深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
从RNN到Attention到Transformer系列
专栏链接:
https://blog.csdn.net/qq_39707285/category_11814303.html
此专栏主要介绍RNN、LSTM、Attention、Transformer及其代码实现。
YOLO系列目标检测算法
专栏链接:
https://blog.csdn.net/qq_39707285/category_12009356.html
此专栏详细介绍YOLO系列算法,包括官方的YOLOv1、YOLOv2、YOLOv3、YOLOv4、Scaled-YOLOv4、YOLOv7,和YOLOv5,以及美团的YOLOv6,还有PaddlePaddle的PP-YOLO、PP-YOLOv2等,还有YOLOR、YOLOX、YOLOS等。
Visual Transformer
专栏链接:
https://blog.csdn.net/qq_39707285/category_12184436.html
此专栏详细介绍各种Visual Transformer,包括应用到分类、检测和分割的多种算法。
本章目录
- 1. 简介
- 2. 模型
- 2.1 输入图片2D转1D
- 2.2 [class] token
- 2.3 位置嵌入
- 2.4 Inductive bias
- 2.5 Hybrid Architecture
- 3. 代码实现
- 3.1 定义参数
- 3.2 图片编码
- 3.3 加入class token
- 3.4 位置编码
- 3.5 Transformer
- 3.6 MLP层
- 3.7 总体代码
1. 简介
虽然Transformer架构已成为自然语言处理任务的基本标准,但其在计算机视觉中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。本文表明,这种对神经网络的依赖是不必要的,直接应用图像patch序列的纯Transformer可以很好地执行图像分类任务。当对大量数据进行预训练并将其迁移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB等)时,与最先进的卷积网络相比,Visual Transformer(ViT)获得了优异的结果,同时训练所需的计算资源大大减少。
2. 模型
模型总体图如下所示:
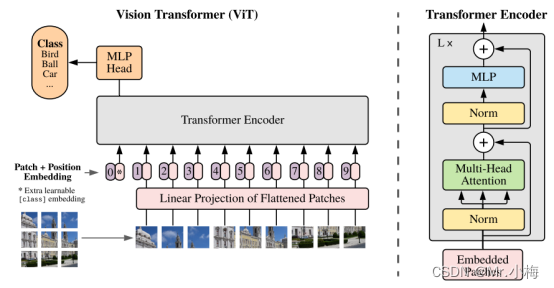
模型总体图。将图像分割成固定大小的patchs,线性嵌入每个patch,添加位置嵌入,并将生成的矢量序列提供给标准的Transformer编码器。为了进行分类,在序列中添加额外可学习的“分类标记class token”。
2.1 输入图片2D转1D
标准的Transformer输入的是1D的序列,为了处理2D的图片,把图片x-(H×W×C)reshape成一系列拉平的2D patchs x p s h a p e : ( N × ( P 2 ⋅ C ) ) x_p shape:(N×(P^2·C)) xpshape:(N×(P2⋅C)),其中 H 、 W H、W H、W是原始图片的高和宽, C C C是通道数, ( P , P ) (P,P) (P,P)是每一个图片patch的分辨率, N = H W / P 2 N=HW/P^2 N=HW/P2是最终的patchs的总数,也是Transformer输入序列的长度。Transformer在其所有层中使用固定大小的向量D,因此需要将patch拉平,并使用可训练的线性投影映射到D维度(公式1)。将此投影的输出称为patch embeddings(patch嵌入)。
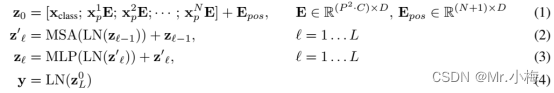
2.2 [class] token
和BERT的[class]token类似,在嵌入patch序列 ( z 0 0 = x c l a s s ) (z^0_0=x_{class}) (z00=xclass)中添加了一个可学习的嵌入,其在Transformer编码器输出端的状态 ( z L 0 ) (z^0_L) (zL0)用作图像的表示y(公式4)。在预训练和微调期间, z L 0 z^0_L zL0上都安装了一个分类头。分类头在预训练时由具有一个隐藏层的MLP实现,在微调时由单个线性层实现。
2.3 位置嵌入
位置嵌入被添加到patch嵌入以保留位置信息。本文使用标准的可学习1D位置嵌入,因为没有观察到使用更高级的2D感知位置嵌入带来的显著性能提高。添加后所得的嵌入向量序列用作编码器的输入。
Transformer编码器由multi-head self attention(MSA)和MLP块的交替组成。在每个块之前应用Layernorm(LN),在每个块之后应用残差连接。
2.4 Inductive bias
注意到,Vision Transformer比CNN具有更少的图像特定感应偏置。在神经网络中,整个模型的每个层的局部性、二维邻域结构和平移不变性都能体现。在ViT中,只有MLP层是局部的并且是平移不变的,而self-attention层是全局的。二维邻域结构的使用非常谨慎:在模型开始时,通过将图像切割成小块,并在微调时调整不同分辨率图像的位置嵌入。除此之外,初始化时的位置嵌入不携带关于patch的2D位置的信息,并且必须从头学习patch之间的所有空间关系。
2.5 Hybrid Architecture
作为原始图像patch的替代,输入序列可以由CNN的特征图形成。在该混合模型中,将patch嵌入投影E(公式1)应用于从CNN特征图提取的patch。作为一种特殊情况,patch可以具有空间大小1x1,这意味着通过简单地展平特征图的空间维度并投影到Transformer维度来获得输入序列。如上所述添加分类输入嵌入和位置嵌入。
3. 代码实现
3.1 定义参数
- 输入图片尺寸:image_size=256
- 每个patch尺寸:patch_size=16
- 输出分类总数:num_classes=1000
- 图片patch编码维度:dim=1024
- Transformer编码器深度:depth=6
- MAS head总数:heads=16
- MLP维度:mlp_dim=2048
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
...
3.2 图片编码
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64):
super().__init__()
...
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
...
def forward(self, img):
x = self.to_patch_embedding(img)
...
输入图片 s h a p e = ( B × C × H × W ) shape=(B×C×H×W) shape=(B×C×H×W),首先reshape成 ( B × ( h × w ) × ( p 1 × p 2 × C ) ) (B×(h×w)×(p_1×p_2×C)) (B×(h×w)×(p1×p2×C)),其中H、W是图片原始宽和高, p 1 、 p 2 p_1、p_2 p1、p2是图片patch的尺寸, h 、 w h、w h、w是图片patch的数量。然后使用线性层转换成指定维度。
3.3 加入class token
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64):
super().__init__()
...
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
...
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
...
首先把class tokens复制B份,B是batchsize。然后联结到patch序列前面。
3.4 位置编码
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64):
super().__init__()
...
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
...
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
...
3.5 Transformer
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64):
super().__init__()
...
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
...
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.transformer(x)
...
3.6 MLP层
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64):
super().__init__()
...
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
...
def forward(self, img):
...
x = self.transformer(x)
x = x[:, 0]
out = self.mlp_head(x)
return out
3.7 总体代码
代码下载地址:
https://download.csdn.net/download/qq_39707285/87405676