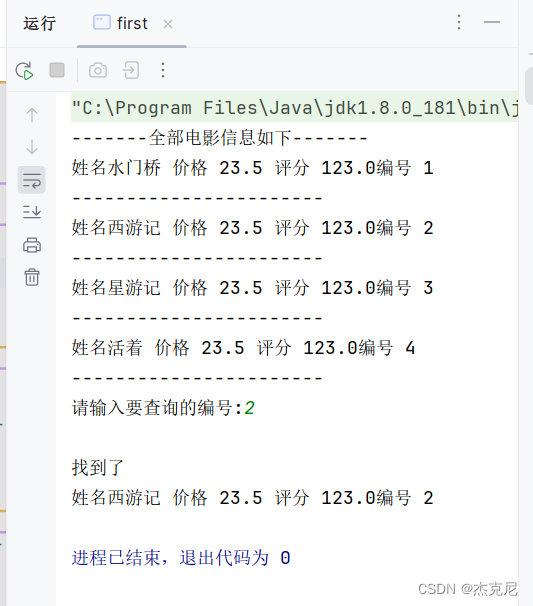
隐私集合求交技术是多方安全计算领域的一个子问题,通常也被称为安全求交、隐私保护集合交集或者隐私交集技术等,其目的是允许持有各自数据集的双方或者多方,执行两方或者多方集合的交集计算,当PSI执行完成,一方或者两方,甚至多方,能够得到交集结果,但是任意一方都无法获得交集以外的其他方集合数据的任何信息。
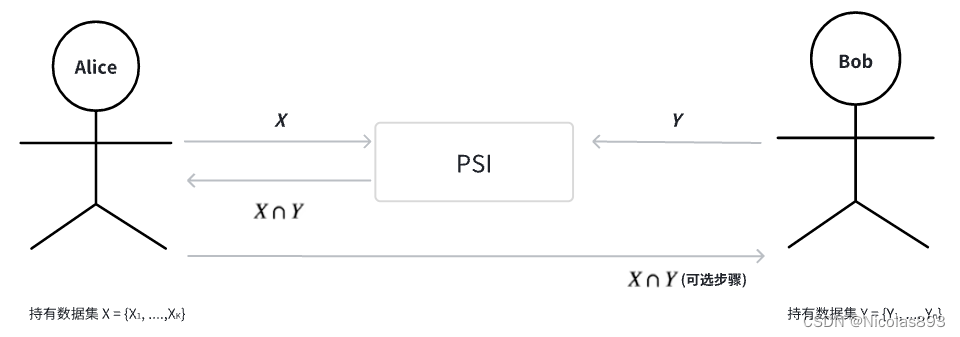
图1. 两方PSI示例
Alice有集合X,Bob有集合Y。在进行PSI计算后,Alice只能知道集合X与集合Y的交集,即X ∩ Y,而无法知道其他任何信息。Alice无法知道Bob的元素中不属于X ∩ Y的部分。如果Alice试图了解Bob的不匹配数据,Alice将无法成功。
1. PSI解决的业务问题
在介绍具体的PSI原理之前,有必要先介绍PSI的应用场景,能够解决哪些业务问题,带着这样的场景解决方案背景知识,能够更快速的理解PSI的原理实现。这里列举了多种业务活动中,可以使用PSI解决的问题,总结起来可以归纳为“黑/白名单应用”以及“撞库应用”:
1. 黑/白名单系列
1.1 金融机构黑名单共享:银行、信用卡公司等金融机构可以共享黑名单信息,防止被多个机构列入黑名单的客户再次申请贷款或信用卡。
1.2 犯罪调查:不同执法机构可以在不泄露案件详细信息的前提下,合作识别共同嫌疑人或案件线索,提高办案效率。
1.3 租赁公司黑名单共享:汽车租赁公司和房屋租赁公司可以共享不良租客信息,防止有违约或损坏财产记录的租客继续租赁。
1.4 医疗研究:不同医院或研究机构可以在不共享患者详细信息的情况下,识别共同患者,进行协同研究或联合分析。
1.5 身份验证:不同组织可以在不共享用户详细信息的情况下,验证用户的身份,确保用户的隐私安全。
2. 撞库系列
2.1 广告投放和数据合作:广告商和平台可以在不暴露各自用户数据的情况下,确定共同用户,以实现更精准的广告投放。
2.2 市场分析:企业之间可以在保护客户隐私的情况下,合作进行市场分析,识别共同客户和市场趋势。
2.3 社交网络:不同社交网络平台可以在不泄露用户数据的情况下,找出重叠用户,以便更好地提供跨平台服务。
2.4 联邦学习:多个机构可以在保护数据隐私的情况下,共享数据特征,进行联合机器学习模型训练,提升模型性能。
2.5 账户保护合作:不同企业可以在不透露具体用户信息的情况下,合作保护那些使用相同账户信息的用户,防止他们在多个平台上遭受撞库攻击。
2. PSI协议的分类及设计
2.1 分类体系
PSI是一个发展相对成熟的领域,因此有非常多的算法,面向的解决场景也多种多样。这里列举一些分类的维度,有更多或者更好的意见补充的话可以评论留言。
- 参与方的数量:两方PSI、三方PSI、多方PSI;
- 参与方数据量级差异:平衡PSI、非平衡PSI;
- 实现的原理差异:
- 基于PKC(公私钥体系)
- 基于全同态加密
- 基于秘密共享
- 基于OPRF协议
- 基于OPPRF协议
- 基于OKVS
- 基于PCG
- 是否为恶意模型:半诚实安全PSI协议、恶意安全PSI协议;
- 不同通信成本:WAN友好PSI协议、LAN适用PSI协议;
- 是否纯在线计算:Online模式、Offline-Online模式;
- 输出交集结果形式:明文交集结果(普通PSI)、不泄露结果(电路PSI/匿踪PSI);
- 是否可证安全:基于密码学的PSI协议、基于可信硬件环境的PSI协议。
虽然分类的体系比较复杂,但是从PSI的定义出发,设计一个合格的PSI,需要解决三个主要问题:
(1)保护非交集元素, 使用密码学保证不暴露,当两个元素不相等时,无法穷尽计算不匹配的元素。
(2)可以通过比较计算交集元素,当两个元素相等时,相等性能够以某种方式被揭示。
(3)高效率,能够满足所应用业务的性能指标要求。
2.2 算法设计
接下来,通过对不同的PSI的设计分析,来进一步理解PSI算法原理。
2.2.1 基于公钥体系的设计方案
基于Diffie-Hellman密钥交换的PSI,基本思路为双重加密具有交换性,加密隐藏元素,交换性满足可比较,通信成本呈线性关系。 在加密原语(如椭圆曲线)上有许多增强,可以设计一种能满足所有要求的加密方法。
该协议的安全性是建立在离散对数问题(DLP)上,给定p、g、x和y四个大正整数,假设,其中p是一个大素数,已知y、g、p,如何找到x是一个“难题”。其中,计算
是高效的,保证了效率。给定y、g、p找到x是困难的,保证了对原始数据的加密隐藏。
等于
,具备交换性,满足可比较。
两方&三方场景的DH-based PSI设计如下,计算量适中,通信量相对可控,由于底层依赖的加密算法(比如采用ECC)如果有性能优化的话,可以显著提升性能。
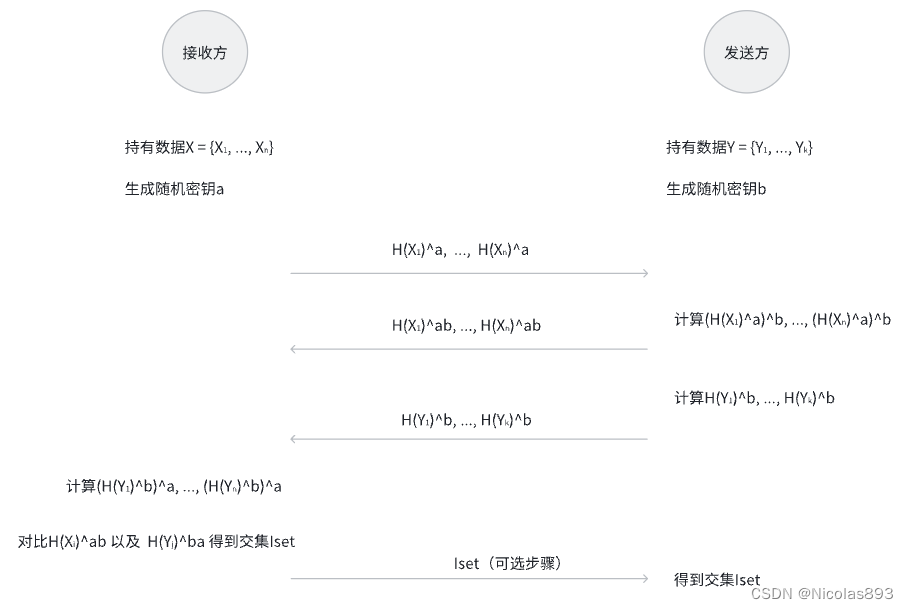
图2. DH-based 两方PSI协议示例

图3. DH-based 三方PSI协议示例
2.2.2 基于OPRF体系的设计方案
OPRF是Oblivious Pseudo-random Function的简称,称为不经意伪随机函数。在介绍具体算法之前,需要先介绍下什么是PRF?
PRF 是一个确定性的函数,记为𝐹。𝐹是定义在(𝑘,𝑋,𝑌)上的 PRF,其中 𝑘 是密钥空间,𝑋 是输入空间,𝑌 是输出空间。它有两个输入,一个是密钥 𝑘,另一个是输入数据块 𝑥∈𝑋。它的输出𝑦=𝐹(𝑘,𝑥)∈𝑌 。对于 PRF,其安全性要求:给定一个随机产生的密钥 𝑘,函数𝐹(𝑘,.)应该看上去“像”是一个定义在 𝑋 到 𝑌 上的随机函数。
此外,OPRF中的不经意性,体现在如何保护参与方的隐私和信息。具体来说,在OPRF中,发送方和接收方可以执行计算,但彼此不会了解对方的关键信息或输入。发送方使用其私密密钥和接收方的输入数据来生成输出,但不会了解接收方的具体输入内容。接收方也可以获取输出结果,但不会知道发送方使用的具体密钥或如何生成输出的详细过程。无论是发送方还是接收方,在计算和通信过程中不会保留对方的私密信息或详细计算过程。每个参与方只能得到必要的信息来执行协议,而不会暴露其他不必要的信息。
通俗来说,OPRF执行流程包含以下步骤,在计算过程中,发送方不能知道接收方的数据,接收方也不能知道秘密函数,有效做到对关键信息的隐藏。经过秘密函数处理后的数据可以进行比较。大部分操作是高效的加密操作,如哈希和对称密钥加密,只有少量的公钥基础设施操作。
- 发送方对其集合计算一个“秘密”函数,并将结果发送给接收方。
- 接收方也通过与发送方交互来计算其集合在这个“秘密”函数上的结果。
- 接收方将从发送方收到的结果与自己的结果进行比较。
事实上,DH-based PSI也是满足OPRF原理。这里,为了进一步介绍清楚OPRF的原理,这里举一个简单的案例,以帮助能理解其工作逻辑。如图4所示,接收方将其项目X哈希到一个在某个密码安全的椭圆曲线上的点 A 上。然后,接收方选择一个随机数 r,计算点 B = rA,并将其发送给发送方。发送方使用其密钥 K 计算点 C =KB,并将其发送回接收方。接收方收到 C 后,计算椭圆曲线阶数的逆元 并进一步计算
。接收方然后从这个点中提取 OPRF哈希值
,例如通过将其 X坐标哈希到适当的域。
发送方知道 K,因此可以简单地用 替换为
。接收方需要与发送方通信以获取
;一旦接收到这些值,协议就可以如上所述进行。使用OFRF后,接收方了解其查询的部分是否匹配的问题将不复存在。由于所有项都使用只有发送方知道的哈希函数进行哈希,接收方从了解发送方的哈希项的部分中将获益不大。

图4. 基于ECC椭圆曲线的OPRF-based PSI示例
有了上述的示例,我们给出OPRF的执行流程框架。

图5. 一般性的OPRF的执行流程
可以看到,一般性的OPRF,在通信和计算上都比较耗时,对于每一个Xi都需要执行一次OPRF,且每次OPRF都需要计算全部的Y,因此时间复杂度差不多是。那么有没有更优的方案呢?
这里给出KKRT16的一种实现方案,引入了Cuckoo hash和simple hash来分桶,实现性能的提升。先来看一个cuckoo hash的例子,如图6所示,假设接收方有三个元素[1, 2, 3], 发送方也有同样的三个元素[1,2,3]。 如果不做分箱处理,也就是用一般性的OPRF,需要执行复杂度计算。但如果引入cuckoo hash bining,整体复杂度会降低到
, 这里的
是指hash函数的数量,一般是2或者3。当然引入cuckoo hash,分箱数量会有扩增,大概到1.5n的规模,也是相对可控的,发送方的max bin size,在大数据下,一般也就是几十到几百的规模,相对于不做bining处理,收益会非常明显。图7展示了引入cuckoo hash bining之后的OPRF版本。

图6. cuckoo hash bining示例

图7. 引入cuckoo hash bining之后的OPRF-based PSI示例
事实上,KKRT16之所以性能好,除了Cuckoo Hashing外,还改进了OPRF的性能。KKRT16是从运行效率上针对KK13的1-n OTE提升为1-无穷 OTE的一个改进,通过将纠错码改为伪随机编码实现(1-无穷)-OTE,避免了OT数量与元素的大小相关。
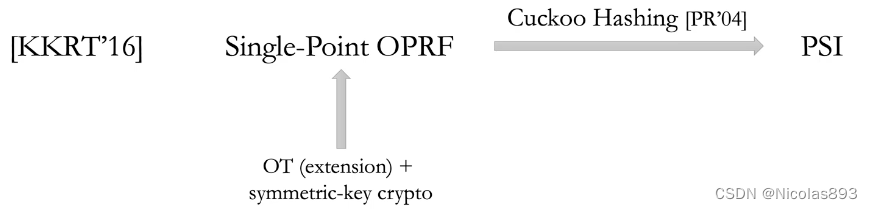
图8. KKRT16实现机制
2.2.2.2.1 Single-point OPRF
虽然KKRT16取得了显著的性能提升,但该算法对于带宽的要求依然较高,不同带宽对其求交性能影响显著。如下表所示,在10M带宽下,KKRT16的性能下降明显。
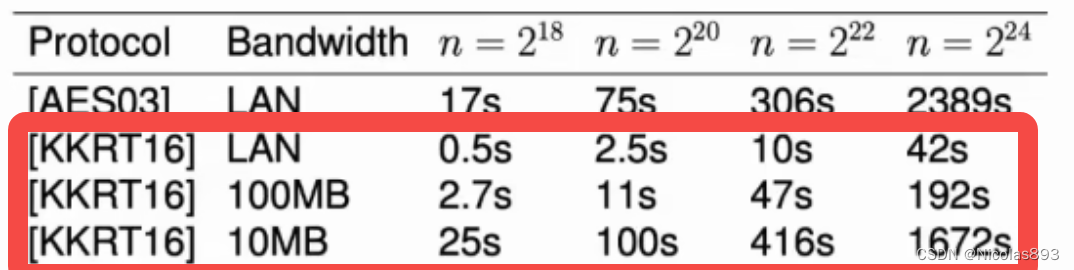
这是因为KKRT16本质上属于单点OPRF,也就是一个OPRF实例仅能对一个元素进行OPRF值的评估。由于每一行的密钥均不同,若直接采用单点-OPRF进行元素比较,则发送方的每个元素需要OPRF评估n次(n为接收方集合大小),即使采用了cuckoo hashing的方案,发送方的每个元素需要OPRF评估hash函数个数+stash大小。图9展示了单点OPRF的计算过程,(a) 如果 x = y,那么无论选择什么 s,。 (b) 如果 x ≠ y,那么
很难猜测。具体的计算步骤如下:
step1: 发送方随机生成
长度的0-1比特串,这里的
以保证生成的比特串的随机性。然后数据Y,需要通过f(Y)函数计算得到新的同等长度
的0-1比特串,这个函数需要具备随机性、确定性。这类函数有很多的不同设计,可以
参考KKRT16的源码实现。有了f(Y)的0-1比特串后,将
与f(Y)按位求异或,得到r1的
0-1比特串。这样得到的
比特串,将会作为后续OT执行的message。
step2:接收方生成随机的选择比特串,长度同样是
素,对应位置为1,则选择
对应位置的元素,这样执行完
q,序列q可以表示成公式
,其中
表示的是与计算。
step3:接收方对自身的X进行同样的f(X)函数转换,得到0-1比特串f(X)。然后将(s, q)作为
OPRF中的秘密k,计算
,同理
。
当
的时候,
将会等于全为0的比特串,刚好被消除,得到
最终的
。当
的时候,
是一个很难猜的对象,因此发送方无法反
推原始的X。说明一下,最后的比较操作,是在图中的发送方一侧计算。这样就实现了
基于单点OPRF的PSI。

图9. 单点OPRF过程
2.2.2.2.2 Multi-point OPRF
由于单点OPRF的不足,因此有必要讨论针对一般带宽资源下的性能更好的OPRF-based PSI算法。这里给出CM20中提到的一种优化方案,CM20提出一种多点OPRF协议。多点OPRF的目的是为了消除发送方的每个元素需要OPRF评估多次的计算和通信开销,使得发送方的每个元素只需要评估一次。
如图10所示的多点OPRF计算过程。整体计算思路基本与单点的类似,需要注意,多点OPRF,是将集合f(Y)映射到一个矩阵中,从step1和step2可以看到,f(y)首先计算出每一列所落的位置,然后将R0矩阵中对应位置的元素拷贝到R1矩阵中。经过对多个y计算f(y), 得到每一个f(y)在矩阵中的位置并拷贝对应的R0矩阵元素到R1中,矩阵R1就同时包含了多个f(y)信息。在step3中,将R1中剩余空缺的位置,在R0中找到对应的位置元素,进行取反,然后填充到R1中对应位置。就得到最终的R1矩阵。Step4,同样左侧参与方生成随机的选择比特串s, 执行次OT,0表示取R0中的对应列元素,1表示取R1中对应列元素。得到矩阵q。此时(q,s)就作为OPRF中的秘密k,然后计算
。即对X进行f(x)计算,得到q中每一列对应的位置,取得对应的元素,图中示例为H(00010)。 与单点OPRF同理,执行
,相当于是获得对应矩阵位置中的r0元素,即H(r0),如果X=Y, 则
为H(00010)。如果不想等,则
是一个难以猜测的值。
CM20的多点OPRF,可以带来cuckoo hash函数的作用,且消除了通信开销。

图10. 多点OPRF过程
为了进一步详细对比原论文中的计算逻辑,这里贴一下【CM20论文】中的步骤,如图11所示,计算顺序上可能有一点点顺序差异,但整理逻辑是一致的,帮助更好的理解实现原理。

图11. CM20论文中PSI协议计算流程
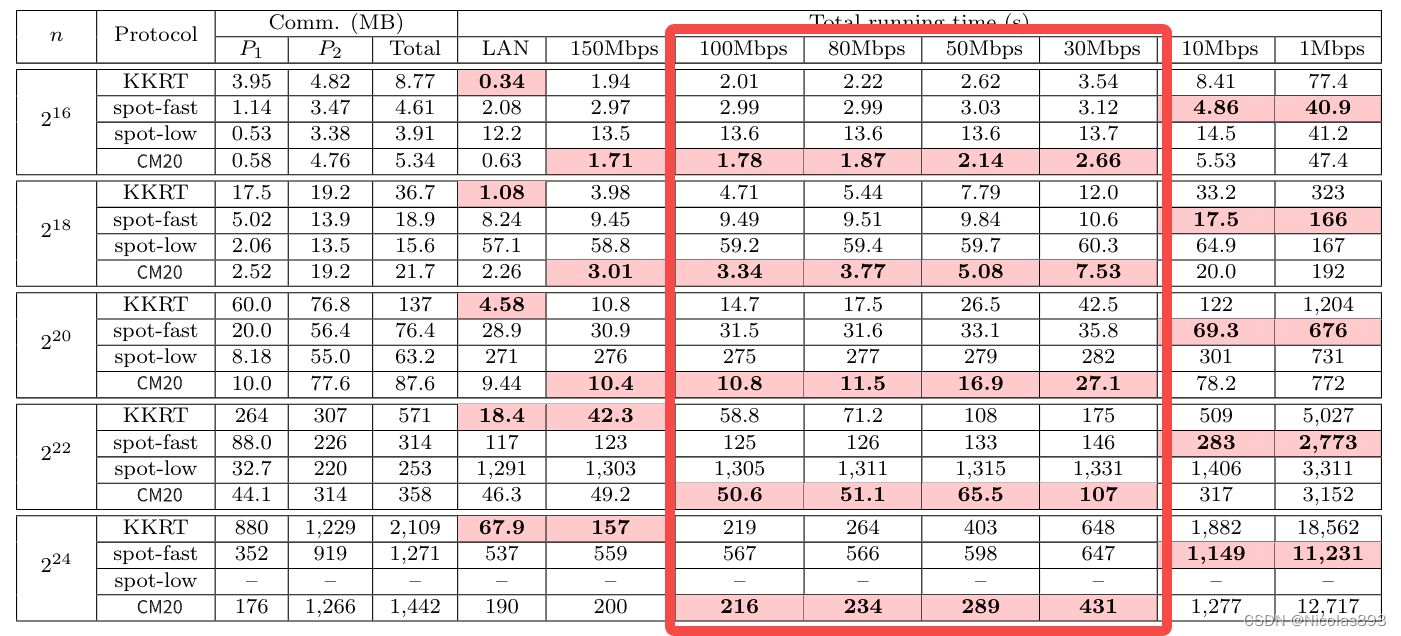
KKRT16 和 CM20在不同带宽下对比,CM20在中带宽(30Mbps - 100Mbps)下,相对于KKRT16有一定的优势。
表1. 不同带宽下的运行耗时对比
2.2.3 基于OKVS+VOLE体系的设计方案
之前提到了KKRT16在高带宽(LAN)场景下性能较佳,而CM20在中带宽(30Mbps-100Mbps),接下来介绍的RR22-PSI,则进一步在通信量优化上做出显著提升,在低带宽(10Mbps-20Mbps)下性能表现优异。
[PRTY20]引入了Probe-and-Xor-of-Strings (PaXoS), 替代Cuckoo Hashing抵抗恶意攻击。
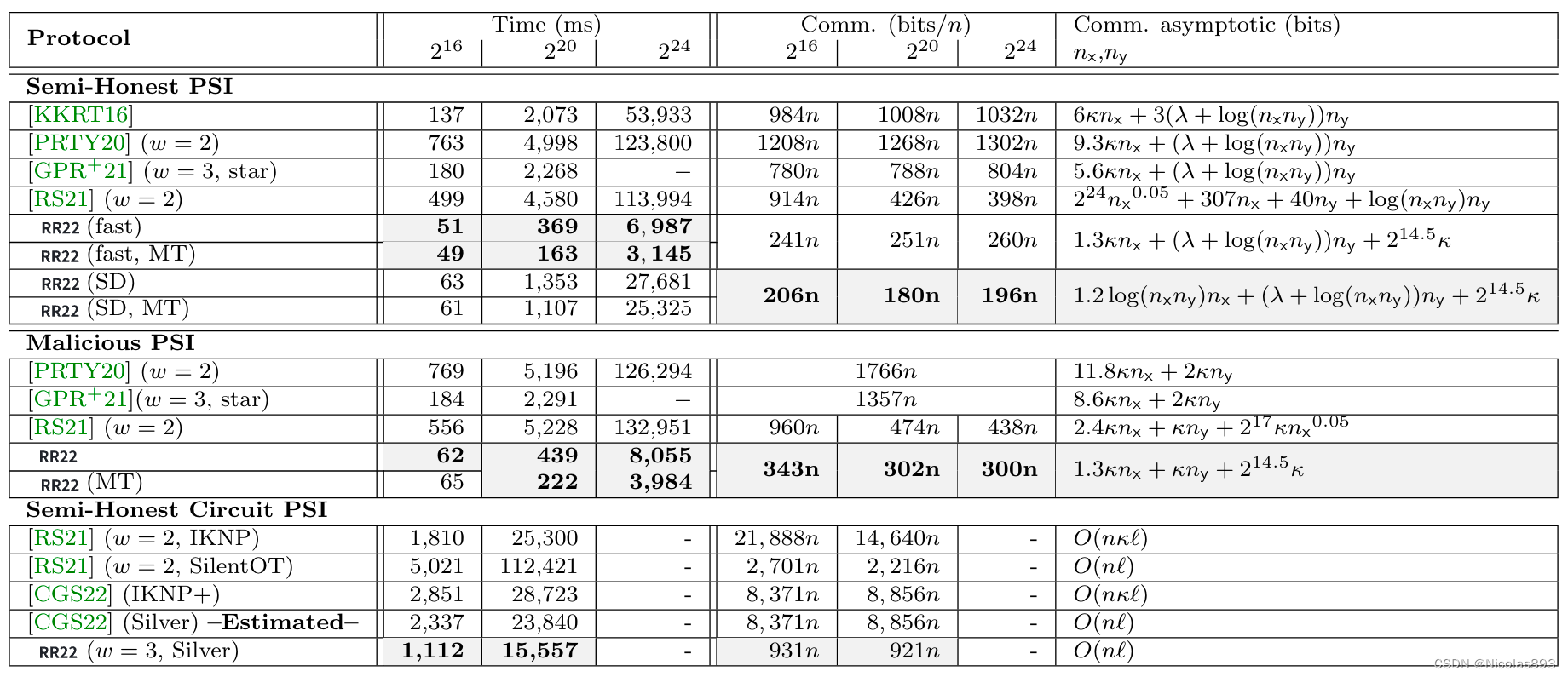
[RR22]把PaXoS抽象成通用工具:Oblivious Key-Value Store (OKVS),且提出了一种改进版本的OKVS结构,提高了计算和通信的效率。使用VOLE替换OT,可以充分利用offline阶段的能力,提升online的计算效率,当然在实际验证中,即使包含offline生成VOLE元组的耗时,整体也很可观,下表展示了相应的通信量分析,可以看到相对于CM20有明显改善。
表2. 不同带宽下的通信量分析
正式分析RR22算法之前,需要先对OKVS和VOLE进行一定的介绍。
2.2.3.1 不经意键值存储OKVS以及VOLE
不经意键值存储(OKVS-oblivious key-value store)是指能够在隐藏key和value内容的前提下,保留key-value映射关系的一种数据结构。假设有一组键值对,那么存在一个OKVS函数f,使得
, 并且对于其他的键
为随机数。OKVS包含了通过key-value构造OKVS的Encode方法和通过key查询value的Decode方法。
举个简单但不安全的示例,将(K, V)通过多项式插值编码,使得
,那么存在以下关系:

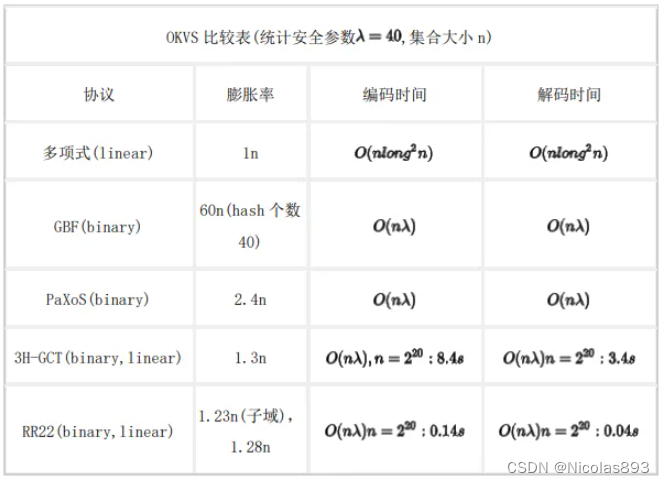
刚才提到的基于多项式插值的构造显然是不安全的,因为Key-Value Store 𝑆 包含了输入 (𝐾,𝑉) 的信息。安全的构造例如PaXoS,PaXoS编码生成的 𝑆 具有随机性,所以是安全的。PaXoS的原型是Garbled Bloom Fitler。一些安全的OKVS的形式有多种,如GBF、PaXoS、3H-GCT、2-cuckoo hash,RR22中OKVS 则是通过cuckoo哈希将 key 映射到 随机矩阵H 中(weight 选择为3时,性能最佳),然后通过三角化、后向传播等方法求解 向量P,使得 H · P = V。[RR22] 还设计了一种称为 Clustering 的优化方法:将系数矩阵分块,使得权重相对聚集在某一部分,例如:第一块的权重主要集中在前半部分。这样每个 Clustering 可以单独进行相应的三角化,并支持多线程并行处理。同时,根据论文分析选取 Clustering 参数为 2^14时,性能达到最优。比较直观的可视化展示可以看下【5】。
【6】中提到相关OKVS结构信息见下表所示:
表3. 不同OKVS结构
有了OKVS,如何实现PSI,这里【12】给出了一个小的示例:
Sender将自己的集合编码成OKVS发送给Receiver,Receiver可以查询自己的集合元素是否在OKVS中。如果存在,那么查询结果是1,否则查询结果是一个随机数。
具体地, PSI协议(简化版本)工作如下:
1. Sender将自己的集合编码成S使得
;
2. Sender发送S给Receiver;
3. Receiver对自己集合中的每一个元素进行解码得
;
4. 若说明
,否则
。
乍一看,似乎OKVS自身就可以执行PSI了,但这种方案还是有一定穷举风险。发送方可以使用 Encode 算法对 向量X 和 向量H(X) 进行处理得到 向量P,并把 向量P 发送给接收方;接收方使用 向量Y 和 Decode 算法能得到 向量V,然后将 向量V 发送给发送方。最后,发送方通过比较向量 H(X) 和 向量V,可以计算出它们的交集。然而,这样的方案不能抵御穷举攻击,换而言之,需要一些密码组件来保护 OKVS。
这引出了下一个组件 VOLE。VOLE 也是一种双方协议,通过执行该协议,左侧的一方会得到 向量A 和 向量B,右侧的一方会得到和和向量C,同时,它们还满足
的关系。

图12. VOLE关系图
需要注意的是,向量A 是属于域,当
时,称之为 VOLE 关系;而当
时,又称之为 subfield-VOLE 关系。同时,这两种 VOLE 也对应了RR22-PSI 中的两种使用模式,分别为快速模式和低带宽模式。
快速模式(FastMode):
低带宽模式(LowComm/Small Domain):
VOLE 的构造:
通过Base VOLE协议得到少量的VOLE:
- 基础VOLE协议用于生成初始的VOLE关系。这些初始的VOLE关系数量较少,但它们是后续步骤的基础。
通过Multi-Point VOLE协议得到“稀疏”的VOLE关系:
- Multi-Point VOLE协议用于扩展基础VOLE关系,以获得更多的VOLE关系。这些关系通常是稀疏的,即其中的一部分元素为零或具有特定的稀疏性结构。
通过LPN/Dual-LPN处理“稀疏”的VOLE关系,使其变成均匀随机的VOLE关系:
- 最后一步,通过LPN(Learning Parity with Noise)或Dual-LPN协议对稀疏的VOLE关系进行处理,使其变成均匀随机的VOLE关系。这一步通常涉及对VOLE关系进行某种形式的编码或变换,以确保最终的VOLE关系在统计上是均匀分布的。
有了 VOLE 关系元组信息之后,可以用其保护 OKVS。首先,发送方使用 VOLE 中的向量A' 对 OKVS 中的向量P进行掩盖,并发送给接收方。接收方使用 VOLE 中的 △ 和 向量B,计算出向量K,并使用向量K和向量Y进行 Decode,然后把 Decode 的结果 向量Y' 发给发送方。最后,发送方通过对比向量X' 和向量Y'得到交集。

3. 全匿踪PSI
随着业内对交集信息的合规性保护越来越重视,目前也开始出现一种称为全匿踪PSI的技术。在这种技术中,比较常见的是电路PSI(Circuit-PSI),这类PSI允许两个参与方计算交集,最终交集结果未泄露给任何一方,而是在参与方之间秘密共享,保证元素信息、交集基数等均未被泄露。其后可在秘密共享的交集结果上执行求势、求交集和、门限等功能,但不泄露交集信息。此类PSI协议虽然通信、计算、内存开销较大,但可在交集秘密共享上执行任意的对称函数计算。
Circuit-PSI是一种框架,实现的方法又有很多,其中涉及到OPPRF的不经意可编程伪随机函数技术以及多方安全计算技术。这类求交算法相对来说复杂度会更高,后续有机会再继续做分享。这里列举一些该领域的参考文献【3、13、14、15、16、17、18、19】,有兴趣的同学可以继续研读学习。
总结:
本文对PSI应用、原理做了相应分析,相信能够对行业内常用的PSI以及内在原理有了一定的认知,对于后续理解更多的PSI算法希望有一定的帮助。
4. 参考文献
【1】Efficient Batched Oblivious PRF with Applications to Private Set Intersection
【2】Private Set Intersection in the Internet Setting From Lightweight Oblivious PRF
【3】Blazing Fast PSI from Improved OKVS and Subfield VOLE
【4】「隐私计算基础理论」安全求交集和匿踪查询
【5】RR22 Blazing Fast PSI 实现介绍
【6】技术分享 | 隐私集合求交(PSI)技术体系整理
【7】libPSI 开源库中实现的协议
【8】不经意传输协议研究综述
【9】不经意传输扩展(OTE)-不经意伪随机函数(OPRF)-隐私集合求交(PSI)
【10】KKRT-PSI
【11】透明伪随机函数(OPRF)与隐私集合求交(PSI)
【12】隐私求交问题(PSI)与透明键值对存储(OKVS)
【13】Circuit-PSI With Linear Complexity via Relaxed Batch OPPRF
【14】VOLE-PSI: Fast OPRF and Circuit-PSI from Vector-OLE
【15】安全求交、联邦学习模型的训练方法及系统、设备及介质
【16】一种安全高效的全匿踪纵向联邦学习方法
【17】iPrivJoin: An ID-Private Data Join Framework for Privacy-Preserving Machine Learning
【18】一种数据处理方法、装置、计算机设备以及可读存储介质
【19】基于国密的高效匿踪联邦学习方法、系统及相关设备