在使用 Elasticsearch 时,频繁更新文档是一种常见误区。这不仅影响性能,还可能导致系统资源的浪费。
理解 Elasticsearch 的文档更新机制对于优化性能至关重要。
关于 Elasticsearch 更新操作,常见问题如下:

——https://t.zsxq.com/bDxwL
1、频繁更新的挑战
在关系型数据库中,更新操作在事务完成后立即生效,查询结果可以立刻反映变化。
而在 Elasticsearch 中,更新操作则依赖于刷新(refresh,如下图标红部分)过程。这增加了额外的开销,特别是在频繁更新的场景下。
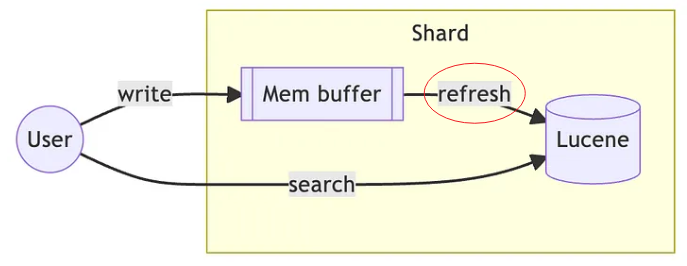
细节参见《一本书讲透Elasticsearch》第342-343页详细阐释。
2、文档更新的步骤
Elasticsearch 更新的本质可以分为以下几个步骤:

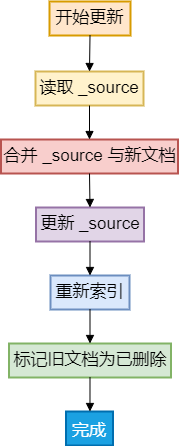
2.1 查找文档
首先,Elasticsearch 根据请求中的文档 ID 或查询条件,在索引中查找需要更新的文档。
2.2 读取并更新
找到文档后,Elasticsearch 会将文档加载到内存中,并根据请求中的更新内容修改文档数据。这包括字段的增加、修改或删除。
2.3 版本控制
Elasticsearch 使用版本号或乐观锁定机制,确保并发更新时数据的一致性。每次更新,版本号都会增加,以避免更新冲突。
示例:首次写入文档,version是 1。
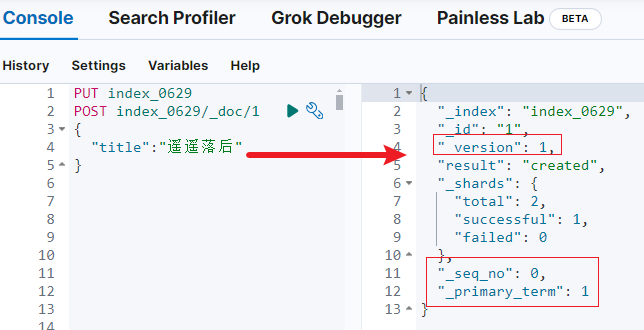
查看索引分段信息如下:
2.4 重新索引
修改后的文档并不会直接更新到原位置,而是作为一个新文档写入索引。这是因为 Elasticsearch 使用不可变的段文件来存储数据。
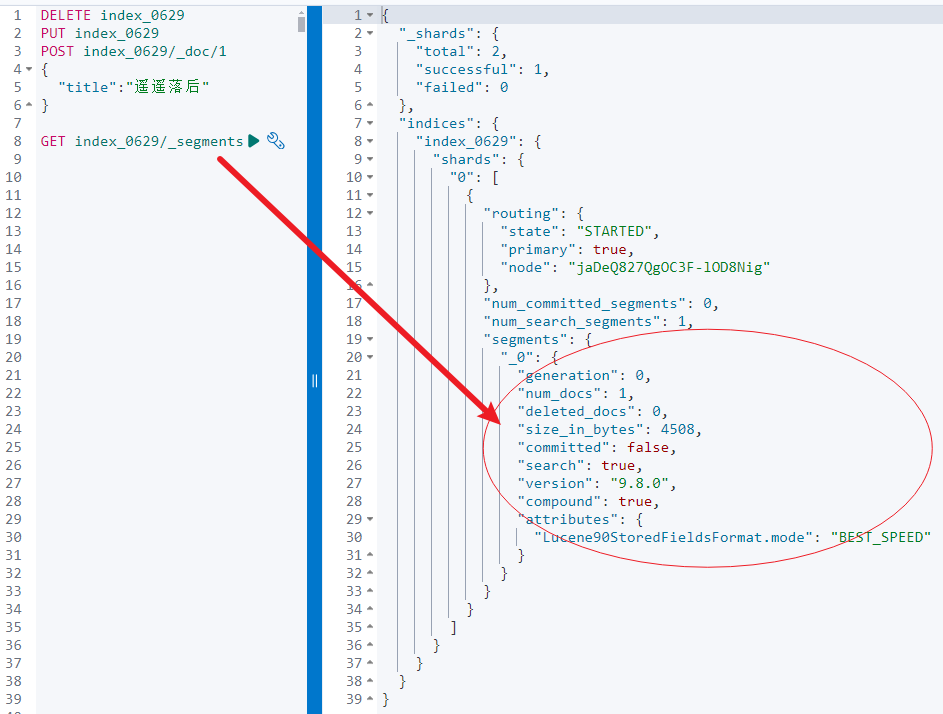
继续刚才的示例:更新操作执行一次后,截图如下:_version 由 1 变成 2。
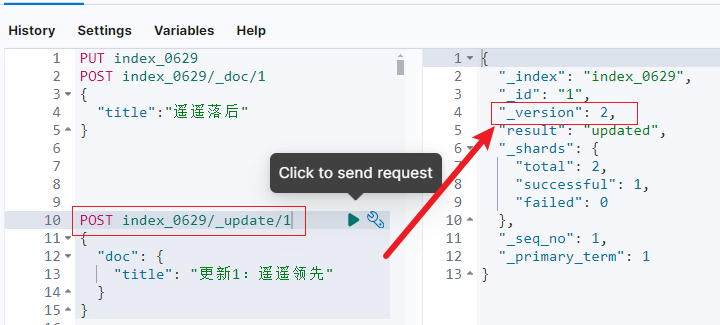
更新后查看分段:

文档数显示为1(如下图),但其实是两个不同的分段(如上图)。
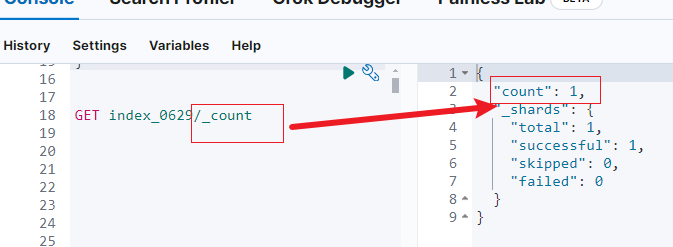
2.5 旧文档标记删除
原始文档被标记为删除。删除标记会在段合并时清理,以节省存储空间。
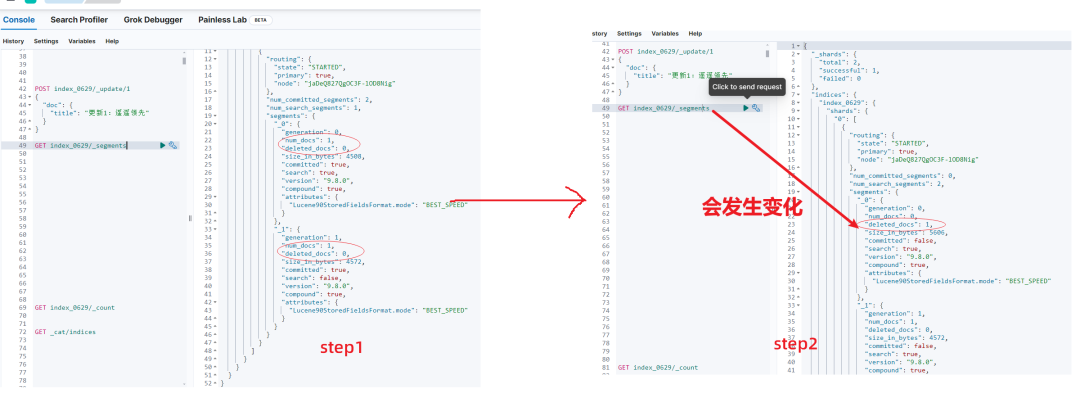
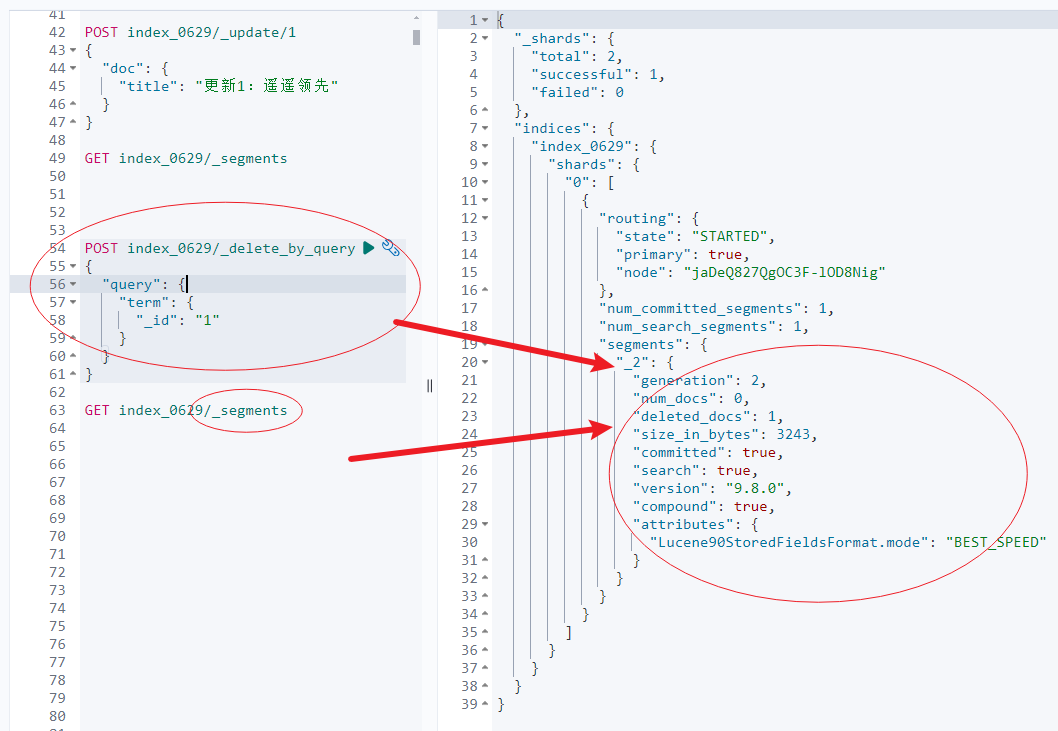
在如下示例中,通过 _delete_by_query 可以看到标记删除的过程。标记的文档将在段合并时被清理。
2.6 刷新与合并
更新完成后,Elasticsearch 定期刷新内存中的变更到磁盘,并合并段文件以优化存储和查询性能。
这些步骤确保了 Elasticsearch 在处理更新时的高效性和数据一致性。
更多细节操作参见源码:
https://github.com/elastic/elasticsearch/blob/main/server/src/main/java/org/elasticsearch/action/update/UpdateHelper.java
3、更新操作的代价
每次更新都涉及到重新索引,而不是简单的“原地”修改。这会增加磁盘 I/O 和计算资源的使用。
此外,标记为删除的文档在段合并前仍然占用空间,增加了存储负担。
第二部分的截图能让我们进一步理解:为什么越更新文档存储占据磁盘空间越大,为什么越删除文档存储占据磁盘越大的原因。
同时,进一步理解,段合并之后,磁盘空间骤降!
4、性能优化建议
4.1. 减少更新频率
实战场景:对于用户行为数据(如浏览次数、点赞数),可以合并多次更新为一次批量更新。
建议1:设置一个合理的批量更新间隔,比如每隔 5 分钟更新一次,而不是每次用户操作后立即更新。
建议2:使用消息队列收集用户操作,定时批量更新。
4.2. 批量处理
实战场景:在电商平台中,商品信息的批量更新。
建议:使用 _bulk API 一次性更新多个文档,减少单次请求的开销。
实践参考:
POST _bulk
{ "update": {"_id": "1"} }
{ "doc": {"price": 100} }
{ "update": {"_id": "2"} }
{ "doc": {"price": 200} }4.3. 延迟刷新
实战场景:日志数据的批量插入场景。
建议:对不需要实时可见性的索引,增加 refresh_interval,比如设置为 30s 或 60s。
实现:
PUT /my_index/_settings
{
"refresh_interval": "30s"
}4.4. 合理的索引设计
实战场景:对于大规模数据的索引设计,避免不必要的字段更新。
建议1:仅索引必要的字段,避免在频繁更新时更新整个文档。
PUT /my_index
{
"mappings": {
"properties": {
"title": {"type": "text"},
"views": {"type": "integer", "index": false}
}
}
}建议2:在设计阶段多花时间,考虑建模的充分性,在创建索引时明确指定需要索引的字段。
建议3:能 ingest pipeline 预处理管道或者 logstash filter 中间过滤阶段搞定的,咱们就不要拖到实现阶段。
如下问题的解决方案就是借助:json processor 实现。相比于更新操作,写入前的预处理非常有必要!
5、结论
频繁更新文档是 Elasticsearch 使用中的一个常见误区。
理解其更新机制和潜在开销是进行系统优化的关键。通过减少更新频率、使用批量处理、延迟刷新等策略,可以显著提高系统的性能和资源利用率。Elasticsearch 的强大功能需要合理使用,才能充分发挥其优势。
希望这篇文章能够帮助你更好地理解和优化 Elasticsearch 的使用!
参考:
https://betterprogramming.pub/boosting-elasticsearch-cluster-performance-3-proven-tips-9b718a9114bc
https://www.youtube.com/watch?v=gWXkAhnYFYw
Elasticsearch 使用误区之一——将 Elasticsearch 视为关系数据库!
Elasticsearch 为什么会产生文档版本冲突?如何避免?

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

比同事抢先一步学习进阶干货!










![[数据库原理]事务](https://img-blog.csdnimg.cn/direct/9ce3de4307e44d49951acc7b53714f87.jpeg)