Matrix - Vector Multiplication
矩阵-向量乘法是线性代数中的基本操作。它用于将一个矩阵与一个向量相乘。乘法的结果是与输入向量大小相同的向量。
矩阵和向量的乘法如图1所示。
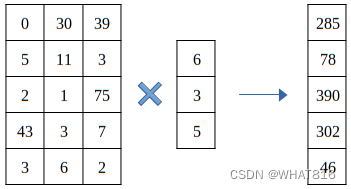
图1
基础kernel与共享内存kernel
执行矩阵-向量乘法的基础kernel是使用单个线程执行输出向量的单个元素的乘法。这意味着所需的线程数等于输出向量中的元素数。线程以一维网格排列,每个线程被分配一个唯一的索引。线程的索引用于访问输入矩阵的对应行。对行和向量进行乘法操作,结果存储在输出向量的对应元素中。
在这种基础kernel中,每个线程将加载整个输入向量。这并不高效,因为输入向量被多次加载。为了避免这种情况,我们可以使用一个tile将输入向量存储在共享内存中。tile是一个大小等于块中线程数的一维数组。向量被加载到tile中,每个线程使用tile执行乘法。
Code
Host代码初始化输入矩阵和向量,随机赋值并调用kernel执行乘法。输入矩阵以线性化格式存储。
#include <iostream>
#include <cstdio>
#include <ctime>
#include <cmath>
#include <cuda_runtime.h>
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include "image2gray.cuh"
#include "helper_cuda.h"
#include "error.cuh"
const int FORTIME = 50;
int main(int argc, char* argv[])
{
int rows, cols, t_x;
rows = 4096;
cols = 4096;
t_x = 1024;
thrust::host_vector<float> h_in_mat(rows * cols);
thrust::host_vector<float> h_in_vec(cols);
srand(time(NULL));
for (int i = 0; i < rows * cols; i++) {
h_in_mat[i] = rand() / (float)RAND_MAX;
if (i < cols)
h_in_vec[i] = rand() / (float)RAND_MAX;
}
thrust::host_vector<float> h_out(rows);
for (int i = 0; i < rows; ++i)
for (int j = 0; j < cols; ++j)
h_out[i] += h_in_mat[i * cols + j] * h_in_vec[j];
thrust::device_vector<float> d_in_mat = h_in_mat;
thrust::device_vector<float> d_in_vec = h_in_vec;
thrust::device_vector<float> d_out(rows);
dim3 block(t_x);
dim3 grid((rows + block.x - 1) / block.x);
cudaEvent_t start, stop;
checkCudaErrors(cudaEventCreate(&start));
checkCudaErrors(cudaEventCreate(&stop));
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++)
mat_vec_mul << <grid, block >> > (
thrust::raw_pointer_cast(d_out.data()),
thrust::raw_pointer_cast(d_in_mat.data()),
thrust::raw_pointer_cast(d_in_vec.data()),
rows, cols);
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
float elapsed_time;
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
std::cout << "elapsed_time:" << elapsed_time / FORTIME << std::endl;
bool success = true;
for (int i = 0; i < rows; ++i)
if (abs(h_out[i] - d_out[i]) >= 0.001) {
std::cout << "Error at " << i << ": " << h_out[i] << " != " << d_out[i] << " (Mat Vec Mul)" << std::endl;
success = false;
break;
}
if (success)
std::cout << "Success (Mat Vec Mul)" << std::endl;
checkCudaErrors(cudaEventRecord(start));
for (int i = 0; i < FORTIME; i++)
mat_vec_mul_tiles << <grid, block, block.x * sizeof(float) >> > (
thrust::raw_pointer_cast(d_out.data()),
thrust::raw_pointer_cast(d_in_mat.data()),
thrust::raw_pointer_cast(d_in_vec.data()),
rows, cols);
checkCudaErrors(cudaEventRecord(stop));
checkCudaErrors(cudaEventSynchronize(stop));
checkCudaErrors(cudaEventElapsedTime(&elapsed_time, start, stop));
std::cout << "elapsed_time:" << elapsed_time / FORTIME << std::endl;
success = true;
for (int i = 0; i < rows; ++i)
if (abs(h_out[i] - d_out[i]) >= 0.001) {
std::cout << "Error at " << i << ": " << h_out[i] << " != " << d_out[i] << " (Mat Vec Mul Tiles)" << std::endl;
success = false;
break;
}
if (success)
std::cout << "Success (Mat Vec Mul Tiles)" << std::endl;
return 0;
}Note:
helper_cuda.h 与error.cuh头文件为错误查验工具。后续会发布到Github。
去除checkCudaErrors等错误查验函数不影响程序运行。
下面显示了两个kernel。
template<typename T> __global__
void mat_vec_mul(T *out, T *in_mat, T *in_vec, int m, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i >= m) return;
T temp = 0;
for (int k = 0; k < n; ++k)
temp += in_mat[i * n + k] * in_vec[k];
out[i] = temp;
}
template<typename T> __global__
void mat_vec_mul_tiles(T *out, T *in_mat, T *in_vec, int m, int n) {
extern __shared__ uint8_t tiles_uint8[];
T *tiles = reinterpret_cast<T*>(tiles_uint8);
int i = blockIdx.x * blockDim.x + threadIdx.x;
T res = 0;
int n_phases = (n + blockDim.x - 1) / blockDim.x;
for (int phase = 0; phase < n_phases; ++phase){
int elem_idx = phase * blockDim.x + threadIdx.x;
tiles[threadIdx.x] = elem_idx < n ? in_vec[elem_idx] : 0;
__syncthreads();
if(i < m)
for (int k = 0; k < blockDim.x && phase * blockDim.x + k < n; ++k)
res += in_mat[i * n + phase * blockDim.x + k] * tiles[k];
__syncthreads();
}
out[i] = res;
}基础kernel
kernel首先计算线程的索引。如果索引在输出向量的范围内,则执行乘法。
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i >= m) return;将矩阵的每一列与向量相应元素相乘,并将结果存储在输出向量的相应元素中。
T temp = 0;
for (int k = 0; k < n; ++k)
temp += in_mat[i * n + k] * in_vec[k];
out[i] = temp;共享内存kernel
kernel首先计算线程的索引。kernel不会检查边界条件,因为需要加载向量到tile中的超出输出向量范围的线程。
int i = blockIdx.x * blockDim.x + threadIdx.x;现在,乘法被分成几个阶段。在每个阶段,线程将把向量的单个或零个元素(如果它们超出范围)加载到tile中。然后线程将执行加载到tile中的向量和输入矩阵行的相应元素的乘法。结果存储在输出向量的相应元素中。
在加载向量到tile中和执行乘法时,线程都会执行边界检查,以避免超出范围的访问。
T res = 0;
int n_phases = (n + blockDim.x - 1) / blockDim.x;
for (int phase = 0; phase < n_phases; ++phase){
int elem_idx = phase * blockDim.x + threadIdx.x;
tiles[threadIdx.x] = elem_idx < n ? in_vec[elem_idx] : 0;
__syncthreads();
if(i < m)
for (int k = 0; k < blockDim.x && phase * blockDim.x + k < n; ++k)
res += in_mat[i * n + phase * blockDim.x + k] * tiles[k];
__syncthreads();
}
out[i] = res;性能分析
运行时间:
矩阵维度:4096 × 4096
向量维度:4096
线程块维度:1024

由运行时间分析,引入共享内存效果比较明显,而且经测试输入向量维度越大,共享内存效果越明显。
Note:单次运行可能因为设备启动原因,各种算法运行时间差异较大,可采用循环20次以上取平均值。
笔者采用设备:RTX3060 6GB
PMPP项目提供的分析
kernel的性能是使用NvBench项目在多个gpu中测量的。研究的性能测量方法有:
内存带宽:每秒传输的数据量。
内存带宽利用率:占用内存带宽的百分比。
基础kernel
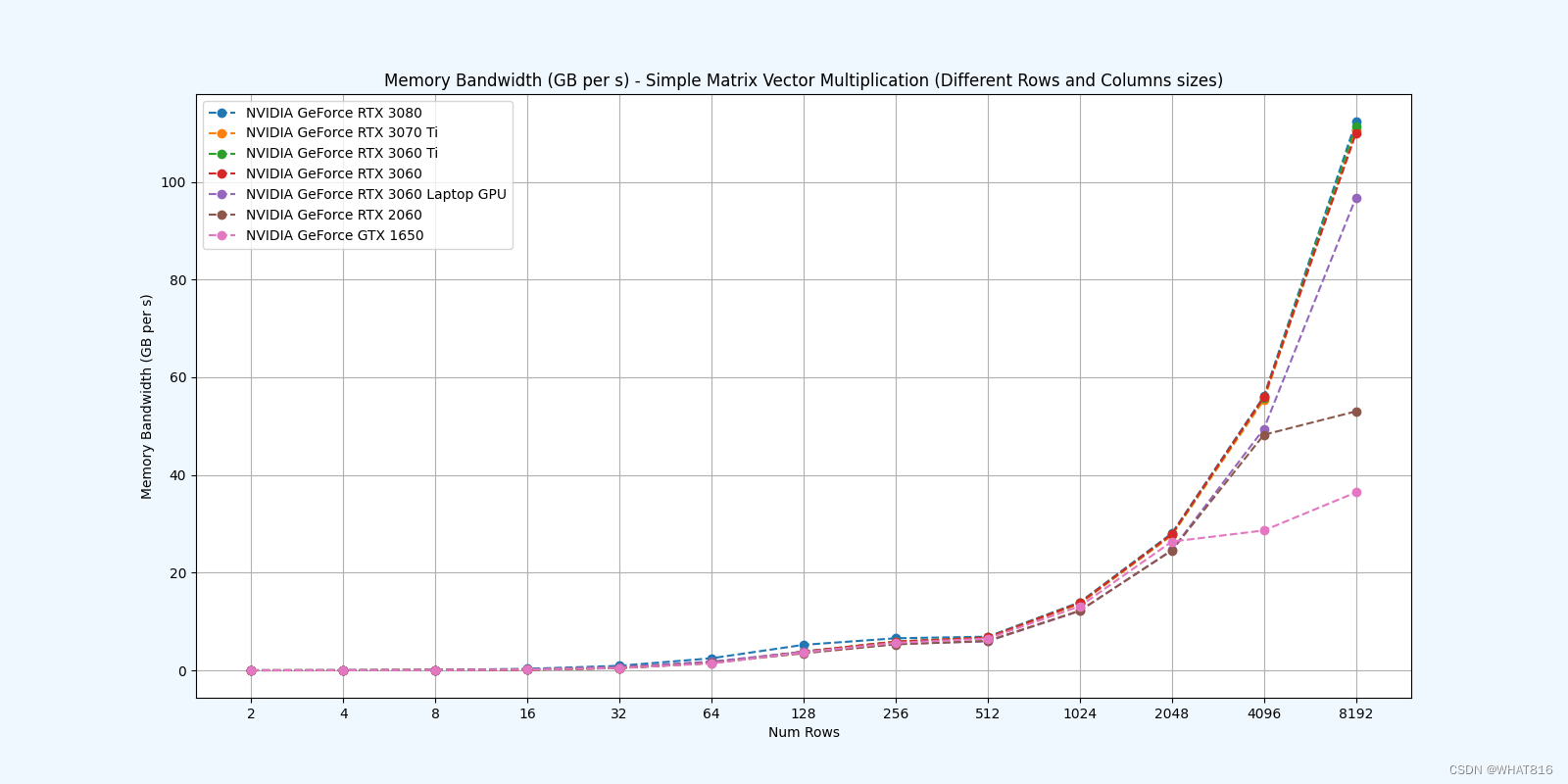

共享内存kernel


参考文献:
1、大规模并行处理器编程实战(第2版)
2、PPMP



![深入解析.[datastore@cyberfear.com].mkp勒索病毒:威胁与防范](https://img-blog.csdnimg.cn/direct/279ed0fe9ef84c489190e53c58884d7d.png)






![AGI 之 【Hugging Face】 的【Transformer】的 [ Transformer 架构 ] / [ 编码器 ]的简单整理](https://img-blog.csdnimg.cn/direct/15ee1c3725ec414bb1f0864b4892249c.jpeg)