场景:
已知广告点击数据的记录已经存在,数据统计在mongodb中,现在要统计广告列表pv和uv。
思路:
这个时候就想到mysql的聚合查询group、count、distinct,但是于是就找了好多文档,发现mongodb的语法和mysql还不一样,但是思路是一样的,于是各种搜索总结下来
关键代码
db.xxw_link_log.aggregate([
{
$match: {
brand: 'test',
_day_key: '20220211'
}
},
{
$group: {
"_id": {
"link_id": "$link_id",
"alipay_id": "$alipay_id",
},
}
},
{
$group: {
"_id": "$_id.link_id",
"distinctV": {
"$addToSet": {
"value": "$_id.alipay_id",
"numberOfValues": "$count"
}
},
count: {
$sum: 1
}
}
},
{
"$project": {
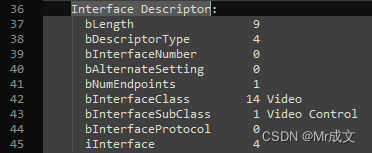
"_id": 0,
"link_id": "$_id",
"distinctV": 1,
"count": 1
}
}
])
返回结果如下

集合 “distinctV” 数据如下
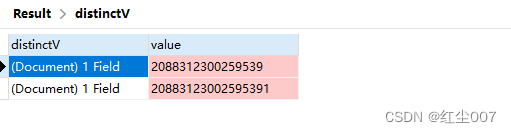
解释
mongodb 中的 aggregate 代表聚合工具之一
常用操作
| 表达式 | 描述 |
|---|---|
| $match | 用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。 |
| $project | 修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。 |
| $limit | 用来限制MongoDB聚合管道返回的文档数。 |
| $skip | 在聚合管道中跳过指定数量的文档,并返回余下的文档。 |
| $unwind | 将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。 |
| $group | 将集合中的文档分组,可用于统计结果。 |
| $sort | 将输入文档排序后输出。 |
| $lookup | 联表查询 |
| $geoNear | 输出接近某一地理位置的有序文档。 |
| facet/bucket | 分类搜索(MongoDB 3.4以上支持) |
未完待续
参考文档:
MongoDB聚合(aggregate)常用操作及示例
用 MongoDB 查询来选择 distinct 和 count?
mongoDB中聚合(aggregate)的具体使用
mongodb 高级聚合查询