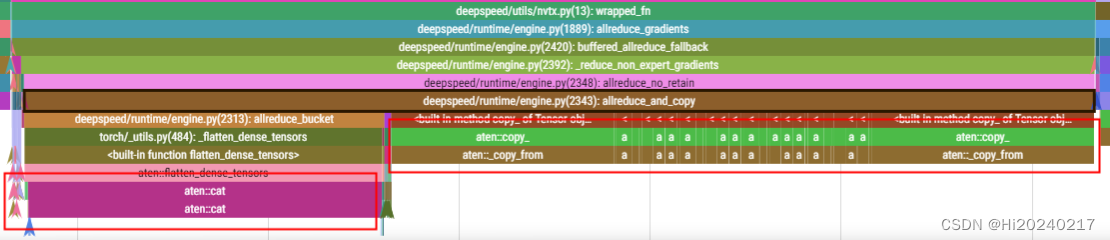
Megatron-DeepSpeed与Megatron-LM在reduce grad上的差异
- 一.Megatron-DeepSpeed 实现【deepspeed/runtime/engine.py】
- 二.ModelLink 实现【ParamAndGradBuffer】
- 1.ParamAndGradBuffer功能介绍
- 2.实现原理
- A.分配一大块内存
- B.获取视图
- C.all_reduce grad
测试DP=1,TP=2,PP=1,MBS=1,zero_stage=0时Megatron-DeepSpeed与Megatron-LM的性能差异
发现它们在处理gradients时方法不同
目前Megatron-DeepSpeed还没有合入Megatron-LM ParamAndGradBuffer的修改
一.Megatron-DeepSpeed 实现【deepspeed/runtime/engine.py】
flatten->all_reduce->unflatten 【二次IO】
Megatron-DeepSpeed链接
def allreduce_bucket(self, bucket, dp_group):
tensor = self.flatten(bucket)
tensor_to_allreduce = tensor
if self.communication_data_type != tensor.dtype:
tensor_to_allreduce = tensor.to(self.communication_data_type)
if self.postscale_gradients():
if self.gradient_predivide_factor() != 1.0:
tensor_to_allreduce.mul_(1.0 / self.gradient_predivide_factor())
dist.all_reduce(tensor_to_allreduce, group=dp_group)
if self.gradient_average:
if self.gradient_predivide_factor() != dist.get_world_size(group=dp_group):
tensor_to_allreduce.mul_(self.gradient_predivide_factor() / dist.get_world_size(group=dp_group))
else:
tensor_to_allreduce.mul_(1. / dist.get_world_size(group=dp_group))
dist.all_reduce(tensor_to_allreduce, group=dp_group)
if self.communication_data_type != tensor.dtype and tensor is not tensor_to_allreduce:
tensor.copy_(tensor_to_allreduce)
return tensor
def allreduce_and_copy(self, small_bucket, dp_group):
allreduced = self.allreduce_bucket(small_bucket, dp_group)
for buf, synced in zip(small_bucket, self.unflatten(allreduced, small_bucket)):
buf.copy_(synced)
二.ModelLink 实现【ParamAndGradBuffer】
分配一大块连续内存,通过视图的方式给相关的grad使用,all_reduce时不需要多余的IO
ModelLink链接
1.ParamAndGradBuffer功能介绍
https://github.com/NVIDIA/Megatron-LM/commit/293e10419fd1b79c8680a0f4a206fc0a373729b5
Lay out params in a contiguous buffer using a new ParamAndGradBuffer
- Re-map parameters only when using the distributed optimizer
- Remove unnecessary param copying logic after all-gather
- Unmap weight_tensor attributes if they exist to reduce memory footprint
2.实现原理
A.分配一大块内存
data_start_index = 0
for param in params[::-1]:
if not param.requires_grad:
continue
this_numel = param.data.nelement()
data_end_index = data_start_index + this_numel
self.param_index_map[param] = (
data_start_index,
data_end_index,
bucket_id,
)
bucket_params.add(param)
data_start_index = data_end_index
self.numel = data_end_index
self.grad_data = torch.zeros(
self.numel,
dtype=self.grad_dtype,
device=torch.cuda.current_device(),
requires_grad=False)
B.获取视图
def _get(self, shape: torch.Size, start_index: int, buffer_type: BufferType) -> torch.Tensor:
"""
Return a tensor with the input `shape` as a view into the 1-D data starting at
`start_index`.
"""
end_index = start_index + shape.numel()
assert end_index <= self.numel, 'Requested tensor is out of buffer range'
if buffer_type == BufferType.PARAM:
assert self.param_data is not None
buffer_tensor = self.param_data[start_index:end_index]
elif buffer_type == BufferType.GRAD:
buffer_tensor = self.grad_data[start_index:end_index]
else:
raise Exception("Illegal buffer type provided to GradBuffer._get() function")
buffer_tensor = buffer_tensor.view(shape)
return buffer_tensor
C.all_reduce grad
def start_grad_sync(self):
self.communication_handle = torch.distributed.all_reduce(
self.grad_data, group=self.data_parallel_group, async_op=self.overlap_grad_reduce
)