Seq2Seq model
Seq2Seq(Sequence to Sequence)模型是一类用于将一个序列转换为另一个序列的深度学习模型,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本摘要、对话生成等。Seq2Seq模型由编码器(Encoder)和解码器(Decoder)两部分组成。
Seq2Seq模型的基本原理

编码器(Encoder)
编码器负责接收输入序列并将其转换为一个固定长度的上下文向量(Context Vector)。这个过程通常使用循环神经网络(RNN)、长短期记忆网络(LSTM)或门控循环单元(GRU)来实现。
编码器的工作流程如下:
- 输入序列中的每个词被转换为词向量。
- 这些词向量依次输入到RNN/LSTM/GRU中,生成一系列的隐藏状态(Hidden States)。
- 最后一个隐藏状态被视为输入序列的上下文向量,包含了输入序列的全部信息。
解码器(Decoder)
解码器接收上下文向量并生成目标序列。解码器同样通常使用RNN、LSTM或GRU来实现。
解码器的工作流程如下:
- 上下文向量作为初始输入,结合解码器的初始隐藏状态,开始生成序列。
- 解码器在每一步生成一个输出词,并将该词输入到下一步的解码器中。
- 这个过程一直持续到生成特殊的结束标志(End Token)或达到最大序列长度。
Seq2Seq模型的结构
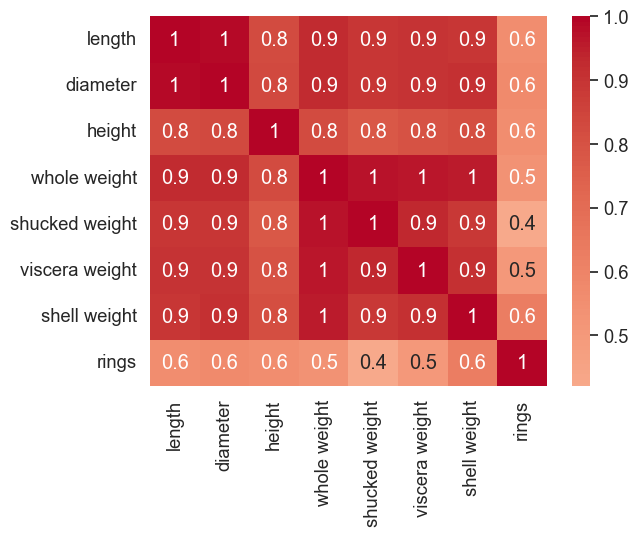
Seq2Seq模型的整体结构如下图所示:
输入序列: X = [x1, x2, x3, ..., xT]
编码器: h1, h2, h3, ..., hT = Encoder(X)
上下文向量: C = hT
解码器: Y = Decoder(C) = [y1, y2, y3, ..., yT']
输出序列: Y = [y1, y2, y3, ..., yT']Attention机制
尽管基本的Seq2Seq模型可以处理许多任务,但在处理长序列时可能会出现性能下降的问题。为了克服这一问题,引入了注意力机制(Attention Mechanism)。注意力机制允许解码器在生成每个输出词时,不仅仅依赖于上下文向量,还可以直接访问编码器的所有隐藏状态。
注意力机制的主要思想是计算每个编码器隐藏状态对当前解码器生成词的“注意力权重”(Attention Weight),然后通过加权求和得到一个动态的上下文向量。
Seq2Seq模型的应用
机器翻译
Seq2Seq模型可以将一个语言的句子转换为另一种语言的句子。编码器将源语言句子编码为上下文向量,解码器将上下文向量解码为目标语言句子。
文本摘要
Seq2Seq模型可以生成输入文本的简短摘要。编码器对输入文本进行编码,解码器生成一个较短的摘要。
对话生成
Seq2Seq模型可以生成对话响应。编码器对输入的对话上下文进行编码,解码器生成合适的响应。
语音识别
Seq2Seq模型可以将语音信号转换为文本。编码器将语音信号的特征提取为上下文向量,解码器生成相应的文本。
实现Seq2Seq模型的框架
TensorFlow
使用TensorFlow实现Seq2Seq模型可以利用其强大的API和工具。以下是一个简单的Seq2Seq模型的示例代码:
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Dense
from tensorflow.keras.models import Model
# 假设输入序列和输出序列的最大长度为max_len
max_len = 100
input_dim = 50 # 输入序列的维度
output_dim = 50 # 输出序列的维度
# 编码器
encoder_inputs = Input(shape=(max_len, input_dim))
encoder_lstm = LSTM(256, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(encoder_inputs)
encoder_states = [state_h, state_c]
# 解码器
decoder_inputs = Input(shape=(max_len, output_dim))
decoder_lstm = LSTM(256, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(output_dim, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Seq2Seq模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='adam', loss='categorical_crossentropy')
# 模型训练
# model.fit([encoder_input_data, decoder_input_data], decoder_target_data, epochs=50)PyTorch
使用PyTorch实现Seq2Seq模型可以利用其灵活的动态计算图和易于调试的特性。以下是一个简单的Seq2Seq模型的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(Encoder, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim)
def forward(self, x):
outputs, (hidden, cell) = self.lstm(x)
return hidden, cell
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim):
super(Decoder, self).__init__()
self.lstm = nn.LSTM(output_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x, hidden, cell):
outputs, (hidden, cell) = self.lstm(x, (hidden, cell))
predictions = self.fc(outputs)
return predictions, hidden, cell
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src, trg, teacher_forcing_ratio=0.5):
hidden, cell = self.encoder(src)
outputs = []
input = trg[0, :]
for t in range(1, trg.size(0)):
output, hidden, cell = self.decoder(input.unsqueeze(0), hidden, cell)
outputs.append(output)
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
input = trg[t] if teacher_force else output
return torch.cat(outputs, dim=0)
# 假设输入序列和输出序列的维度为input_dim和output_dim
input_dim = 50
output_dim = 50
hidden_dim = 256
encoder = Encoder(input_dim, hidden_dim)
decoder = Decoder(output_dim, hidden_dim)
model = Seq2Seq(encoder, decoder)
# 优化器和损失函数
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
# 模型训练
# for epoch in range(num_epochs):
# for src, trg in data_loader:
# optimizer.zero_grad()
# output = model(src, trg)
# loss = criterion(output, trg)
# loss.backward()
# optimizer.step()总结
Seq2Seq模型是将一个序列转换为另一个序列的强大工具,广泛应用于各种自然语言处理任务。通过编码器和解码器的组合,Seq2Seq模型能够处理复杂的序列到序列转换任务。引入注意力机制进一步提升了Seq2Seq模型的性能,使其在长序列处理和各种实际应用中表现出色。使用TensorFlow和PyTorch等框架可以方便地实现和训练Seq2Seq模型,为各种实际任务提供解决方案。