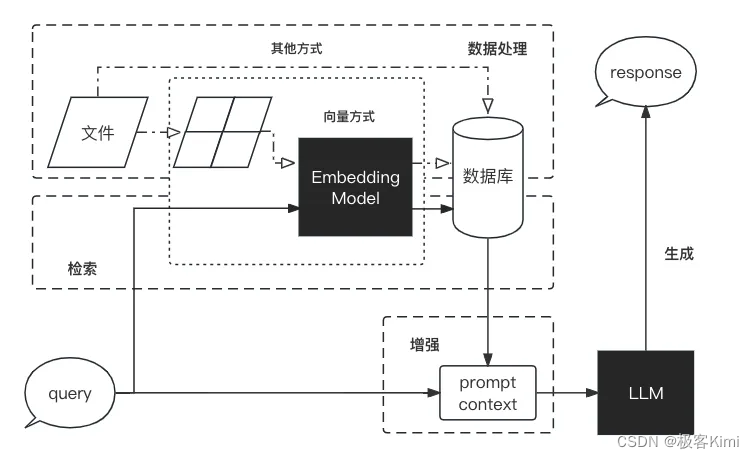
大型语言模型(LLM)相较于传统的语言模型具有更强大的能力,然而在某些情况下,它们仍可能无法提供准确的答案。为了解决大型语言模型在生成文本时面临的一系列挑战,提高模型的性能和输出质量,研究人员提出了一种新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation)。该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
RAG流程分为数据处理、检索、增强、生成:
以下网站是美团外卖中的常见问题:美团外卖 - 常见问题,我们希望利用它和大模型的自然语言理解能力来打造一套企业智能客服系统。
首先,我们如果直接在ChatGPT中问:美团外卖中在线支付取消订单后钱怎么返还?
它给的答案是:

而网站中的答案为:

所以,直接利用ChatGPT来作为智能客服系统行不通,它能够理解你的问题,但是它并不能给你确切的答案,因为对于ChatGPT来说,它并不知道企业内部的专有数据,而这个时候,我们就可以利用langchain4j来给企业内部搭一套智能客服系统。
整理数据
首先,我们需要把现有的常见文件整理成文档,可以是txt、pdf、xlsx、markdown等格式都可以,我们这里将美团外卖 - 常见问题网页中的问题和答案转成txt文件,文件为:meituan-qa.txt
功能实现
创建一个工程
直接创建一个普通的Maven工程就可以了,然后引入langchain4j的依赖和你选择的大模型依赖,我这里使用open-ai:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.27.1</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>0.27.1</version>
</dependency>
以及slf4j的依赖:
<dependency>
<groupId>org.tinylog</groupId>
<artifactId>tinylog-impl</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>org.tinylog</groupId>
<artifactId>slf4j-tinylog</artifactId>
<version>2.6.2</version>
</dependency>
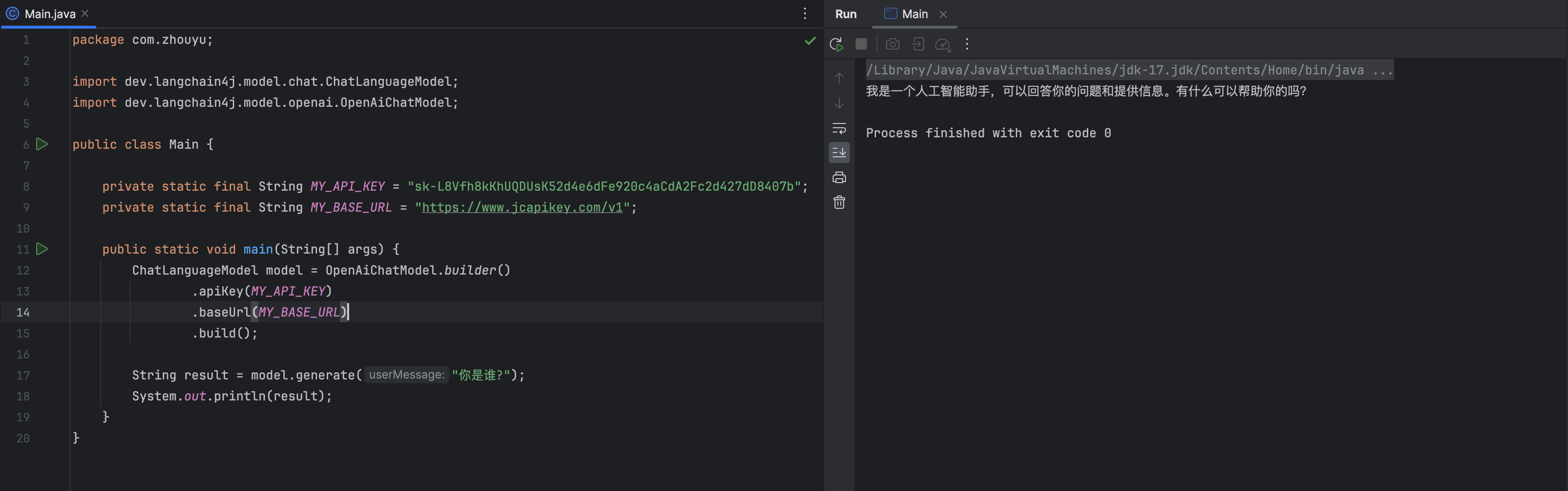
在main方法中进行简单测试:
定义Agent
我们可以定义一个智能客服专门的Agent,比如CustomerServiceAgent,后续就可以直接这个Agent来充当客服回答问题了,比如:
public interface CustomerServiceAgent {
// 用来回答问题的方案
String answer(String question);
// 利用AiServices创建一个CustomerServiceAgent的代理对象
static CustomerServiceAgent create() {
// 创建模型
ChatLanguageModel model = OpenAiChatModel.builder()
.apiKey(MY_API_KEY)
.baseUrl(MY_BASE_URL)
.build();
// 指定模型,创建并返回代理对象
return AiServices.builder(CustomerServiceAgent.class)
.chatLanguageModel(model)
.build();
}
}
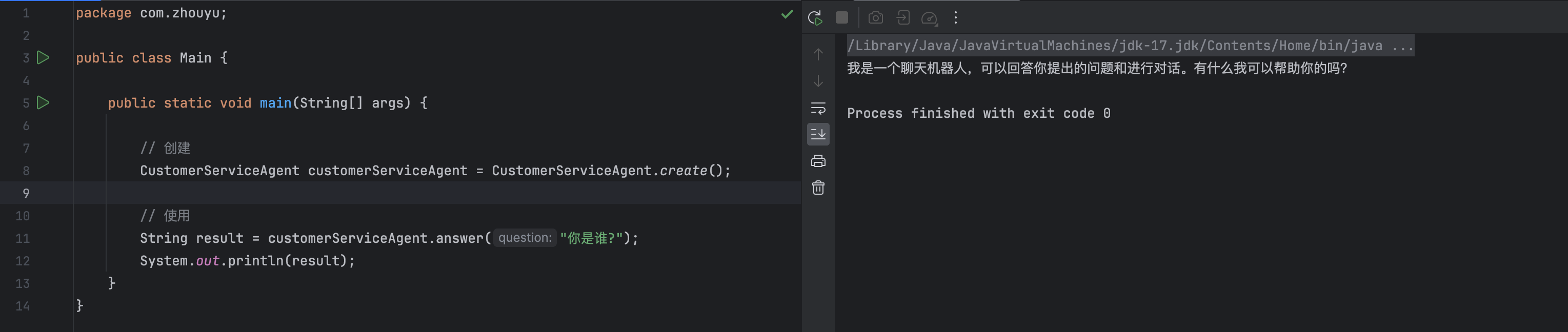
以上CustomerServiceAgent接口,提供了一个answer方法用来回答问题,同时提供了create方法用来利用AiServices生成CustomerServiceAgent代理对象,比如我们可以直接这么来创建并使用CustomerServiceAgent:
导入知识库
上面create方法创建出来的CustomerServiceAgent目前来说只拥有普通大模型的功能,此时的它还没有企业内部的信息,要想让它成为一个智能客服系统,需要将前面整理出来的问答数据送给CustomerServiceAgent。
加载并解析文件
我们需要这么来做,首先加载并解析问答txt文件:
// 加载并解析文件
Document document;
try {
Path documentPath = Paths.get(CustomerServiceAgent.class.getClassLoader().getResource("meituan-qa.txt").toURI());
DocumentParser documentParser = new TextDocumentParser();
document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser);
} catch (URISyntaxException e) {
throw new RuntimeException(e);
}
以上代码我们使用FileSystemDocumentLoader来加载本地文件,利用TextDocumentParser来解析txt文件,最终得到"meituan-qa.txt"文件所对应的Document对象。
切分文件
然后需要对文件进行切分,把"meituan-qa.txt"文件中的内容切分成问答对,"meituan-qa.txt"文件内容格式已经被我整理好了,比如:

所以我们可以使用正则表达式"\s*\R\s*\R\s*"来进行切分,我们自定义一个DocumentSplitter来实现:
public class CustomerServiceDocumentSplitter implements DocumentSplitter {
@Override
public List<TextSegment> split(Document document) {
List<TextSegment> segments = new ArrayList<>();
String[] parts = split(document.text());
for (String part : parts) {
segments.add(TextSegment.from(part));
}
return segments;
}
public String[] split(String text) {
return text.split("\\s*\\R\\s*\\R\\s*");
}
}
然后使用以下代码对Document对象进行切分就可以了:
// 切分文件
DocumentSplitter splitter = new CustomerServiceDocumentSplitter() ;
List<TextSegment> segments = splitter.split(document);
切分结果为:

其中每个TextSegment对象就表示切分之后的一段文本,在本项目中就是一个问答对。
文本向量化
得到切分之后的文本后,就可以对文本进行向量化处理了,比如你可以直接使用open-ai的向量化模型接口来进行向量化:
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey(MY_API_KEY)
.baseUrl(MY_BASE_URL)
.build();
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
得到的向量化结果为:

每个TextSegment,也就是每个问答对,对应了一个向量,而向量就是一个数字数组,如果简化一下数组的大小,比如大小为2,那么一个向量相当于一个(x,y)坐标点,放在坐标中就可以两个坐标点的距离,距离越近就表示坐标点越相似,也就是表示两个向量越相似。
当然,我们也可以使用其他的向量模型来对文本进行向量化,比如使用AllMiniLmL6V2QuantizedEmbeddingModel这个向量化模型,使用它就需要通过网络请求去进行向量化了,因为这个模型可以直接部署在你当前的应用进程内,不过需要额外添加依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2-q</artifactId>
<version>0.25.0</version>
</dependency>
然后使用以下代码即可得到文本的向量:
EmbeddingModel embeddingModel = new AllMiniLmL6V2QuantizedEmbeddingModel();
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
不同的向量化模型效果肯定是有区别,比如A1、A2两个文本,open-ai计算出来的向量可能是比较相似的,而AllMiniLmL6V2QuantizedEmbeddingModel则可能计算出来的向量之间差别较大,所以在实际工作中还是建议使用效果更好的向量化模型。
向量存储
正对拆分后的文本得到向量后,就需要把文本和向量之间的映射关系存储下来,使用CustomerServiceAgent在回答问题时,能够根据向量相似度找到和用户问题相似的知识库问题。
存储向量的代码大致为:
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.addAll(embeddings, segments);
这是把向量和文本数据直接存在了JVM内存中,本质上就是一个CopyOnWriteArrayList,该List中存储的是Entry对象,而Entry对象则分别存储了文本和向量。
实际工作中,我们肯定需要文本和向量存储可持久化的向量数据库中,你可以选择Chroma、Milvus这种专门的向量数据库,也可以使用Elasticsearch、Redis、PostgreSQL、MongoDb来存储,比如使用Redis需要这么来做。
首先普通的Redis是不支持向量存储和查询的,需要额外的redisearch模块,我这边是直接使用docker来运行一个带有redisearch模块的redis容器的,命令为:
docker run -p 6379:6379 redis/redis-stack-server:latest
注意端口6379不要和你现有的Redis冲突了。
然后就可以使用以下代码把向量存到redis中了:
EmbeddingStore<TextSegment> embeddingStore = RedisEmbeddingStore.builder()
.host("127.0.0.1")
.port(6379)
.dimension(384)
.build();
embeddingStore.addAll(embeddings, segments);
这里的dimension表示向量维度,也就是上面数组的大小,执行完以上代码后向量和文本就会存储到Redis中了。
可以使用以下命令来查看:
redis-cli FT.SEARCH embedding-index "*" LIMIT 0 10
能得到结果就证明是正常的:

如果想删除某个index和对应数据,可以:
redis-cli FT.DROPINDEX embedding-index DD
组装ContentRetriever
当把向量存入向量数据库后,就可以组装一个ContentRetriever用来后续进行内容查找了,组装代码为:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5) // 最相似的5个结果
.minScore(0.8) // 只找相似度在0.8以上的内容
.build();
以上代码将向量数据库和向量模型组装成了一个ContentRetriever,并指定ContentRetriever后续查找内容时,只返回相似度在0.8以上的前5个结果。
我现在针对以下原始问题来进行提问:
Q:余额提现到账时间是多久?
1-7个工作日内可退回您的支付账户。由于银行处理可能有延迟,具体以账户的到账时间为准。
我的问题和原始问题并不完全相同,但是我希望ContentRetriever能根据我的问题找到和问题相似的原始问题和答案:
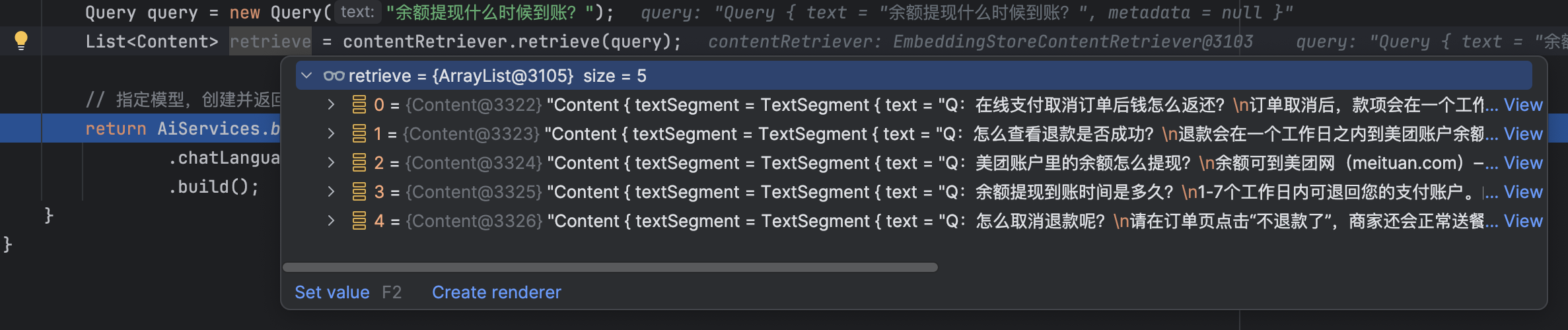
Query query = new Query("余额提现什么时候到账?");
List<Content> retrieve = contentRetriever.retrieve(query);
但是得到的答案为:

效果优化
发现答案不太理想,我们预期的原始问题并没有在这5个中,我们换成open-ai的向量化模型来试试,注意使用open-ai得到的向量维度为1536,所以记得修改dimension:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5) // 最相似的5个结果
.minScore(0.8) // 只找相似度在0.8以上的内容
.build();
改为之后得到的结果为:

发现答案就比较理想了,"余额提现到账时间是多久?"排在了第一个,说明和原始问题最匹配,这里也能看出不同向量化模型之间的差距。
当然,我们也可以从另外一个角度来进行优化,由于我们在做文本向量化时,使用的是“问题+答案”一起做的向量化,而查询的时候只使用了“问题”做向量化,由于两者不一致,导致某些较弱的向量化模型生成出来的向量偏离的更远,导致在做向量匹配时出现了差距,那能不能在做文本向量化时,也只使用“问题”来做向量化呢?
我们之前是把整个TextSegment对象一起做的向量化,相当于“问题+答案”一起做的向量化:
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
所以我们只需要将TextSegment中的问题提取出来然后做向量化就可以了,可以这么做:
EmbeddingModel embeddingModel = new AllMiniLmL6V2QuantizedEmbeddingModel();
// 将问题抽取出来单独进行向量化
List<TextSegment> questions = new ArrayList<>();
for (TextSegment segment : segments) {
questions.add(TextSegment.from(segment.text().split("\n")[0]));
}
List<Embedding> embeddings = embeddingModel.embedAll(questions).content();
记得将dimension改回384,然后我们来看效果:
效果比上一次提升了,至少原始问题已经出现了,之所以还没有出现在第一个,那就是AllMiniLmL6V2QuantizedEmbeddingModel这个向量化模型确实效果不咋地,比较它比较小,而不想open-ai那种大的向量化模型。
整合大模型
当我们能根据用户问题匹配到原始问题和答案后,该如何将问题的答案返回给用户呢?比如今天是2024年3月17号,假如用户问“今天的余额提现,最晚什么时候能到账?”,作为智能客服系统,能不能直接告诉客户具体的日期呢,而不是只返回一个“1-7个工作日内可退回您的支付账户”让客户来算日期,实现这个功能就可以结合大模型来实现了。
在创建了ContentRetriever之后,我们可以通过AiServices来整合它与大模型:
// 构造ChatMemory,用来保存历史聊天记录
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
// 指定模型,创建并返回代理对象
return AiServices.builder(CustomerServiceAgent.class)
.chatLanguageModel(model)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
通过AiServices指定了大模型、ContentRetriever,以及一个用来记录历史聊天记录的ChatMemory,这样AiServices就可以创建出来一个CustomerServiceAgent代理对象进行使用了:
// 创建
CustomerServiceAgent customerServiceAgent = CustomerServiceAgent.create();
// 使用
String result = customerServiceAgent.answer("今天的余额提现,最晚什么时候能到账?");
System.out.println(result);
让我们来看看结果:
根据以上信息,余额提现到账时间为1-7个工作日内,具体以账户的到账时间为准。因此,最迟可能在7个工作日内到账。您可以在美团账户的“账号管理——我的账号”中查看是否到账。
没有达到我们想要的效果,我们可以这么问:
// 创建
CustomerServiceAgent customerServiceAgent = CustomerServiceAgent.create();
// 使用
String result = customerServiceAgent.answer("今天的余额提现,最晚哪天能到账?给我具体的日期");
System.out.println(result);
给的答案是:
如果提现是在工作日内进行的话,最晚最晚会在7个工作日内到账。如果提现是在周五进行的话,最晚会在下周的周五到账。
我继续问:
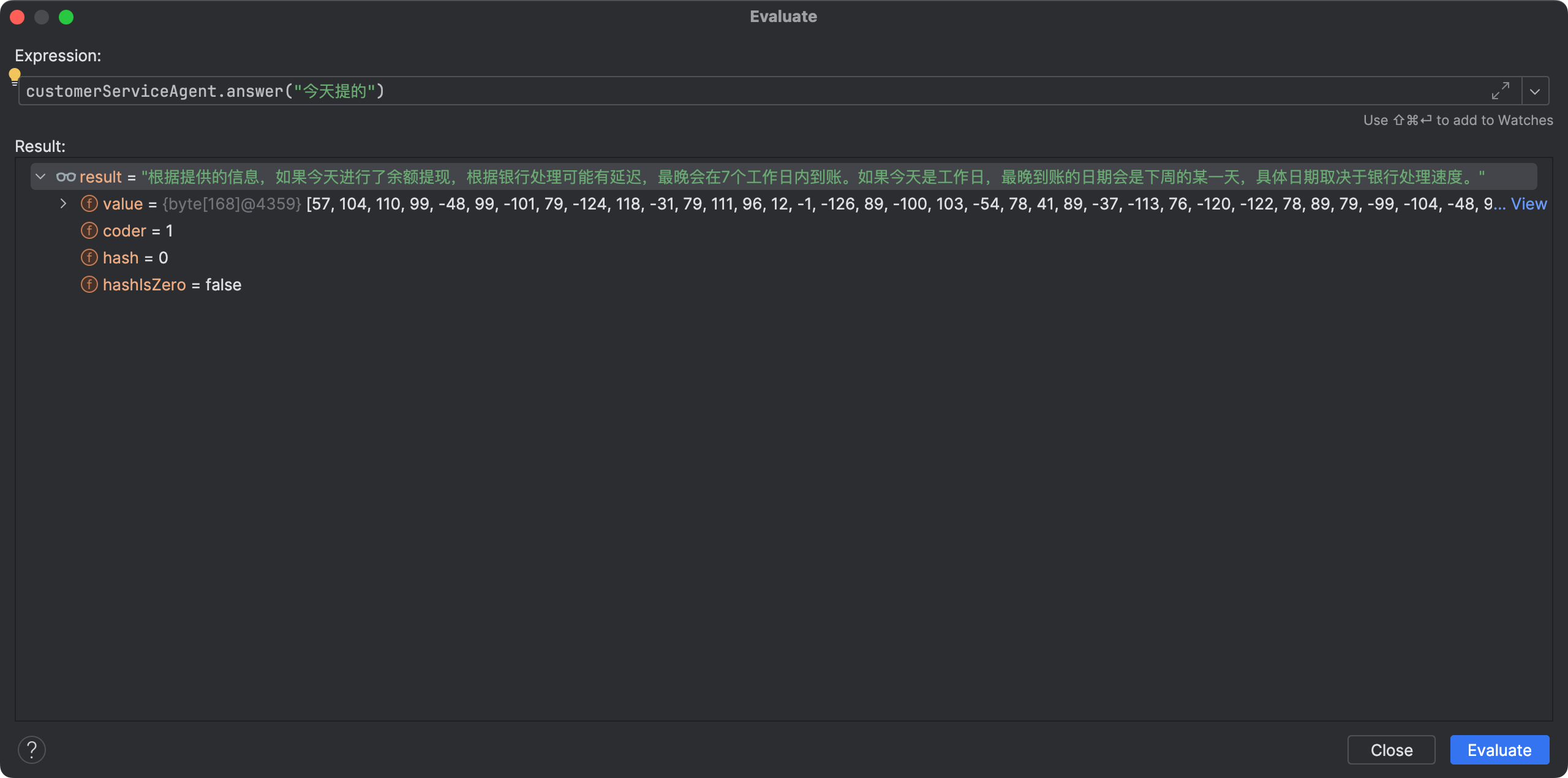
继续问:
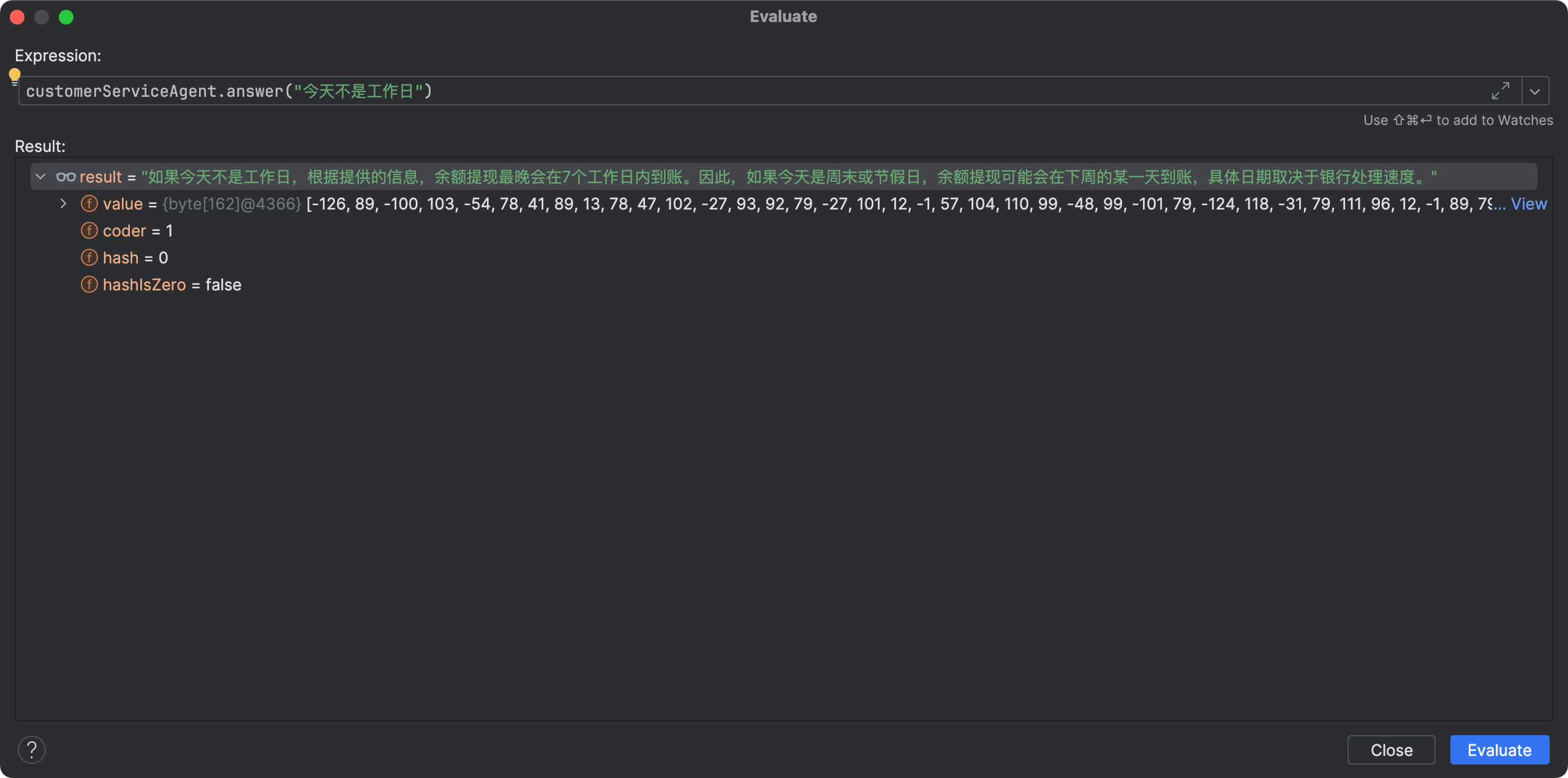
继续问:
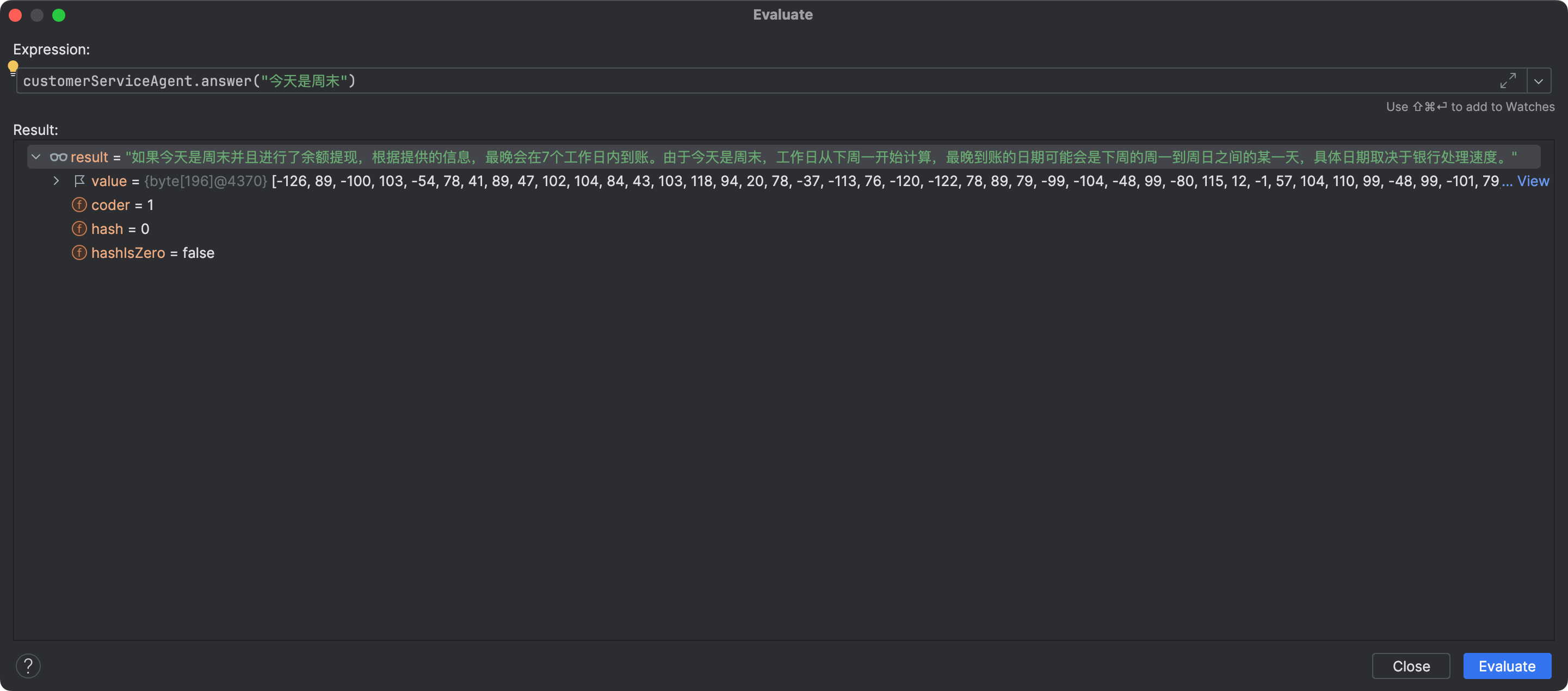
通过这个过程,我们发现虽然整合了大模型,但是大模型似乎对今天是不是周末、是不是工作日这些不太智能,那这就需要利用langchain4j的Tools技术了。
Tool
定义一个Tool:
public class DateCalculator {
@Tool("计算指定天数后的具体日期")
String date(Integer days) {
return LocalDate.now().plusDays(days).toString();
}
}
@Tool就表示定义了一个Tool,这个Tool需要绑定到AiService中:
return AiServices.builder(CustomerServiceAgent.class)
.chatLanguageModel(model)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.tools(new DateCalculator())
.build();
这样大模型在得到初步答案后,会自动匹配到这个Tool,因为我问的是“最晚”,所以大模型能把“1-7”中的“7”提出来并传给我定义的Tool,从而算出具体的日期:

到这,一个智能客服系统算是初具雏形了,这中间也涉及到了langchain4j中最为关键的几个核心组件,大家可以基于以上流程在自己公司内部也搭建这么一套系统。






![[我靠升级逆袭成为大师]韩漫日漫无删减完整版,免费在线观看漫画](https://img-blog.csdnimg.cn/direct/19544f7f1a6a4e6fa04cc3609281a204.jpeg)