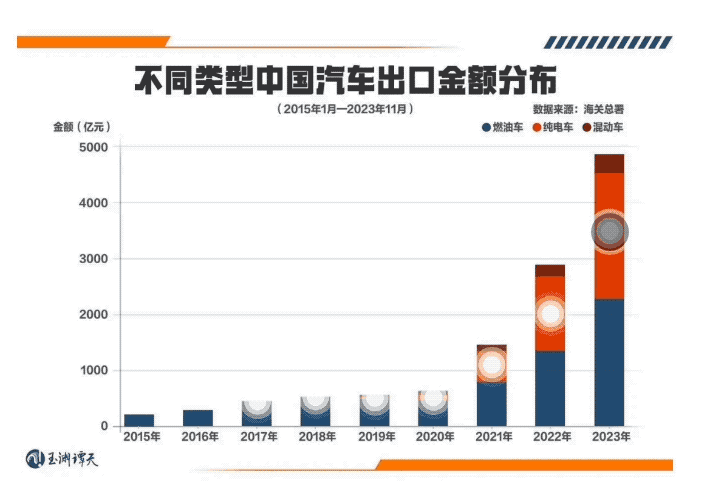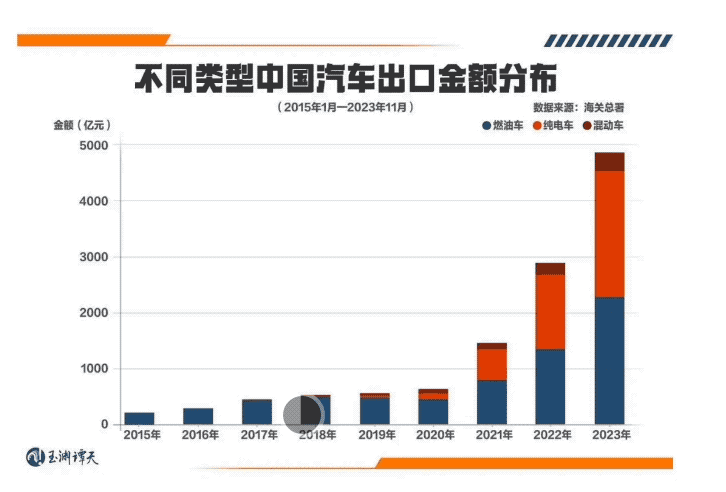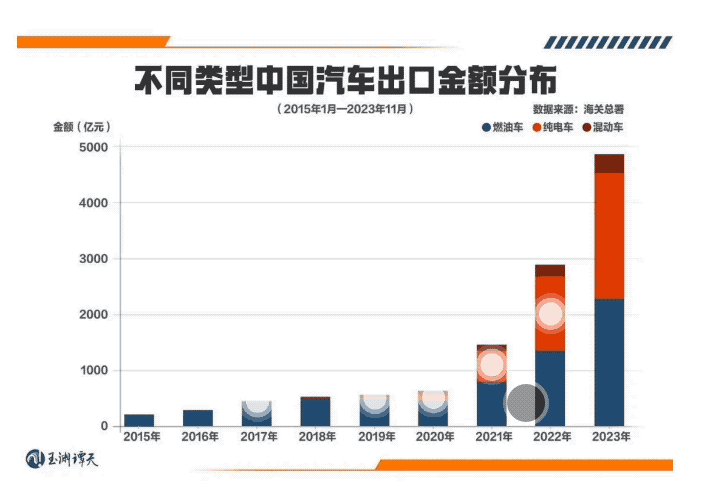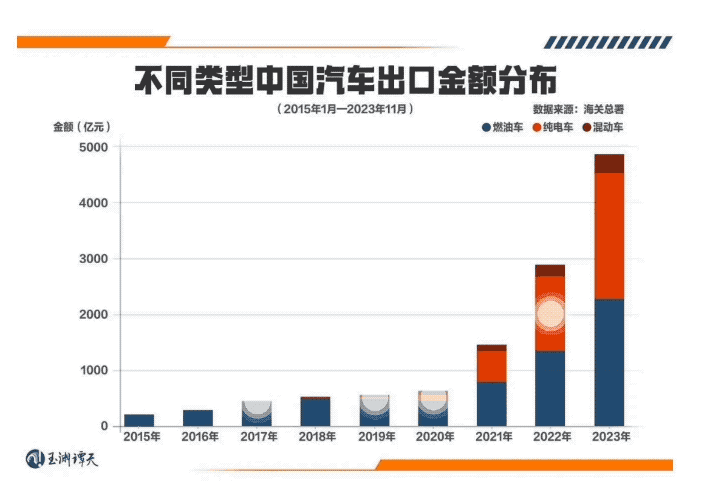
引言
在现代人工智能的发展中,构建大规模GPU集群是提升计算能力的关键手段。今天我们探讨如何搭建一个包含10万个H100 GPU的集群。这个项目不仅涉及巨大的资本支出,还面临电力供应、并行化处理、网络拓扑结构以及可靠性和恢复等多方面的挑战。通过深入分析这些问题,本文将为大家揭示构建如此庞大集群的复杂性和关键技术。
电力挑战
搭建一个10万卡的H100 GPU集群,每年的耗电量大约为1.59太瓦时,按照美国电力标准费率计算,每年用电成本达到1.24亿美元。这样的电力消耗不仅要求稳定的电力供应,还需要有效的电力管理策略。
关键部件的功耗
- GPU功耗:每张H100的功耗为700W。
- 服务器整体功耗:包括CPU、网卡、供电单元等,约为575W。
- 其他设备:存储服务器、网络交换机、CPU节点、光纤收发器等,约占总IT功耗的10%。
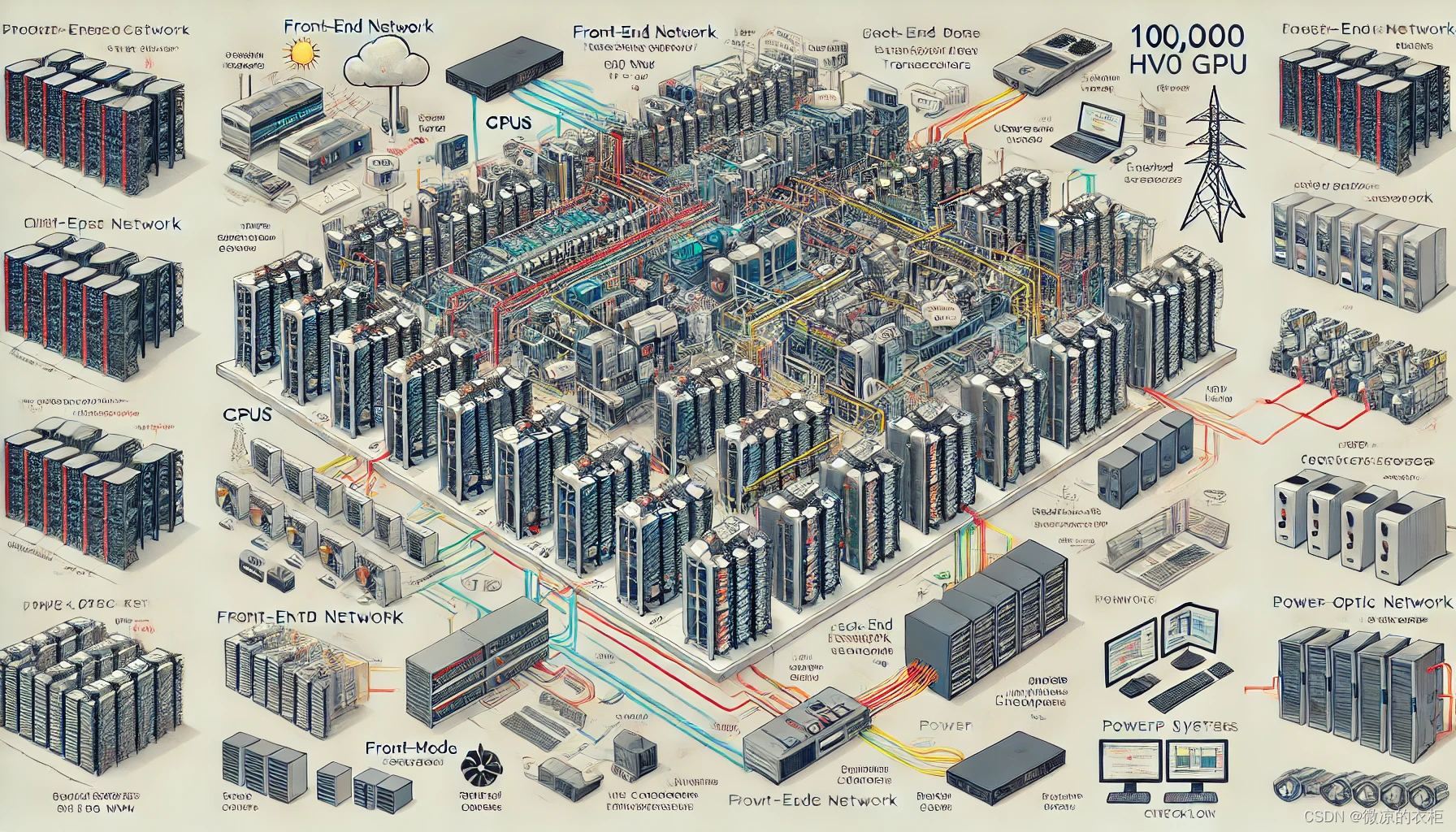
由于单栋数据中心无法承受150兆瓦的设备功率,10万GPU集群通常需要分布在整个园区中,而非单座大楼。
网络拓扑结构
为了实现高效的数据传输和计算性能,网络拓扑设计至关重要。以下是主要的网络拓扑结构及其特点:
多层交换机架构
- 小型集群:使用多模收发器,通过一层或两层交换机以400G的速度将每个GPU连接在一起。
- 大型集群:需要增加更多层的交换机,并使用长距离收发器。通常每栋大楼包含一个或多个pod,通过较为廉价的铜缆或多模收发器连接形成“计算岛”。
并行化挑战
在训练大规模模型时,需要采用数据并行、张量并行和流水线并行等多种并行化方式:
- 数据并行:每个GPU拥有模型权重的全部副本,分别保存一部分数据,前向计算过程中每个GPU独自工作,梯度更新时再将所有GPU计算出的梯度相加更新。
- 张量并行:神经网络中每层的权重和计算分布在多个GPU上,设备间需要多次归约,适用于高带宽、低延迟的网络环境。
- 流水线并行:将前向计算看成流水线,每个GPU负责其中的一环,完成计算后将结果传递给下一个GPU。
为了最大限度地提高模型的FLOP利用率,三种并行模式通常结合使用,形成3D并行。
可靠性与恢复
由于大规模集群的复杂性,可靠性和故障恢复至关重要。常见的可靠性问题包括GPU HBM ECC错误、GPU驱动器卡死、光纤收发器故障、网卡过热等。
- 热备用节点和冷备用组件:保持较短的平均故障恢复时间,通过现场保留热备用节点和冷备用组件,发生故障时迅速切换。
- 检查点存储:频繁将检查点存储到CPU内存或NAND SSD,以防出现HBM ECC等错误。
- 内存重建:通过后端结构从其他GPU进行RDMA复制,最大限度减少数据丢失和恢复时间。
成本优化
在构建和维护10万个H100 GPU集群时,成本优化是一个关键考量因素。以下是几个主要的成本优化策略:
- 使用Cedar Fever-7网络模块:代替ConnectX-7网络卡,减少OSFP插槽和收发器数量,从而降低初始作业失败的概率。
- 采用Spectrum-X以太网:相比InfiniBand,Spectrum-X以太网提供更高的端口容量和更具成本效益的解决方案。
- 部署基于博通Tomahawk 5的交换机:与Nvidia Spectrum-X和InfiniBand相比,具有更低的成本,同时提供相似的网络性能。
总结
搭建一个10万个H100 GPU的集群,需要在电力供应、网络拓扑、并行化处理、可靠性和成本优化等多方面进行综合考虑。通过合理设计和优化,可以在保持高性能的同时,显著降低成本和提高系统的可靠性。
构建如此庞大的集群是一项复杂且昂贵的工程,但它对于推动人工智能技术的发展和应用具有重要意义。希望本文能够为相关从业者提供有价值的参考,帮助大家更好地理解和应对构建大型GPU集群的挑战。