基础原理讲解
应用路径
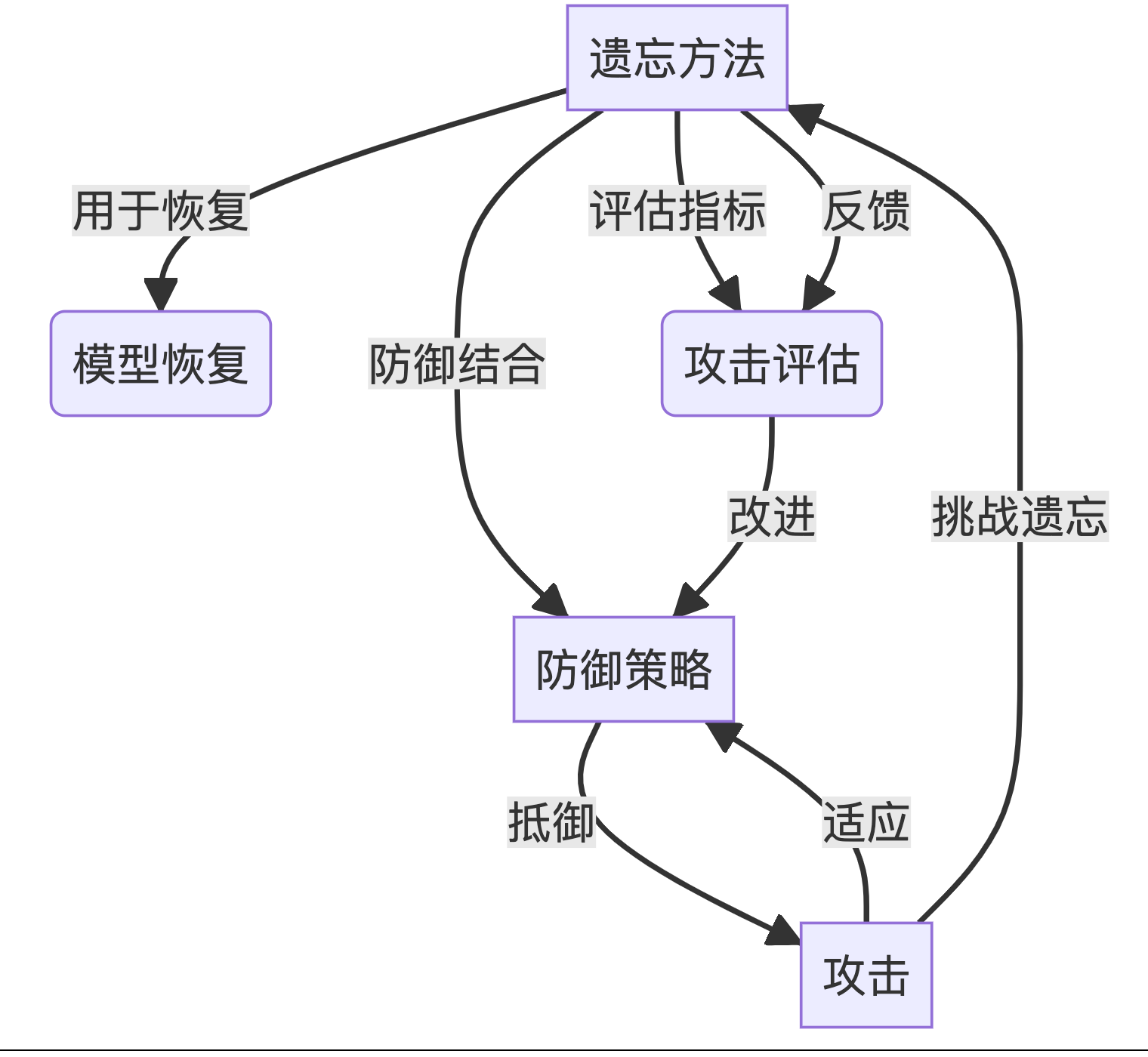
卷积网络最经典的就是CNN,其 可以提取图片中的有效信息,而生活中存在大量拓扑结构的数据。图卷积网络主要特点就是在于其输入数据是图结构数据,即 G ( V , E ) G(V,E) G(V,E),其中V是节点,E是边,能有效提取拓扑结构中的有效信息,实现节点分类,边预测等。
基础原理
其核心公式是:
H
(
l
+
1
)
=
σ
(
D
~
−
1
/
2
A
~
D
~
−
1
/
2
H
l
W
l
)
H^{(l+1)}=\sigma(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}H^{l}W^l)
H(l+1)=σ(D~−1/2A~D~−1/2HlWl)
其中:
- σ \sigma σ 是非线性激活函数
- D ~ \tilde{D} D~是度矩阵, D ~ i i = ∑ j A ~ i j \tilde{D}_{ii}=\sum_j\tilde{A}_{ij} D~ii=∑jA~ij
- A ~ \tilde{A} A~是加了自环的邻接矩阵,通常表示为 A + I A+I A+I, A A A是原始邻接矩阵, I I I是单位矩阵
- H l H^l Hl是第 l l l层的节点特征矩阵, H l + 1 H^{l+1} Hl+1是第 l + 1 l+1 l+1层的节点特征矩阵
- W l W^l Wl是第 l l l层的学习权重矩阵
步骤讲解:
1、邻接矩阵归一化: 将邻接矩阵归一化,使得邻居节点特征对中心节点特征的贡献相等。
2、特征聚合: 通过邻接矩阵与节点特征矩阵相乘,实现邻居特征聚合。
3、线性变换: 通过可学习的权重矩阵对聚合后的特征进行线性变换。
加自环的邻接矩阵
A
~
=
A
+
λ
I
\tilde{A} = A+\lambda I
A~=A+λI
邻接矩阵加上一个单位矩阵,
λ
\lambda
λ是一个可以训练的参数,但也可直接取1。加自环 是为了增强节点自我特征表示,这样在进行图卷积操作时,节点不仅会聚合来自邻居节点的特征,还会聚合自己的特征。
图卷积操作

图片的卷积是一个一个卷积核,在图片上滑动着做卷积。图的卷积就是自己加邻居一起做加和。
即:
A
~
X
\tilde{A}X
A~X
度矩阵求解
D
~
i
i
=
∑
j
A
~
i
j
\tilde{D}_{ii}=\sum_j\tilde{A}_{ij}
D~ii=j∑A~ij

标准化
在进行加和时,节点的度不同,有存在较高度值的节点和较低度值的节点,这可能导致梯度爆炸或梯度消失的问题。
根据度矩阵,求逆,然后
D
~
−
1
A
~
D
~
−
1
X
\tilde{D}^{-1}\tilde{A} \tilde{D}^{-1}X
D~−1A~D~−1X,就进行了标准化,前一个
D
~
−
1
\tilde{D}^{-1}
D~−1是对行进行标准化,后一个
D
~
−
1
\tilde{D}^{-1}
D~−1是对列进行标准化。能够实现给与低度节点更大的权重,从而降低高节点的影响。
在上式推导中,
D
~
−
1
A
~
D
~
−
1
X
\tilde{D}^{-1}\tilde{A} \tilde{D}^{-1}X
D~−1A~D~−1X 做了两次标准化,所以修改上式为
D
~
−
1
/
2
A
~
D
~
−
1
/
2
X
\tilde{D}^{-1/2}\tilde{A} \tilde{D}^{-1/2}X
D~−1/2A~D~−1/2X
简单python实现
基于cora数据集实现节点分类
- cora数据集处理
# cora数据集测试
raw_data = pd.read_csv('./data/data/cora/cora.content', sep='\t', header=None)
print("content shape: ", raw_data.shape)
raw_data_cites = pd.read_csv('./data/data/cora/cora.cites', sep='\t', header=None)
print("cites shape: ", raw_data_cites.shape)
features = raw_data.iloc[:,1:-1]
print("features shape: ", features.shape)
# one-hot encoding
labels = pd.get_dummies(raw_data[1434])
print("\n----head(3) one-hot label----")
print(labels.head(3))
l_ = np.array([0,1,2,3,4,5,6])
lab = []
for i in range(labels.shape[0]):
lab.append(l_[labels.loc[i,:].values.astype(bool)][0])
#构建邻接矩阵
num_nodes = raw_data.shape[0]
# 将节点重新编号为[0, 2707]
new_id = list(raw_data.index)
id = list(raw_data[0])
c = zip(id, new_id)
map = dict(c)
# 根据节点个数定义矩阵维度
matrix = np.zeros((num_nodes,num_nodes))
# 根据边构建矩阵
for i ,j in zip(raw_data_cites[0],raw_data_cites[1]):
x = map[i] ; y = map[j]
matrix[x][y] = matrix[y][x] = 1 # 无向图:有引用关系的样本点之间取1
# 查看邻接矩阵的元素
print(matrix.shape)
- GCN网络实现
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f'Using device: {device}')
class GCNLayer(nn.Module):
def __init__(self, in_features, out_features):
super(GCNLayer, self).__init__()
self.linear = nn.Linear(in_features, out_features)
def forward(self, x, adj):
rowsum = torch.sum(adj,dim=1)
d_inv_sqrt = torch.pow(rowsum,-0.5)
d_inv_sqrt[torch.isinf(d_inv_sqrt)] =0.0
d_mat_inv_sqrt = torch.diag(d_inv_sqrt)
adj_normalized = torch.mm(torch.mm(d_mat_inv_sqrt,adj),d_mat_inv_sqrt)
out = torch.mm(adj_normalized,x)
out = self.linear(out)
return out
class GCN(nn.Module):
def __init__(self, n_features, n_hidden, n_classes):
super(GCN, self).__init__()
self.gcn1 = GCNLayer(n_features, n_hidden)
self.gcn2 = GCNLayer(n_hidden, n_classes)
def forward(self, x, adj):
x = self.gcn1(x, adj)
x = F.relu(x)
x = self.gcn2(x, adj)
return x#F.log_softmax(x, dim=1)
# 示例数据(实际数据应根据具体情况加载)
features = torch.tensor(features.values, dtype=torch.float32)
adj = torch.tensor(matrix, dtype=torch.float32)
labels = torch.tensor(lab, dtype=torch.long)
# features = torch.tensor([[1, 0], [0, 1], [1, 1]], dtype=torch.float32)
# adj = torch.tensor([[1, 1, 0], [1, 1, 1], [0, 1, 1]], dtype=torch.float32)
# labels = torch.tensor([0, 1, 0], dtype=torch.long)
# 模型参数
n_features = features.shape[1]
n_hidden = 16
n_classes = len(torch.unique(labels))
# 创建模型
model = GCN(n_features, n_hidden, n_classes)
model = model.cuda()
optimizer = optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
# 训练模型
n_epochs = 200
for epoch in range(n_epochs):
model.train()
features, labels = features.cuda(), labels.cuda()
adj = adj.cuda()
optimizer.zero_grad()
output = model(features, adj)
loss = loss_fn(output, labels)
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
print("Training complete.")
参考
cora数据集及简介
图卷积网络详细介绍
GCN讲解