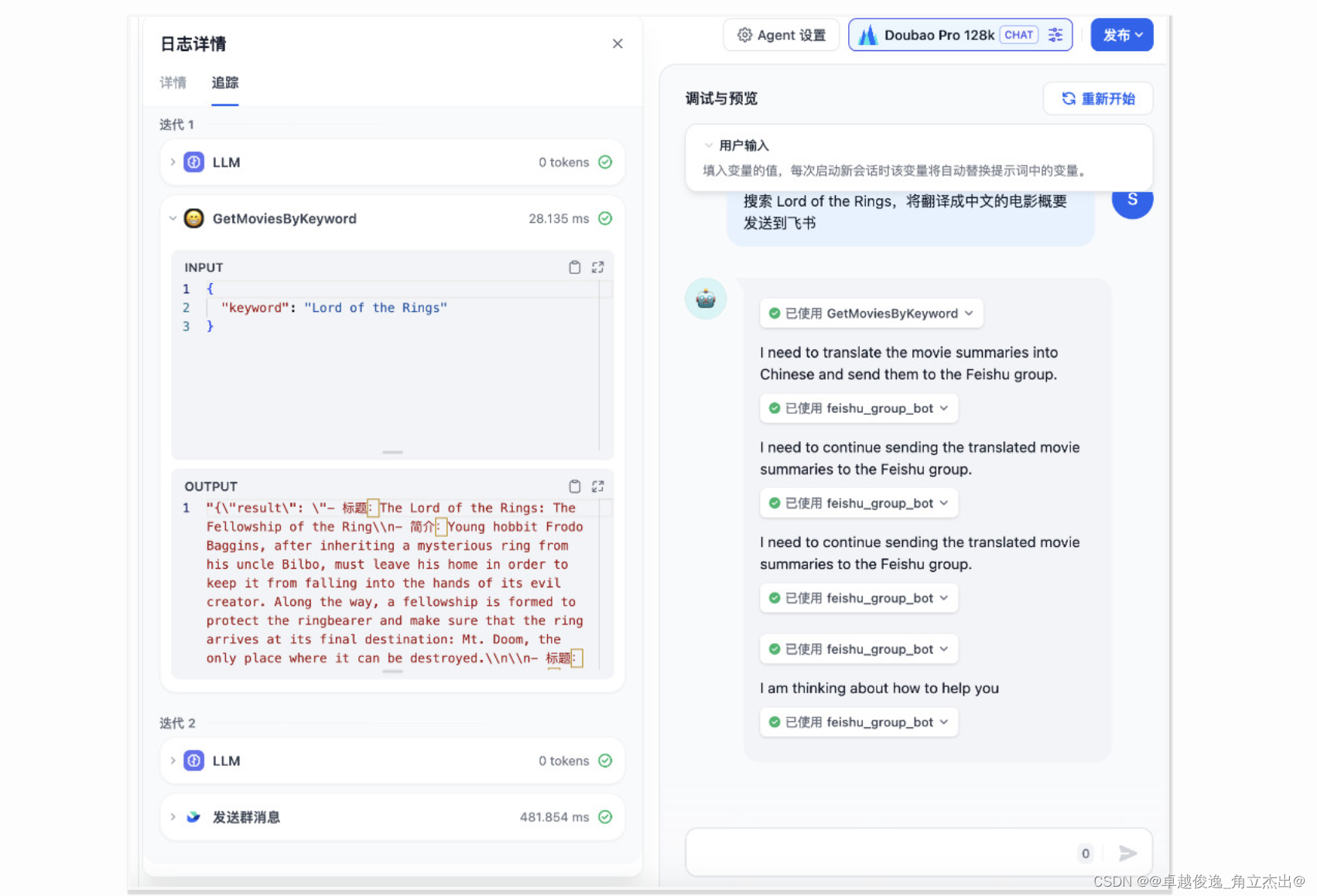
创建上下文——io_context_t
它是一个上下文结构,在内部它包含一个完成队列,在线程之间是可以共享的。
提交请求——iocb
io回调数据结构,和io_submit配合使用。
处理结果
通过io_event处理结果,
struct io_event {
void *data;
struct iocb *obj;
long long res;
};2222222222222222222222222222222222222222222222222222222222222222222
Linux异步IO:AIO教程(libaio)

迹寒
华中科技大学 计算机系统结构硕士
关注他
10 人赞同了该文章
AIO使用顺序
- 打开一个I/O Context以提交或者获取I/O请求;
- 创建一个或多个请求对象并设置;
- 将这些请求提交到I/O Context,这些请求会被发送到设备;
- 以事件的方式获取完成的对象;
- 回到2,循环往复。
创建上下文——io_context_t
它是一个上下文结构,在内部它包含一个完成队列,在线程之间是可以共享的。
struct io_context {
int32_t ctx_id;
uint32_t aio_max_events;
uint32_t aio_pendings;
// for system io_context_t, the type is long, point to kernel aio_ring
void* sys_ctx;
pthread_mutex_t ring_lock; // protect tail
pthread_mutex_t completion_lock; // protect head
pthread_spinlock_t rlock;
pthread_spinlock_t clock;
pthread_spinlock_t nrlock;
struct io_event** ring = nullptr;
uint32_t head;
uint32_t tail;
io_context(uint32_t maxevents, uint32_t ctxid)
: ctx_id(ctxid),
aio_max_events(maxevents),
aio_pendings(0),
sys_ctx(nullptr),
head(0),
tail(0) {
// init lock
pthread_mutex_init(&ring_lock, nullptr);
pthread_mutex_init(&completion_lock, nullptr);
pthread_spin_init(&nrlock, 0);
pthread_spin_init(&rlock, 0);
pthread_spin_init(&clock, 0);
// iocb ring
ring = reinterpret_cast<struct io_event**>(calloc(maxevents, sizeof(struct io_event*)));
}
~io_context() {
pthread_mutex_destroy(&ring_lock);
pthread_mutex_destroy(&completion_lock);
pthread_spin_destroy(&nrlock);
pthread_spin_destroy(&rlock);
pthread_spin_destroy(&clock);
free(ring);
}
};如果你需要创建一个io_context_t,请使用:
int io_setup(int maxevents, io_context_t *ctxp);maxevents是最大事件数,也就是IO队列的长度。如果需要析构一个io_context_t:
int io_destroy(io_context_t ctx);提交请求——iocb
io回调数据结构,和io_submit配合使用。
struct iocb {
void *data;
short aio_lio_opcode; // 表明一个op是读还是写,分别用IO_CMD_PREAD和IO_CMD_PWRITE表示
int aio_fildes; // iocb读写文件的fd
union {
struct {
void *buf; // 指向读写内存的指针
unsigned long nbytes; // 请求的长度
long long offset; // 请求的offset
} c;
} u;
};初始化iocb需要用到io_prep_pread andio_prep_pwrite
io_prep_pwritev:为异步写建立iocb,也就是回调函数。
inline void io_prep_pwrite(struct iocb *iocb, int fd, void *buf, size_t count,
long long offset);io_prep_write() 是用于设置并行写入的便捷函数。
iocb->aio_fildes = fd 是描述符的文件的第一个 iocb->u.c.nbytes = count 字节从 iocb->u.c.buf = buf 开始的缓冲区写入。 写入从文件中的绝对位置 ioc->u.c.offset = offset 开始。
该函数立即返回。 要安排操作,必须调用函数 io_submit(3)。
io_prep_pread也类似:
inline void io_prep_pread(struct iocb *iocb, int fd, void *buf, size_t count,
long long offset);提交请求需要用到io_submit
int io_submit(io_context_t ctx, long nr, struct iocb *ios[]);注意它提交的是一组iocb,nr是ios数组的长度。如果一次提交多个iocb,那么返回的iocb的顺序得不到保证。由于 CPU 使用率的降低,大批量提交有时会导致性能提升。有时还可以通过同时保持许多 I/O 的“运行”来提高性能。
如果提交包含太多iocb,以至于内部队列io_context_t在完成时会溢出,io_submit则将返回一个非零数字并设置errno为EAGAIN。务必使用O_DIRECT标志打开文件时使用该标志,并在原始块设备上进行操作。
处理结果
通过io_event处理结果,
struct io_event {
void *data;
struct iocb *obj;
long long res;
};data就是传入iocb的数据,obj是原始的iocb,res是读或写返回的结果。
通过以下函数得到io_event:
int io_getevents(io_context_t ctx_id, long min_nr, long nr, struct io_event *events, struct timespec *timeout);ctx_id是获取的io_context;
min_nr是返回的io_event的最小数量。除非这有min_nr个IO完成事件,否则该函数将会阻塞;
nr是IO完成事件的最大数量,即ios数组长度;
events是io_events数组,
timeout是调用io_getevents可能阻塞直到它返回的最长时间。如果传入NULL,io_getevents则将阻塞,直到min_nr 个事件完成。
返回值表示报告了多少完成,即写入了多少事件。返回值将介于 0 和 之间nr。返回值可能低于min_nr超时时间;如果超时为NULL,则返回值将介于min_nr和之间nr。
- min_nr = 0(或者,等效地,timeout = 0)。此选项形成了一种非阻塞轮询技术:无论是否有任何完成可用,它总是会立即返回。在每次迭代中作为应用程序主运行循环的一部分min_nr = 0调用时使用它是有意义的。io_getevents
- min_nr = 1. 此选项会阻塞,直到有一个完成可用。该参数是产生阻塞调用的最小值,因此对于某些用户来说可能是低延迟操作的最佳值。当应用程序注意到eventfd触发了与 iocb 对应的一个(参见下一节epoll),然后应用程序可以调用io_getevents对应io_context_t的,并保证不会发生阻塞。
- min_nr > 1. 此选项等待多个完成返回,除非超时到期。由于减少了 CPU 使用率,等待多个完成可能会提高吞吐量,这既是由于更少的io_getevents调用,也是因为如果完成队列中由于移除的完成而有更多的空间,那么稍后的io_submit调用可能具有更大的粒度,以及减少的当事件可用时,上下文切换回调用线程的次数。此选项存在增加操作延迟的风险,尤其是在操作率较低时。
即使min_nr = 0或 1,出于性能原因将 nr 设置得更大一点也是有用的:可能已经完成了多个事件,并且可以在不多次调用 的情况下对其进行处理io_getevents。更大的 nr 值库的唯一成本是用户必须分配更大的事件数组并准备好接受它们。
性能考虑
- io_submit在ext4、缓冲操作、网络访问、管道等期间阻塞。AIO 接口不能很好地表示某些操作。对于缓冲读取、套接字或管道上的操作等完全不受支持的操作,整个操作将在 io_submit 系统调用期间执行,完成后可立即通过 io_getevents 访问。部分支持对文件系统(如 ext4)上文件的 AIO 访问:如果需要读取元数据来查找数据块(即,如果元数据尚未在内存中),则 io_submit 调用将阻塞读取元数据。某些类型的文件放大写入完全不受支持,并在整个操作期间阻塞。
- CPU 开销。当在高性能设备上执行小操作并针对单个 CPU 的非常高的操作率时,可能会导致 CPU 瓶颈。这可以通过从多个线程提交和获取 AIO 来解决。
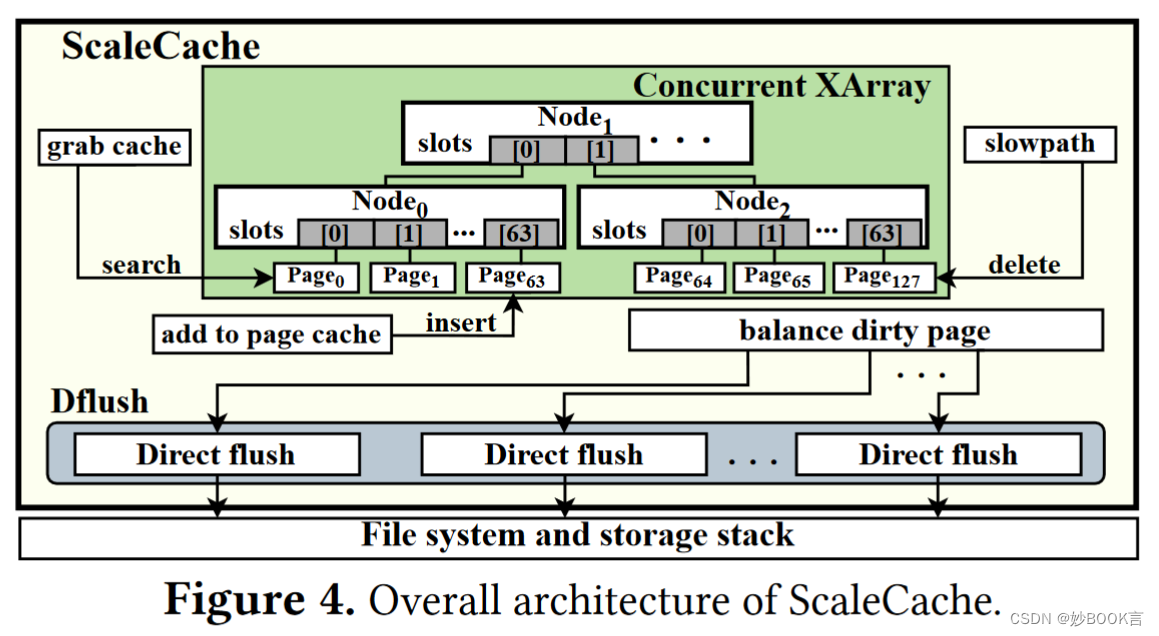
- 当许多 CPU 或请求共享一个 io_context_t 时锁争用。在某些情况下,可以从多个 CPU 访问对应于 io_context_t 的内核数据结构。例如,多个线程可以从同一个 io_context_t 提交和获取事件。一些设备可能对所有完成使用单个中断线。这可能导致锁在内核之间反弹或锁被严重竞争,从而导致更高的 CPU 使用率和潜在的更低吞吐量。一种解决方案是分片成多个 io_context_t 对象,例如通过线程和地址的哈希。
- 确保足够的并行性。一些设备需要许多并发操作才能达到峰值性能。这意味着要确保同时有几个“在进行中”的操作。在一些高性能存储设备上,当操作量较小时,必须并行提交数十或数百个,才能达到最大吞吐量。对于磁盘驱动器,如果电梯调度程序可以在飞行中同时进行更多操作做出更好的决策,则性能可能会随着更大的并行性而提高,但在许多情况下预计效果会很小。
AIO的替代技术
- 同步 I/O 线程的线程池。这适用于许多用例,并且可能更容易编程。与 AIO 不同,所有功能都可以通过线程池并行化。一些用户发现线程池不能很好地工作,因为线程在 CPU 和内存带宽使用方面的开销来自上下文切换。对于高性能存储设备上的小随机读取,这是一个特别大的问题。
- POSIX AIO。另一个异步 I/O 接口是 POSIX AIO。它是作为 glibc 的一部分实现的。但是,glibc 实现在内部使用线程池。Joel Becker 实现了一个基于上述 Linux AIO 机制的 POSIX AIO版本。IBM DeveloperWorks对 POSIX AIO有很好的介绍。
- epoll。Linux 对使用 epoll 作为异步 I/O 机制的支持有限。对于以缓冲模式(即没有 O_DIRECT)打开的文件的读取,如果文件以 O_NONBLOCK 方式打开,则读取将返回 EAGAIN,直到相关部分在内存中。对缓冲文件的写入通常是立即的,因为它们是通过另一个写回线程写出的。但是,这些机制并没有提供直接 I/O 提供的对 I/O 的控制级别。
示例代码
下面是一些使用 Linux AIO 的示例代码。我在谷歌写的,所以它使用谷歌 glog 日志库和谷歌 gflags 命令行标志库,以及对谷歌 C++ 编码约定的松散解释。使用 gcc 编译时,传递-laio给与 libaio 动态链接。(它不包含在 glibc 中,因此必须明确包含。)
// Code written by Daniel Ehrenberg, released into the public domain
#include <fcntl.h>
#include <gflags/gflags.h>
#include <glog/logging.h>
#include <libaio.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/stat.h>
#include <sys/types.h>
DEFINE_string(path, "/tmp/testfile", "Path to the file to manipulate");
DEFINE_int32(file_size, 1000, "Length of file in 4k blocks");
DEFINE_int32(concurrent_requests, 100, "Number of concurrent requests");
DEFINE_int32(min_nr, 1, "min_nr");
DEFINE_int32(max_nr, 1, "max_nr");
// The size of operation that will occur on the device
static const int kPageSize = 4096;
class AIORequest {
public:
int* buffer_;
virtual void Complete(int res) = 0;
AIORequest() {
int ret = posix_memalign(reinterpret_cast<void**>(&buffer_),
kPageSize, kPageSize);
CHECK_EQ(ret, 0);
}
virtual ~AIORequest() {
free(buffer_);
}
};
class Adder {
public:
virtual void Add(int amount) = 0;
virtual ~Adder() { };
};
class AIOReadRequest : public AIORequest {
private:
Adder* adder_;
public:
AIOReadRequest(Adder* adder) : AIORequest(), adder_(adder) { }
virtual void Complete(int res) {
CHECK_EQ(res, kPageSize) << "Read incomplete or error " << res;
int value = buffer_[0];
LOG(INFO) << "Read of " << value << " completed";
adder_->Add(value);
}
};
class AIOWriteRequest : public AIORequest {
private:
int value_;
public:
AIOWriteRequest(int value) : AIORequest(), value_(value) {
buffer_[0] = value;
}
virtual void Complete(int res) {
CHECK_EQ(res, kPageSize) << "Write incomplete or error " << res;
LOG(INFO) << "Write of " << value_ << " completed";
}
};
class AIOAdder : public Adder {
public:
int fd_;
io_context_t ioctx_;
int counter_;
int reap_counter_;
int sum_;
int length_;
AIOAdder(int length)
: ioctx_(0), counter_(0), reap_counter_(0), sum_(0), length_(length) { }
void Init() {
LOG(INFO) << "Opening file";
fd_ = open(FLAGS_path.c_str(), O_RDWR | O_DIRECT | O_CREAT, 0644);
PCHECK(fd_ >= 0) << "Error opening file";
LOG(INFO) << "Allocating enough space for the sum";
PCHECK(fallocate(fd_, 0, 0, kPageSize * length_) >= 0) << "Error in fallocate";
LOG(INFO) << "Setting up the io context";
PCHECK(io_setup(100, &ioctx_) >= 0) << "Error in io_setup";
}
virtual void Add(int amount) {
sum_ += amount;
LOG(INFO) << "Adding " << amount << " for a total of " << sum_;
}
void SubmitWrite() {
LOG(INFO) << "Submitting a write to " << counter_;
struct iocb iocb;
struct iocb* iocbs = &iocb;
AIORequest *req = new AIOWriteRequest(counter_);
io_prep_pwrite(&iocb, fd_, req->buffer_, kPageSize, counter_ * kPageSize);
iocb.data = req;
int res = io_submit(ioctx_, 1, &iocbs);
CHECK_EQ(res, 1);
}
void WriteFile() {
reap_counter_ = 0;
for (counter_ = 0; counter_ < length_; counter_++) {
SubmitWrite();
Reap();
}
ReapRemaining();
}
void SubmitRead() {
LOG(INFO) << "Submitting a read from " << counter_;
struct iocb iocb;
struct iocb* iocbs = &iocb;
AIORequest *req = new AIOReadRequest(this);
io_prep_pread(&iocb, fd_, req->buffer_, kPageSize, counter_ * kPageSize);
iocb.data = req;
int res = io_submit(ioctx_, 1, &iocbs);
CHECK_EQ(res, 1);
}
void ReadFile() {
reap_counter_ = 0;
for (counter_ = 0; counter_ < length_; counter_++) {
SubmitRead();
Reap();
}
ReapRemaining();
}
int DoReap(int min_nr) {
LOG(INFO) << "Reaping between " << min_nr << " and "
<< FLAGS_max_nr << " io_events";
struct io_event* events = new io_event[FLAGS_max_nr];
struct timespec timeout;
timeout.tv_sec = 0;
timeout.tv_nsec = 100000000;
int num_events;
LOG(INFO) << "Calling io_getevents";
num_events = io_getevents(ioctx_, min_nr, FLAGS_max_nr, events,
&timeout);
LOG(INFO) << "Calling completion function on results";
for (int i = 0; i < num_events; i++) {
struct io_event event = events[i];
AIORequest* req = static_cast<AIORequest*>(event.data);
req->Complete(event.res);
delete req;
}
delete events;
LOG(INFO) << "Reaped " << num_events << " io_events";
reap_counter_ += num_events;
return num_events;
}
void Reap() {
if (counter_ >= FLAGS_min_nr) {
DoReap(FLAGS_min_nr);
}
}
void ReapRemaining() {
while (reap_counter_ < length_) {
DoReap(1);
}
}
~AIOAdder() {
LOG(INFO) << "Closing AIO context and file";
io_destroy(ioctx_);
close(fd_);
}
int Sum() {
LOG(INFO) << "Writing consecutive integers to file";
WriteFile();
LOG(INFO) << "Reading consecutive integers from file";
ReadFile();
return sum_;
}
};
int main(int argc, char* argv[]) {
google::ParseCommandLineFlags(&argc, &argv, true);
AIOAdder adder(FLAGS_file_size);
adder.Init();
int sum = adder.Sum();
int expected = (FLAGS_file_size * (FLAGS_file_size - 1)) / 2;
LOG(INFO) << "AIO is complete";
CHECK_EQ(sum, expected) << "Expected " << expected << " Got " << sum;
printf("Successfully calculated that the sum of integers from 0"
" to %d is %d\n", FLAGS_file_size - 1, sum);
return 0;
}参考资料:
https://github.com/littledan/linux-aio
编辑于 2022-06-28 11:06