作者简介:
专注于研究Linux内核、Hotspot虚拟机、汇编语言、JDK源码、各大中间件源码等等
喜欢的话,可以三连+关注~
SynchronousQueue是什么
在JDK源码中JUC包下的并发编程阻塞/同步队列实现各种花样,但是队列的实现无非是。
先进先出,后进后出(FIFO)
先进后出,后进先出(LIFO)
再考虑,不管是FIFO还是LIFO,其实最终就是根据数组或者链表,改变插入的方式即可实现。
FIFO:
尾插头出
头插尾出
LIFO:
尾插尾出
头插头出
那么,什么是SynchronousQueue呢?字面意思是同步队列?线程安全的队列?

SynchronousQueue继承与AbstractQueue,实现于BlockingQueue,为了一些初学的读者,笔者认为有必要介绍一下基础的API的意义。
API | 作用 | 注意事项 |
offer | 尝试往队列中插入节点 | 只是尝试,不成功就退出 |
poll | 尝试从队列中取出节点 | 只是尝试,不成功就退出 |
put | 往队列中插入节点 | 插入后,一定要被消费,要不然就一直阻塞等待 |
take | 从队列中取出节点 | 直到消费到节点要不然就一直阻塞等待 |
从上述描述中可以看到,put和take方法一定要被消费或者消费到节点才能退出,要不然就一直等待,所以这也是SynchronousQueue的特点。接下来我们再从构造方法入手。

我们从构造方法就可以知道SynchronousQueue实现分为队列实现和栈实现,也就是我们上文介绍2种实现方式。
读者们,应该清楚,关乎到多并发,那么就要跟线程安全打交道,线程安全又分为锁的力度,因为这关乎于多线程的效率问题。
所以接下来我们需要去分析DougLea是如何高效的实现SynchronousQueue。
基于队列实现(FIFO)


// SynchronousQueue的put方法
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
// SynchronousQueue的take方法
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}可以很清楚的看到不管是put还是take方法,他们的统一入口都是transferer.transfer方法,只不过参数不一致,所以也可以明白,内部可能是根据参数来判断当前是消费者还是生产者。
QNode s = null; // constructed/reused as needed
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
// 半对象问题处理,与我们关系不大
if (t == null || h == null) // saw uninitialized value
continue; // spin
// 当h==t的时候代表当前队列中只存在伪节点
// t.isData == isData代表之前插入的节点跟本次插入的节点是相同的角色。
// 如果当前队列是消费者,那么本次插入是消费者就进入if,反之进入到else
if (h == t || t.isData == isData) {}
// 当前队列中存在节点
// 并且本次进入的节点与队列尾部的节点不一致
// 这里需要理解,SynchronousQueue队列在某一时刻只能都是生产者或者都是消费者节点。
// 因为进入else的是与当前队列相反的节点,所以进入else的线程,代表与队列头部节点匹配。
else {}
}我们需要先理解整体分支,再理解细节。而Doug Lea老爷子的代码规范就是for(;;) 然后if else的分支,CAS保证原子性,这里也是依旧如此。而生产者和消费者都是进入此方法,这里需要理解,SynchronousQueue队列在某一时刻只能都是生产者或者都是消费者节点。为什么这么说,因为对于SynchronousQueue而言,他是生产者和消费者做匹配,匹配成功消耗一个队列节点,所以某一时刻只能都是生产者或者都是消费者节点。

// SynchronousQueue中队列实现的transfer方法
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
// 用bool代表当前是消费者还是生产者
// case1:true为生产者
// case2:false为消费者
boolean isData = (e != null);
for (;;) {
// 缓存思想666666666666
QNode t = tail;
QNode h = head;
// 当前未初始化?
// 构造方法半对象问题?
// 创建对象分为三步:开辟空间,初始化对象,返回对象。
// 这里极端情况:创建完SynchronousQueue对象就立马调用了方法,并且出现了半对象问题
// 所以出现这种极端情况就直接continue一次即可,因为半对象一般在很短的时间内会初始化完毕。
if (t == null || h == null) // saw uninitialized value
continue; // spin
// 当h==t的时候代表当前队列中只存在伪节点
// t.isData == isData代表当前队列存在节点,
// t.isData == isData代表之前插入的节点跟本次插入的节点是相同的角色。
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
// 当前队列尾部发生了变化
if (t != tail) // inconsistent read
continue;
// 当前队列尾部发生了变化
if (tn != null) { // lagging tail
// 拿到最新的尾节点
advanceTail(t, tn);
continue;
}
// offer和poll方法是不等待的,这是尝试
// 如果不愿意等,那就滚蛋。
if (timed && nanos <= 0) // can't wait
return null;
// 初始化本次插入的节点。
if (s == null)
s = new QNode(e, isData);
// 尝试CAS插入到队列尾部。
// 如果失败那就continue重试。
if (!t.casNext(null, s)) // failed to link in
continue;
// 这里的t是缓存,也即只要改变了最新的tail指针,这里就不会cas成功。
// 如果成功,那就改变tail指针,tail指向当前线程节点。
advanceTail(t, s); // swing tail and wait
// 等待对方来匹配。
Object x = awaitFulfill(s, e, timed, nanos);
/**
* 以下代码是被醒来(也可以是自旋尝试成功)
* case1:正常唤醒
* case2:中断或者超时唤醒
*
* 当前线程已经匹配完成了,顺带帮忙把队列调整一下(也即多线程之间的协作)
* */
// 如果匹配返回的值是本身,那就代表已经被中断或者超时等待了。
// 所以我们需要去清楚自身节点。
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
/**
* 很好奇,在下面的else中已经帮忙推进了下一个节点了,为什么这里还需要。
* 考虑一下,awaitFulfill自旋成功了,并没有去操作系统中阻塞。所以这里可以抢先推进
*
* */
// 如果s.isOffList()返回是false代表自身的收尾工作其他线程没有帮我完成,所以我需要自己去完成,反之,为true代表其他线程已经帮我完成
if (!s.isOffList()) { // not already unlinked
// 因为是尾插头出,所以当t是头节点的next
// 推进下一个头节点的指向,并且把自身设置成垃圾回收状态。
advanceHead(t, s); // unlink if head
// x !=null
// case1:消费者
// case2:中断或者超时等待
if (x != null) // and forget fields
// 把节点自身的item设置成自身
// 目的是为了下次来的节点知道当前节点已经作废了。
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
// else代表当前是最后节点的对应匹配节点。
} else { // complementary-mode
// 因为head节点指向的是伪节点,所以需要拿到head.next节点。
QNode m = h.next; // node to fulfill
// 队列发生了变化 或者当前队列只有伪节点存在,那就直接重试
if (t != tail || m == null || h != head)
continue; // inconsistent read
// 拿到当前要匹配的节
Object x = m.item;
// case1:如果当前模式是一样
// case2:或者被中断或者超时等待取消了节点
// case3:或者cas尝试匹配失败。
// 就直接推进到下一个节点匹配,当前匹配节点已经失效。
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
// 尝试匹配失败,推进下一个节点,然后重试。
advanceHead(h, m); // dequeue and retry
continue;
}
// 尝试匹配成功了,所以head.next节点已经无用,所以需要改变节点,所以把head.next节点作为伪节点。
advanceHead(h, m); // successfully fulfilled
// 唤醒在等待的节点
return (x != null) ? (E)x : e;
}
}
}
// 线程自旋等待或者阻塞
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
// 因为当前存在超时等待,所以要记录时间
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 得到当前线程对象,因为可能要睡眠,所以需要记录。
Thread w = Thread.currentThread();
// 得到当前自旋的次数。
// 如果当前的head.next == s 就代表当前是排在队列的第一位,很大几率被匹配成功.反之,不是第一位就直接滚去阻塞。
// 如果是第一位还要参考是否存在超时等待。
// maxTimedSpins 如果当前是单核就为0,非单核就是32(如果带超时)
// maxUntimedSpins 如果当前是单核就为0,非单核就是32*16(如果不带超时)
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
//
for (;;) {
// 如果被中断了
if (w.isInterrupted())
// 把当前节点的item设置为this
s.tryCancel(e);
Object x = s.item;
// 如果已经被匹配了。
// 或者已经被中断或者超时等待取消了。
if (x != e)
return x;
// 检查是否超时等待了。
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
// 如果还有自旋次数就--
if (spins > 0)
--spins;
// 把当前线程对象赋值,用于唤醒
else if (s.waiter == null)
s.waiter = w;
// 如果当前是非超时等待,就直接park即可。
else if (!timed)
LockSupport.park(this);
// 如果当前是超时等待,那就超时等待的park即可。
// 并且这里有一个点是,如果超时等待的时间小于1秒,就不去阻塞了,自旋即可。
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}以上代码是transfer方法的所有实现,读者先需明白,这个方法是统一的入口。大致的流程如下:
相同节点的插入逻辑
从方法参数得到当前是消费者还是生产者
判断当前队列是否存在节点,不存在节点就需要去阻塞,因为SynchronousQueue的特性是一定要匹配成功才返回,要不然一直阻塞
判断当前线程与队列最后一个节点是否是同一个模式(因为在SynchronousQueue队列同一时刻节点都是一样的,如果当前插入的节点不一致,他就是一个匹配节点,反之,如果一致就需要插入到队尾中,阻塞等待,直到轮到他与其他线程做匹配)
创建一个节点
CAS尝试插入到尾部
CAS改变tail指针
自旋等待匹配线程来匹配,等待一定次数没成功就去操作系统阻塞
匹配成功或者是中断或者超时等待被唤醒,也有可能没睡眠,自旋等待成功了。
如果是中断或者超时等待就返回null
如果是匹配成功,那就推进下一个头结点,因为当前节点已经作废。
然后就是return

相同模式尾部插入节点
相反节点的插入逻辑(匹配)
从方法参数得到当前是消费者还是生产者
当前线程与队尾节点不是同一个模式
那就拿到头节点的next节点(因为头结点是伪节点)
CAS尝试匹配
如果失败就continue;重试
如果是匹配成功,那就推进下一个头结点,因为当前节点已经作废。
然后就是return

相反模式头部匹配节点
基于栈实现(LIFO)
有了队列的实现,再去看栈的实现会轻松很多,大概的思想不变,不过栈玩的比较花。
/**
* 基于Stack的实现
* */
// 当前是消费者
static final int REQUEST = 0;
// 当前是生产者
static final int DATA = 1;
// 当前已经在匹配中
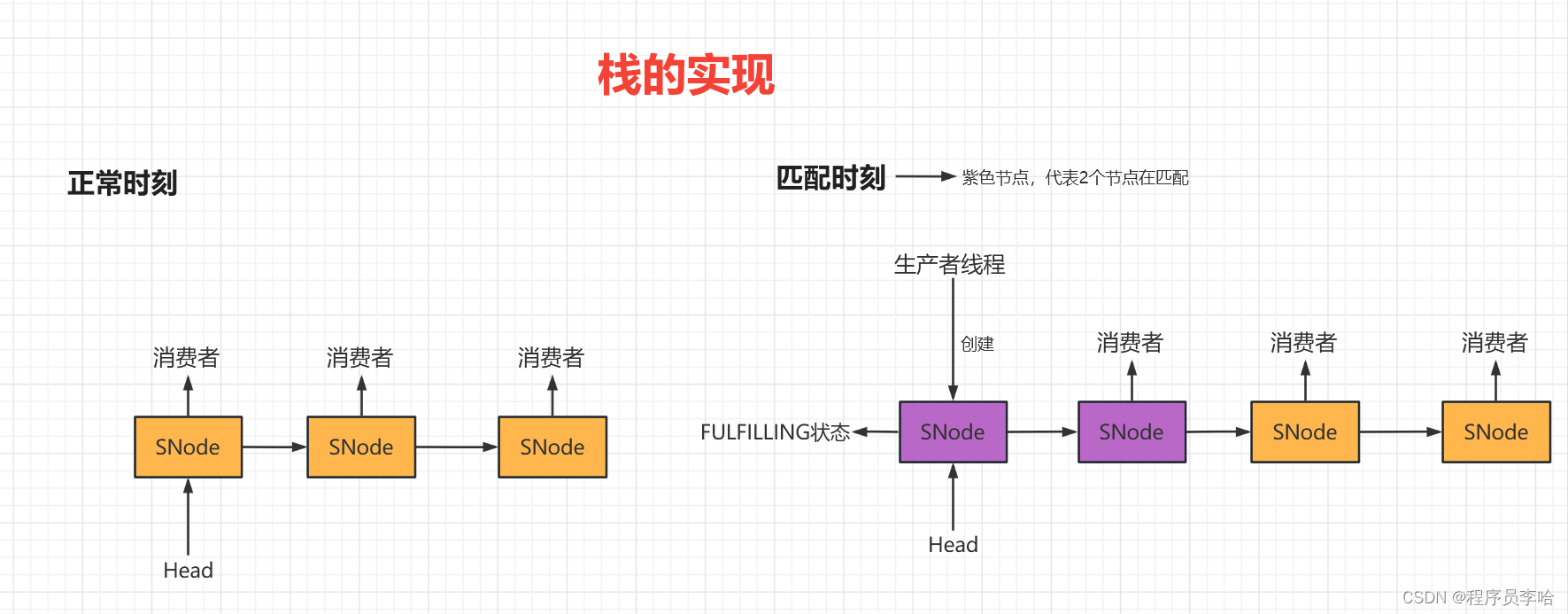
static final int FULFILLING = 2;读者们应该知道,栈结构是后进先出,所以对于栈节点就不存在tail指针,就只需要存在head节点即可。
从队列实现,我们可以知道,只创建了一个节点,匹配线程进来并不会创建节点,而是直接CAS交换。但是对于栈的实现不一致,匹配线程会创建一个状态位为FULFILLING节点,作为head节点,FULFILLING节点与之前的head节点匹配。如下图所示:
栈的实现也是统一入口方法transfer,不管是生产者put还是消费者take方法最终就是进入到transfer,这跟队列实现是一样的,毕竟面向对象的思想。
所以我们分析transfer方法即可。
老规矩,我们把整体的结构分析,再陷入细节分析。还是DougLea的经典写法for(;;) + if else + CAS
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
// REQUEST代表消费者
// DATA代表生产者
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
// case1:h==null代表当前栈中还没有数据(为什么不需要伪节点,因为永远时刻都是一个竞争点)
// case2:h.mode == mode 代表当前栈中有数据,但是本次模式跟栈顶的一样。
if (h == null || h.mode == mode) { // empty or same-mode
// 栈中已经存在数据,且当前模式与栈顶的模式不一致,并且需要当前模式是生产者或者消费者
// isFulfilling(h.mode) 返回为false代表当前是生产者或者消费者
// 所以这个else if就是与栈顶尝试匹配的线程。
} else if (!isFulfilling(h.mode)) { // try to fulfill
// 这里表示当前是FULFILLING模式,代表当前头节点已经在匹配了。
} else { // help a fulfiller
}
}
}第一个if代表当前队列为空,或者当前线程模式与头节点一致,此时就需要添加到栈顶了
第二个else if代表当前线程模式与头节点不一致,模式是生产者或者消费者
第三个else代表当前栈顶模式是正在匹配模式(由上面的图可以看到,在匹配过程中,会创建一个状态为FULFILLING节点充当head节点)
把整体结构分析完以后,那么接下来就是陷入细节了。
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
// REQUEST代表消费者
// DATA代表生产者
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
// case1:h==null代表当前栈中还没有数据(为什么不需要伪节点,因为永远时刻都是一个竞争点)
// case2:h.mode == mode 代表当前栈中有数据,但是本次模式跟栈顶的一样。
if (h == null || h.mode == mode) { // empty or same-mode
// 如果当前不愿意等待的条件,
// 因为当前模式一样,或者要当栈顶的节点,需要等待匹配的节点,所以不愿意等待的就要gun。。。
if (timed && nanos <= 0) { // can't wait
// 多线程的协作
// 如果当前栈中有数据,并且栈顶的节点被取消了。
if (h != null && h.isCancelled())
// 尝试帮助切换栈顶节点,因为栈顶节点已经没用了
// 不管尝试成功还是失败,都会进入到下一轮for循环中,因为栈顶节点改变了,所以当前节点可能匹配或者站位成功
casHead(h, h.next); // pop cancelled node
// 如果当前栈中没有数据,或者栈顶的节点没有被取消,直接返回,因为当前不想等待,那就gun。。。
else
return null;
// 来到这里代表当前节点愿意等待
// case1:无限期等待。
// case2:超时等待。
// 因为当前栈是头插法,所以CAS尝试头插。
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 尝试成功了,也即插入到栈顶了。
// 此时,就需要等待匹配的线程节点完成匹配即可。
// 所以方案是:自旋尝试,自旋一定次数后,再去OS中阻塞,等待被匹配的线程唤醒即可。
SNode m = awaitFulfill(s, timed, nanos);
// 如果当前唤醒是因为被中断或者是超时了
if (m == s) { // wait was cancelled
clean(s);
return null;
}
// 来到这里代表当前已经匹配成功了,我们是不是需要做一些汕尾工作呢?没错,是需要多线程协作一些,当个好人准没错。
// 如果当前栈还有数据,并且栈顶的next节点就是当前线程节点。
if ((h = head) != null && h.next == s)
// 尝试把栈顶指针改成当前节点的下一个节点。
casHead(h, s.next); // help s's fulfiller
return (E) ((mode == REQUEST) ? m.item : s.item);
}
// 栈中已经存在数据,且当前模式与栈顶的模式不一致,并且需要当前模式是生产者或者消费者
// isFulfilling(h.mode) 返回为false代表当前是生产者或者消费者
// 所以这个else if就是与栈顶尝试匹配的线程。
} else if (!isFulfilling(h.mode)) { // try to fulfill
// 如果已经被取消。
if (h.isCancelled()) // already cancelled
// 尝试把栈顶指针修改成next节点,也即尝试与下一个节点匹配。
casHead(h, h.next); // pop and retry
// 这里与队列实现不一样,他这里匹配线程,也创建一个节点。
//
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
for (;;) { // loop until matched or waiters disappear
// m是与当前线程节点匹配的节点。
SNode m = s.next; // m is s's match
// m==null的可能是被取消了,并且已经被清理了。
if (m == null) { // all waiters are gone
// 匹配的节点被取消了
casHead(s, null); // pop fulfill node
s = null; // use new node next time
// 再次尝试。
break; // restart main loop
}
// 因为匹配消耗2个节点,所以这里拿到后面的节点,当匹配成功后,协作完成节点的转换。
SNode mn = m.next;
// 尝试匹配
if (m.tryMatch(s)) {
// 如果匹配成功,协作把下次匹配的节点改变。也即改变栈顶指针。
casHead(s, mn); // pop both s and m
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
// 尝试失败的话,
s.casNext(m, mn); // help unlink
}
}
// 这里表示当前是FULFILLING模式,代表当前头节点已经在匹配了。
} else { // help a fulfiller
SNode m = h.next; // m is h's match
// 已经匹配成功了。
if (m == null) // waiter is gone
//
casHead(h, null); // pop fulfilling node
// 当前还未匹配成功。
else {
SNode mn = m.next;
// 尝试帮他们匹配
if (m.tryMatch(h)) // help match
// 匹配成功改变头结点指针,方便其他线程下次匹配。
casHead(h, mn); // pop both h and m
// 如果匹配失败,就把头节点改变成
else // lost match
// 切换到下一个节点。
// 因为匹配的节点可能被中断或者超时取消了,或者其他线程已经完成了匹配工作。
h.casNext(m, mn); // help unlink
}
}
}
}
// 线程CAS自旋或者阻塞
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
//
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
// 被中断了
if (w.isInterrupted())
// 取消节点
s.tryCancel();
// 拿到匹配到的数据,如果没有匹配到就为null
SNode m = s.match;
// case1:匹配到了数据
// case2:中断唤醒或者超时(这种情况下,m为this)
if (m != null)
return m;
// 判断当前是否超时
if (timed) {
nanos = deadline - System.nanoTime();
// 如果超时就把match设置为this,然后continue,下次for循环就可以退出了。
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
// 如果还有次数
if (spins > 0)
// 动态次数,这才是douglea的玩法。
// 如果shouldSpin(s)返回false,代表前面已经有相同的节点插入进去了,所以我的可能性特别小,所以下一轮直接阻塞去了。
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
// 尝试匹配
boolean tryMatch(SNode s) {
// match == null判断前缀,如果这个都不成功,下面的CAS就没必要执行了
if (match == null &&
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {
Thread w = waiter;
if (w != null) { // waiters need at most one unpark
waiter = null;
// 匹配成功,需要唤醒对方
LockSupport.unpark(w);
}
return true;
}
// 如果match == s代表当前匹配成功
// 如果match != s代表当前匹配失败
return match == s;
}当前线程与栈顶节点模式相同的情况
当前是不阻塞的模式下直接返回
阻塞的模式下创建新的节点CAS插入到head节点
自旋等待匹配,自旋次数用尽以后去OS阻塞
唤醒,这里要区分唤醒是中断还是超时,还是匹配完成后唤醒
如果是中断或者超时,此时做特殊处理
匹配完成以后,当前节点就是作废节点,我有必要把自己回收
return返回
当前线程与栈顶节点模式不同的情况(匹配)
创建一个FULFILLING节点,把head节点指向FULFILLING节点
CAS尝试匹配
如果匹配成功就把当前节点引用置空(Help GC)
失败的话,换下个节点重试(有可能匹配的节点中断唤醒或者超时了)
head节点是FULFILLING模式(此模式是帮助正在匹配的线程完成匹配)
CAS尝试匹配,如果成功就把匹配的节点引用置空(Help GC)
如果CAS失败,换下个节点重试(有可能匹配的节点中断唤醒或者超时了)
总结
最后,如果本帖对您有一定的帮助,希望能点赞+关注+收藏!您的支持是给我最大的动力,后续会一直更新各种框架的使用和框架的源码解读~!