一、双向链表的结构
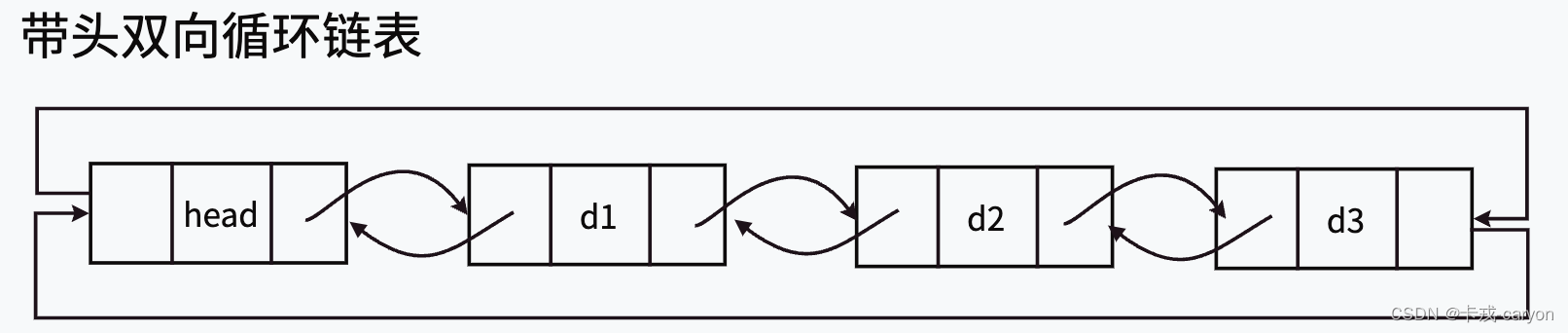
注意:这里的“带头”跟前面我们说的“头节点”是两个概念,带头链表里的头节点,实际为“哨兵位”,哨兵位节点不存储任何有效元素,只是站在这里“放哨的”。
“哨兵位”存在的意义:遍历循环链表避免死循环。
二、双向链表的实现
2.1 双向链表结点的创建
typedef int DLType;
//创建结构体
typedef struct DList
{
DLType data;
struct DList* prev;
struct DList* next;
}DL;
2.2 双向链表的初始化与销毁
//初始化phead
DL* init(void)
{
DL* phead = BuyNewNode(0);
return phead;
}
//销毁链表,这里需要主要phead是形参,这里的最后将phead置空并不能将原链表中的phead置空,
//因此原链表中的phead需要手动置空,详细实现见源码
void DLDesdroy(DL* phead)
{
assert(phead);
DL* tail =phead->next;
while (tail != phead)
{
DL* next = tail->next;
free(tail);
tail= next;
}
free(phead);
phead = NULL;
}
2.3 双向链表的增删查改
由于多次创建结点,因此我们将它提炼为一个函数
//创造新的节点
DL* BuyNewNode(DLType x)
{
DL* newnode = (DL*)malloc(sizeof(DL));
if (newnode == NULL)
{
perror("malloc is failed!\n");
return 1;
}
newnode->data = x;
newnode->next = newnode->prev = newnode;
return newnode;
}
//尾插
void DLPushBack(DL* phead,DLType x)
{
assert(phead);
DL* newnode = BuyNewNode(x);
newnode->next = phead;
phead->prev->next = newnode;
newnode->prev = phead->prev;
phead->prev = newnode;
}
//尾删
void DLPopBack(DL* phead)
{
assert(phead);
assert(phead->next != phead);
DL* tail = phead->prev;
DL* prev = tail->prev;
prev->next = phead;
phead->prev = prev;
free(tail);
tail = NULL;
}
//头插
void DLPushFront(DL* phead, DLType x)
{
assert(phead);
DL* newnode = BuyNewNode(x);
DL* first = phead->next;
newnode->next = first;
first->prev = newnode;
phead->next = newnode;
newnode->prev=phead;
}
//头删
void DLPopFront(DL* phead)
{
assert(phead);
assert(phead->next != phead);
DL* first = phead->next;
DL* second = first->next;
phead->next = second;
second->prev = phead;
free(first);
first = NULL;
}
//查找
DL* DLFind(DL* phead,DLType x)
{
assert(phead);
DL* cur = phead->next;
while ( cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//pos位置插入数据
void DLInsert(DL* pos,DLType x)
{
assert(pos);
DL* newnode = BuyNewNode(x);
DL* prev = pos->prev;
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
//pos位置之后插入数据
void DLInsertAfter(DL* pos, DLType x)
{
assert(pos);
DL* newnode = BuyNewNode(x);
DL* next = pos->next;
newnode->next = next;
next->prev = newnode;
pos->next = newnode;
newnode->prev = pos;
}
//删除pos位置元素
void DLErase(DL* pos)
{
assert(pos);
DL* next = pos->next;
DL* prev = pos->prev;
prev->next = next;
next->prev = prev;
free(pos);
pos = NULL;
}
2.4 双向链表的打印
//打印链表
void DLPrint(DL* phead)
{
DL* pcur = phead->next;
while (pcur != phead)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
2.5 双向链表的源码
//DL.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int DLType;
typedef struct DList
{
DLType data;
struct DList* prev;
struct DList* next;
}DL;
//初始化
DL* init(void);
//打印
void DLPrint(DL* phead);
//尾插、尾删
void DLPushBack(DL* phead, DLType x);
void DLPopBack(DL* phead);
//头插、头删
void DLPushFront(DL* phead, DLType x);
void DLPopFront(DL* phead);
//查找
DL* DLFind(DL* phead, DLType x);
//指定位置插入数据、指定位置之后插入数据
void DLInsert(DL* pos, DLType x);
void DLInsertAfter(DL* pos, DLType x);
//删除pos
void DLErase(DL* phead);
void DLDesdroy(DL** phead);
//DL.c
#include "DList.h"
//创造新的节点
DL* BuyNewNode(DLType x)
{
DL* newnode = (DL*)malloc(sizeof(DL));
if (newnode == NULL)
{
perror("malloc is failed!\n");
return 1;
}
newnode->data = x;
newnode->next = newnode->prev = newnode;
return newnode;
}
//初始化phead
DL* init(void)
{
DL* phead = BuyNewNode(0);
return phead;
}
//打印链表
void DLPrint(DL* phead)
{
DL* pcur = phead->next;
while (pcur != phead)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
//尾插
void DLPushBack(DL* phead,DLType x)
{
assert(phead);
DL* newnode = BuyNewNode(x);
newnode->next = phead;
phead->prev->next = newnode;
newnode->prev = phead->prev;
phead->prev = newnode;
}
//尾删
void DLPopBack(DL* phead)
{
assert(phead);
assert(phead->next != phead);
DL* tail = phead->prev;
DL* prev = tail->prev;
prev->next = phead;
phead->prev = prev;
free(tail);
tail = NULL;
}
//头插
void DLPushFront(DL* phead, DLType x)
{
assert(phead);
DL* newnode = BuyNewNode(x);
DL* first = phead->next;
newnode->next = first;
first->prev = newnode;
phead->next = newnode;
newnode->prev=phead;
}
//头删
void DLPopFront(DL* phead)
{
assert(phead);
assert(phead->next != phead);
DL* first = phead->next;
DL* second = first->next;
phead->next = second;
second->prev = phead;
free(first);
first = NULL;
}
//查找
DL* DLFind(DL* phead,DLType x)
{
assert(phead);
DL* cur = phead->next;
while ( cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
//pos位置插入数据
void DLInsert(DL* pos,DLType x)
{
assert(pos);
DL* newnode = BuyNewNode(x);
DL* prev = pos->prev;
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
//pos位置之后插入数据
void DLInsertAfter(DL* pos, DLType x)
{
assert(pos);
DL* newnode = BuyNewNode(x);
DL* next = pos->next;
newnode->next = next;
next->prev = newnode;
pos->next = newnode;
newnode->prev = pos;
}
//删除
void DLErase(DL* pos)
{
assert(pos);
DL* next = pos->next;
DL* prev = pos->prev;
prev->next = next;
next->prev = prev;
free(pos);
pos = NULL;
}
//销毁链表
void DLDesdroy(DL* phead)
{
assert(phead);
DL* tail =phead->next;
while (tail != phead)
{
DL* next = tail->next;
free(tail);
tail= next;
}
free(phead);
phead = NULL;
}