1 介绍
年份:2024
作者:刘子耀,陈晨,南洋理工大学
期刊: 未发表
引用量:6
Liu Z, Ye H, Chen C, et al. Threats, attacks, and defenses in machine unlearning: A survey[J]. arXiv preprint arXiv:2403.13682, 2024.
本文提出了一个统一的机器遗忘工作流程,并基于此框架和威胁模型,提出了机器遗忘系统中威胁、攻击和防御的新分类法。对当前机器非遗忘中的威胁、攻击和防御进行了详细分析,并阐述了遗忘方法、攻击和防御策略之间的复杂关系。
此外,讨论了机器遗忘系统中存在的漏洞,如信息泄露和恶意遗忘请求,这些导致重大的安全和隐私问题。遗忘方法和普遍的攻击在MU系统中扮演着不同的角色。例如,遗忘可以作为从后门攻击中恢复模型的机制,而后门攻击本身可以作为遗忘有效性的评估指标。这强调了这些机制在维护系统功能和安全方面的复杂关系和相互作用。
2 创新点
- 综合性调查:提供了对机器遗忘(MU)领域的综合性调查,尤其集中在MU系统中的安全威胁、攻击手段和防御策略上。
- 新的分类法:基于对现有研究的分析,提出了一个新的威胁、攻击和防御的分类法,这有助于更好地理解MU系统中的复杂关系和相互作用。
- 统一工作流程:提出了一个统一的机器遗忘工作流程,这有助于标准化MU系统的分析和讨论。
- 深入分析:对MU系统中的威胁、攻击和防御进行了深入的分析,包括信息泄露、恶意遗忘请求、以及其他潜在的漏洞,提供了对这些威胁的详细讨论和相应的防御策略。
- 防御机制的探讨:不仅讨论了如何防御攻击,还探讨了遗忘本身如何作为一种防御机制,例如通过遗忘来恢复被后门攻击影响的模型,以及实现与人类价值观和伦理标准一致的价值对齐。
- 攻击作为评估工具:创新性地提出使用攻击手段来评估遗忘的有效性,例如通过隐私泄露审计、模型鲁棒性评估和遗忘证明来加深对遗忘系统的理解并提高其有效性。
3 相关研究
3.1 相关概念
(1)Machine Unlearning Systems(机器遗忘系统)
- 系统结构:机器遗忘系统由服务器和多个参与者组成,服务器在系统中扮演关键角色,包括模型开发和基于输入提供服务。
- 角色分类:参与者分为数据贡献者(提供训练数据)、请求用户(提交遗忘请求)和可访问用户(使用服务进行推断)。
- 工作流程:机器遗忘系统的工作流程分为三个阶段:训练阶段(使用数据贡献者提供的数据训练ML模型)、遗忘阶段(服务器响应请求用户的遗忘请求,从模型知识库中移除特定数据点的影响)和后遗忘阶段(基于遗忘模型提供推断服务)。
- MLaaS集成:在机器学习即服务(MLaaS)的背景下,服务器同时接收遗忘和推断请求,这增加了管理不同类型请求的复杂性。
(2)Threats, Attacks, and Defenses in MU Systems(机器遗忘系统中的威胁、攻击和防御)
- 系统脆弱性:机器遗忘系统在各个阶段都存在脆弱性,受到攻击者的威胁。
- 信息泄露:在训练阶段,数据贡献者恶意构造训练数据,为后续攻击做准备;在遗忘阶段,请求用户提交恶意遗忘请求;在后遗忘阶段,参与者利用对训练和遗忘模型的双重访问来揭露额外的信息泄露。
- 攻击手段:基于上述威胁,攻击者可以执行各种攻击,例如数据投毒、利用模型推断服务来提取未遗忘数据的额外信息等。
- 防御策略:探讨了针对机器遗忘系统攻击的潜在防御方法,如进行成员检查以确保请求遗忘的数据真实存在于训练数据集中,实施差分隐私来防止成员推断攻击,以及通过模型监控在遗忘阶段有效识别潜在问题。
- 遗忘的双重角色:遗忘不仅可以作为从后门攻击中恢复模型的机制,而且后门攻击本身可以作为评估遗忘有效性的指标,揭示了这些元素在维护系统安全性和功能性方面的复杂相互作用。
3.2 机器遗忘中的威胁、攻击和防御的分类
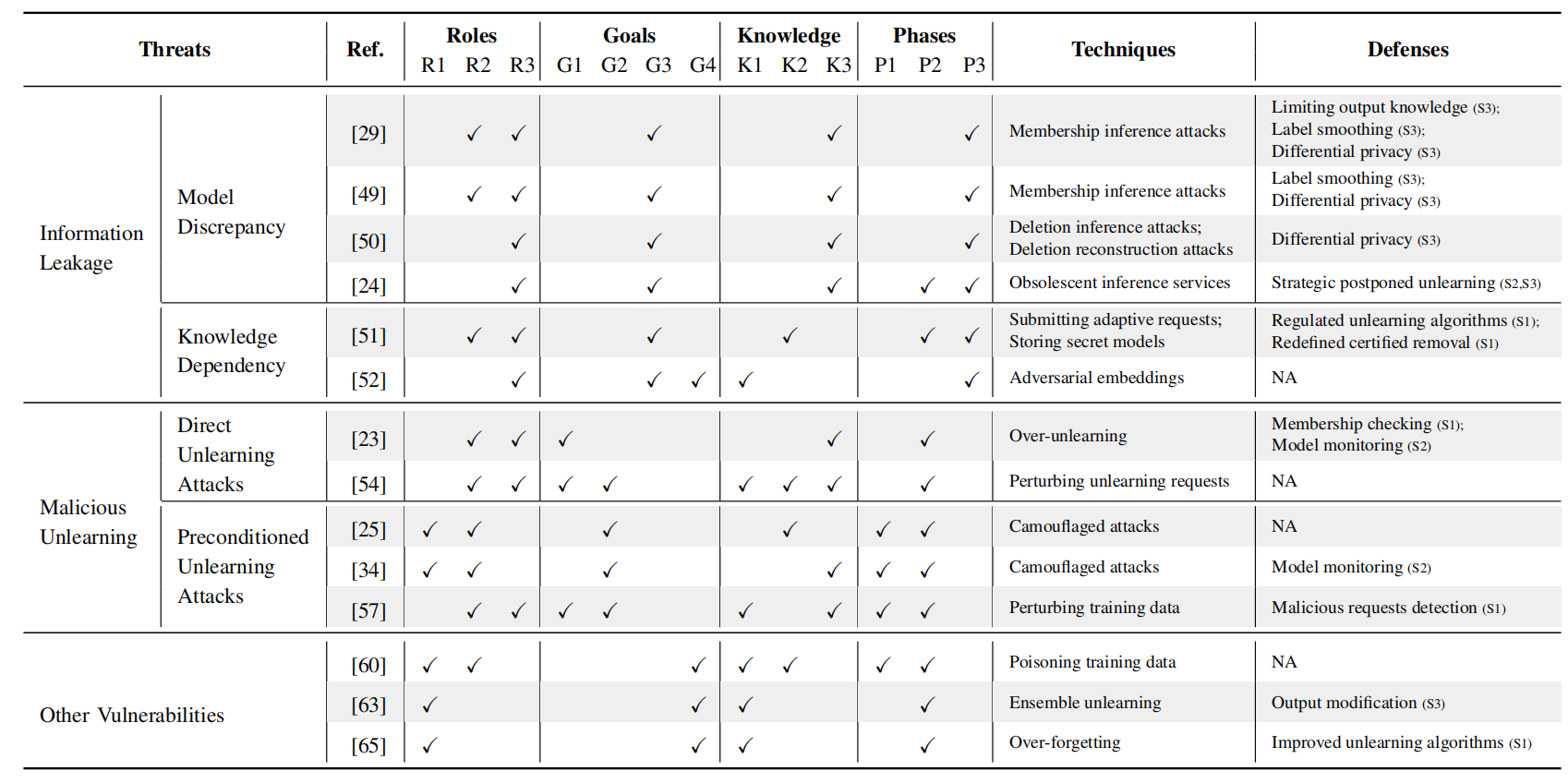
(1)威胁(Threats):指的是危害机器遗忘系统的安全和隐私的潜在风险。这些威胁源自系统内部的脆弱性或外部的恶意行为。威胁包括信息泄露(Information Leakage)和恶意遗忘(Malicious Unlearning)。
- 信息泄露(Information Leakage):未遗忘模型和遗忘模型之间的差异被用来推断敏感信息。
- 模型差异导致的泄露(Leakage from Model Discrepancy): 这种方式的信息泄露来自于训练模型和被遗忘模型之间的差异。攻击者可以利用这些差异来获取关于被遗忘数据的额外信息。具体手段可能包括:
- 成员资格推断攻击(Membership Inference Attacks):攻击者尝试确定特定的数据点是否属于被遗忘的数据,通过分析模型对数据点的响应差异。
- 数据重建攻击(Data Reconstruction Attacks):攻击者尝试根据模型的输出重建被遗忘的数据点。
- 恶意请求(Malicious Requests):恶意用户提交请求以破坏模型的安全性或性能。
- 知识依赖性导致的泄露(Leakage from Knowledge Dependency): 这种方式的信息泄露来自于模型与外部知识源之间的自然关系。这可能包括:
- 自适应请求(Adaptive Requests):连续的遗忘请求可能揭示关于其他数据点的信息,攻击者可以通过一系列请求来收集足够的知识,以确定特定数据的成员资格。
- 缓存的计算(Cached Computations):遗忘算法可能缓存部分计算以加快处理速度,这可能无意中泄露了跨多个版本中本应被删除的数据的信息。
- 模型差异导致的泄露(Leakage from Model Discrepancy): 这种方式的信息泄露来自于训练模型和被遗忘模型之间的差异。攻击者可以利用这些差异来获取关于被遗忘数据的额外信息。具体手段可能包括:
- 恶意遗忘(Malicious Unlearning)
- 直接遗忘攻击(Direct Unlearning Attacks): 这类攻击仅在遗忘阶段发生,不需要在训练阶段操纵训练数据。攻击者可能利用模型的推断服务来获取关于训练模型的知识,并使用对抗性扰动等方法来制定恶意遗忘请求。直接遗忘攻击可以是无目标的,旨在降低模型在遗忘后的整体性能,也可以是有目标的,目的是使遗忘模型对具有预定义特征的目标输入进行错误分类。
- 预条件遗忘攻击(Preconditioned Unlearning Attacks): 与直接遗忘攻击不同,预条件遗忘攻击采取更策略性的方法,在训练阶段操纵训练数据。这些攻击通常设计为执行更复杂和隐蔽的有目标攻击。预条件遗忘攻击通常通过以下步骤执行:
- 攻击者在干净数据集中插入有毒数据(Poisoned Data)和缓解数据(Mitigation Data),形成一个训练数据集。
- 服务器基于这个数据集训练机器学习模型并返回模型。
- 攻击者提交请求以遗忘缓解数据。
- 服务器执行遗忘过程并返回一个遗忘模型,该模型实际上对应于仅在有毒数据和干净数据上训练的模型。通过这种方式,遗忘过程中移除缓解数据后,模型就会对训练阶段插入的有毒数据变得脆弱。
- 其他漏洞(Other Vulnerabilities)
- “减速攻击”:一种旨在减慢遗忘过程的投毒攻击,通过策略性地在训练数据中制作有毒数据,最小化通过近似更新处理的遗忘请求的间隔或数量。
- 公平性影响:讨论了遗忘算法本身可能在特定领域应用中引入的副作用,例如在大型语言模型中影响公平性。
(2)攻击(Attacks):基于上述威胁,攻击者执行的具体行动。这些攻击发生在机器遗忘的任何阶段,包括:
- 训练阶段攻击(Training Phase Attacks):如数据投毒,攻击者在训练数据中注入恶意数据。
- 遗忘阶段攻击(Unlearning Phase Attacks):如提交设计精巧的请求以移除对模型性能至关重要的数据点。
- 后遗忘阶段攻击(Post-Unlearning Phase Attacks):利用对模型的双重访问来提取额外信息或发起更复杂的攻击。
(3)防御(Defenses):为了保护机器遗忘系统免受威胁和攻击,研究者和实践者开发了多种防御机制。这些防御包括:
- 预遗忘阶段(Pre-unlearning Stage):在遗忘过程开始之前检测恶意请求或制定遗忘规则。
- 遗忘阶段(In-unlearning Stage):监控模型变化,如果检测到异常则停止遗忘过程。
- 后遗忘阶段(Post-unlearning Stage):保护遗忘后模型的信息泄露,或恢复模型到攻击前的状态。
3.3 威胁模型
(1)攻击角色(Attack Roles)
数据贡献者 (R1):负责提供构建训练数据集的个体。
请求用户 (R2):有能力提交遗忘请求的个体。
可访问用户 (R3):能够使用模型服务进行推断的个体。攻击者在遗忘系统中可能承担多种攻击角色,例如请求用户通常也有权访问模型服务进行推断。
(2)攻击目标(Attack Goals)
无目标攻击 (G1):意图使遗忘模型产生错误预测,而不针对特定结果。
有目标攻击 (G2):旨在诱导遗忘模型产生错误预测或以特定预定方式行为。
隐私泄露 (G3):试图提取关于请求遗忘的额外信息。
其他 (G4):可能包括增加遗忘过程的计算成本、影响遗忘模型的公平性和效用等。
(3)对抗性知识(Adversarial Knowledge)
白盒 (K1):攻击者对模型架构、参数、训练和遗忘算法以及数据有全面了解。
灰盒 (K2):攻击者可以访问模型架构、参数、训练和遗忘算法或数据的部分元素,但并非全部。
黑盒 (K3):攻击者对模型一无所知,包括其架构和参数,无法访问或修改模型的训练过程。
(4)攻击阶段(Attack Phases)
训练阶段 (P1):作为数据贡献者的攻击者可能在训练阶段操纵或构造训练数据集,为后续阶段的攻击做准备。
遗忘阶段 (P2):攻击者可能提交恶意的遗忘请求来发起攻击,这些请求可能或可能不基于训练阶段的准备。
后遗忘阶段 (P3):攻击者可能利用遗忘模型以及在前几个阶段获得的信息发起攻击。
3.4 通过机器遗忘来加强防御机制
(1)模型恢复(Model Recovery)
模型恢复是指在检测到数据投毒攻击后,从受损的机器学习模型中恢复一个准确的模型的过程。机器遗忘在这一过程中扮演了关键角色,它允许针对性地移除被识别出的有毒数据:
- 后门移除:通过反转触发器来重新训练受感染的机器学习模型,或者通过梯度上升法来识别触发模式并执行遗忘。
- 模型剪枝:在执行遗忘之前先对模型进行剪枝,以简化模型并可能提高恢复过程的效率。
- 基于访问受限数据的恢复:即使只有有限的访问权限,也可以通过遗忘来恢复模型,这在实际应用中可能非常有用。
(2)价值对齐(Value Alignment)
价值对齐强调了将机器学习模型与人类价值观和伦理标准对齐的重要性,以确保AI系统的安全性和合规性:
- 属性遗忘:用于删除推荐系统中的敏感属性,以符合隐私合规性。
- 大型语言模型中的不当行为移除:使用相应的检测方法和遗忘技术来删除不当或非法的内容,包括质量差、受版权保护或有害的内容。
- 识别有害内容的数据集:通过遗忘每个数据集并评估遗忘后模型生成有害内容的影响,来识别对生成有害内容最有影响的训练数据集。
3.5 通过攻击手段来评估机器遗忘系统的有效性
(1)隐私泄露审计(Audit of Privacy Leakage)
- 目的:评估机器遗忘系统在遗忘过程中可能产生的隐私泄露。
- 方法:使用攻击手段,如推断攻击,来检测训练模型和遗忘模型之间的差异,或利用系统内部的漏洞来提取信息。
- 指标:采用诸如区域下曲线(AUC)和攻击成功率(ASR)等指标来量化隐私攻击的有效性,从而指示隐私泄露的程度。
(2)模型鲁棒性评估(Assessment of Model Robustness)
- 目的:通过恶意遗忘评估遗忘模型的鲁棒性,类似于对抗性攻击中使用的原则。
- 方法:提交被扰动的数据点进行遗忘,以改变分类器的决策边界,从而评估模型对边界附近数据点的敏感性和对挑战模型预测能力的点的影响。
- 技术:例如,在大型语言模型(LLMs)中,攻击者可能插入对抗性嵌入到提示的嵌入中,以提取模型中本应被遗忘的知识。
(3)遗忘证明(Proof of Unlearning)
- 目的:使用攻击手段来证明遗忘过程的有效性,即验证数据是否已被有效地从模型中移除。
- 方法:如果遗忘后的数据在模型中没有显示出成员资格,或者遗忘数据中的后门无法被检测到,则可以认为遗忘数据已以高概率从模型中有效移除。
- 应用:研究中使用了标准的推断攻击和后门攻击的变体,或其他对抗性攻击来检测遗忘程序的不足。
3.6 机器遗忘领域当前面临的挑战
(1)对抗恶意遗忘的防御( Defenses against Malicious Unlearning)
- 挑战:恶意遗忘请求可能对遗忘模型产生负面影响,包括降低模型性能或引入后门。
- 检测困难:直接恶意遗忘请求较易检测,但预条件恶意遗忘请求由于其数据实际属于训练数据集,因此难以识别。
- 未来方向:需要开发更强大的检测机制,以识别这些微妙且复杂的遗忘请求,保护机器遗忘系统的完整性。
(2)联邦遗忘(Federated Unlearning)
- 挑战:联邦学习的特性给机器遗忘带来了特定挑战,如通过聚合实现的知识扩散和为保护用户数据隐私而进行的数据隔离。
- 研究空白:联邦遗忘中的分布式攻击可能特别隐蔽且难以检测,这一领域目前研究较少,存在明显缺口。
- 未来方向:研究如何在不违反联邦学习隐私原则的前提下,开发符合RTBF合规要求的遗忘机制。
(3)隐私保护(Privacy Preservation)
- 挑战:现有机器遗忘系统假设待删除的数据对负责遗忘过程的服务器是可访问的,但在MLaaS环境中,模型开发者和服务提供商可能是不同的实体,这引发了隐私保护的问题。
- 技术应用:可以使用同态加密、安全多方计算或差分隐私等隐私增强技术(PETs)来促进隐私保护的机器学习。
- 未来方向:探索这些技术在机器遗忘中的权衡,特别是隐私保护、遗忘效率和模型性能之间的折衷。
(4)大型模型的遗忘(Unlearning over Large Models)
- 挑战:在大型模型上进行遗忘的研究面临效率低下、验证遗忘效果困难、大型模型的非解释性等问题。
- 研究需求:需要针对大型模型遗忘系统特有的威胁、攻击和防御进行更深入的研究。
- 未来方向:开发创新解决方案以提高大型模型遗忘的效率,并探索有效的遗忘验证方法。
4 思考
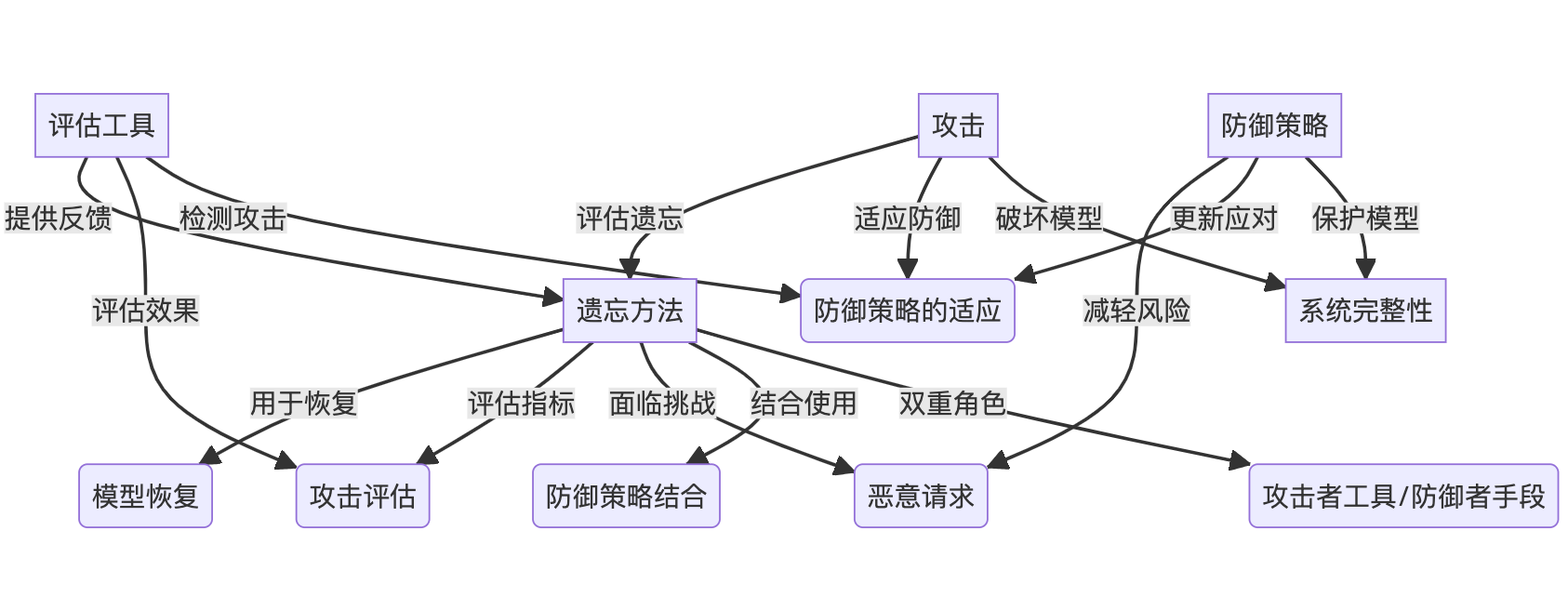
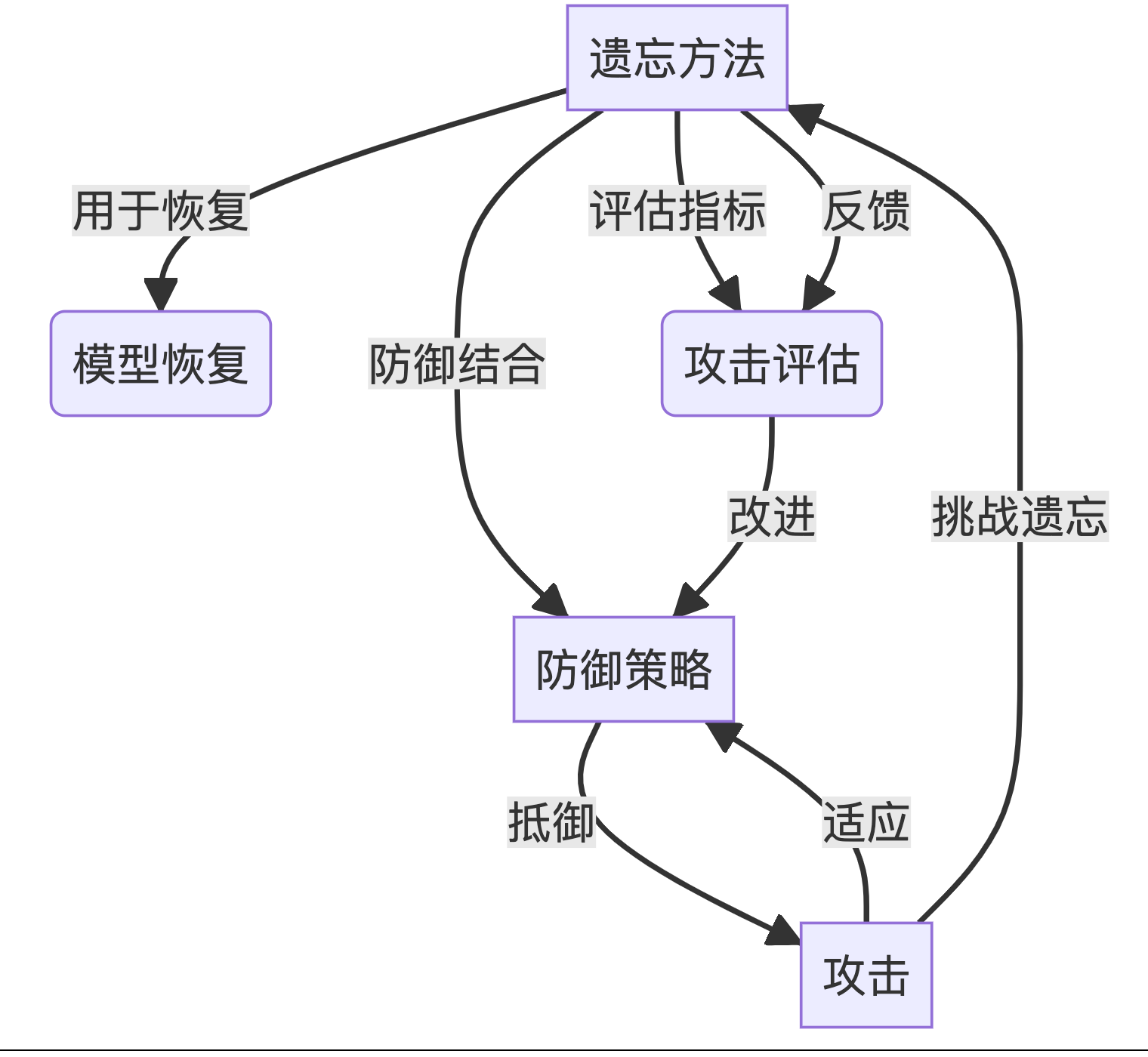
(1)遗忘方法、攻击和防御策略之间的关系是什么?
- 遗忘方法作为恢复机制:遗忘方法可以用于从后门攻击中恢复模型。通过有效地从模型中移除特定数据点,可以减少后门攻击的影响。
- 攻击作为评估指标:后门攻击和其他攻击手段可以作为评估遗忘方法有效性的指标。通过观察攻击在遗忘过程中的效果,可以评估遗忘方法的健壮性。
- 攻击对遗忘方法的挑战:恶意请求和信息泄露攻击对遗忘方法提出了挑战,要求遗忘方法不仅要有效地删除数据,还要抵御可能的攻击,确保数据的安全性和隐私性。
- 防御策略与遗忘方法的结合:防御策略可以与遗忘方法结合使用,以提高系统的安全性。例如,通过实施差分隐私或模型监控,可以在执行遗忘操作时保护模型不受攻击。
- 防御策略对攻击的缓解:防御策略如成员检查、数据扰动和访问控制等,旨在减轻由攻击引起的风险,包括恶意非学习和信息泄露。
- 攻击对防御策略的适应:攻击者可能会适应现有的防御策略,开发新的攻击手段来绕过或破坏防御。这要求防御策略不断更新以应对新的威胁。
- 遗忘方法的双重角色:遗忘方法既可以作为攻击者的工具,也可以作为防御者的手段。攻击者可能利用遗忘来破坏模型的完整性,而防御者可以使用遗忘来净化模型,消除不良影响。
- 评估工具的反馈循环:使用攻击作为评估工具可以提供对遗忘方法的反馈,帮助改进和加强防御策略,形成一个动态的反馈循环。
graph TD
A[遗忘方法] -->|用于恢复| B(模型恢复)
A -->|评估指标| C(攻击评估)
A -->|面临挑战| D(恶意请求)
A -->|结合使用| E(防御策略结合)
A -->|双重角色| F(攻击者工具/防御者手段)
G[攻击] -->|评估遗忘| A
G -->|适应防御| H(防御策略的适应)
G -->|破坏模型| I[系统完整性]
J[防御策略] -->|减轻风险| D
J -->|更新应对| H
J -->|保护模型| I
K[评估工具] -->|提供反馈| A
K -->|评估效果| C
K -->|检测攻击| H
graph TD
A[遗忘方法] -->|用于恢复| B(模型恢复)
A -->|评估指标| C(攻击评估)
A -->|防御结合| D[防御策略]
D -->|抵御| E[攻击]
E -->|适应| D
E -->|挑战遗忘| A
A -->|反馈| C
C -->|改进| D