一、 SSH免密登录配置
1 生成公钥和秘钥(在hadoop101上)
# su star
# cd /home/star/.ssh
# ssh-keygen -t rsa
2 公钥和私钥
公钥id_rsa.pub
私钥id_rsa
3 将公钥拷贝到目标机器上(在hadoop101上)
# ssh-copy-id hadoop101
# ssh-copy-id hadoop102
# ssh-copy-id hadoop103
4 生成后将公钥拷贝到目标机器上(在hadoop102上)
# ssh-keygen -t rsa
# ssh-copy-id hadoop101
# ssh-copy-id hadoop102
# ssh-copy-id hadoop1035 生成后将公钥拷贝到目标机器上(在hadoop103上)
# ssh-keygen -t rsa
# ssh-copy-id hadoop101
# ssh-copy-id hadoop102
# ssh-copy-id hadoop103
6 生成后将公钥拷贝到目标机器上(在hadoop101上)
生成root用户的公钥和私钥
# su root
# ssh-keygen -t rsa
# ssh-copy-id hadoop101
# ssh-copy-id hadoop102
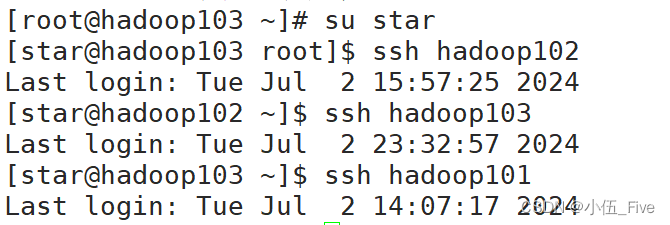
# ssh-copy-id hadoop1037 测试免密登录(在hadoop101上)
# su star
# ssh hadoop102
# ssh hadoop103
# ssh hadoop1018 .ssh文件夹下的文件解释
==========================
authorized_keys 存放授权过的免密登录的服务器公钥
id_rsa 生成的私钥
id_rsa.pub 生成的公钥
known_hosts 记录ssh访问过的计算机的公钥
====================================
二、Hadoop集群配置
1 配置core-site.xml(在hadoop101上)
# cd $HADOOP_HOME/ect/hadoop/
# vim core-site.xml
==========配置内容如下=================
<!--1.指定 NameNode 的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9820</value>
</property>
<!--2.指定 hadoop 数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!--3.配置 HDFS 网页登录使用静态用户为 star-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>star</value>
</property>
<!--4.配置 star(superUser)允许通过代理访问的主机节点-->
<property>
<name>hadoop.proxyuser.star.hosts</name>
<value>*</value>
</property>
<!--5.配置 star(superGroup)允许通过代理用户所属组-->
<property>
<name>hadoop.proxyuser.star.groups</name>
<value>*</value>
</property>
<!--6.配置 star(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.star.groups</name>
<value>*</value>
</property>
==================================================
2 配置yarn-site.xml(在hadoop101上)
# cd $HADOOP_HOME/ect/hadoop/
# vim yarn-site.xml
=========配置内容如下=============
<!--1.指定 MR 走 shuffle 机制-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--2.指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!--3.环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOM
E,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YAR
N_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--4.yarn 容器允许分配的最大最小内存-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!--5.yarn 容器允许管理的物理内存大小-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!--6.关闭 yarn 对物理内存和虚拟内存的限制检查-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
====================================================
3 配置hfds-site.xml(在hadoop101上)
# cd $HADOOP_HOME/ect/hadoop/
# vim hdfs-site.xml
===========配置内容如下==========
<!--1.NameNode nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!--2.SecondaryNameNode 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
<!--3.设置 HDFS 不启动权限检查-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
==========================================
4 配置mapred-site.xml(在hadoop101上)
# cd $HADOOP_HOME/ect/hadoop/
# vim mapred-site.xml
==========配置内容如下=========
<!--1.指定 Mapreduce 程序运行在 Yarn 之上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
=============================
5 将集群文件进行分发(在hadoop101上)
# xsync.sh /opt/module/
6 查看分发配置文件的情况
在hadoop102上
# cd /opt/module/hadoop-3.1.3/etc/hadoop
# cat core-site.xml
在hadoop103上
# cd /opt/module/hadoop-3.1.3/etc/hadoop
# cat core-site.xml
三、 Hadoop集群部署
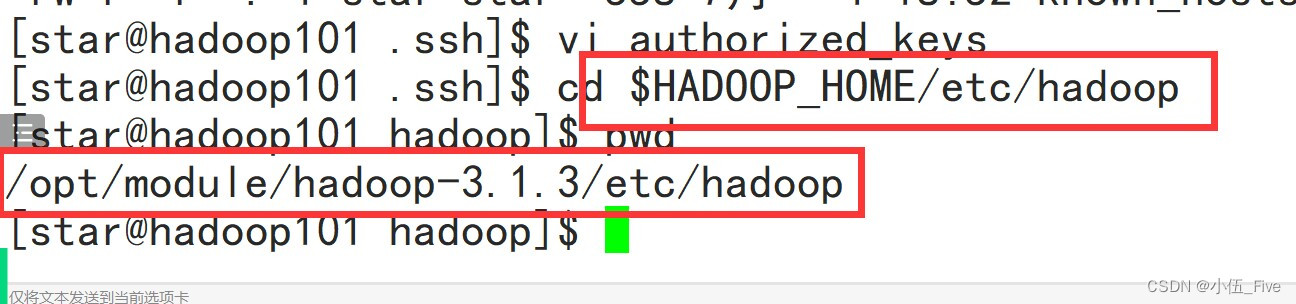
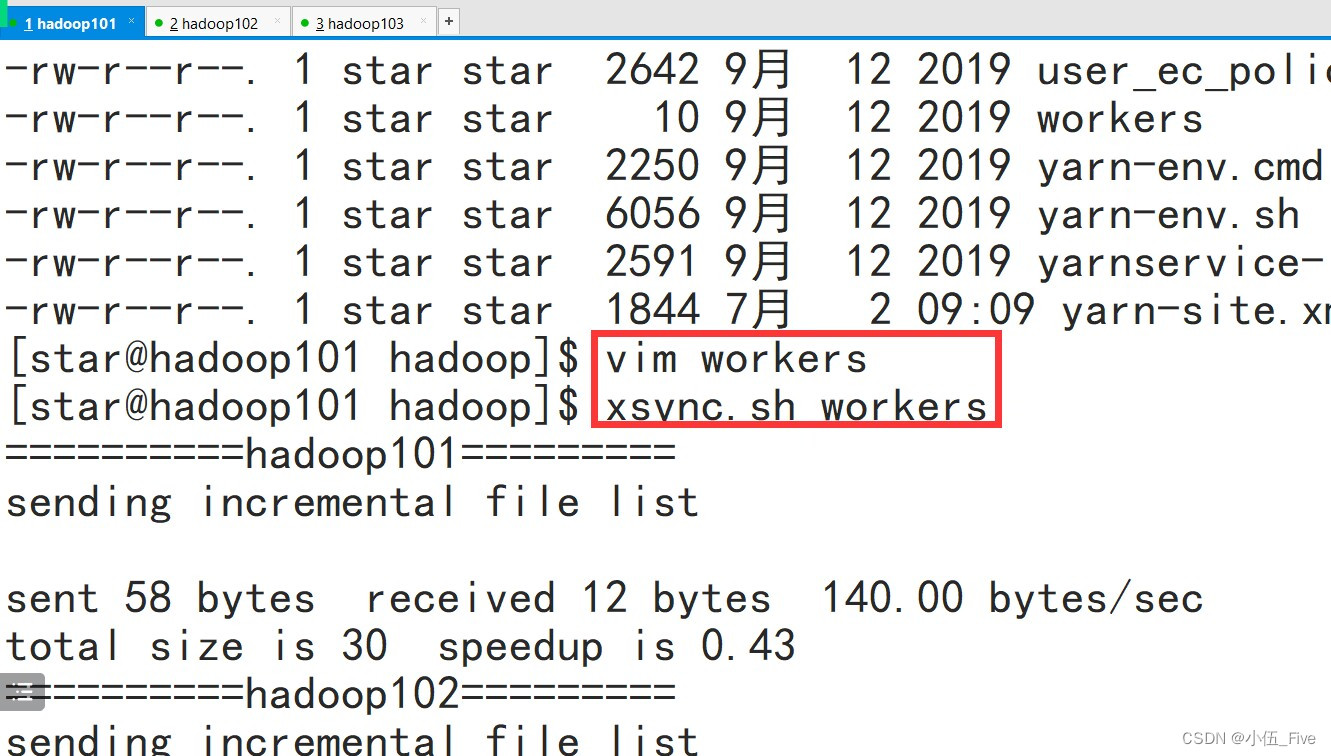
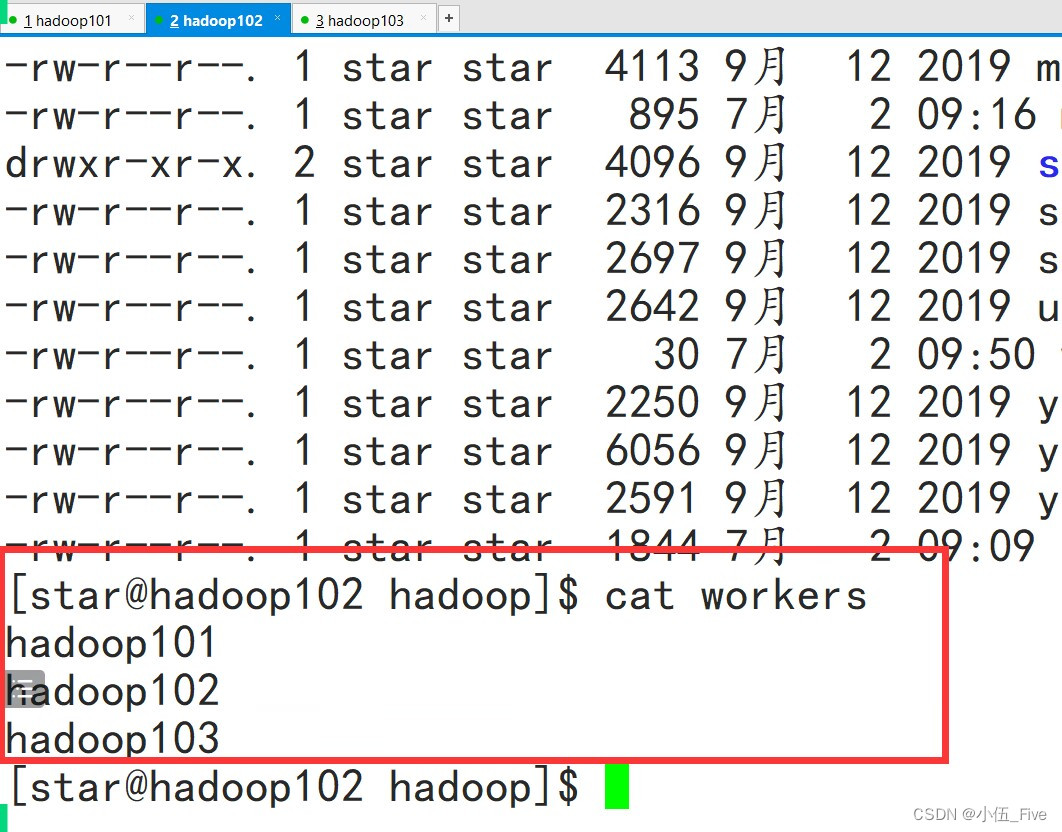
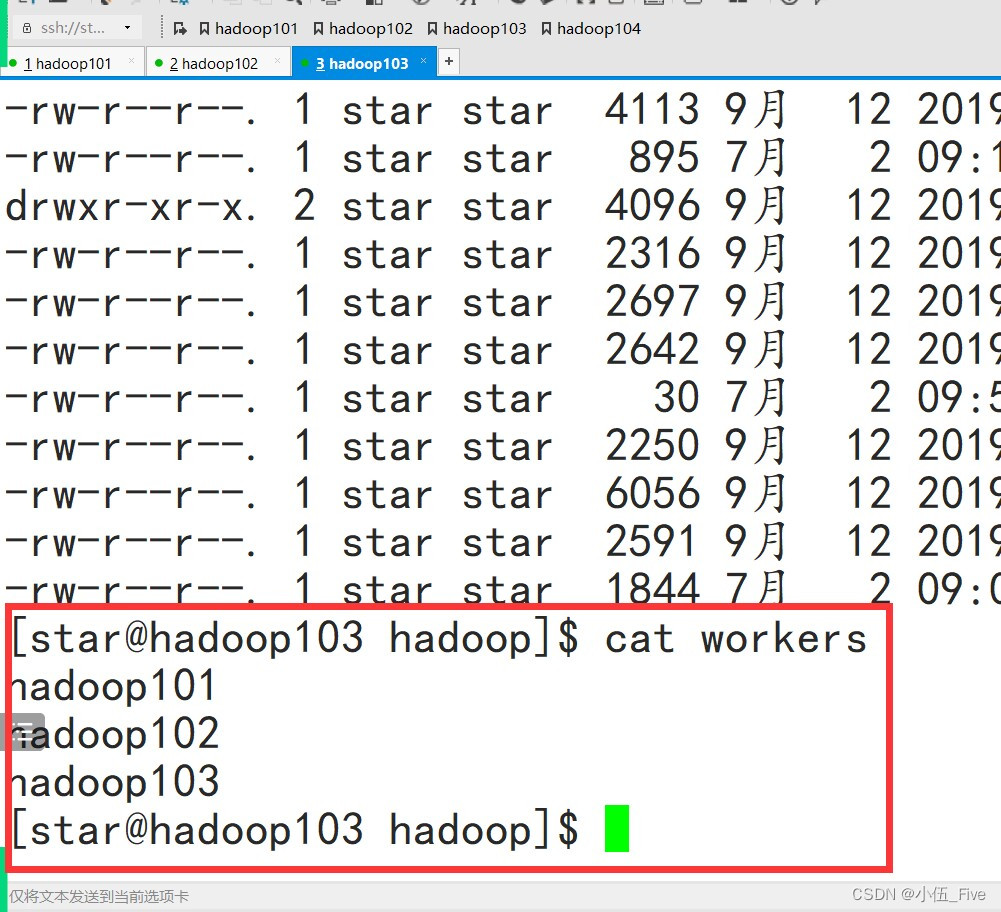
1 配置works(在hadoop101上)
# cd /opt/module/hadoop-3.1.3/ect/hadoop/
# vim workers
=========配置内容如下(删除原先内容)====
hadoop101
hadoop102
hadoop103
=====注意保存时不允许有空格以及空行====
将该文件进行分发
# xsync.sh /opt/module/hadoop-3.1.3/ect/hadoop/workers
2.Hadoop集群格式化(在hadoop101上)
# su star
#hdfs namenode -format
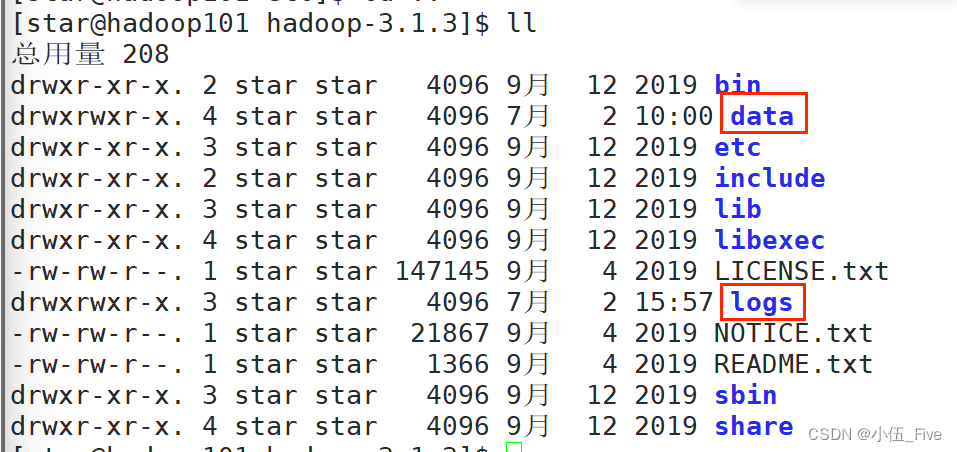
注意事项:
1.各种端口号是用.表示
2.各种配置文件tag写错了
3.若需要再次格式化则需要
先删除hadoop-3.1.3文件夹下的data和logs文件夹
4.必须使用star用户进行格式化
当格式化之后就会产生data 和 logs 文件

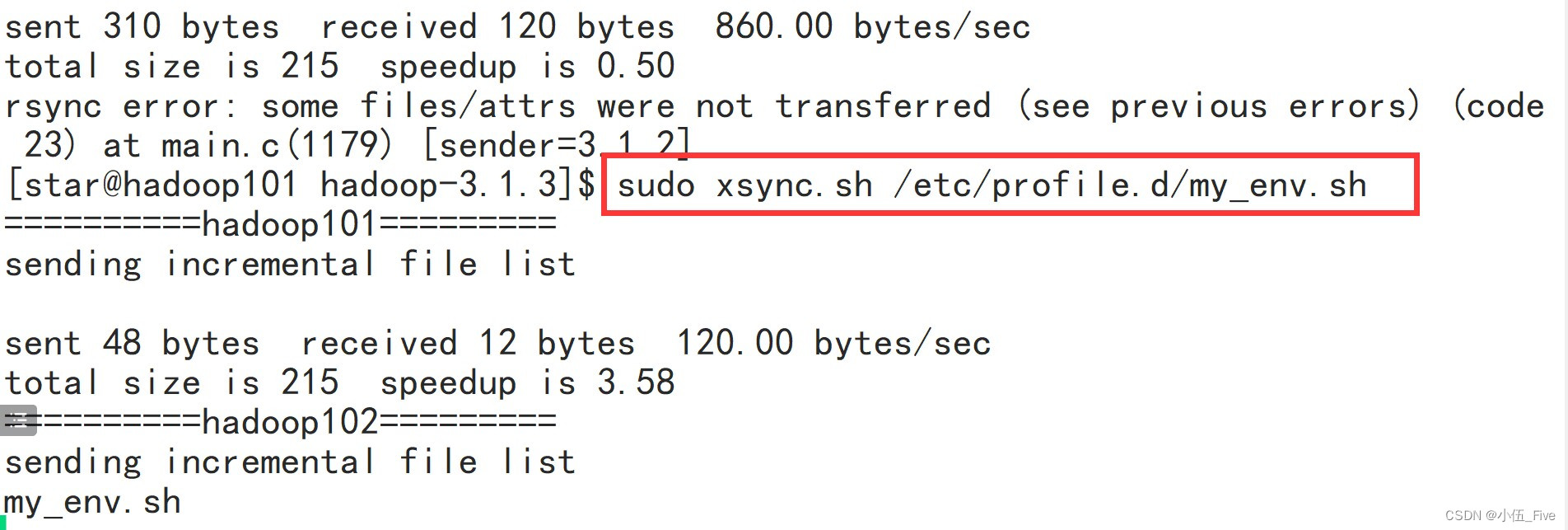
3 环境变量的分发及生效(在hadoop101上)
# sudo xsync.sh /etc/profile.d/my_env.sh
在hadoop102上
# source /etc/profile.d/my_env.sh
# java -version
# hadoop version
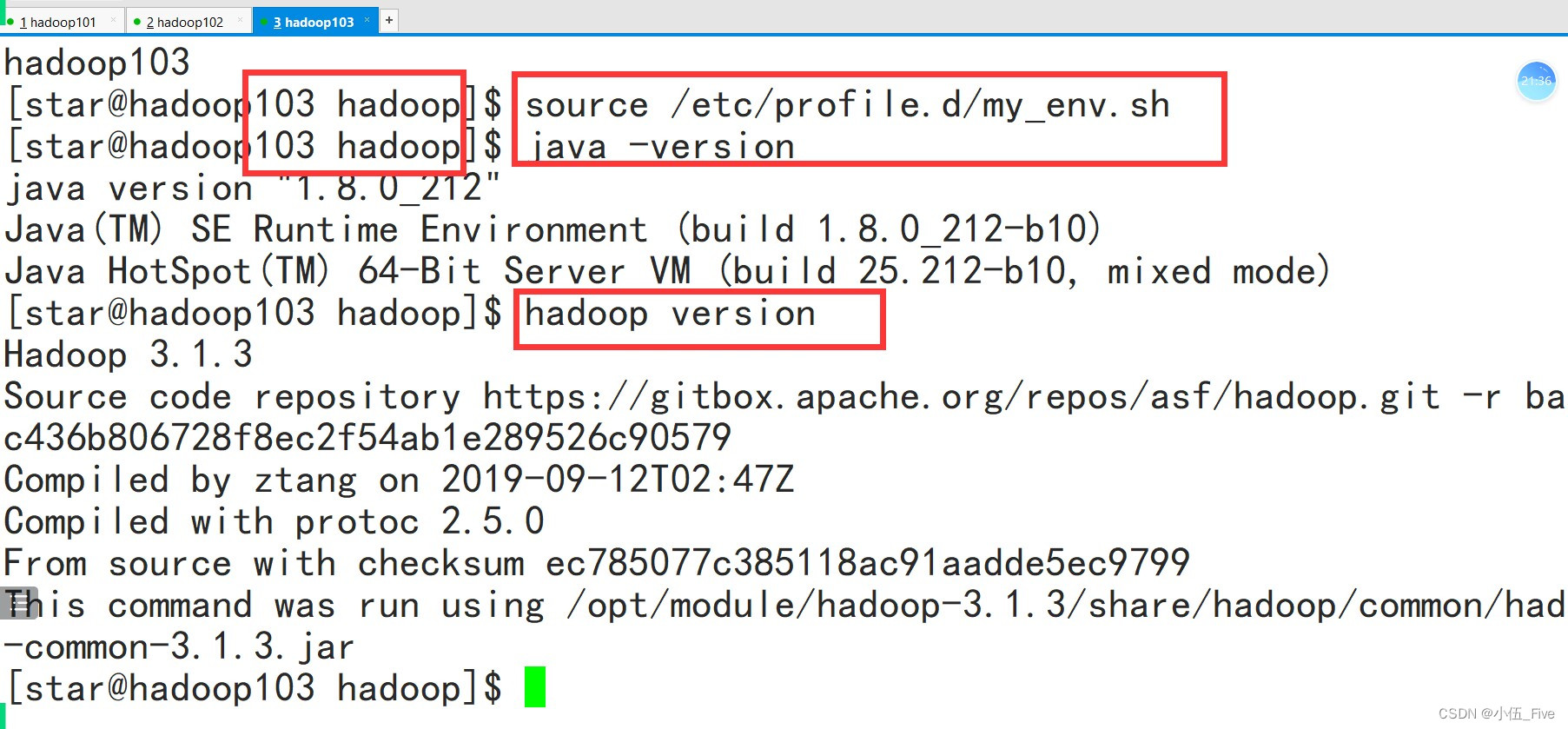
在hadoop103上
# source /etc/profile.d/my_env.sh
# java -version
# hadoop version

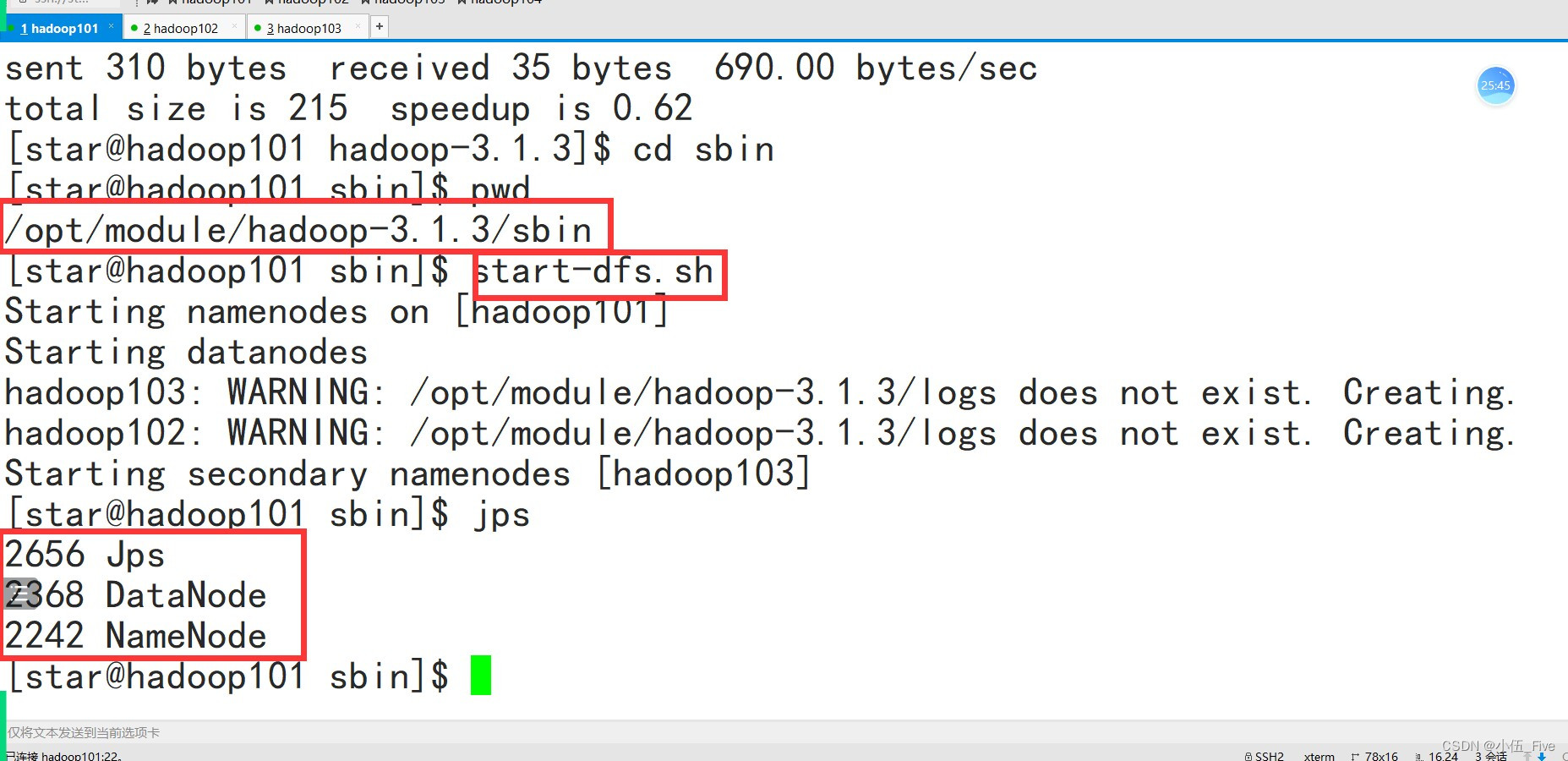
4 Hadoop分布式集群启动(在hadoop101上)
启动Hadoop集群
# cd $HADOOP_HOME/sbin
# start-dfs.sh
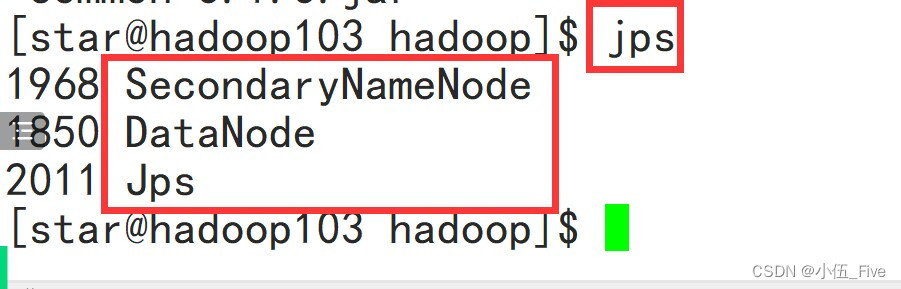
# jps

5 Yarn的启动(在hadoop102上)
启动Yarn
# cd $HADOOP_HOME/sbin
# start-yarn.sh
# jps

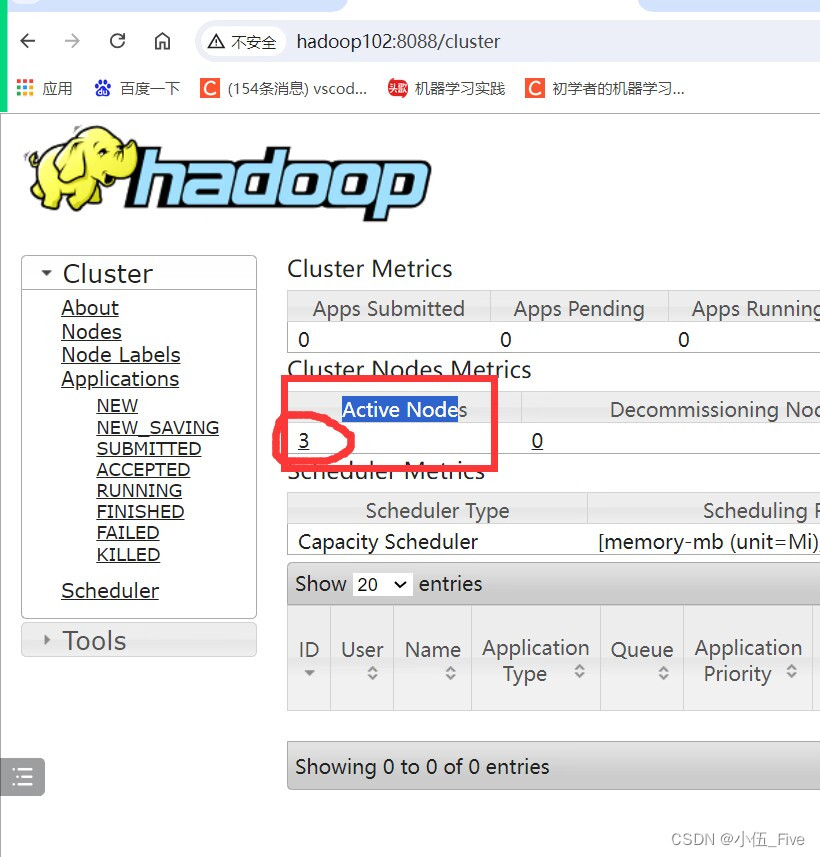
6 WEB端查看HDFS(需先启动HDFS)
http://hadoop101:9870

7 WEB端查看YARN(需先启动YARN)
http://hadoop102:8088
四、MySQL安装
1 查看是否安装过
# rpm -qa | grep mariadb mariadb-libs-5.5.56-2.el7.x86_64
# sudo rpm -e ---nodeps
2 MySQL安装包上传(在hadoop101上)
# cd /opt/software
上传到该目录mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
3 解压缩第一层包(在hadoop101上)
# cd /opt/software
# tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
4 安装MySQL文件(必须按照顺序安装 在hadoop101上)
# cd /opt/software
# sudo rpm -ivh
mysql-community-common-5.7.28-1.el7.x86_64.rpm
# sudo rpm -ivh
mysql-community-libs-5.7.28-1.el7.x86_64.rpm --force --nodeps
# sudo rpm -ivh
mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm --force --nodeps
# sudo rpm -ivh
mysql-community-client-5.7.28-1.el7.x86_64.rpm
# sudo yum install -y libaio
# sudo rpm -ivh
mysql-community-server-5.7.28-1.el7.x86_64.rpm --force --nodeps5 删除配置文件(在hadoop101上)
查看mysql所安装的目录(查看datadir的目录结果)
# vim /etc/my.cnf
删除datadir指向的目录所有文件内容
# cd /var/lib/mysql
# sudo rm -rf ./*
6 初始化数据库(在hadoop101上)
# sudo mysqld --initialize --user=mysql
7 查看初始化密码(在hadoop101上 -localhost后面)
# sudo cat /var/log/mysqld.log
8 启动MySQL的服务(在hadoop101上)
# sudo systemctl start mysqld
9 登录MySQL数据库(在hadoop101上)
# mysql -u root -p
Enter password:输入mysqld.log中的密码
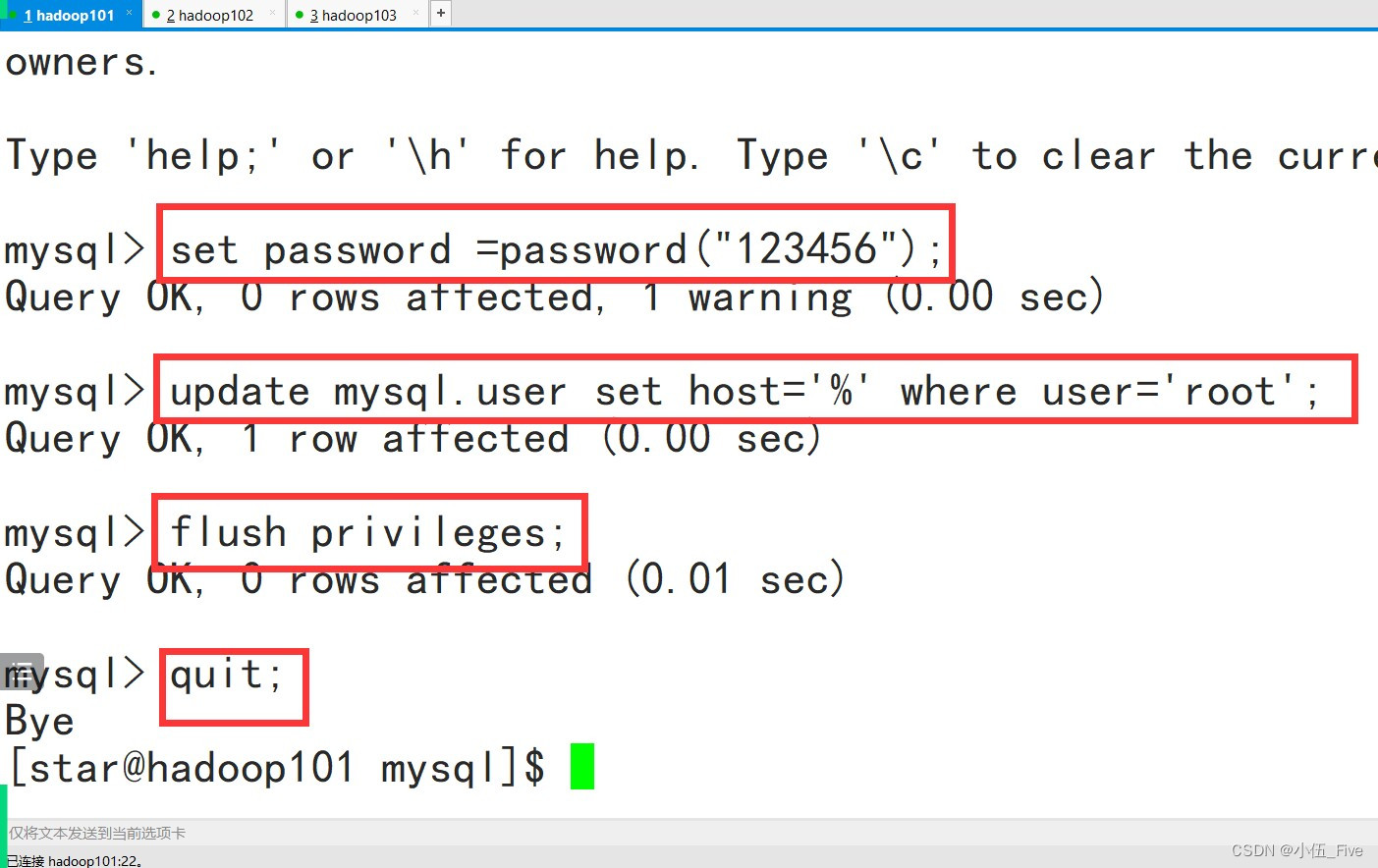
10 修改数据库密码
mysql>set password = password("123456");
11 修改数据库任意连接(在hadoop101上)
mysql>update mysql.user set host='%' where
user='root';
mysql>flush privileges;
mysql>quit;
12 测试mysql数据库(在hadoop101上)
# mysql -u root -p
Enter password:123456
mysql>quit;
数据库删除操作
五、Hive安装
1 上传安装包(在hadoop101上)
# cd /opt/software
上传apache-hive-3.1.2-bin.tar.gz压缩包
2 解压缩安装包(在hadoop101上)
# cd /opt/software
# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
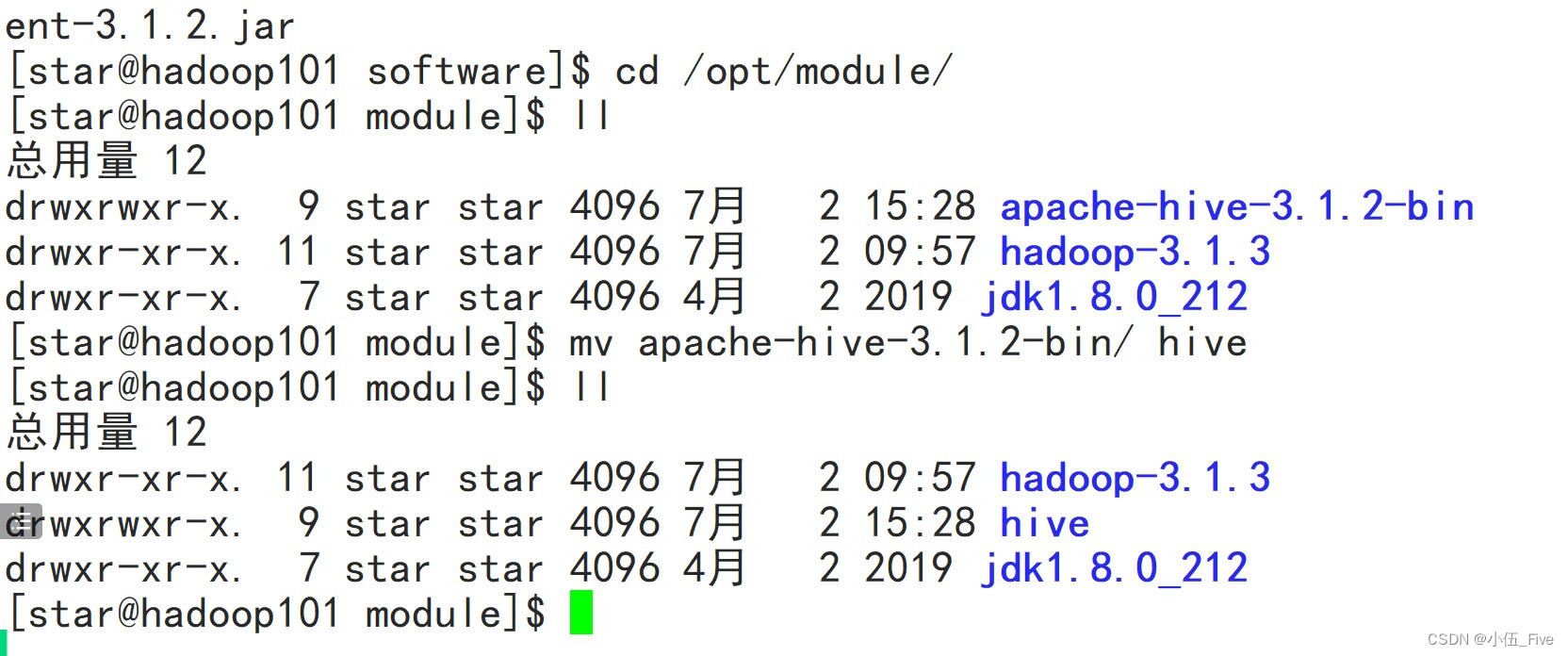
3 修改hive的文件夹名称(在hadoop101上)
# cd /opt/module/
# mv apache-hive-3.1.2-bin hive
4 添加hive的环境变量(在hadoop101上)
# sudo vim /etc/profile.d/my_env.sh
=======添加内容如下======
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
===============================
# soruce /etc/profile.d/my_env.sh
# cd $HIVE_HOME
cd $HIVE_HOME/conf
vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--1.jdbc连接的URL-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop101:3306/hivedb?useSSL=false</value>
</property>
<!--2.jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--3.jdbc连接username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--4.jdbc连接password-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--5.hive默认在HDFS的工作目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!--6.hive元数据存储的验证-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--7.元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>cd /opt/software/
5.上传mysql-connector-java-5.1.27-bin.jar
cp mysql-connector-java-5.1.27-bin.jar $HIVE_HOME/lib
cd $HIVE_HOME/lib
cd $HIVE_HOME/conf
vim hive-site.xml
mysql -u root -p123456
mysql> create database hivedb CHARACTER set utf8;
quit;
6.初始化
schematool -initSchema -dbType mysql -verbose
7.启动hadoop
start-dfs.sh
start-yarn.sh
8.启动Hive
cd /opt/module/hive
bin/hive
hive> show databases;
hive> use default ;
hive> show tables;
hive> create table test(id int);
hive> insert into test values(1);
hive> select * from test;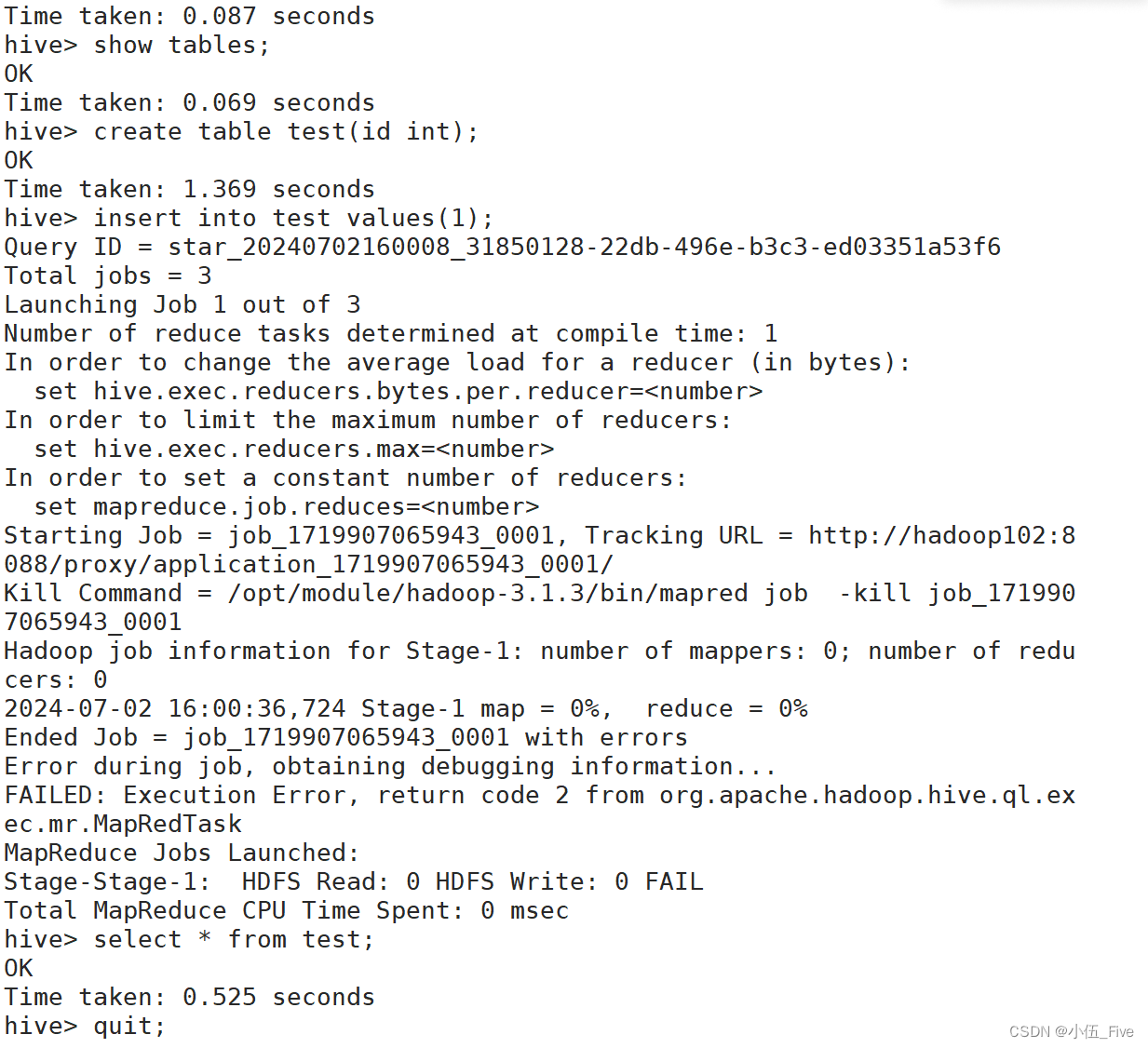
hive安装部署成功

![[C++][设计模式][访问器]详细讲解](https://img-blog.csdnimg.cn/direct/c61a50f4955e4d518965e670e83269b4.png)