[0])
second_dx.append(dx2)
dy2=abs(self.obstacle2_y[i]-state_position[1])
second_dy.append(dy2)
mindx=min(second_dx)
mindy=min(second_dy)
if mindx>=self.limit_distance_x or mindy>=self.limit_distance_y:
flag2=0
if flag1==0 and flag2==0:
flag=0
#判断是否边界碰撞
if state_position[0]>1080 or state_position[0]<0 or state_position[1]>810 or state_position[1]<0:
flag=1
return flag
#雄鸟找到雌鸟的判断
def find(self,state_position):
flag=0
if abs(state_position[0]-self.bird_female_init_position[0])<self.limit_distance_x and abs(state_position[1]-self.bird_female_init_position[1])<self.limit_distance_y:
flag=1
return flag
#状态转换为坐标
def state_to_position(self,state):
i=int(state/10)
j=state%10
position=[0,0]
position[0]=120*j
position[1]=90*j
return position
#坐标转换为状态
def position_to_state(self,position):
i=position[0]/120
j=position[1]/90
return int(i+10*j)
#环境重置函数
def reset(self):
#随机产生初始状态
flag1=1
flag2=1
while flag1 or flag2==1:
state=self.states[int(random.random()*len(self.states))]
state_position=self.state_to_position(state)
flag1=self.collide(state_position)
flag2=self.find(state_position)
return state
#状态转移概率模型P
def transform(self,state,action):
#将当前状态转换为坐标
current_position=self.state_to_position(state)
next_position=[0,0]
flag_collide=0
flag_find=0
flag_collide=self.collide(current_position) #判断当前坐标是否与障碍物碰撞
flag_find=self.find(current_position)
if flag_collide==1 or flag_find==1:
return state,0,True
#状态转移
if action=='e':
next_position[0]=current_position[0]+120
next_position[1]=current_position[1]
if action=='s':
next_position[0]=current_position[0]
next_position[1]=current_position[1]+90
if action=='w':
next_position[0]=current_position[0]-120
next_position[1]=current_position[1]
if action=='n':
next_position[0]=current_position[0]
next_position[1]=current_position[1]-90
#判断next_state是否与状态碰撞
flag_collide=self.collide(next_position)
#如果碰撞,回报为-1,并结束
if flag_collide==1:
return self.position_to_state(next_position),-1,True
#判断是否是终点
flag_find=self.find(next_position)
if flag_find==1:
return self.position_to_state(next_position),1,True
return self.position_to_state(next_position),0,False
#游戏结束控制
def gameover(self):
for event in pygame.event.get():
if event.type==quit:
exit()
#渲染游戏
def render(self):
if self.viewer is None:
pygame.init()
#画一个窗口
self.viewer=pygame.display.set_mode(self.screen_size,0,32)
pygame.display.set_caption('yuanyang')
#下载图片
self.bird_male=load_bird_male()
self.bird_female=load_bird_female()
self.background= load_background()
self.obstacle=load_obstacle()
self.viewer.blit(self.bird_male,self.bird_male_init_position)
self.viewer.blit(self.bird_female,self.bird_female_init_position)
self.viewer.blit(self.background,(0,0))
self.font=pygame.font.SysFont('times',15)
self.viewer.blit(self.background,(0,0))
#画直线
for i in range(11):
pygame.draw.lines(self.viewer,(255,255,255),True,((120*i,0),(120*i,900)),1)
pygame.draw.lines(self.viewer,(255,255,255),True,((0,90*i),(1200,90*i)),1)
self.viewer.blit(self.bird_female,self.bird_female_init_position)
#画障碍物
for i in range(8):
self.viewer.blit(self.obstacle,(self.obstacle1_x[i],self.obstacle1_y[i]))
self.viewer.blit(self.obstacle,(self.obstacle2_x[i],self.obstacle2_y[i]))
#画小鸟
self.viewer.blit(self.bird_male,self.bird_male_position)
#画值函数
for i in range(10):
for j in range(10):
surface=self.font.render(str(round(float(self.value[i,j]),3)),True,(0,0,0))
self.viewer.blit(surface,(120*i+5,90*j+70))
pygame.display.update()
self.gameover()
self.FPSCLOCK.tick(30)
#主函数进行测试
if __name__=='__main__':
yy=YuanYangEnv()
yy.render()
while True:
for event in pygame.event.get():
if event.type==quit:
exit()
里面用的图片需要下载,存在resources文件夹中。

load.py
import pygame
import os
from pygame.locals import *
from sys import exit
#得到当前工程目录
current_dir = os.path.split(os.path.realpath(__file__))[0]
print(current_dir)
#得到文件名
bird_file = current_dir+"/resources/bird.png"
obstacle_file = current_dir+"/resources/obstacle.png"
background_file = current_dir+"/resources/background.png"
#创建小鸟,
def load_bird_male():
bird = pygame.image.load(bird_file).convert_alpha()
return bird
def load_bird_female():
bird = pygame.image.load(bird_file).convert_alpha()
return bird
#得到背景
def load_background():
background = pygame.image.load(background_file).convert()
return background
#得到障碍物
def load_obstacle():
obstacle = pygame.image.load(obstacle_file).convert()
return obstacle