简介
本篇主要是使用jmx配合Prometheus监控大数据平台
前提
链接:https://pan.baidu.com/s/1c6nsjOKw4-a_Wqr82l0QhQ
提取码:yyds
--来自百度网盘超级会员V5的分享
先安装好Prometheus
Flink(Pometheus监控)_顶尖高手养成计划的博客-CSDN博客_${env:max_log_file_number:-10} 
prometheus.service启动、停止、重启、自启动
vi /usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
Group=root
WorkingDirectory=/opt/prometheus-2.28.0
ExecStart=/opt/prometheus-2.28.0/prometheus \
--web.listen-address=localhost:9090 \
--storage.tsdb.path="/mnt/data/prometheus" \
--config.file=prometheus.yml
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动的时候要开启相关配置才行
nohup ./prometheus --web.enable-lifecycle &
优雅关闭
curl -X POST http://localhost:9090/-/quit优雅重启
curl -XPOST http://localhost:9090/-/reload
window和linux的\n问题
sudo yum install dos2unix
dos2unix prometheus.ymlHadoop3.x监控
Hadoop配置
由于我的集群规划
| master | datanode,nodemanager,namenode |
| node1 | datanode,nodemanager,resourcemanager |
| node2 | datanode,nodemanager,secondnamenode,historyserver |
jmx_exporter Github地址 包含下载链接和使用说明。
我们可以看到jmx的使用方法是以java agent的形式启动,会开启一个端口供Prometheus拉数:
java -javaagent:./jmx_prometheus_javaagent-0.13.0.jar=8080:config.yaml -jar yourJar.jar
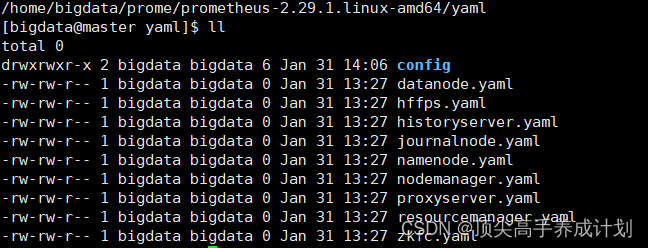
1.上传jar
2.创建prometheus文件夹
创建组件配置文件
启动jmx_exporter的时候需要指定配置文件,配置文件可以为空,但不能没有。为每个组件创建一下配置文件,暂时设置为空就好:
mkdir /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml
cd /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml
touch namenode.yaml
touch datanode.yaml
touch resourcemanager.yaml
touch nodemanager.yaml
touch journalnode.yaml
touch zkfc.yaml
touch hffps.yaml
touch proxyserver.yaml
touch historyserver.yaml
3.修改hadoop配置文件
cd /home/bigdata/hadoop/hadoop/etc/hadoop
vi hadoop-env.shexport HDFS_NAMENODE_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30002:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/namenode.yaml $HDFS_NAMENODE_OPTS"
export HDFS_DATANODE_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30003:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/datanode.yaml $HDFS_DATANODE_OPTS"
export YARN_RESOURCEMANAGER_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30004:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/resourcemanager.yaml $YARN_RESOURCEMANAGER_OPTS"
export YARN_NODEMANAGER_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30005:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/nodemanager.yaml $YARN_NODEMANAGER_OPTS"
export HDFS_JOURNALNODE_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30006:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/journalnode.yaml $HDFS_JOURNALNODE_OPTS"
export HDFS_ZKFC_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30007:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/zkfc.yaml $HDFS_ZKFC_OPTS"
export HDFS_HTTPFS_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30008:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/httpfs.yaml $HDFS_HTTPFS_OPTS"
export YARN_PROXYSERVER_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30009:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/proxyserver.yaml $YARN_PROXYSERVER_OPTS"
export MAPRED_HISTORYSERVER_OPTS="-javaagent:/home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar=30010:/home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/historyserver.yaml $MAPRED_HISTORYSERVER_OPTS"./xsync /home/bigdata/hadoop/hadoop/etc/hadoop/hadoop-env.sh
./xsync /home/bigdata/hadoop/hadoop/jmx_prometheus_javaagent-0.16.1.jar
./xsync /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml重启以后查看对应的服务是否开启
netstat -tulnp | grep 300master(namenode,datanode,nodemanage)

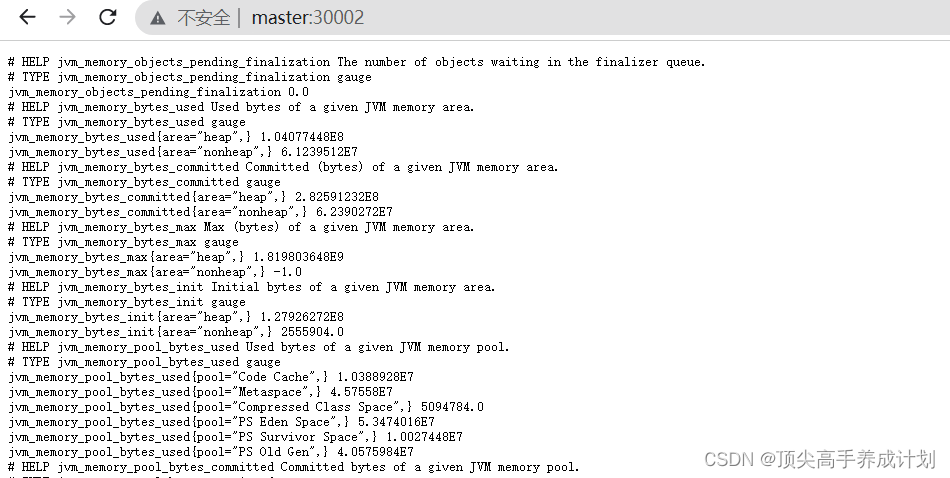 node1(resourcemanage,datanode,nodemanage)
node1(resourcemanage,datanode,nodemanage)

node2(datanode,nodemanager,historyserver)

这里每一个组件仅有一行配置。配置完后记得分发、保存和重启集群。
如果你搜索了其他攻略,会发现有些攻略中配置了很多其他东西,包括JMX相关的配置项、修改启动文件等等。
从个人角度来讲,我不太喜欢这样直接修改组件本身的操作。优秀的项目往往会充分地留有入口让我们传入一些自定义配置。
拿我们一句组件启动命令为例:
$HADOOP_HOME/bin/hdfs --daemon start namenode这句命令 hdfs 为 command, namenode为subcommand。因此想要对namenode组件传入配置参数则需要配置HDFS_NAMENODE_OPTS这一属性。
相关的说明在 yarn-env.sh,hdfs-env.sh,mapred-env.sh这几个环境配置脚本文件中也有说明。上述配置也可以对应command名称分别写入这几个脚本文件,它们的优先级会高于hadoop-env.sh
Prometheus 配置
采取引用外部配置文件的模式,具有更好的结构性和易管理性,当组件节点发生变动,我们只需修改json文件,不需要重启prometheus。
在prometheus根目录下新建yaml/configs目录,并新建文件 组件名.json
[
{
"targets": ["ip1:port","ip2:port","ip3:port"]
}
] 
vi namenode.json
[
{
"targets": ["master:30002"]
}
]
vi datanode.json
[
{
"targets": ["master:30003","node1:30003","node2:30003"]
}
]
vi resourcemanager.json
[
{
"targets": ["node1:30004"]
}
]
vi nodemanager.json
[
{
"targets": ["master:30005","node1:30005","node2:30005"]
}
]
vi journalnode.json
[
{
"targets": ["master:30006"]
}
]
vi zkfc.json
[
{
"targets": ["master:30007"]
}
]
vi httpfs.json
[
{
"targets": ["master:30008"]
}
]
vi proxyserver.json
[
{
"targets": ["master:30009"]
}
]
vi historyserver.json
[
{
"targets": ["node2:30010"]
}
]
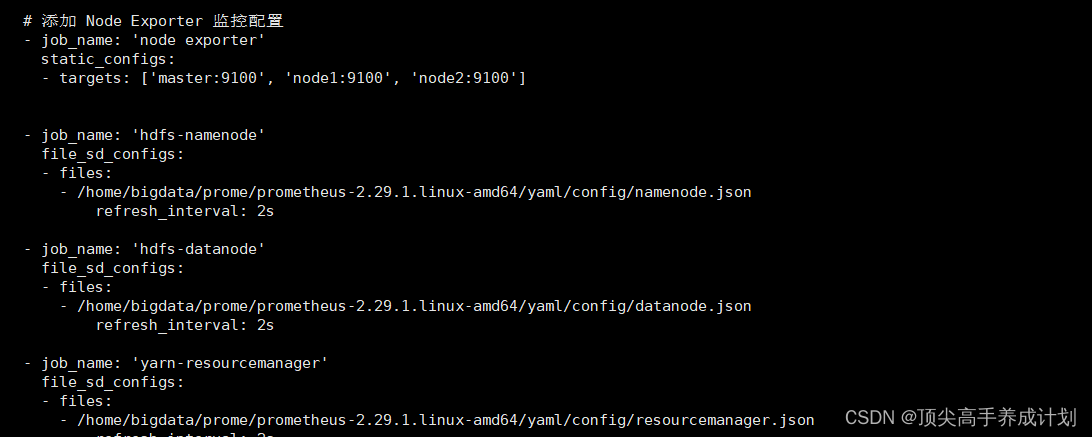
修改配置文件prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['master:9090']
# 添加 PushGateway 监控配置
- job_name: 'pushgateway'
static_configs:
- targets: ['master:9091']
labels:
instance: pushgateway
# 添加 Node Exporter 监控配置
- job_name: 'node exporter'
static_configs:
- targets: ['master:9100', 'node1:9100', 'node2:9100']
- job_name: 'hdfs-namenode'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/namenode.json
refresh_interval: 2s
- job_name: 'hdfs-datanode'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/datanode.json
refresh_interval: 2s
- job_name: 'yarn-resourcemanager'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/resourcemanager.json
refresh_interval: 2s
- job_name: 'yarn-nodemanager'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/nodemanager.json
refresh_interval: 2s
- job_name: 'hdfs-journalnode'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/journalnode.json
refresh_interval: 2s
- job_name: 'hdfs-zkfc'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/zkfc.json
refresh_interval: 2s
- job_name: 'hdfs-httpfs'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/httpfs.json
refresh_interval: 2s
- job_name: 'yarn-proxyserver'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/proxyserver.json
refresh_interval: 2s
- job_name: 'mapred-historyserver'
file_sd_configs:
- files:
- /home/bigdata/prome/prometheus-2.29.1.linux-amd64/yaml/config/historyserver.json
refresh_interval: 2s
监控展示
Prometheus+grafana的安装配置和使用可参考
https://www.yuque.com/u552836/hu5de3/mvhz9a
启动 prometheus
nohup ./prometheus --web.enable-lifecycle --config.file=prometheus.yml > ./prometheus.log 2>&1 &
启动 grafana
nohup bin/grafana-server & 接下来就是漫长的制作面板的过程了。。。
社区也貌似没有太多好面板模版,之后可能我会更新一些模版贴出来
Hadoop高可用版
vi namenode.json
[
{
"targets": ["master1:30002","master2:30002"]
}
]
vi datanode.json
[
{
"targets": ["node1:30003","node2:30003","node3:30003"]
}
]
vi resourcemanager.json
[
{
"targets": ["master1:30004","master2:30004"]
}
]
vi nodemanager.json
[
{
"targets": ["node1:30005","node2:30005","node3:30005"]
}
]
vi journalnode.json
[
{
"targets": ["node1:30006","node2:30006","node3:30006"]
}
]
vi zkfc.json
[
{
"targets": ["maste1:30007","maste2:30007"]
}
]
vi httpfs.json
[
{
"targets": ["master1:30008"]
}
]
vi proxyserver.json
[
{
"targets": ["master1:30009"]
}
]
vi historyserver.json
[
{
"targets": ["master1:30010"]
}
]