传统的DSSM双塔无法在早期进行user和item侧的特征交互,这在一定程度上降低了模型性能。我们想要对双塔模型进行细粒度的特征交互,同时又不失双塔模型离线建向量索引的解耦性。下面介绍两篇这方面的工作。
美团-Dual Augmented Two-tower
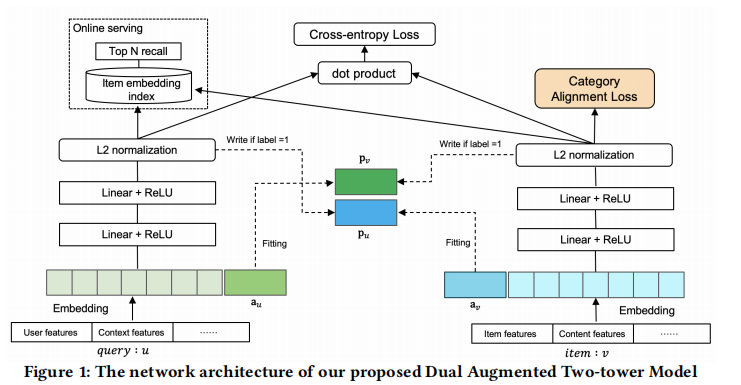
- 在user和item的特征侧分别引入可学习的特征向量
- 当label=1的时候,user的 a u a_u au去学习item正样本的输出表征,从而实现隐式特征交互;item侧亦如此
损失函数如下:
loss
u
=
1
T
∑
(
u
,
v
,
y
)
∈
T
[
y
a
u
+
(
1
−
y
)
p
v
−
p
v
]
2
loss
v
=
1
T
∑
(
u
,
v
,
y
)
∈
T
[
y
a
v
+
(
1
−
y
)
p
u
−
p
u
]
2
y
∈
{
0
,
1
}
\begin{aligned} \operatorname{loss}_u & =\frac{1}{T} \sum_{(u, v, y) \in \mathcal{T}}\left[y \mathbf{a}_u+(1-y) \mathbf{p}_v-\mathbf{p}_v\right]^2 \\ \operatorname{loss}_v & =\frac{1}{T} \sum_{(u, v, y) \in \mathcal{T}}\left[y \mathrm{a}_v+(1-y) \mathrm{p}_u-\mathbf{p}_u\right]^2 \\ y &\in \{0,1\} \end{aligned}
lossulossvy=T1(u,v,y)∈T∑[yau+(1−y)pv−pv]2=T1(u,v,y)∈T∑[yav+(1−y)pu−pu]2∈{0,1}
- p u p_u pu 和 p v p_v pv 梯度冻结,不进行更新
缺点
这种方式引入的交叉特征实际是非常"粗粒度"和"高阶"的,即携带的信息仅仅是对方tower最后输出的表征,对方tower在编码这段表征时,也仅仅只利用了fake的emb和tower本身的输入特征的交互。
百度-I3 Retriever

- 在doc侧设计一个轻量的query生成模块,利用doc侧特征作为输入,去fake一个query侧表征,去重构出query侧的输入特征。当然需要注意的是,也仅仅是在正样本上执行重构loss
- doc侧与生成的query进行特征交互
- 交互完的doc侧与query侧对比学习
重构损失函数如下:
L
r
=
−
∑
w
i
∈
q
y
w
i
log
(
W
R
K
(
p
)
q
)
\mathcal{L}_r=-\sum_{w_i \in \mathbf{q}} \mathbf{y}_{w_i} \log \left(\mathbf{W}^{R_{\mathbb{K}}}(\mathbf{p})_q\right)
Lr=−wi∈q∑ywilog(WRK(p)q)
对比损失函数如下:
L
c
=
−
log
exp
(
S
(
q
,
p
+
)
)
exp
(
S
(
q
,
p
+
)
)
+
∑
p
−
∈
N
−
exp
(
S
(
q
,
p
−
)
)
,
\mathcal{L}_c=-\log \frac{\exp \left(S\left(\mathbf{q}, \mathbf{p}_{+}\right)\right)}{\exp \left(S\left(\mathbf{q}, \mathbf{p}_{+}\right)\right)+\sum_{\mathbf{p}-\in \mathcal{N}_{-}} \exp \left(S\left(\mathbf{q}, \mathbf{p}_{-}\right)\right)},
Lc=−logexp(S(q,p+))+∑p−∈N−exp(S(q,p−))exp(S(q,p+)),
参考
- CIKM2023 | 突破双塔: 生成式交互的向量化召回