文章目录
- 1. 写在前面
- 2. 特征分析
- 3. 接口分析
- 3. 补JS环境
- 4. 补后缀参数
【🏠作者主页】:吴秋霖
【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究与开发工作!
【🌟作者推荐】:对爬虫领域以及JS逆向分析感兴趣的朋友可以关注《爬虫JS逆向实战》《深耕爬虫领域》
未来作者会持续更新所用到、学到、看到的技术知识!包括但不限于:各类验证码突防、爬虫APP与JS逆向分析、RPA自动化、分布式爬虫、Python领域等相关文章
作者声明:文章仅供学习交流与参考!严禁用于任何商业与非法用途!否则由此产生的一切后果均与作者无关!如有侵权,请联系作者本人进行删除!
1. 写在前面
瑞数相关的教程在网上可以说是层出不穷,各种技术方案均有!开源社区上多款针对瑞数定制的补环境框架,现在的过瑞数难度相比较于以前难度已经大大降低了!人均瑞数的成就人均可达成,本次我们使用补环境框架来过一下瑞数
2. 特征分析
在分析网站之前,我们需要去了解瑞数防护的一些特征。首先就是开局的无限debugger,然后4代的话请求是两次,一次的话是一个202状态码!在返回HTMl内容中包含动态加载的meta标签包含content跟script标签,如下图所示:
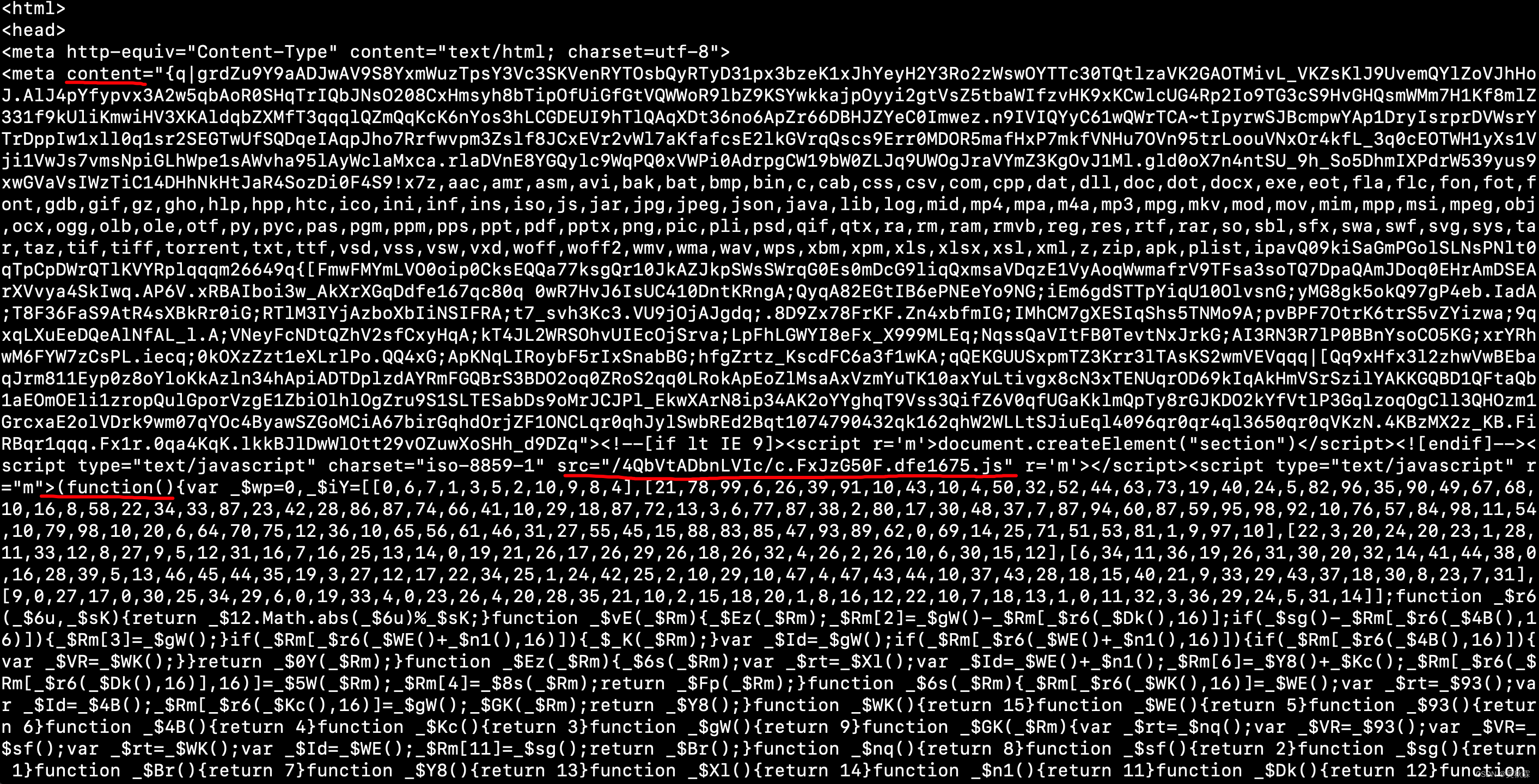
可以看到有一个外链的JS地址,_ts=window[…]可以直接请求获取JS代码,如下所示:

3. 接口分析
第一次请求页面我们可以监测一下,FSSBB…就是JS代码生成的Cookie,开头的数字表示它是瑞数几,如下所示:

这里我们可以直接在浏览器Curl请求出来,进行一下重放请求验证。如下所示:
标准的202,其实到这一步我们现在需要解决的一个问题就是过瑞数的反爬虫防护,让我们的请求能够正常的拿到页面的响应信息
3. 补JS环境
既然是使用补环境的框架(开源的rs框架很多,大家可以自行去查找测试),环境相关的东西基本都是借助Proxy模式让它自吐出来!
有时候使用框架并页不一定就好使,可能拿到的结果会跟你浏览器的不一样,这个时候就需要再回过头去分析JS,将框架监测到的环境尽可能跟浏览的一致!
这个地方还会有很多的细节坑,也是很多初学者或者rs新手经常补不出来的一个原因!JS的检测点很多,多次补的结果都跟浏览器的不一样,那就需要继续去分析,肯定是JS中没有补到或者监测到的环境
这里的补环境的JS源码很长。文章内作者不对其进行贴出,有需要的小伙伴可以找作者获取学习
这里我们直接运行补环境的框架,检测对象并进行自动代理。然后打印可以看到所有对象的属性信息,如下所示:

这里我们先使用Python来构造请求,将开始分析得到的content跟自执行JS提取出来(需要放到补出来的JS中执行调用),代码实现如下:
import requests
import re
import logging
logger = logging.getLogger(__name__)
class WebScraper:
def __init__(self, head_url, headers):
self.head_url = ""
self.headers = headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "" # 自行获取
}
def fetch_page(self):
response = requests.get(self.head_url, headers=self.headers, verify=False)
logger.info(f"请求响应状态: {response.status_code}")
meta_content_match = re.search(r'<meta content="(.*?)">', response.text)
js_code_match = re.search(r'r="m">(.*?)</s', response.text)
if not meta_content_match or not js_code_match:
logger.error("未能找到所需的meta内容或JavaScript代码")
return None
meta_content = meta_content_match.group(1)
js_code = js_code_match.group(1)
logger.info(f"获取meta_content: {meta_content}")
logger.info(f"获取自执行JS: {js_code}")
运行上面的程序,在第一次请求响应失败时,提取信息,运行效果如下所示:

将第一次请求提取到的信息塞到补环境的JS中,全局导出后可直接拿最到新的Cookie信息,如下所示:

拿到生成的Cookie信息携带发送新的请求,可以看到上图已成功过了瑞数反爬。请求状态码已是200,成功拿到了页面信息
4. 补后缀参数
绕过瑞数反爬虫后,我们需要处理的另一个问题则是后缀!拿接口数据,参数是有加密的,也就是后缀的那个MmEwMD,如下所示:

这个参数的还原其实有多种方案,第一个就是分析JS对其进行算法还原。有一定的难度!第二个则比较简单,直接在补环境的基础之上,对XMLHttpRequest对象的open方法进行修改并对其进行拦截,以此获取到完整的URL(含后缀)
重写open方法的这种方案目前看是比较常见的,针对部分瑞数的反爬虫场景,至少作者在开源社区看到了多种此类的方案
(function() {
// 保存原始的open方法
var originalOpen = XMLHttpRequest.prototype.open;
// 创建一个变量来保存URL
var lastURL;
// 重写open方法
XMLHttpRequest.prototype.open = function(method, url, async, user, password) {
// 记录URL
lastURL = url;
// 调用原始的open方法
return originalOpen.apply(this, arguments);
};
// 提供一个函数来获取记录的URL
window.getLastRequestURL = function() {
return lastURL;
};
})();
作者给出了一个示例,通过这个例子我们可以拦截到XMLHttpRequest对象的open方法,以此来记录传入的URL,并通过getLastRequestURL拿到完整的URL,使用示例如下所示:
// 创建一个XMLHttpRequest对象并调用open方法
var xhr = new XMLHttpRequest();
xhr.open("GET", "http://www.xxx.com.cn/service/xxx/xxx.actionId", true);
// 获取最后一次请求的URL
console.log(getLastRequestURL());
最终作者对整个网站的请求进行了一个封装,测试了一下完整的流程,如下所示:

成功拿到后缀参数并提交接口获取到结构化数据,我们可以在此框架的基础去拓展,让其可以适用与所有瑞数的环境场景