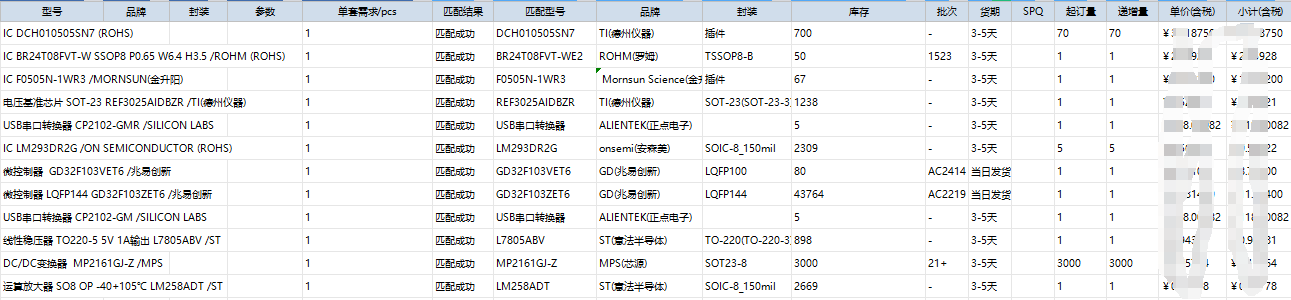
概述
这节课的作用:


本节课大纲如下:

Motivating examples
先回顾一下 mean estimation :

为什么总数反复提到这个 mean estimation,就是因为 RL 当中有非常多的 expectation,后面就会知道除了 state value 这些定义之外,还有很多类似的我们都得使用数据去进行估计。
那么如何计算平均值呢?除了上图中的方法,实际上我们还有另外一种:

这第二种方式被称为增量式的或者说是迭代式的方法,基本的思路就是来几个我就先计算几个,这样的效率会更高。
如何做?推导过程如下:

而推导完的最后的式子就是一个迭代式的算法,比如说在上个时刻我已经计算出 wk 了,那么这个时刻我就得到一个新的采样 xk,那我就直接通过这个式子我就可以得到新的 wk+1 。
这样就不需要像之前一样把前面所有的 xi 全部加起来然后再求平均,也就克服了之前那种计算方式的缺陷。

关于这个算法的一些注意点:

这个算法还可以进行进一步的推广:

实际上,当这个 αk 满足一些条件的时候,它虽然不是 1/k 的形式,但它依然可以让 wk 逐渐逼近期望 E[X],后面会再详述。
可以看出,这个算法实际上就是一种特殊的随机近似算法,其也是一种特殊的随机梯度下降的算法。
Robbins-Monro algorithm
这是随机近似理论当中一个非常经典的算法。



可以看到,如果 g(w) 的表达式都不知道是什么,该怎么进行求解?
这很像我们学深度学习时候的神经网络的概念,只给输入然后就能得到输出,却不知道中间过程,而这可以通过 Robbins-Monro 算法来解决。
Algorithm description

RM算法首先是一个迭代式的算法,首先要明确我们的目标是求解 g(w)=0,然后这里面假设最优解是 w*,这个迭代式的算法是 我对 w* 第 k 次的估计是 wk,然后第 k+1 次估计是 w(k+1),w(k+1) 等于 wk 减去后面那个式子。后面这个又进一步分为两个部分,第一个是 ak,ak 是一个系数,第二个是 g~(wk, ηk),其是一个函数,该函数表达式也很简单,就是 g(wk) 加上一个 ηk,ηk 是一个噪音。所以 g~ 是 g 的一个观测,但是是带有噪音的这样一个观测。
在这个算法当中我们实际上是将函数 g(w) 给作为了一个黑盒,我们不知道其表达式是什么,因此该算法依赖的是数据。
相当于有一个黑盒 g(w),我们输入 w,然后其会有一个 y 输出,但是这个 y 不能直接测量还需要加上一个噪音,噪音我们也不知道但是我们此时就能得到一个测量值 g~,输入一个 w 就能得到一个 g~:

因此这样反复输入输出之后,我们会得到一个 wk 的序列和一个 g~k 的序列,RM 算法就是通过这样一种方式来进行求解的。
Convergence analysis
分析其为什么可以找到解呢?



下面是数学上的证明:






Application to mean estimation


Stochastic gradient descent



Examples and application
介绍几个例子:


Convergence analysis
分析一下 SGD 为什么是有效的,也就是为什么是收敛的:




Convergence pattern
继续分析,分析它在收敛过程当中的一些非常有意思的行为:





A deterministic formulation



BGD, MBGD, and SGD


下面使用一些例子来例证刚刚的这三种算法:



Summary

从上图以及之前的学习内容可以总结如下:
我们首先是介绍了 mean estimation 这样一个问题,什么问题?就是我要用一组数来求它的 expectation。在之前其实我们就简单地把这一组数求平均,然后就可以来近似估计它的 expectation,但现在我们就知道了我们其实可以用迭代的方式(就是上图第一条表达式)进行计算,也就是当得到一个采样就计算一次,这样就不需要等到所有的采样全部拿到了我们再计算,会更加地高效。
然后介绍了非常经典的 SA 领域当中的 RM 的算法,这个算法解决了什么问题呢?就是我有一个方程 g(w) = 0,我要求解它的最优解 w*,但是我不知道 g(w) 的表达式,我知道的是什么呢?我知道给我一个 w,我能测出来它的输出,而且这个输出是有噪音或者是有误差的,这个输出用 g~ 来表示,所以这个 RM 算法就是我怎么样用这样的含有噪音的测量来估计这个 w*。
最后介绍了 SGD 这样的算法,求解了什么问题呢?就是我有一个目标函数,长 J(w) = E[f(wk, xk)] 这个样子,然后我可以知道它的梯度的一个采样,然后我们就可以用这个 stochastic 的 gradient,然后用这个算法(上图第三条表达式)让最后这个 wk 趋于最优值 w*。