花一秒钟就看透事物本质的人,和花一辈子都看不清的人,注定是截然不同的命运。——唐·柯里昂
除了少数天纵奇才,大多数人都是通过知识和阅历的不断积累,才逐渐锻炼出观察和判断事物变化规律的能力。而如果说有一件事,可以牵动着我们去不断追踪、分析和判断,那无疑就是明天的彩票号码(划掉),股票涨跌了!尤其对许多曾经或者现在仍在股市征战四方的朋友来说。
那么不知道大家有没有想过,作为世界上最博学的存在,大模型是否能做到透过某一事件的变化,就能准确预测出相应股票涨跌的能力呢?或许今天这篇文章,会给你答案。
论文标题:
LLMFactor: Extracting Profitable Factors through Prompts for Explainable Stock Movement Prediction
论文链接:
https://arxiv.org/pdf/2406.10811.pdf

金融市场分析
近年来,大模型(LLM)在处理文本数据,尤其是对文本数据的分析和理解方面取得了巨大成功,但金融市场的预测依赖于对时间序列数据的复杂分析,这要求模型不仅要理解历史数据,还要能够从中提取对未来有预测价值的信息。
现有方法,如基于关键词或情感分析的预测模型,虽然能够提供一定程度的市场洞察,但往往缺乏对股票价格变动的清晰解释和人类可读性。此外,有效市场假说(Efficient Market Hypothesis,EMH)虽然提出股票价格反映了所有可用信息,从而使得预测未来价格变动变得困难。但后续研究揭示了市场效率的局限性,如信息不对称和非理性行为等现象,这为通过识别市场低效性来寻求超额回报提供了机会。

因此,研究者开始探索包括新闻报道和社交媒体在内的多种数据类型,以增强预测能力。同时,随着公众情绪对市场趋势影响的实证研究增多,研究者尝试从这些数据中提取情绪和关键词来预测市场动态。然而,这些方法在提供预测结果的同时,往往忽略了解释性,而这对于投资者和分析师来说是至关重要的。
本文提出了LLMFactor框架,旨在通过序列知识引导提示(Sequential Knowledge-Guided Prompting,SKGP)策略,从LLMs中提取与股票市场动态直接相关的因素,并提供清晰的解释,以增强预测的可信度和实用性。
LLMFactor
任务定义
考虑某股票的历史价格序列,其中表示时间窗口的大小。预测股票走势的任务被公式化为一个二元分类问题,其中股票价格序列被转换为一系列股票走势,在这个序列中,表示股票价格从到的上升,而表示下降。
本文的任务目标是对于目标股票,在给定目标预测日期,相关新闻和的情况下,预测其,即预测特定股票在未来某一时间点的价格走势。
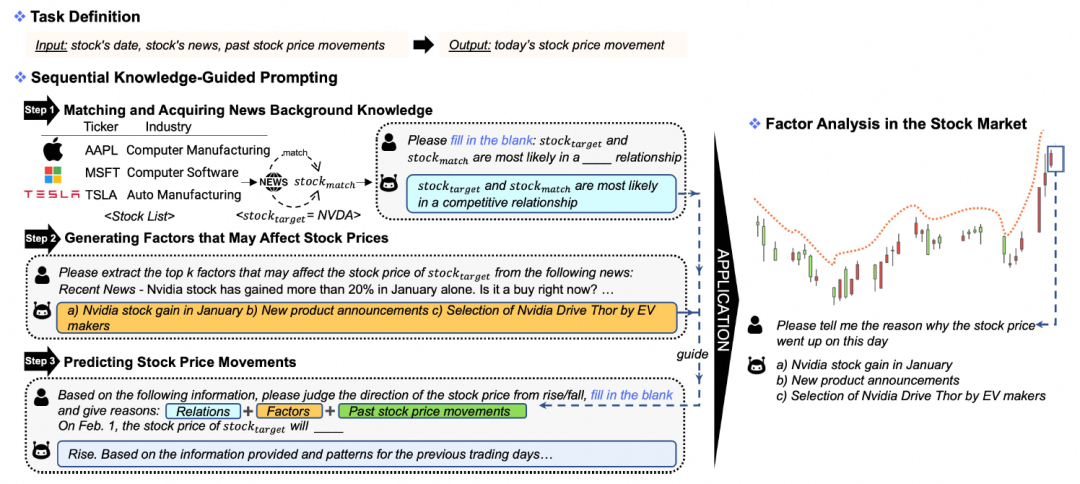
第一阶段:匹配和获取新闻背景知识
匹配和获取新闻背景知识(Matching and Acquiring News Background Knowledge)的过程是SKGP的首要阶段。
这一阶段的核心在于将目标股票与目标预测日期的相关新闻进行匹配,并从中获取有助于理解新闻内容和预测股票价格走势的背景知识。
具体来说,研究者首先构建了一个包含公司、其股票代码和所属行业的元组列表,这些信息从纽约证券交易所(NYSE)和纳斯达克(NASDAQ)交易所收集而来。然后,通过匹配过程,确定与目标新闻相关的股票列表,即。
接下来,利用LLMs通过填空提示(fill-in-the-blank)技术来获取目标股票与匹配股票之间的关系。这种提示方法定义为。输入是一个关系模板,例如“请填空:和最可能处于 ___ 关系”,输出是关系类型,记为 。
这种获取新闻背景知识的方法显著提高了对新闻内容的理解,并且由于公司之间的关系在预测股票市场走势中起着关键作用,因此这种填空技术旨在通过限制响应格式来直接且明确地识别关系类型。例如,如果目标股票和匹配股票被识别为竞争对手,那么匹配股票的信息可能对目标股票产生负面影响。这一过程不仅增强了对新闻文本的理解,而且为后续的因素生成和股票价格走势预测提供了坚实的基础。
生成可能影响股票价格的因素
生成可能影响股票价格的因素(Generating Factors that May Affect Stock Prices)是SKGP的第二阶段。
在这一阶段,研究者指导LLMs分析目标新闻内容,识别出可能对股票价格产生影响的关键因素。这些因素与股票走势的关联度比关键词、情感、新闻摘要或整篇新闻文章更为紧密,因此提供了更高可能性的市场趋势预测。
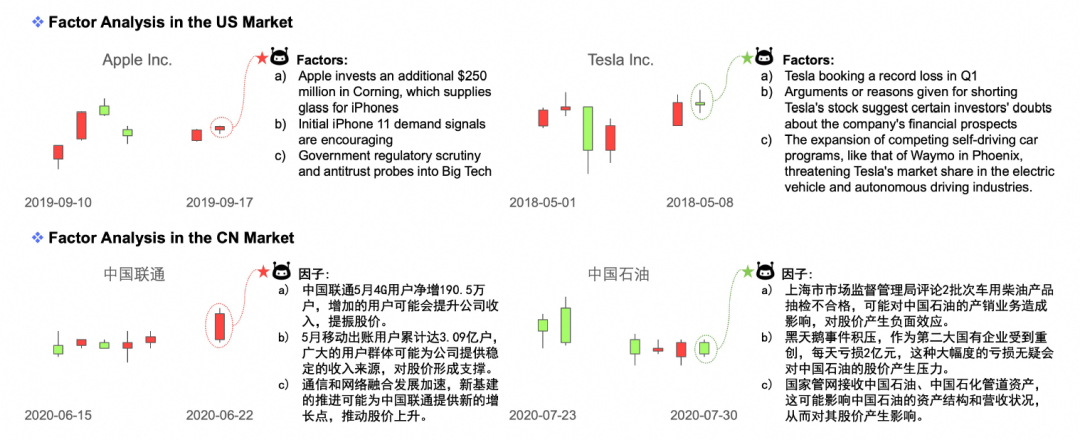
为了生成可靠的因素,研究者使用特定的提示模板(FactorTemplate),要求LLMs从新闻中提取可能影响目标股票价格的前k个因素。LLMs在生成因素时,不仅考虑新闻中出现的词汇,而且综合考虑新闻内容及其对股票走势的潜在影响,并将内容中的重要元素进行概括。例如,如果新闻中提到“Nvidia股票在一月份的增长”,这表明Nvidia过去的股票表现良好,这种增长可能会对Nvidia未来的股价产生积极影响。
生成的因素不仅提供了对股票价格波动更即时和详细的见解,而且提高了股票价格趋势的可解释性以及LLMs预测背后的理由。这些因素随后被用于预测模型中,与历史股票价格数据和背景知识相结合,以提高预测的准确性和可解释性。通过这种方式,LLMFactor框架能够将从新闻文本中提取的深层次信息转化为对股票市场动态的清晰理解和预测。
预测股票价格走势
预测股票价格走势是LLMFactor框架的核心环节,它融合了新闻背景知识和可能影响股票价格的因素,以指导LLMs进行预测。这一过程始于将时间序列数据转换为文本格式,使LLMs能够理解并处理。具体来说,股票价格走势序列被转换成一个文本序列,其中上升和下降分别用“rose”和“fell”表示。
接着,研究者构建了一个时间模板(TimeTemplate),将过去的股价走势转换成具有特定结构的句子,例如“在,的股价”。此外,还构建了一个价格模板(PriceTemplate),它包括一个初始指令,要求基于所提供的信息判断股票价格的走向(上升或下降),并给出理由,以及一个结论性指令,用于预测特定日期的股价走势“在,的股价会”。
通过这种方式,LLMFactor框架不仅能够预测股票价格的未来走势,还能够提供对这些预测背后逻辑的清晰解释,从而增强了预测的可解释性和透明度。
实验
实验设置
实验使用了四个基准数据集,包括:
-
StockNet:包含87个美国股市股票,相关的推文和2014-01-01至2016-01-01期间的历史价格数据。
-
CMIN-US:包含110个美国股市股票,相关的推文和2018-01-01至2021-12-31期间的历史价格数据。
-
CMIN-CN:包含300个中国股市CSI300指数股票,相关的推文和同一时间段的历史价格数据。
-
EDT:包含54,080篇新闻文章,以及2020-03-01至2021-05-06期间的相关股票和价格信息。
本文使用了准确率(Accuracy, ACC)和马修斯相关系数(Matthews Correlation Coefficient, MCC)作为评估模型效果的指标。
同时,采用了:
-
基于关键词提取的模型(如PromptRank,KeyBERT,YAKE,TextRank,TopicRank,SingleRank,TFIDF)。-
-
基于情感分析的模型(如EDT,FinGPT,GPT-4-turbo,GPT-4,GPT-3.5-turbo, RoBERTa,FinBERT)。
-
结合文本和时间序列数据的模型(如CMIN,StockNet)。
共同作为本文的基线
实验结果
LLMFactor 在所有评估方法中表现最佳,其性能优于基于关键词、情感分析和多模态数据输入的现有最先进方法(SOTA)。在四个数据集上,LLMFactor的MCC分别实现了2.9%,0.4%,11%,和4.8%的改进。
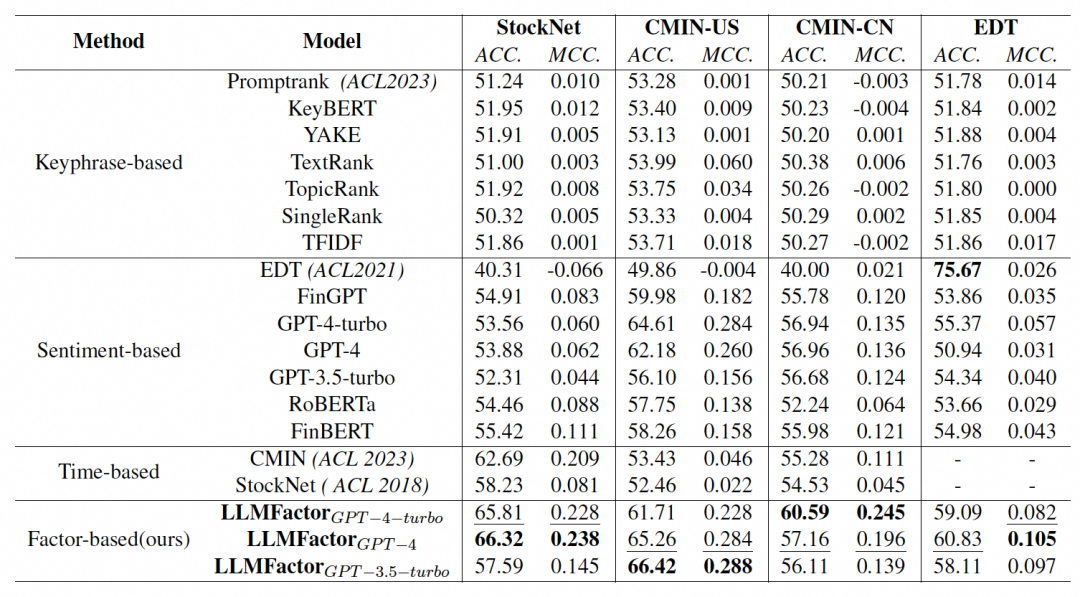
对比基线模型,关键词模型在预测股价走势方面表现有限,这表明仅依靠关键词可能不足以提供对股价变动的深入洞察。而情感分析方法在不同模型间表现不一,其中一些基于LLM的模型(如GPT-4和GPT-4-turbo)在文本情感分析方面表现较好。结合文本和时间序列的模型(如CMIN, StockNet)整体性方面表现良好,但可能缺乏对文本细节的深入分析。
实验中使用了三种不同的LLM模型变体(LLMFactorGPT-4-turbo, LLMFactorGPT-4, LLMFactorGPT-3.5-turbo)来评估框架的性能。这些变体在不同数据集上的表现略有差异,但总体上都优于基线模型。
此外,通过消融研究,发现LLMFactor的因素层(factor layer)对整体性能的提升贡献最大,其次是关系层(relation layer)。价格层(price layer)虽然提供了基础的股价走势信息,但其对性能提升的贡献相对较小。

总的来说,LLMFactor通过结合背景知识、从新闻中提取的因素以及历史股价数据,显著提高了预测的准确性和可解释性。尽管LLMFactor在所有数据集上都取得了良好的结果,但在不同市场和数据类型上的细微性能差异表明,模型对英语文本的处理可能更为熟练。
结论和展望
股市就像是一个巨大的海洋,里面充满了各种各样的信息。有的像是水面上的波纹,一眼就能看出来,比如公司的新闻报道或者社交媒体上的热门话题。但是,真正影响船只方向的,可能是那些藏在水下的暗流,也就是那些不容易被发现,但影响力巨大的因素。
LLMFactor就像是一个熟练的潜水员,依托于LLM的强大基础能力,它能够深入到这些信息的海洋里,找到那些关键的暗流。通过SKGP方法,先了解一些背景知识,比如公司之间的关系,然后再从新闻报道中提取出可能影响股票价格的因素,从而更加准确地预测股票价格将会上涨还是下跌。
当然,正如文中提到,LLMFactor对不同语言之间存在一定的性能差异,而它在预测时,也会出现一些不确定性,这就需要未来对其鲁棒性改进的研究。此外,如果能更充分地应用上LLM的知识储备,尤其是金融zhuan,或许还能进一步提高LLMFactor对事件的理解和分析能力。