背景
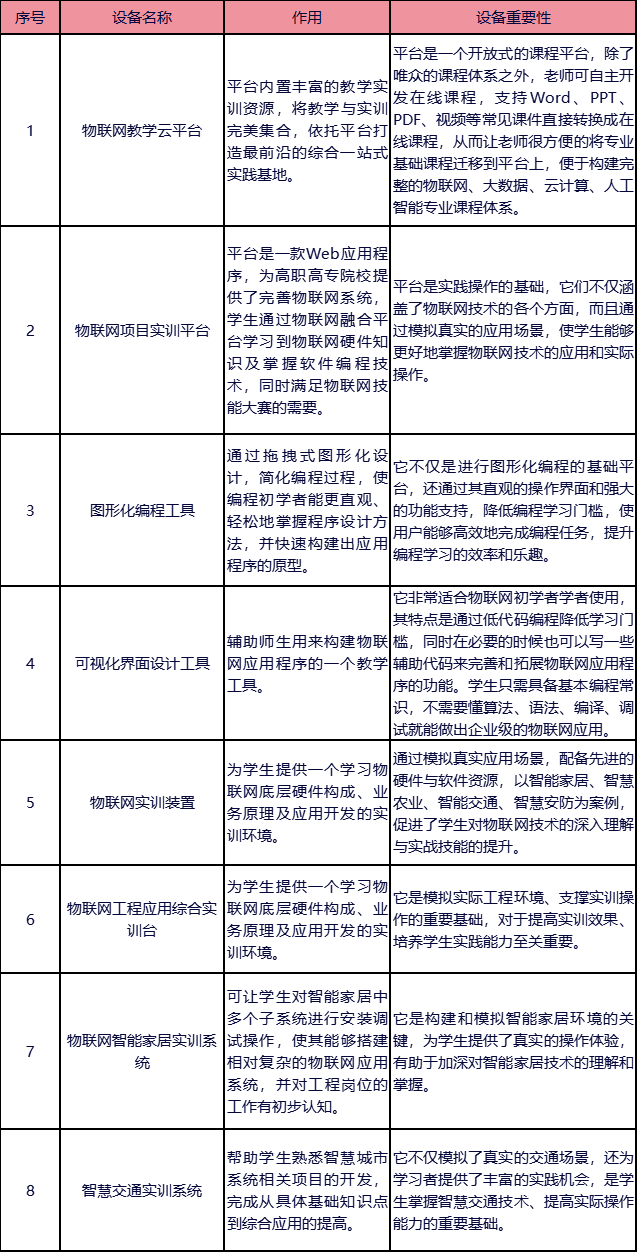
今天开始写下Milvus,为了方便,我直接使用的是 milvus-lite 版本,default 情况下,你可能不知道他到底将 db 存储到什么位置了。启动 default-server,看下Milvus 的start及存储逻辑
主逻辑
def start(self):
self.config.resolve()
_initialize_data_files(self.config.base_data_dir)
-> 看下 resolve 的逻辑:
def resolve(self):
self.cleanup_listen_ports()
self.resolve_all_listen_ports()
self.resolve_storage()
for key, value in self.configurable_items.items():
if value[1] is None:
raise RuntimeError(f'{key} is still not resolved, please try specify one.')
# ready to start
self.cleanup_listen_ports()
self.write_config()
self.verbose_configurable_items()
-> 重点是 resolve_storage,继续看:
def resolve_storage(self):
self.base_data_dir = self.configs.get('data_dir', self.get_default_data_dir())
self.base_data_dir = abspath(self.base_data_dir)
makedirs(self.base_data_dir, exist_ok=True)
config_dir = join(self.base_data_dir, 'configs')
logs_dir = join(self.base_data_dir, 'logs')
storage_dir = join(self.base_data_dir, 'data')
for subdir in (config_dir, logs_dir, storage_dir):
makedirs(subdir, exist_ok=True)
-> 先看下 base dir:,get_default_data_dir:
def get_default_data_dir(cls):
if sys.platform.lower() == 'win32':
default_dir = expandvars('%APPDATA%')
return join(default_dir, 'milvus.io', 'milvus-server', __version__)
default_dir = expandvars('${HOME}')
return join(default_dir, '.milvus.io', 'milvus-server', __version__)
看到这里,你应该明白,网上有人说使用Milvus 必须要下载 docker,那不太对,别人是支持 win32的。而且这个源码还是使用的 2.26 的版本,最新的2.4 更应该支持。

非常清晰。继续看,日志和配置,晚点在说,先看 data,因为你最关心的,也应该是 data 部分:
看下 data 的 结构:

# data
self.set('etcd_data_dir', join(storage_dir, 'etcd.data'))
self.set('local_storage_dir', storage_dir)
self.set('rocketmq_data_dir', join(storage_dir, 'rocketmq'))

关于这里的配置文件最终会写在:

中,当然除了上面的咨询,你也可以看到下面索引的核心default 配置:

HNSW 在前面的文章已经讲述过了,默认采用的是 HNSW 可导航分成小世界算法,采用IP丈量距离的方式,M和efCons 是 HNSW 的两个参数,分别代表本层和向下寻找的节点数。
config = MilvusServerConfig() config.base_data_dir = 'milvus_austin_base_data_dir' server = MilvusServer(config, debug=True) server.start()
你发现这样设置了无效,原因应该通过上面的代码很清楚了,
self.base_data_dir = self.configs.get('data_dir', self.get_default_data_dir())
已经限制了他的输出路径。
如何修改
要怎么才能使得放在自己的目录下呢?其实有个函数,你在调用下:
server.set_base_dir(config.base_data_dir)

ok了
你可能会比较疑惑,代码是


为什么设置了 没有被覆盖?
原因很简单:

原因很清楚了
当然你也可以直接调用 Milvus 封装好的 milvus-server --debug 启动,后面也可以接 --data 参数。但我更喜欢自己看内部的实现。
start逻辑
其实 milvus lite 的 start 就三个作用:
1)加载全局配置,将 data 相关的copy 到指定位置,没有的话,就创建folder 和文件
2)用进程方式加载 milvus.exe
cmds = [milvus_exe, 'run', 'standalone']
proc_fds = self.proc_fds
if self._debug:
self.server_proc = subprocess.Popen(cmds, env=envs)
else:
# pylint: disable=consider-using-with
self.server_proc = subprocess.Popen(cmds, stdout=proc_fds['stdout'], stderr=proc_fds['stderr'], env=envs)
3)等待 client 指令

实际上, milvus lite,只是一个外壳,启动了 milvus exe 执行
与传统数据库对比
Milvus Collection 就是 传统db 的 table
entity 就是 传统 db 的row
field 就是传统db 的 column
这个前面讲的chroma 很接近。因为在vector db 的世界中都大同小异。
milvus架构

1)接入层(Access Layer):系统的门面,由一组无状态 proxy 组成。负责客户端请求并返回结果。
2)协调服务(Coordinator Service):Coordinator,顾名思义,协调者,负责分配任务给执行节点。协调功能有四种,分别为 root coord、data coord、query coord 和 index coord。
3)执行节点(Worker Node):负责执行协调者所下发的任务,实际干活儿的人。执行节点分为三种角色,分别为 data node、query node 和 index node。
4)存储服务 (Storage): 负责 Milvus 数据的存储,也就是持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
实际上我们看到 Milvus 这种架构做的非常优秀,适合数据与服务的横向扩展
接入层和协调服务

root coordinator
主要处理DDL 与 DCL 请求,包括 create 与 delete collections, partitions, or indexes 等。还有一些与时间同步等请求。
query coodinator
查询coodinator 有点不太好理解,要多描述下。它主要负责管理查询节点(Query node)的拓扑结构和负载均衡,以及处理从增长段(Growing segments)到密封段(Sealed segments)的转换操作。有点生硬,展开描述一下:
1.管理查询节点的拓扑结构
- 拓扑结构管理:Query coord负责维护系统中所有查询节点的布局和连接关系。这确保了当查询请求到来时,系统能够高效地将请求分发到合适的查询节点上进行处理。
- 节点状态监控:Query coord还负责监控查询节点的状态,包括节点的健康状况、负载情况等,以便在必要时进行节点间的负载均衡调整。
2. 负载均衡
- 请求分发:Query coord接收来自客户端的查询请求,并根据当前查询节点的负载情况和拓扑结构,智能地将请求分发到合适的节点上进行处理。这有助于提高系统的整体性能和响应时间。
- 动态调整:随着查询请求的变化和查询节点负载的波动,Query coord会动态地调整查询节点的负载,以确保系统的负载均衡性和稳定性。
3. 从增长段到密封段的转换
这算是milvus 的一大特色。其他地方很少听到这种存储理念。
- 段的状态管理:在Milvus中,数据被组织成段(segments),这些段可以是增长段(Growing segments)或密封段(Sealed segments)。增长段用于存储新的写入数据,而密封段则用于存储已经稳定的数据。
- 转换操作:当增长段的数据量达到一定程度时(默认为512MB),Query coord会触发从增长段到密封段的转换操作。这个过程中,Query coord会协调查询节点和数据节点,将增长段中的数据迁移到密封段,并进行必要的索引构建和优化操作。
data coordinator
顾名思义,就是存data的。包括了索引,数据,及元数据。负责管理数据节点(Data node)和索引节点(Index node)的拓扑结构、维护元数据,并触发如flush、compact、索引构建等后台数据操作。以下是这些职责的详细阐述:
1. 管理数据节点和索引节点的拓扑结构
Data coord负责维护系统中数据节点和索引节点的整体布局和相互连接关系。这种拓扑结构的设计旨在确保数据的均匀分布和高效访问。随着系统的扩展或节点的增减,Data coord会相应地调整拓扑结构,以保持系统的平衡和高效。
2. 维护元数据
元数据是描述数据的数据,对于Milvus系统来说,包括但不限于集合(collection)、分区(partition)、段(segment)的定义、属性以及它们之间的关系。Data coord负责存储和更新这些元数据,确保它们在系统中的一致性和准确性。这对于数据查询、数据迁移、数据恢复等操作至关重要。
3. 触发后台数据操作
Data coord负责监控系统的状态,并在适当时机触发一系列后台数据操作,以优化数据存储和查询性能。这些操作包括:
- Flush操作:当内存中的数据量达到阈值时,Data coord会触发flush操作,将内存中的数据写入磁盘上的段中。这有助于减少内存使用,并确保数据的持久化。
- Compact操作:为了优化存储效率和查询性能,Data coord会定期或按需触发compact操作。这个过程中,多个小段(segment)会被合并成一个大段,并删除其中的重复或无效数据。
- 索引构建:根据用户配置的索引策略和参数,Data coord会触发索引构建操作。索引的创建可以显著加快查询速度,因为系统可以直接在索引上执行搜索,而无需遍历整个数据集。
- 其他后台操作:除了上述操作外,Data coord还可能触发其他必要的后台数据操作,如数据修复、数据迁移、数据清理等,以确保系统的稳定性和数据的可靠性。
从整体上说,query coord 就是为了负载均衡及query 等效率。所以从这里看出 milvus 对query 效能是有比较好的设计。当然类似 partition 的设计 chroma 也有。只是segment 在 milvus 中还进行了区分。
Index coordinator
index coord主要负责管理索引节点(Index node)的拓扑结构、构建索引、维护索引元信息,并协调索引相关的操作。以下是Index coord主要职责的详细阐述:
1. 管理索引节点的拓扑结构
- Index coord负责维护系统中索引节点的布局和连接关系,确保索引数据能够均匀分布在各个索引节点上,以实现高效的索引构建和查询。
- 随着系统的扩展或索引节点的增减,Index coord会相应地调整拓扑结构,以保持系统的平衡和高效。
2. 构建和维护索引
- 当有新的向量数据需要被索引时,Index coord会协调索引节点进行索引构建工作。这包括选择合适的索引算法、分配索引任务给索引节点,并监控索引构建的进度和结果。
- Index coord还负责维护索引的元信息,如索引的类型、参数、状态等,以便在查询时能够快速地定位到相应的索引数据。
3. 协调索引相关的操作
- Index coord会与其他协调器(如Data coord、Query coord)和执行节点(如Data node、Query node)进行交互,以协调索引相关的操作。例如,在数据迁移或数据修复过程中,Index coord会确保索引数据的一致性和完整性。
- 当索引节点发生故障或性能瓶颈时,Index coord会参与故障恢复或负载均衡的决策过程,以确保系统的稳定性和性能。
4. 支持索引的更新和删除
- 随着数据的不断变化,索引也需要进行相应的更新或删除操作。Index coord会处理这些请求,并确保索引的更新或删除操作能够正确地执行,同时保持索引数据的一致性和准确性。
5. 监控和优化索引性能
- Index coord会监控索引的性能指标,如索引构建速度、查询响应时间等,并根据监控结果进行相应的优化操作。例如,通过调整索引算法、参数或增加索引节点来提高索引的性能。

milvus 的底层采用的是对象存储,负责存储日志的快照文件、标量/向量索引文件以及查询的中间处理结果。采用 MinIO 作为对象存储。
当系统启动后,我们看到各自服务的端口是不一样的:
[INFO] [indexcoord/service.go:328] [IndexCoord] ["network address"=192.168.3.164] ["network port"=40003]
[INFO] [querynode/service.go:111] [QueryNode] [port=40002]
["Proxy internal server listen on tcp"] [port=19529]
["Proxy server listen on tcp"] [port=19530]
外面使用 19530 访问,内部 milvus 通过 19529 进行分发到内部处理
存储结构
其实在最底层,milvus 的存储是 etcd + MinIO 的形式

我们可以打开etcd文件夹,能窥探到一点内容,当然,网上有专门的软件打开,我这里直接打开看一看,也能看到一点痕迹:

其实这里每一个概念都可以是一个topic,先简单介绍下吧,后面再细说。什么是 wal?write-ahead logging,预写日志系统。这里就体现出milvus的设计理念。尽快可靠的返回,不要阻塞用户操作,真正需要系统落地的事情,根据wal 的记录交给milvus后面以async的方式来完成吧。
当用户向系统中插入数据时, milvus会先把数据攒在内存里,然后当内存数据达到一定规模(默认128M)或者定时器超时(默认1s)后,内存数据再排队刷入磁盘。当数据真正落盘后它们就能被访问了。这个设计借鉴了操作系统对流数据的处理方式,在写磁盘频率和数据可靠性之间做了一定的平衡。然而随着我们接触到越来越多的用户场景,以上设计渐渐不能满足需求了。首先,用户命令的原子性没得到保证,比如在系统意外退出时,用户某一次插入的数据可能部分落盘、部分丢失;其次,用户无法明确知道数据何时可见,即使在客户端等待1s也未必能保证之前插入数据全部可见;最后,当初设计时没有考虑数据删除,同步执行删除有可能要长时间阻塞用户线程。为解决上述问题,wal文件机制应运而生,没记错的话,应该是 milvus早期0.7 就引入wal文件。
先直观感受下wal文件:

还是能感受点东西,可以自己体会下,好东西有时候只能意会不能言传。
其核心思想是把用户所有的修改操作(插入、删除)先写入日志中,然后再应用到系统状态里。一旦成功写完日志,即可通知用户操作成功。由于日志是以尾部追加方式写入,耗时较短,所以不会长时间阻塞用户线程。此外为防止意外退出导致数据丢失,系统重启时还会根据日志重做用户操作,以保证数据可靠性。这个消息队列的某些机制很像。时间有限,今天先写到这里。后面再慢慢梳理