背景
之前学习k8s的各组件还是感觉不深入, 只停留在名字解释上面。总是不能深入理解,例如应用部署后kuber-proxy会在master 和node上添加什么样的iptables规则、部署一个应用的完整流程( 手画各组件功能并介绍10分钟以上 )、schedule具体是怎么调度的、limit request 是如何限制资源的…
- [ 在这里先抛砖引玉,极客时间孟老师的云原生训练营讲的比较深,推荐观看。后续把学习笔记再更新上来。]
k8s主要组件及功能(感性认知)
一个kubernetes集群主要是由控制节点(master)、**工作节点(node)**构成,每个节点上都会安装不同的组件。
master:集群的控制平面,负责集群的决策 ( 管理 )
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
Etcd :负责存储集群中各种资源对象的信息
node:集群的数据平面,负责为容器提供运行环境 ( 干活 )
Kubelet : 负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器
KubeProxy : 负责提供集群内部的服务发现和负载均衡
Docker : 负责节点上容器的各种操作

各组件再认识
Kubernetes的节点包含两种角色:Master节点和Node节点。
Master节点上面部署
- apiserver
- scheduler
- controller manager(replication controller、node controller等)
Node节点上面部署kubelet和proxy。当然也可以将它们部署到一起,只是生产环境通常不建议这样做。
Apiserver
Apiserver是Kubernetes最核心的组件,它是整个集群API的入口,每个组件都需要和它交互。
Kubernetes所有资源数据都是通过Apiserver保存到后端Etcd的,当然它本身还提供了对资源的缓存。它本身是无状态的,所以在集群的高可用部署中,可以部署成多活。
Kubernetes API接口的分层
Kubernetes API接口主要分为组、版本和资源三层,接口层次如图所示。
对于“/apis/batch/v1/jobs”接口,batch是组,v1是版本,jobs是资源。Kubernetes的核心资源都放在“/api”接口下,扩展的接口放在“/apis”下。

api版本规划
Kubernetes资源会同时存在多个版本。当新的资源接口刚加入还不成熟时,通常会使用alpha版本,伴随着充分测试逐渐成熟后会变更为beta版本,最终稳定版本将会使用vx版本。譬如statefuleset这个资源之前在“/apis/batch/v2alpha1”和“/apis/batch/v1beta1”中都存在,但伴随着该功能的完善,现在已经将会迁移到v1版本下。
请求到达apiserver后的流程
Apiserver启动后会将每个版本的接口都注册到一个核心的路由分发器(Mux)中。当客户端请求到达Apiserver后,首先经过Authentication认证和Authorization授权。认证支持Basic、Token及证书认证等。授权目前默认使用的是RBAC。经过路由分发到指定的接口,为了兼容多个资源版本,请求的不同版本的资源类型会统一转化为一个内部资源类型,然后进入Admission准入控制和Validation资源校验,在准入控制采用插件机制,用户可以定义自己的注入控制器验证,并更改资源配置。资源校验主要是验证参数是否合法,必传参数是否齐备等。最后再转化到用户最初的资源版本,并保存到Etcd中

详细的架构图如下:

为了将外部传入不同版本的资源类型统一转化为对应的内部类型,需要这个内部资源类型能够兼容不同版本的外部资源。
内部的版本定义在types.go文件中。如果是其他版本和内部版本之间转化可以通过自动生成的zz_generated.conversion.go或者自定义的conversion.go完成。
由于v2beta2版本的autoscaling可以直接转化为内部autoscaling,而v1版本的autoscaling并不支持多指标(只能根据CPU扩容),所以需要在conversion.go中将CPU指标当作多指标中的一个指标进行处理。
Controller manager
Controller manager是真正负责资源管理的组件,它主要负责容器的副本数管理、节点状态维护、节点网段分配等。
它是Kubernetes负责实现生命式API和控制器模式的核心。
ReplicaSet controller 是如何被管理的?
以ReplicaSet为例,它会周期地检测理想的“目标容器数”和真实的“当前容器数”是否相同。如果不相等,则会将实际的容器数调整到目标容器数。
当设置一个ReplicaSet的副本数为10的时候,如果实际的容器数小于10,则会执行调用Apiserver创建Pod。如果当前容器数大于10,则会执行删除Pod操作。ReplicaSet检测过程如图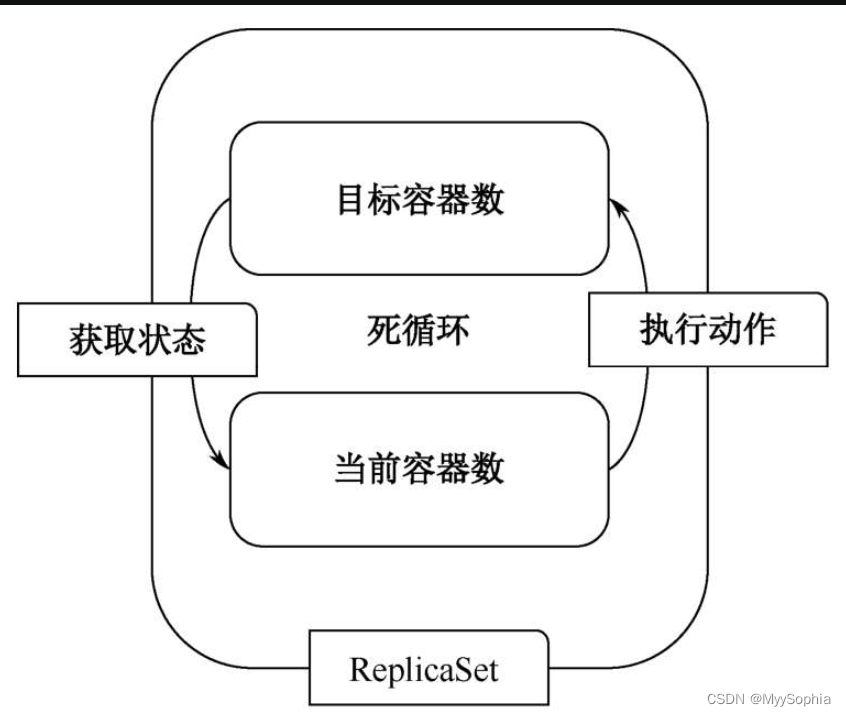
Scheduler
Scheduler负责容器调度组件。每个Pod最终需要在一台node节点上启动,通过Scheduler调度组件的筛选、打分,可以选择出Pod启动的最佳节点。当Pod创建后,Pod的NodeName属性为空,Scheduler会查询所有NodeName为空的Pod,并执行调度策略。选择最优的放置节点后,调用Apiserver绑定Pod对应的主机(设置Pod NodeName属性)。当绑定过后,对应节点的Kubelet便可以启动容器。
Scheduler的调度过程的两个步骤
第一步是筛选(Predicate)
筛选满足需要的节点。筛选的条件主要包括
1)Pod所需的资源(CPU、内存、GPU等);
2)端口是否冲突(主要是针对Pod HostPort端口和主机上面已有端口);
3)nodeSelector及亲和性(Pod亲和性和Node亲和性)
4)如果使用本地存储,那么Pod在调度时,将只会调度存储绑定的节点;
5)节点的驱赶策略,节点可以通过taint(污点)设置驱赶Pod策略,对应的Pod也可以设置Toleration(容忍)。


第二步是根据资源分配算法排序打分(Priorities)
最终选择得分最高的节点作为最终的调度节点,主要调度策略包括
-
LeastRequestedPriority(最少资源请求算法)
-
BalancedResourceAllocation(均衡资源使用算法
-
ImageLocalityPriority(镜像本地优先算法)
-
NodeAffinityPriority(主机亲和算法)等。
为了归一化每种算法的权重,每种算法取值范围都是0~10,最终累加所有算法的总和,取得分最大的主机作为Pod的运行主机。


为了提高调度的效率,Scheduler的Predicate和Priorities采用了并行调度。除此之外,Scheduler组件本地维护了一个调度队列和本地缓存,调度队列暂存了需要被调度的Pod,还可以调整调度的先后顺序。本地缓存主要是缓存Pod和Node信息,这样可以避免每次调度时都要从Apiserver获取主机信息。如图

Scheduler中的乐观锁
Predicate和Priorities都是并行操作的,那么有可能会出现数据的不一致,即Pod调度时主机上面资源是符合要求的。当容器启动时,由于其他容器也调度到该节点导致资源又不满足要求了。所以,在Kubelet启动容器之前首先执行一遍审计(在Kubelet上重新执行一遍Predicate)操作,确认资源充足才会启动容器,否则将更新Pod状态为Failed。
Init Container的资源限制的坑

pod资源申请计算实例
下面以Pod资源使用为例,Pod通过request和limit的定义资源使用的下限和上限。Scheduler会累加Pod中每个容器的资源申请量,作为Pod的资源申请量。这里需要注意的是Initcontainer容器的资源用量,由于它只是在运行业务容器之前启动一段时间,并不会累加到Pod总资源申请量中,因此只是影响Pod资源申请的最大值
containers:
- name: nginx
image: nginx:1.17.1
resources:
limits:
cpu: "2"
memory: "1Gi"
- name: nginx
image: nginx:1.20.2
resources:
limits:
cpu: "1"
memory: "1Gi"
initContainers:
- name: test-mysql
image: busybox:1.30
resources:
limits:
cpu: "2"
memory: "3Gi"
- name: test-redis
image: busybox:1.30
resources:
limits:
cpu: "2"
memory: "1Gi"
最终得出这个Pod总的资源申请量为:CPU:3,Memory:3G。其中,CPU为3,两个业务容器CPU申请之和,大于任何一个InitContainers的CPU,而内存的3G来自InitContainers的内存申请。(init container 是串行执行完之后资源就释放了,所以不需要4GB)
nodeSelector
Node Affinity
podAffinity
Taints和Tolerations
Kubelet
Kubelet是具体干活的组件,它接收Apiserver分配的启动容器的任务,然后拉起容器。
当然,如果收到销毁指令,同样会执行删除容器的操作。本地镜像也是由Kubelet负责维护,配合GC机制,删除无用的镜像和容器。除此之外,它还需要定时向Apiserver上报自己的状态,一方面告知Apiserver自身还存活着,另一方面为了将本节点的Pod状态、存储使用等信息上报到Apiserver。Kubelet启动一个主线程,用于保持和Apiserver的通信,主线程不能被阻塞,否则将无法定时完成上报,导致Apiserver将该节点设置为NotReady状态。所以,Kubelet会启动很多协程用于检测节点状态,回收废旧资源,驱赶低优先级Pod,探测Pod健康状态等。
syncLoop是Kubelet的核心,它通过一个死循环不断接收来自Pod的变化信息,并通过各种Manger执行对应的操作。

Kube-proxy
Kube-proxy是代理服务,它可以为Kubernetes的Service提供负载均衡。本质上是iptables或者ipvs实现的。
Kubernetes将服务和Pod通过标签的方式关联到一起,通过服务的标签筛选找到后端的Pod,但服务的后端并非直接关联Pod,而是通过Endpoint(端点)关联。
Endpoint可以理解成“Pod地址:Pod端口”的组合,一个Endpoint可以加入多个服务中。
kube-proxy如何生成iptables规则的?
下面将通过一个服务的案例阐述kube-proxy如何生成iptables规则的。当我们创建一个服务后,默认情况下,Kubernetes会为每个服务生成一个集群虚IP。通过访问该IP便可以采用负载均衡的方式访问后端Pod中的服务。

service的yaml文件
apiVersion: v1
kind: Service
metadata:
name: nginx-service-nodeport
namespace: dev
spec:
clusterIP: 10.96.70.31
ports:
- nodePort: 30001
port: 80
protocol: TCP
targetPort: 80
selector:
name: nginx
sessionAffinity: None
type: NodePort
pod 分布在不同的节点
k get po -l name=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-web-2ztjg 1/1 Running 6 (144d ago) 144d 10.244.166.133 node1 <none> <none>
nginx-web-jl78g 1/1 Running 8 (144d ago) 144d 10.244.104.6 node2 <none> <none>
访问nginx
kubectl exec -it nginx-web-2ztjg -- /bin/bash
root@nginx-web-2ztjg:/#
root@nginx-web-2ztjg:/#
root@nginx-web-2ztjg:/# curl -s 10.96.70.31 | grep -i welcome
<title>Welcome to nginx!</title>
<h1>Welcome to nginx!</h1>
Pod-to-Service 的iptables规则探究
Pod-to-Service 数据包都被PREROUTING链拦截
iptables -t nat -nvL PREROUTING

这些数据包被重定向到KUBE-SERVICES链,在那里它们与所有配置的匹配,最终到达这些行:
iptables -t nat -nvL KUBE-SERVICES
Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * !10.244.0.0/16 0.0.0.0/0 /* Kubernetes service cluster ip + port for masquerade purpose */ match-set KUBE-CLUSTER-IP dst,dst
38 2192 KUBE-NODE-PORT all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 match-set KUBE-CLUSTER-IP dst,dst
为iptable设置alias
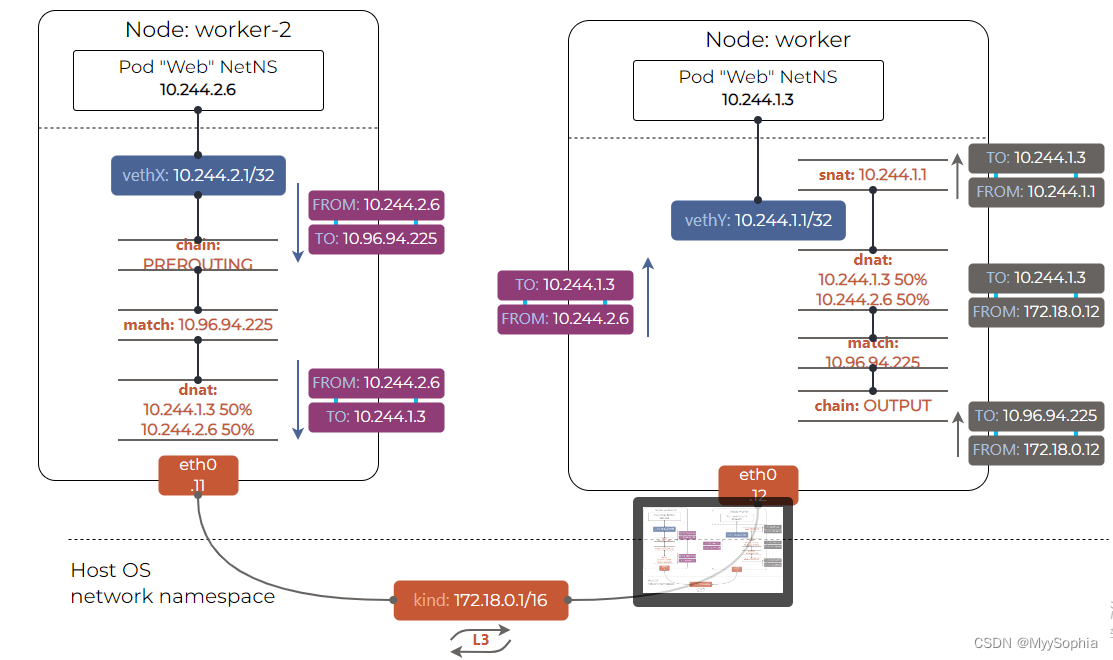
Pod 到svc的通信(紫色数据包)——完全在出口节点内实现,并依赖 CNI 实现 Pod 到 Pod 的可达性。
外部到svc的通信(灰色数据包)——包括任何外部来源的,最值得注意的是,节点到服务的流量。
iptables规则参考
Deployment的启动流程串起来
kubectl run(eg:kubectl run nginx–image=nginx–replicas=5)命令去创建一个Deployment。这个请求先到达Apiserver,Apiserver负责保存到Etcd,Controller manager中的Deployment控制器会监测到有一个Deployment被创建,此时会创建相应的ReplicaSet,ReplicaSet的控制器也会监测到有新的ReplicaSet创建这个事情,会根据相应的副本数调用Apiserver创建Pod。此时的Pod的主机字段是空的,因为还不知道将要在哪台机器上面启动,然后Scheduler开始介入,调度没有分配主机的Pod,通过预先设定的调度规则,包括节点标签匹配、资源使用量等选择出最合适的一台机器,在通过apiserver的bind请求将Pod的主机字段设置完成。那么Kubelet也监测到属于自己的节点有新容器创建的事件,于是便拉起一个容器,并上报给apiserver容器的状态
cloud-controller-manager
Kubernetes 1.6后面添加的,主要负责与IaaS云管理平台进行交互,主要是GCE和AWS。Kubernetes大部分部署目前都是在公有云环境中。Cloud-controller-manager通过调用云API获取计算节点状态,通过与云中负载均衡器交互,创建及销毁负载均衡,并且还可以支持云中存储的创建、挂载及销毁,主要是利用IaaS的能力扩展和增强Kubernetes的功能。



![[附源码]SSM计算机毕业设计智能视频推荐网站JAVA](https://img-blog.csdnimg.cn/5373a83253d541b7a94f872a17867d2e.png)