介绍:
文件系统是操作系统中负责管理和存储文件信息的软件结构,它组织和管理磁盘上的文件和目录,并定义了文件的存储结构。
Linux文件系统采用树状结构,只有一个根目录(用“/”表示),其中含有下级子目录或文件的信息。子目录中又可以包含更多的子目录或文件,这样一层一层地延伸下去,构成一棵倒置的树。
磁盘
进程打开文件,没有打开的文件在磁盘上保存,并通过文件系统进行管理。在笔记本电脑(或任何计算机)中,C盘和D盘(以及其他可能的盘符,如E盘、F盘等)并不是物理硬件本身,而是硬盘或固态硬盘(SSD)上的逻辑分区或卷。这些分区或卷在操作系统中被识别为不同的驱动器或“盘”,并分配了不同的字母标识符(如C:、D:等)。
在磁盘中,文件属性对应的数据存储在结构体inode中。它包括文件类型、大小、权限、时间等等,但inode没有包含文件名,因为文件名不属于文件属性。Linux中使用ll -i 指令可查看文件或目录的inode。这里要说明的是系统管理文件的属性大小是固定的(内容与属性分开存储),因为属性的类别是一样的,只不过每个类别的内容不一样,即inode大小通常固定,大小通常是128字节,有些的文件系统中可以设置为256字节。
inode结构
inode管理
inode结构体准确来说记录了文件的元数据信息,是唯一标识文件系统中的每一个文件的。元数据包括文件属性,其中,一个inode可以有多个文件名,但一个文件名只能对应一个inode。
那么inode具体是如何怎么管理文件的呢?在同一文件系统中,每个inode结构中都存储着一个唯一的编号,即inode编号。操作系统使用inode编号来识别不同的文件,而不是文件名来识别文件。系统都是通过inode来对文件进行操作的。我们通常使用ls -i命令可以查看文件的inode号。
通常,每个文件或目录都有一个唯一的inode与之关联(一个inode对应一个文件名的情况),但是有些特殊情况下(一个inode对应多个文件名的情况下),多个文件名(文件名也叫硬链接)可能对应同一个inode。这种情况下,所有的这些文件名都会引用同一个inode,并且具有相同的inode编号。这意味着这些文件实际上是同一个文件的不同名称,它们共享相同的文件内容和元数据。需要注意的是,虽然多个文件名可以指向同一个inode,但一个inode通常只能与一个文件内容相关联。也就是说,你不能有两个不同的文件内容共享同一个inode。如果你尝试这样做,系统通常会创建一个新的inode来存储新的文件内容。
inode在文件系统中存储在磁盘文件系统的分区里的inode表中,即inode Table。
inode链接和inode表
inode中包含一个链接数(link count),表示有多少个文件名(即硬链接)指向这个inode。当创建一个新的硬链接时,链接数会增加一个;当删除一个硬链接(无论是通过rm命令还是删除目录项)时,链接数会减少一个。当链接数减少到0时,inode会被标记为可回收,对应磁盘空间上的文件内容会被删除。
这里我们说明一下文件名。Linux系统中,inode本身并不直接存储文件名,而是存储了文件的元数据信息。文件名实际上是与inode关联的目录项中的一部分,具体来说文件名与相应的inode编号关联,它们保存在文件系统的目录结构中。文件名只是一个标识符,真正的文件内容和属性是通过inode来访问的。至于文件内容,inode是通过内部数据块指针来指向的,inode中的数据块指针指向文件内容在磁盘上的存储位置。这些指针是文件系统定位文件内容的关键,不同的文件会有不同的数据块指针分布。
文件=“文件属性” + “文件内容”。文件的一系列信息基本都是通过inode间接引出的。总的来说,当系统对文件进行操作时,首先会找到对应inode编号,找到inode编号后就能在inode表(inode Table)中找到inode,找到inode后,就能拿到inode里面对应的文件数据块。
磁盘文件系统
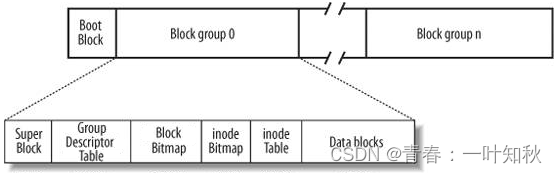
上图中是磁盘文件系统的分区(如同windows下的C盘、D盘等)。磁盘是典型的块设备,硬盘分区(如上图)被划分为一个个大小固定的block。一个block的大小是由格式化的时候确定的,不可以更改。其中上图的 Boot Block 是启动块。上图的Block group 0......Block group n是一个分区中对应的很多分组。每个分组中又划分了许多个块(Block),下面我们依次来分析这些块。
inode Table:inode表。从逻辑和概念上讲,可以将inode表(inode Table)视为一个数组,其中每个inode的编号可以看作是这个数组的一个下标。通过inode编号,可找到文件在磁盘上的存储位置。具体有多少个inode是系统根据分区早早分配好的。
inode Bitmap:inode位图。我们不能确定inode Table(inode表)中的inode是否被占用,系统是通过inode Bitmap(inode位图)使用每个bit来表示一个inode是否空闲可用。比特位的位置表示第几个inode,比特位的内容表示该inode是否被使用(0表示未占用,1表示已被占用)。
Data blocks:数据块。存放文件内容。Data blocks是由无数的块(block)组成,每个块大小一般固定约4KB,存放文件内容时从左到右依次使用块存储,且每个块都有自己的编号。这些块的数量也是系统根据分区就已分配好的。
Block Bitmap(Block位图):块位图。记录着Data Blocks中哪个数据块已经被占用,哪个数据块没有被占用。Block Bitmap原理与inode Bitmap一样,都是通过相应编号(即:数组下标)标识是否被用过。
下面问题来了,系统如何知道哪一个inode和哪一个Date blocks(即文件内容)是对应关系呢?inode内部里面包含了block整型数组,此数组记录了对应文件数据块的编号。即通过inode中的block数组即可找到对应的文件内容。
例如:当我们新建一个文件并写入文件内容时,在上面四种块结构中,系统首先会在inode Bitmap查找没有使用的位图,这里会通过计数从左到右开始遍历,直到找到未占用的inode(即数组下标为0),然后会在inode Table中进行索引(如在inode位图中找到的是10,直接在inode表中找到第十个inode),接下来会使用inode属性结构体把文件对应的字段填入进入,之后会把这个inode结构体按照二进制形式拷贝到inode Table中对应的inode块中(如拷贝到inode表中第十个inode里),这里属性就有了,至于文件内容的填充取决于内容的大小,若文件内容大小估计使用1个块,即内容小于4KB,这里会分配一个块进行填充,分配的块号会被写入block整型数组中,对应的Block Bitmap也会被修改成1。当清除文件时,这里先找到inode,将对应的inode Bitmap和Block Bitmap位图号从1变成0即可。也就是说删除文件时不会删除inode的内容以及block的内容,只需把对应的两个位图清掉即可。
现在我们都明白,查找一个文件就是通过inode编号来查找,那么具体是如何快速通过inode编号找到对应的文件呢?我们要先明白inode是在一个分区中唯一的,不是在一个分组中唯一的。倘若在第一个分组中分配10000个inode,即起始值是1,那么第二个分组中分配的inode就会从10001开始,即起始值是10001,后面同理。当系统给文件分配inode编号时,若在一个分区中的第n个分组中对应inode Bitmap找到第m个bit为0,即找到了inode Table中的第m个inode,那么在往第m个inode填充属性时,填充inode字段里的inode编号其实是 “inode Table中的起始偏移量” + m。拿到对应的inode编号查找具体的inode时,首先会在每个分组中分配的inode范围中找到具体对应的分组,然后再用inode编号减去对应分组下的起始inode偏移量就能找到对应的inode Bitmap中的位号和inode Table中具体的inode号,当查到对应inode Bitmap中的位号属于存在位号时,就会在对应的inode Table中找到具体的inode获取属性信息。文件内容同理,只不过在inode对应的block整型数组字段中,眏射的块并不是全部对应的文件内容,而是采用直接索引、间接索引和三级索引或更多的索引通过块来引出,块中存放着指向对应块的指针,指向对应块,但大多数情况下(文件内容较小的情况)block是直接眏射文件内容的。
Group Descriptor Table(GDT):块组描述符,描述块组属性信息。它也是一个结构体,包含了该分组的具体信息,如inode的数量、空闲inode的数量、数据块的数量、空闲数据块的数量等。因此,每个分组中的GDT大概率都是不一样的,GDT被损坏会导致这个分组被破坏。
Super Block(超级快):超级块包含了关于文件系统的全局信息,存放文件系统本身的结构信息,包括每个分组的描述块的位置和大小。通过读取超级块,系统可以定位到每个分组的描述块。记录的信息主要有:bolck 和 inode的总量, 未使用的block 和 inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了,因此,虽然整个文件系统的关键信息只需要一个Super Block就足够了,但是系统还会在个别的分组中加入Super Block,而不是全部分组中加入,这样既保证了某个Block Group的Super Block数据损坏,文件系统仍然可以通过其他Block Group中的Super Block备份信息来恢复,也能保证跟新Super Block时的效率问题。总的来说,系统只要拿到了Super Block就可对此分区进行管理。
Boot Block块比较特殊,它并不是所有分区都拥有的,主要功能是协助系统了解磁盘的分区情况,这里了解即可。
上面的分区情况就是文件系统下的情况,即一个分区对应一个文件系统。平常电脑上磁盘的格式化本质是向指定的分区中写入全新的文件系统(上面介绍的文件系统属于ext2版本,其它版本的文件系统可能有所不同,但原理都是一样的,只不过增添了一些日志内容)。那么系统如何管理多个文件系统?一个分区一个文件系统,每个分区中的核心是Super Block,里面包含了该分区下的所有属性。系统只需拿到每个分区下的Super Block,然后将它们用链表的形式连接起来即可。总的来说,系统对分区的管理就是对Super Block的管理;系统对多个文件系统的管理就是对链表的管理。
文件名
了解文件名,首先我们要先了解下目录。任何一个普通文件一定在一个目录中,而目录也是文件,也通过inode管理,但目录的内容放什么呢?目录的数据块中存放的是文件名和inode编号的眏射关系。当在目录中查找一个文件名时,系统能够根据文件名来找到对应的inode。当在目录中创建一个新文件时,将对应的inode和数据块填充之后,系统会拿到对应文件的inode编号的眏射关系和文件名再写入到文件目录内容里面。文件权限的限制功能对应的是以上原理。
当我们在一个目录中创建一个文件时,若该目录没有写权限,将不能在该目录下创建文件,因为创建文件时需要将该文件的inode编号的眏射关系和文件名再写入到目录内容里,若没有写权限就无法写入。查找文件时同理,若是无法读取文件名与inode编号的眏射关系进而将无法使用对应的功能。删除一个文件时需要去除目录里面的文件名与inode编号的眏射关系,这也需要修改目录内容,这也就是为什么去掉写权限将无法删除文件。其它权限功能同理。
这里有一个问题,当查找一个文件,我们需要拿到该目录的内容,目录内容在数据块中存储的,要想拿到该目录的内容就要拿到该目录的inode编号,要想拿到该目录的inode编号就要拿到该目录的目录的内容,这样就出现了 “鸡生蛋,蛋生鸡” 的问题,最终会在根目录(“/”)下终止。因此,在系统层面上,当查找一个文件时,在内核中都要逆向的递归般得到根目录,然后系统再从根目录下诼渐往下查找,进行路径解析,直到找到指定文件。查找的过程中系统会把此路径信息缓存下来,方便我们在此路径下对不同目录或文件进行快速切换或操作。
当我们拿到inode后,又该如何在分区中寻找inode呢?这里我们要先明白挂载的概念。一个被写入文件系统的分区,要被Linux使用,必须要先把这个具有文件系统的分区进行 “挂载” 。“挂载” 是把一个文件系统所对应的分区,挂载在对应的目录中,文件系统的数据结构与目录的数据结构之间通过指针关联,访问分区下的文件系统都是要通过目录来访问。在Linux中使用 df -h 命令可查看。比如我们使用云服务器时,上面左侧Filesystem表示文件系统,服务器上的云盘只有一块,即分区只有一个,叫做/dev/vda1,它被挂载到根目录上。因为只有一个分区,所以从根目录下的所有内容都会在这一个分区中,也就是说要访问此分区,只要保证我们在根目录下,就能访问当前对应的分区。倘若我们系统中存在多盘的情况下,即存在 /dev/vda1、/dev/vda2、/dev/vda3...,这时需要时用mount命令将分区挂载到Linux下的一个文件夹中,从而将分区和该目录联系起来,从此往后只需访问这个文件夹就相当于访问该分区了。挂载好之后使用 df -h 指令可查看到此挂载后的目录,当进行路径切换后,就可能从一个分区切换到另一个分区了,本质就是从一个目录切换到另一个目录。总的来说,分区的访问就是通过所挂载的路径访问的,我们也可使用Linux下的命令来创建文件系统,实现挂载,然后cd到指定的目录后,我们就是在访问这个分区。
当查找指定的文件时,系统会根据路径最前缀的目录优先判断出该文件在具体哪个分区下,然后根据路径不断往下解析将会找到所有对应的inode。对于路径若不详细说明,系统会默认在当前路径下。最终将指定的文件inode导入内存中,通过进程打开。















![[Unity入门01] Unity基本操作](https://i-blog.csdnimg.cn/direct/fc99f0c9da1c4aaf9efd229e1eef51b9.png)