前言
- 学习视频:Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强
- 学习文档:
- 谷粒商城-个人笔记(基础篇一)
- 谷粒商城-个人笔记(基础篇二)
- 谷粒商城-个人笔记(基础篇三)
- 谷粒商城-个人笔记(高级篇一)
- 谷粒商城-个人笔记(高级篇二)
- 谷粒商城-个人笔记(高级篇三)
- 谷粒商城-个人笔记(高级篇四)
- 谷粒商城-个人笔记(高级篇五)
- 谷粒商城-个人笔记(集群部署篇一)
3. 接口文档:https://easydoc.net/s/78237135/ZUqEdvA4/hKJTcbfd
4. 本内容仅用于个人学习笔记,如有侵扰,联系删
一、k8s 集群部署
1、k8s 快速入门
1.1、简介
Kubernetes 简称 k8s。是用于自动部署,扩展和管理容器化应用程序的开源系统。
中文官网:https://kubernetes.io/zh/
中文社区:https://www.kubernetes.org.cn/
官方文档:https://kubernetes.io/zh/docs/home/
社区文档:http://docs.kubernetes.org.cn/
-
部署方式的进化
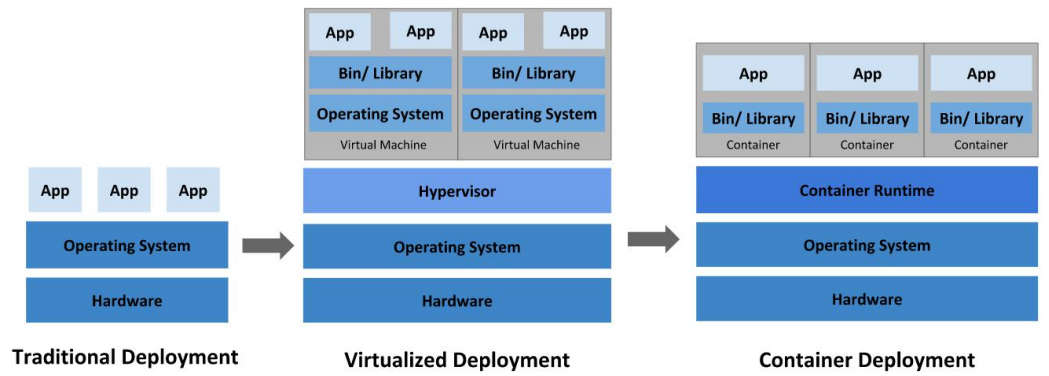
https://kubernetes.io/zh/docs/concepts/overview/传统部署时代:
早期,各个组织是在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。 例如,如果在同一台物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。 一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程序资源利用率不高时,剩余资源无法被分配给其他应用程序, 而且维护许多物理服务器的成本很高。
虚拟化部署时代:
因此,虚拟化技术被引入了。虚拟化技术允许你在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可扩缩性,以及降低硬件成本等等的好处。 通过虚拟化,你可以将一组物理资源呈现为可丢弃的虚拟机集群。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来,例如:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
- 可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
-
为什么需要 Kubernetes,它能做什么?
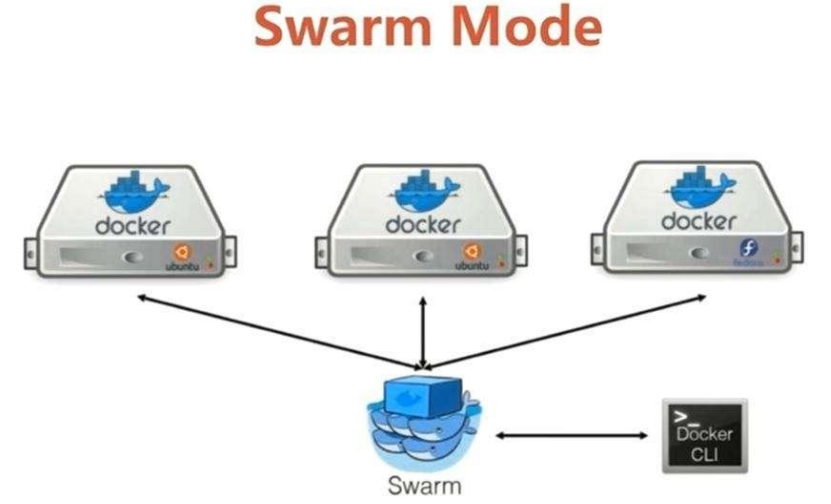
以前使用Swarm Mode方式调度,功能简单,现在使用Kubernetes容器是打包和运行应用程序的好方式。在生产环境中, 你需要管理运行着应用程序的容器,并确保服务不会下线。 例如,如果一个容器发生故障,则你需要启动另一个容器。 如果此行为交由给系统处理,是不是会更容易一些?
这就是 Kubernetes 要来做的事情! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移你的应用、提供部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary (金丝雀) 部署。
Kubernetes 为你提供:
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址来暴露容器。 如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 -
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 -
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 -
自动完成装箱计算
你为 Kubernetes 提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。 Kubernetes 可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。 -
自我修复
Kubernetes 将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。 -
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。 -
批处理执行 除了服务外,Kubernetes 还可以管理你的批处理和 CI(持续集成)工作负载,如有需要,可以替换失败的容器。
-
水平扩缩 使用简单的命令、用户界面或根据 CPU 使用率自动对你的应用进行扩缩。
-
IPv4/IPv6 双栈 为 Pod(容器组)和 Service(服务)分配 IPv4 和 IPv6 地址。
-
为可扩展性设计 在不改变上游源代码的情况下为你的 Kubernetes 集群添加功能。
-
-
Kubernetes 不是什么
Kubernetes 不是传统的、包罗万象的 PaaS(平台即服务)系统。 由于 Kubernetes 是在容器级别运行,而非在硬件级别,它提供了 PaaS 产品共有的一些普遍适用的功能, 例如部署、扩展、负载均衡,允许用户集成他们的日志记录、监控和警报方案。 但是,Kubernetes 不是单体式(monolithic)系统,那些默认解决方案都是可选、可插拔的。 Kubernetes 为构建开发人员平台提供了基础,但是在重要的地方保留了用户选择权,能有更高的灵活性。Kubernetes:
- 不限制支持的应用程序类型。 Kubernetes 旨在支持极其多种多样的工作负载,包括无状态、有状态和数据处理工作负载。 如果应用程序可以在容器中运行,那么它应该可以在 Kubernetes 上很好地运行。
- 不部署源代码,也不构建你的应用程序。 持续集成(CI)、交付和部署(CI/CD)工作流取决于组织的文化和偏好以及技术要求。
- 不提供应用程序级别的服务作为内置服务,例如中间件(例如消息中间件)、 数据处理框架(例如 Spark)、数据库(例如 MySQL)、缓存、集群存储系统 (例如 Ceph)。这样的组件可以在 Kubernetes 上运行,并且/或者可以由运行在 Kubernetes 上的应用程序通过可移植机制(例如开放服务代理)来访问。
- 不是日志记录、监视或警报的解决方案。 它集成了一些功能作为概念证明,并提供了收集和导出指标的机制。
- 不提供也不要求配置用的语言、系统(例如 jsonnet),它提供了声明性 API, 该声明性 API 可以由任意形式的声明性规范所构成。
- 不提供也不采用任何全面的机器配置、维护、管理或自我修复系统。
- 此外,Kubernetes 不仅仅是一个编排系统,实际上它消除了编排的需要。 编排的技术定义是执行已定义的工作流程:首先执行 A,然后执行 B,再执行 C。 而 Kubernetes 包含了一组独立可组合的控制过程,可以持续地将当前状态驱动到所提供的预期状态。 你不需要在乎如何从 A 移动到 C,也不需要集中控制,这使得系统更易于使用且功能更强大、 系统更健壮,更为弹性和可扩展。
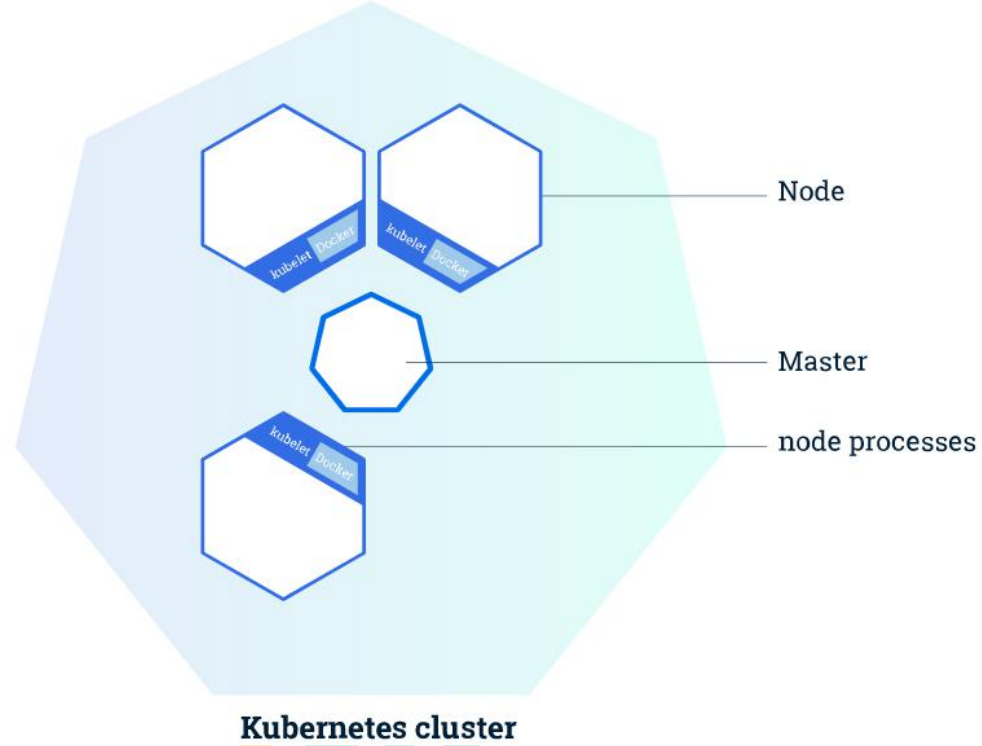
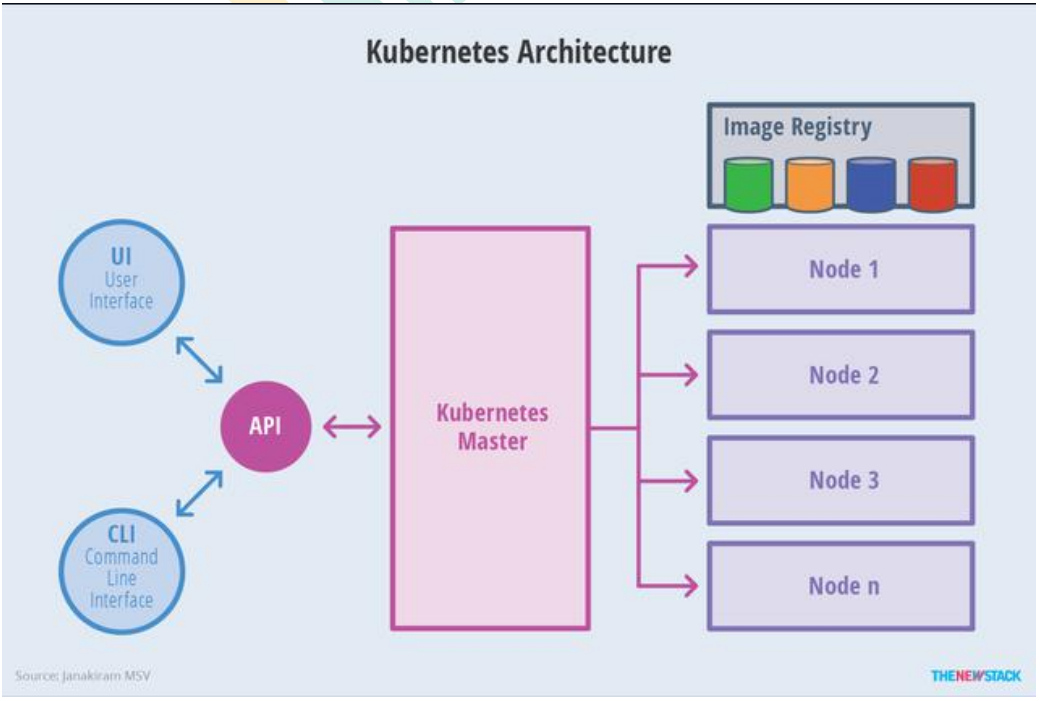
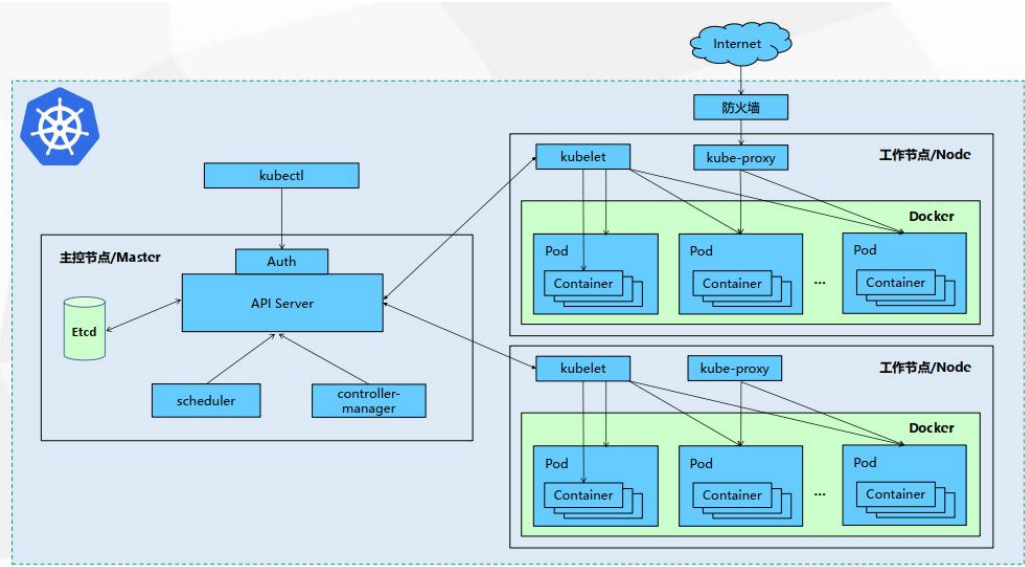
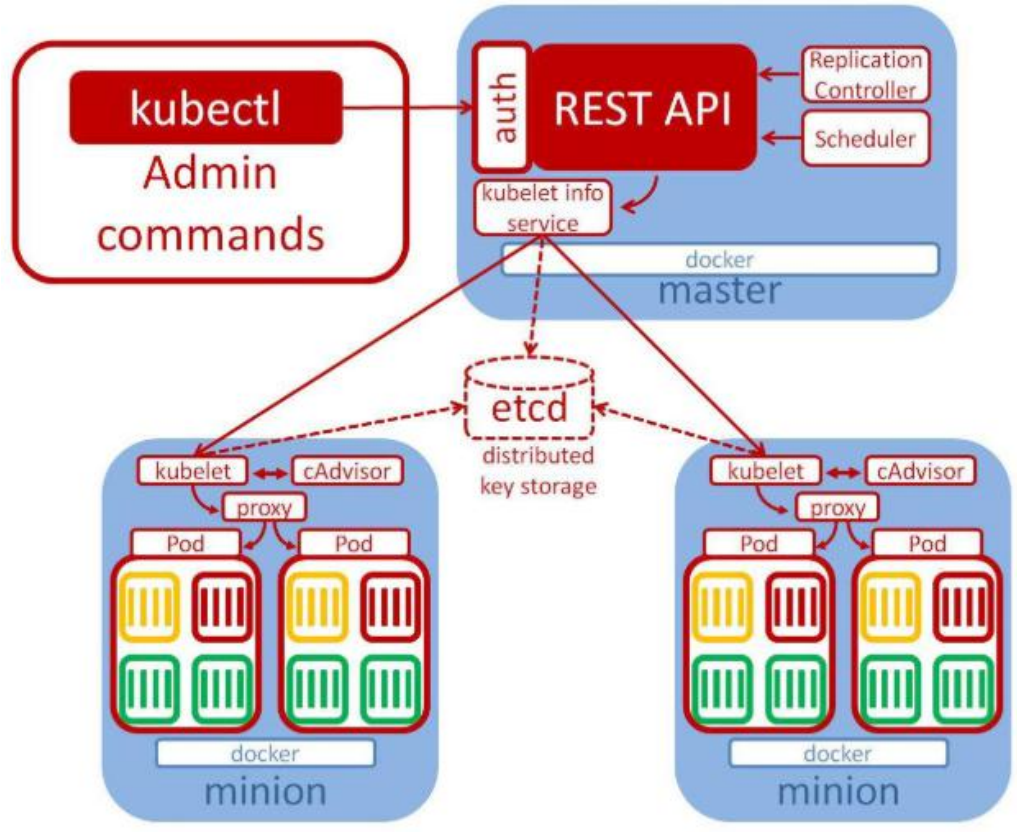
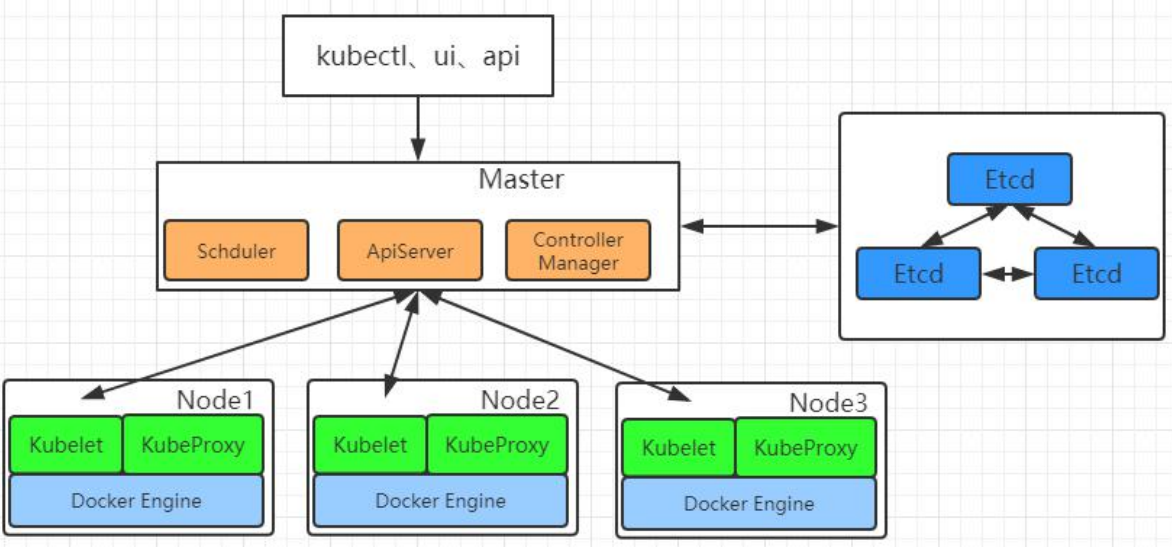
1.2、架构
- 整体主从方式
- Master 节点架构
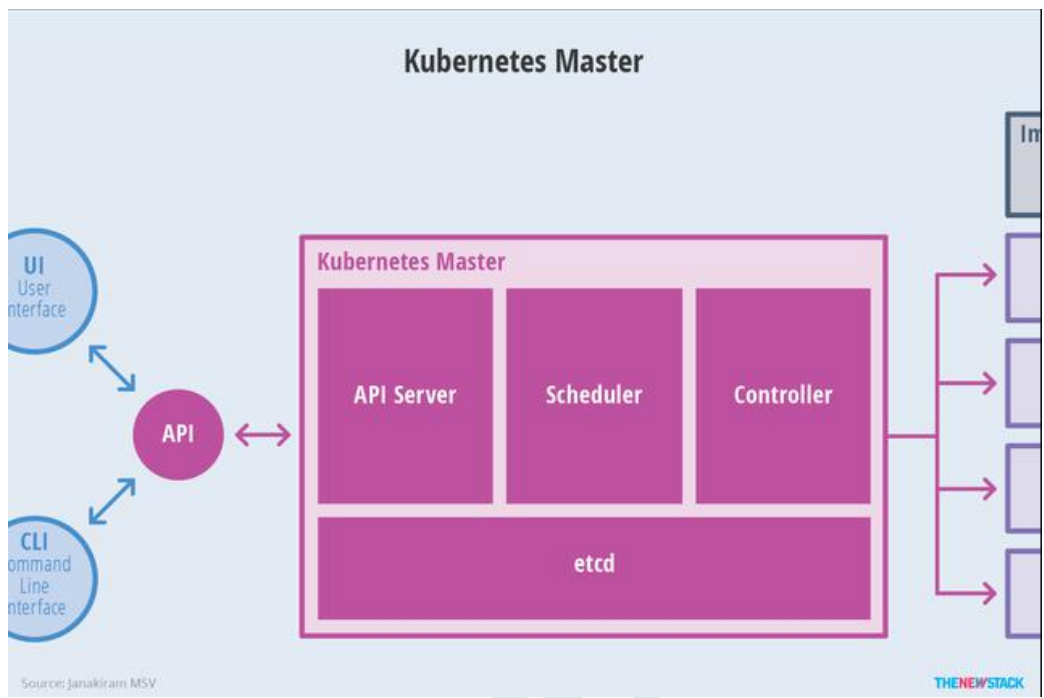
- kube-apiserver
- 对外暴露 K8S 的 api 接口,是外界进行资源操作的唯一入口
- 提供认证、授权、访问控制、API 注册和发现等机制
- etcd
- etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
- Kubernetes 集群的 etcd 数据库通常需要有个备份计划
- kube-scheduler
- 主节点上的组件,该组件监视那些新创建的未指定运行节点的 Pod,并选择节点让 Pod 在上面运行。
- 所有对 k8s 的集群操作,都必须经过主节点进行调度
- kube-controller-manager
- 在主节点上运行控制器的组件
- 这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应。
- 副本控制器(Replication Controller): 负责为系统中的每个副本控制器对象维护正确数量的 Pod。
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service与 Pod)。
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
- kube-apiserver
3. Node 节点架构
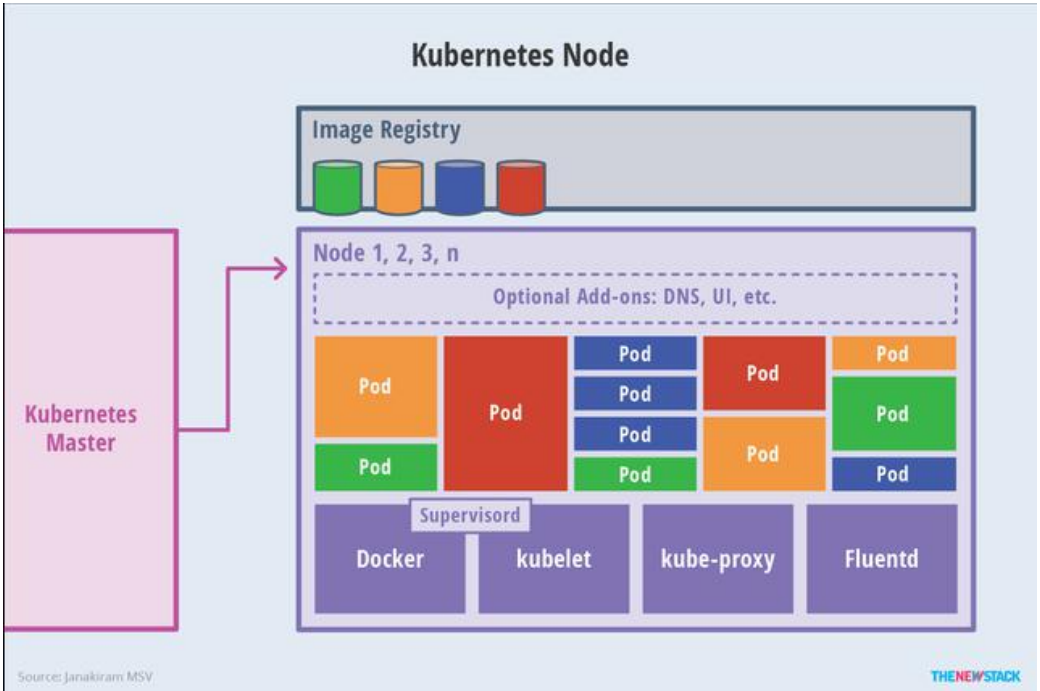
- kubelet
- 一个在集群中每个节点上运行的代理。它保证容器都运行在 Pod 中。
- 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理;
- kube-proxy
- 负责为 Service 提供 cluster 内部的服务发现和负载均衡;
- 容器运行环境(Container Runtime)
- 容器运行环境是负责运行容器的软件。
- Kubernetes 支持多个容器运行环境: Docker、 containerd、cri-o、 rktlet 以及任何实现 Kubernetes CRI (容器运行环境接口)。
- fluentd
- 是一个守护进程,它有助于提供集群层面日志 集群层面的日志
1.3、概念
-
Container:容器,可以是 docker 启动的一个容器
-
Pod:
- k8s 使用 Pod 来组织一组容器
- 一个 Pod 中的所有容器共享同一网络。
- Pod 是 k8s 中的最小部署单元
-
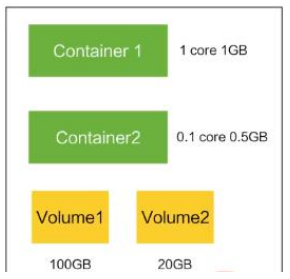
Volume
- 声明在 Pod 容器中可访问的文件目录
- 可以被挂载在 Pod 中一个或多个容器指定路径下
- 支持多种后端存储抽象(本地存储,分布式存储,云存储…)
-
Controllers:更高层次对象,部署和管理 Pod;
- ReplicaSet:确保预期的 Pod 副本数量
- Deplotment:无状态应用部署
- StatefulSet:有状态应用部署
- DaemonSet:确保所有 Node 都运行一个指定 Pod
- Job:一次性任务
- Cronjob:定时任务
-
Deployment:
- 定义一组 Pod 的副本数目、版本等
- 通过控制器(Controller)维持 Pod 数目(自动回复失败的 Pod)
- 通过控制器以指定的策略控制版本(滚动升级,回滚等)
-
Service
- 定义一组 Pod 的访问策略
- Pod 的负载均衡,提供一个或者多个 Pod 的稳定访问地址
- 支持多种方式(ClusterIP、NodePort、LoadBalance)
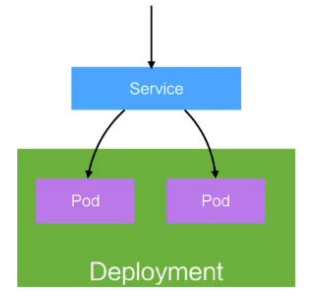
-
Label:标签,用于对象资源的查询,筛选

-
Namespace:命名空间,逻辑隔离
- 一个集群内部的逻辑隔离机制(鉴权,资源)
- 每个资源都属于一个 namespace
- 同一个 namespace 所有资源名不能重复
- 不同 namespace 可以资源名重复
API:
我们通过 kubernetes 的 API 来操作整个集群。
可以通过 kubectl、ui、curl 最终发送 http+json/yaml 方式的请求给 API Server,然后控制 k8s集群。k8s 里的所有的资源对象都可以采用 yaml 或 JSON 格式的文件定义或描述

1.4、快速体验
1、安装 minikube
https://github.com/kubernetes/minikube/releases
下载 minikube-windows-amd64.exe 改名为 minikube.exe
打开 VirtualBox,打开 cmd,
运行
minikube start --vm-driver=virtualbox --registry-mirror=https://registry.docker-cn.com
等待 20 分钟左右即可
2、体验 nginx 部署升级

1.5、流程叙述
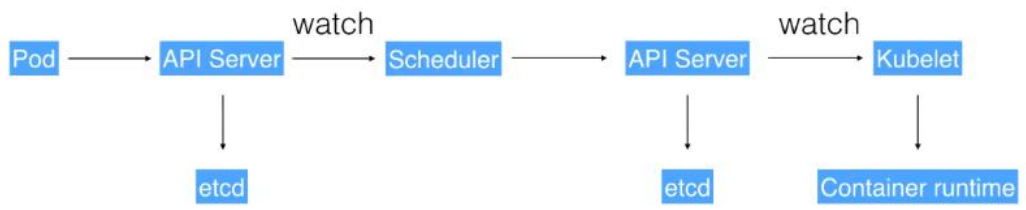
- 通过 Kubectl 提交一个创建 RC(Replication Controller)的请求,该请求通过 APIServer被写入 etcd 中
- 此时 Controller Manager 通过 API Server 的监听资源变化的接口监听到此 RC 事件
- 分析之后,发现当前集群中还没有它所对应的 Pod 实例,
- 于是根据 RC 里的 Pod 模板定义生成一个 Pod 对象,通过 APIServer 写入 etcd
- 此事件被 Scheduler 发现,它立即执行一个复杂的调度流程,为这个新 Pod 选定一个落户的 Node,然后通过 API Server 讲这一结果写入到 etcd 中,
- 目标 Node 上运行的 Kubelet 进程通过 APIServer 监测到这个“新生的”Pod,并按照它的定义,启动该 Pod 并任劳任怨地负责它的下半生,直到 Pod 的生命结束。
- 随后,我们通过 Kubectl 提交一个新的映射到该 Pod 的 Service 的创建请求
- ControllerManager 通过 Label 标签查询到关联的 Pod 实例,然后生成 Service 的Endpoints 信息,并通过 APIServer 写入到 etcd 中,
- 接下来,所有 Node 上运行的 Proxy 进程通过 APIServer 查询并监听 Service 对象与其对应的 Endpoints 信息,建立一个软件方式的负载均衡器来实现 Service 访问到后端Pod 的流量转发功能。
k8s 里的所有的资源对象都可以采用 yaml 或 JSON 格式的文件定义或描述
2、k8s 集群安装
2.1、kubeadm
kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具。
这个工具能通过两条指令完成一个 kubernetes 集群的部署:
-
创建一个 Master 节点
$ kubeadm init -
将一个 Node 节点加入到当前集群中
$ kubeadm join <Master 节点的 IP 和端口 >
2.2、前置要求
一台或多台机器,操作系统 CentOS7.x-86_x64
硬件配置:2GB 或更多 RAM,2 个 CPU 或更多 CPU,硬盘 30GB 或更多
集群中所有机器之间网络互通
可以访问外网,需要拉取镜像
禁止 swap 分区
2.3、部署步骤
- 在所有节点上安装 Docker 和 kubeadm
- 部署 Kubernetes Master
- 部署容器网络插件
- 部署 Kubernetes Node,将节点加入 Kubernetes 集群中
- 部署 Dashboard Web 页面,可视化查看 Kubernetes 资源
2.4、环境准备
1、准备工作
-
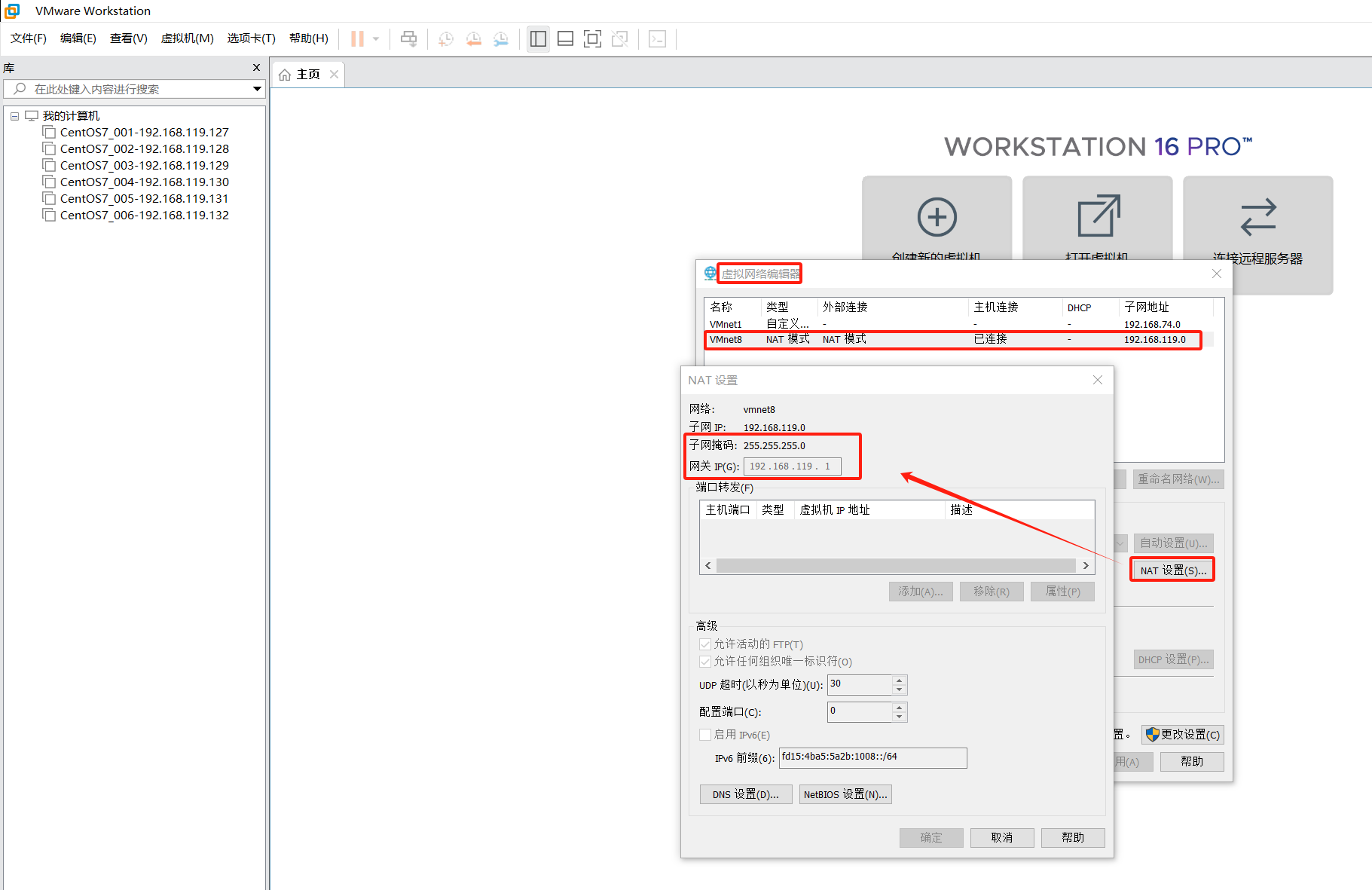
我们可以使用 VMware 快速创建三个虚拟机。虚拟机启动前先设置 VMware 的主机网络。现全部统一为 192.168.119.1,以后所有虚拟机都是 119.x 的 ip 地址
-
设置虚拟机存储目录,防止硬盘空间不足
2、启动三个虚拟机
-
使用我们提供的 vagrant 文件,复制到非中文无空格目录下,运行 vagrant up 启动三个
虚拟机。其实 vagrant 完全可以一键部署全部 k8s 集群。
https://github.com/rootsongjc/kubernetes-vagrant-centos-cluster
http://github.com/davidkbainbridge/k8s-playground -
进入三个虚拟机,开启 root 的密码访问权限。
所有虚拟机设置为 node1分配 4g、4C;gnode2、node3 分配 16g,16C设置好 NAT 网络
3、设置 linux 环境(三个节点都执行)
-
关闭防火墙:
systemctl stop firewalld systemctl disable firewalld -
关闭 selinux:
sed -i 's/enforcing/disabled/' /etc/selinux/config setenforce 0 -
关闭 swap:
swapoff -a #临时 sed -ri 's/.*swap.*/#&/' /etc/fstab #永久 free -g #验证,swap 必须为 0; -
添加主机名与 IP 对应关系
vi /etc/hosts 192.168.119.133 k8s-node1 192.168.119.134 k8s-node2 192.168.119.135 k8s-node3 hostnamectl set-hostname <newhostname>:指定新的 hostname su 切换过来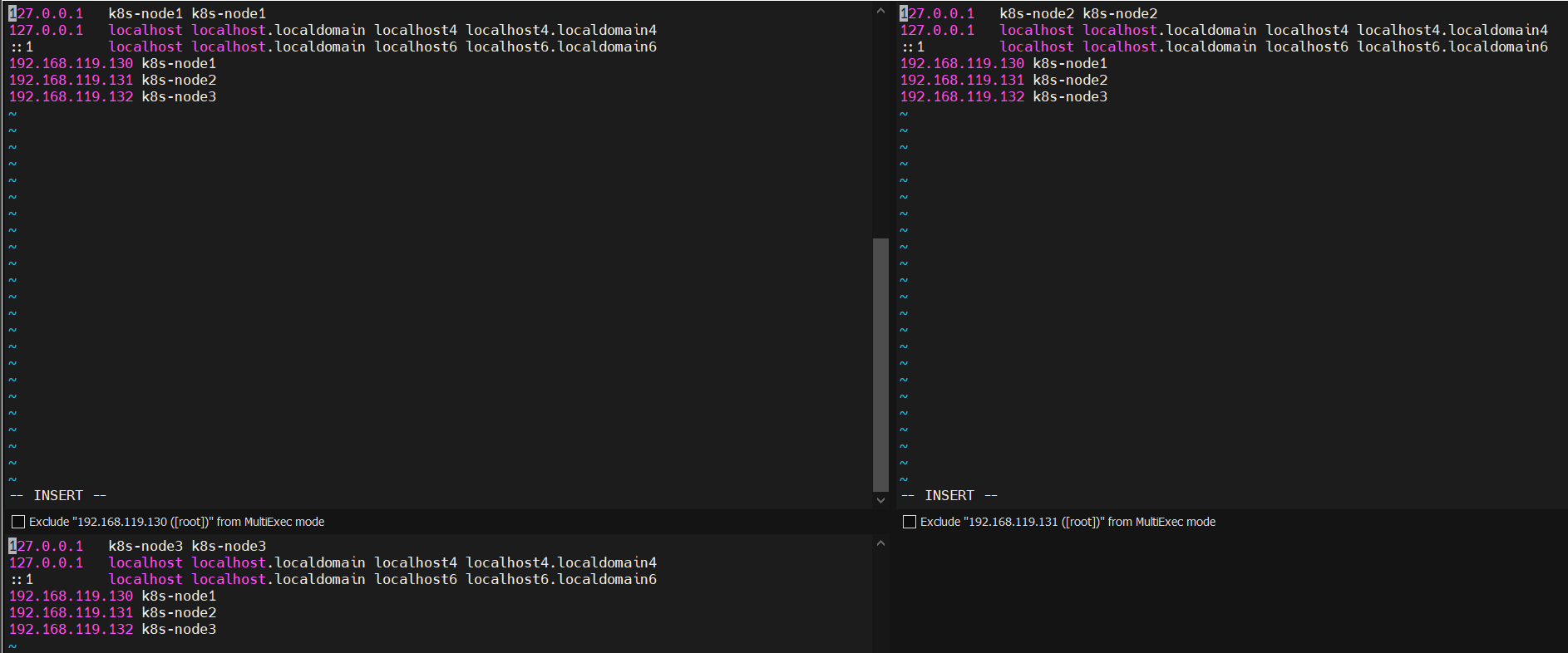
wq保存,然后重启每台服务 -
将桥接的 IPv4 流量传递到 iptables 的链:
cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF # 加载参数 sysctl --system
2.5、所有节点安装 Docker、kubeadm、kubelet、kubectl
Kubernetes 默认 CRI(容器运行时)为 Docker,因此先安装 Docker。
1、安装 docker
-
卸载系统之前的 docker
# 安装前先更新yum,不然有可能出现本机无法连接虚拟机的mysql、redis等 sudo yum update # 卸载系统之前的docker,以及 docker-cli sudo yum remove docker-ce docker-ce-cli containerd.io # 卸载系统之前的docker sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine -
安装 Docker-CE
(1)、安装必须的依赖sudo yum install -y yum-utils \ device-mapper-persistent-data \ lvm2(2)、设置 docker repo 的 yum 位置
# 配置镜像 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo(3)、安装 docker,以及 docker-cli
该命令安装docker以后,kubeadm初始化时会报错,提示版本不兼容sudo yum install -y docker-ce docker-ce-cli containerd.io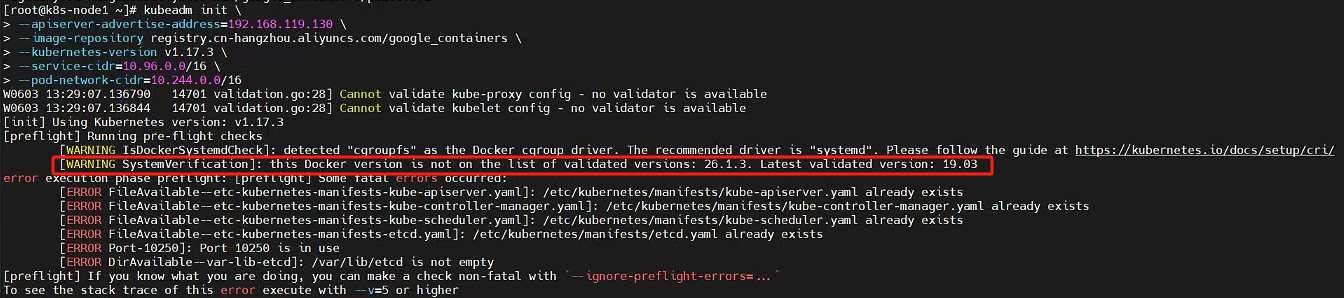
所以我们使用推荐docker版本sudo yum install docker-ce-3:19.03.15-3.el7.x86_64 docker-ce-cli-19.03.15-3.el7.x86_64 containerd.io -
配置 docker 加速
sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://chqac97z.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker -
启动 docker & 设置 docker 开机自启
systemctl enable docker
基础环境准备好,可以给三个虚拟机备份一下;为 node1分配 4g、4C;gnode2、node3 分配 16g,16C。方便未来侧测试
2、添加阿里云 yum 源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
3、安装 kubeadm,kubelet 和 kubectl
yum list|grep kube
yum install -y kubelet-1.17.3 kubeadm-1.17.3 kubectl-1.17.3
systemctl enable kubelet
systemctl start kubelet
2.6、部署 k8s-master(master节点)
-
下载镜像
由于需要下载好多镜像,我们也不知道下载进入如何,此时我们通过运行提供的脚本来下载镜像,可以看到下载进度(1)、上传k8s文件到主节点
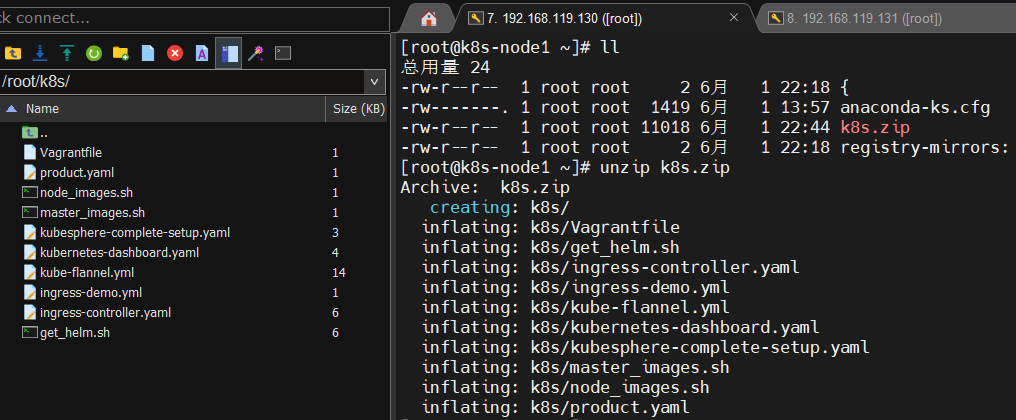
解压发现没有该命令unzip,安装unzip命令sudo yum update sudo yum install unzip(2)、可以看到master_images.sh脚本内容
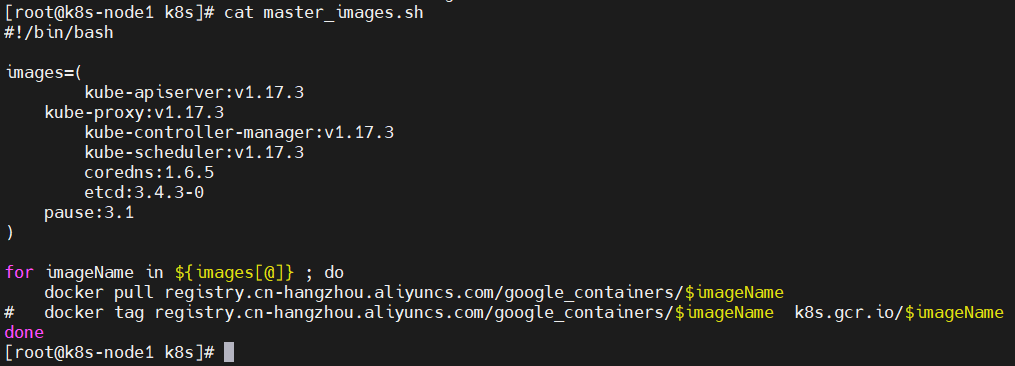
我们只需要启动该脚本就可以了(3)、我们看到master_images.sh脚本没有执行权限,我们这个时候还不能启动脚本下载镜像,修改权限
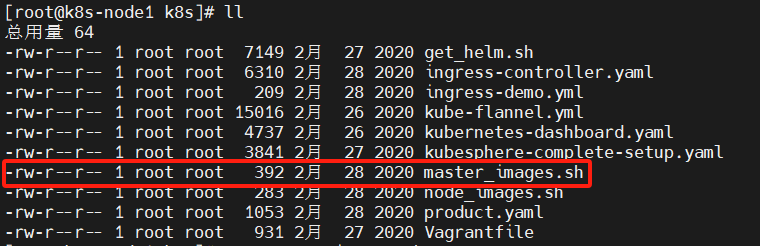
chmod 700 master_images.sh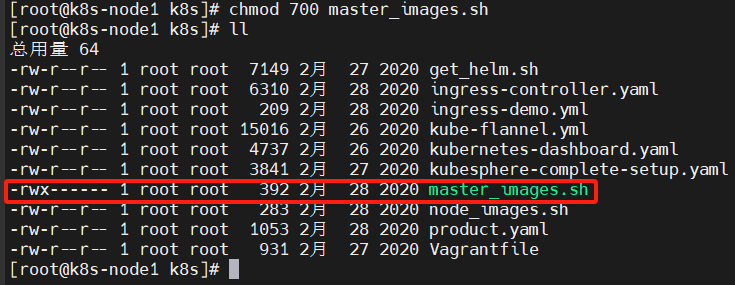
(4)、启动脚本
./master_images.sh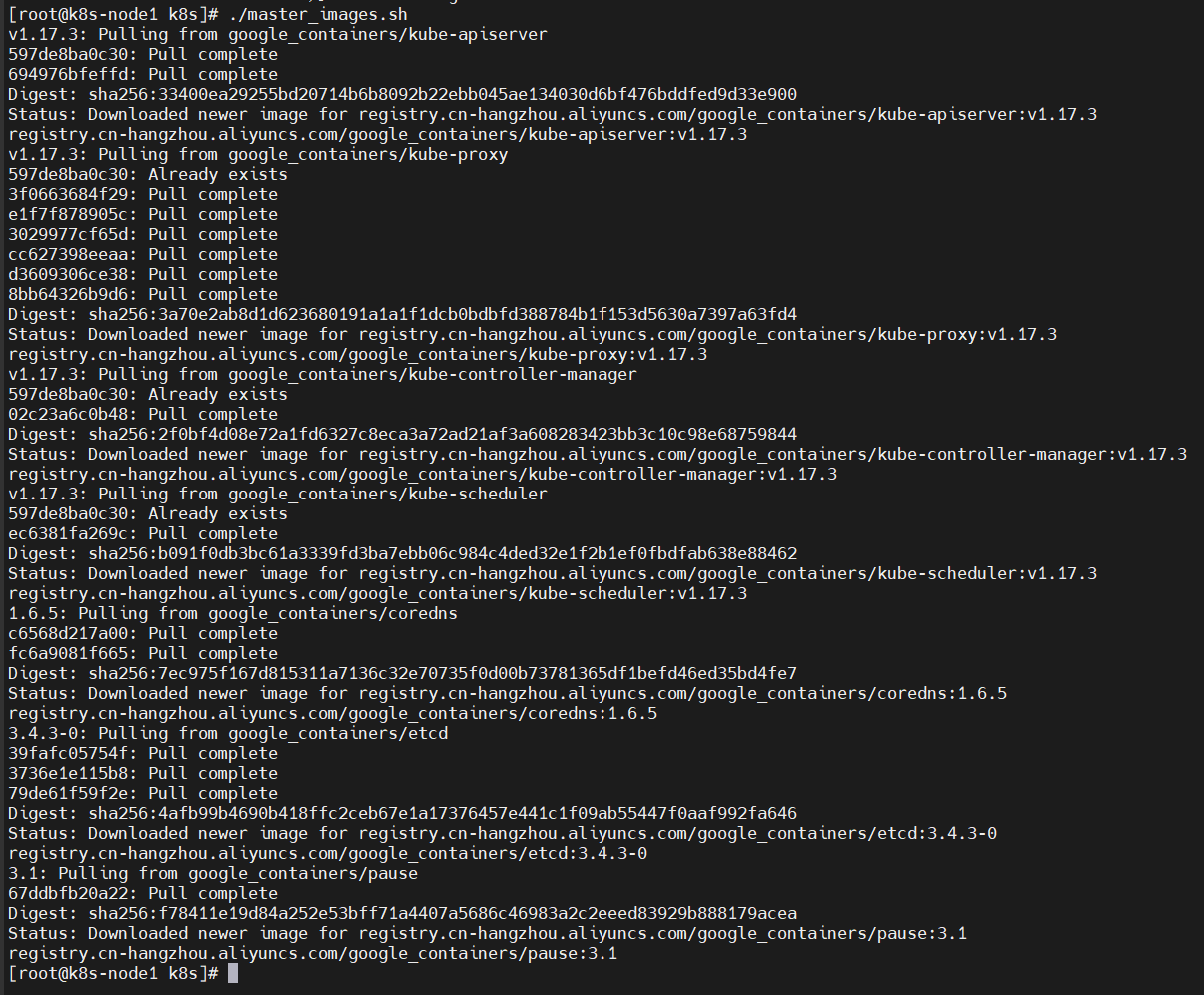
-
master 节点初始化
kubeadm init \ --apiserver-advertise-address=192.168.119.133 \ --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \ --kubernetes-version v1.17.3 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=10.244.0.0/16由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址。可以手动
按照我们的 images.sh 先拉取镜像,地址变为 registry.aliyuncs.com/google_containers 也可以。科普:无类别域间路由(Classless Inter-Domain Routing、CIDR)是一个用于给用户分配 IP
地址以及在互联网上有效地路由 IP 数据包的对 IP 地址进行归类的方法。
拉取可能失败,需要下载镜像。运行完成提前复制:加入集群的令牌
【注意】初始化的时候报错
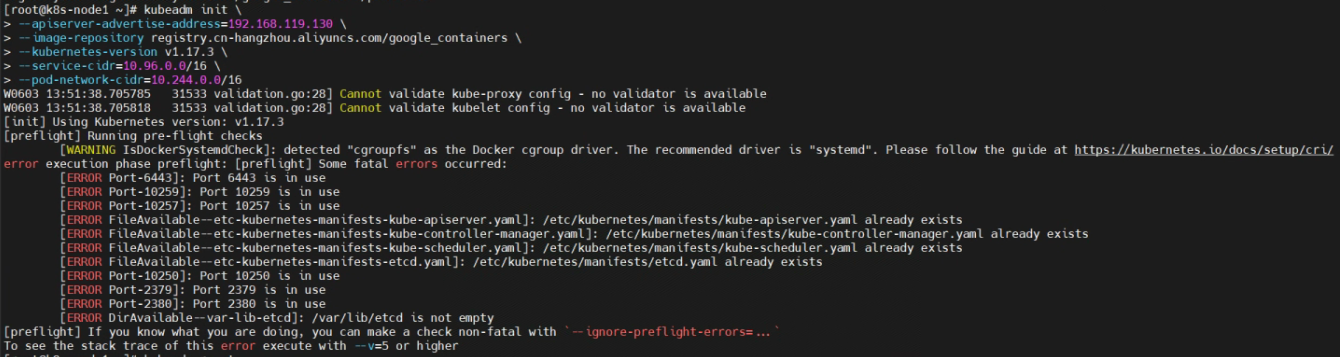
尝试推倒重来,重置k8s集群
kubeadm reset提示是否确认,是。然后成功重置

重新安装,成功
-
测试 kubectl(主节点执行)
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config获取所有节点
kubectl get nodes目前 master 状态为 notready。等待网络加入完成即可。
查看 kubelet 日志
journalctl -u kubelet先记录下来,等网络加入完成才可以在从节点操作
kubeadm join 192.168.119.130:6443 --token qyc2xb.1ygxll0plko0te5n \ --discovery-token-ca-cert-hash sha256:6bfd3aeba6116f586b39f15428e6f358055fb14b819414785f7b4499da9255fb
kubeadm join 192.168.119.133:6443 --token gqb4j5.c6f3n7hd2gaif5bv \
--discovery-token-ca-cert-hash sha256:73746a1d5a5efbae299b1b96c363395f8e9dd08e69c7dd168abf41eff38aa064
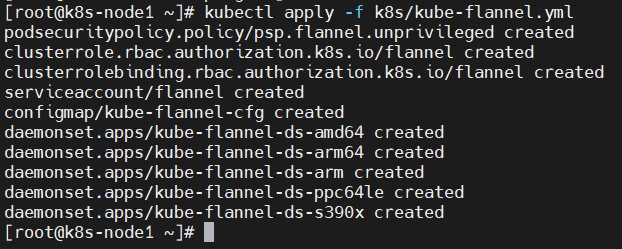
2.7、安装 Pod 网络插件(CNI)(master节点)
初始化完成后,对集群进行网络配置
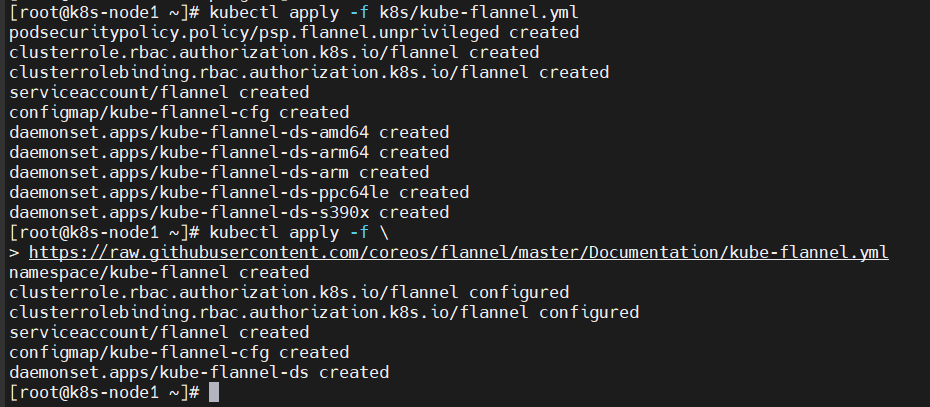
kubectl apply -f k8s/kube-flannel.yml
kubectl apply -f \
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
以上地址可能被墙,大家获取上传我们下载好的 flannel.yml 运行即可,同时 flannel.yml 中
指定的 images 访问不到可以去 docker hub 找一个
wget yml 的地址
vi 修改 yml 所有 amd64 的地址都修改了即可。
等待大约 3 分钟
kubectl get pods -n kube-system 查看指定名称空间的 pods
kubectl get pods --all-namespaces 查看所有名称空间的 pods
ip link set cni0 down 如果网络出现问题,关闭 cni0,重启虚拟机继续测试
执行 watch kubectl get pod -n kube-system -o wide 监控 pod 进度
等 3-10 分钟,完全都是 running 以后继续

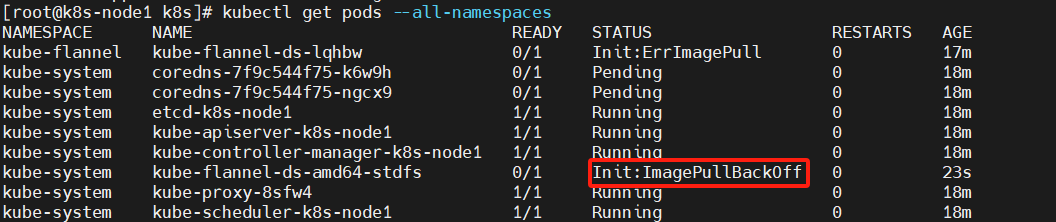
【注意】
问题一:(主节点)
k8s应用flannel状态为Init:ImagePullBackOff
查看kube-flannel.yml文件时发现quay.io/coreos/flannel:v0.11.0-amd64
quay.io网站目前国内无法访问
解决方法:
查看kube-flannel.yml需要什么image
[root@k8s-node1 k8s]# grep image kube-flannel.yml
image: quay.io/coreos/flannel:v0.11.0-amd64
image: quay.io/coreos/flannel:v0.11.0-amd64
image: quay.io/coreos/flannel:v0.11.0-arm64
image: quay.io/coreos/flannel:v0.11.0-arm64
image: quay.io/coreos/flannel:v0.11.0-arm
image: quay.io/coreos/flannel:v0.11.0-arm
image: quay.io/coreos/flannel:v0.11.0-ppc64le
image: quay.io/coreos/flannel:v0.11.0-ppc64le
image: quay.io/coreos/flannel:v0.11.0-s390x
image: quay.io/coreos/flannel:v0.11.0-s390x
下载flannel:v0.11.0-amd64导入到docker中
可以去https://github.com/flannel-io/flannel/releases/tag/v0.11.0官方仓库下载镜像
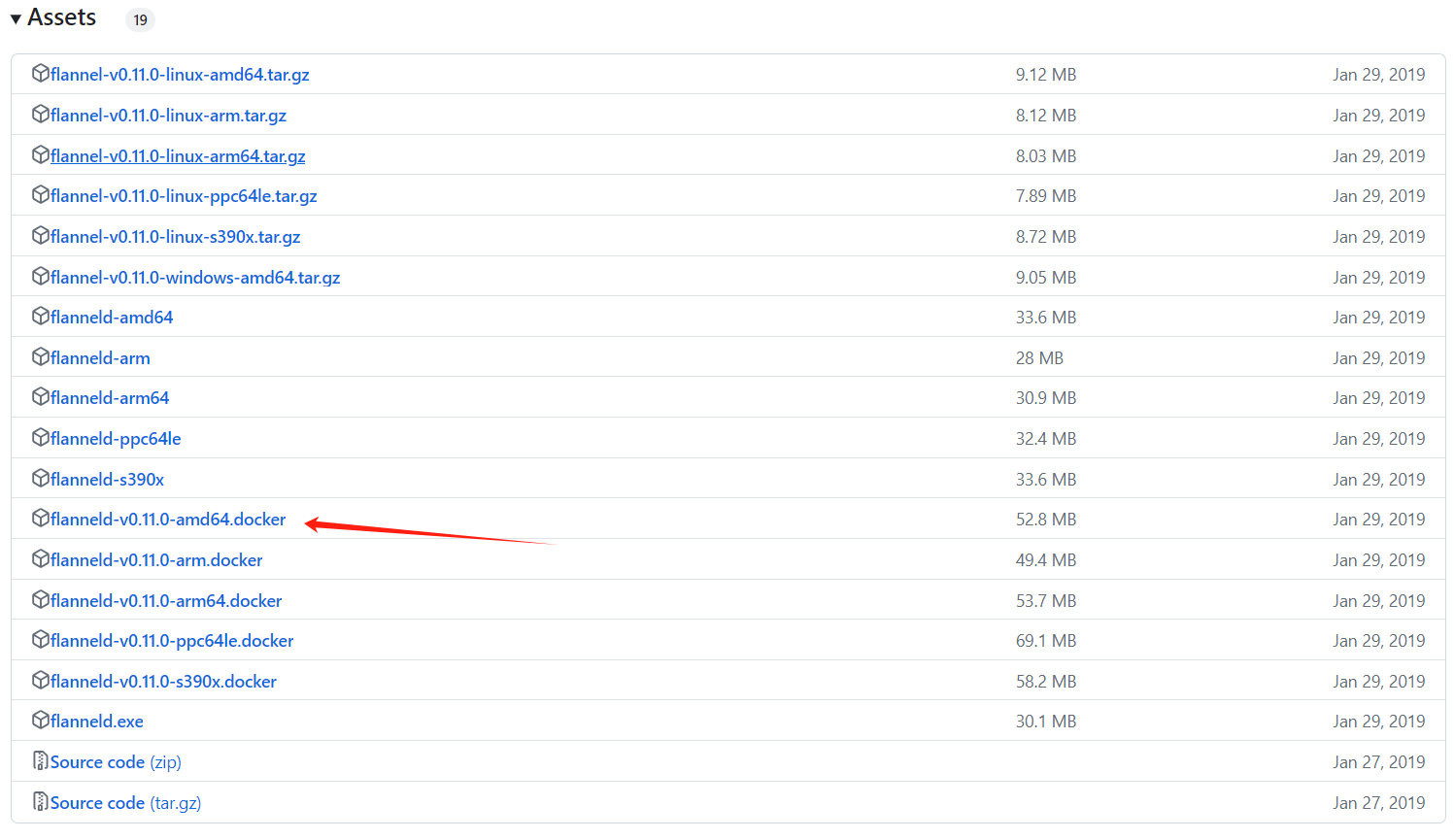
mkdir /opt/cni-plugins
[root@k8s-node1 cni-plugins]# docker load < flanneld-v0.11.0-amd64.docker
7bff100f35cb: Loading layer [==================================================>] 4.672MB/4.672MB
5d3f68f6da8f: Loading layer [==================================================>] 9.526MB/9.526MB
9b48060f404d: Loading layer [==================================================>] 5.912MB/5.912MB
3f3a4ce2b719: Loading layer [==================================================>] 35.25MB/35.25MB
9ce0bb155166: Loading layer [==================================================>] 5.12kB/5.12kB
Loaded image: quay.io/coreos/flannel:v0.11.0-amd64
[root@k8s-node1 cni-plugins]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.17.3 ae853e93800d 4 years ago 116MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.17.3 90d27391b780 4 years ago 171MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.17.3 b0f1517c1f4b 4 years ago 161MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.17.3 d109c0821a2b 4 years ago 94.4MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.5 70f311871ae1 4 years ago 41.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.4.3-0 303ce5db0e90 4 years ago 288MB
quay.io/coreos/flannel v0.11.0-amd64 ff281650a721 5 years ago 52.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 6 years ago 742kB
修改本地Linux上的kube-flannel.yml文件:
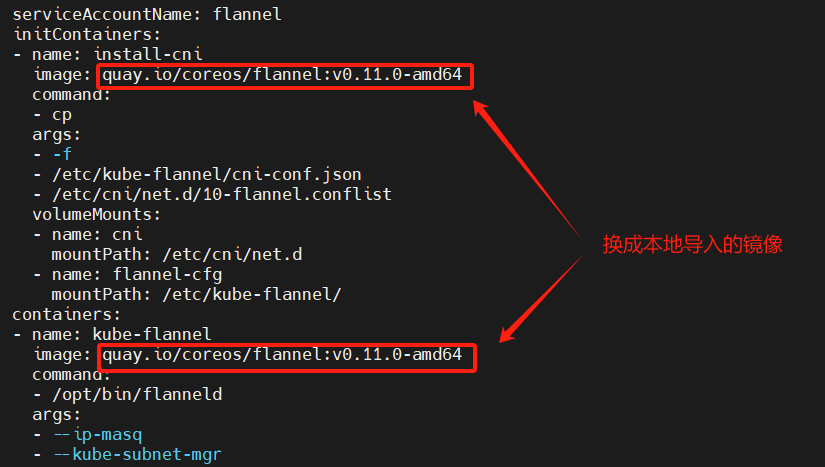
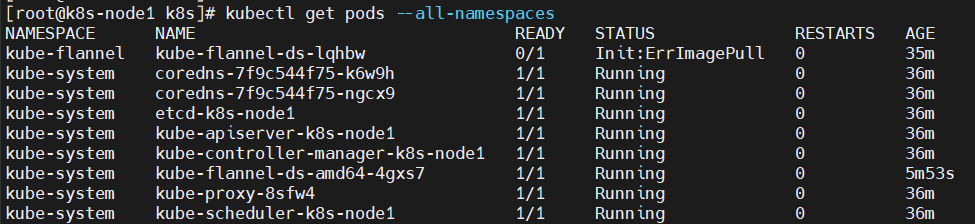
最后刷新pod
kubectl apply -f kube-flannel.yml
结果:
问题二:(所有节点)
执行完毕后,问题表现为coredns无法启动,master与node1处于NotReady状态,如图所示:
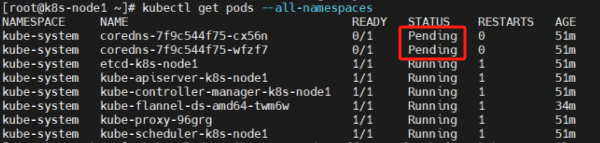
原因排查:
-
对有问题的pod进行describe
报错显示:2个节点都有污点,因此无法调度,于是对k8s-node1进行排查
kubectl describe po coredns-7f9c544f75-cx56n -n kube-system|less
-
对node1进行describe
kubectl describe nodes k8s-node1|less发现错误如下:
KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized由此推断是Kubelet没有部署好,并且是网络插件导致的,因此对Kubelet进行打印
journalctl -u kubelet --since today | less6月 16 22:18:26 k8s-node1 kubelet[49627]: : [failed to find plugin "flannel" in path [/opt/cni/bin]] 6月 16 22:18:26 k8s-node1 kubelet[49627]: W0616 22:18:26.884471 49627 cni.go:237] Unable to update cni config: no valid networks found in /etc/cni/net.d 6月 16 22:18:28 k8s-node1 kubelet[49627]: E0616 22:18:28.582488 49627 pod_workers.go:191] Error syncing pod 815f19d1-da0d-467f-a16b-79193ccbae39 ("kube-flannel-ds-lqhbw_kube-flannel(815f19d1-da0d-467f-a16b -79193ccbae39)"), skipping: failed to "StartContainer" for "install-cni-plugin" with ImagePullBackOff: "Back-off pulling image \"docker.io/flannel/flannel-cni-plugin:v1.4.1-flannel1\"" 6月 16 22:18:31 k8s-node1 kubelet[49627]: W0616 22:18:31.887401 49627 cni.go:202] Error validating CNI config list { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "name": "cbr0", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "cniVersion": "0.3.1", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "plugins": [ 6月 16 22:18:31 k8s-node1 kubelet[49627]: { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "type": "flannel", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "delegate": { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "hairpinMode": true, 6月 16 22:18:31 k8s-node1 kubelet[49627]: "isDefaultGateway": true 6月 16 22:18:31 k8s-node1 kubelet[49627]: } 6月 16 22:18:31 k8s-node1 kubelet[49627]: }, 6月 16 22:18:31 k8s-node1 kubelet[49627]: { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "type": "portmap", 6月 16 22:18:31 k8s-node1 kubelet[49627]: "capabilities": { 6月 16 22:18:31 k8s-node1 kubelet[49627]: "portMappings": true 6月 16 22:18:31 k8s-node1 kubelet[49627]: } 6月 16 22:18:31 k8s-node1 kubelet[49627]: } 6月 16 22:18:31 k8s-node1 kubelet[49627]: ] 6月 16 22:18:31 k8s-node1 kubelet[49627]: }最终定位问题至flannel问题
报错:failed to find plugin “flannel” in path /opt/cni/bin
又在网上差了一些资料,得到解决方案
解决方法:
Github 手动下载 cni plugin v0.8.6
地址如下:https://github.com/containernetworking/plugins/releases/download/v0.8.6/cni-plugins-linux-amd64-v0.8.6.tgz
解压后将flannel文件拷贝至 /opt/cni/bin/目录下
mkdir /opt/cni-plugins tar -zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni-plugins/ cp flannel /opt/cni/bin/容器瞬间启动,master节点处于Ready状态。同理,k8s-node2,k8s-node3进行同样操作。问题解决。
2.8、加入 Kubernetes Node(从节点)
在 Node 节点执行。
向集群添加新节点,执行在 kubeadm init 输出的 kubeadm join 命令:
确保 node 节点成功
token 过期怎么办
kubeadm token create --print-join-command
kubeadm token create --ttl 0 --print-join-command
kubeadm join 192.168.119.130:6443 --token oqnc6s.wiqeib0osvp37yxg --discovery-token-ca-cert-hash sha256:b3e6f39c9b70eece87cc9d29c32b42b4d0d2db930383e2e799208c07b489979d
执行 watch kubectl get pod -n kube-system -o wide 监控 pod 进度
等 3-10 分钟,完全都是 running 以后使用 kubectl get nodes 检查状态
执行命令报错
[root@k8s-node1 k8s]# kubeadm join 192.168.119.130:6443 --token enj3vg.fikkr30njmptrtem \
> --discovery-token-ca-cert-hash sha256:b7b3baf3082e0d9acd3a0a4f2352224ecb007da583bcc02861f36956c9f017c1
W0605 11:06:13.897366 36607 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR DirAvailable--etc-kubernetes-manifests]: /etc/kubernetes/manifests is not empty
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
-
问题一
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/报错原因:
在kubeadm join 添加工作节点时出现docker 驱动cgroup的问题。检测到"cgroupfs"作为Docker的cgroup驱动程序,推荐使用systemd驱动。解决办法:
-
修改前先查看驱动信息
docker info | grep Cgrou
-
修改/etc/docker/daemon.json文件
vi /etc/docker/daemon.json #添加以下信息 { "exec-opts":["native.cgroupdriver=systemd"] }
-
重启docker
systemctl restart docker -
确认下修改后的驱动信息

-
-
问题二
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists [ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists报错原因:
有残留文件
解决办法
#删除k8s配置文件和证书文件 rm -rf /etc/kubernetes/kubelet.conf /etc/kubernetes/pki/ca.crt -
问题三
端口占用提示:[ERROR Port-10250]: Port 10250 is in usesudo yum install -y net-tools -q #安装相关工具(-q:静默安装)然后查看端口

可以看出,是K8S占用了,那就尝试重启服务看看能不能解决

2.9、入门操作 kubernetes 集群
1、部署一个 tomcat
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8
kubectl get pods -o wide #可以获取到 tomcat 信息

2、暴露 tomcat 访问
kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort
现在我们使用NodePort的方式暴露,这样访问每个节点的端口,都可以访问各个Pod,如果节点宕机,就会出现问题。
Pod 的 80 映射容器的 8080;service 会代理 Pod 的 80
kubectl get svc

3、动态扩容测试
kubectl get deployment

应用升级 kubectl set image (–help 查看帮助)
扩容:
kubectl scale --replicas=3 deployment tomcat6
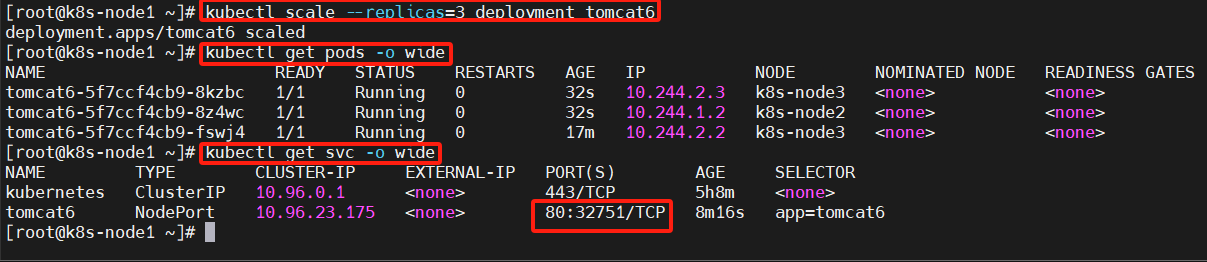
扩容了多份,所有无论访问哪个 node 的指定端口,都可以访问到 tomcat6
4、以上操作的 yaml 获取
参照 k8s 细节
5、删除
kubectl get all
kubectl delete deployment.apps/tomcat6
kubectl delete service/tomcat6
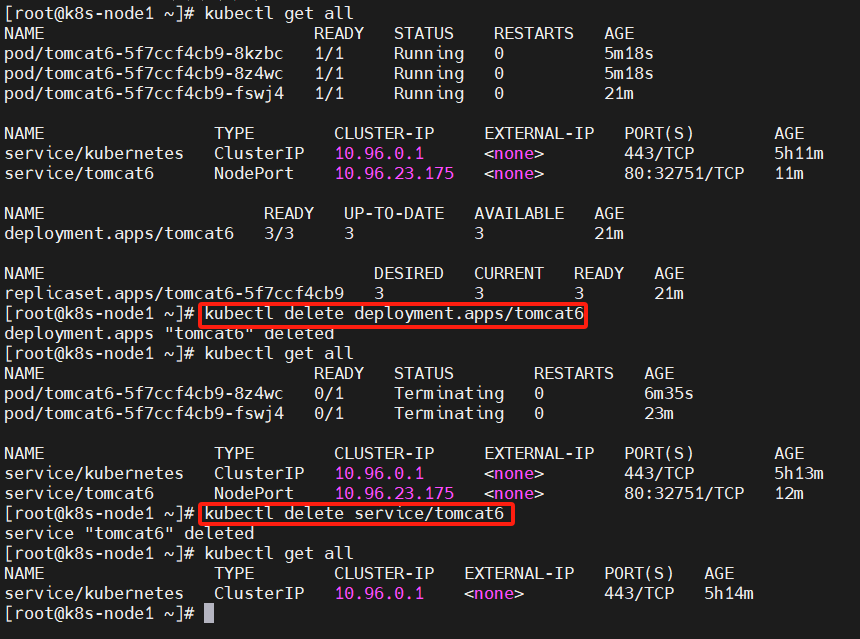
流程;创建 deployment 会管理 replicas,replicas 控制 pod 数量,有 pod 故障会自动拉起新的 pod
2.10、安装默认 dashboard
1、部署 dashboard
kubectl apply -f \
https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommende
d/kubernetes-dashboard.yaml
墙的原因,文件已经放在我们的 code 目录,自行上传
文件中无法访问的镜像,自行去 docker hub 找
2、暴露 dashboard 为公共访问
默认 Dashboard 只能集群内部访问,修改 Service 为 NodePort 类型,暴露到外部:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 30001
selector:
k8s-app: kubernetes-dashboard
访问地址:http://NodeIP:30001
3、创建授权账户
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk
'/dashboard-admin/{print $1}')
使用输出的 token 登录 Dashboard。
二、K8S 细节
1、kubectl
-
kubectl 文档
https://kubernetes.io/zh/docs/reference/kubectl/overview/ -
资源类型
https://kubernetes.io/zh-cn/docs/reference/kubectl/#%E8%B5%84%E6%BA%90%E7%B1%BB%E5%9E%8B -
格式化输出
https://kubernetes.io/zh-cn/docs/reference/kubectl/#%E6%A0%BC%E5%BC%8F%E5%8C%96%E8%BE%93%E5%87%BA -
常用操作
https://kubernetes.io/zh-cn/docs/reference/kubectl/#%E7%A4%BA%E4%BE%8B-%E5%B8%B8%E7%94%A8%E6%93%8D%E4%BD%9C -
命令参考
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
2、yaml 语法
-
yml 模板

-
yaml 字段解析
参照官方文档:
https://kubernetes.io/zh-cn/docs/reference/kubectl/#%E8%B5%84%E6%BA%90%E7%B1%BB%E5%9E%8B -
yaml输出
在此示例中,以下命令将单个 pod 的详细信息输出为 YAML 格式的对象:
kubectl get pod web-pod-13je7 -o yaml–dry-run:
–dry-run=‘none’: Must be “none”, “server”, or “client”. If client strategy, only print the object that would be sent, without sending it. If server strategy, submit server-side request without persisting the resource. 值必须为,或。
- none
- server:提交服务器端请求而不持久化资源。
- client:只打印该发送对象,但不发送它。
也就是说,通过–dry-run选项,并不会真正的执行这条命令。
输出yaml案例
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 --dry-run -o yaml > tomact6-deployment.yaml查看yaml:
cat tomact6-deployment.yamlapiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: tomcat6 name: tomcat6 spec: replicas: 1 selector: matchLabels: app: tomcat6 strategy: {} template: metadata: creationTimestamp: null labels: app: tomcat6 spec: containers: - image: tomcat:6.0.53-jre8 name: tomcat resources: {} status: {}
3、入门操作
-
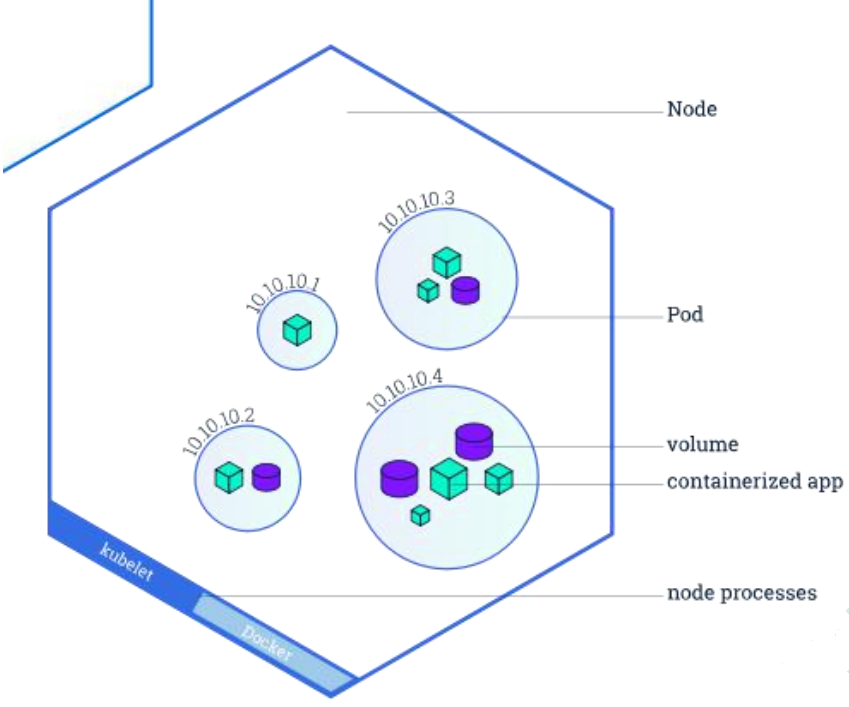
Pod 是什么,Controller 是什么
https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/#pods-and-controllersPod和控制器
控制器可以为您创建和管理多个 Pod,管理副本和上线,并在集群范围内提供自修复能力。
例如,如果一个节点失败,控制器可以在不同的节点上调度一样的替身来自动替换 Pod。
包含一个或多个 Pod 的控制器一些示例包括:
Deployment
StatefulSet
DaemonSet
控制器通常使用您提供的 Pod 模板来创建它所负责的 Pod
-
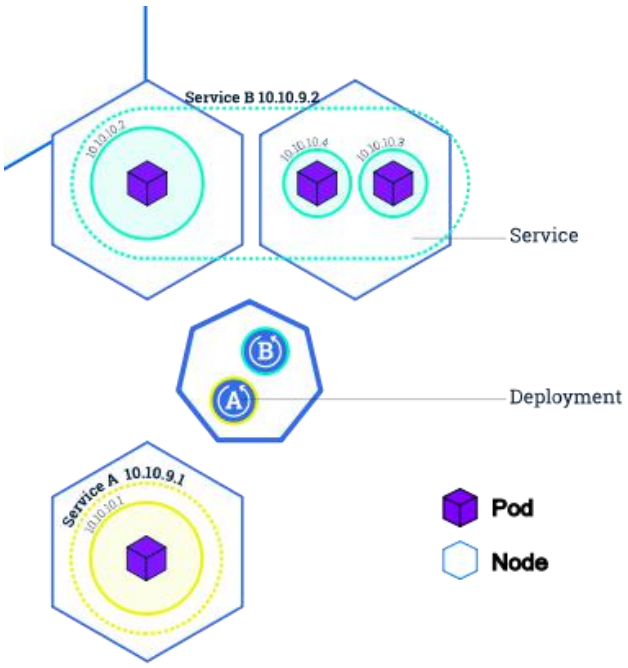
Deployment&Service 是什么
-
Service 的意义
- 部署一个 nginx
kubectl create deployment nginx --image=nginx - 暴露 nginx 访问
kubectl expose deployment nginx --port=80 --type=NodePort
统一应用访问入口;
Service 管理一组 Pod。
防止 Pod 失联(服务发现)、定义一组 Pod 的访问策略
现在 Service 我们使用 NodePort 的方式暴露,这样访问每个节点的端口,都可以访问到这个 Pod,如果节点宕机,就会出现问题。
- 部署一个 nginx
-
labels and selectors
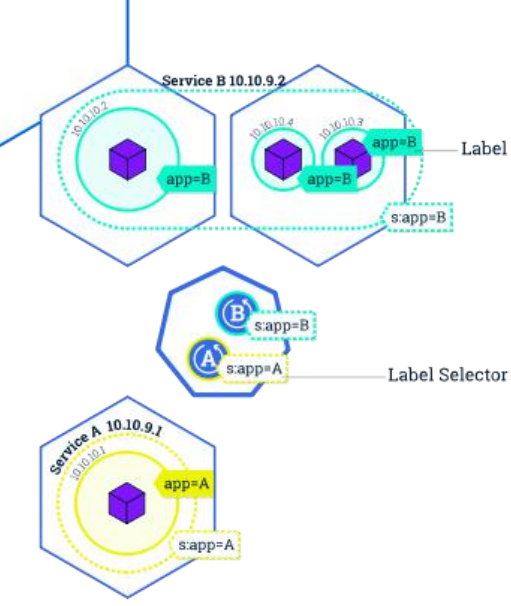
-
Ingress
通过 Service 发现 Pod 进行关联。基于域名访问。
通过 Ingress Controller 实现 Pod 负载均衡
支持 TCP/UDP 4 层负载均衡和 HTTP 7 层负载均衡
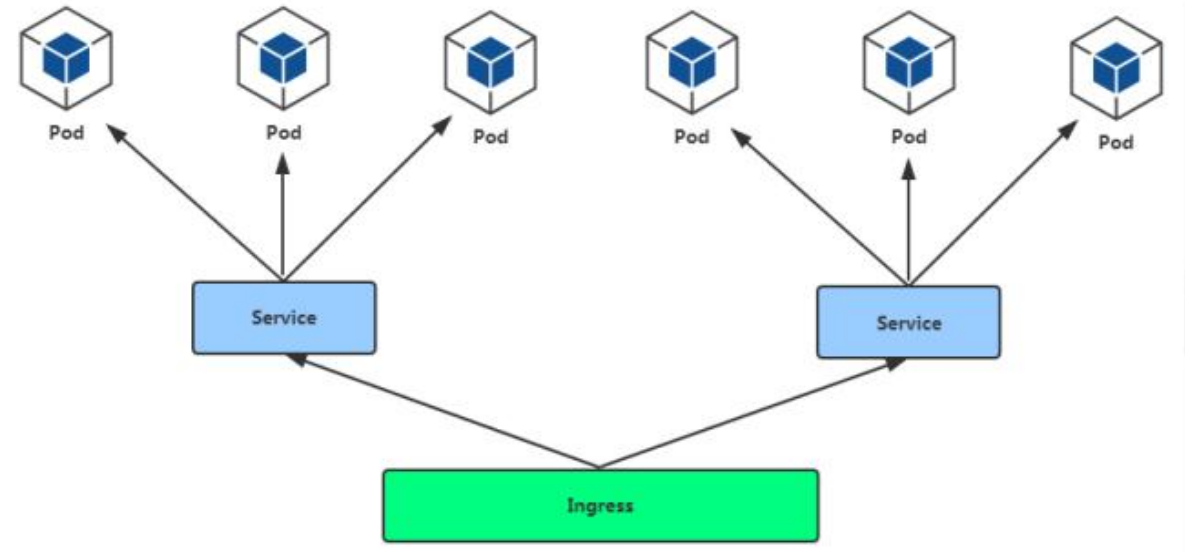
步骤:
1)、部署 Ingress Controller
2)、创建 Ingress 规则apiVersion: extensions/v1beta1 kind: Ingress metadata: name: web spec: rules: - host: tomcat6.atguigu.com http: paths: - backend: serviceName: tomcat6 servicePort: 80如果再部署了 tomcat8;看效果;
kubectl create deployment tomcat8 --image=tomcat:8.5.51-jdk8 kubectl expose deployment tomcat8 --port=88 --target-port=8080 --type=NodePort kubectl delete xxx #删除指定资源随便配置域名对应哪个节点,都可以访问 tomcat6/8;因为所有节点的 ingress-controller 路由表是同步的。
-
网络模型
Kubernetes 的网络模型从内至外由四个部分组成:- Pod 内部容器所在的网络
- Pod 所在的网络
- Pod 和 Service 之间通信的网络
- 外界与 Service 之间通信的网络
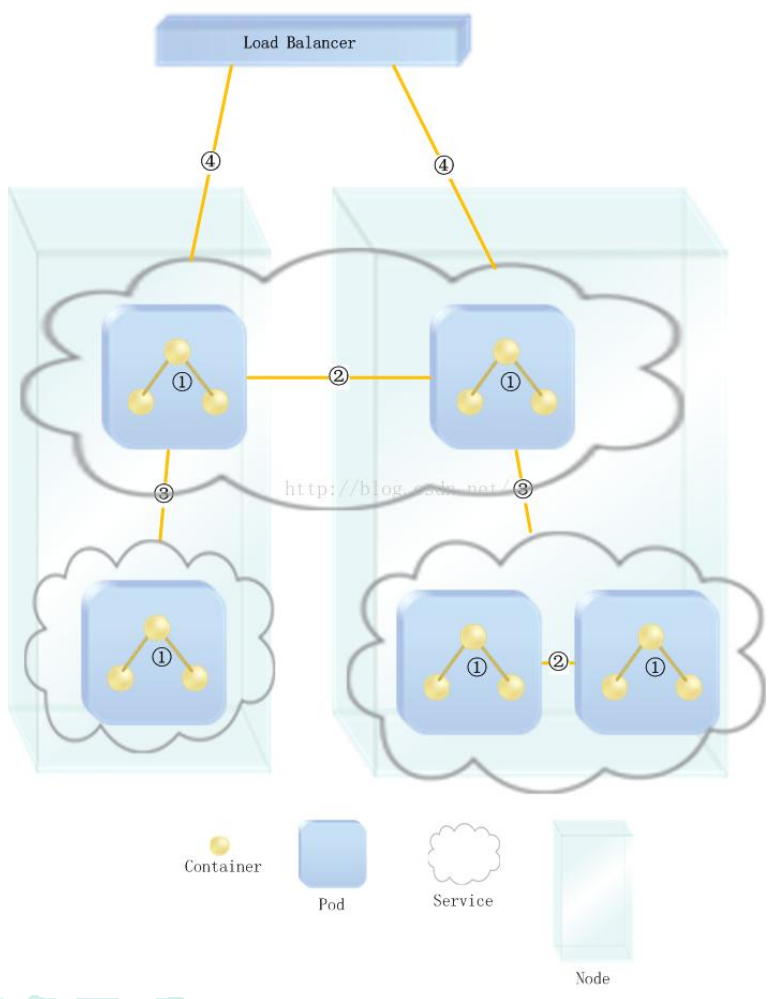
4、项目部署
项目部署流程:
- 制作项目镜像(将项目制作为 Docker 镜像,要熟悉 Dockerfile 的编写)
- 控制器管理 Pod(编写 k8s 的 yaml 即可)
- 暴露应用
- 日志监控
接下来我们还是以原先部署tomact6为实例
-
创建yaml
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 --dry-run -o yaml > tomact6-deployment.yaml
修改yaml
vi tomact6-deployment.yamlapiVersion: apps/v1 kind: Deployment metadata: labels: app: tomcat6 name: tomcat6 spec: replicas: 3 selector: matchLabels: app: tomcat6 template: metadata: labels: app: tomcat6 spec: containers: - image: tomcat:6.0.53-jre8 name: tomcat -
应用 tomact6-deployment.yaml 部署tomact6
kubectl apply -f tomact6-deployment.yaml
查看某个pod的具体信息:
[root@k8s-node1 k8s]# kubectl get pods NAME READY STATUS RESTARTS AGE tomcat6-5f7ccf4cb9-qrnvh 1/1 Running 0 11h tomcat6-5f7ccf4cb9-sb6jg 1/1 Running 0 11h tomcat6-5f7ccf4cb9-xsxsx 1/1 Running 0 11h [root@k8s-node1 k8s]# kubectl get pods tomcat6-5f7ccf4cb9-qrnvh -o yaml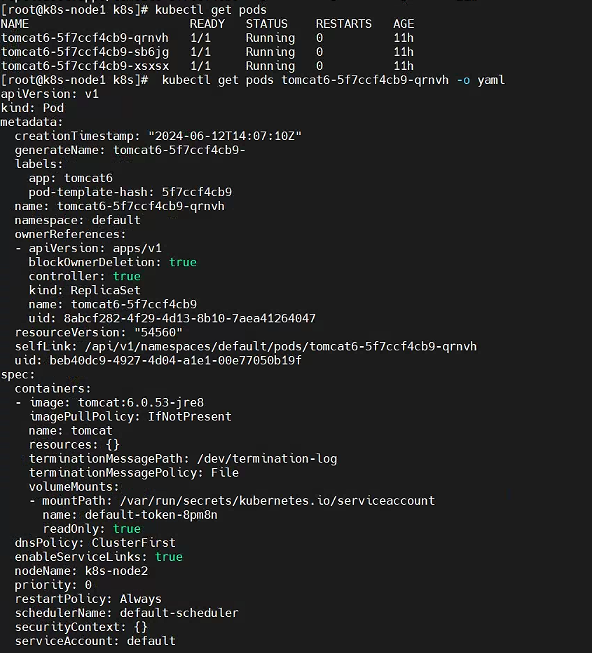
-
暴露 tomcat6 访问
前面我们通过命令行的方式,部署和暴露了tomcat,实际上也可以通过yaml的方式来完成这些操作。暴露端口也通过yaml,生成yaml,并部署kubectl expose deployment tomcat6 --port=80 --target-port=8080 --type=NodePort --dry-run -o yaml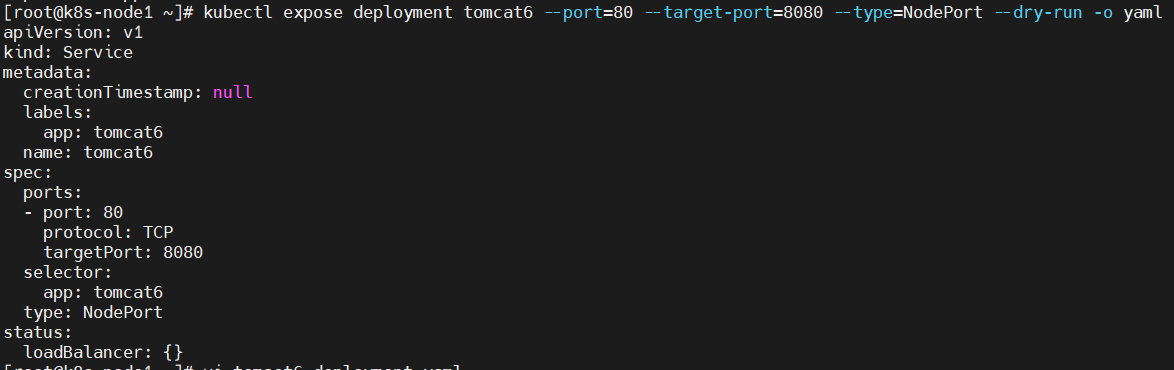
-
整合 tomact6-deployment.yaml - 关联部署和service
将这段输出和“tomcat6-deployment.yaml”用—进行拼接,表示部署完毕并进行暴露服务:
vi tomact6-deployment.yamlapiVersion: apps/v1 kind: Deployment #部署 metadata: labels: app: tomcat6 #标签 name: tomcat6 spec: replicas: 3 #副本数 selector: matchLabels: app: tomcat6 template: metadata: labels: app: tomcat6 spec: containers: - image: tomcat:6.0.53-jre8 name: tomcat --- apiVersion: v1 kind: Service metadata: labels: app: tomcat6 #标签 name: tomcat6 spec: ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: tomcat6 #标签 type: NodePort上面类型一个是Deployment,一个是Service
-
删除以前的部署
kubectl get all kubectl delete deployment.apps/tomcat6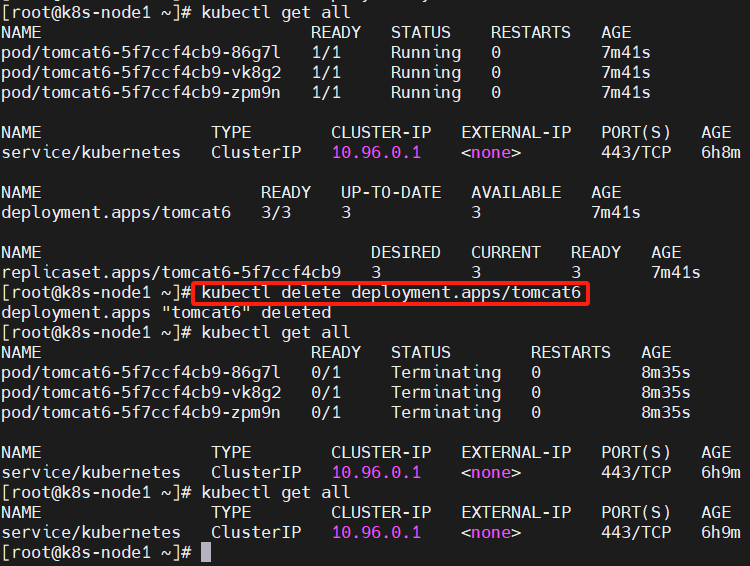
-
部署并暴露服务
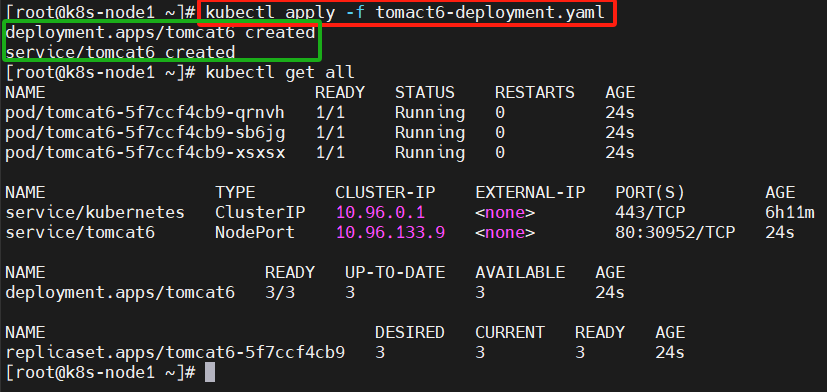
kubectl apply -f tomact6-deployment.yaml查看服务和部署信息
-
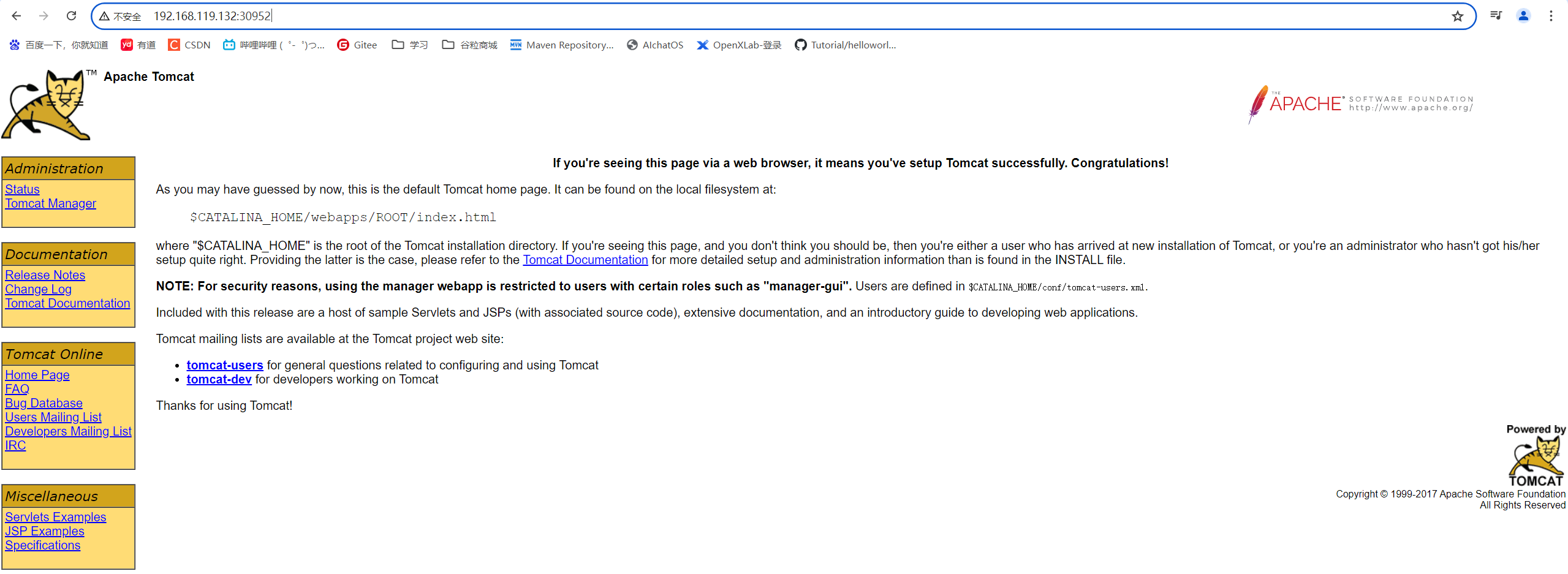
测试
访问k8s-node1,k8s-node1和k8s-node3的30952端口:随便访问一个地址:http://192.168.119.132:30952/
现在的问题是service的3个pod都可以访问,但怎么创建个总的管理者,以便负载均衡
-
部署Ingeress
通过Ingress发现pod进行关联。基于域名访问
通过Ingress controller实现POD负载均衡
支持TCP/UDP 4层负载均衡和HTTP 7层负载均衡可以把ingress理解为nginx,通过域名访问service端口
- Ingress管理多个service
- service管理多个pod
步骤:
1)、部署Ingress controller主节点执行“k8s/ingress-controller.yaml”,
cd k8s kubectl apply -f ingress-controller.yaml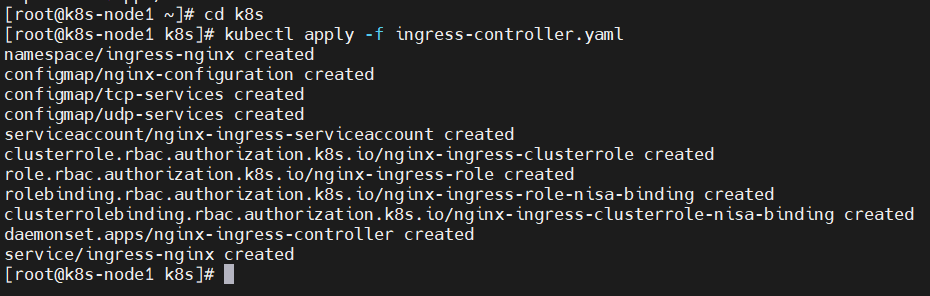
查看
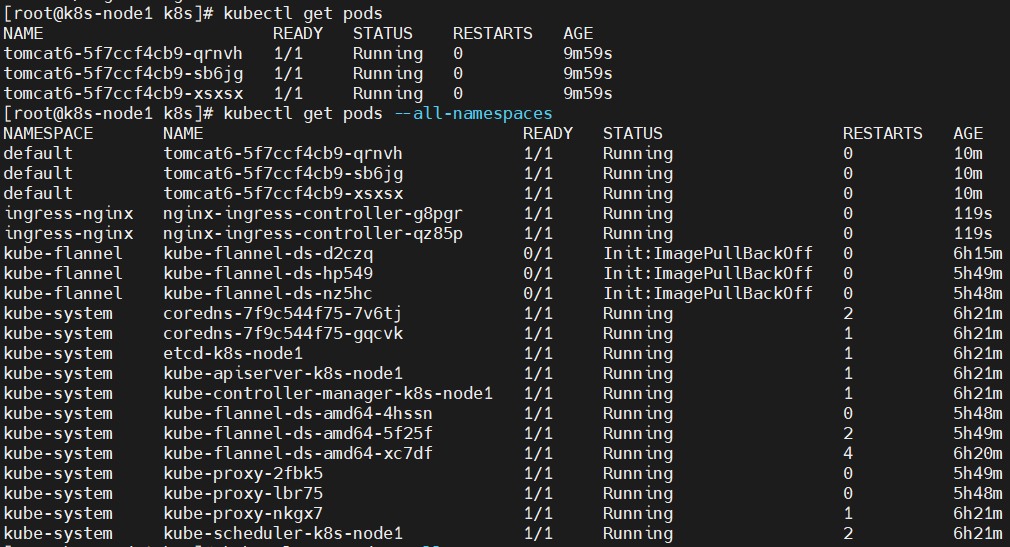
这里master节点负责调度,具体执行交给node2和node3来完成2)、创建Ingress规则
vi ingress-tomact6.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: name: web spec: rules: - host: tomcat6.atguigu.com http: paths: - backend: serviceName: tomcat6 servicePort: 80执行
kubectl apply -f ingress-tomact6.yaml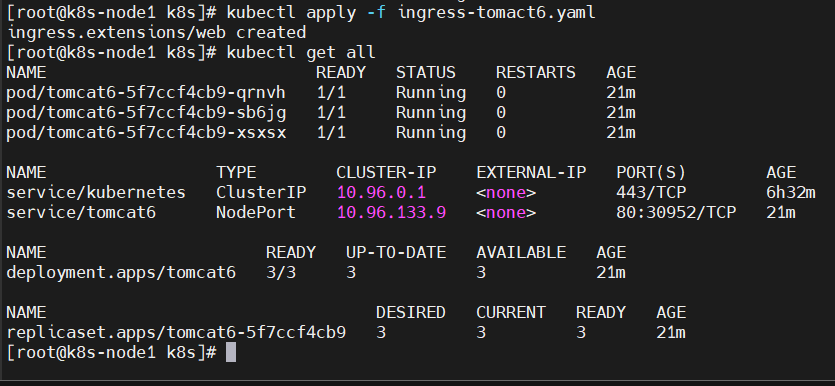
修改本机的hosts文件,添加如下的域名转换规则:
修改“C:\Windows\System32\drivers\etc\hosts”192.168.119.130 tomact6.atguigu.com 192.168.119.131 tomact6.atguigu.com 192.168.119.132 tomact6.atguigu.com访问:http://tomact6.atguigu.com:30952/
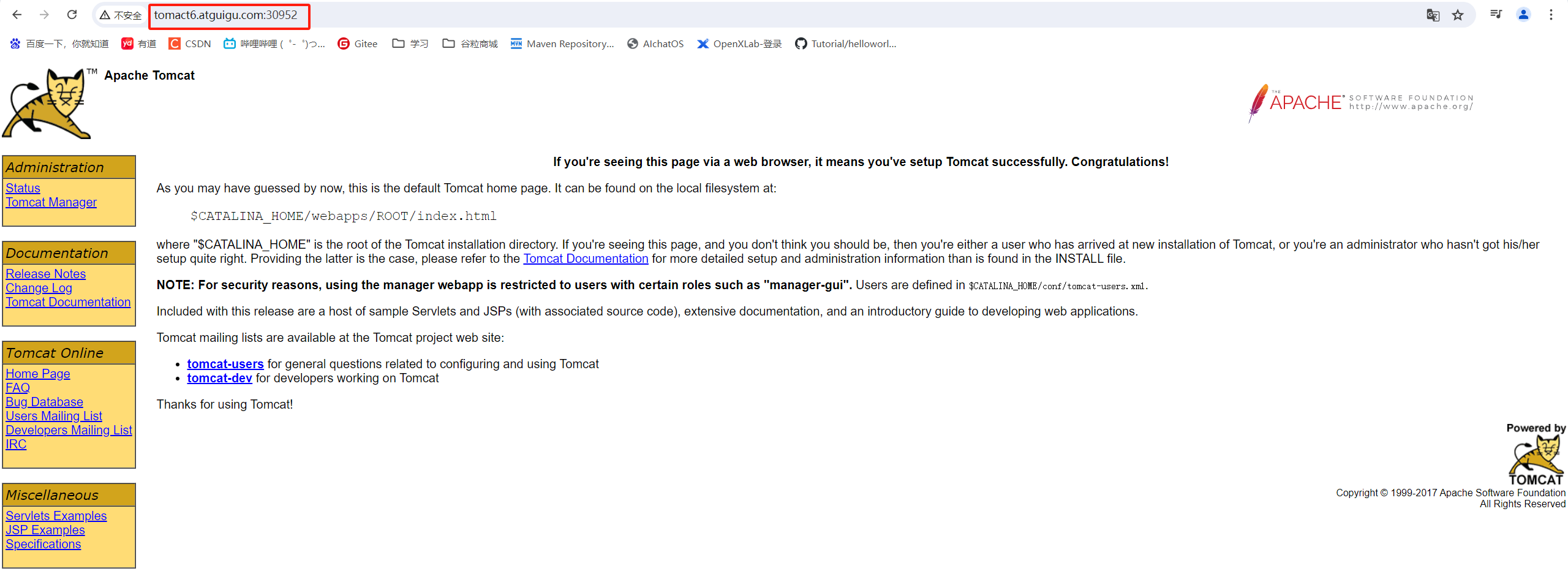
并且集群中即便有一个节点不可用,也不影响整体的运行。
三、KubeSphere
默认的 dashboard 没啥用,我们用 kubesphere 可以打通全部的 devops 链路。
Kubesphere 集成了很多套件,集群要求较高
https://kubesphere.io/
Kuboard 也很不错,集群要求不高
https://kuboard.cn/support/
1、简介
KubeSphere 是一款面向云原生设计的开源项目,在目前主流容器调度平台 Kubernetes 之上构建的分布式多租户容器管理平台,提供简单易用的操作界面以及向导式操作方式,在降低用户使用容器调度平台学习成本的同时,极大降低开发、测试、运维的日常工作的复杂度。
2、安装
2.1、前提条件
https://v2-1.docs.kubesphere.io/docs/zh-CN/installation/prerequisites/
2.2、安装前提环境
2.2.1、安装 helm(master 节点执行)
Helm 是 Kubernetes 的包管理器。包管理器类似于我们在 Ubuntu 中使用的 apt、Centos中使用的 yum 或者 Python 中的 pip 一样,能快速查找、下载和安装软件包。Helm 由客户端组件 helm 和服务端组件 Tiller 组成, 能够将一组 K8S 资源打包统一管理, 是查找、共享和使用为 Kubernetes 构建的软件的最佳方式。
1)、安装
curl -L https://git.io/get_helm.sh | bash
墙原因,上传我们给定的 get_helm.sh,chmod 700 然后./get_helm.sh
可能有文件格式兼容性问题,用 vi 打开该 sh 文件,输入:
:set ff
回车,显示 fileformat=dos,重新设置下文件格式:
:set ff=unix
保存退出:
:wq
# github打不开可以去gitee搜搜,一般软件都有人克隆过
# 可以去这里下载压缩包 https://github.com/helm/helm/releases/tag/v2.16.13
# helm-v2.16.3-linux-amd64.tar.gz
tar xf helm-v2.16.3-linux-amd64.tar.gz
cp linux-amd64/helm /usr/local/bin
cp linux-amd64/tiller /usr/local/bin
helm version
# Client: &version.Version{SemVer:"v2.16.3"}
# Error: could not find tiller
2)、验证版本
helm version
3)、创建权限(master 执行)
创建 helm-rbac.yaml,写入如下内容
vi helm-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
应用配置
kubectl apply -f helm-rbac.yaml

2.2.2、安装 Tiller(master 执行)
1)、初始化
helm init --service-account=tiller --tiller-image=jessestuart/tiller:v2.16.3 --history-max 300
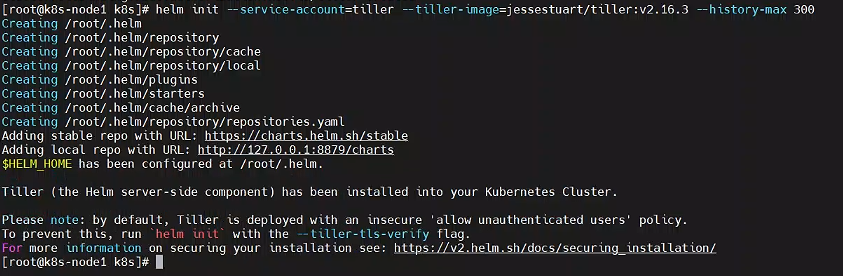
–tiller-image 指定镜像,否则会被墙。大家使用这个镜像比较好
jessestuart/tiller:v2.16.3
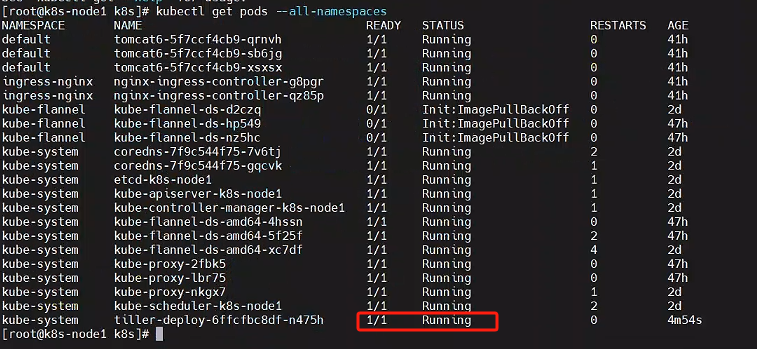
等待节点上部署的 tiller 完成即可
kubectl get pod --all-namespaces
【注意】
如果初始化执行指定镜像还是报错。更改仓库地址:尝试将稳定仓库的 URL 更改为其他可用的地址。您可以尝试使用 Helm 官方维护的仓库地址进行初始化。
报错内容:
Creating /root/.helm/repository/repositories.yaml
Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com
Error: error initializing: Looks like "https://kubernetes-charts.storage.googleapis.com" is not a valid chart repository or cannot be reached: Failed to fetch https://kubernetes-charts.storage.googleapis.com/index.yaml : 403 Forbidden
更改仓库地址命令:
helm init --service-account=tiller --tiller-image=jessestuart/tiller:v2.16.3 --history-max 300 --stable-repo-url https://charts.helm.sh/stable
2)、测试
helm install stable/nginx-ingress --name nginx-ingress
helm ls
helm delete nginx-ingress
3)、使用语法
创建一个 chart 范例
helm create helm-chart
检查 chart 语法
helm lint ./helm-chart
使用默认 chart 部署到 k8s
helm install --name example1 ./helm-chart --set service.type=NodePort
查看是否部署成功
kubectl get pod
2.2.3、安装 OpenEBS(master 执行)
https://v2-1.docs.kubesphere.io/docs/zh-CN/appendix/install-openebs/
前提条件
- 已有 Kubernetes 集群,并安装了 kubectl 或 Helm
- Pod 可以被调度到集群的 master 节点(可临时取消 master 节点的 Taint)
关于第二个前提条件,是由于安装 OpenEBS 时它有一个初始化的 Pod 需要在 k8s-node1 节点启动并创建 PV 给 KubeSphere 的有状态应用挂载。因此,若您的 k8s-node1 节点存在 Taint,建议在安装 OpenEBS 之前手动取消 Taint,待 OpenEBS 与 KubeSphere 安装完成后,再对 k8s-node1 打上 Taint,以下步骤供参考:
-
例如本示例有一个 k8s-node1 节点,节点名称即 k8s-node1,可通过以下命令查看节点名称:
[root@k8s-node1 k8s]# kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME k8s-node1 Ready master 2d v1.17.3 192.168.119.130 <none> CentOS Linux 7 (Core) 3.10.0-1160.119.1.el7.x86_64 docker://19.3.15 k8s-node2 Ready <none> 47h v1.17.3 192.168.119.131 <none> CentOS Linux 7 (Core) 3.10.0-1160.119.1.el7.x86_64 docker://19.3.15 k8s-node3 Ready <none> 47h v1.17.3 192.168.119.132 <none> CentOS Linux 7 (Core) 3.10.0-1160.119.1.el7.x86_64 docker://19.3.15 -
确定 master 节点是否有 taint
kubectl describe node k8s-node1 | grep Taint
-
去掉 master 节点的 Taint:
kubectl taint nodes k8s-node1 node-role.kubernetes.io/master:NoSchedule-
安装 OpenEBS
-
创建 OpenEBS 的 namespace,OpenEBS 相关资源将创建在这个 namespace 下:
kubectl create ns openebs查看所有的名称空间
kubectl get ns
-
安装 OpenEBS,以下列出两种方法,可参考其中任意一种进行创建:
A. 若集群已安装了 Helm,可通过 Helm 命令来安装 OpenEBS:helm install --namespace openebs --name openebs stable/openebs --version 1.5.0B. 除此之外 还可以通过 kubectl 命令安装:
kubectl apply -f https://openebs.github.io/charts/openebs-operator-1.5.0.yaml -
安装 OpenEBS 后将自动创建 4 个 StorageClass,查看创建的 StorageClass:
kubectl get sc
-
如下将 openebs-hostpath设置为 默认的 StorageClass:
kubectl patch storageclass openebs-hostpath -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'

-
至此,OpenEBS 的 LocalPV 已作为默认的存储类型创建成功。可以通过命令
kubectl get pod -n openebs来查看 OpenEBS 相关 Pod 的状态,若 Pod 的状态都是 running,则说明存储安装成功。kubectl get pod -n openebs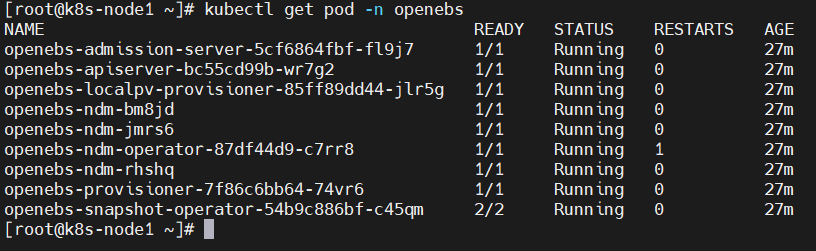
由于在文档开头手动去掉了 k8s-node1 节点的 Taint,我们可以在安装完 OpenEBS 后将 k8s-node1 节点 Taint 加上,避免业务相关的工作负载调度到 k8s-node1 节点抢占 k8s-node1 资源。
kubectl taint nodes k8s-node1 node-role.kubernetes.io=master:NoSchedule
注意:此时不要给master加上污点,否者导致后面的pods安装不上(openldap,redis),待kubesphere安装完成后加上污点
2.3、最小化安装 KubeSphere
-
若集群可用 CPU > 1 Core 且可用内存 > 2 G,可以使用以下命令最小化安装 KubeSphere:
kubectl apply -f https://raw.githubusercontent.com/kubesphere/ks-installer/v2.1.1/kubesphere-minimal.yaml -
提示:若您的服务器提示无法访问 GitHub,可将 kubesphere-minimal.yaml 或 kubesphere-complete-setup.yaml文件保存到本地作为本地的静态文件,再参考上述命令进行安装。
vi kubesphere-mini.yaml--- apiVersion: v1 kind: Namespace metadata: name: kubesphere-system --- apiVersion: v1 data: ks-config.yaml: | --- persistence: storageClass: "" etcd: monitoring: False endpointIps: 192.168.0.7,192.168.0.8,192.168.0.9 port: 2379 tlsEnable: True common: mysqlVolumeSize: 20Gi minioVolumeSize: 20Gi etcdVolumeSize: 20Gi openldapVolumeSize: 2Gi redisVolumSize: 2Gi metrics_server: enabled: False console: enableMultiLogin: False # enable/disable multi login port: 30880 monitoring: prometheusReplicas: 1 prometheusMemoryRequest: 400Mi prometheusVolumeSize: 20Gi grafana: enabled: False logging: enabled: False elasticsearchMasterReplicas: 1 elasticsearchDataReplicas: 1 logsidecarReplicas: 2 elasticsearchMasterVolumeSize: 4Gi elasticsearchDataVolumeSize: 20Gi logMaxAge: 7 elkPrefix: logstash containersLogMountedPath: "" kibana: enabled: False openpitrix: enabled: False devops: enabled: False jenkinsMemoryLim: 2Gi jenkinsMemoryReq: 1500Mi jenkinsVolumeSize: 8Gi jenkinsJavaOpts_Xms: 512m jenkinsJavaOpts_Xmx: 512m jenkinsJavaOpts_MaxRAM: 2g sonarqube: enabled: False postgresqlVolumeSize: 8Gi servicemesh: enabled: False notification: enabled: False alerting: enabled: False kind: ConfigMap metadata: name: ks-installer namespace: kubesphere-system --- apiVersion: v1 kind: ServiceAccount metadata: name: ks-installer namespace: kubesphere-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: creationTimestamp: null name: ks-installer rules: - apiGroups: - "" resources: - '*' verbs: - '*' - apiGroups: - apps resources: - '*' verbs: - '*' - apiGroups: - extensions resources: - '*' verbs: - '*' - apiGroups: - batch resources: - '*' verbs: - '*' - apiGroups: - rbac.authorization.k8s.io resources: - '*' verbs: - '*' - apiGroups: - apiregistration.k8s.io resources: - '*' verbs: - '*' - apiGroups: - apiextensions.k8s.io resources: - '*' verbs: - '*' - apiGroups: - tenant.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - certificates.k8s.io resources: - '*' verbs: - '*' - apiGroups: - devops.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - monitoring.coreos.com resources: - '*' verbs: - '*' - apiGroups: - logging.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - jaegertracing.io resources: - '*' verbs: - '*' - apiGroups: - storage.k8s.io resources: - '*' verbs: - '*' - apiGroups: - admissionregistration.k8s.io resources: - '*' verbs: - '*' --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: ks-installer subjects: - kind: ServiceAccount name: ks-installer namespace: kubesphere-system roleRef: kind: ClusterRole name: ks-installer apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: Deployment metadata: name: ks-installer namespace: kubesphere-system labels: app: ks-install spec: replicas: 1 selector: matchLabels: app: ks-install template: metadata: labels: app: ks-install spec: serviceAccountName: ks-installer containers: - name: installer image: kubesphere/ks-installer:v2.1.1 imagePullPolicy: "Always"执行kubesphere-mini.yaml
kubectl apply -f kubesphere-mini.yaml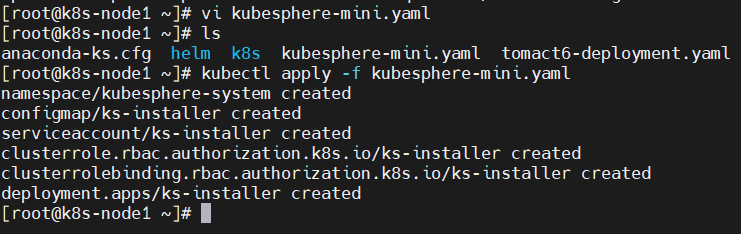
-
查看安装日志,请耐心等待安装成功。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f打印结果
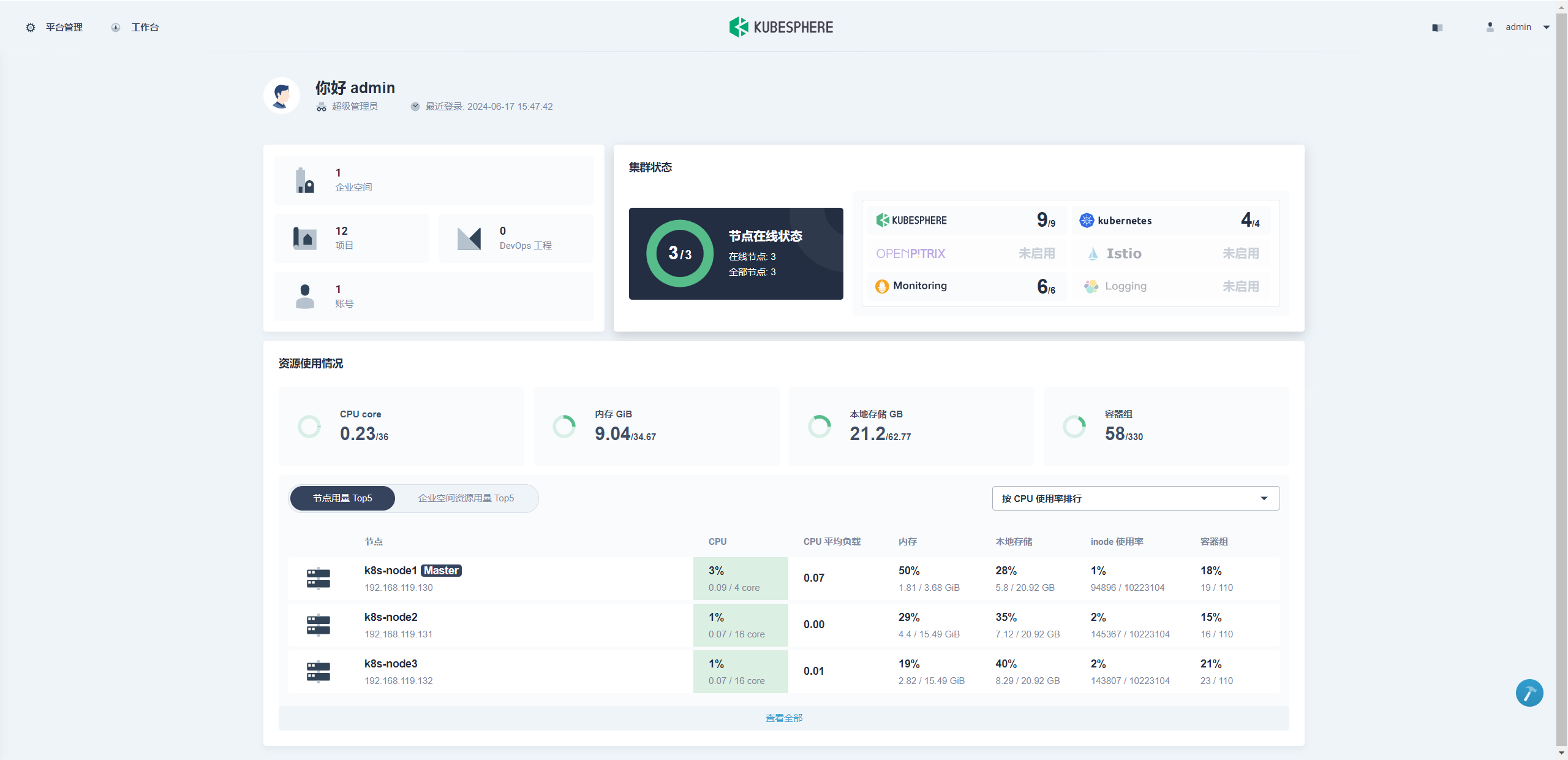
Start installing monitoring ************************************************** task monitoring status is successful total: 1 completed:1 ************************************************** ##################################################### ### Welcome to KubeSphere! ### ##################################################### Console: http://192.168.119.130:30880 Account: admin Password: P@88w0rd NOTES: 1. After logging into the console, please check the monitoring status of service components in the "Cluster Status". If the service is not ready, please wait patiently. You can start to use when all components are ready. 2. Please modify the default password after login. #####################################################- 当所有的pod都是running状态则说明安装完成,才可以访问该地址
kubectl get pods --all-namespaces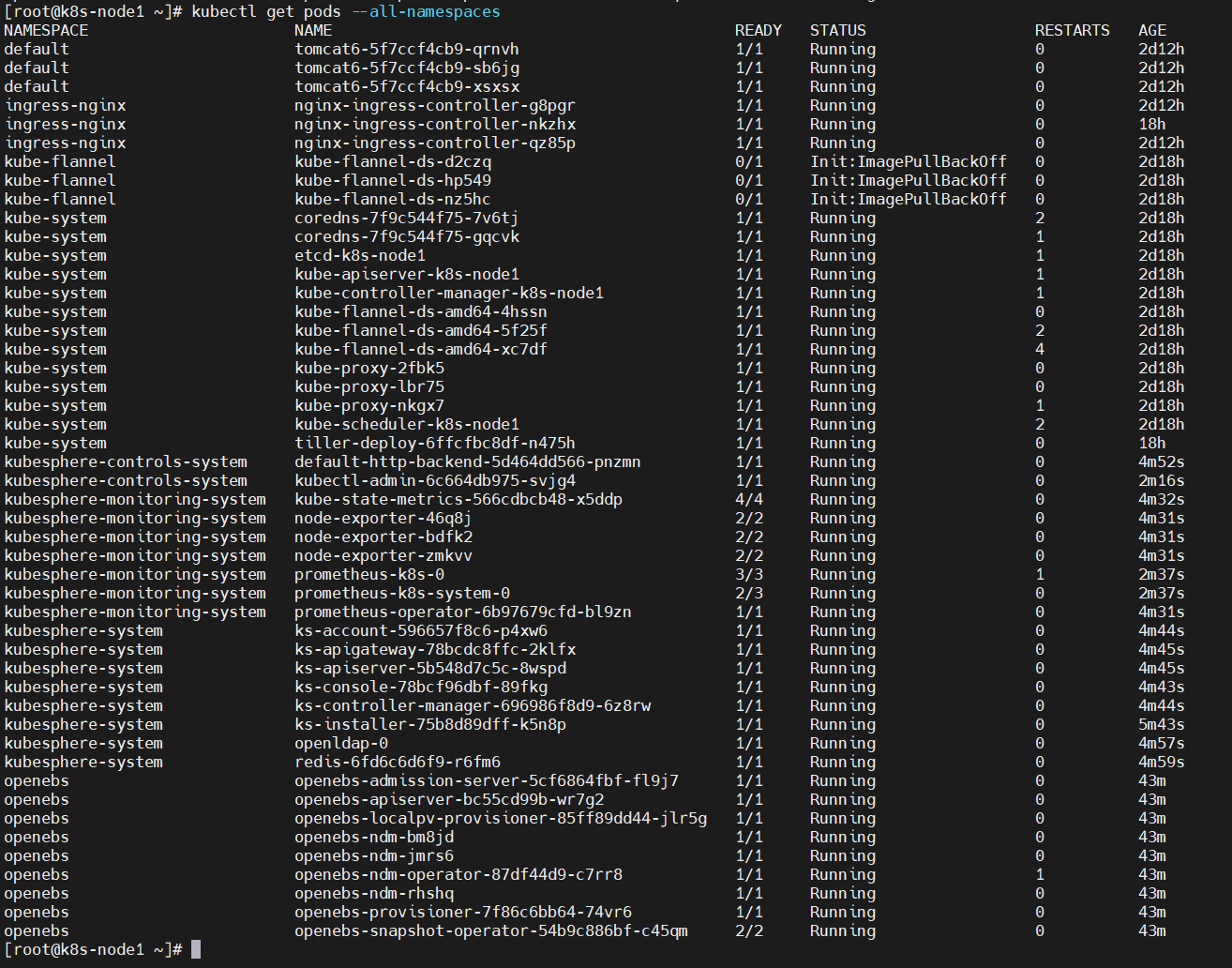
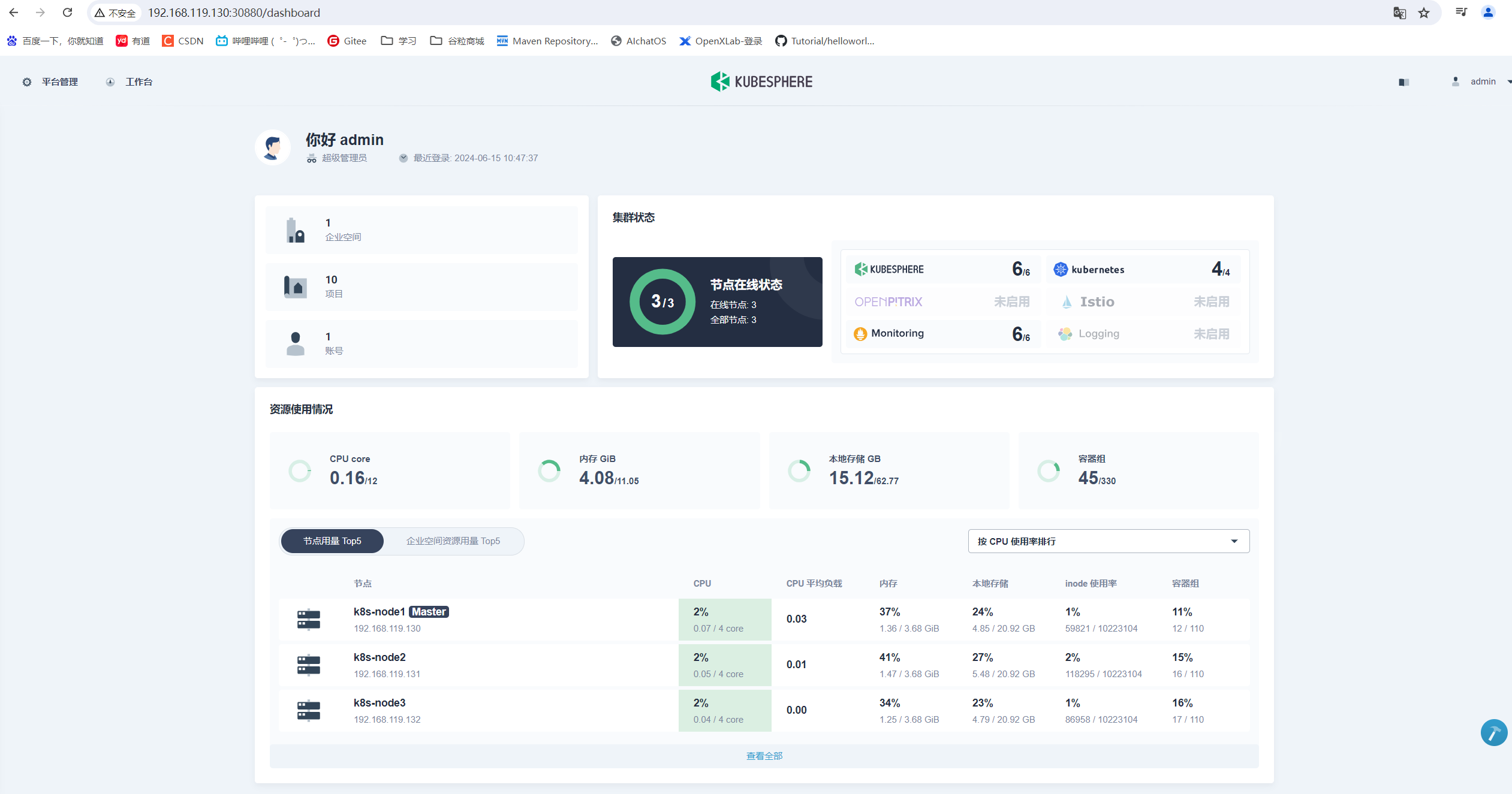
访问:http://192.168.119.130:30880
Account: admin
Password: P@88w0rd
2.4、完整化安装
- 若集群可用 CPU > 8 Core 且可用内存 > 16 G,可以使用以下命令完整安装 KubeSphere。
注意,应确保集群中有一个节点的可用内存大于 8 G。
kubectl apply -f https://raw.githubusercontent.com/kubesphere/ks-installer/v2.1.1/kubesphere-complete-setup.yaml
- 查看滚动刷新的安装日志,请耐心等待安装成功。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
说明:安装过程中若遇到问题,也可以通过以上日志命令来排查问题。
- 通过
kubectl get pod --all-namespaces查看 KubeSphere 相关 namespace 下所有 Pod 状态是否为 Running。确认 Pod 都正常运行后,可使用 IP:30880访问 KubeSphere UI 界面,默认的集群管理员账号为 admin/P@88w0rd。
2.5、安装可插拔的功能组件
安装 Metrics-server 开启 HPA
KubeSphere 支持对 Deployment 设置 弹性伸缩 (HPA),支持根据集群的监控指标如 CPU 使用率和内存使用量来设置弹性伸缩,当业务需求增加时,KubeSphere 能够无缝地自动水平增加 Pod 数量,提高应用系统的稳定性。
关于如何使用 HPA 请参考 设置弹性伸缩,注意,Installer 默认最小化安装因此初始安装时并未开启 Metrics-server 的安装,请在使用 HPA 之前开启 Metrics-server 的安装,参考以下文档。
安装后如何开启 Metrics-server 安装
-
通过修改 ks-installer 的 configmap 可以选装组件,执行以下命令。
kubectl edit cm -n kubesphere-system ks-installer参考如下修改 ConfigMap
··· devops: enabled: True #自动化部署打开 jenkinsMemoryLim: 2Gi jenkinsMemoryReq: 1000Mi #jenkins初始化申请调整为1G jenkinsVolumeSize: 8Gi jenkinsJavaOpts_Xms: 512m jenkinsJavaOpts_Xmx: 512m jenkinsJavaOpts_MaxRAM: 2g sonarqube: enabled: True #代码质量检查打开 postgresqlVolumeSize: 8Gi servicemesh: enabled: False notification: enabled: True #通知系统打开 alerting: enabled: True #告警通知系统打开 -
保存退出,参考 验证可插拔功能组件的安装 ,通过查询 ks-installer 日志或 Pod 状态验证功能组件是否安装成功。
-
查看安装日志
开启可插拔功能组件的安装后,需要通过日志或 Pod 状态验证功能组件是否安装成功。
查看 ks-installer 安装过程中产生的动态日志,等待安装成功:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f当动态日志出现如下提示,说明开启的组件已安装成功。
##################################################### ### Welcome to KubeSphere! ### ##################################################### Console: http://192.168.119.130:30880 Account: admin Password: P@88w0rd NOTES: 1. After logging into the console, please check the monitoring status of service components in the "Cluster Status". If the service is not ready, please wait patiently. You can start to use when all components are ready. 2. Please modify the default password after login. ##################################################### -
安装成功后,可登陆控制台,在 服务组件下查看可插拔功能组件下的所有组件是否都已经安装启动完毕。
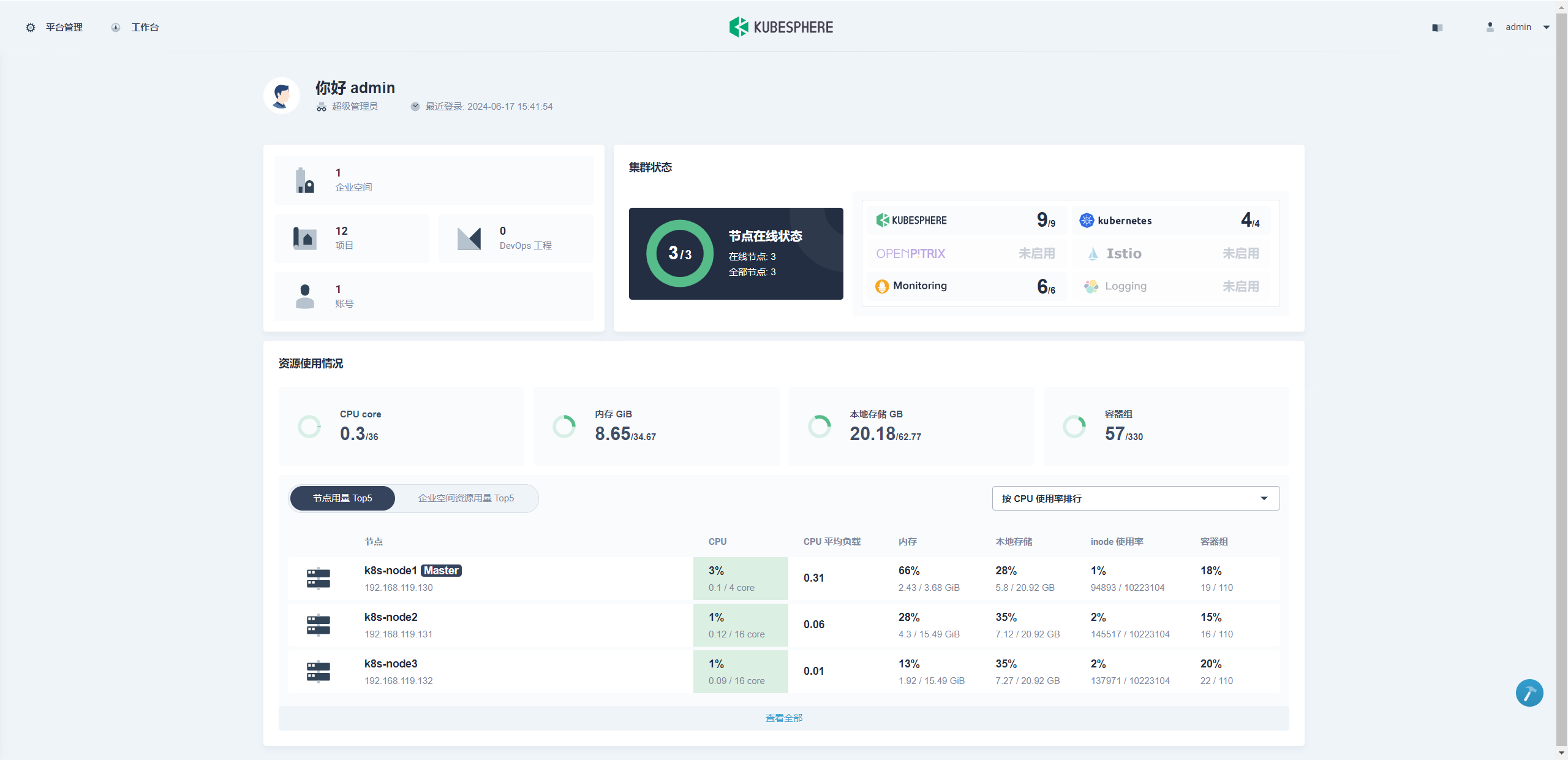
-
验证可插拔功能组件的运行结果
除了在控制台查看组件状态,还可以通过 kubectl 命令确认可插拔的组件是否安装成功。
通常情况下,当该 namespace 下的所有 Pod 状态都为 Running,并且 Job 都为 Completed 状态,则说明该组件安装成功。kubectl get pods --all-namespaces
-
3、多租户管理快速入门
3.1、目的
本文档面向初次使用 KubeSphere 的集群管理员用户,引导新手用户创建企业空间、创建新的角色和账户,然后邀请新用户进入企业空间后,创建项目和 DevOps 工程,帮助用户熟悉多租户下的用户和角色管理,快速上手 KubeSphere。
3.2、前提条件
已安装 KubeSphere,并使用默认的 admin 用户名和密码登录了 KubeSphere。
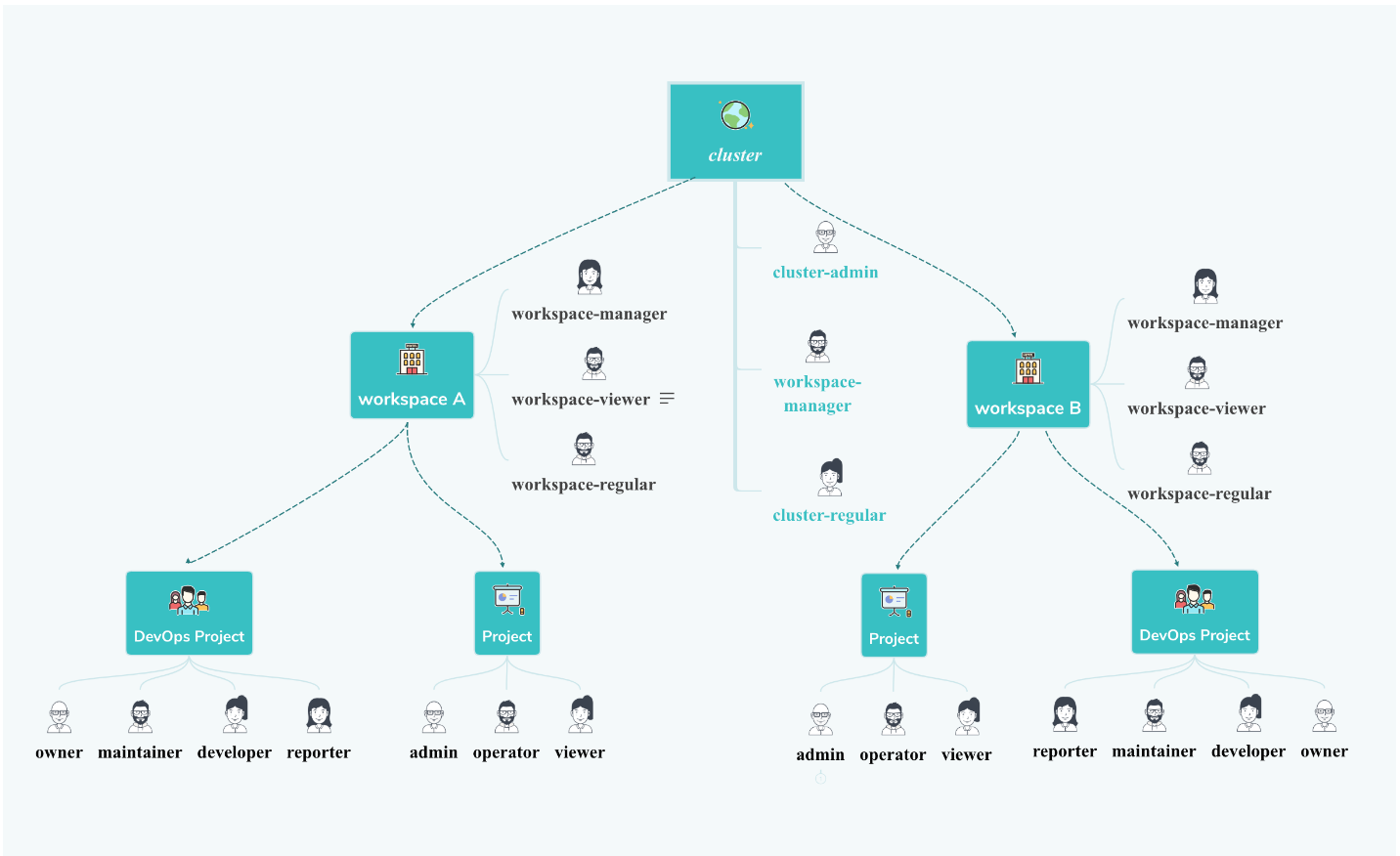
目前,平台的资源一共有三个层级,包括 集群 (Cluster)、 企业空间 (Workspace)、 项目 (Project) 和 DevOps Project (DevOps 工程),层级关系如下图所示,即一个集群中可以创建多个企业空间,而每个企业空间,可以创建多个项目和 DevOps工程,而集群、企业空间、项目和 DevOps工程中,默认有多个不同的内置角色。
3.3、集群管理员
第一步:创建角色和账号
平台中的 cluster-admin 角色可以为其他用户创建账号并分配平台角色,平台内置了集群层级的以下三个常用的角色,同时支持自定义新的角色。
| 内置角色 | 描述 |
|---|---|
| cluster-admin | 集群管理员,可以管理集群中所有的资源。 |
| workspaces-manager | 集群中企业空间管理员,仅可创建、删除企业空间,维护企业空间中的成员列表。 |
| cluster-regular | 集群中的普通用户,在被邀请加入企业空间之前没有任何资源操作权限。 |
通过下图您可以更清楚地了解本示例的逻辑:
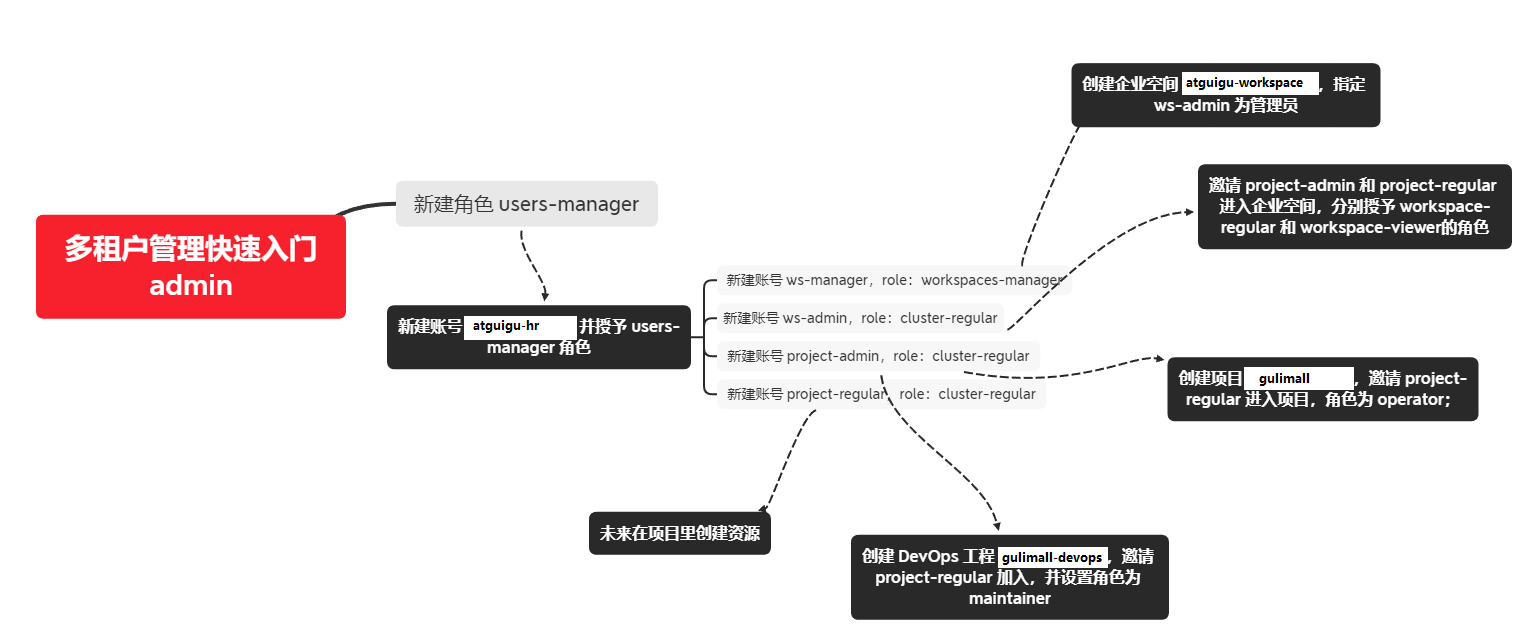
本示例首先新建一个角色 (users-manager),为该角色授予账号管理和角色管理的权限,然后新建一个账号并给这个账号授予 users-manager 角色。
| 账号名 | 集群角色 | 职责 |
|---|---|---|
| user-manager | users-manager | 管理集群的账户和角色 |
-
点击控制台左上角 平台管理 → 平台角色,可以看到当前的角色列表,点击 创建,创建一个角色用于管理所有账户和角色。

-
填写角色的基本信息和权限设置。
名称:起一个简洁明了的名称,便于用户浏览和搜索,如 users-manager
描述信息:简单介绍该角色的职责,如 管理账户和角色
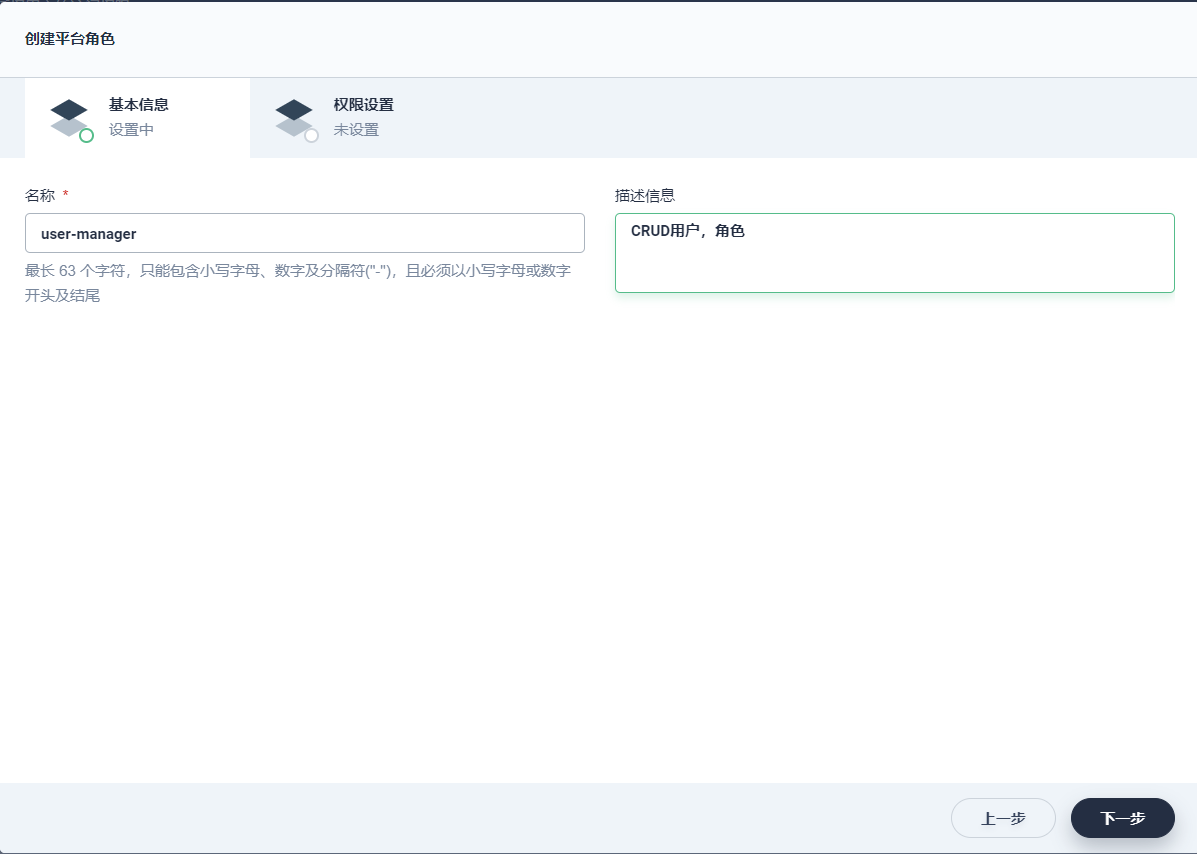
-
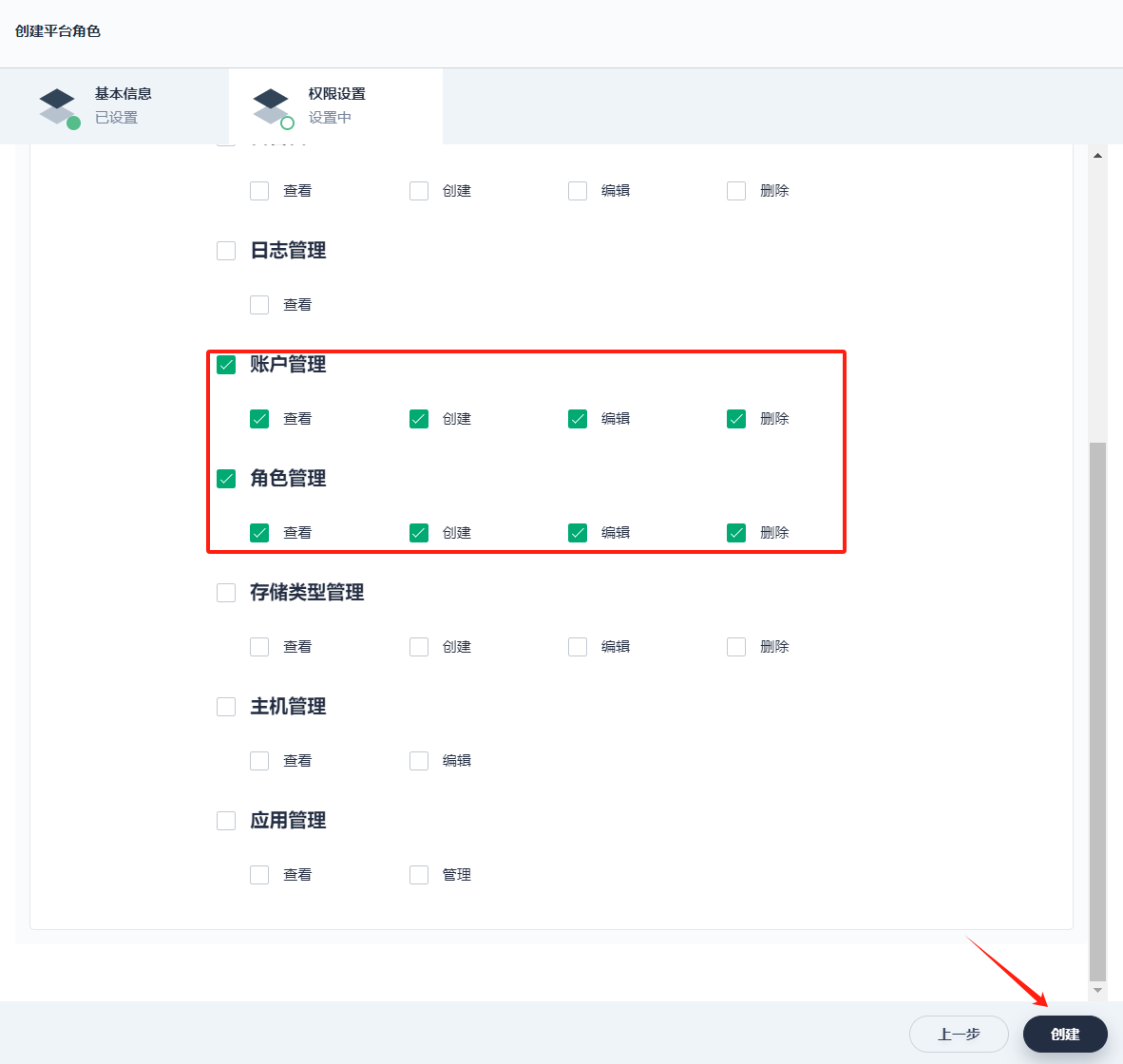
权限设置中,勾选账户管理和角色管理的所有权限,点击 创建,自定义的用户管理员的角色创建成功。
-
点击控制台左上角 平台管理 → 账户管理,可以看到当前集群中所有用户的列表,点击 创建 按钮。

-
填写新用户的基本信息,如用户名设置为
atguigu-hr,角色选择user-manager,其它信息可自定义,点击 确定。
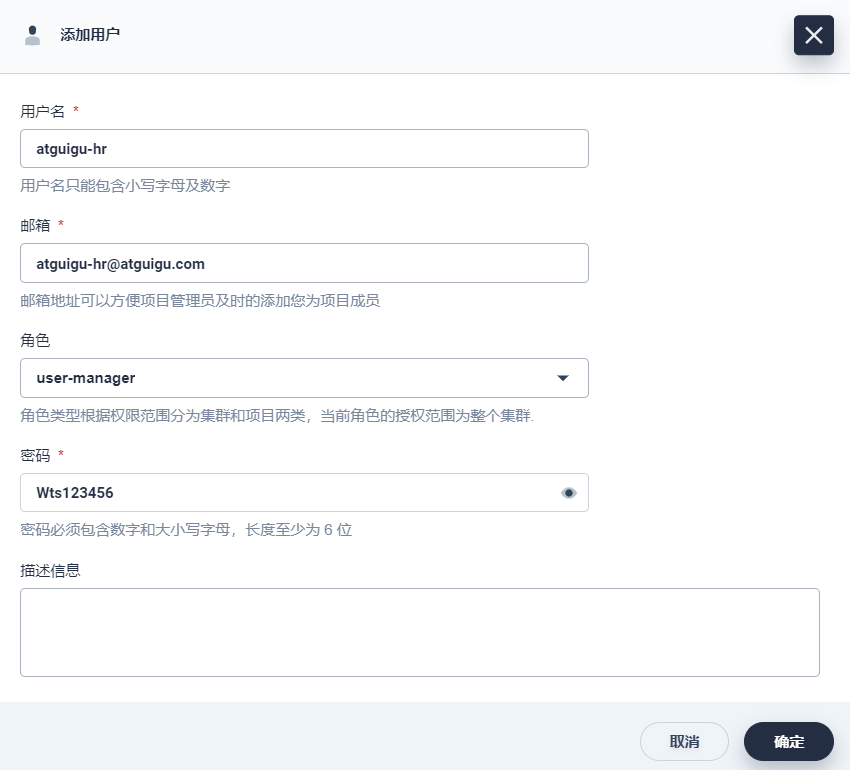
-
登录
说明:上述步骤仅简单地说明创建流程,关于账号管理与角色权限管理的详细说明,请参考 角色权限概览 和 账号管理。
-
然后用
atgugu-hr账户登录来创建下表中的四个账号,ws-manager将用于创建一个企业空间,并指定其中一个用户名为ws-admin作为企业空间管理员。切换atgugu-hr账号登录后在 账号管理 下,新建四个账号,创建步骤同上,参考如下信息创建。用户名 集群角色 职责 ws-manager workspaces-manager 创建和管理企业空间 ws-admin cluster-regular 管理企业空间下所有的资源(本示例用于邀请新成员加入企业空间) project-admin cluster-regular 创建和管理项目、DevOps 工程,邀请新成员加入 project-regular cluster-regular 将被 project-admin 邀请加入项目和 DevOps 工程,用于创建项目和工程下的工作负载、Pipeline 等资源 - ws-manager
- ws-admin
- project-admin
- project-regular
- ws-manager
-
查看新建的四个账号信息。
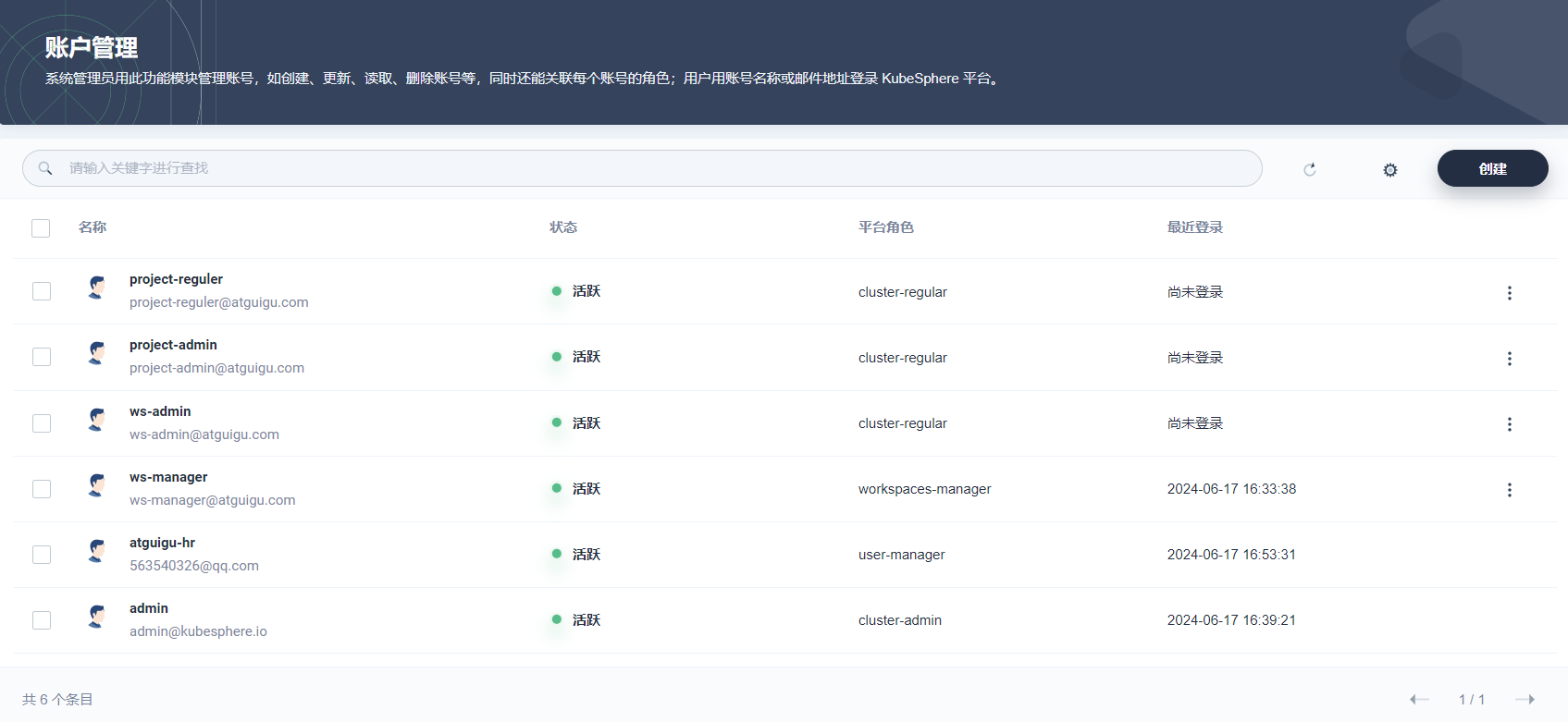
3.4、企业空间管理员
第二步:创建企业空间
企业空间 (workspace) 是 KubeSphere 实现多租户模式的基础,是用户管理项目、DevOps 工程和企业成员的基本单位。
-
切换为
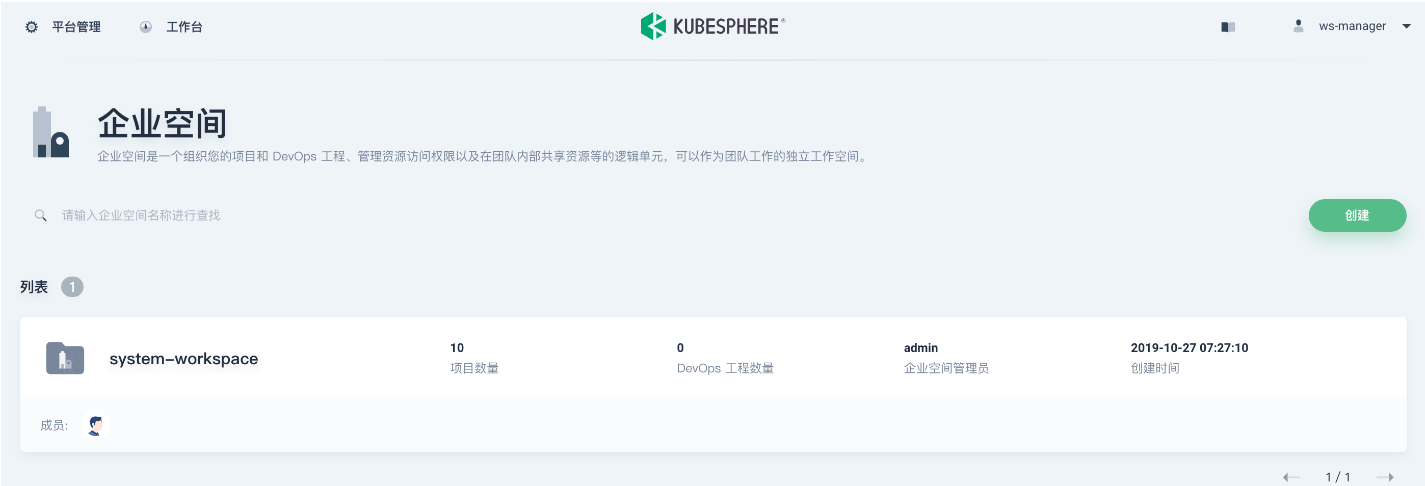
ws-manager登录 KubeSphere,ws-manager有权限查看和管理平台的所有企业空间。点击左上角的 平台管理→ 企业空间,可见新安装的环境只有一个系统默认的企业空间 system-workspace,用于运行 KubeSphere 平台相关组件和服务,禁止删除该企业空间。
在企业空间列表点击 创建;
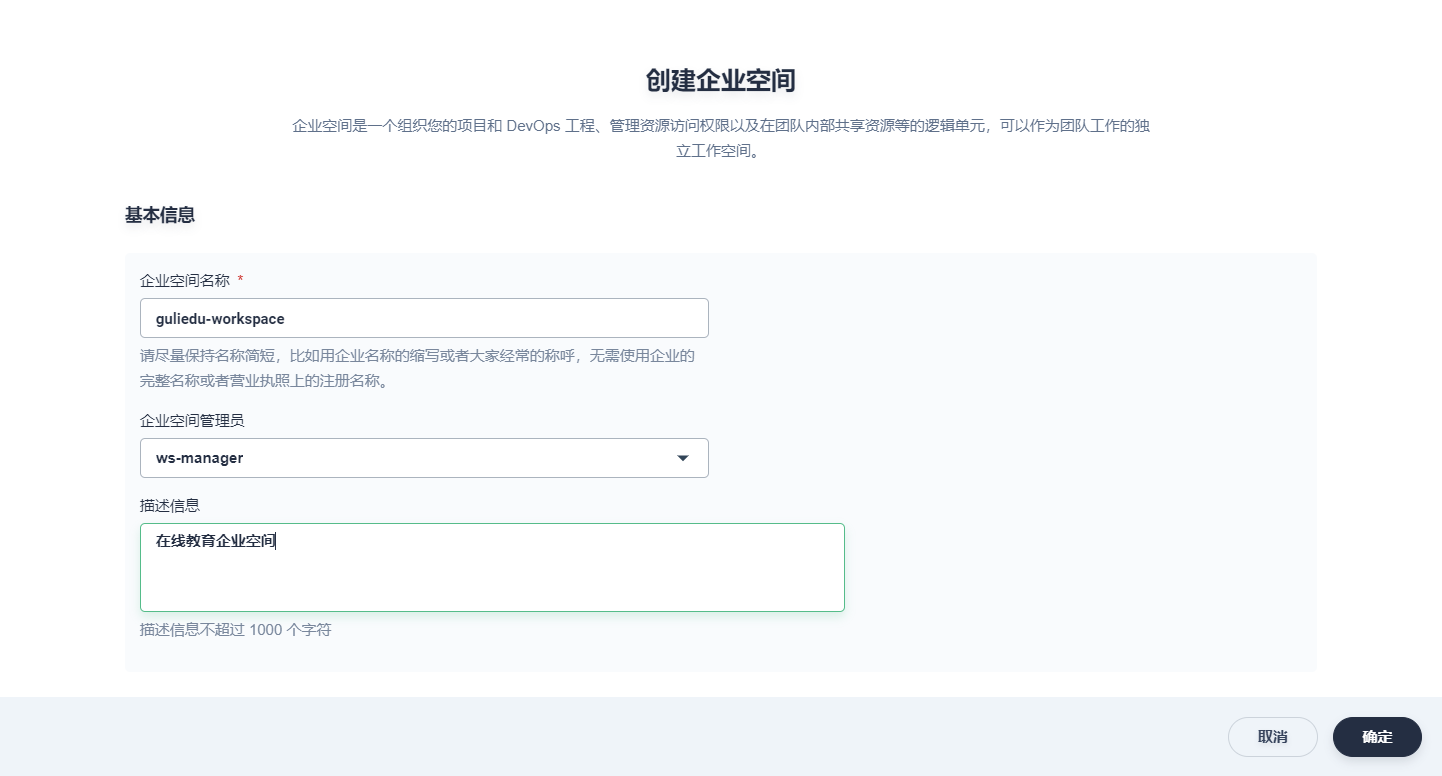
-
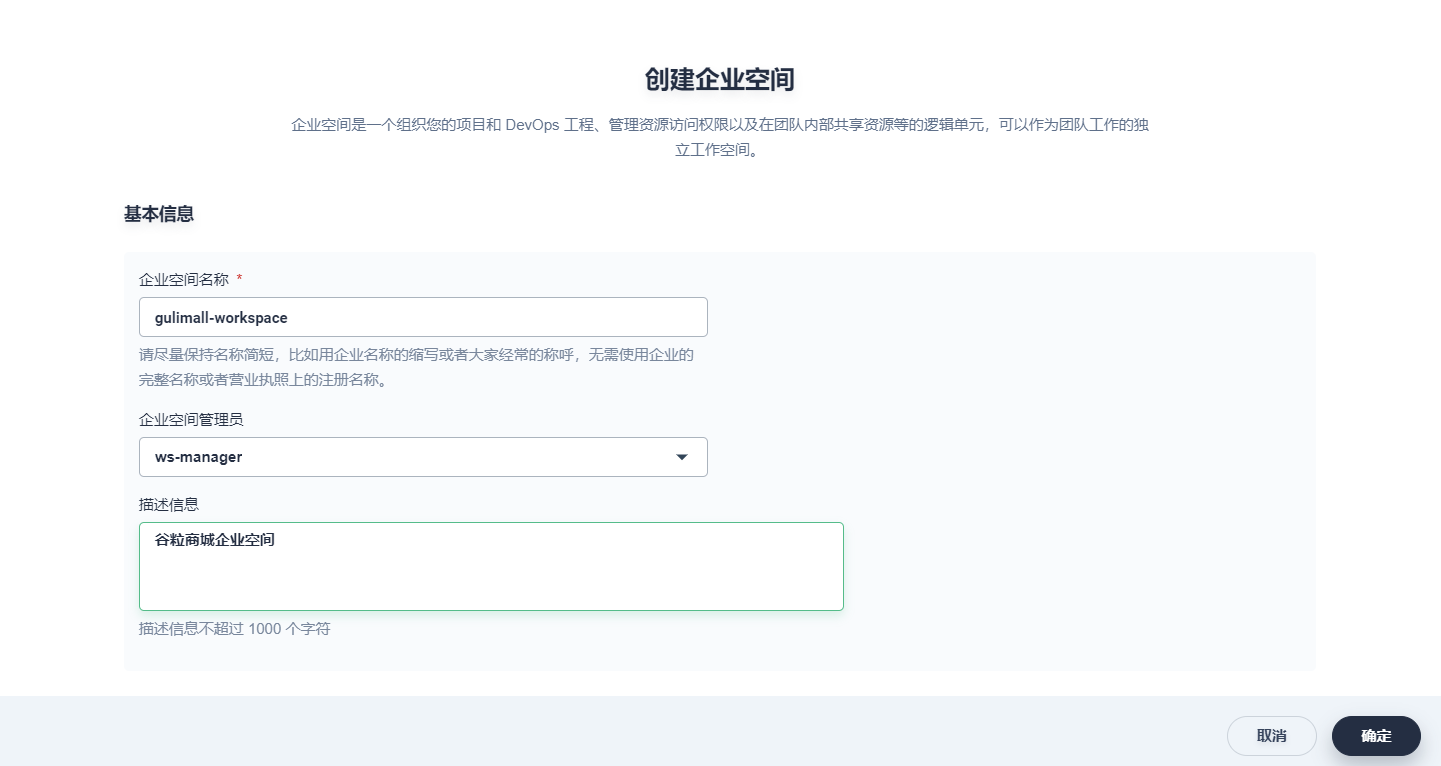
参考如下提示填写企业空间的基本信息,然后点击 确定。企业空间的创建者同时默认为该企业空间的管理员 (workspace-admin),拥有企业空间的最高管理权限。
- 企业空间名称:请尽量保持企业名称简短,便于用户浏览和搜索,本示例是 gulimall-workspace
- 企业空间管理员:可从当前的集群成员中指定,这里指定上一步创建的 ws-manager用户为管理员,同时邀请了 ws-manager用户进入该企业空间
- 描述信息:简单介绍该企业空间
说明:企业空间管理的详细说明请参考 企业空间管理。
-
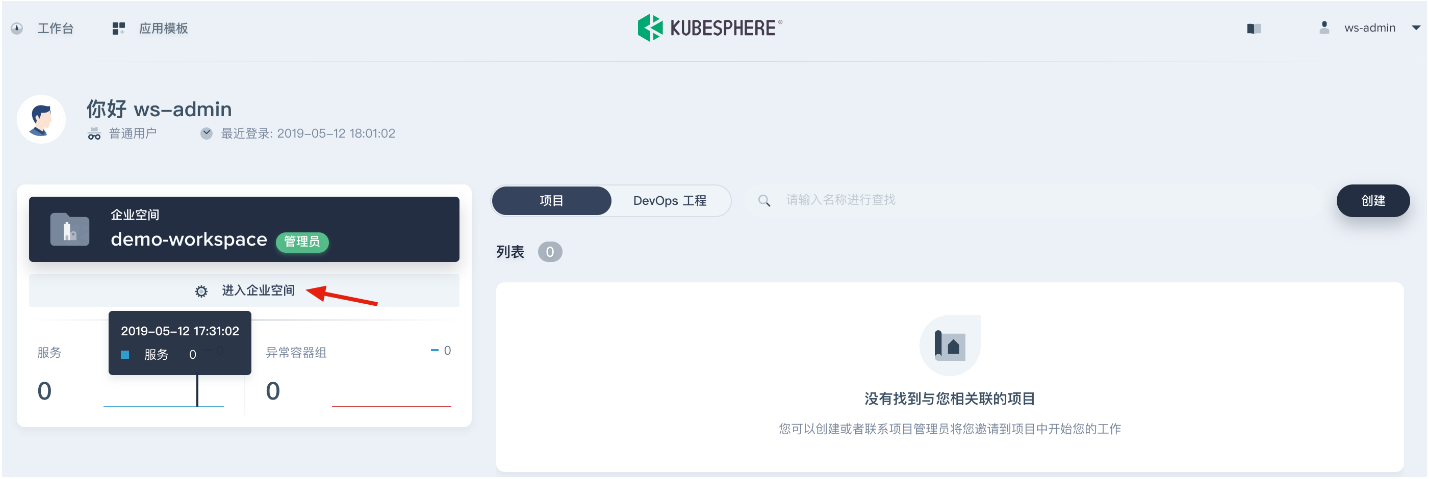
企业空间 demo-workspace创建完成后,切换为 ws-admin登录 KubeSphere,点击左侧「进入企业空间」进入企业空间详情页。
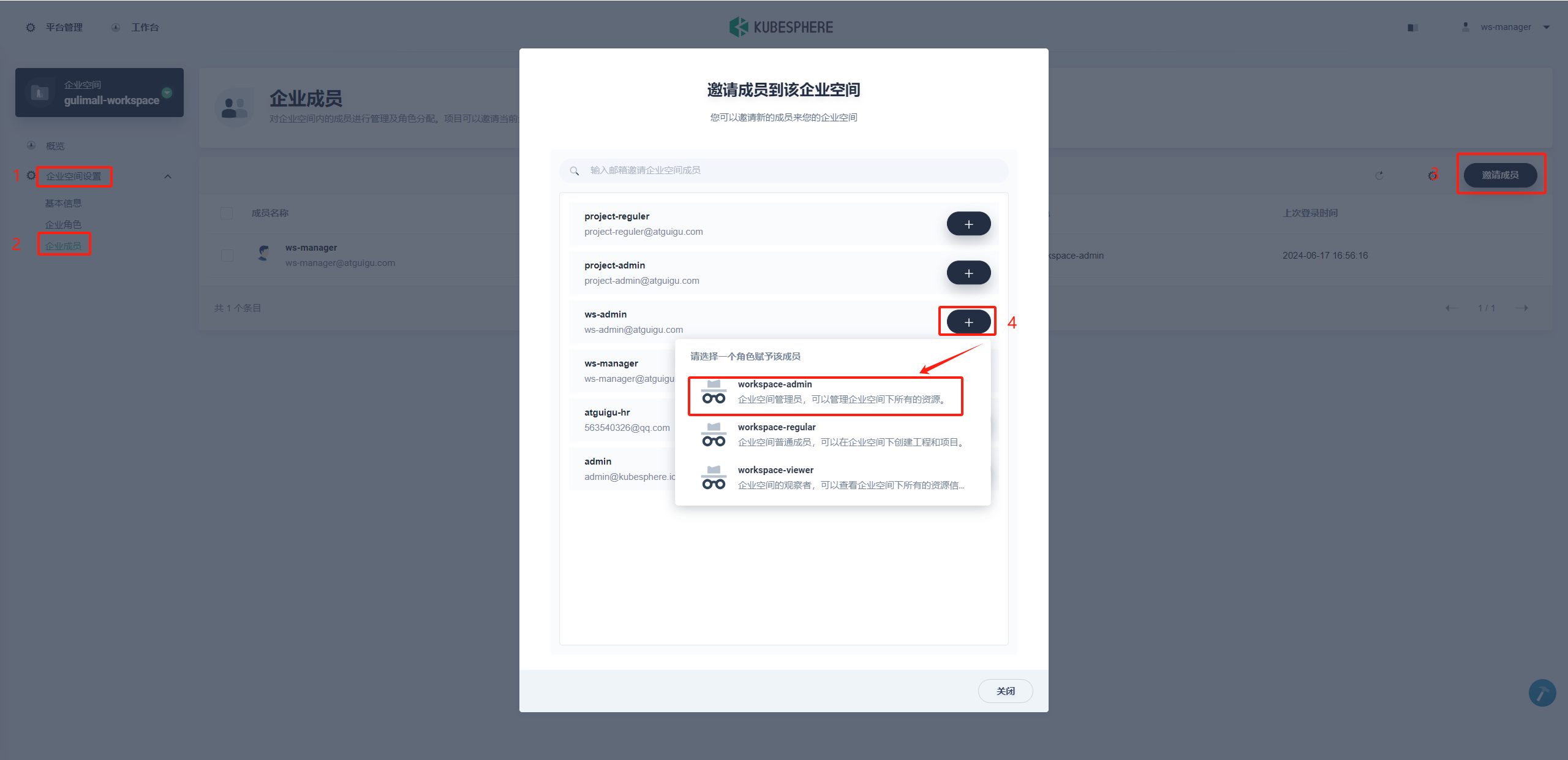
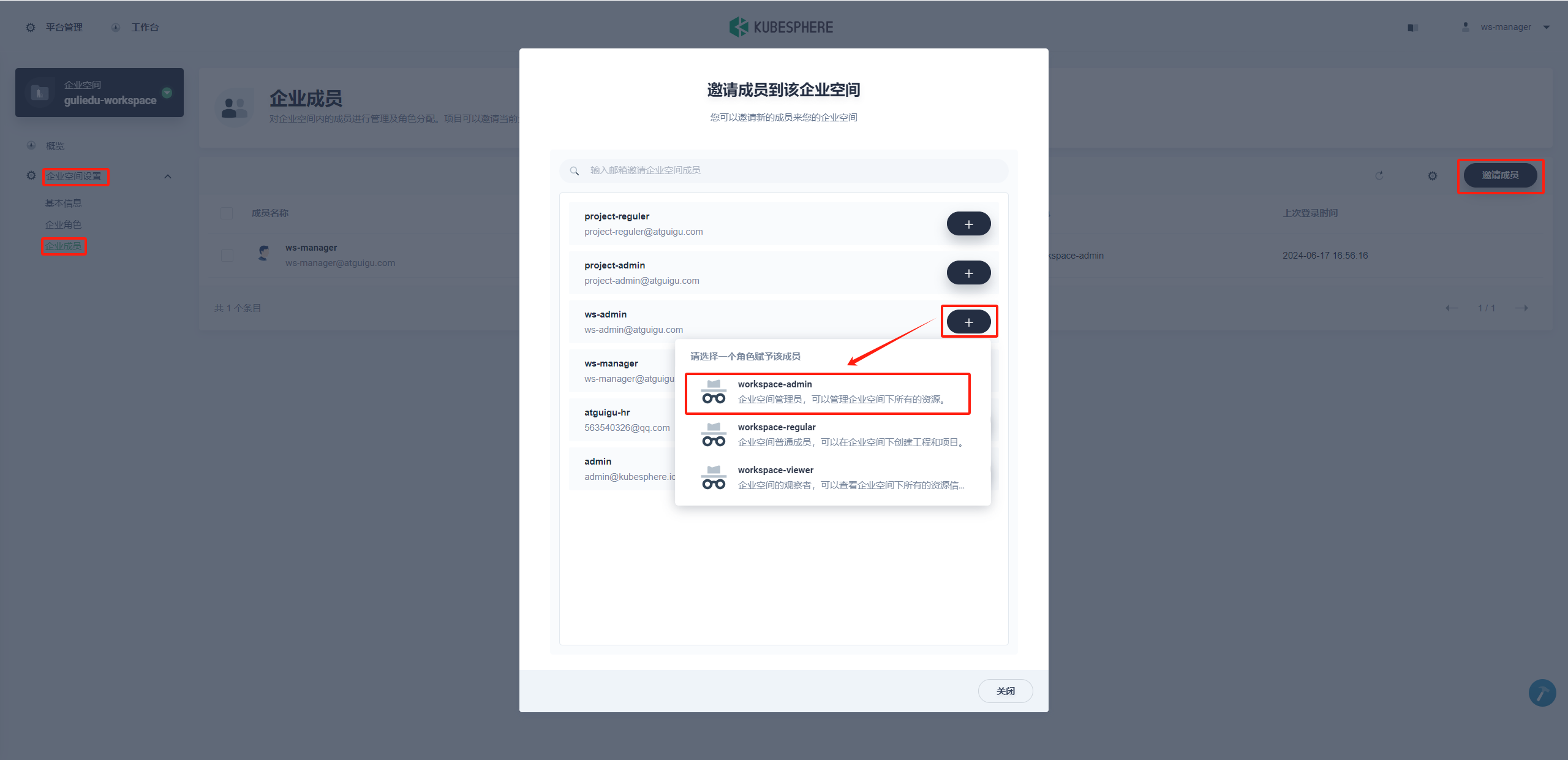
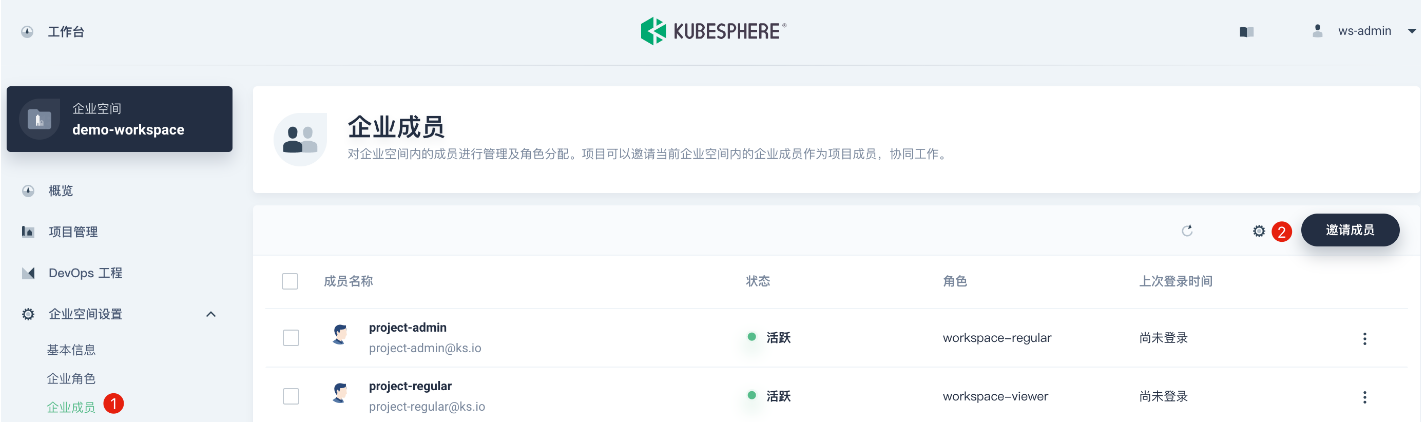
ws-admin可以从集群成员中邀请新成员加入当前企业空间,然后创建项目和 DevOps 工程。在左侧菜单栏选择 企业空间管理→ 成员管理,点击 邀请成员。
-
这一步需要邀请在 步骤 1.6. 创建的两个用户 project-admin和 project-regular进入企业空间,且分别授予 workspace-regular和 workspace-viewer的角色,此时该企业空间一共有如下三个用户:
用户名 企业空间角色 职责 ws-admin workspace-admin 管理企业空间下所有的资源(本示例用于邀请新成员加入企业空间) project-admin workspace-regular 创建和管理项目、DevOps 工程,邀请新成员加入 project-regular workspace-viewer 将被 project-admin 邀请加入项目和 DevOps 工程,用于创建工作负载、流水线等业务资源

3.5、项目和 DevOps 工程管理员
第三步:创建项目
创建工作负载、服务和 CI/CD 流水线等资源之前,需要预先创建项目和 DevOps 工程。
-
上一步将用户项目管理员 project-admin邀请进入企业空间后,可切换为 project-admin账号登录KubeSphere,默认进入 demo-workspace 企业空间下,点击 创建,选择 创建资源型项目。
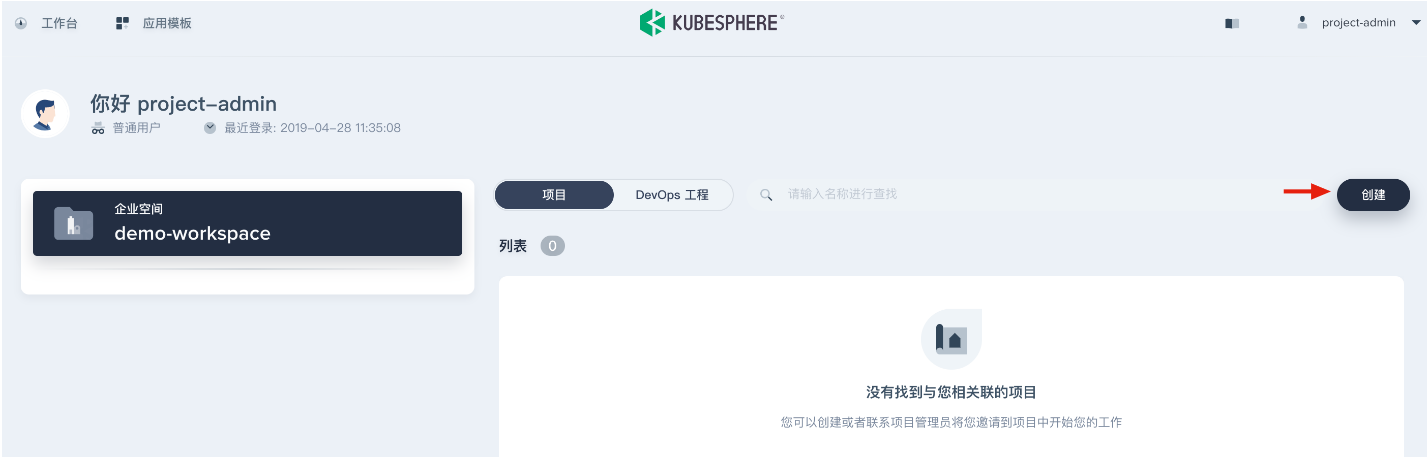

-
填写项目的基本信息和高级设置,完成后点击 下一步。
基本信息
- 名称:为项目起一个简洁明了的名称,便于用户浏览和搜索,比如 demo-project
- 别名:帮助您更好的区分资源,并支持中文名称,比如 示例项目
- 描述信息:简单介绍该项目
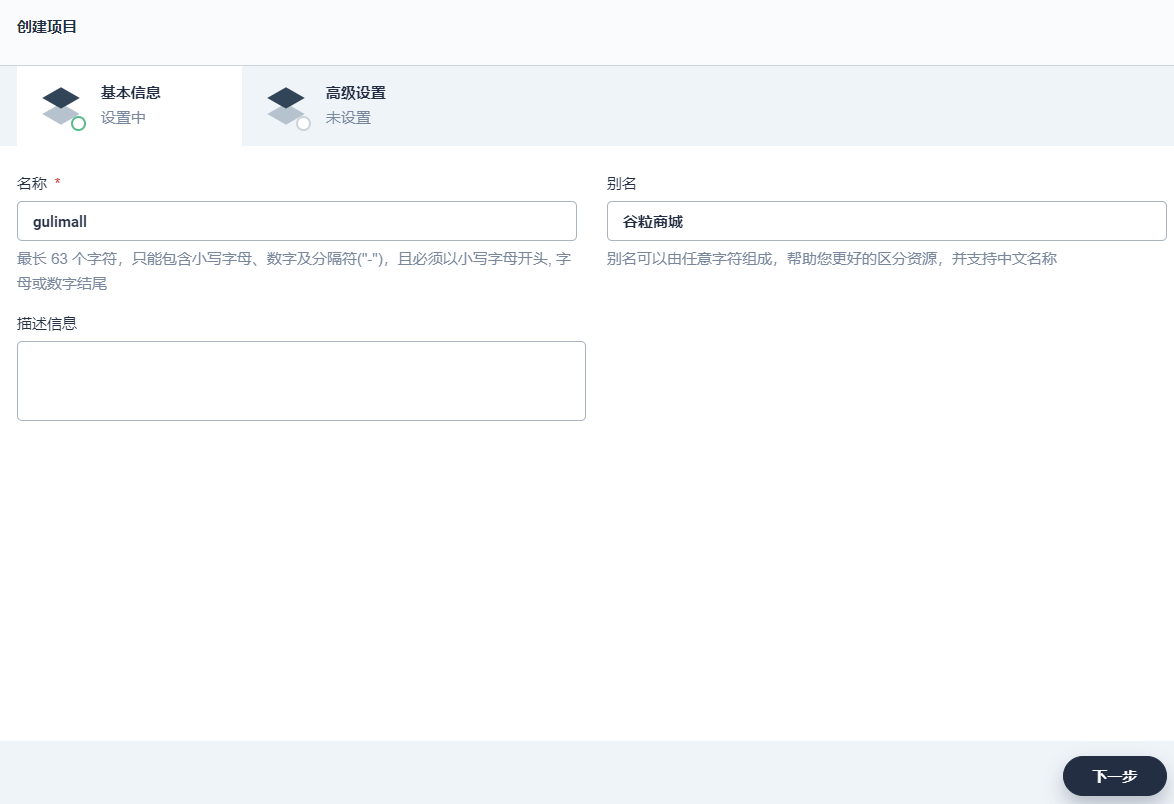
高级设置
此处将默认的最大 CPU 和内存分别设置 1 Core和 1000 Mi,后续的示例都可以在这个示例项目中完成,在项目使用过程中可根据实际情况再次编辑资源默认请求。
完成高级设置后,点击 创建。
说明:高级设置是在当前项目中配置容器默认的 CPU 和内存的请求与限额,相当于是给项目创建了一个 Kubernetes 的 LimitRange 对象,在项目中创建工作负载后填写容器组模板时,若不填写容器 CPU 和内存的请求与限额,则容器会被分配在高级设置的默认 CPU 和内存请求与限额值。
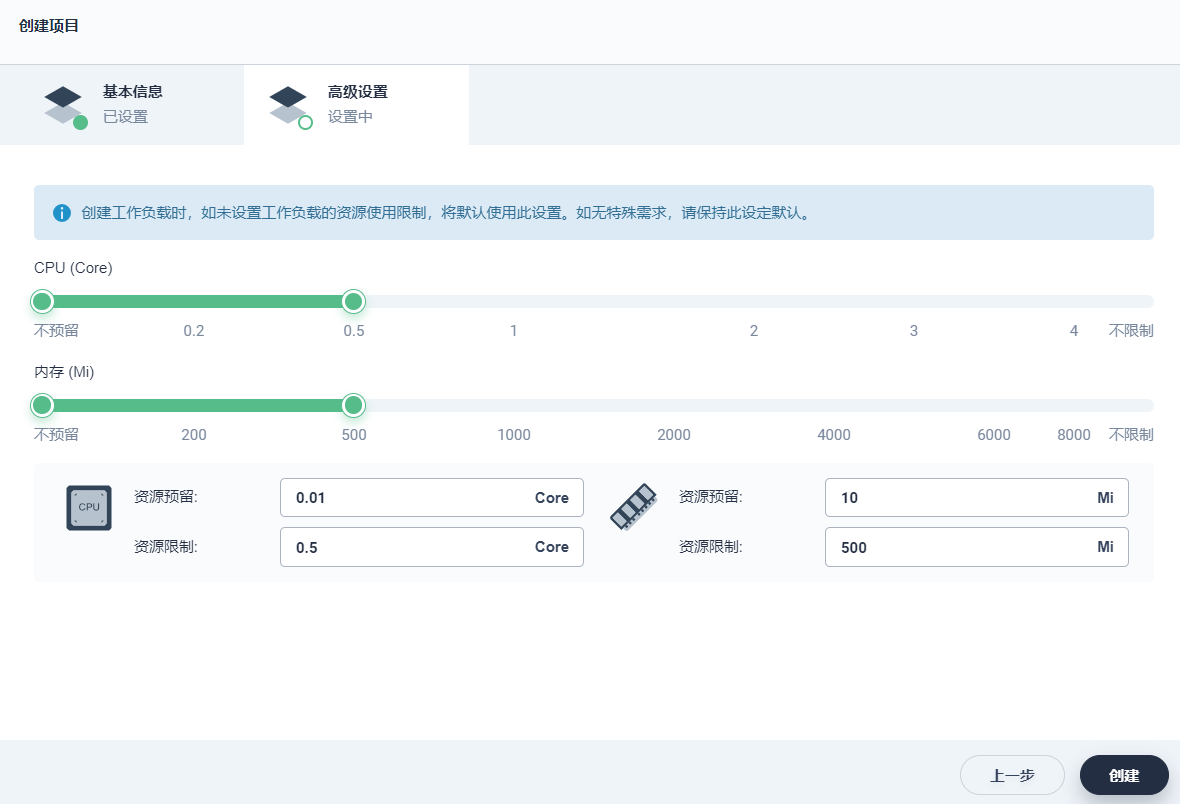
提示:项目管理和设置的详细说明,请参考用户指南下的项目设置系列文档。
-
邀请成员
示例项目 gulimall 创建成功后,点击进入示例项目。在 3.4、企业空间管理员步骤4. 已邀请用户 project-regular加入了当前企业空间 gulimall-workspace,下一步则需要邀请 project-regular 用户进入该企业空间下的项目 gulimall 。点击项目列表中的 gulimall 进入该项目。
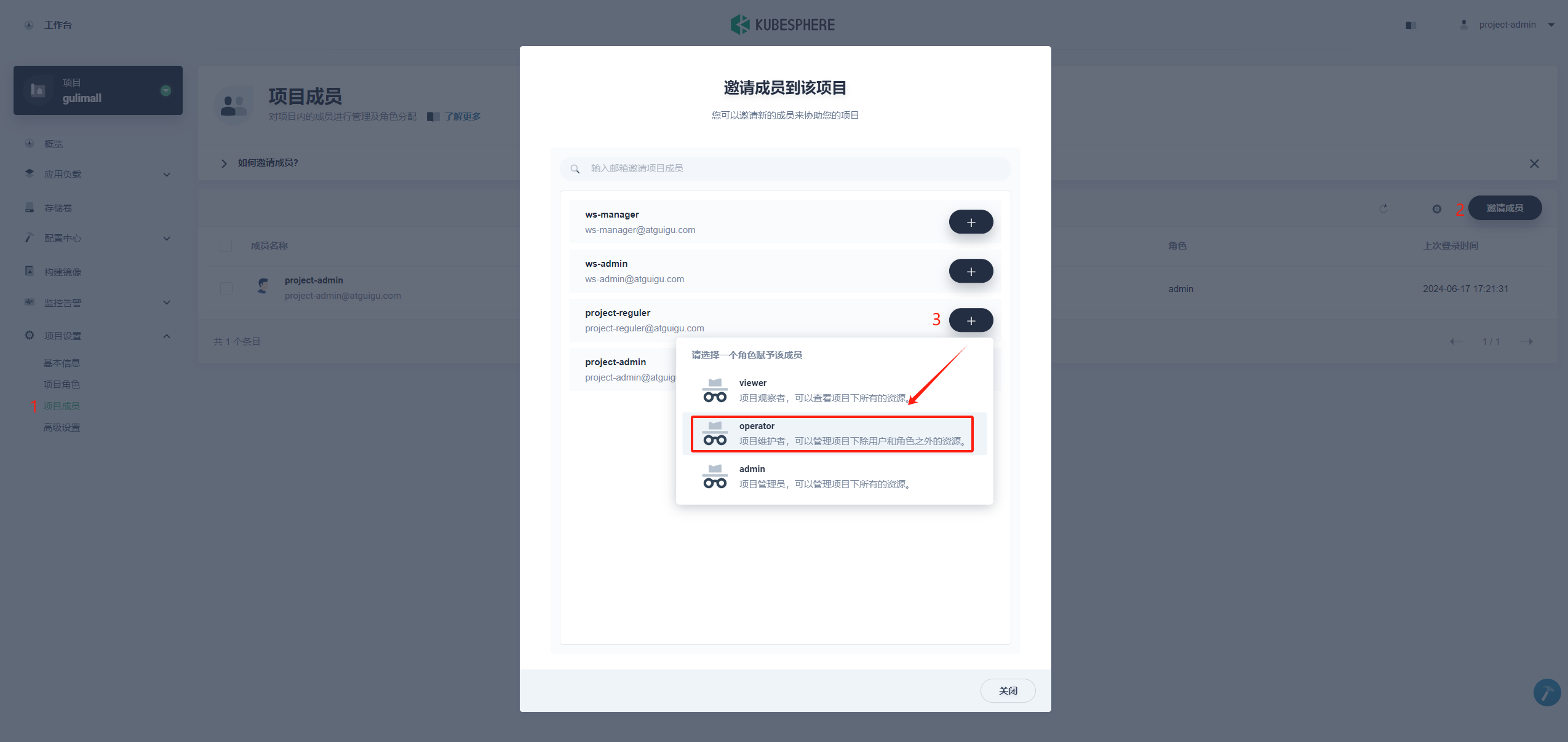
在项目的左侧菜单栏选择 项目设置 → 项目成员,点击 邀请成员。在弹窗中的 project-regular点击 “+”,在项目的内置角色中选择 operator角色。因此,后续在项目中创建和管理资源,都可以由 project-regular用户登录后进行操作。
3.7. 请使用项目管理员 project-admin设置外网访问,选择 「项目设置」 → 「外网访问」,点击 「设置网关」。
第四步:创建 DevOps 工程(可选)
说明:DevOps 功能组件作为可选安装项,提供 CI/CD 流水线、B2i/S2i 等丰富的企业级功能,若还未安装可参考 自定义组件安装(安装后) 开启 DevOps 组件安装,然后参考以下步骤。
-
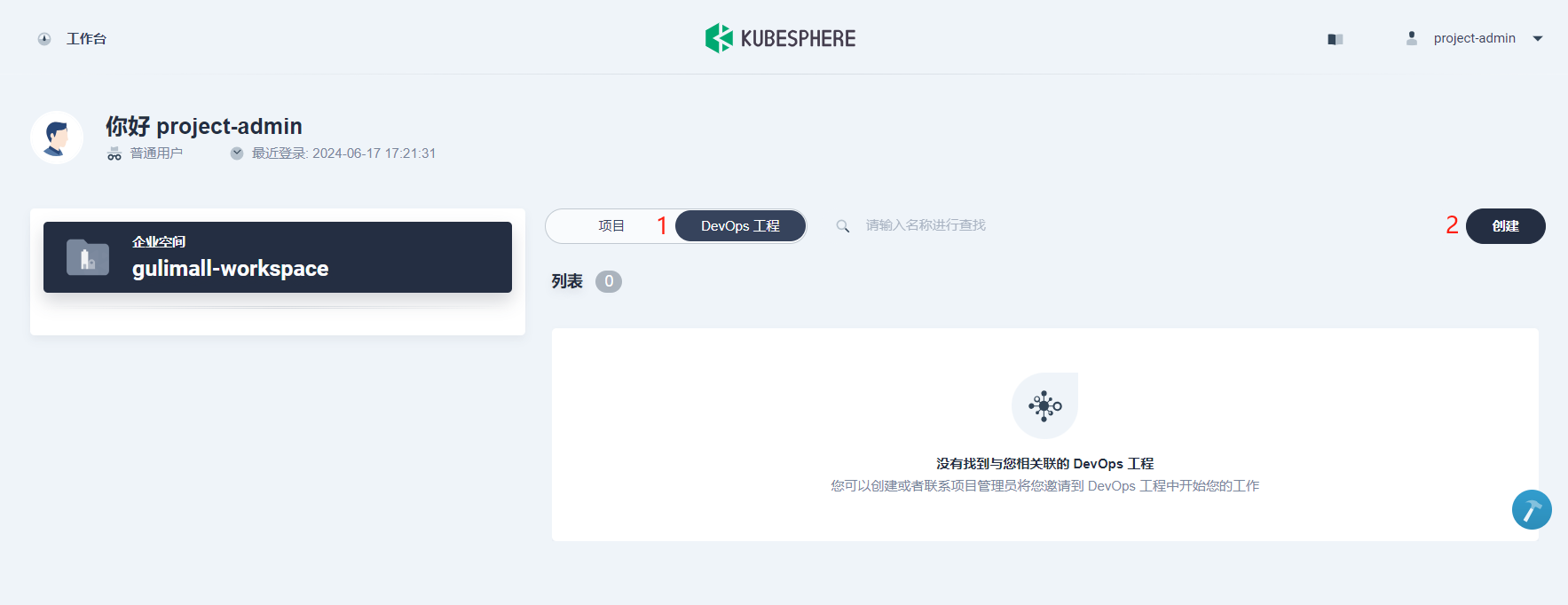
继续使用 project-admin用户创建 DevOps 工程。点击 工作台,在当前企业空间下,点击 创建,在弹窗中选择 创建一个 DevOps 工程。DevOps 工程的创建者 project-admin将默认为该工程的 Owner,拥有 DevOps 工程的最高权限。
-
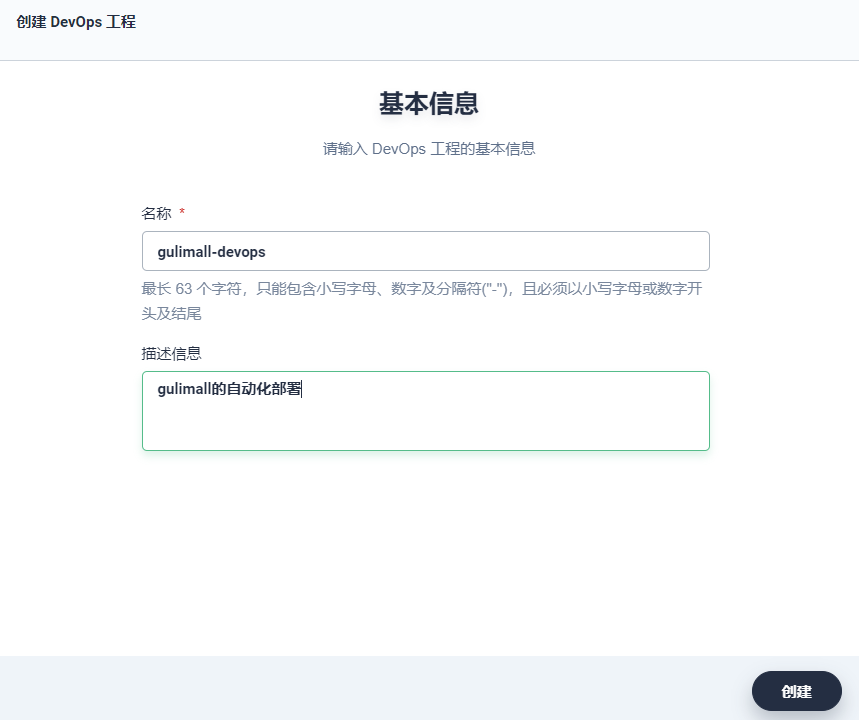
输入 DevOps 工程的名称和描述信息,比如名称为 gulimall-devops。点击 创建,注意创建一个 DevOps 有一个初始化环境的过程需要几秒钟。
-
点击 DevOps 工程列表中的 demo-devops进入该工程的详情页。
-
同上,这一步需要在 demo-devops工程中邀请用户 project-regular,并设置角色为 maintainer,用于对工程内的 Pipeline、凭证等创建和配置等操作。菜单栏选择 工程管理 → 工程成员,然后点击 邀请成员,为用户 project-regular设置角色为 maintainer。后续在 DevOps 工程中创建 Pipeline 和凭证等资源,都可以由 project-regular用户登录后进行操作。
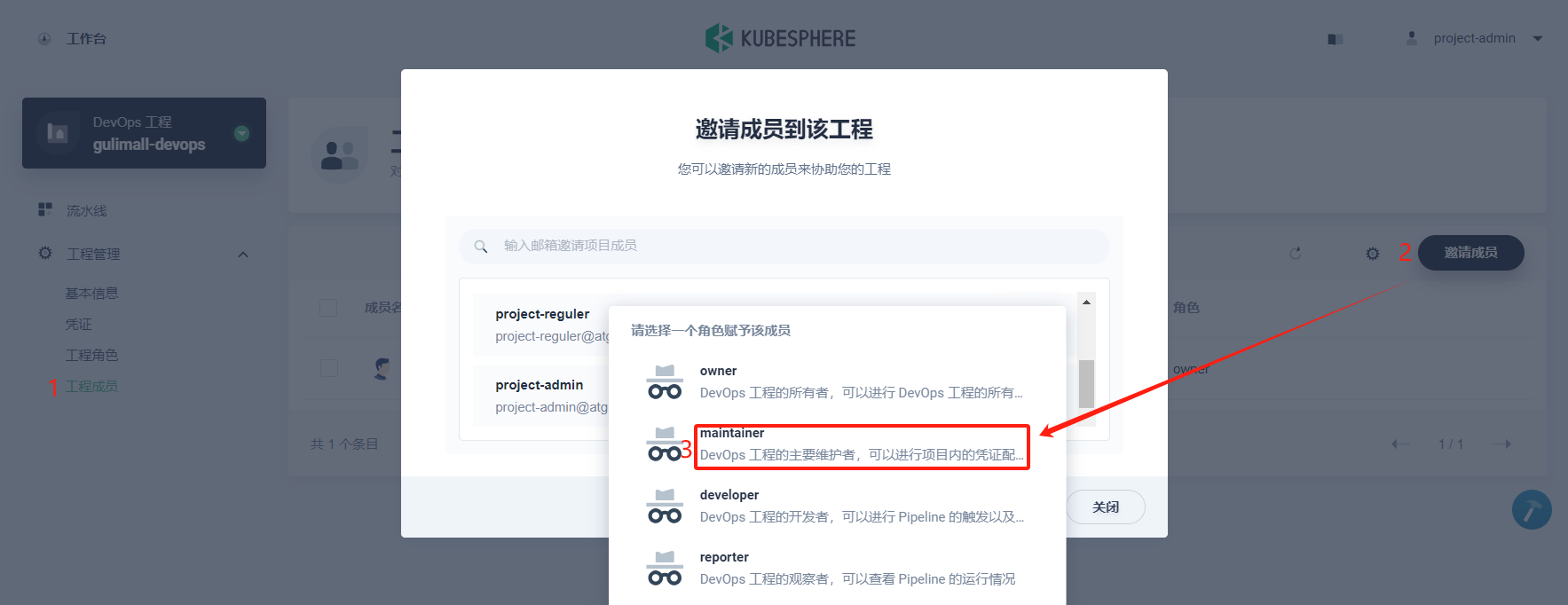
至此,本文档为您演示了如何在多租户的基础上,使用账户管理和角色管理的功能,以示例的方式介绍了常用内置角色的用法,以及创建项目和 DevOps 工程。
4、创建 Wordpress 应用并发布至 Kubernetes
4.1、WordPress 简介
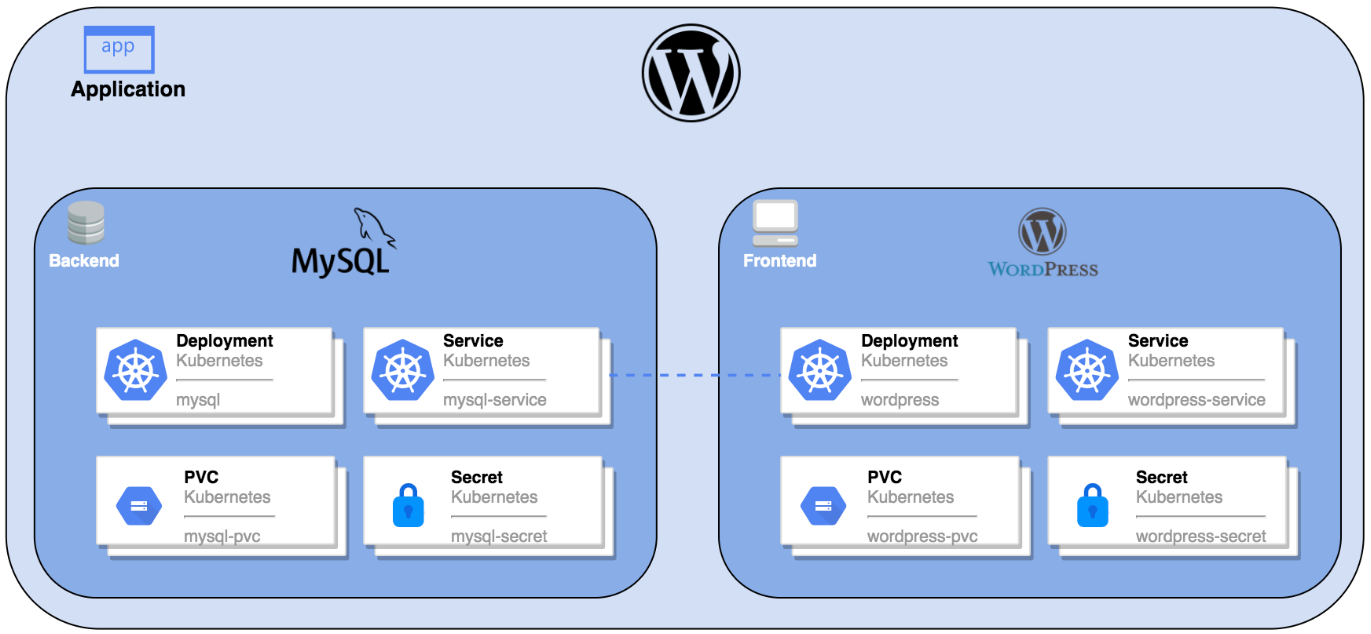
WordPress 是使用 PHP 开发的博客平台,用户可以在支持 PHP 和 MySQL 数据库的环境中架设属于自己的网站。本文以创建一个 Wordpress 应用 为例,以创建 KubeSphere 应用的形式将 Wordpress 的组件(MySQL 和 Wordpress)创建后发布至 Kubernetes 中,并在集群外访问 Wordpress 服务。
一个完整的 Wordpress 应用会包括以下 Kubernetes 对象,其中 MySQL 作为后端数据库,Wordpress 本身作为前端提供浏览器访问。
4.2、前提条件
已创建了企业空间、项目和普通用户 project-regular账号(该已账号已被邀请至示例项目),并开启了外网访问,请参考 多租户管理快速入门。
4.3、创建密钥
MySQL 的环境变量 MYSQL_ROOT_PASSWORD即 root 用户的密码属于敏感信息,不适合以明文的方式表现在步骤中,因此以创建密钥的方式来代替该环境变量。创建的密钥将在创建 MySQL 的容器组设置时作为环境变量写入。
4.3.1、创建 MySQL 密钥
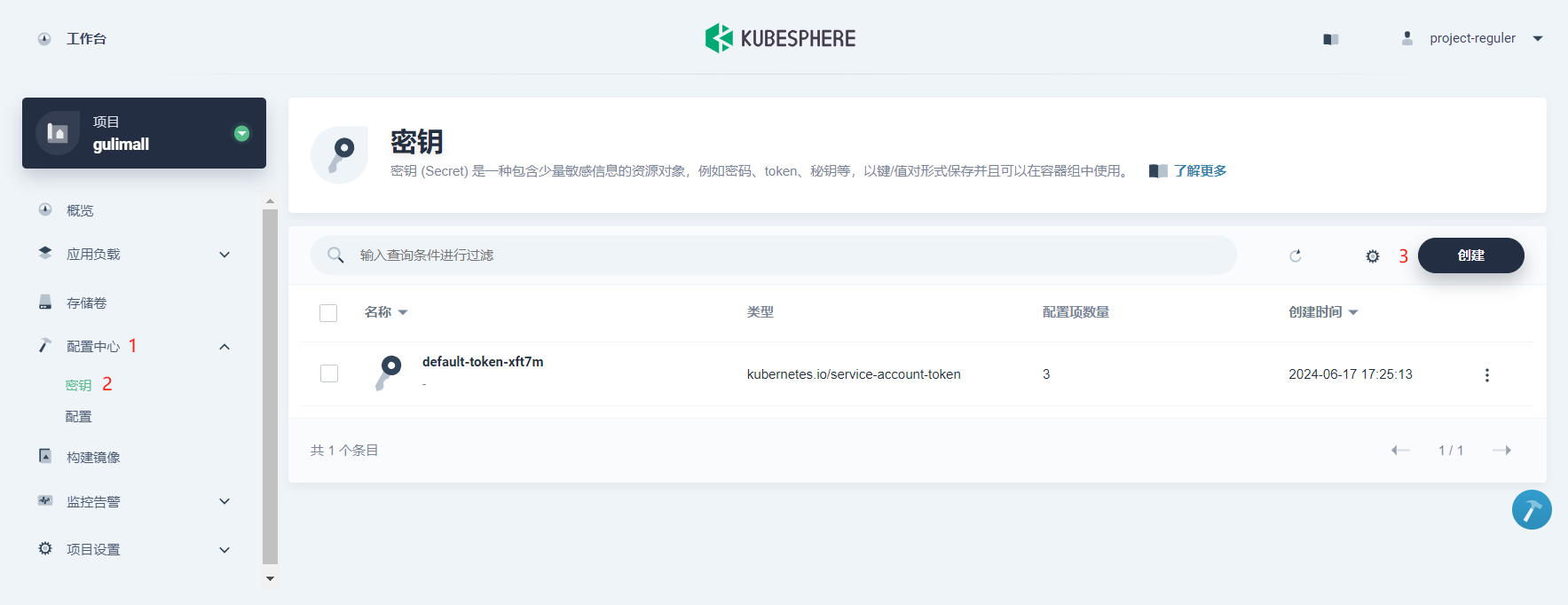
-
以项目普通用户
project-regular登录 KubeSphere,在当前项目下左侧菜单栏的 配置中心 选择 密钥,点击 创建。
-
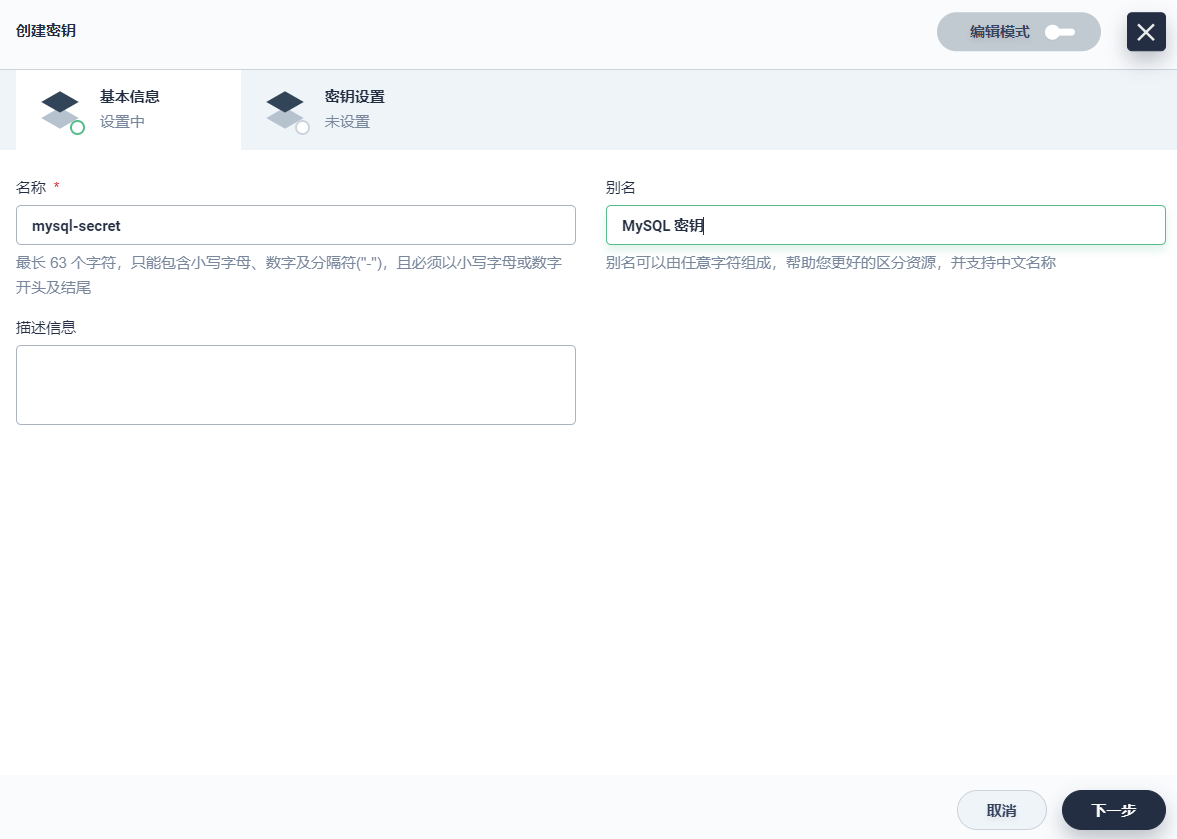
填写密钥的基本信息,完成后点击 下一步。
- 名称:作为 MySQL 容器中环境变量的名称,可自定义,例如 mysql-secret
- 别名:别名可以由任意字符组成,帮助您更好的区分资源,例如 MySQL 密钥
- 描述信息:简单介绍该密钥,如 MySQL 初始密码
-
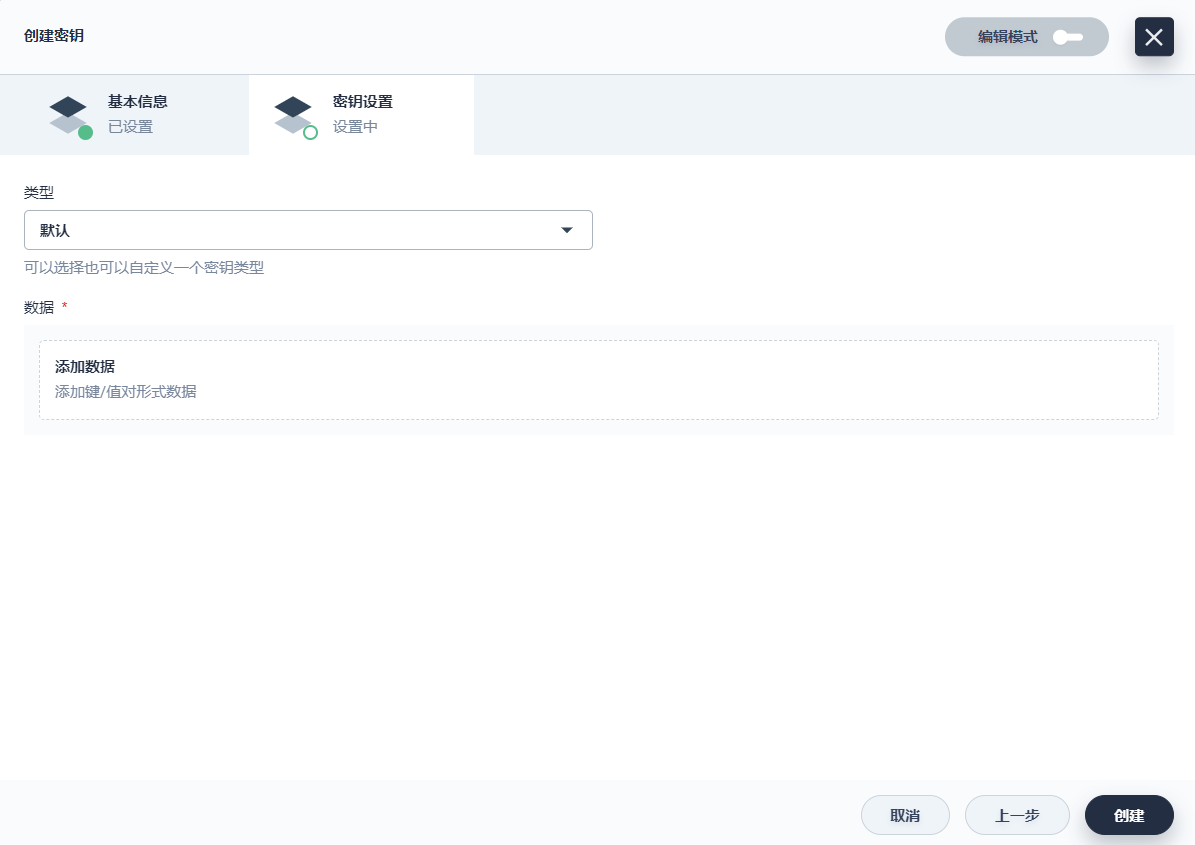
密钥设置页,填写如下信息,完成后点击 创建。
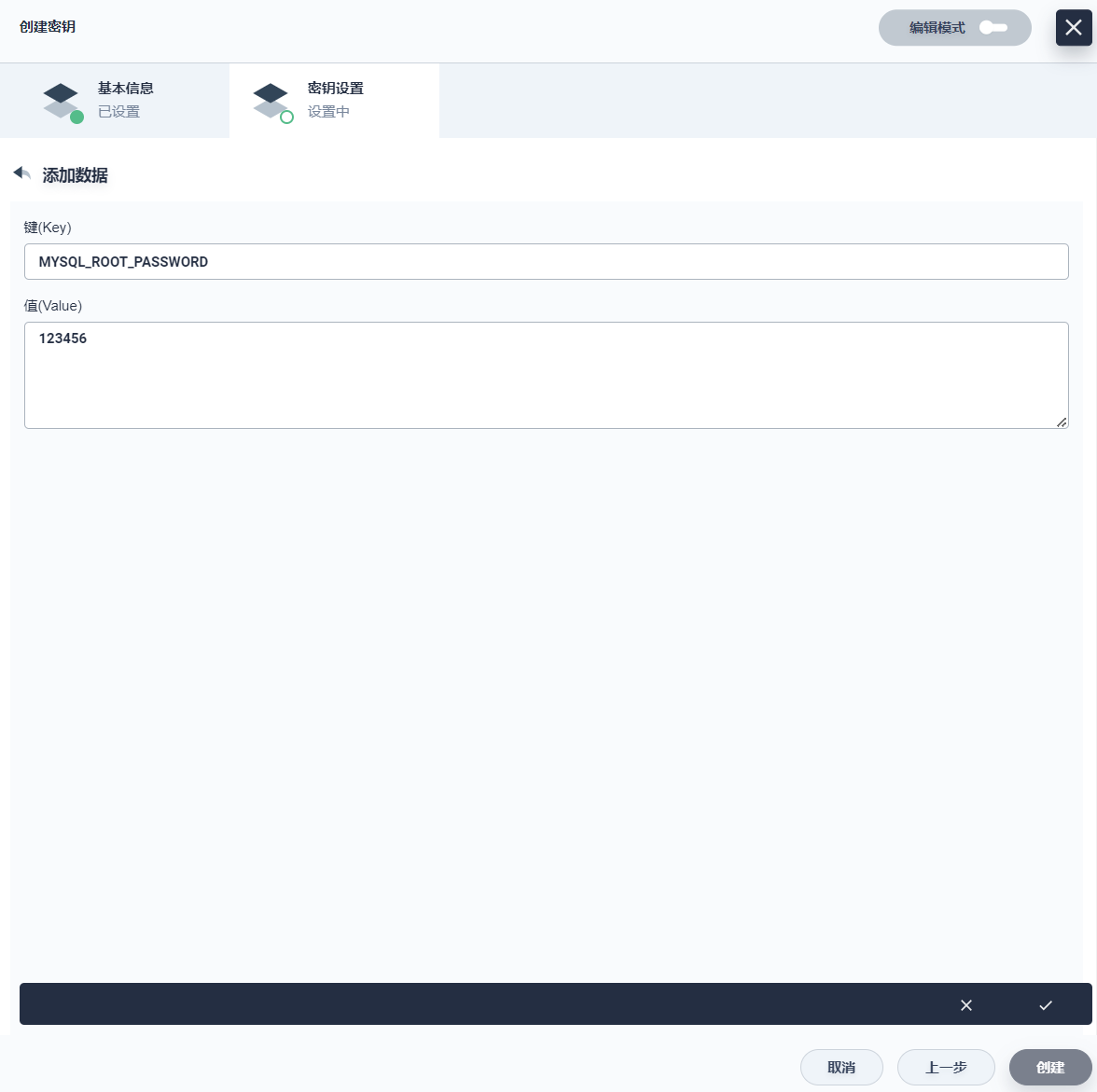
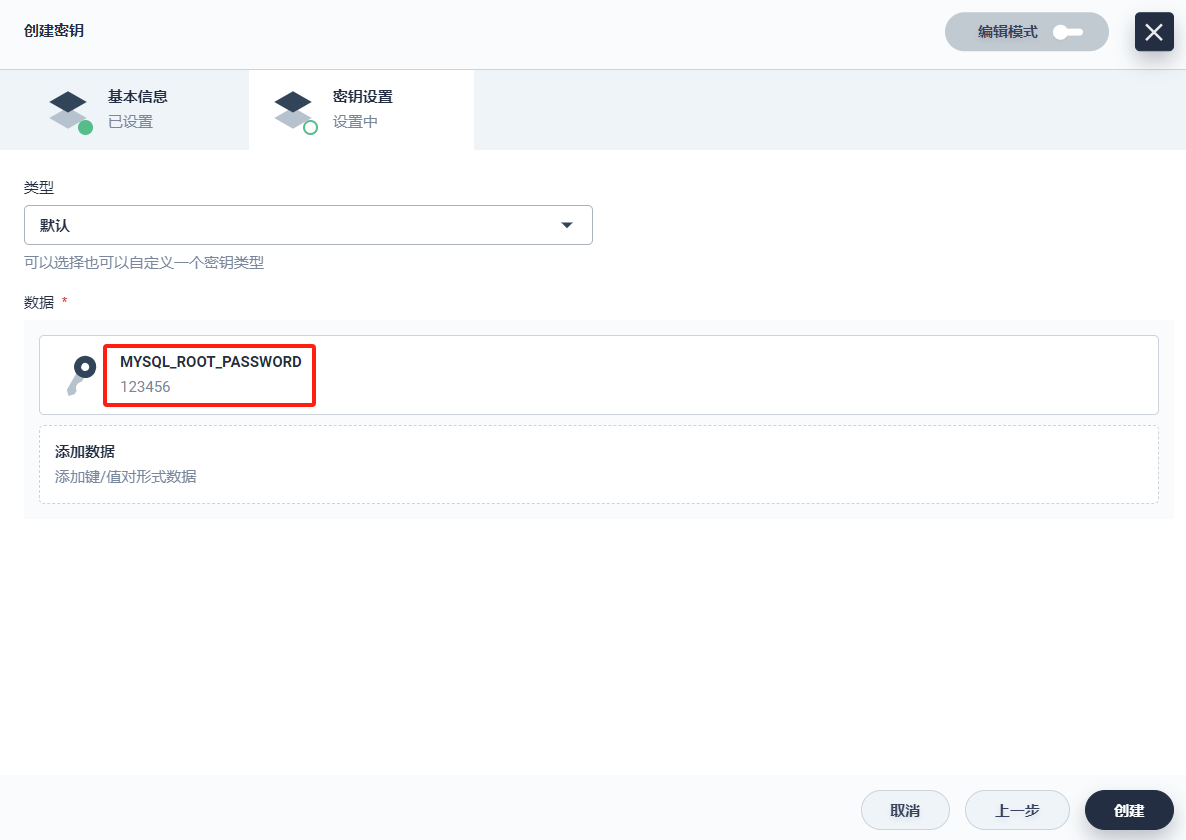
- 类型:选择 默认(Opaque)
- Data:Data 键值对填写 MYSQL_ROOT_PASSWORD和 123456
4.3.2、创建 WordPress 密钥
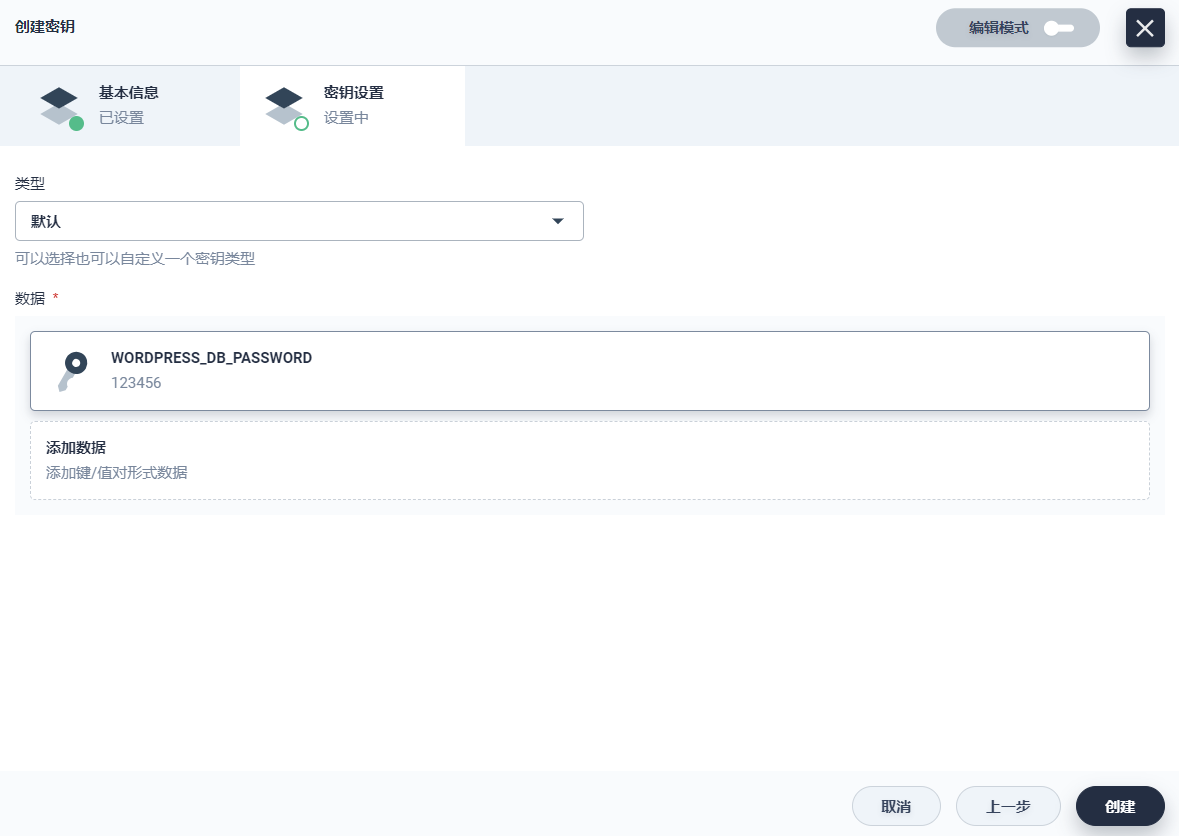
同上,创建一个 WordPress 密钥,Data 键值对填写 WORDPRESS_DB_PASSWORD和 123456。此时两个密钥都创建完成。
4.4、创建存储卷
-
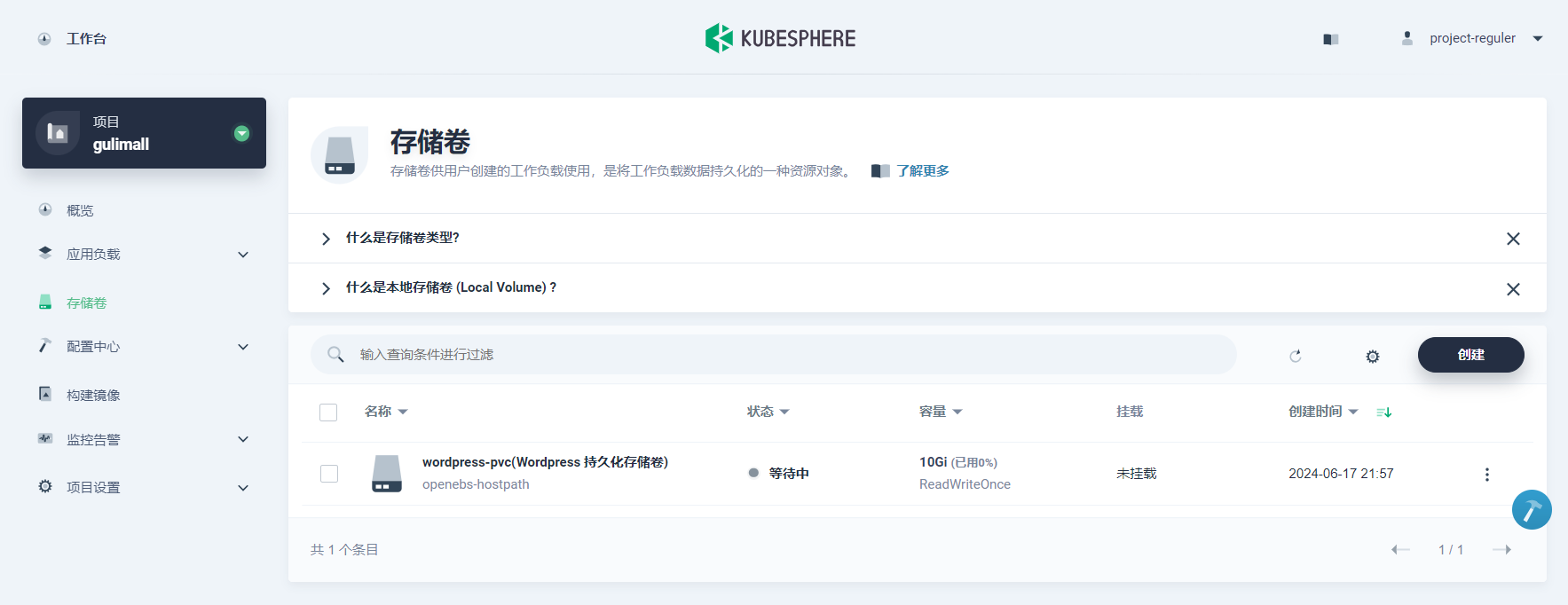
在当前项目下左侧菜单栏的 存储卷,点击 创建,基本信息如下。
- 名称:wordpress-pvc
- 别名:Wordpress 持久化存储卷
- 描述信息:Wordpress PVC
-
完成后点击 下一步,存储类型默认 local,访问模式和存储卷容量也可以使用默认值,点击 下一步,直接创建即可。
-
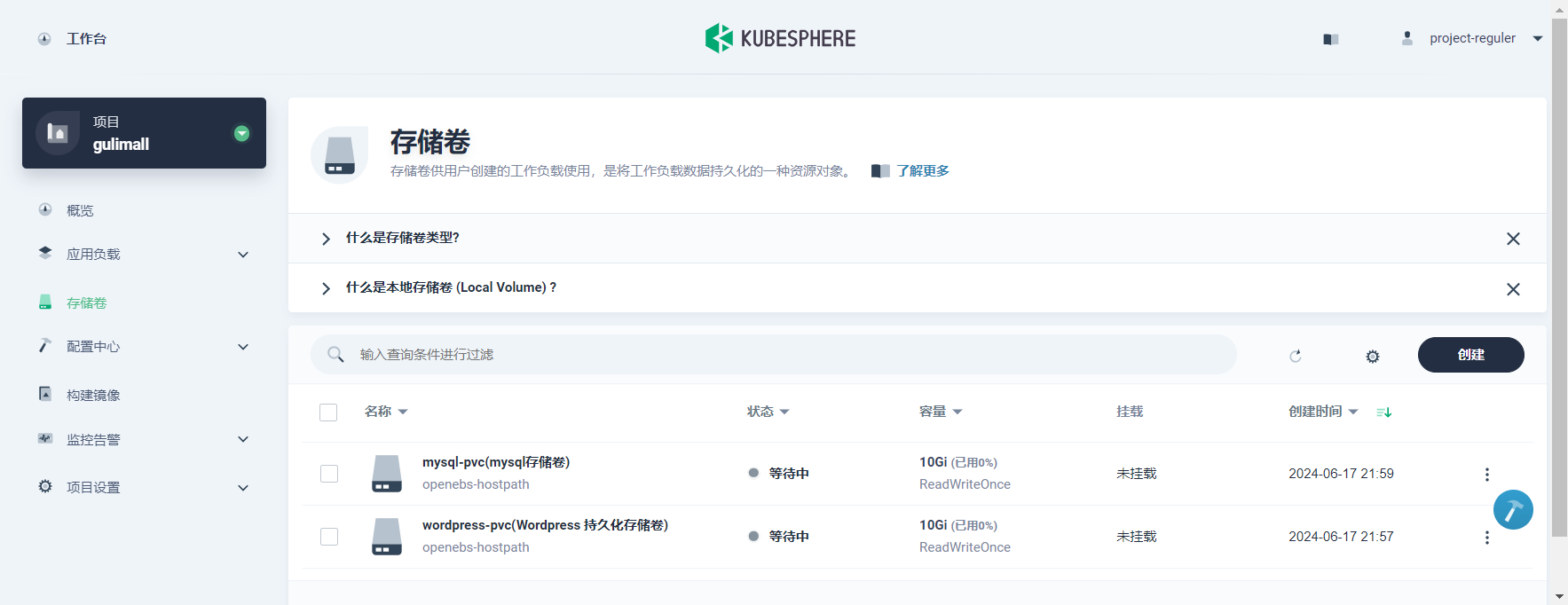
同上方法创建mysql存储卷
4.5、创建应用
4.5.1、添加 MySQL 组件
1)、KubeSphere2.1 集成私有镜像仓库 Harbor
前置条件:
因docker hub已经不允许访问,我们添加容器镜像的时候无法从官网下载镜像,所以我们需要自己搭建 docker私有仓库-Harbor。
KubeSphere集成本地容器镜像仓库 Harbor前提是我们需要有一个私有镜像仓库。如何搭建docker私有仓库-Harbor,请参考文档:docker搭建私有仓库
添加 Harbor 镜像仓库
Harbor 简介
Harbor 是一个用于存储和分发 Docker 镜像的企业级 Registry 服务器,通过添加一些企业必需的功能特性,例如安全、标识和管理等,扩展了开源 Docker Distribution,作为一个企业级私有 Registry 服务器,Harbor 提供了更好的性能和安全。注意,添加之前请确保已创建了 Harbor 镜像仓库服务端,以下详细介绍如何在 KubeSphere 中添加 Harbor 镜像仓库。
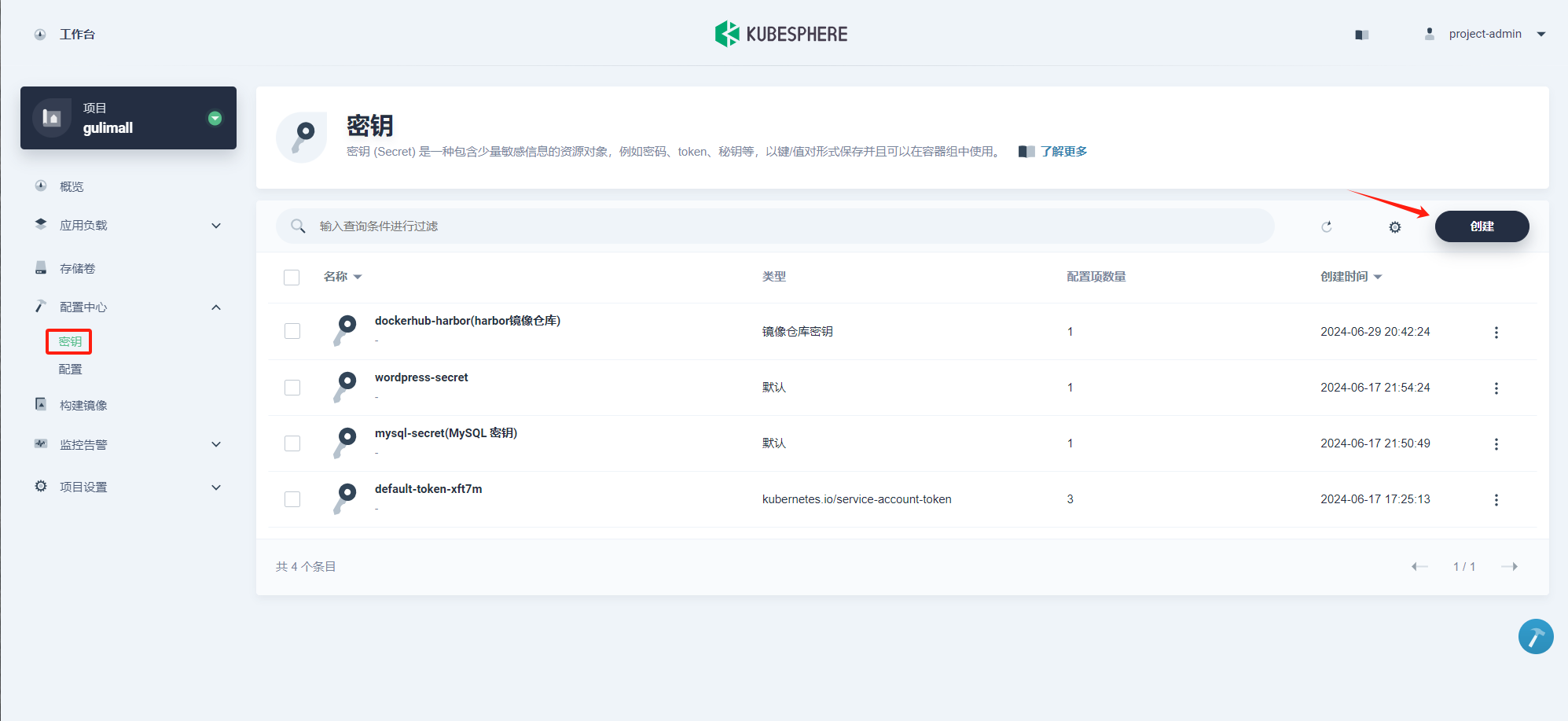
-
登录 KubeSphere 管理控制台,在已创建的项目中,左侧菜单栏中选择 配置中心 → 密钥,点击 创建。
-
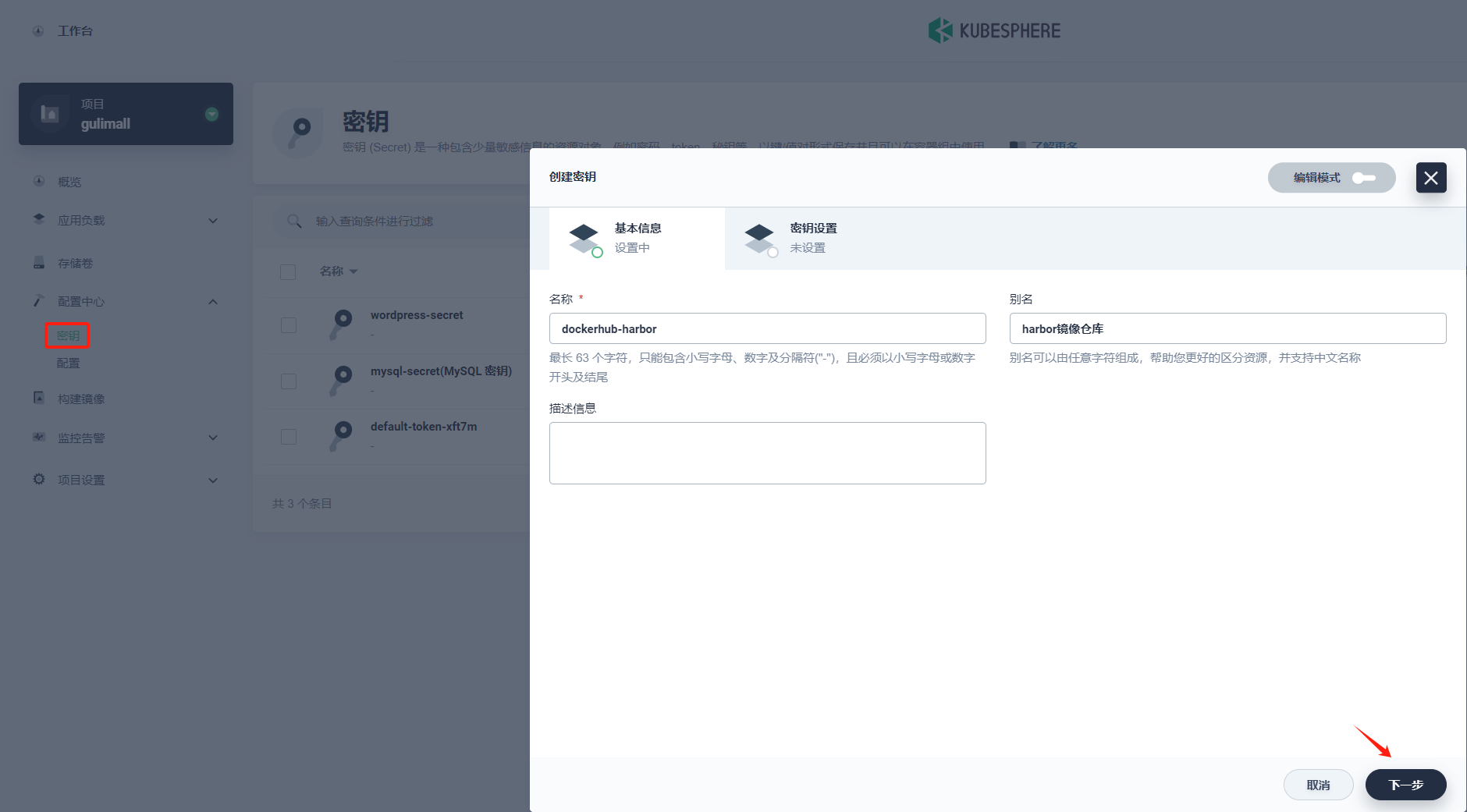
填写镜像仓库的基本信息
- 名称:为镜像仓库起一个简洁明了的名称,便于浏览和搜索。
- 别名:帮助您更好的区分资源,并支持中文名称。
- 描述信息:简单介绍镜像仓库的主要特性,让用户进一步了解该镜像仓库。
-
密钥设置中,类型选择 镜像仓库密钥,填写镜像仓库的登录信息。
- 仓库地址:用 Harbor 镜像仓库地址
192.168.119.133作为示例 - 用户名/密码:填写 admin/ Harbor
- 邮箱:填写个人邮箱
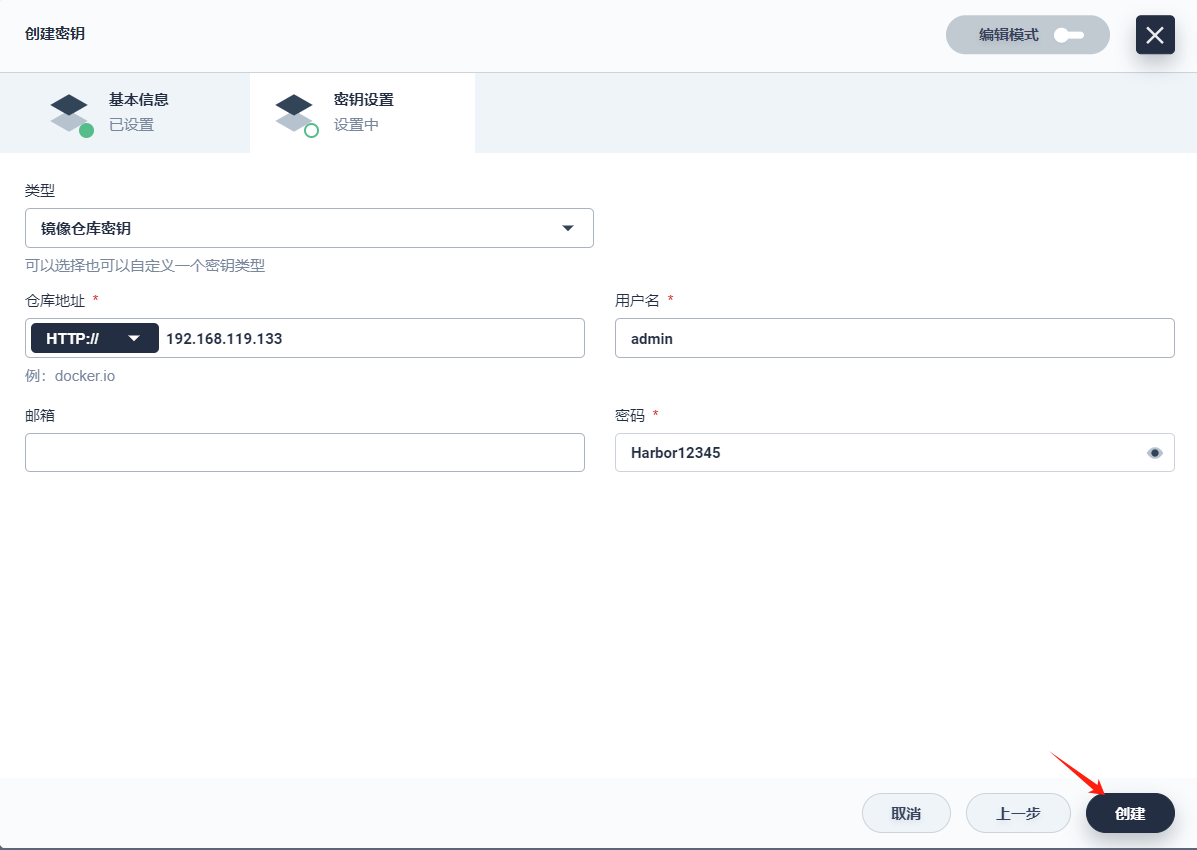
- 仓库地址:用 Harbor 镜像仓库地址
-
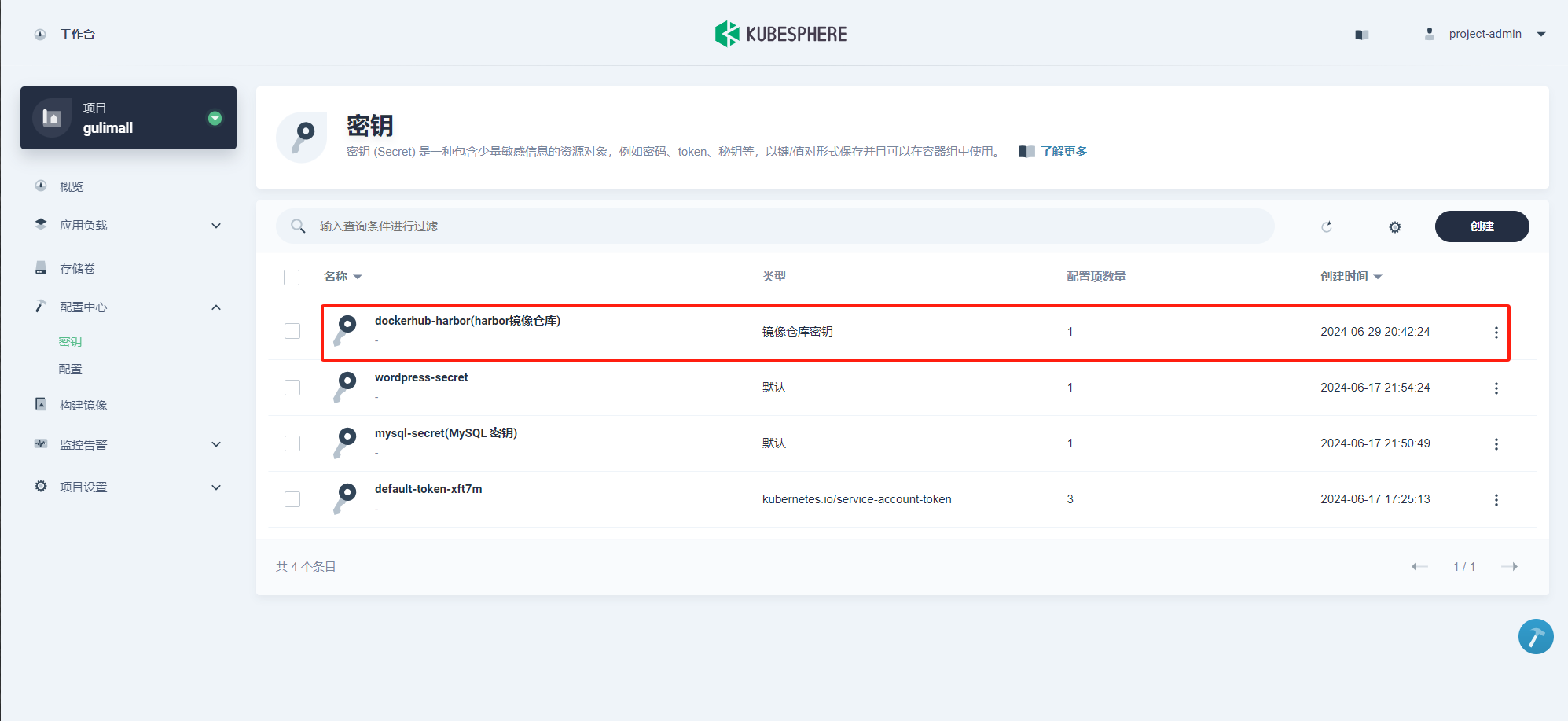
点击 创建,即可查看创建结果。
2)、添加 MySQL 组件
-
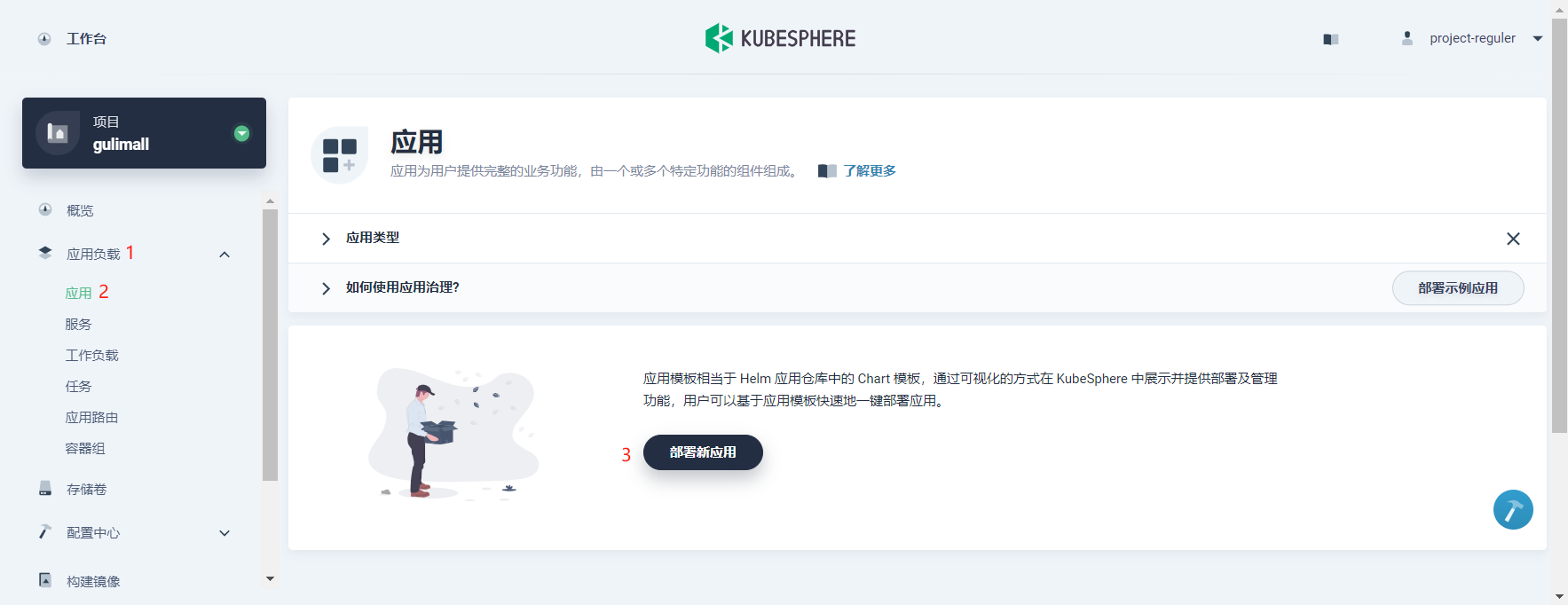
在左侧菜单栏选择 应用负载 → 应用,然后点击 部署新应用。
-
基本信息中,参考如下填写,完成后在右侧点击 添加组件。
- 应用名称:必填,起一个简洁明了的名称,便于用户浏览和搜索,例如填写
wordpress-application - 描述信息:简单介绍该工作负载,方便用户进一步了解
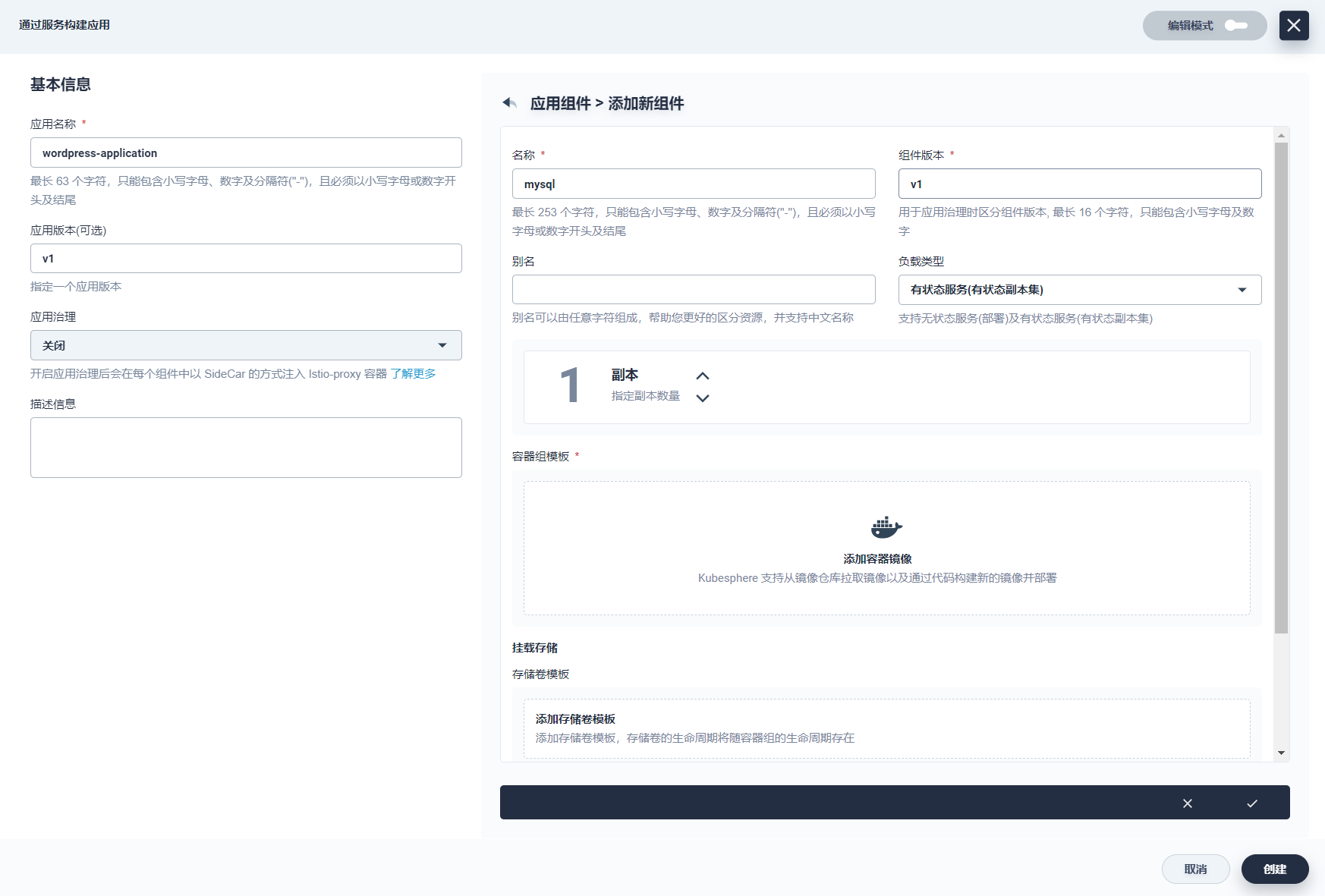
- 应用名称:必填,起一个简洁明了的名称,便于用户浏览和搜索,例如填写
-
参考如下提示完成 MySQL 组件信息:
- 名称: mysql
- 组件版本:v1
- 别名:MySQL 数据库
- 负载类型:选择
有状态服务
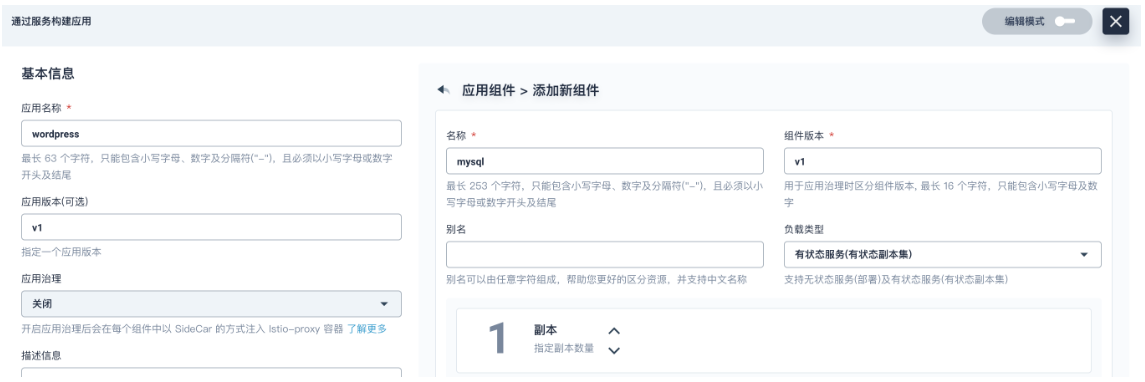
-
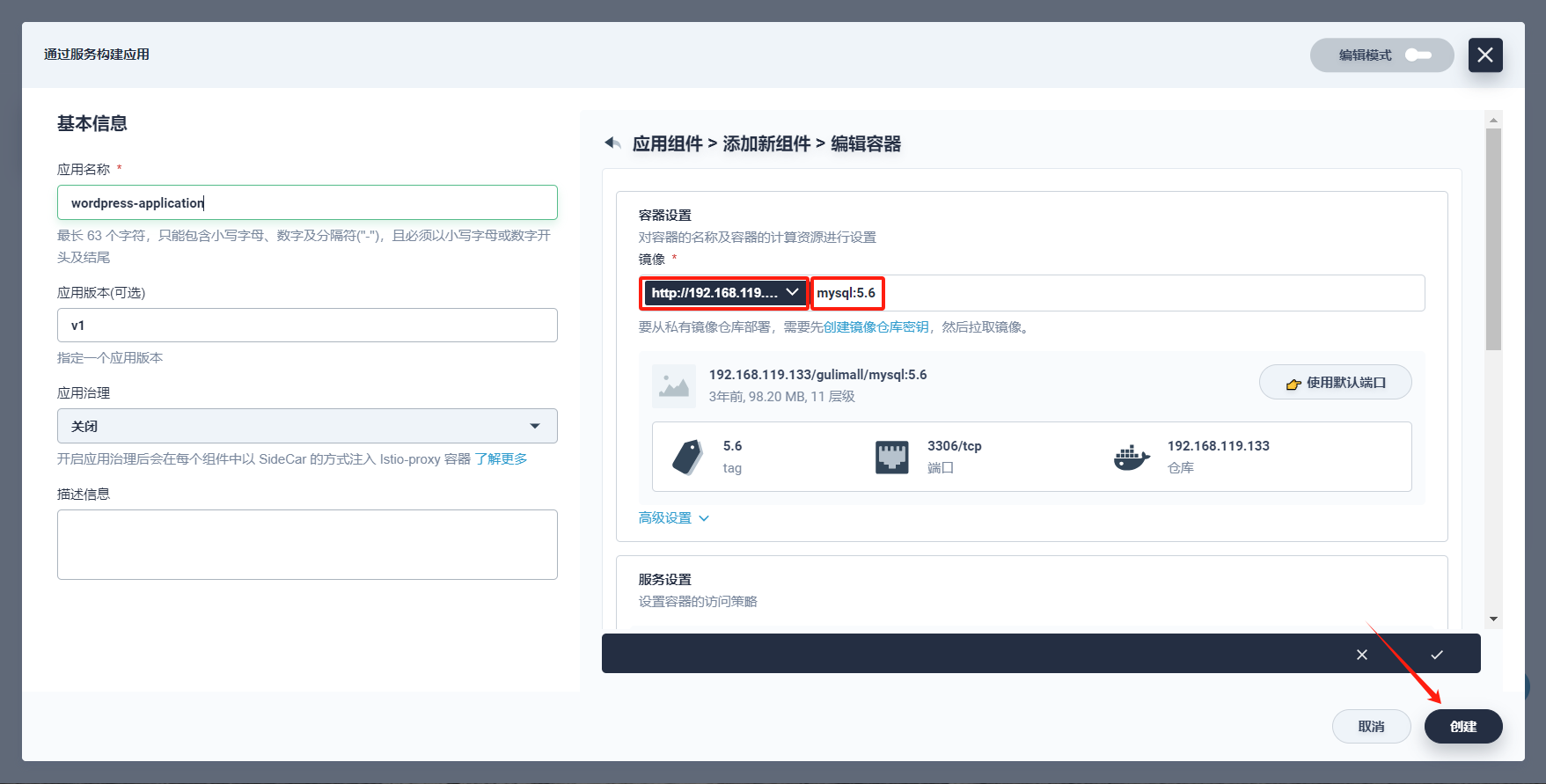
点击 添加容器镜像,镜像填写 mysql:5.6(应指定镜像版本号),然后按回车键或点击 DockerHub,点击 使用默认端口。
提示 :
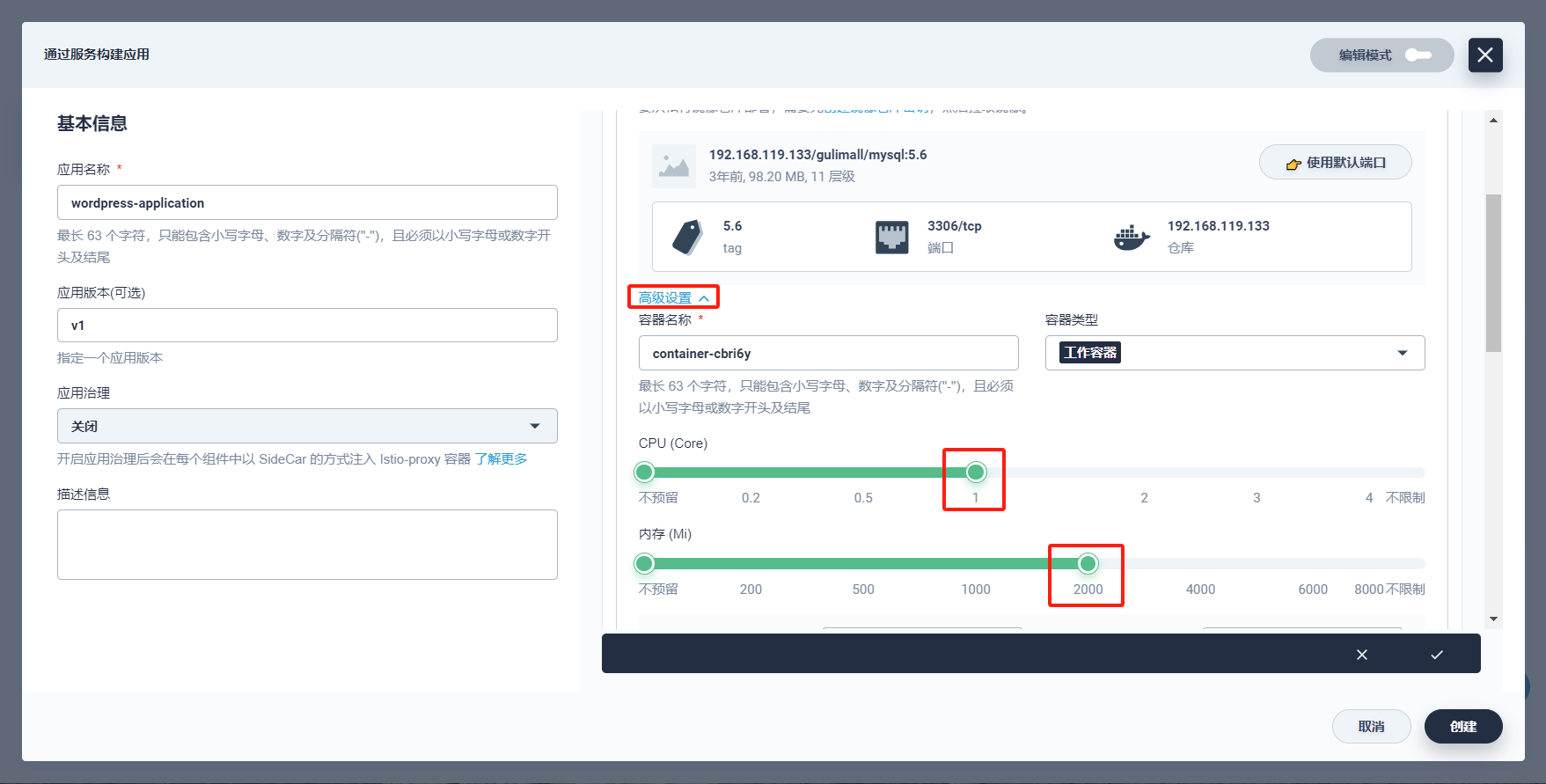
注意,DockerHub官网关闭了,现在我们无法访问,在此我们使用自己私有镜像仓库:192.168.119.133/mysql/注意,在高级设置中确保内存限制 ≥ 1000 Mi,否则可能 MySQL 会因内存 Limit 不够而无法启动。
-
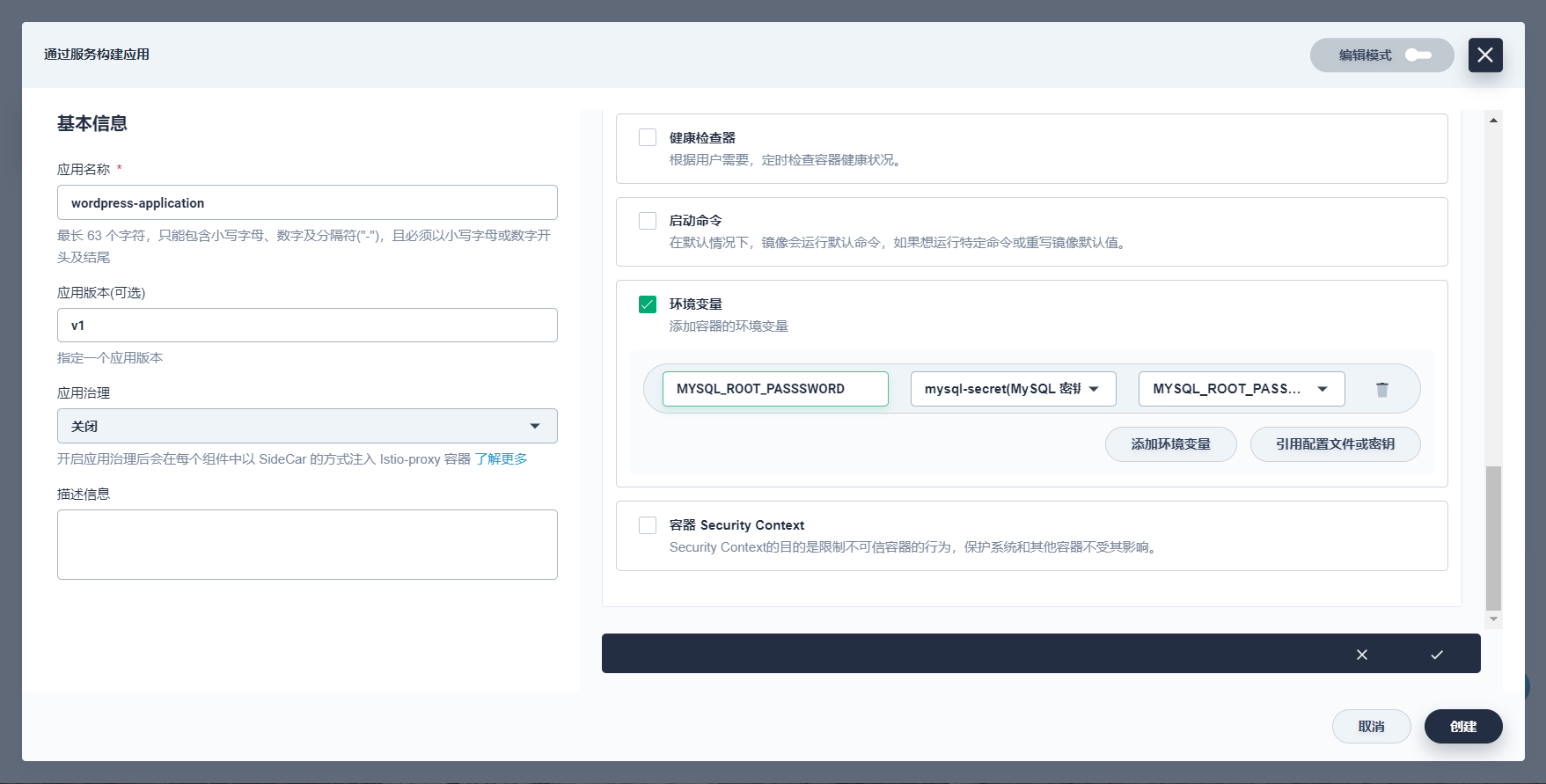
下滑至环境变量,在此勾选 环境变量,然后选择 引用配置文件或密钥,名称填写为
MYSQL_ROOT_PASSWORD,下拉框中选择密钥为mysql-secret和MYSQL_ROOT_PASSWORD。
完成后点击右下角 √。
-
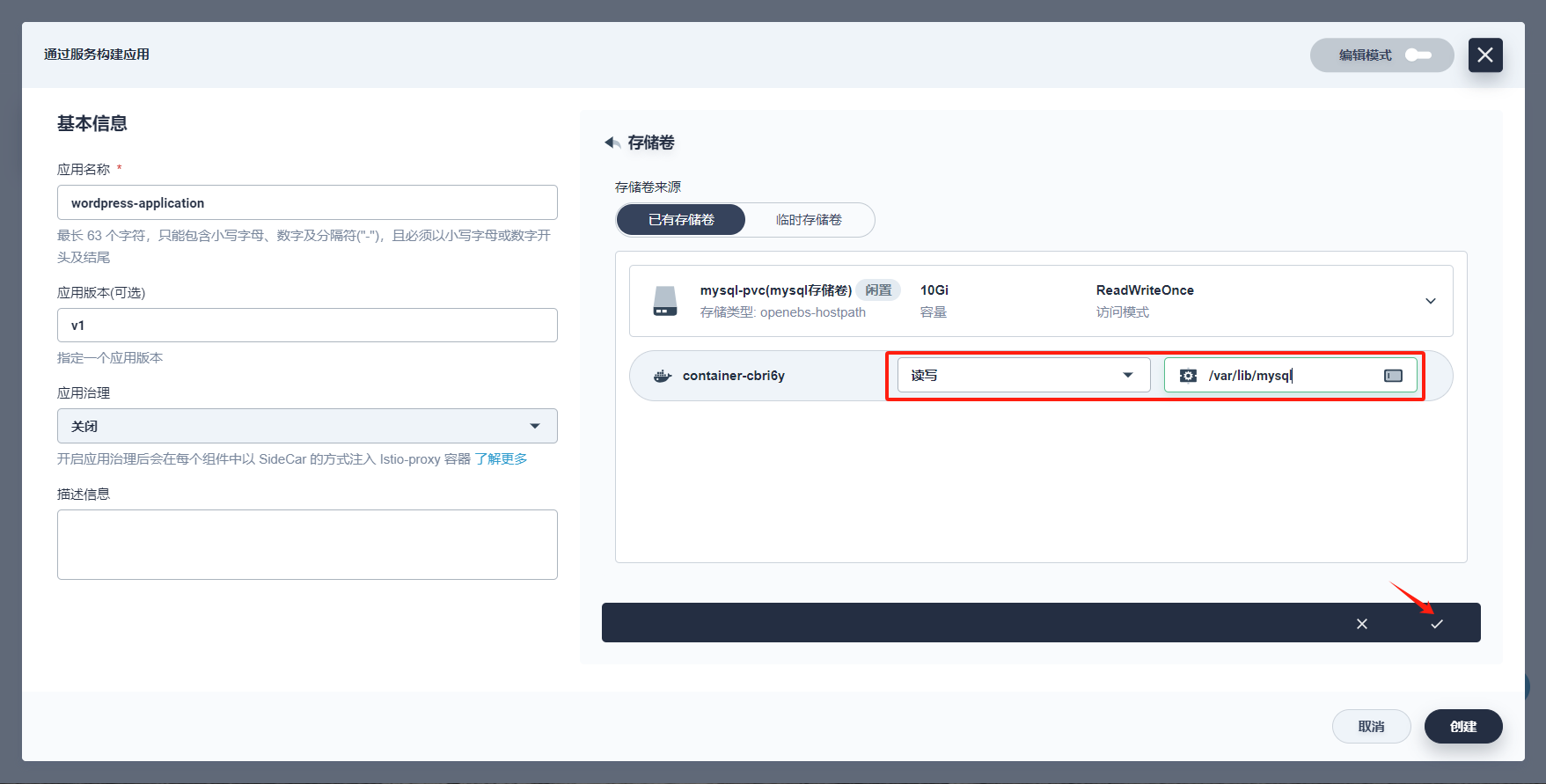
点击 添加存储卷模板,为 MySQL 创建一个 PVC 实现数据持久化。
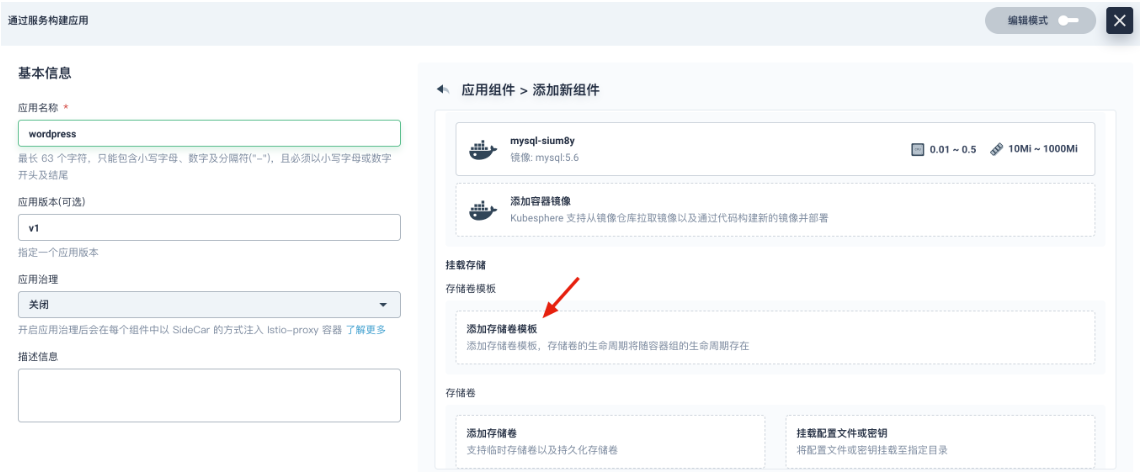
参考下图填写存储卷信息。- 存储卷名称:必填,起一个简洁明了的名称,便于用户浏览和搜索,此处填写
mysql-pvc - 存储类型:选择集群已有的存储类型,如
Local - 容量和访问模式:容量默认
10 Gi,访问模式默认ReadWriteOnce (单个节点读写) - 挂载路径:存储卷在容器内的挂载路径,选择 读写,路径填写
/var/lib/mysql
完成后点击 √。
- 存储卷名称:必填,起一个简洁明了的名称,便于用户浏览和搜索,此处填写
4.5.2、添加 WordPress 组件
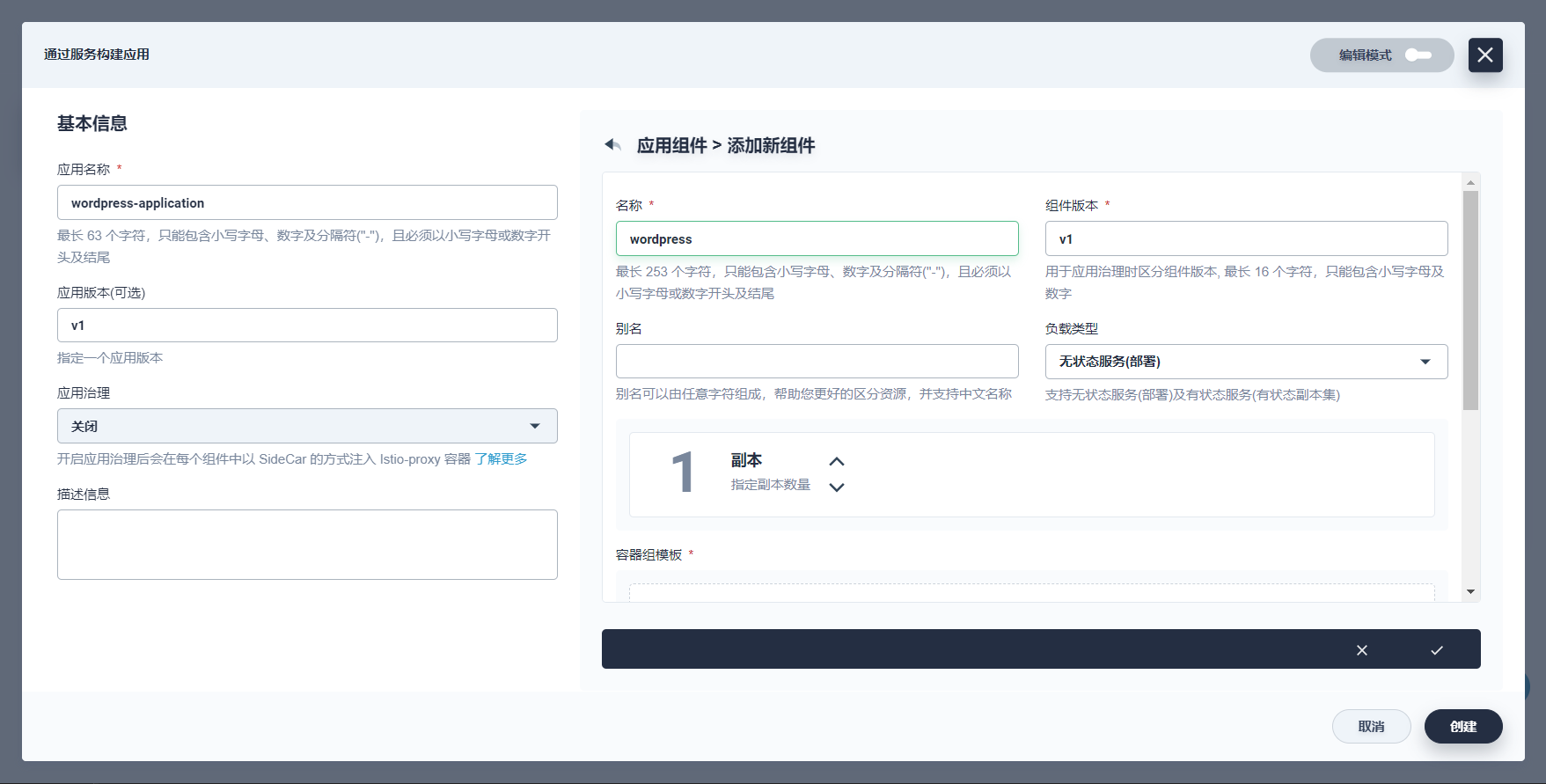
-
参考如下提示完成 WordPress 组件信息:
- 名称: wordpress
- 组件版本:v1
- 别名:Wordpress前端
- 负载类型:默认 无状态服务
-
点击 添加容器镜像,镜像填写
wordpress:4.8-apache(应指定镜像版本号),然后按回车键或点击 DockerHub,点击 使用默认端口。
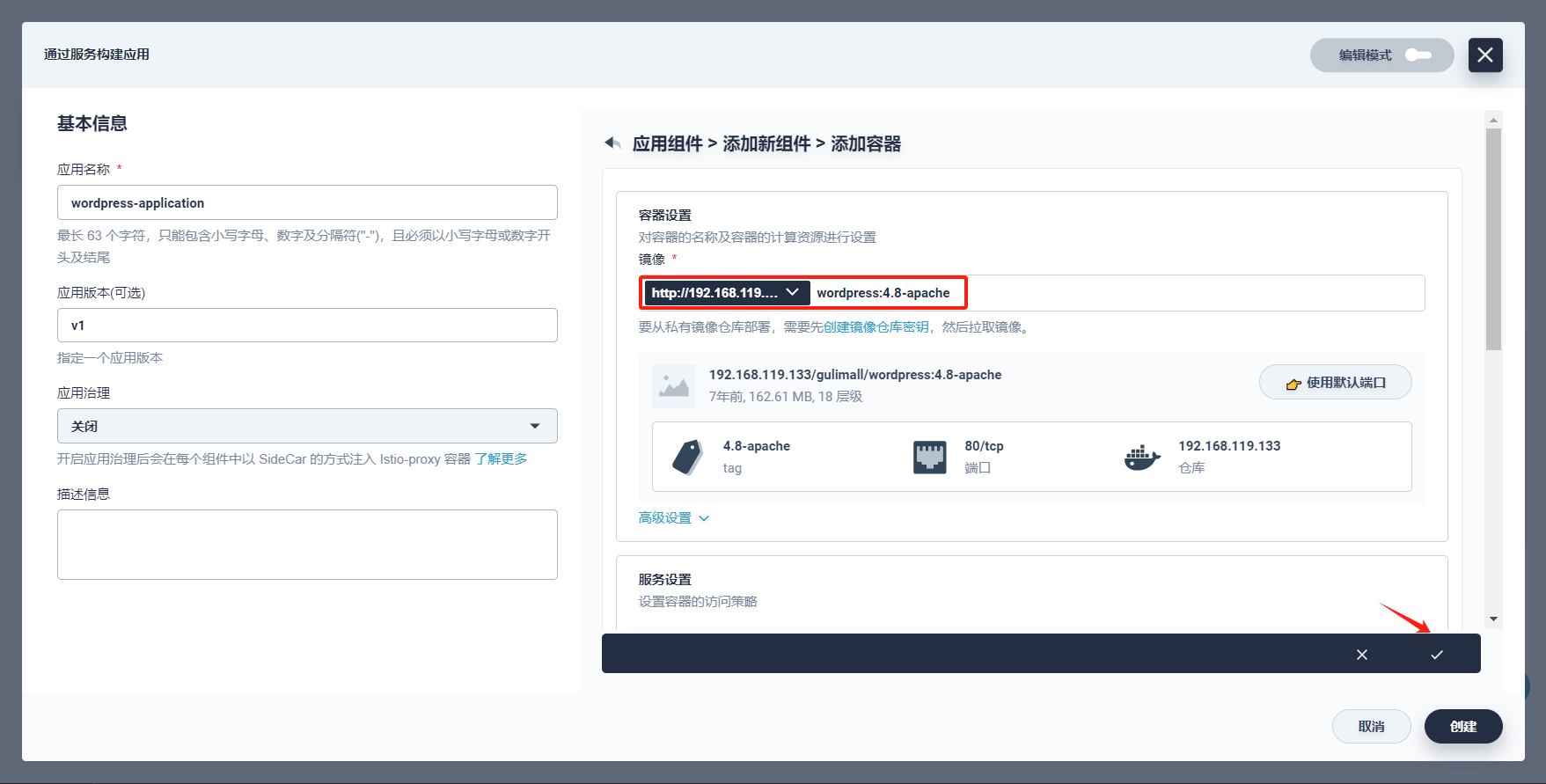
-
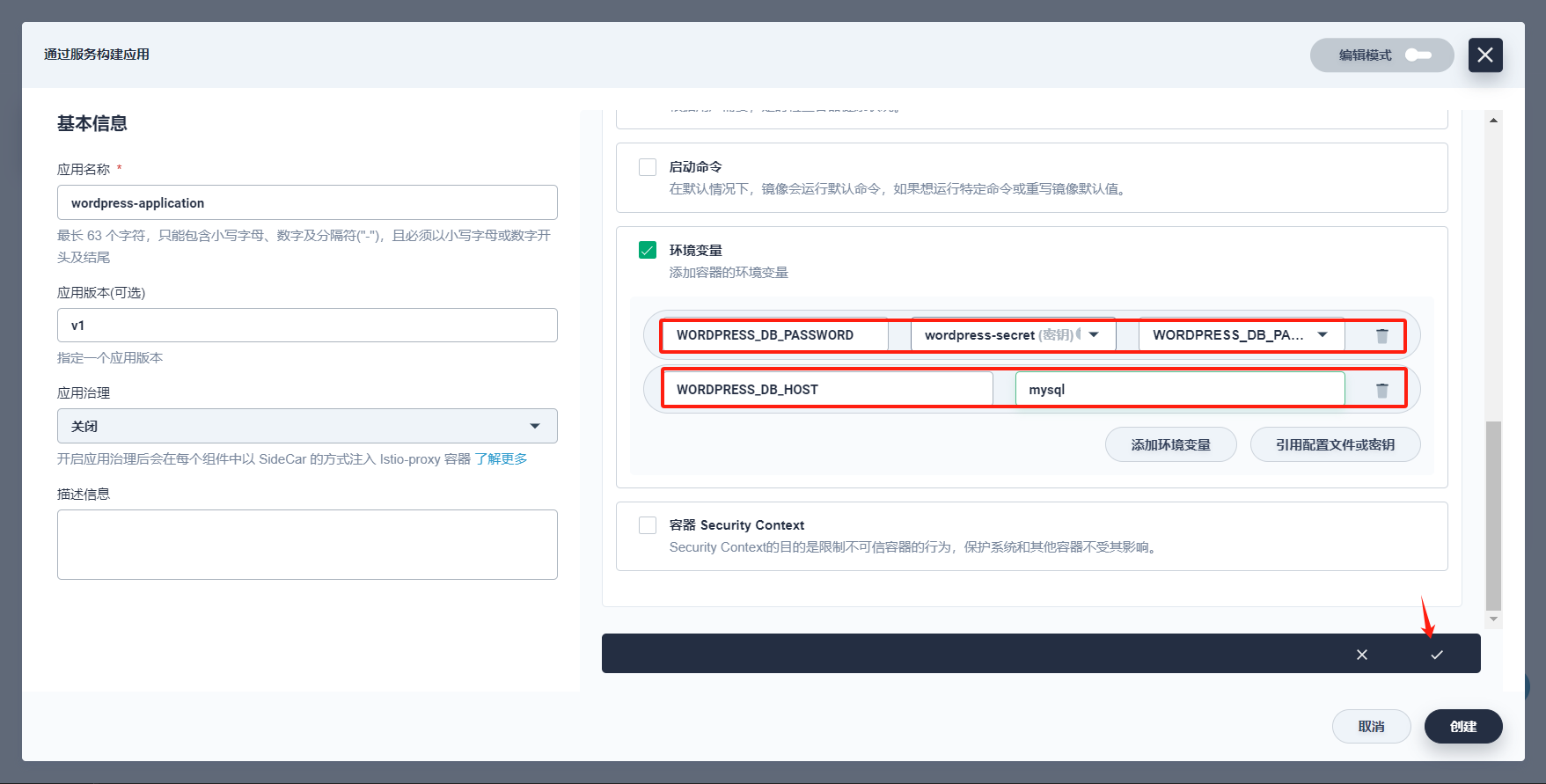
下滑至环境变量,在此勾选 环境变量,这里需要添加两个环境变量:
- 点击 引用配置文件或密钥,名称填写
WORDPRESS_DB_PASSWORD,选择在第一步创建的配置 (Secret)wordpress-secret和WORDPRESS_DB_PASSWORD。 - 点击 添加环境变量,名称填写
WORDPRESS_DB_HOST,值填写mysql,对应的是上一步创建 MySQL 服务的名称,否则无法连接 MySQL 数据库。
完成后点击 √。
提示 :
注意,DockerHub官网关闭了,现在我们无法访问,在此我们使用自己私有镜像仓库:192.168.119.133/mysql/
- 点击 引用配置文件或密钥,名称填写
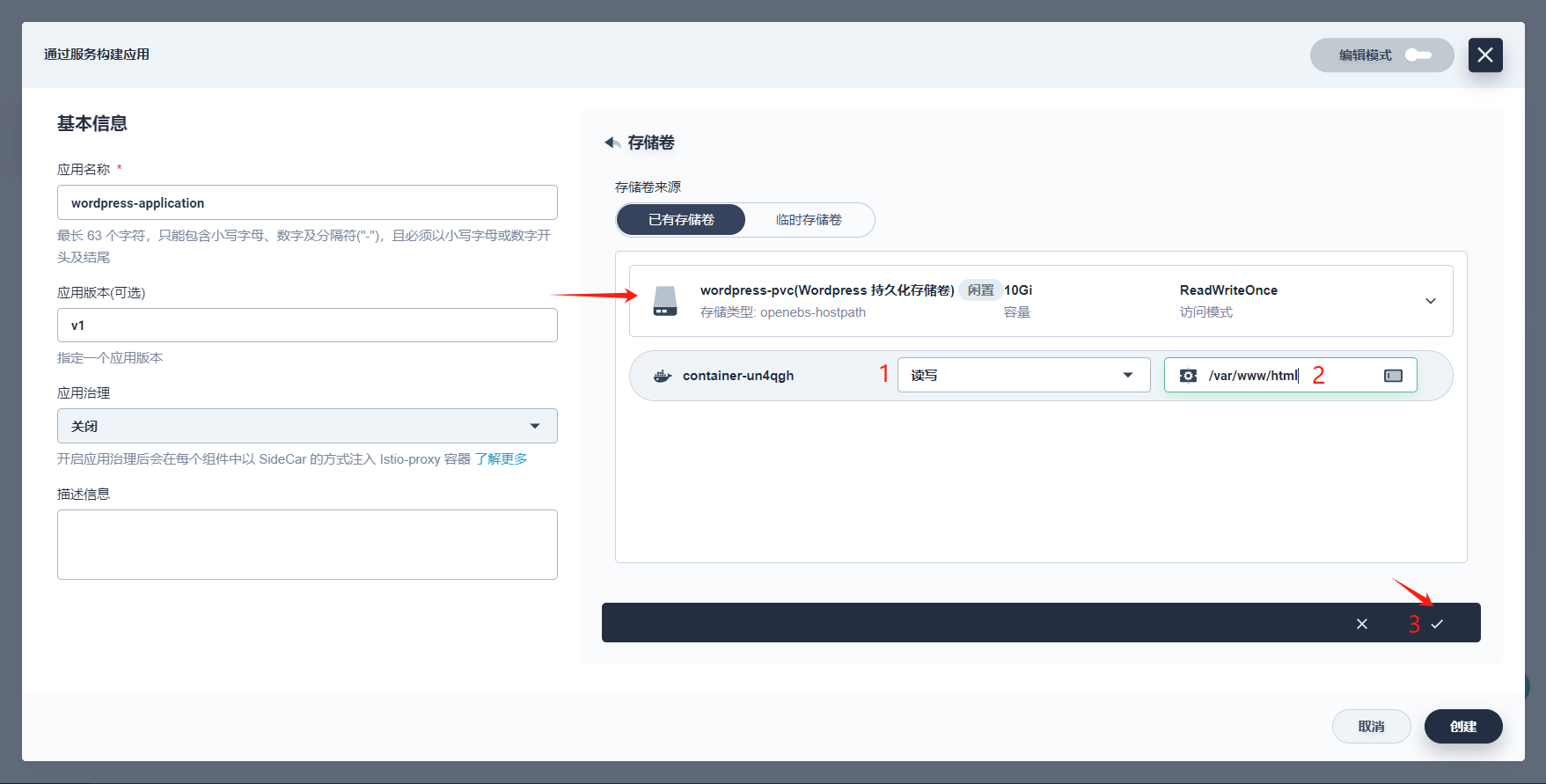
-
点击 添加存储卷,选择已有存储卷 wordpress-pvc,访问模式改为 读写,容器挂载路径
/var/www/html。完成后点击 √。
-
检查 WordPress 组件信息无误后,再次点击 √,此时 MySQL 和 WordPress 组件信息都已添加完成,点击 创建。
4.5.3、查看应用资源
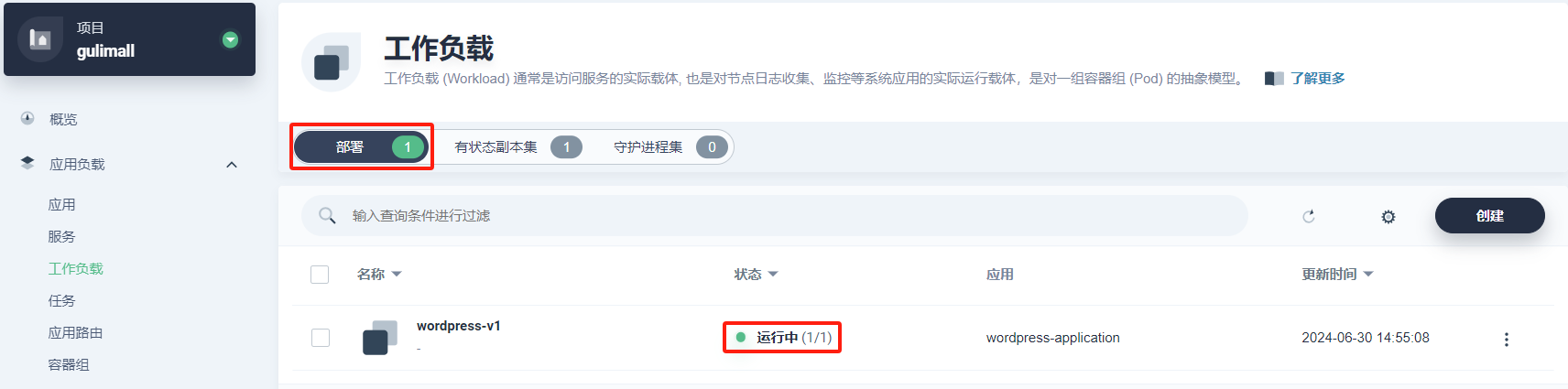
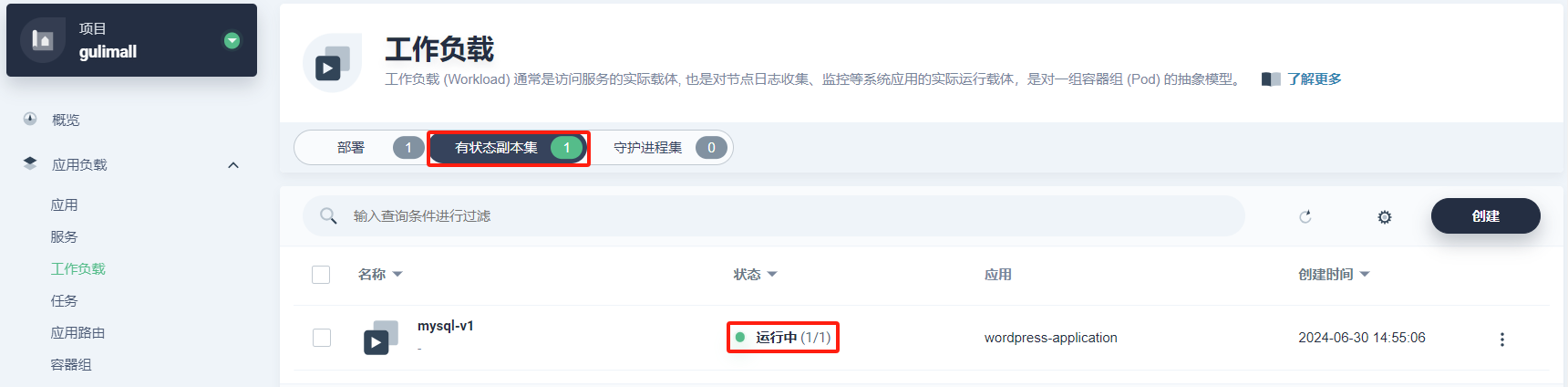
-
在 工作负载 下查看 部署 和 有状态副本集 的状态,当它们都显示为 运行中,说明 WordPress 应用创建成功。
-
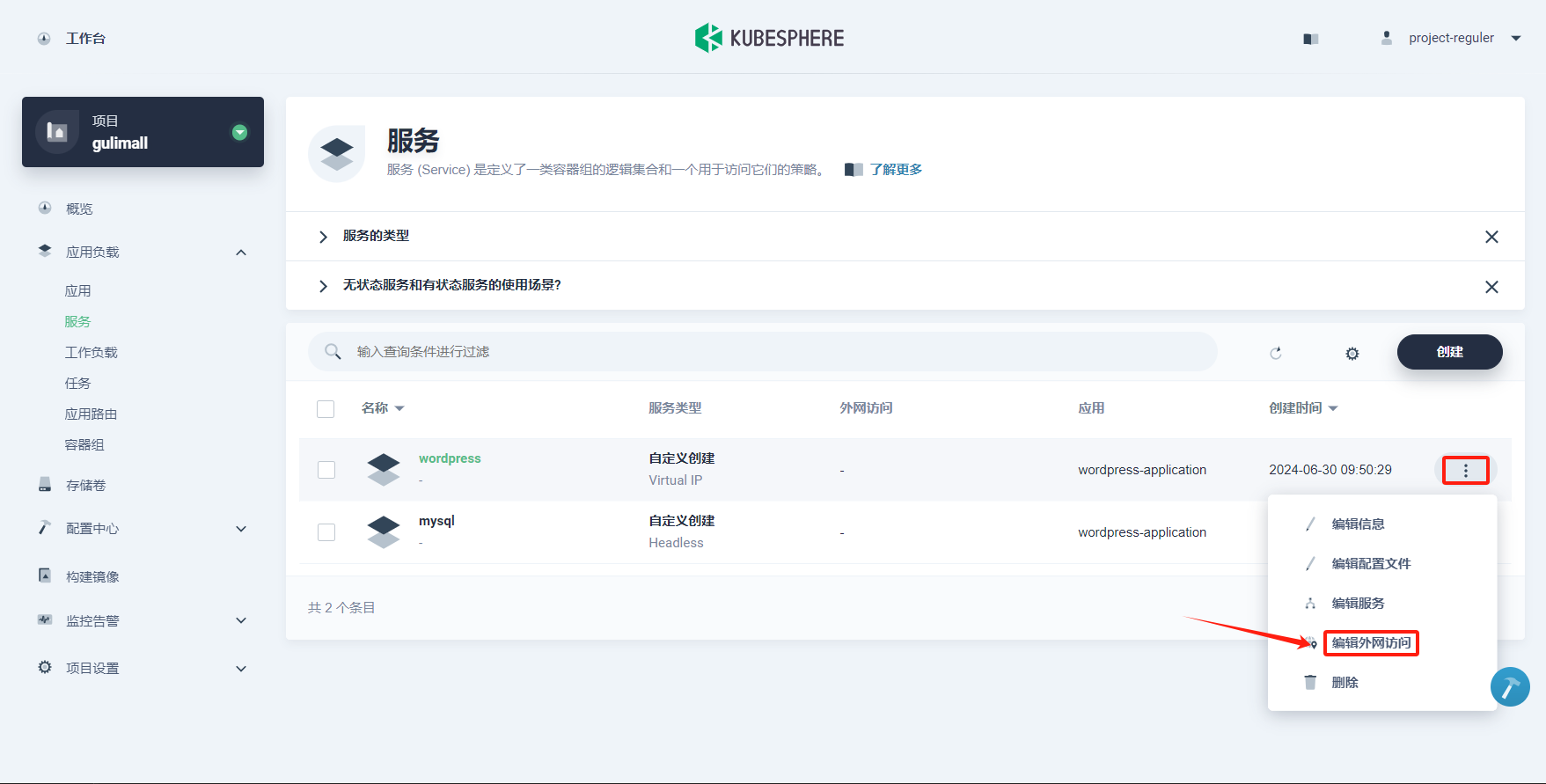
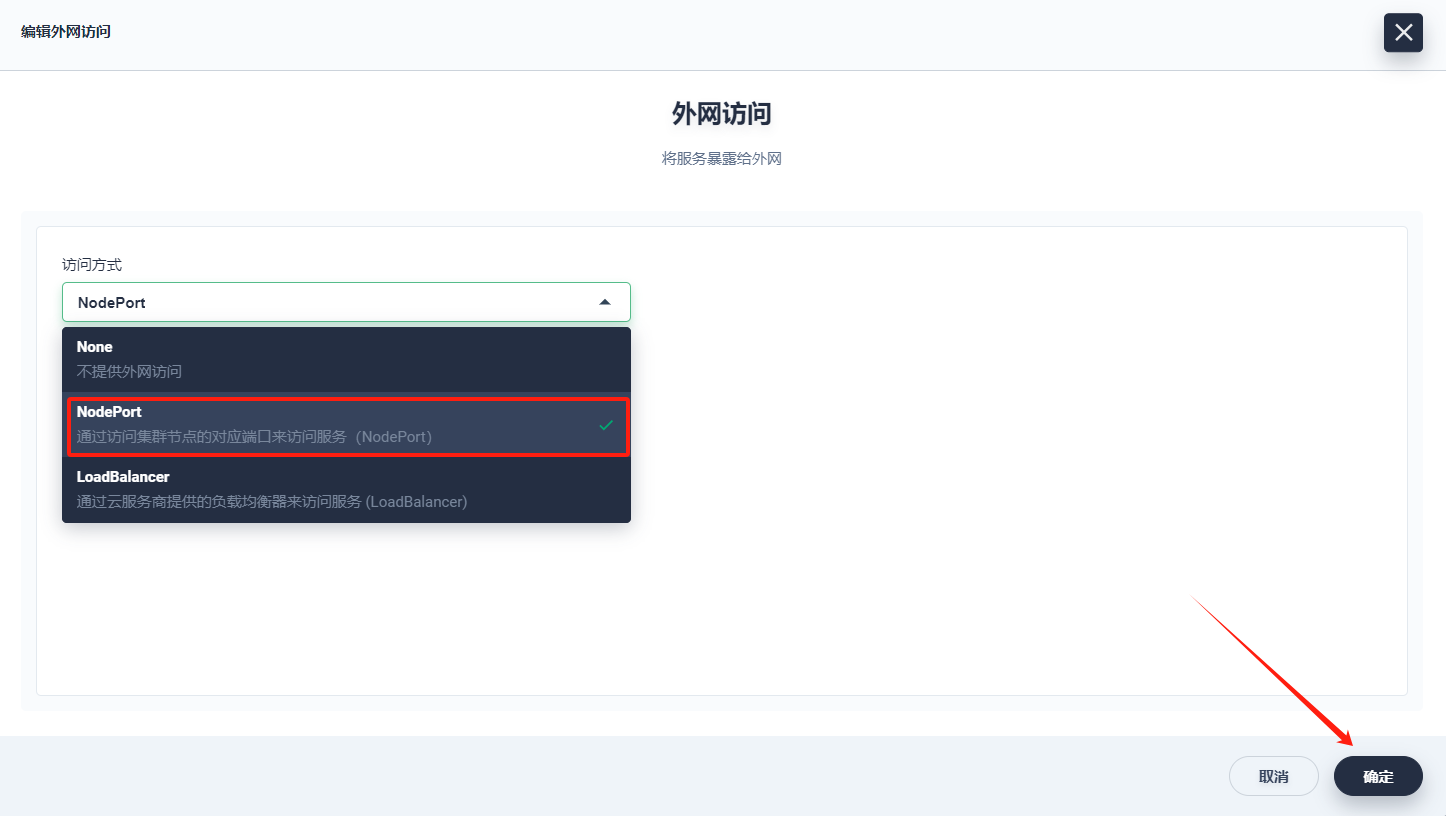
点击 更多操作→ 编辑外网访问,选择 NodePort,然后该服务将在每个节点打开一个节点端口,通过 点击访问即可在浏览器访问 WordPress。
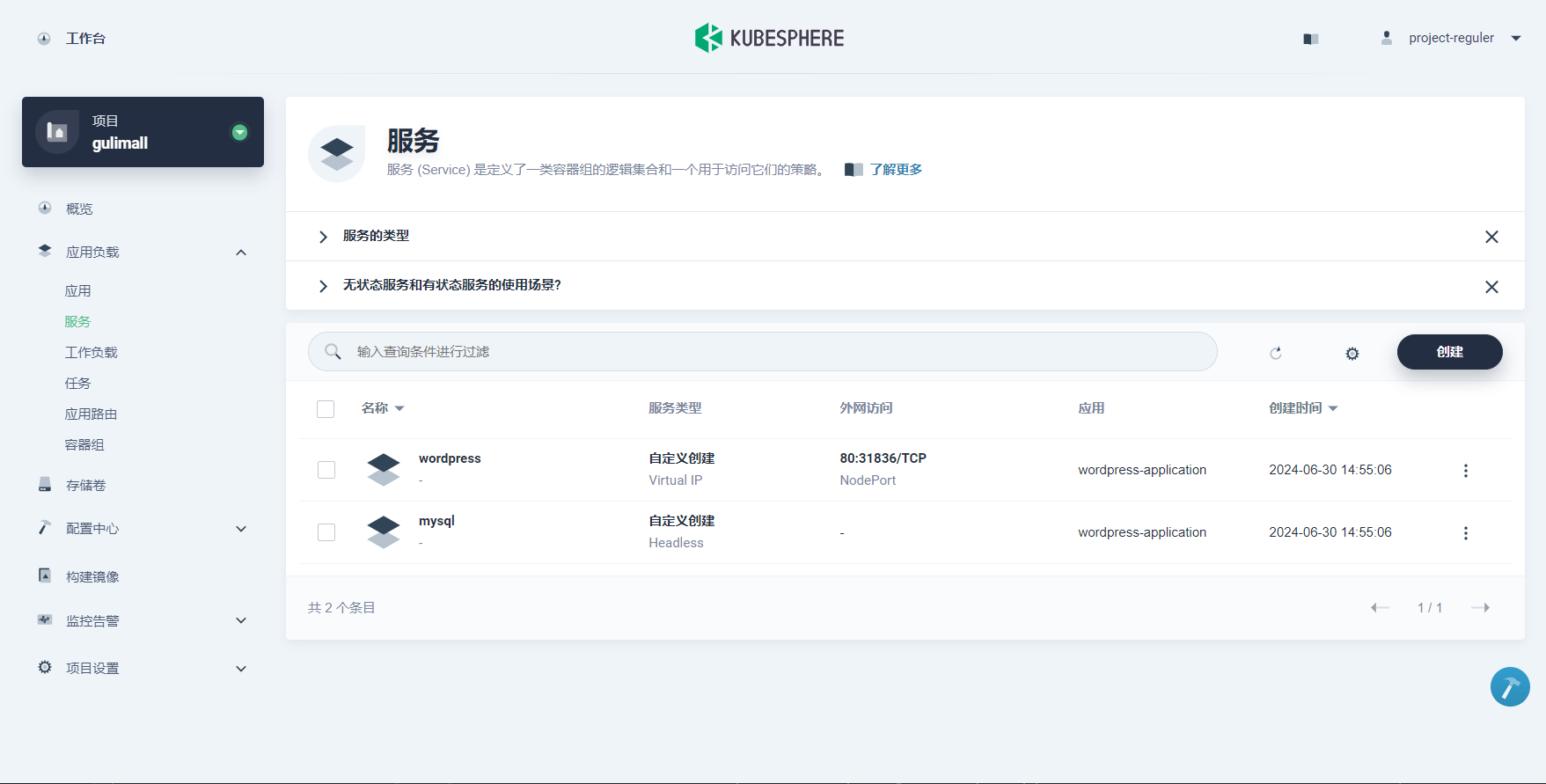
-
访问 Wordpress 服务前,查看 wordpress 服务,将外网访问设置为 NodePort。
4.5.4、访问 Wordpress
以上访问将通过 http://{KaTeX parse error: Expected 'EOF', got '}' at position 6: 节点 IP}̲:{节点端口 NodePort}访问 WordPress 博客网站。
访问地址:http://192.168.119.130:31836/
-
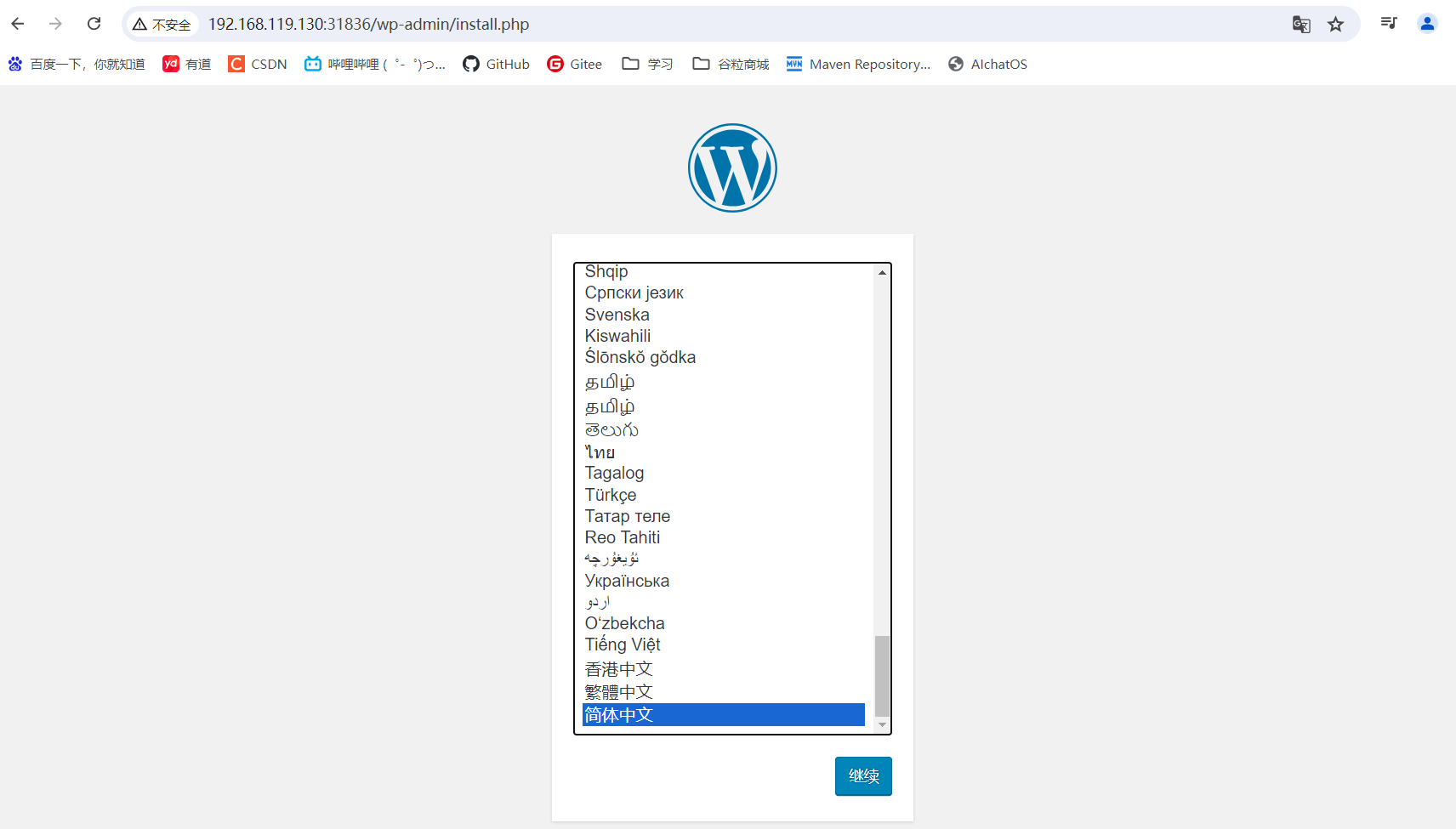
选则简体中文
-
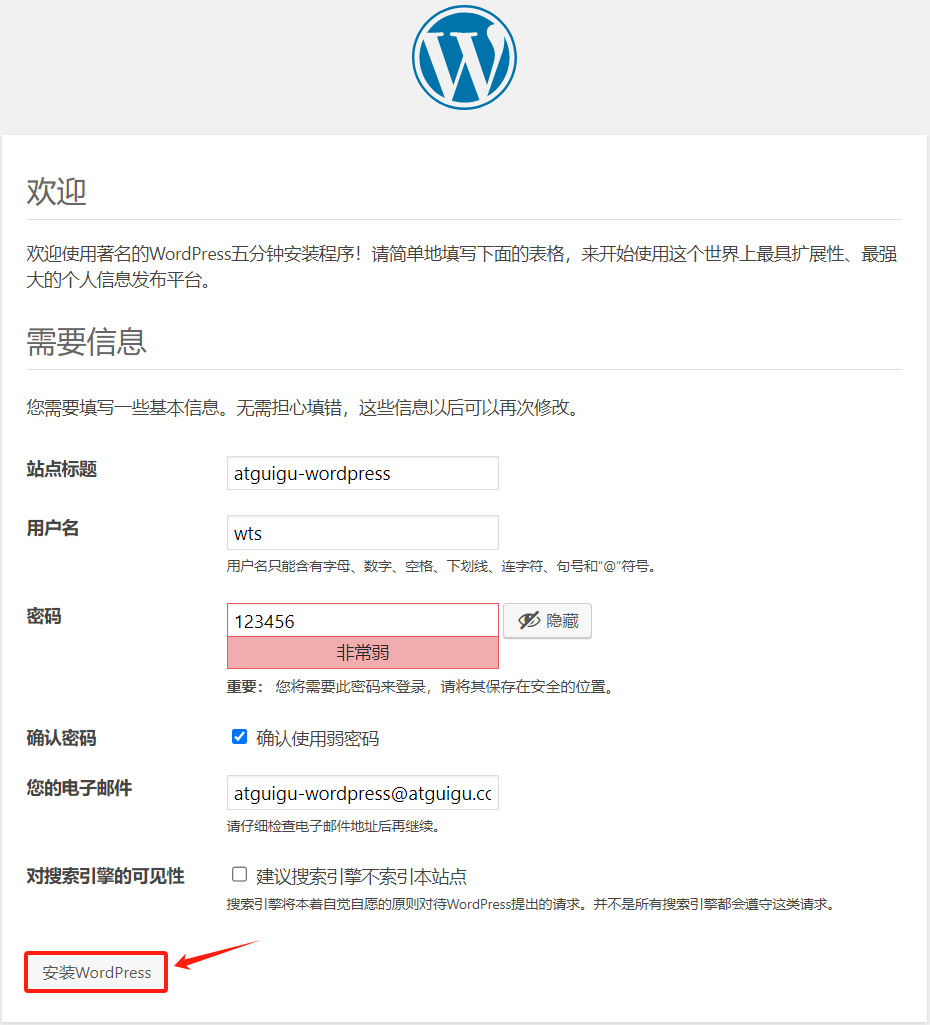
注册信息 ,并点击安装WordPress
-
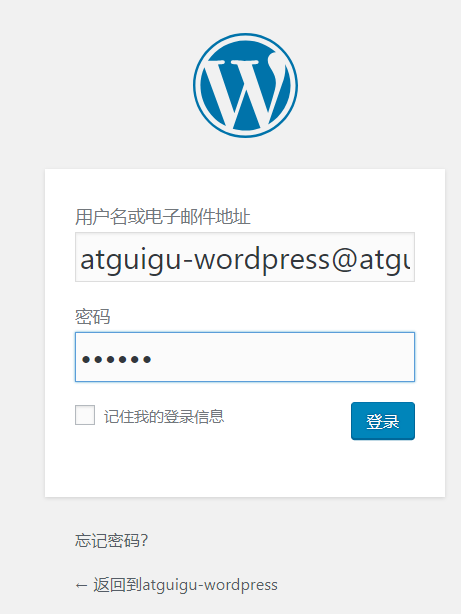
安装完成进行登录
- 用户名 / 电子邮箱地址:wts / atguigu-wordpress@atguigu.com
- 密码:123456
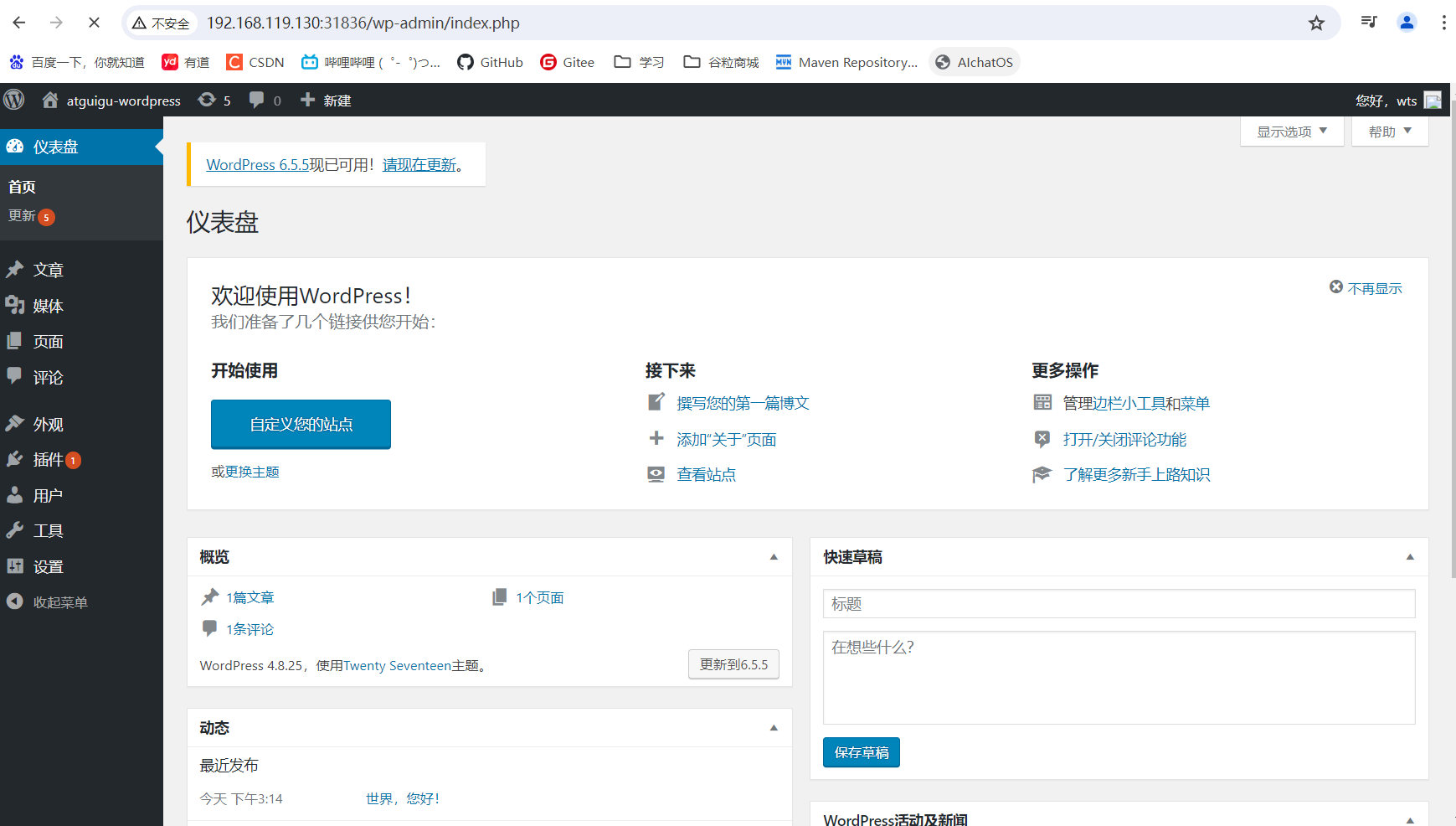
- 登录成功页面
至此,您已经熟悉了如何通过创建一个 KubeSphere 应用的方式,通过快速添加多个组件来完成一个应用的构建,最终发布至 Kubernetes。这种创建应用的形式非常适合微服务的构建,只需要将各个组件容器化以后,即可通过这种方式快速创建一个完整的微服务应用并发布 Kubernetes。
同时,这种方式还支持用户以 无代码侵入的形式开启应用治理,针对 微服务、流量治理、灰度发布与 Tracing 等应用场景,开启应用治理后会在每个组件中以 SideCar 的方式注入 Istio-proxy 容器来接管流量,后续将以一个 Bookinfo 的示例来说明如何在创建应用中使用应用治理。
4.5.5、应用部署的时候,工作负载状态一直更新中,查看日志发现有报错
journalctl -u kubelet -n 100
6月 30 10:33:17 k8s-node1 kubelet[626]: E0630 10:33:17.078664 626 summary_sys_containers.go:47] Failed to get system container stats for "/system.slice/docker.service": failed to get cgroup stats for "/system.s
lice/docker.service": failed to get container info for "/system.slice/docker.service": unknown container "/system.slice/docker.service"
6月 30 10:33:22 k8s-node1 kubelet[626]: E0630 10:33:22.207119 626 pod_workers.go:191] Error syncing pod 6bc8a4d3-fab3-4938-a54d-36fb15f9c864 ("alerting-client-685d4d47fc-7gkjg_kubesphere-alerting-system(6bc8a4d
3-fab3-4938-a54d-36fb15f9c864)"), skipping: failed to "StartContainer" for "alerting-client" with CrashLoopBackOff: "back-off 5m0s restarting failed container=alerting-client pod=alerting-client-685d4d47fc-7gkjg_ku
besphere-alerting-system(6bc8a4d3-fab3-4938-a54d-36fb15f9c864)"
6月 30 10:33:23 k8s-node1 kubelet[626]: E0630 10:33:23.208725 626 pod_workers.go:191] Error syncing pod 815f19d1-da0d-467f-a16b-79193ccbae39 ("kube-flannel-ds-lqhbw_kube-flannel(815f19d1-da0d-467f-a16b-79193ccb
ae39)"), skipping: failed to "StartContainer" for "install-cni-plugin" with ImagePullBackOff: "Back-off pulling image \"docker.io/flannel/flannel-cni-plugin:v1.4.1-flannel1\""
6月 30 10:33:26 k8s-node1 kubelet[626]: E0630 10:33:26.207183 626 pod_workers.go:191] Error syncing pod e5168039-6100-41a4-bba2-55fc0d856abf ("ks-sonarqube-sonarqube-f68dd5ff5-bl9fk_kubesphere-devops-system(e51
68039-6100-41a4-bba2-55fc0d856abf)"), skipping: failed to "StartContainer" for "sonarqube" with CrashLoopBackOff: "back-off 5m0s restarting failed container=sonarqube pod=ks-sonarqube-sonarqube-f68dd5ff5-bl9fk_kube
sphere-devops-system(e5168039-6100-41a4-bba2-55fc0d856abf)"
解决办法
vi /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf

修改kubelet配置文件,在/etc/systemd/system/kubelet.service.d/10-kubeadm.conf文件中增加环境配置:
Environment="KUBELET_CGROUP_ARGS=--runtime-cgroups=/systemd/system.slice --kubelet-cgroups=/systemd/system.slice"
并在启动命令尾部添加变量 $KUBELET_CGROUP_ARGS如下:
ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_CGROUP_ARGS
重启 kubelet 服务,让 kubelet 重新加载配置。
systemctl daemon-reload
systemctl restart kubelet
四、DevOps
1、项目开发需要考虑的维度
Dev:怎么开发?
Ops:怎么运维?
高并发:怎么承担高并发
高可用:怎么做到高可用
2、什么是 DevOps
微服务,服务自治。
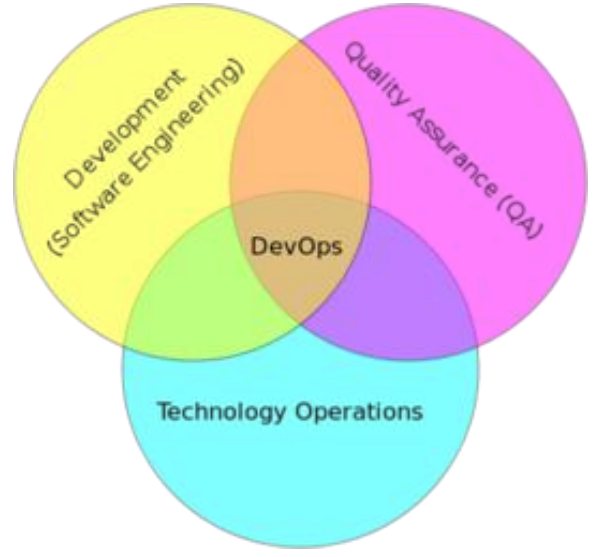
DevOps: Development 和 Operations 的组合
- DevOps 看作开发(软件工程)、技术运营和质量保障(QA)三者的交集。
- 突出重视软件开发人员和运维人员的沟通合作,通过自动化流程来使得软件构建、测试、
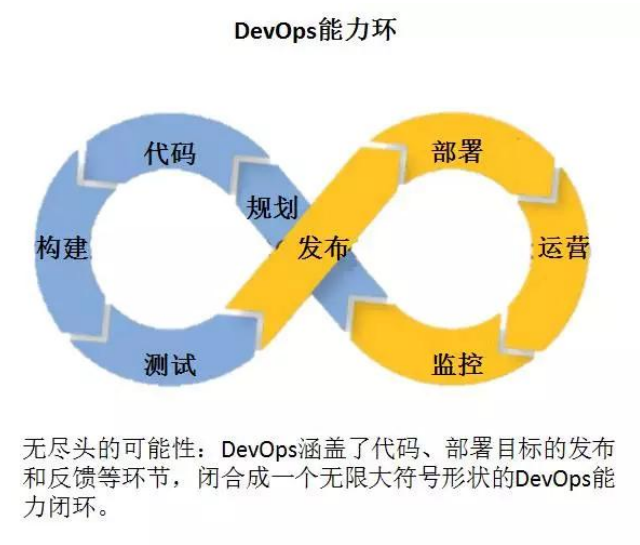
发布更加快捷、频繁和可靠。 - DevOps 希望做到的是软件产品交付过程中 IT 工具链的打通,使得各个团队减少时间损
耗,更加高效地协同工作。专家们总结出了下面这个 DevOps 能力图,良好的闭环可以大大
增加整体的产出。
3、什么是 CI&CD
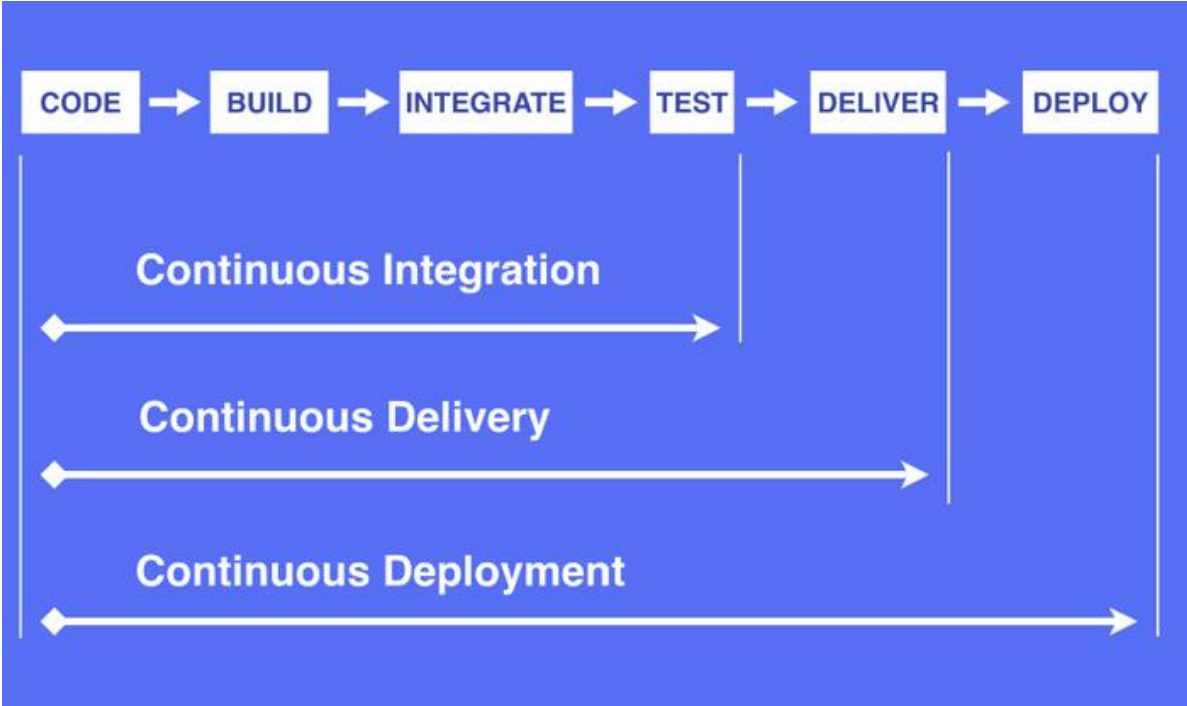
3.1、持续集成(Continuous Integration)
- 持续集成是指软件个人研发的部分向软件整体部分交付,频繁进行集成以便更快地发现其中的错误。“持续集成”源自于极限编程(XP),是 XP 最初的 12 种实践之一。
- CI 需要具备这些:
- 全面的自动化测试。这是实践持续集成&持续部署的基础,同时,选择合适的
自动化测试工具也极其重要; - 灵活的基础设施。容器,虚拟机的存在让开发人员和 QA 人员不必再大费周折;
- 版本控制工具。如 Git,CVS,SVN 等;
- 自动化的构建和软件发布流程的工具。如
Jenkins,flow.ci; - 反馈机制。如构建/测试的失败,可以快速地反馈到相关负责人,以尽快解决达到一个更稳定的版本。
- 全面的自动化测试。这是实践持续集成&持续部署的基础,同时,选择合适的
3.2、持续交付(Continuous Delivery)
持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」
(production-like environments)中。持续交付优先于整个产品生命周期的软件部署,建立在高水平自动化持续集成之上。
灰度发布。
持续交付和持续集成的优点非常相似:
- 快速发布。能够应对业务需求,并更快地实现软件价值。
- 编码->测试->上线->交付的频繁迭代周期缩短,同时获得迅速反馈;
- 高质量的软件发布标准。整个交付过程标准化、可重复、可靠,
- 整个交付过程进度可视化,方便团队人员了解项目成熟度;
- 更先进的团队协作方式。从需求分析、产品的用户体验到交互 设计、开发、测试、运维等角色密切协作,相比于传统的瀑布式软件团队,更少浪费。
3.3、持续部署(Continuous Deployment)
持续部署是指当交付的代码通过评审之后,自动部署到生产环境中。持续部署是持续交付的最高阶段。这意味着,所有通过了一系列的自动化测试的改动都将自动部署到生产环境。它也可以被称为“Continuous Release”。
“开发人员提交代码,持续集成服务器获取代码,执行单元测试,根据测试结果决定是否部署到预演环境,如果成功部署到预演环境,进行整体验收测试,如果测试通过,自动部署到产品环境,全程自动化高效运转。“
持续部署主要好处是,可以相对独立地部署新的功能,并能快速地收集真实用户的反馈。
“You build it, you run it”,这是 Amazon 一年可以完成 5000 万次部署,
平均每个工程师每天部署超过 50 次的核心秘籍。
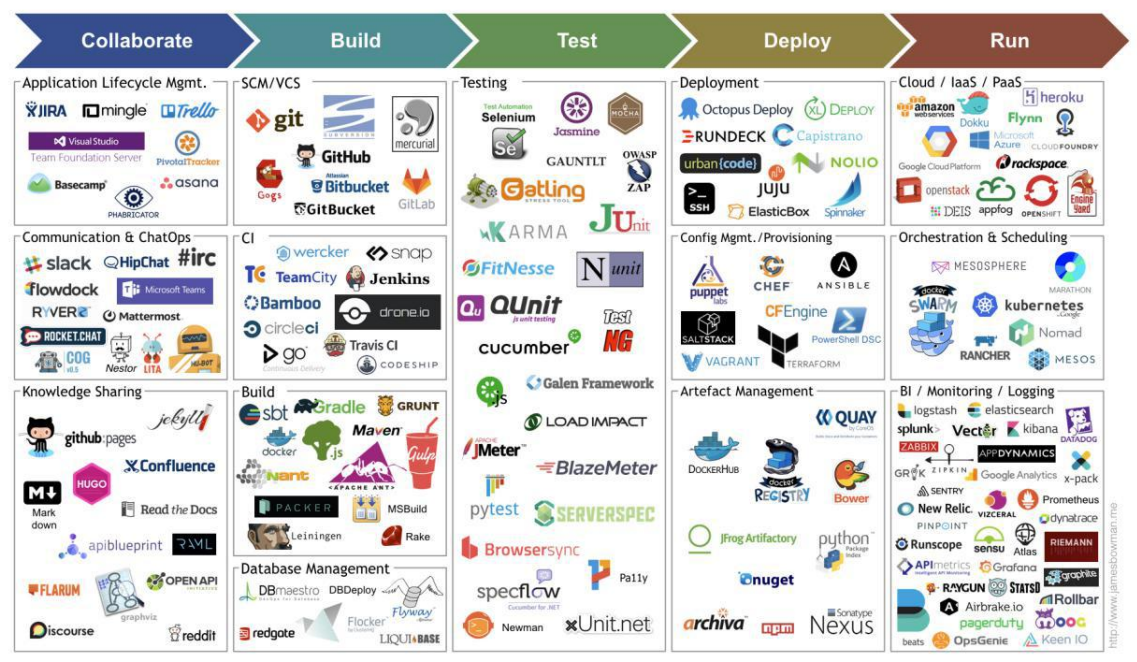
下图是由 Jams Bowman 绘制的持续交付工具链图
4、落地方案
Maven+Github+Jenkins(Hudson[现由甲骨文维护])+Docker
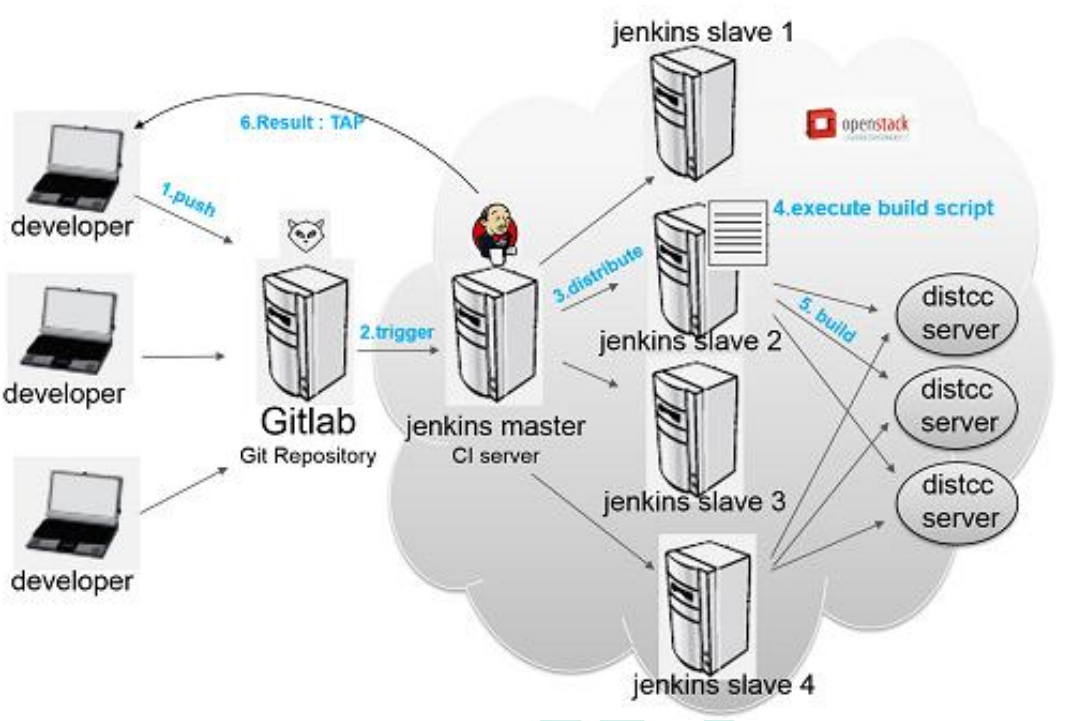
自动化部署
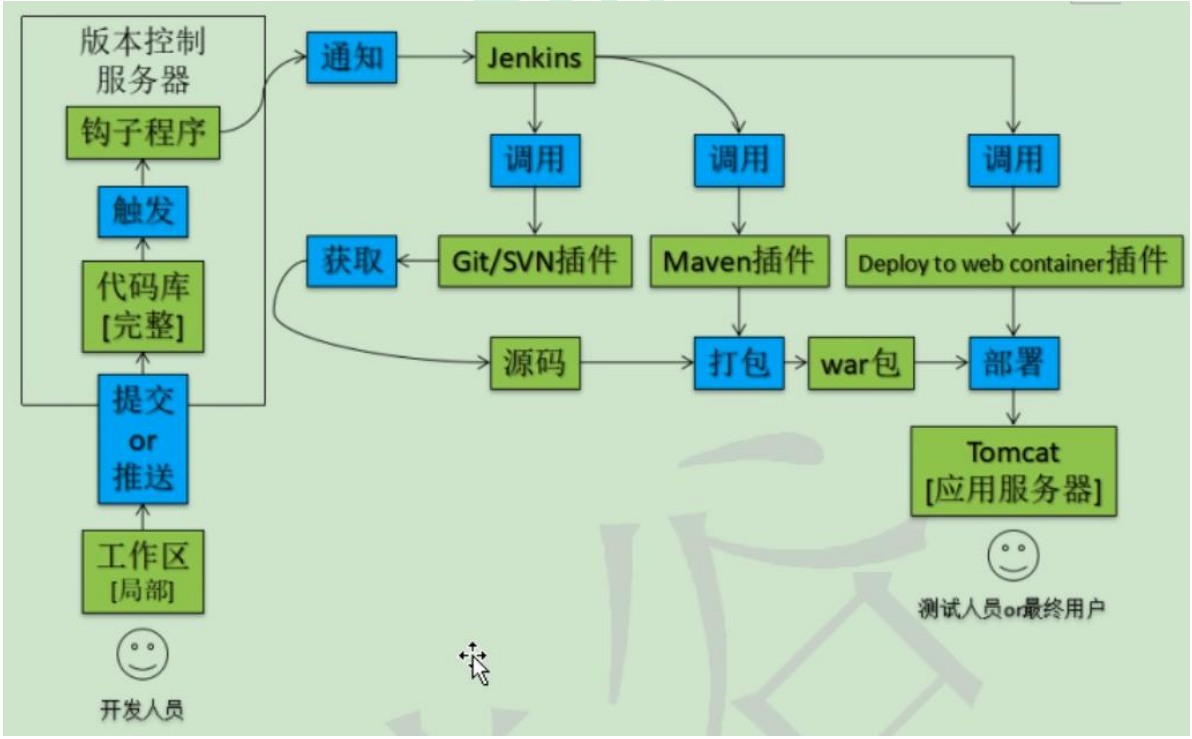
5、基于Spring Boot项目构建流水线
https://v2-1.docs.kubesphere.io/docs/zh-CN/quick-start/devops-online/
Jenkinsfile in SCM 意为将 Jenkinsfile 文件本身作为源代码管理 (Source Control Management) 的一部分,根据该文件内的流水线配置信息快速构建工程内的 CI/CD 功能模块,比如阶段 (Stage),步骤 (Step) 和任务 (Job)。因此,在代码仓库中应包含 Jenkinsfile。
5.1、目的
本示例演示如何通过 GitHub 仓库中的 Jenkinsfile 来创建流水线,流水线共包括 8 个阶段,最终将演示示例部署到 KubeSphere 集群中的开发环境和生产环境且能够通过公网访问。 仓库中的 dependency 分支为缓存测试用例,测试方式与 master 分支类似,对 dependency 的多次构建可体现出利用缓存可以有效的提升构建速度。
5.2、前提条件
- 开启安装了 DevOps 功能组件,参考 安装 DevOps 系统;
- 本示例以 GitHub 和 DockerHub 为例,参考前确保已创建了 GitHub 和 DockerHub 账号;
已创建了企业空间和 DevOps 工程并且创建了项目普通用户 project-regular 的账号,若还未创建请参考 多租户管理快速入门; - 使用项目管理员
project-admin邀请项目普通用户project-regular加入 DevOps 工程并授予maintainer角色,若还未邀请请参考 多租户管理快速入门 - 邀请成员。 - 参考 配置 ci 节点为流水线选择执行构建的节点。
5.3、流水线概览
下面的流程图简单说明了流水线完整的工作过程:
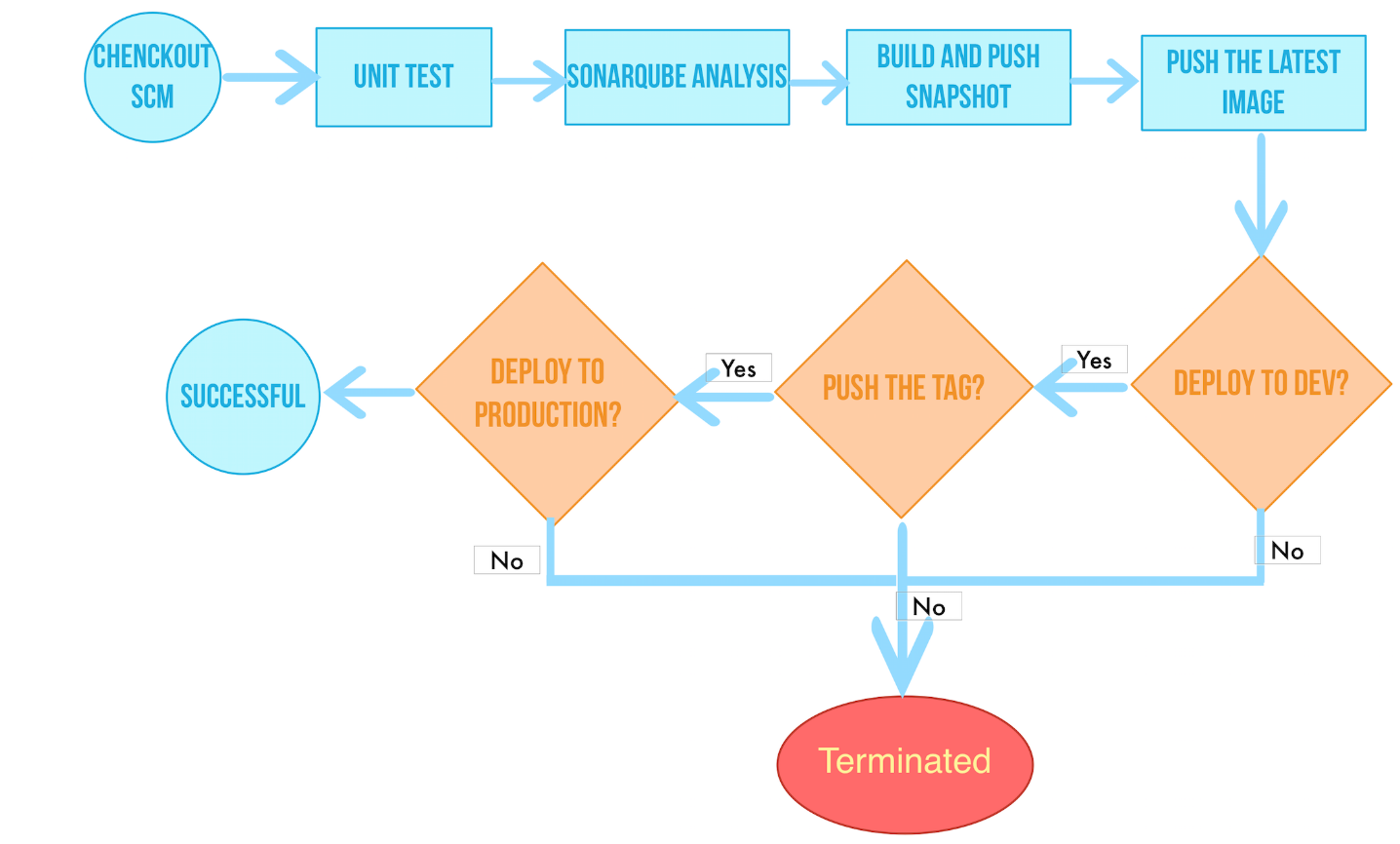
流程说明:
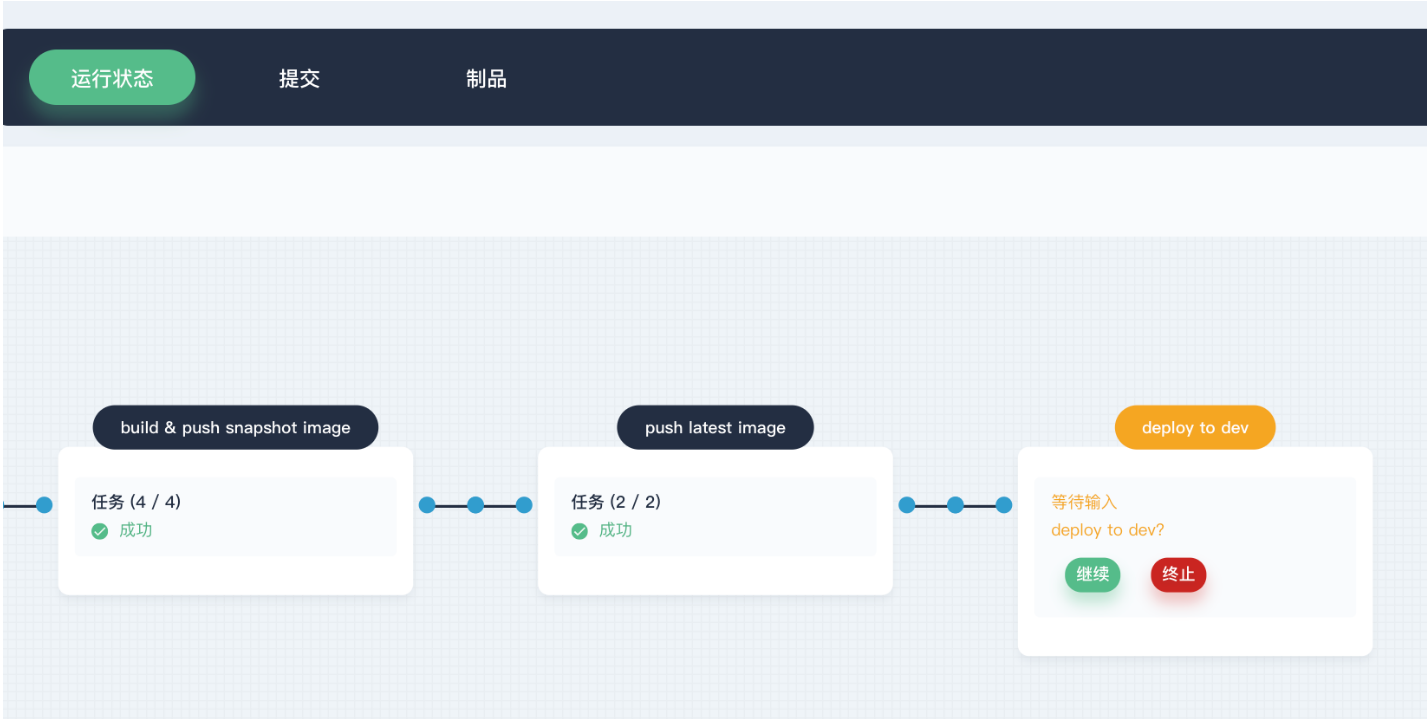
- 阶段一. Checkout SCM: 拉取 GitHub 仓库代码
- 阶段二. Unit test: 单元测试,如果测试通过了才继续下面的任务
- 阶段三. SonarQube analysis:sonarQube 代码质量检测
- 阶段四. Build & push snapshot image: 根据行为策略中所选择分支来构建镜像,并将 tag 为 SNAPSHOT- B R A N C H N A M E − BRANCH_NAME- BRANCHNAME−BUILD_NUMBER推送至 Harbor (其中 $BUILD_NUMBER为
pipeline 活动列表的运行序号)。- 阶段五. Push latest image: 将 master 分支打上 tag 为 latest,并推送至 DockerHub。
- 阶段六. Deploy to dev: 将 master 分支部署到 Dev 环境,此阶段需要审核。
- 阶段七. Push with tag: 生成 tag 并 release 到 GitHub,并推送到 DockerHub。
- 阶段八. Deploy to production: 将发布的 tag 部署到 Production 环境。
5.4、创建凭证
注意:
- GitHub 账号或密码带有 “@” 这类特殊字符,需要创建凭证前对其进行 urlencode 编码,可通过一些 第三方网站 进行转换,然后再将转换后的结果粘贴到对应的凭证信息中。
- 这里需要创建的是凭证(Credential),不是密钥(Secret)。
在 多租户管理快速入门 中已给项目普通用户 project-regular 授予了 maintainer 的角色,因此使用 project-regular 登录 KubeSphere,进入已创建的 devops-demo 工程,开始创建凭证。
1、本示例代码仓库中的 Jenkinsfile 需要用到 DockerHub、GitHub 和 kubeconfig (kubeconfig 用于访问接入正在运行的 Kubernetes 集群) 等一共 3 个凭证 (credentials) ,参考 创建凭证依次创建这三个凭证。
2、然后参考 访问 SonarQube 并创建 Token,创建一个 Java 的 Token 并复制。
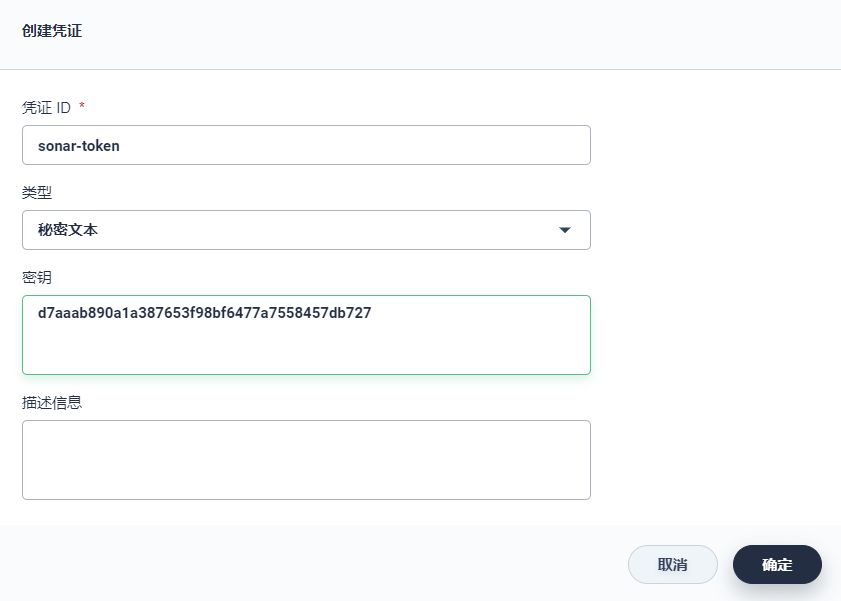
3、最后在 KubeSphere 中进入 gulimall-devops的 DevOps 工程中,与上面步骤类似,在 凭证 下点击 创建,创建一个类型为 秘密文本的凭证,凭证 ID 命名为 sonar-token,密钥为上一步复制的 token 信息,完成后点击 确定。
-
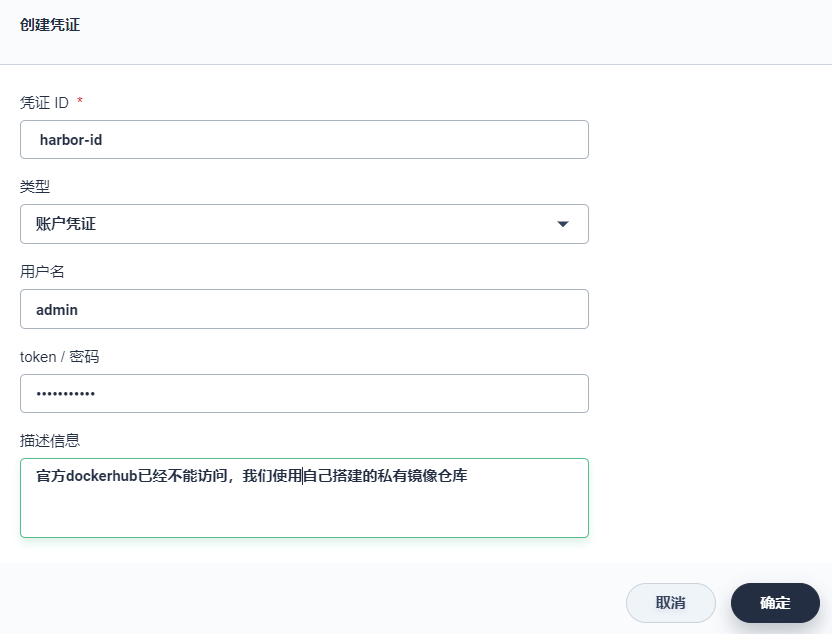
创建 Harbor 凭证
创建一个用于 内置 Harbor 登录的凭证,此处命名为 harbor-id,类型选择 账户凭证。用户名和密码填写 admin 和 Harbor12345,完成后点击 确定。
-
创建 GitHub 凭证
同上,创建一个用于 GitHub 的凭证,凭证 ID 可命名为 github-id,类型选择 账户凭证,输入您个人的 GitHub 用户名和密码,备注描述信息,完成后点击 确定。注意:github 的认证策略发生了改变,在 2021年8月13日的时候,用户名加密码的认证方式被去掉了,换成了 个人令牌(Personal Access Token)的校验方式。所以我们这里使用token
创建token的具体操作步骤可以参考文档:https://blog.csdn.net/liuzehn/article/details/128037853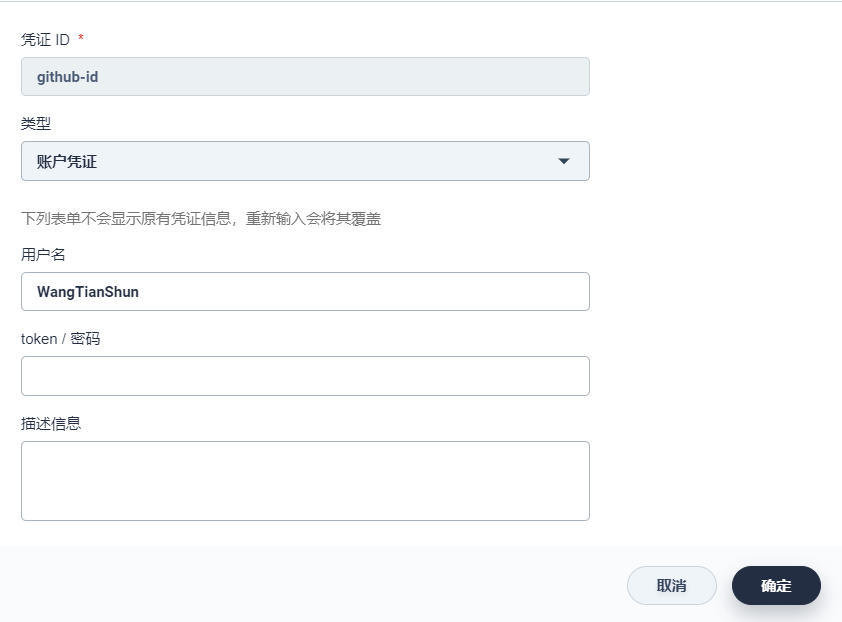
-
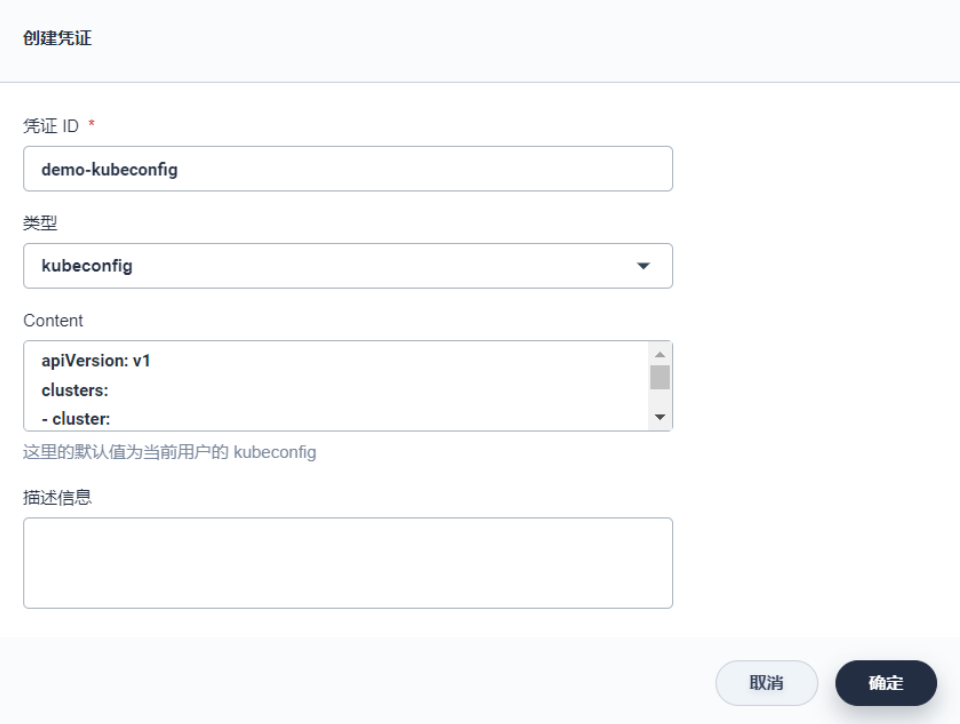
创建 kubeconfig 凭证
在 凭证 下点击 创建,创建一个类型为kubeconfig的凭证,凭证 ID 可命名为demo-kubeconfig,完成后点击 确定。说明:kubeconfig 类型的凭证用于访问接入正在运行的 Kubernetes 集群,在流水线部署步骤将用到该凭证。注意,此处的 Content 将自动获取当前 KubeSphere 中的 kubeconfig 文件内容,若部署至当前 KubeSphere 中则无需修改,若部署至其它 Kubernetes 集群,则需要将其 kubeconfig 文件的内容粘贴至 Content 中。
-
访问 SonarQube 并创建 Token,创建一个 Java 的 Token 并复制
我们显示通过kubectl get svc --all-namespaces命令,找到SonarQube服务,可以看到端口信息kubectl get svc --all-namespaces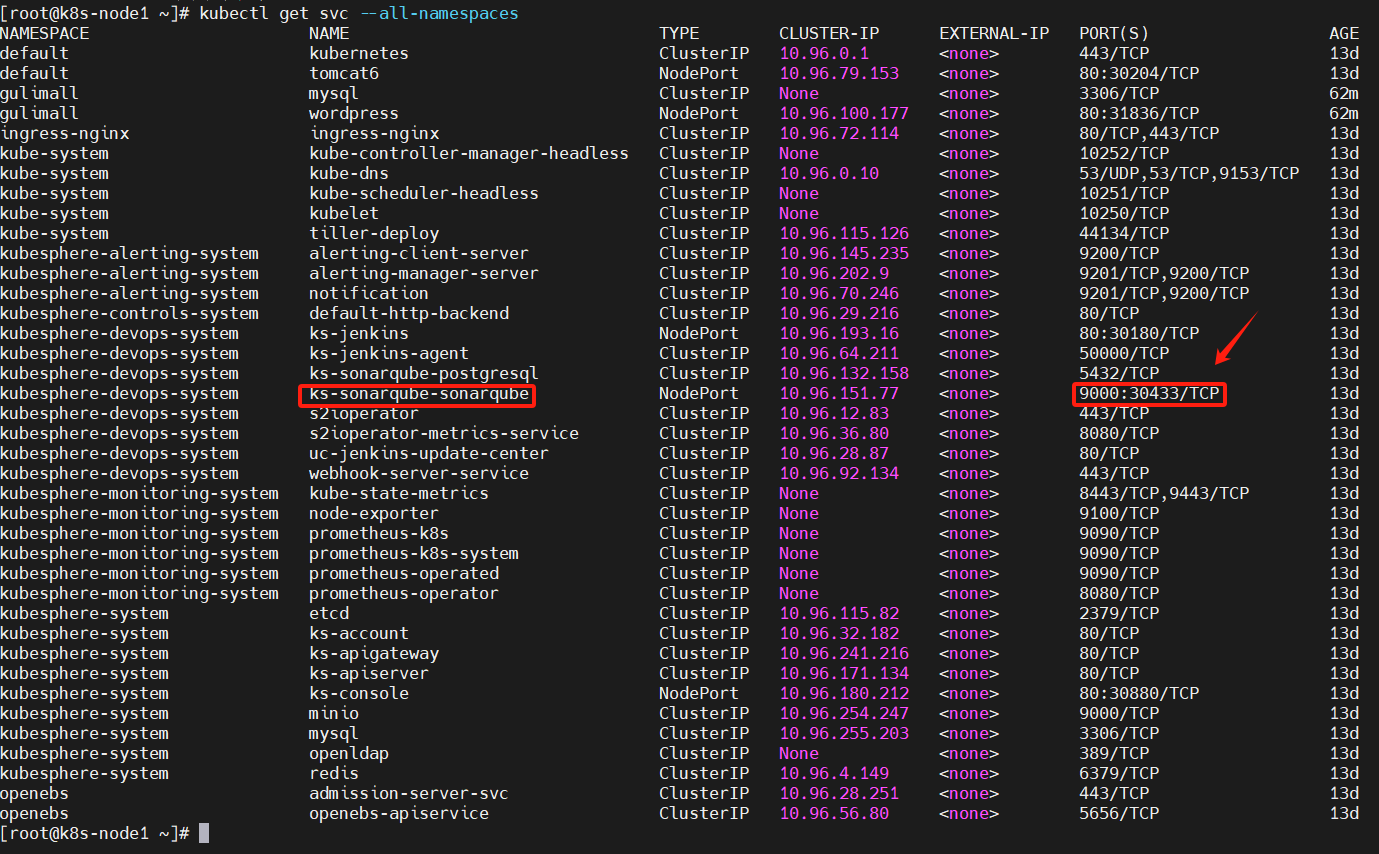
访问地址:http://192.168.119.130:30433/
账号:admin
密码:admin
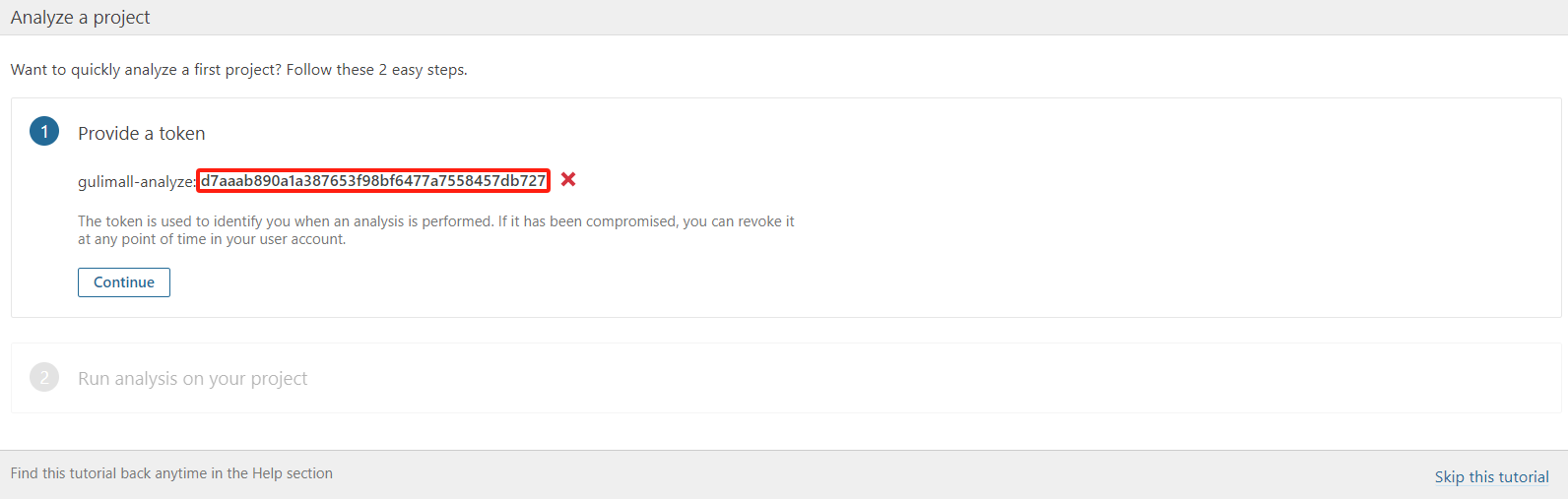
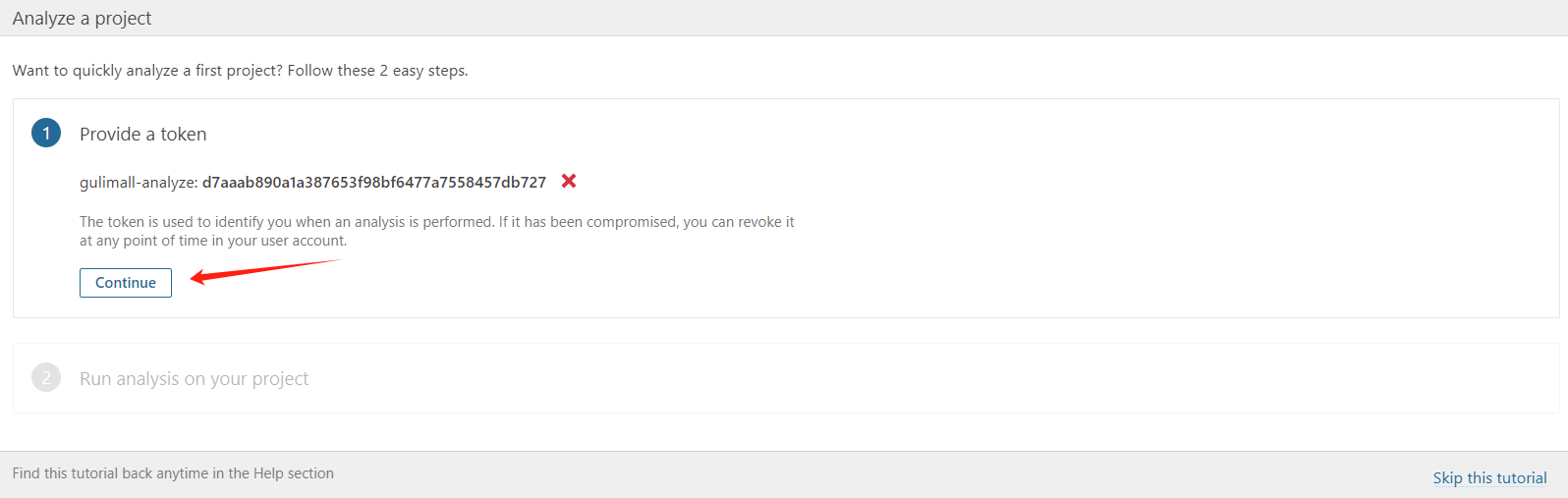
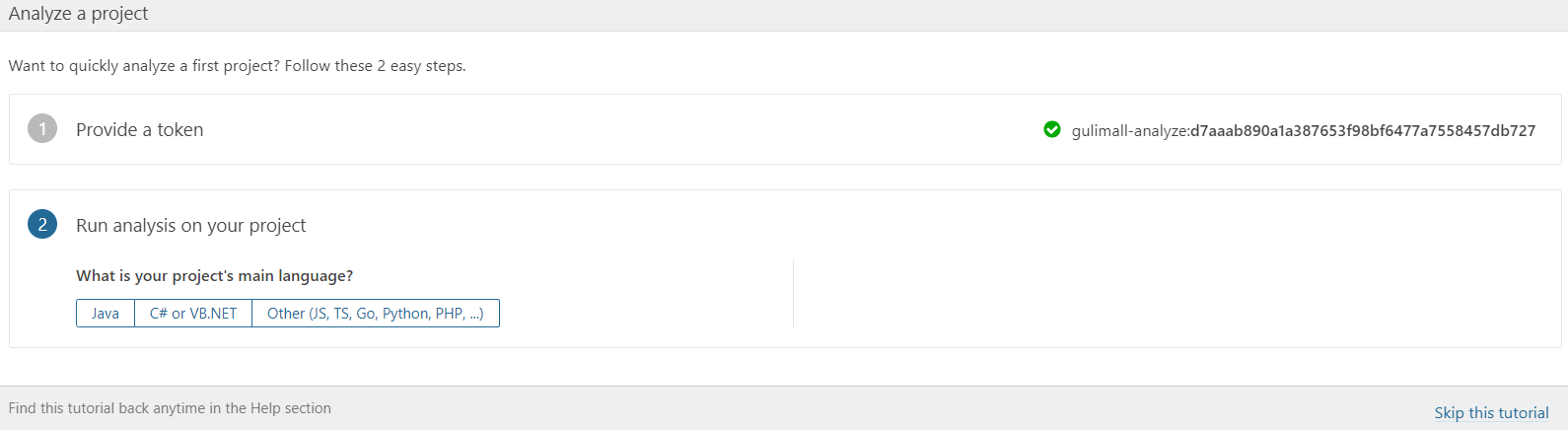
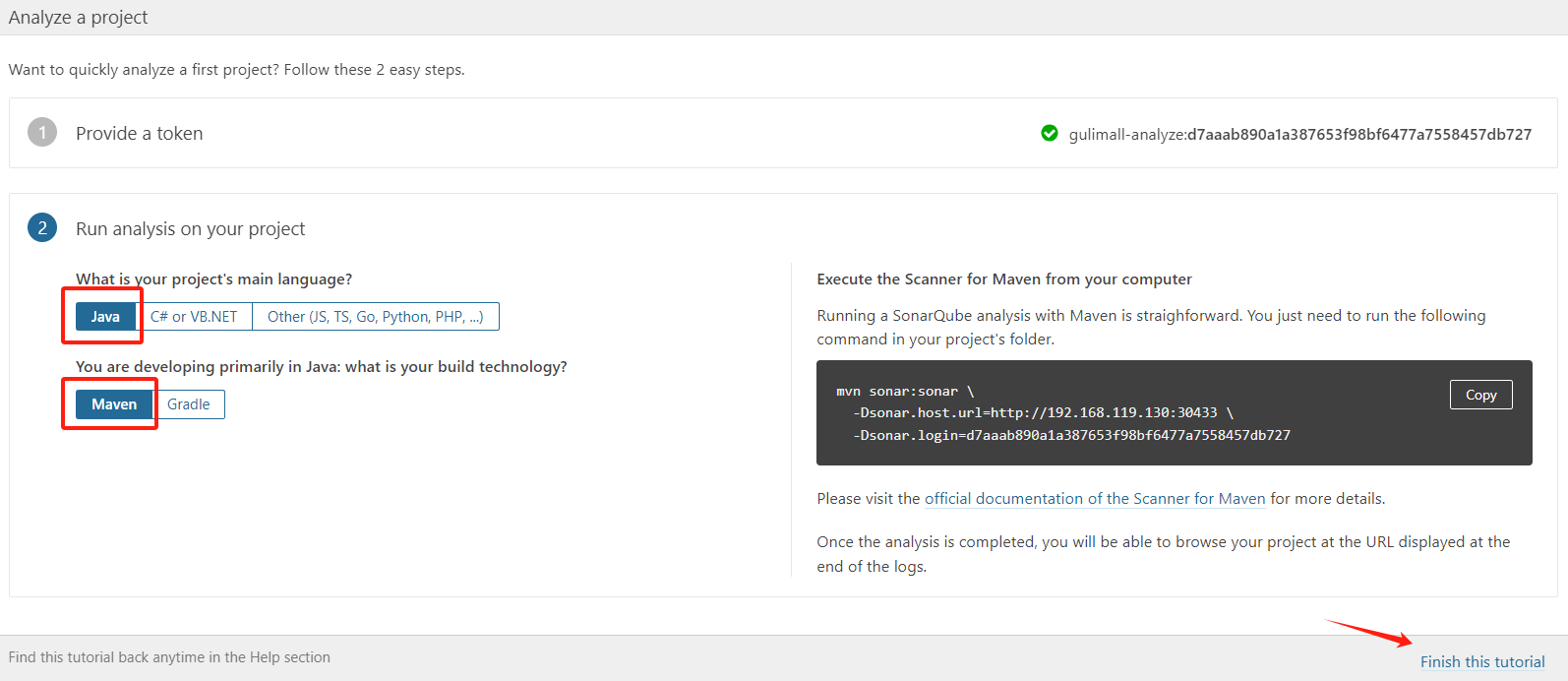
d7aaab890a1a387653f98bf6477a7558457db727创建 SonarQube Token
5.5、修改 Jenkinsfile
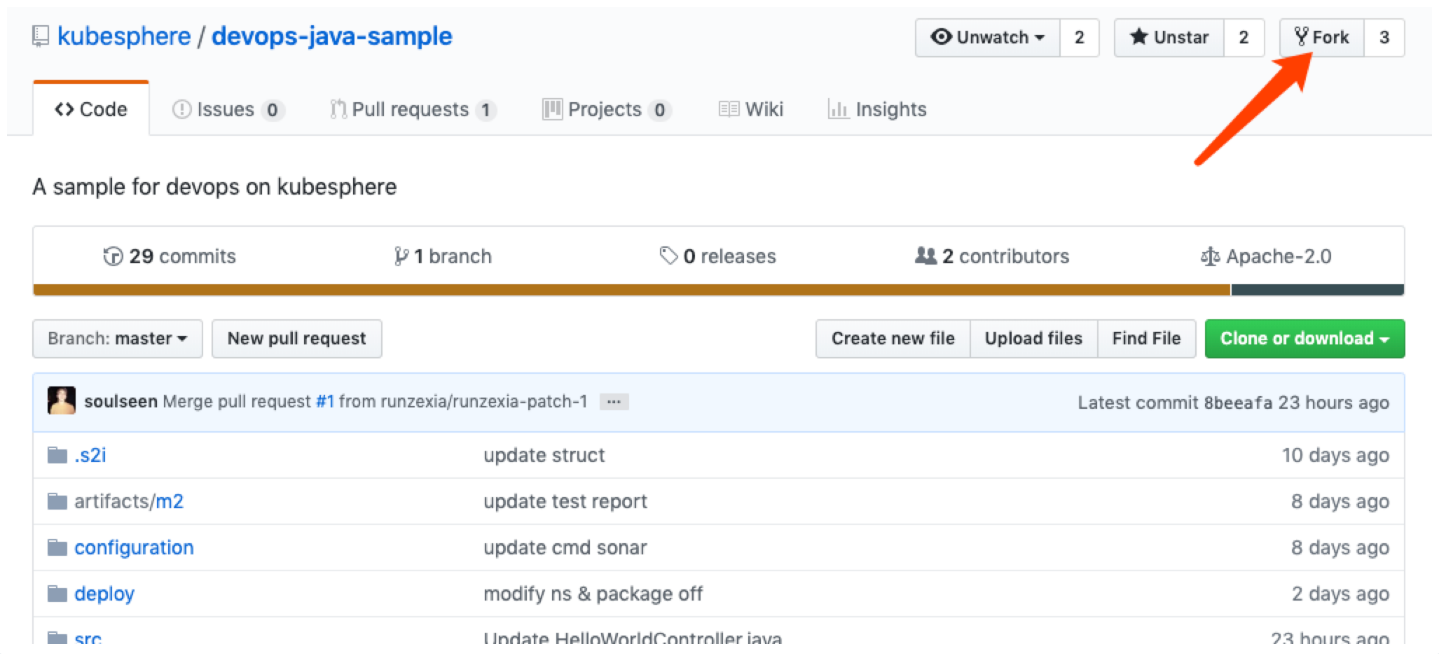
5.5.1、第一步:Fork项目
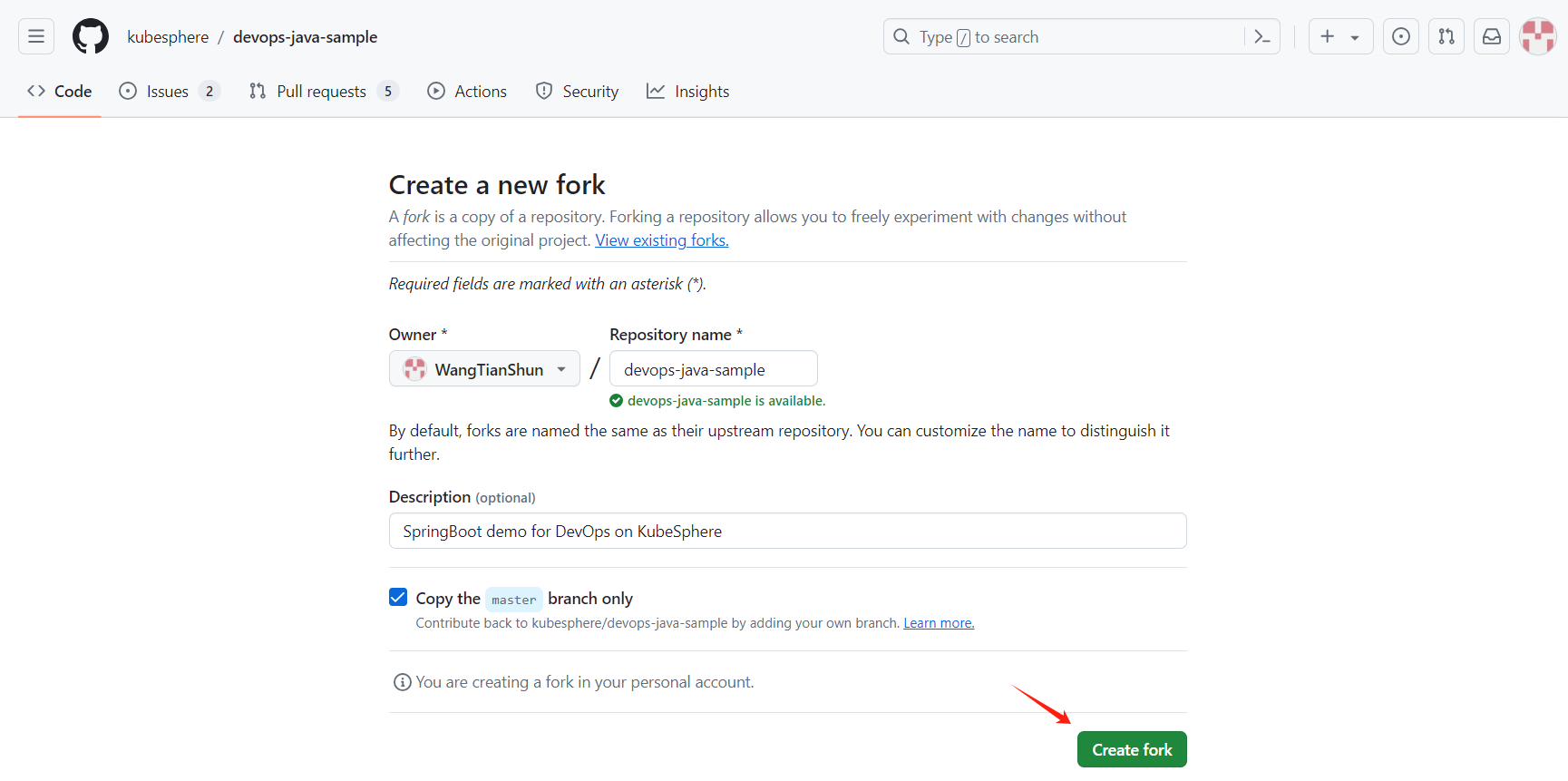
登录 GitHub,将本示例用到的 GitHub 仓库 devops-java-sample Fork 至您个人的 GitHub。
5.5.2、第二步:修改 Jenkinsfile
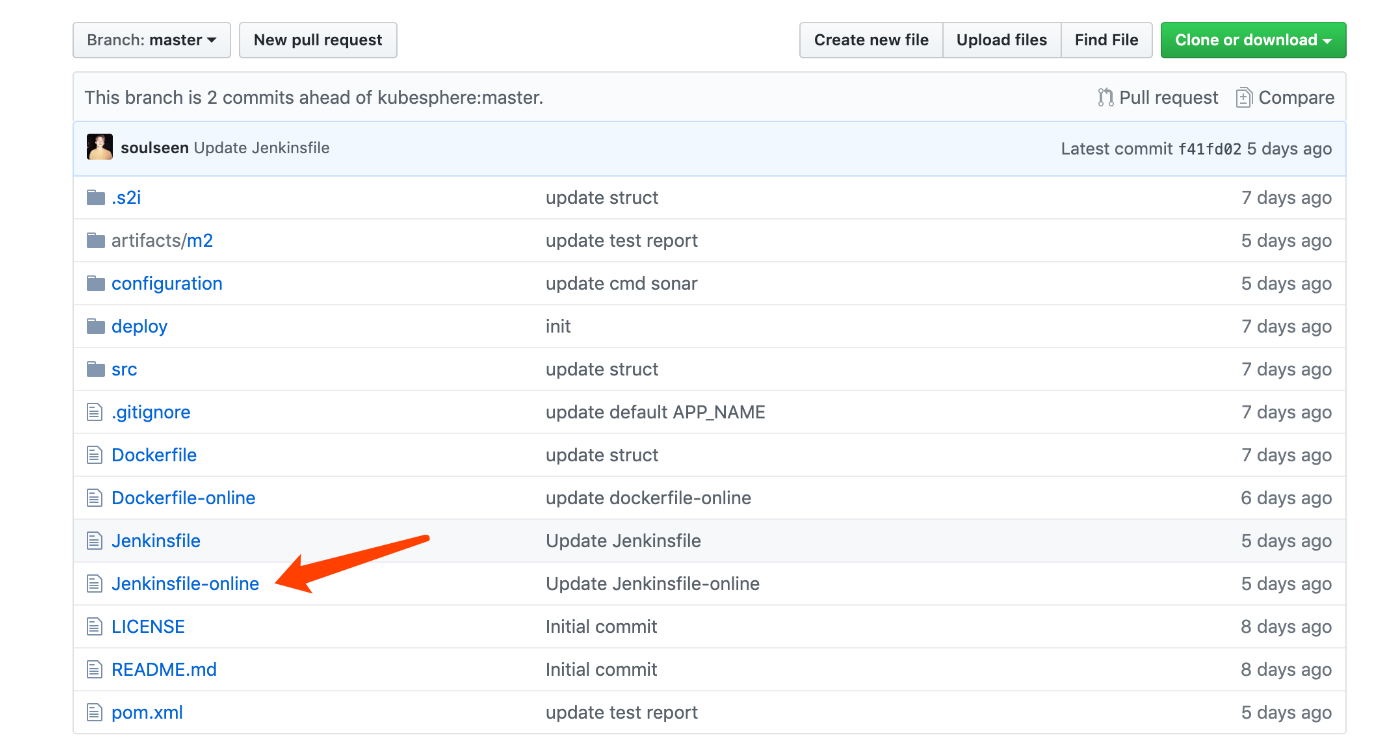
1、Fork 至您个人的 GitHub 后,在 根目录 进入 Jenkinsfile-online。
2、在 GitHub UI 点击编辑图标,需要修改如下环境变量 (environment) 的值。
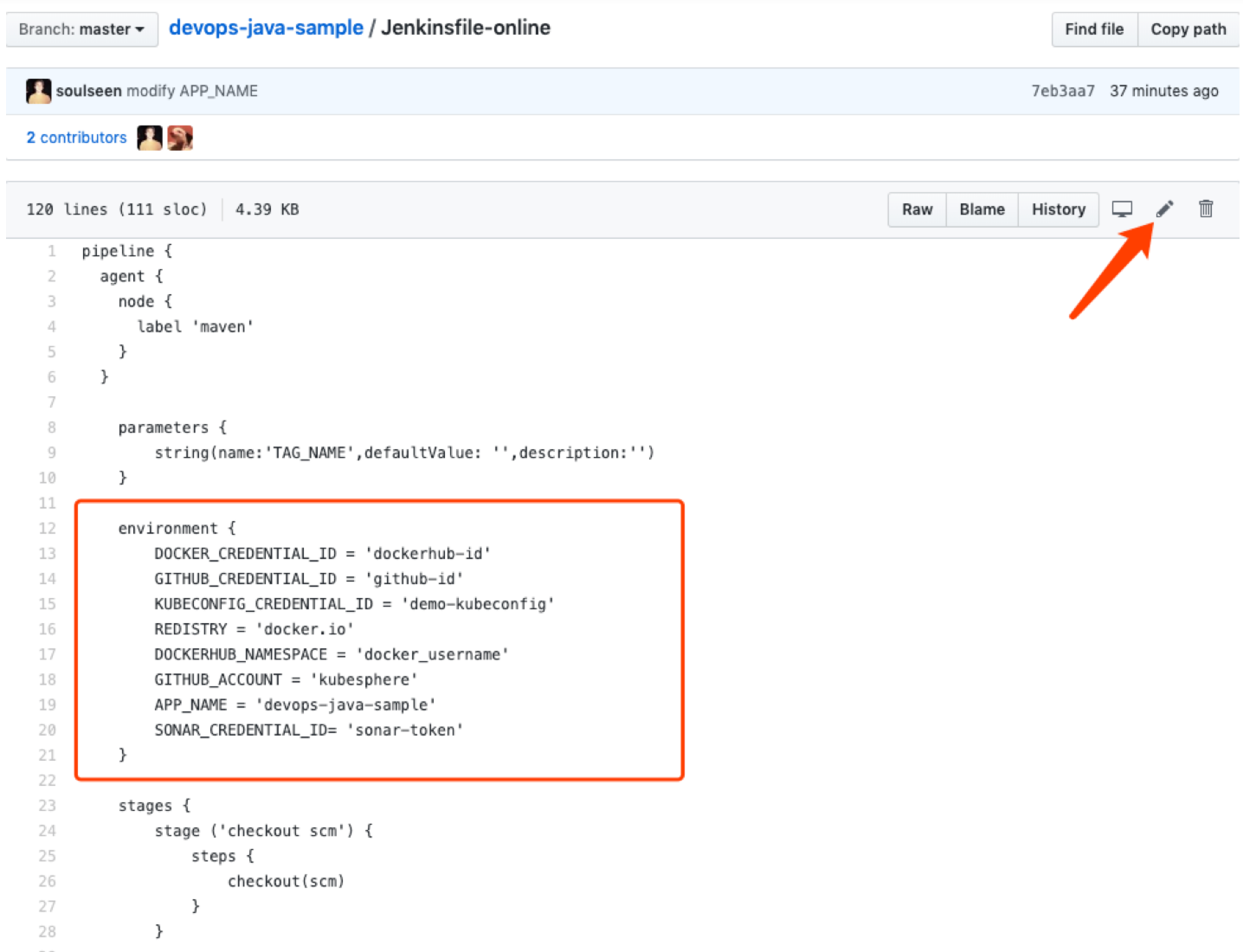
| 修改项 | 值 | 含义 |
|---|---|---|
| DOCKER_CREDENTIAL_ID | dockerhub-id | 填写创建凭证步骤中的 DockerHub 凭证 ID,用于登录您的 DockerHub |
| GITHUB_CREDENTIAL_ID | github-id | 填写创建凭证步骤中的 GitHub 凭证 ID,用于推送 tag 到 GitHub 仓库 |
| KUBECONFIG_CREDENTIAL_ID | demo-kubeconfig | kubeconfig 凭证 ID,用于访问接入正在运行的 Kubernetes 集群 |
| REGISTRY | docker.io | 默认为 docker.io 域名,用于镜像的推送 |
| DOCKERHUB_NAMESPACE | your-dockerhub-account | 替换为您的 DockerHub 账号名(它也可以是账户下的 Organization 名称) |
| GITHUB_ACCOUNT | your-github-account | 替换为您的 GitHub 账号名,例如 https://github.com/kubesphere/则填写 kubesphere(它也可以是账户下的 Organization 名称) |
| APP_NAME | devops-java-sample | 应用名称 |
| SONAR_CREDENTIAL_ID | sonar-token | 填写创建凭证步骤中的 SonarQube token凭证 ID,用于代码质量检测 |
修改后的内容
environment {
DOCKER_CREDENTIAL_ID = 'harbor-id'
GITHUB_CREDENTIAL_ID = 'github-id'
KUBECONFIG_CREDENTIAL_ID = 'demo-kubeconfig'
REGISTRY = '192.168.119.133/gulimall/'
DOCKERHUB_NAMESPACE = 'admin'
GITHUB_ACCOUNT = 'WangTianShun'
APP_NAME = 'devops-java-sample'
SONAR_CREDENTIAL_ID = 'sonar-token'
}
注:master分支 Jenkinsfile 中 mvn命令的参数 -o,表示开启离线模式。本示例为适应某些环境下网络的干扰,以及避免在下载依赖时耗时太长,已事先完成相关依赖的下载,默认开启离线模式。
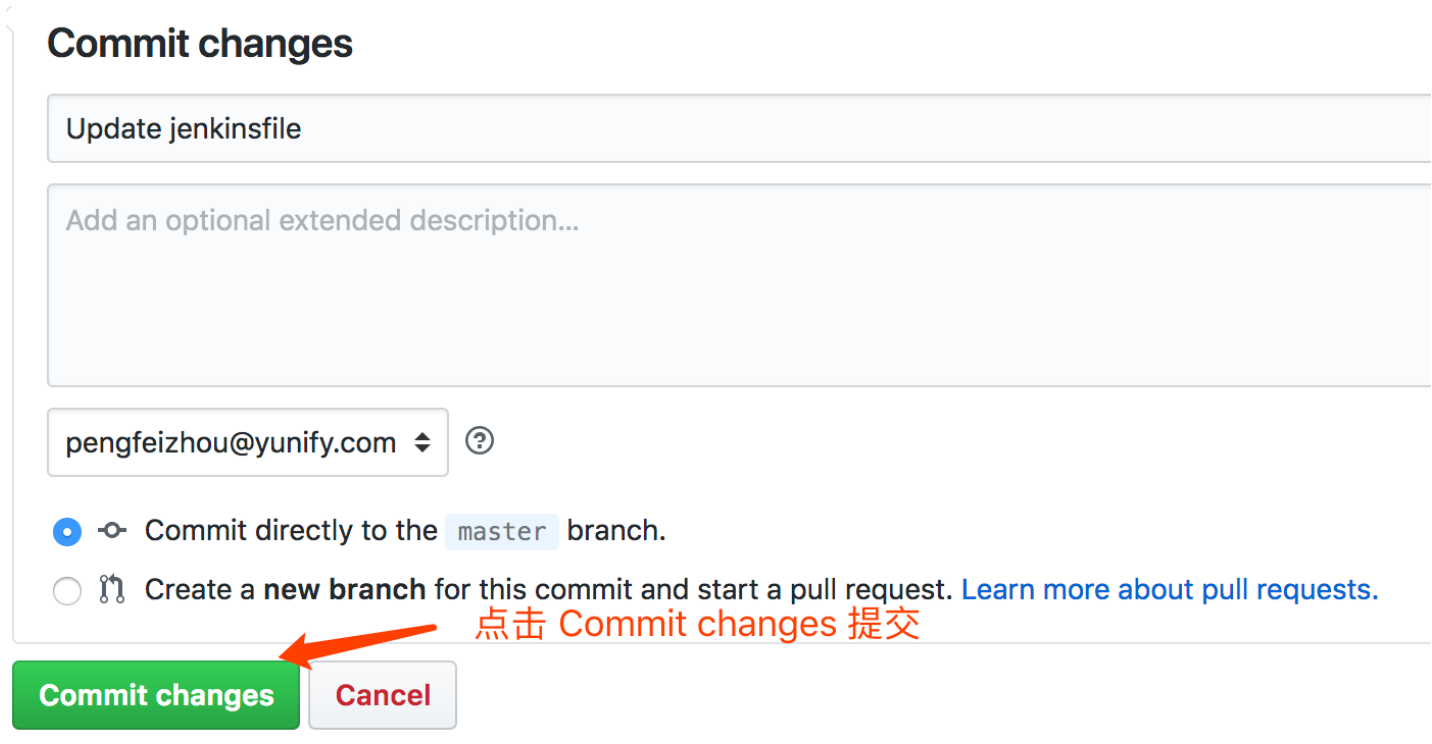
3、修改以上的环境变量后,点击 Commit changes,将更新提交到当前的 master 分支。
5.6、创建项目
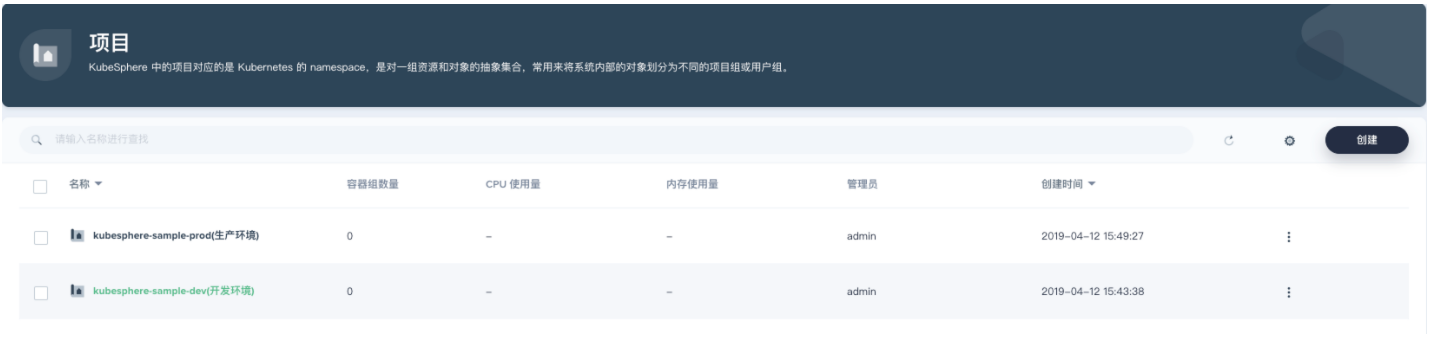
CI/CD 流水线会根据示例项目的 yaml 模板文件,最终将示例分别部署到 kubesphere-sample-dev和 kubesphere-sample-prod这两个项目 (Namespace) 环境中,这两个项目需要预先在控制台依次创建,参考如下步骤创建该项目。
5.6.1、第一步:创建第一个项目
提示:项目管理员 project-admin账号已在 多租户管理快速入门 中创建。
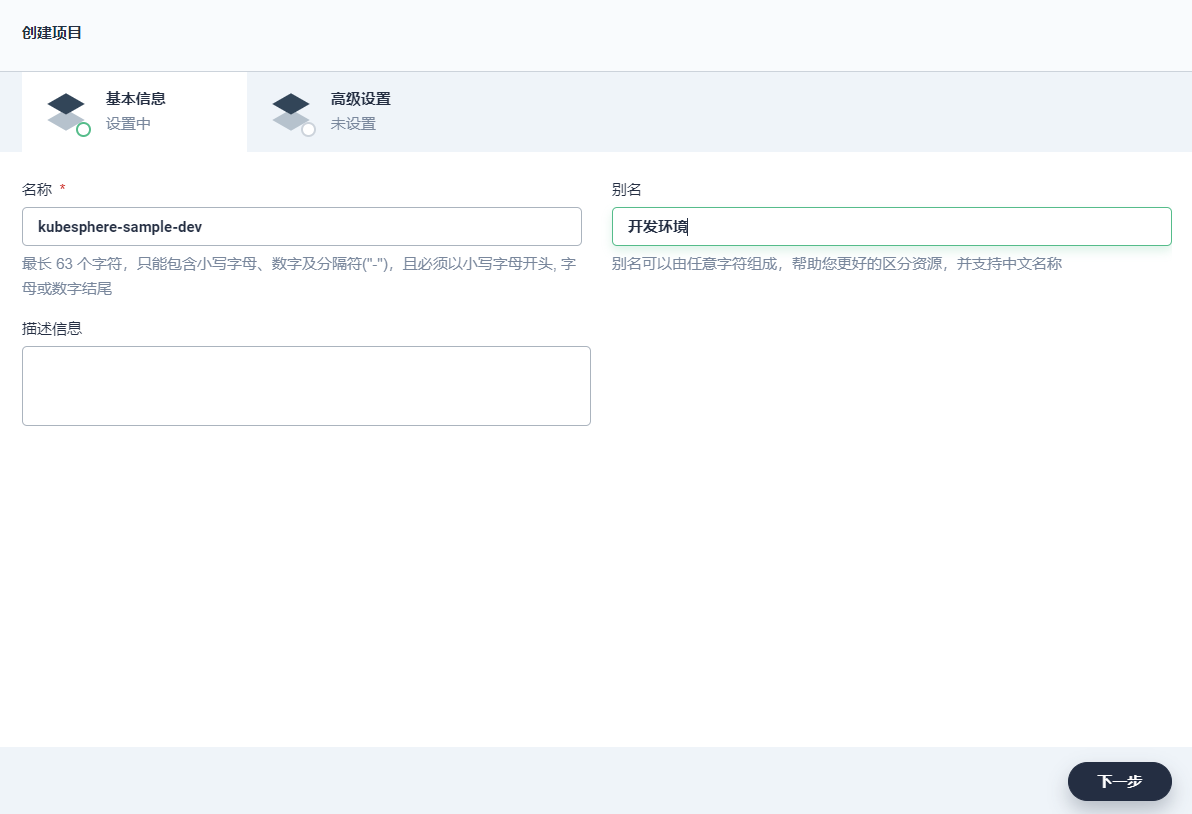
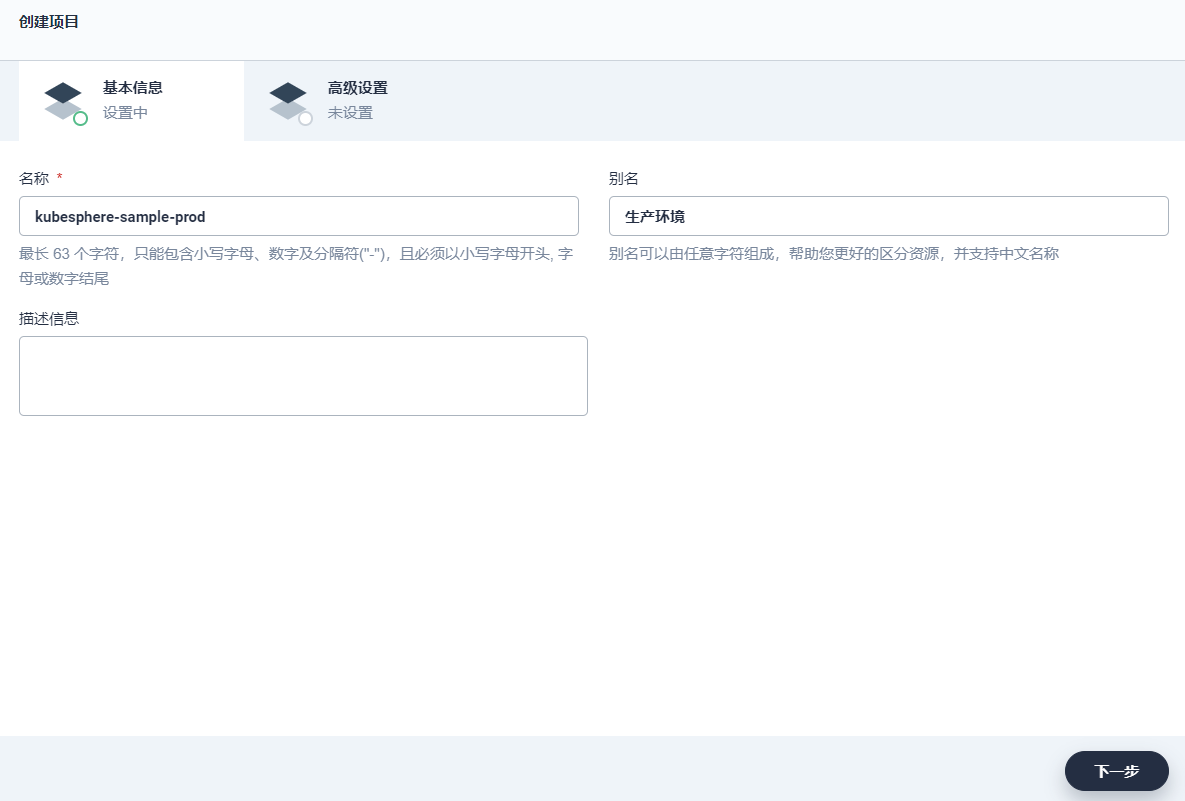
1、使用项目管理员 project-admin账号登录 KubeSphere,在之前创建的企业空间 (gulimall-workspace) 下,点击 项目 → 创建,创建一个 资源型项目,作为本示例的开发环境,填写该项目的基本信息,完成后点击 下一步。
名称:固定为 kubesphere-sample-dev,若需要修改项目名称则需在 yaml 模板文件 中修改 namespace
别名:可自定义,比如 开发环境
描述信息:可简单介绍该项目,方便用户进一步了解
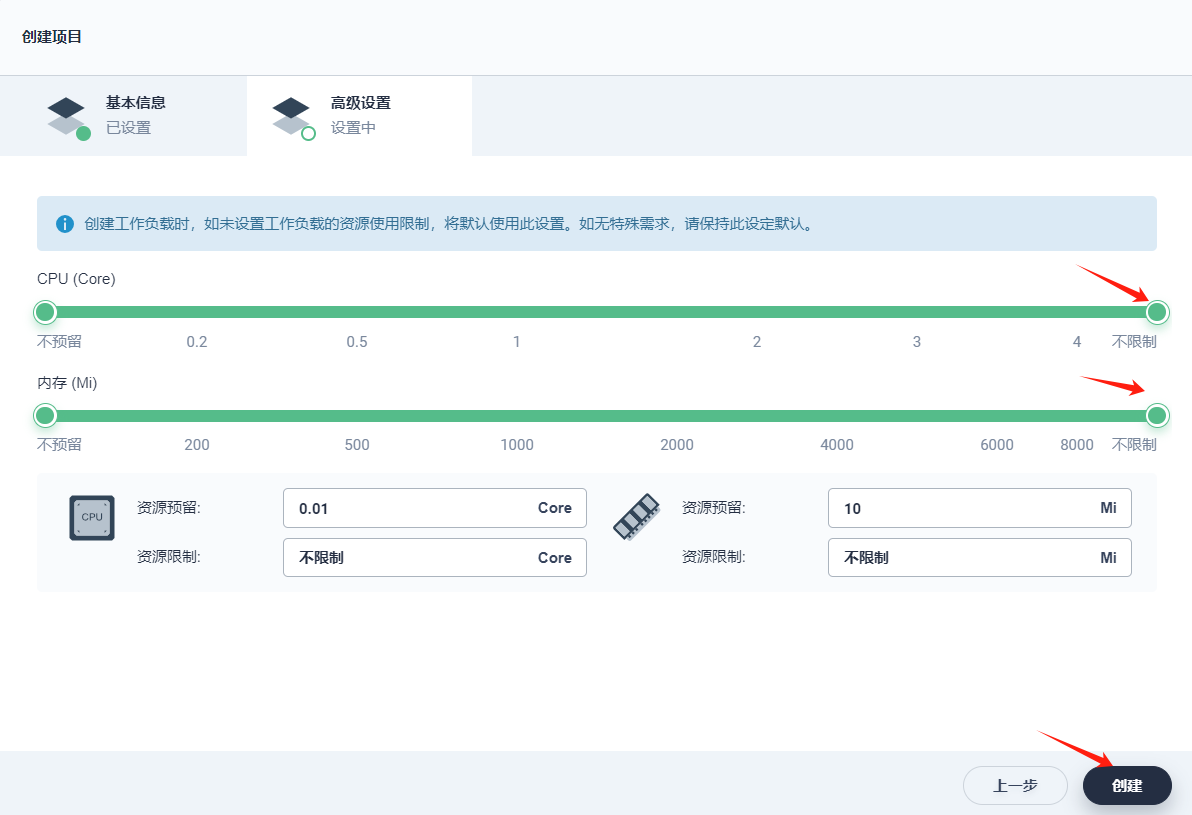
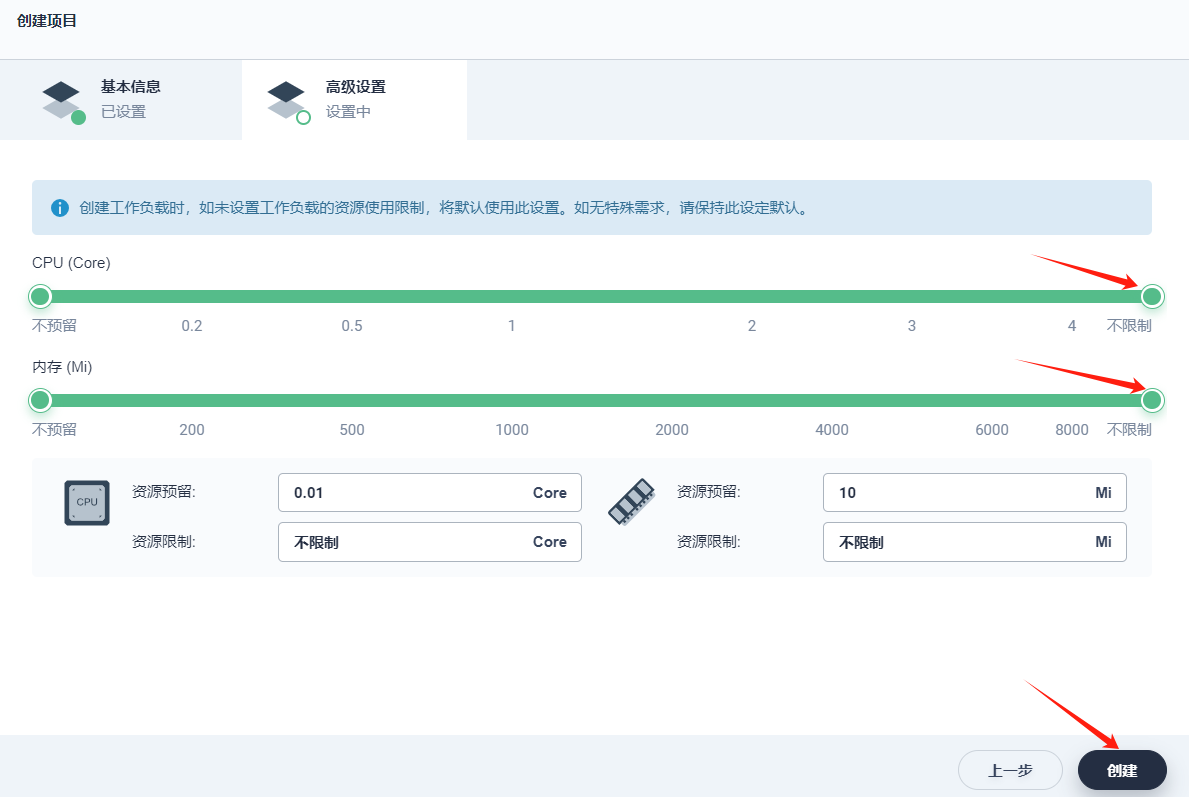
2、本示例暂无资源请求和限制,因此高级设置中无需修改默认值,点击 创建,项目可创建成功。
3、邀请成员
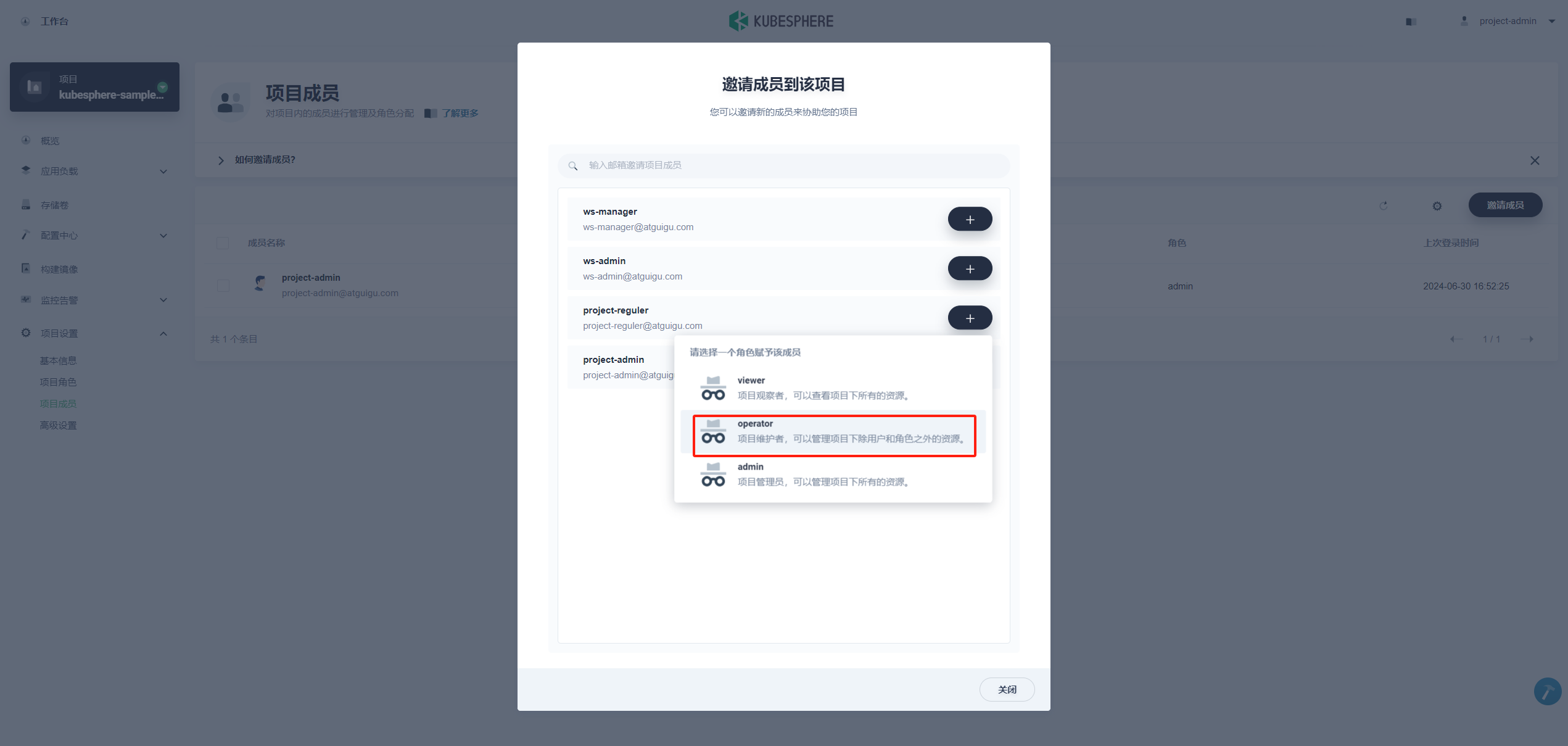
第一个项目创建完后,还需要项目管理员 project-admin邀请当前的项目普通用户 project-regular进入 kubesphere-sample-dev项目,进入**「项目设置」→「项目成员」,点击「邀请成员」**选择邀请 project-regular并授予 operator角色 。
5.6.2、第二步:创建第二个项目
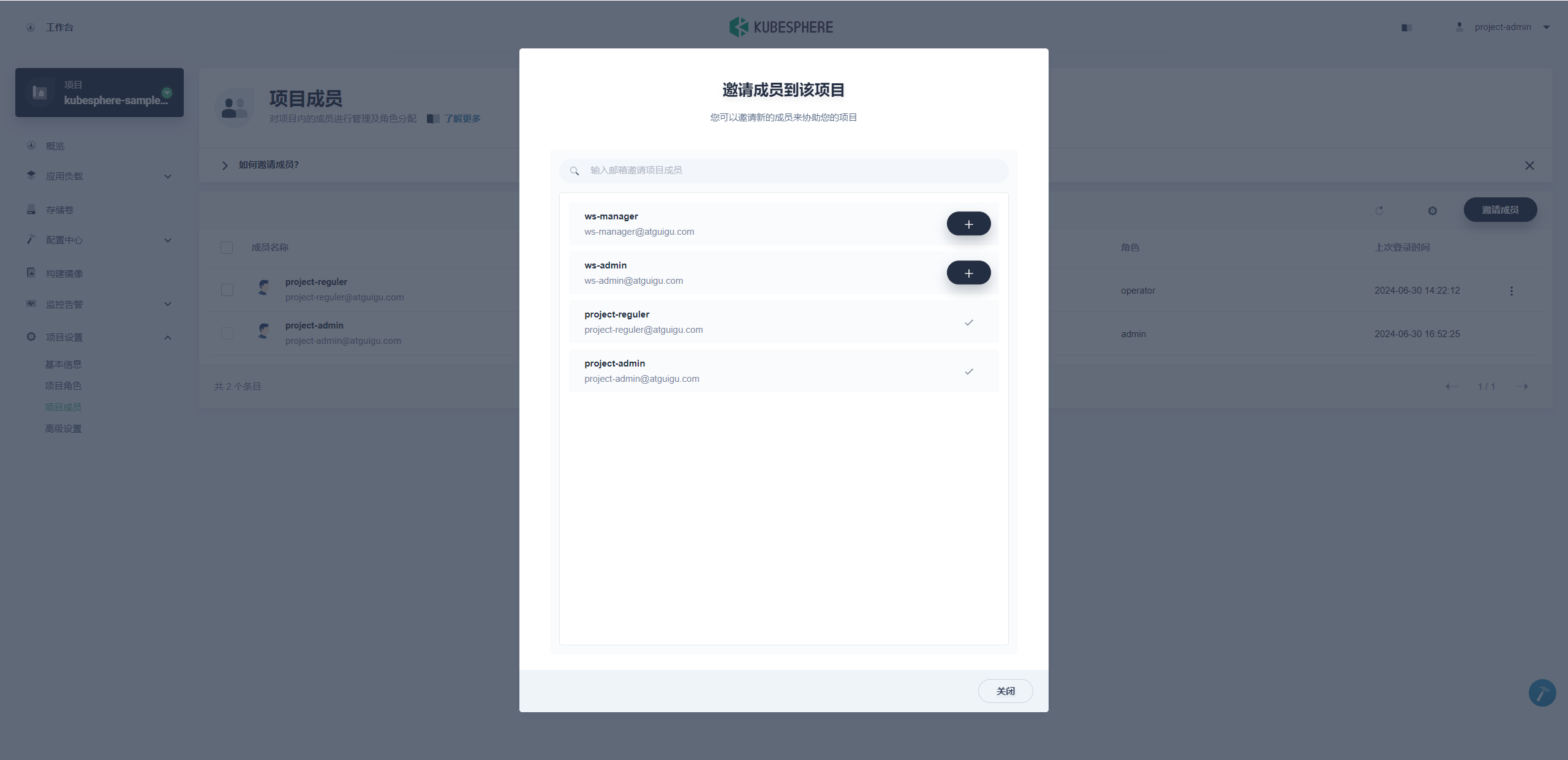
同上,参考以上两步创建一个名称为 kubesphere-sample-prod的项目作为生产环境,并邀请普通用户 project-regular进入 kubesphere-sample-prod项目并授予 operator角色。
3、kubesphere-sample-prod创建同上
说明:当 CI/CD 流水线后续执行成功后,在 kubesphere-sample-dev和 kubesphere-sample-prod项目中将看到流水线创建的部署 (Deployment) 和服务 (Service)。
5.7、创建流水线
5.7.1、第一步:填写基本信息
1、进入已创建的 DevOps 工程,选择左侧菜单栏的 流水线,然后点击 创建。
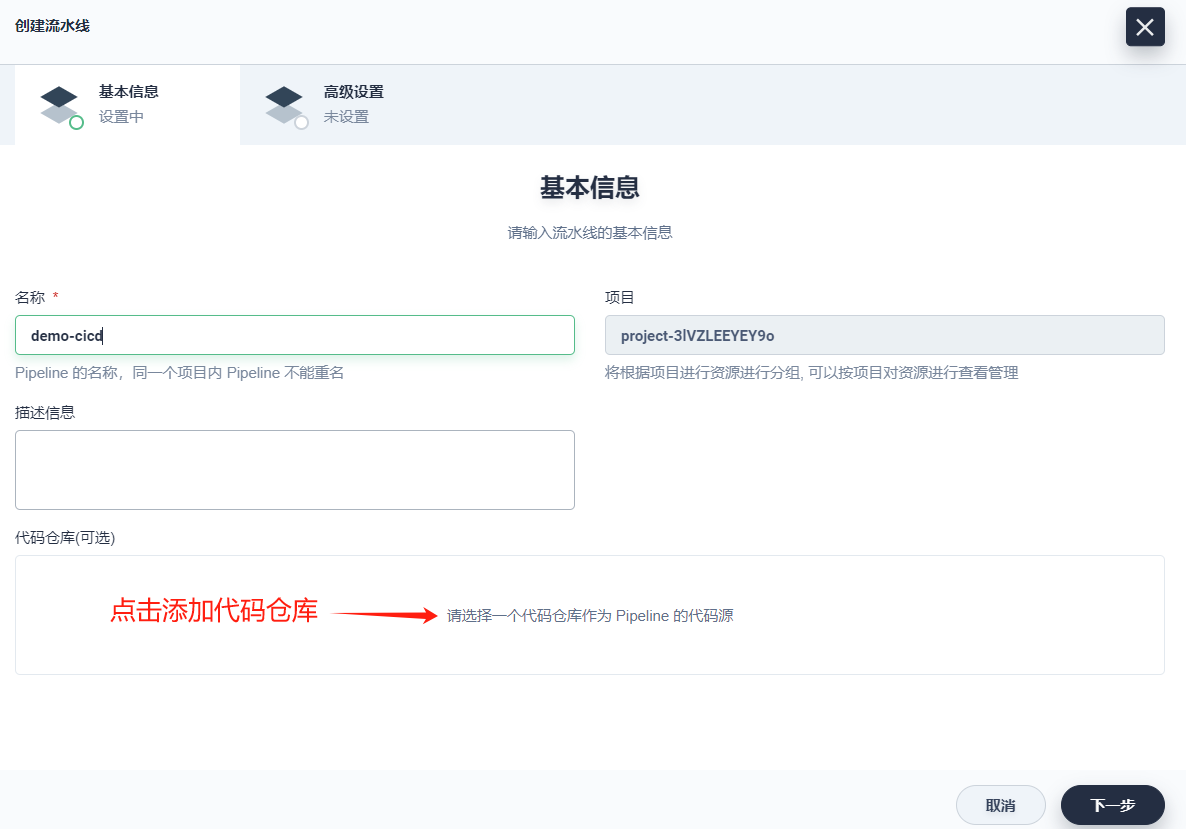
2、在弹出的窗口中,输入流水线的基本信息。
- 名称:为创建的流水线起一个简洁明了的名称,便于理解和搜索
- 描述信息:简单介绍流水线的主要特性,帮助进一步了解流水线的作用
- 代码仓库:点击选择代码仓库,代码仓库需已存在 Jenkinsfile
5.7.2、第二步:添加仓库
1、点击代码仓库,以添加 Github 仓库为例。
2、点击弹窗中的 获取 Token。
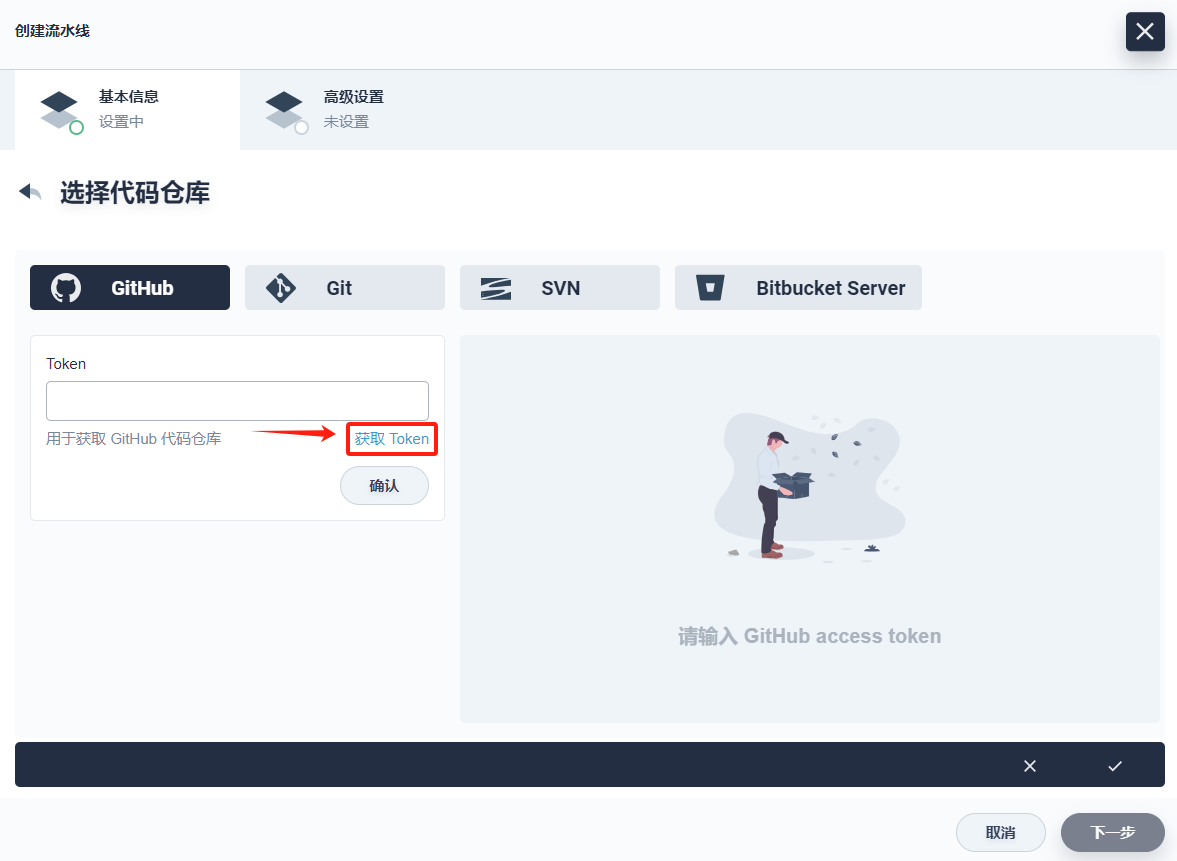
3、在 GitHub 的 access token 页面填写 Token description,简单描述该 token,如 DevOps demo,在 Select scopes 中无需任何修改,点击 Generate token,GitHub 将生成一串字母和数字组成的 token 用于访问当前账户下的 GitHub repo。
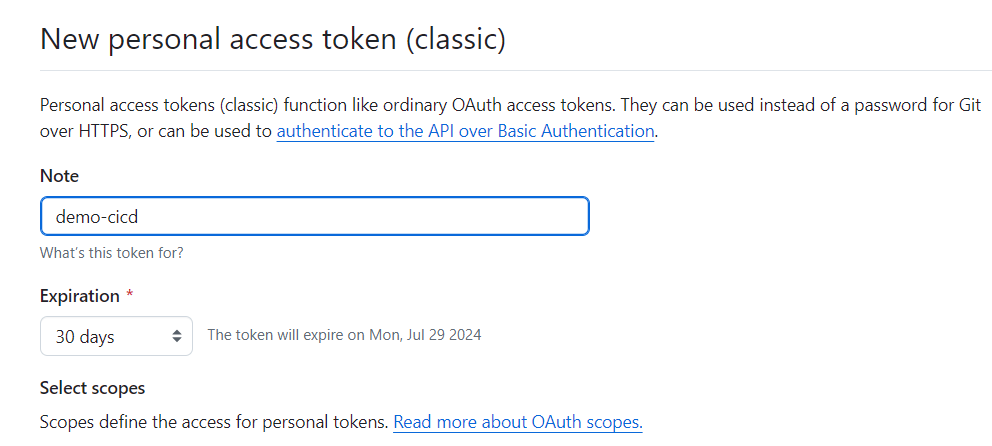

4、复制生成的 token,在 KubeSphere Token 框中输入该 token 然后点击保存。
5、验证通过后,右侧会列出此 Token 关联用户的所有代码库,选择其中一个带有 Jenkinsfile 的仓库。比如此处选择准备好的示例仓库 devops-java-sample,点击 选择此仓库,完成后点击 下一步。
5.7.3、第三步:高级设置
完成代码仓库相关设置后,进入高级设置页面,高级设置支持对流水线的构建记录、行为策略、定期扫描等设置的定制化,以下对用到的相关配置作简单释义。
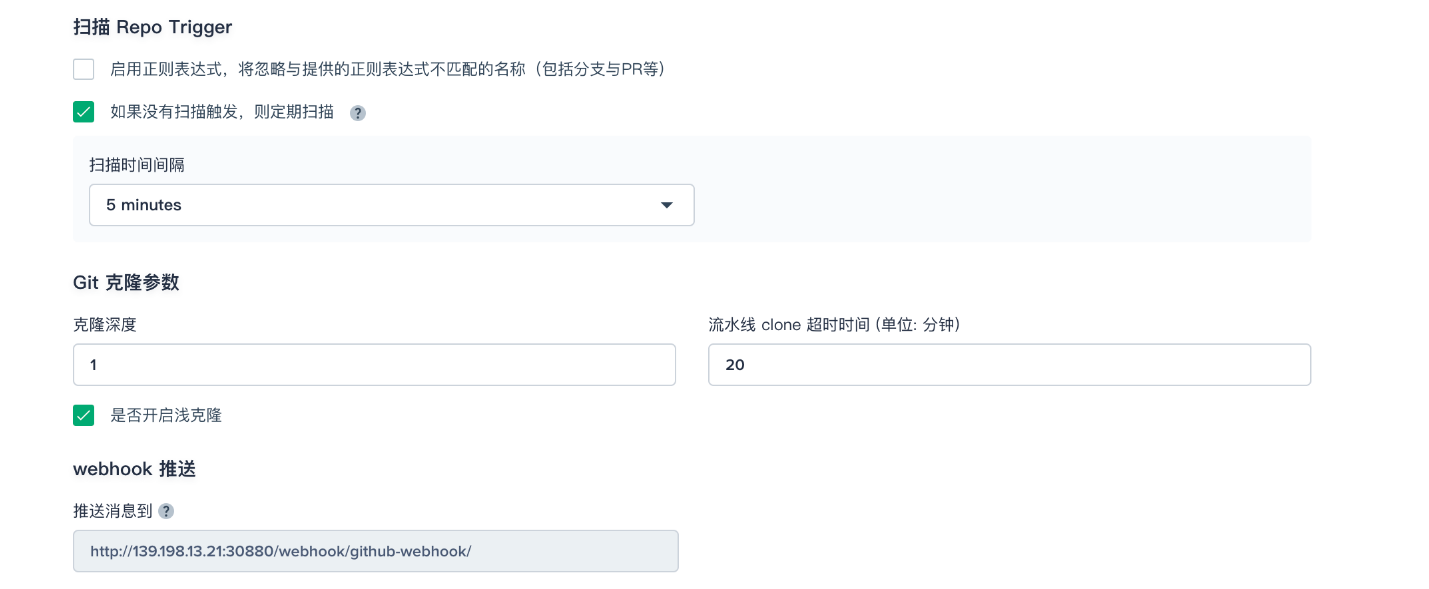
1、分支设置中,勾选 丢弃旧的分支,此处的 保留分支的天数 和 保留分支的最大个数 默认为 -1。
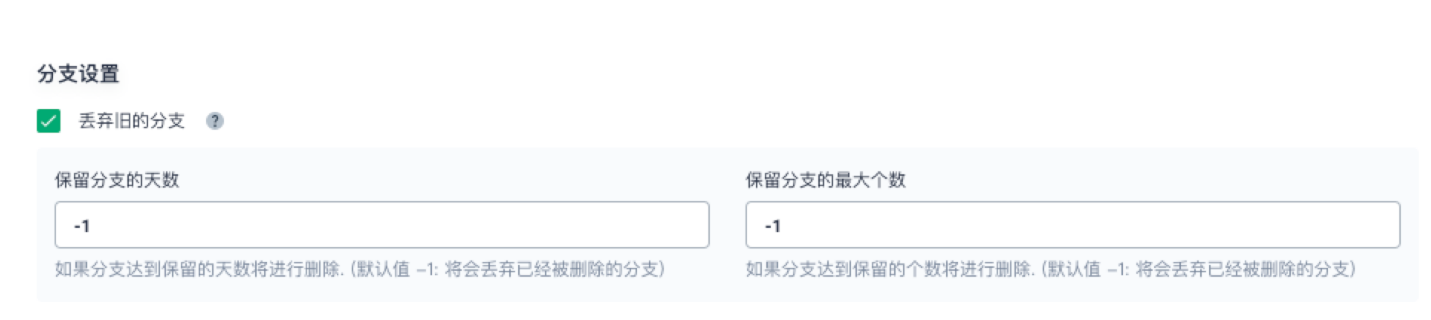
说明:
分支设置的保留分支的天数和保持分支的最大个数两个选项可以同时对分支进行作用,只要某个分支的保留> 天数和个数不满足任何一个设置的条件,则将丢弃该分支。假设设置的保留天数和个数为 2 和 3,则分支的保留天数一旦超过 2 或者保留个数超过 3,则将丢弃该分支。默认两个值为 -1,表示将会丢弃已经被删除的分支。丢弃旧的分支将确定何时应丢弃项目的分支记录。分支记录包括控制台输出,存档工件以及与特定分支相关的其他元数据。保持较少的分支可以节省 Jenkins 所使用的磁盘空间,我们提供了两个选项来确定应何时丢弃旧的分支:
- 保留分支的天数:如果分支达到一定的天数,则丢弃分支。
- 保留分支的个数:如果已经存在一定数量的分支,则丢弃最旧的分支。
2、行为策略中,KubeSphere 默认添加了三种策略。由于本示例还未用到 从 Fork 仓库中发现 PR 这条策略,此处可以删除该策略,点击右侧删除按钮。
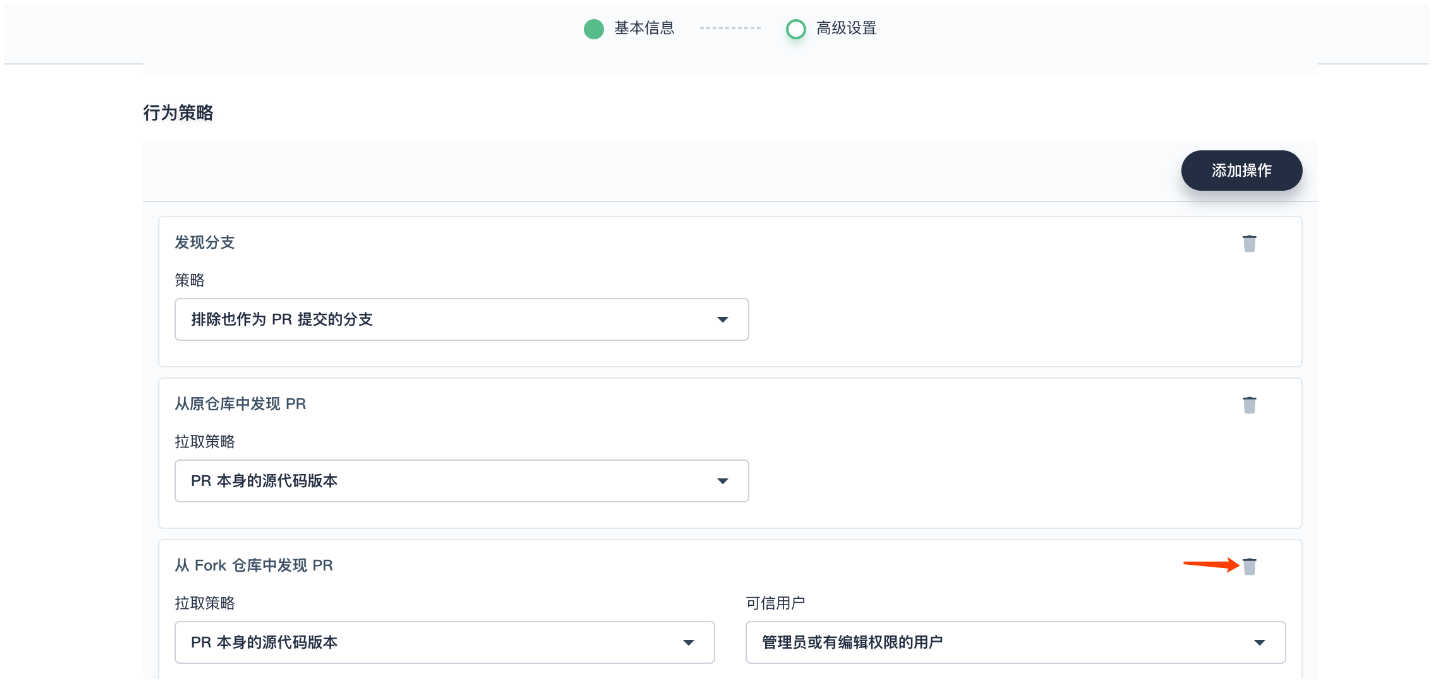
说明:
支持添加三种类型的发现策略。需要说明的是,在 Jenkins 流水线被触发时,开发者提交的 PR (Pull Request) 也被视为一个单独的分支。发现分支:
- 排除也作为 PR 提交的分支:选择此项表示 CI 将不会扫描源分支 (比如 Origin 的 master branch),也就是需要被 merge 的分支
- 只有被提交为 PR 的分支:仅扫描 PR 分支
- 所有分支:拉取的仓库 (origin) 中所有的分支
从原仓库中发现 PR:
- PR 与目标分支合并后的源代码版本:一次发现操作,基于 PR 与目标分支合并后的源代码版本创建并运行流> 水线
- PR 本身的源代码版本:一次发现操作,基于 PR 本身的源代码版本创建并运行流水线
- 当 PR 被发现时会创建两个流水线,一个流水线使用 PR 本身的源代码版本,一个流水线使用 PR 与目标分> - 支合并后的源代码版本:两次发现操作,将分别创建两条流水线,第一条流水线使用 PR 本身的源代码版本,第二条流水线使用 PR 与目标分支合并后的源代码版本。
3、默认的 脚本路径 为 Jenkinsfile,请将其修改为 Jenkinsfile-online。
注:路径是 Jenkinsfile 在代码仓库的路径,表示它在示例仓库的根目录,若文件位置变动则需修改其脚本路径。

4、在 扫描 Repo Trigger 勾选 如果没有扫描触发,则定期扫描,扫描时间间隔可根据团队习惯设定,本示例设置为 5 minutes。
说明:定期扫描是设定一个周期让流水线周期性地扫描远程仓库,根据 行为策略 查看仓库有没有代码更新或新的 PR。
Webhook 推送:
Webhook 是一种高效的方式可以让流水线发现远程仓库的变化并自动触发新的运行,GitHub 和 Git (如 > Gitlab) 触发 Jenkins 自动扫描应该以 Webhook 为主,以上一步在 KubeSphere 设置定期扫描为辅。在本示例中,可以通过手动运行流水线,如需设置自动扫描远端分支并触发运行,详见 设置自动触发扫描 - GitHub > SCM。
完成高级设置后点击 创建。
5.7.4、第四步:运行流水线
流水线创建后,点击浏览器的 刷新 按钮,可见两条自动触发远程分支后的运行记录,分别为 master和 dependency分支的构建记录。
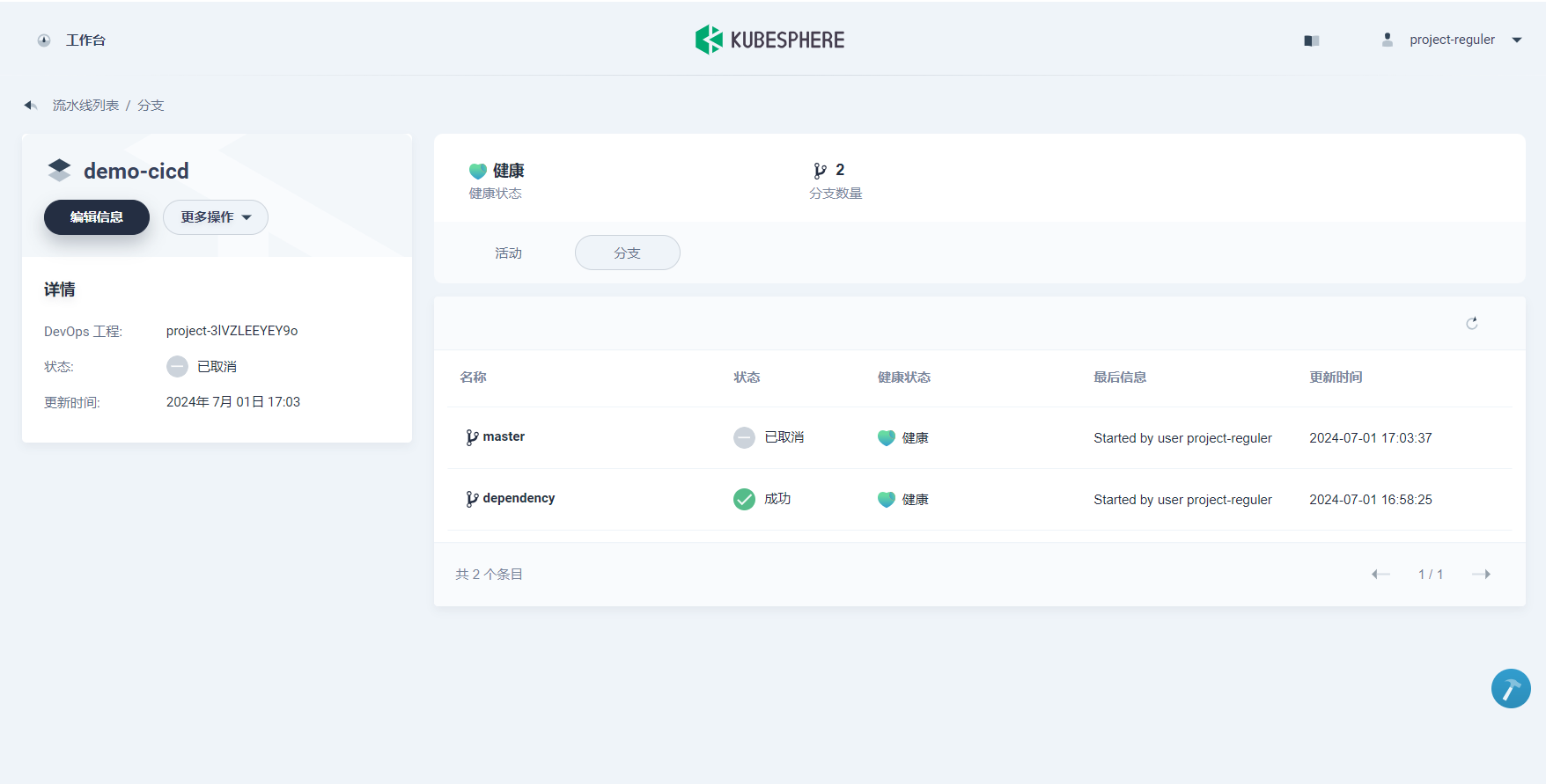
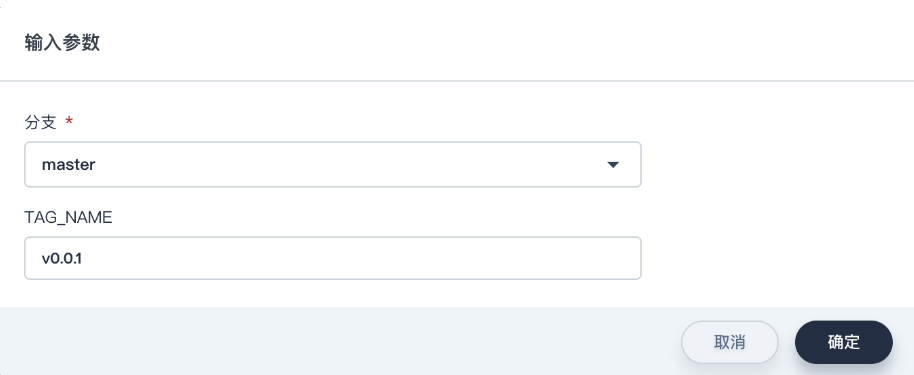
1、点击右侧 运行,将根据上一步的 行为策略 自动扫描代码仓库中的分支,在弹窗选择需要构建流水线的 master分支,系统将根据输入的分支加载 Jenkinsfile-online (默认是根目录下的 Jenkinsfile)。
2、由于仓库的 Jenkinsfile-online 中 TAG_NAME: defaultValue没有设置默认值,因此在这里的 TAG_NAME可以输入一个 tag 编号,比如输入 v0.0.1。
3、点击 确定,将新生成一条流水线活动开始运行。
说明: tag 用于在 Github 和DockerHub 中分别生成带有 tag 的 release 和镜像。 注意: 在主动运行流水线以发布 release 时,TAG_NAME不应与之前代码仓库中所存在的 tag名称重复,如果重复会导致流水线的运行失败。
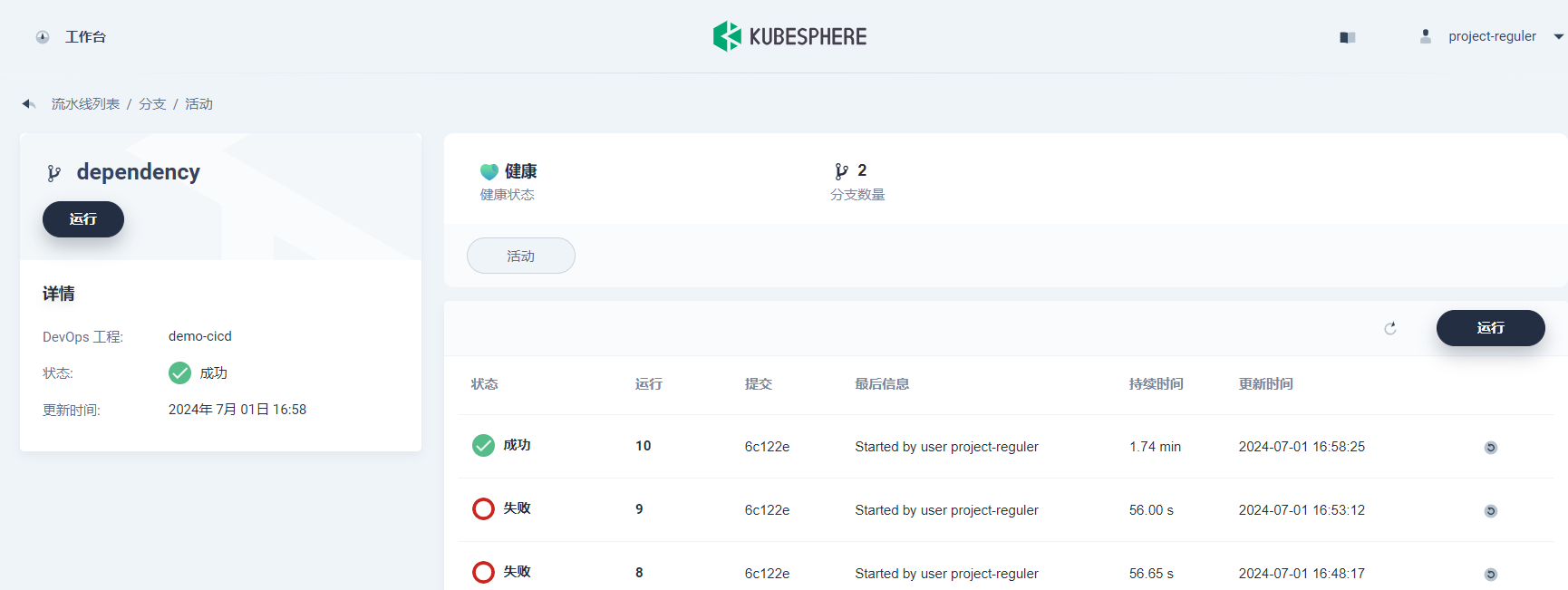
至此,流水线 已完成创建并开始运行。
注:点击 分支 切换到分支列表,查看流水线具体是基于哪些分支运行,这里的分支则取决于上一步 行为策略 的发现分支策略。
5.7.5、第五步:审核流水线
为方便演示,此处默认用当前账户来审核,当流水线执行至 input步骤时状态将暂停,需要手动点击 继续,流水线才能继续运行。注意,在 Jenkinsfile-online 中分别定义了三个阶段 (stage) 用来部署至 Dev 环境和 Production 环境以及推送 tag,因此在流水线中依次需要对 deploy to dev, push with tag, deploy to production这三个阶段审核 3次,若不审核或点击 终止 则流水线将不会继续运行。
说明:在实际的开发生产场景下,可能需要更高权限的管理员或运维人员来审核流水线和镜像,并决定是否允许将其推送至代码或镜像仓库,以及部署至开发或生产环境。Jenkinsfile 中的
input步骤支持指定用户审核流水线,比如要指定用户名为 project-admin 的用户来审核,可以在 Jenkinsfile 的 input 函数中追加一个字段,如果是多个用户则通过逗号分隔,如下所示:
···
input(id: 'release-image-with-tag', message: 'release image with tag?', submitter: 'project-admin,project-admin1')
···
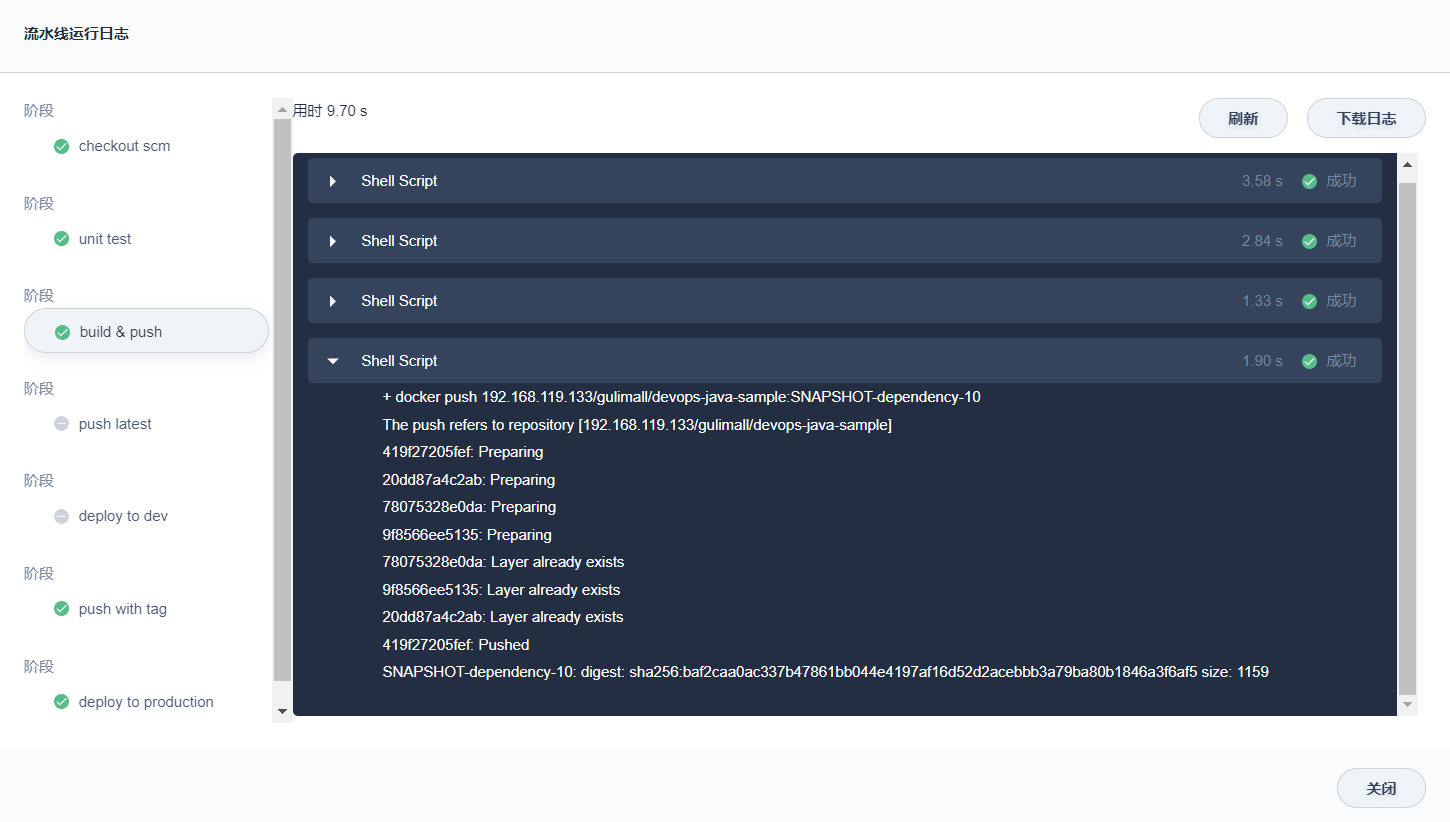
5.8、查看流水线
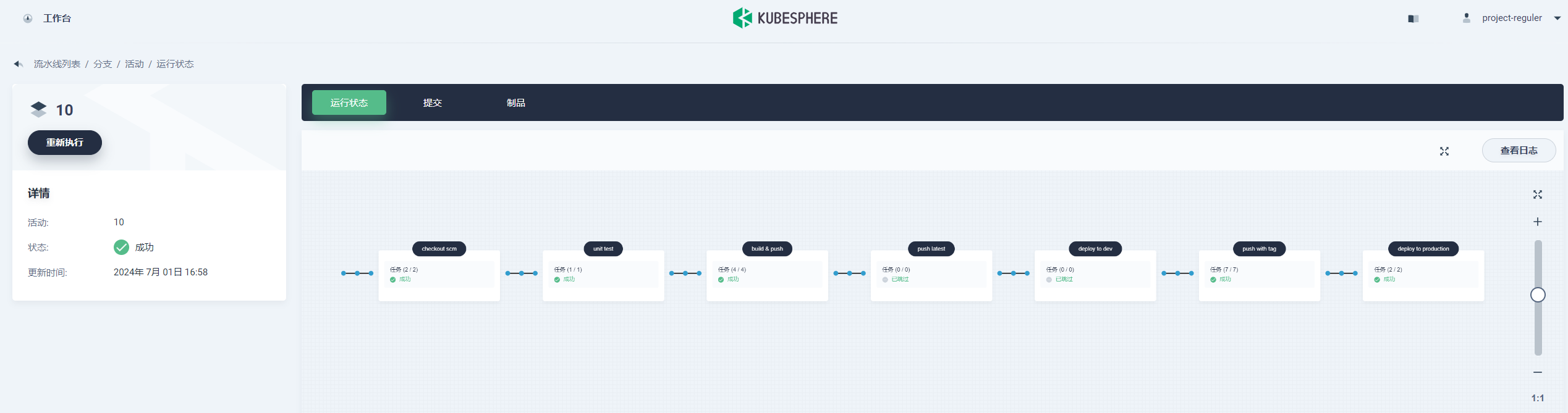
1、点击流水线中 活动列表下当前正在运行的流水线序列号,页面展现了流水线中每一步骤的运行状态,注意,流水线刚创建时处于初始化阶段,可能仅显示日志窗口,待初始化 (约一分钟) 完成后即可看到流水线。黑色框标注了流水线的步骤名称,示例中流水线共 8 个 stage,分别在 Jenkinsfile-online 中被定义。
2、当前页面中点击右上方的 查看日志,查看流水线运行日志。页面展示了每一步的具体日志、运行状态及时间等信息,点击左侧某个具体的阶段可展开查看其具体的日志。日志可下载至本地,如出现错误,下载至本地更便于分析定位问题。