Hadoop发行版本较多,Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称CDH)收费版本通常用于生产环境,这里用开源免费的Apache Hadoop原始版本。
下载:Apache Hadoop
版本下载:Index of /hadoop/common
Hadoop基础知识可查看本专栏其它篇章:Apache Hadoop的核心组成及其架构_hadoop的核心架构是怎样-CSDN博客
环境准备
准备三台虚拟机,并安装JDK1.8,时间需要同步。
集群规划
| 应用 | hadoop01 | hadoop02 | hadoop03 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | NodeManager | NodeManager、ResourceManager |
| ntpd | ntpd | ntpd | ntpd |
主机名与域名设置
hostnamectl --static set-hostname hadoop01修改/etc/hosts
192.168.43.101 hadoop01
192.168.43.102 hadoop02
192.168.43.103 hadoop03ssh免密登录
在三台主机执行下面两句命令,一直回车即可,不需要输入密码,确保三台主机都可免密登录,后续使用hadoop集群批量启动脚本时会特别方便。
ssh-keygen
ssh-copy-id root@192.168.43.101
ssh-copy-id root@192.168.43.102
ssh-copy-id root@192.168.43.103Hadoop集群安装
hadoop安装
解压安装包
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/将hadoop添加到环境变量,/etc/profile
export HADOOP_HOME=/opt/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin使环境变量生效
source /etc/profile
验证版本
hadoop version
Hadoop目录介绍
drwxr-xr-x 2 root root 194 Nov 13 2018 bin
drwxr-xr-x 3 root root 20 Nov 13 2018 etc
drwxr-xr-x 2 root root 106 Nov 13 2018 include
drwxr-xr-x 3 root root 20 Nov 13 2018 lib
drwxr-xr-x 2 root root 239 Nov 13 2018 libexec
-rw-r--r-- 1 root root 106210 Nov 13 2018 LICENSE.txt
-rw-r--r-- 1 root root 15917 Nov 13 2018 NOTICE.txt
-rw-r--r-- 1 root root 1366 Nov 13 2018 README.txt
drwxr-xr-x 3 root root 4096 Nov 13 2018 sbin
drwxr-xr-x 4 root root 31 Nov 13 2018 share
1.bin目录:对Hadoop进行操作的相关命令,如hadoop,hdfs等
2.etc目录:Hadoop的配置文件目录,入hdfs-site.xml,core-site.xml等
3.lib目录:Hadoop本地库(解压缩的依赖)
4.sbin目录:存放的是Hadoop集群启动停止相关脚本,命令
5.share目录:Hadoop的一些jar,官方案例jar,文档等集群配置
Hadoop集群配置 = HDFS集群配置 + MapReduce集群配置 + Yarn集群配置
HDFS集群配置
-
配置jdk路径,etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_231
-
指定NameNode节点以及数据存储目录,修改etc/hadoop/core-site.xml,添加如下配置
<configuration> <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.9.2/data/tmp</value> </property> </configuration>core-site.xml默认配置参考:https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
-
指定secondarynamenode节点,修改 hdfs-site.xml
<configuration> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop03:50090</value> </property> <!--副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>官方默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
-
指定datanode从节点(修改slaves文件,每个节点配置信息占一行),修改 slaves 文件,文件不允许出现空格
hadoop01 hadoop02 hadoop03
MapReduce集群配置
-
指定MapReduce使用的jdk路径,修改mapred-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_231 -
指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
cp mapred-site.xml.template mapred-site.xml vim mapred-site.xml
<configuration> <!-- 指定MR运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>mapred-site.xml默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
Yarn集群配置
-
指定jdk路径,vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_231
-
指定ResourceMnager的master节点信息,修改yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop03</value> </property> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>yarn-site.xml的默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
配置完后,将虚拟机拷贝两份,分别用作hadoop02、hadoop03节点。
启动hadoop集群
NameNode格式化与启动
第一次启动,需要在Namenode所在节点格式化NameNode,非第一次不用执行格式化Namenode操作。根据上面的规划,我们只将hadoop01格式化,其它两个节点不执行此操作。
hadoop namenode -format
格式化后创建的文件:/opt/hadoop-2.9.2/data/tmp/dfs/name/current/fsimage_0000000000000000000
启动
[root@hadoop01 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-namenode-hadoop01.out
[root@hadoop01 ~]# jps
1496 Jps
1455 NameNodeDataNode启动
三个节点都启动dataNode
[root@hadoop02 ~]# hadoop-daemon.sh start datanode
starting datanode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-datanode-hadoop02.out
[root@hadoop02 ~]# jps
1570 Jps
1530 DataNodeHDFS Web界面查看
全部启动后,可以通过web浏览HDFS管理界面,地址如下(本地hosts做下映射):
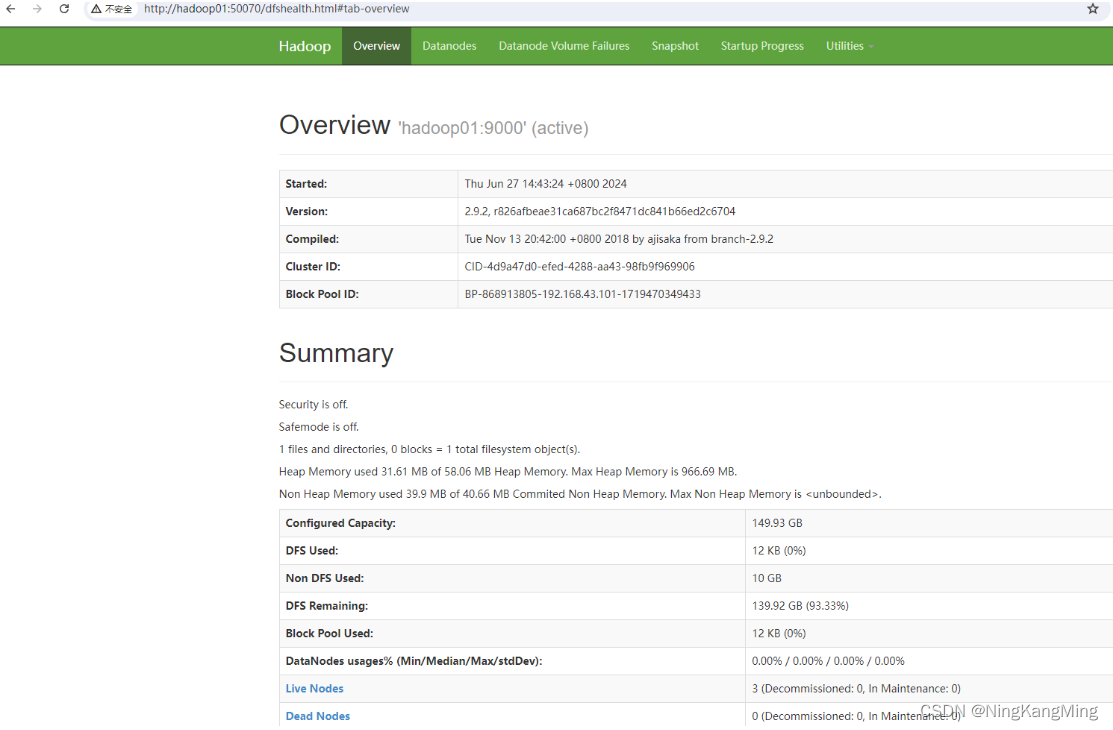
可以通过管理界面查看dataNode存活、存储使用等情况。
Yarn启动
根据规划,yarn ResourceManager资源管理节点在hadoop03,单独启动这个。
yarn-daemon.sh start resourcemanager另外,nodemanager规划到每个节点,三个节点都启动nodemanager即可,
yarn-daemon.sh start nodemanagerHadoop多节点集群启动
先把上面的节点手动停止,然后进入hadoop01的sbin目录,执行如下指令(先做好三个节点无密码ssh登录)
start-dfs.sh
stop-dfs.sh通过上面的start-dfs.sh脚本,执行后三个节点的状态如下
hadoop01
[root@hadoop01 ~]# jps
3444 Jps
3080 NameNode
3193 DataNodehadoop02
[root@hadoop02 ~]# jps
2246 DataNode
2330 Jpshadoop03
[root@hadoop03 ~]# jps
2725 Jps
2663 SecondaryNameNode
2556 DataNode可见,此脚本会根据我们的配置来启动各个节点,省去我们逐个节点启动的麻烦。
Yarn多节点集群启动
跟hadoop集群一样,yarn也可以通过一个脚本来启动整个集群。注意:NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。 在ResouceManager所在的机器上启动YARN
start-yarn.sh
stop-yarn.sh日志输出如下
[root@hadoop03 sbin]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.9.2/logs/yarn-root-resourcemanager-hadoop03.out
hadoop01: starting nodemanager, logging to /opt/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop01.out
hadoop02: starting nodemanager, logging to /opt/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop02.out
hadoop03: starting nodemanager, logging to /opt/hadoop-2.9.2/logs/yarn-root-nodemanager-hadoop03.out通过日志可以看出,hadoop03启动了resourcemanager,三个节点都启动了nodemanager。
至此,基于apache hadoop的完全分布式hadoop集群搭建完毕。
上传下载测试
从linux本地文件系统上传下载文件验证HDFS集群工作是否正常
#创建目录
hdfs dfs -mkdir -p /test/input
#本地hoome目录创建一个文件,随便写点内容进去
cd /root
vim test.txt
#上传linxu文件到Hdfs
hdfs dfs -put /root/test.txt /test/input
#从Hdfs下载文件到linux本地(可以换别的节点进行测试)
hdfs dfs -get /test/input/test.txt分布式计算测试
在HDFS文件系统根目录下面创建一个wcinput文件夹
[root@hadoop01 hadoop-2.9.2]# hdfs dfs -mkdir /wcinput创建wc.txt文件,输入如下内容
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn kmning
kmning
kmning上传wc.txt到Hdfs目录/wcinput下
hdfs dfs -put wc.txt /wcinput执行mapreduce任务
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput/ /wcoutput打印如下
24/07/03 20:44:26 INFO client.RMProxy: Connecting to ResourceManager at hadoop03/192.168.43.103:8032
24/07/03 20:44:28 INFO input.FileInputFormat: Total input files to process : 1
24/07/03 20:44:28 INFO mapreduce.JobSubmitter: number of splits:1
24/07/03 20:44:28 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
24/07/03 20:44:29 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1720006717389_0001
24/07/03 20:44:29 INFO impl.YarnClientImpl: Submitted application application_1720006717389_0001
24/07/03 20:44:29 INFO mapreduce.Job: The url to track the job: http://hadoop03:8088/proxy/application_1720006717389_0001/
24/07/03 20:44:29 INFO mapreduce.Job: Running job: job_1720006717389_0001
24/07/03 20:44:45 INFO mapreduce.Job: Job job_1720006717389_0001 running in uber mode : false
24/07/03 20:44:45 INFO mapreduce.Job: map 0% reduce 0%
24/07/03 20:44:57 INFO mapreduce.Job: map 100% reduce 0%
24/07/03 20:45:13 INFO mapreduce.Job: map 100% reduce 100%
24/07/03 20:45:14 INFO mapreduce.Job: Job job_1720006717389_0001 completed successfully
24/07/03 20:45:14 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=70
FILE: Number of bytes written=396911
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=180
HDFS: Number of bytes written=44
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=9440
Total time spent by all reduces in occupied slots (ms)=11870
Total time spent by all map tasks (ms)=9440
Total time spent by all reduce tasks (ms)=11870
Total vcore-milliseconds taken by all map tasks=9440
Total vcore-milliseconds taken by all reduce tasks=11870
Total megabyte-milliseconds taken by all map tasks=9666560
Total megabyte-milliseconds taken by all reduce tasks=12154880
Map-Reduce Framework
Map input records=5
Map output records=11
Map output bytes=124
Map output materialized bytes=70
Input split bytes=100
Combine input records=11
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=70
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=498
CPU time spent (ms)=3050
Physical memory (bytes) snapshot=374968320
Virtual memory (bytes) snapshot=4262629376
Total committed heap usage (bytes)=219676672
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=80
File Output Format Counters
Bytes Written=44查看结果
[root@hadoop01 hadoop-2.9.2]# hdfs dfs -cat /wcoutput/part-r-00000
hadoop 2
hdfs 1
kmning 3
mapreduce 3
yarn 2可见,程序将单词出现的次数通过MapReduce分布式计算统计了出来。
![[Unity入门01] Unity基本操作](https://i-blog.csdnimg.cn/direct/fc99f0c9da1c4aaf9efd229e1eef51b9.png)