传统的恶意域名检测方法在检测由域名生成算法(DGA)随机生成的恶意域名方面性能不佳,尤其是对于那些由随机单词组成的域名。文章提出了一种新的检测算法,通过融合字符和词特征来提高对恶意域名的检测能力,特别是对于更具挑战性的恶意域名家族。
CWNet算法:该算法利用并行卷积神经网络(CNN)提取域名中的字符和词特征,然后将这些特征进行拼接融合,并通过Softmax函数实现合法域名与恶意域名的分类检测。
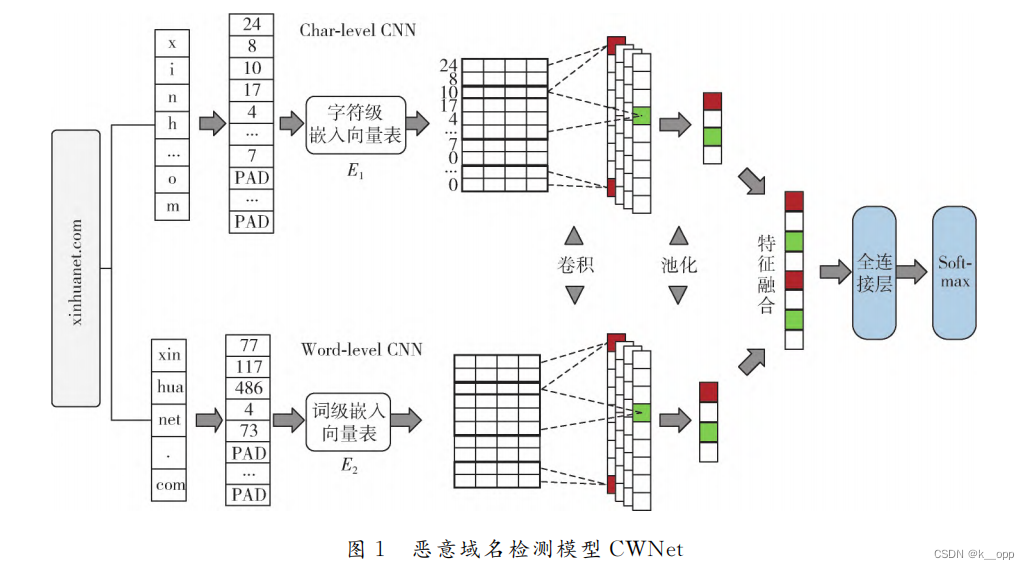
将域名字符串作为cwnet的输入,利用卷积神经网络CNN分别提取字符级特征和词级特征;然后,将两种特征进行融合,最后,利用Softmax实现待测域名的分类。
字符级特征提取
字符嵌入
根据数据集中最长域名的字符个数(本例中为67个字符),设置字符级向量表示的长度L1为67。对于长度小于67的域名字符串,使用零向量进行填充。
域名字符串向量化,将数据集中每条域名的每个字符Di转换为一个L1长度的向量{d1, …, dL1},然后将所有字符的向量串联起来,得到整条域名的向量化表示。
字符特征提取
设定卷积核的大小,使用卷积核在输入数据上进行卷积操作。通过卷积操作,可以提取多个不同大小的卷积核对应的特征图。这些特征图可以被拼接起来,以捕获不同尺度的特征。在提取了特征图之后,使用最大池化(Max Pooling)操作来降低特征的维数。经过卷积和池化操作后,网络输出一组降维后的特征,这些特征可以被用于后续的分类或其他任务。
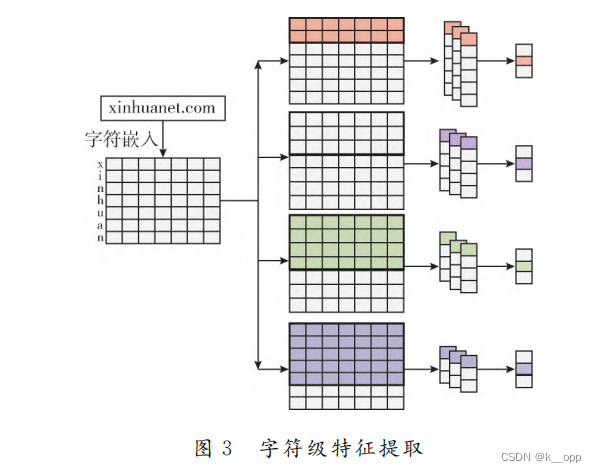
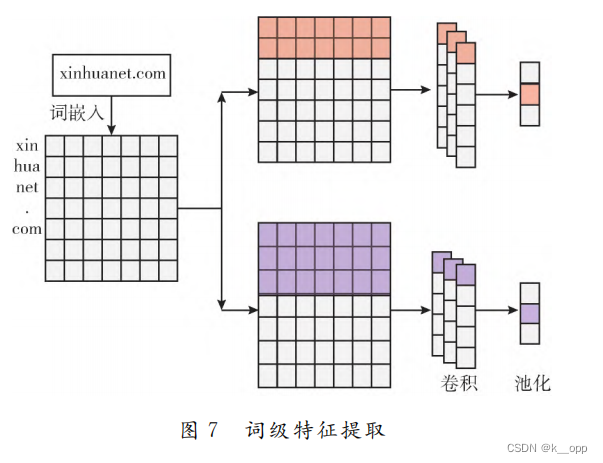
词级特征提取
单独的字符级特征不足以区分所有类型的域名,融合字符和词特征进行合法域名与恶意域名的分类。
简单词嵌入
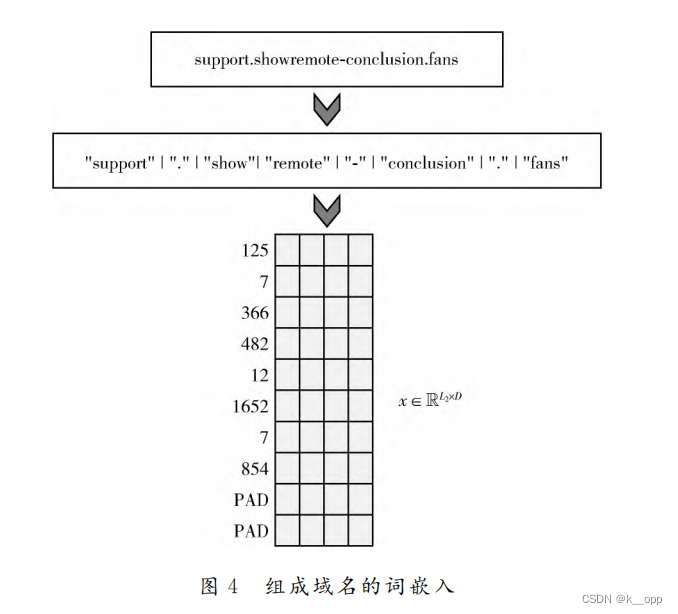
字符级词嵌入

词特征提取
特征融合
将字符级和词级得到的特征图进行拼接分别接入256个 结 点 的全连接层。最后,使用concat将字符和词的特征进行融合,作为之后全连接层的输入。
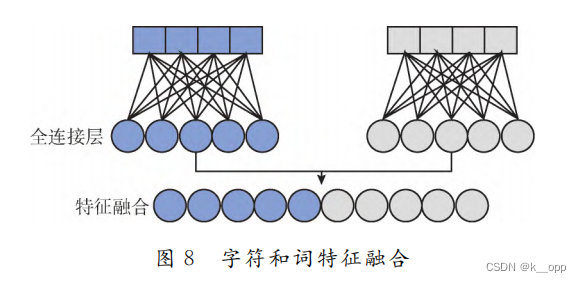
全连接层
在这里,融合后的特征向量被送入三个连续的全连接层。每一层的节点数依次减少,分别为256、128和64。这种设计有助于逐步减少数据的维度,同时学习更高层次的特征表示。在全连接层之后,使用Softmax函数作为激活函数来处理最终的输出层。Softmax函数可以将一个向量或一组实数输入转换成概率分布,即输出每个类别的概率预测值。为每个输入样本输出两个概率值,分别对应于合法域名和恶意域名。这些概率值表示模型预测样本属于每个类别的置信度。
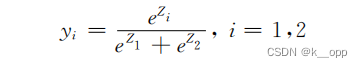
Focal Loss引入
为了减少简单样本对损失函数的影响,更加关注难分类的样本,引入了Focal Loss作为损失函数。Focal Loss旨在调整模型的注意力,使其更加关注那些难以正确分类的样本。
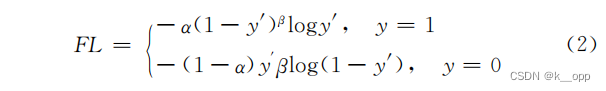
根据实验结果,将 𝛼,β 分别设置为0.5和2可以得到最佳效果。
实验设计与结果分析
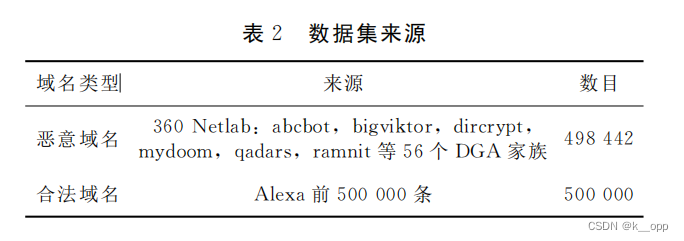
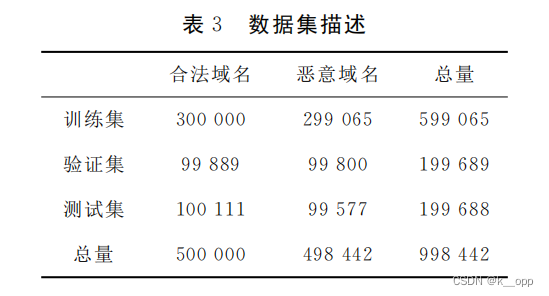
验证本文提出的模型(CWNet)的有效性,与其他5种不同的深度学习结构模型进行比较。
准确率(Accuracy):模型正确预测的样本数占总样本数的比例。
召回率(Recall):模型正确识别的正样本数占所有实际正样本数的比例。
精确率(Precision):模型正确预测为正的样本数占模型预测为正的样本数的比例。
F1值(F1-Score):精确率和召回率的调和平均值,是评价模型性能的一个综合指标。
误报率(False Positive Rate):错误地将负样本预测为正样本的比例。

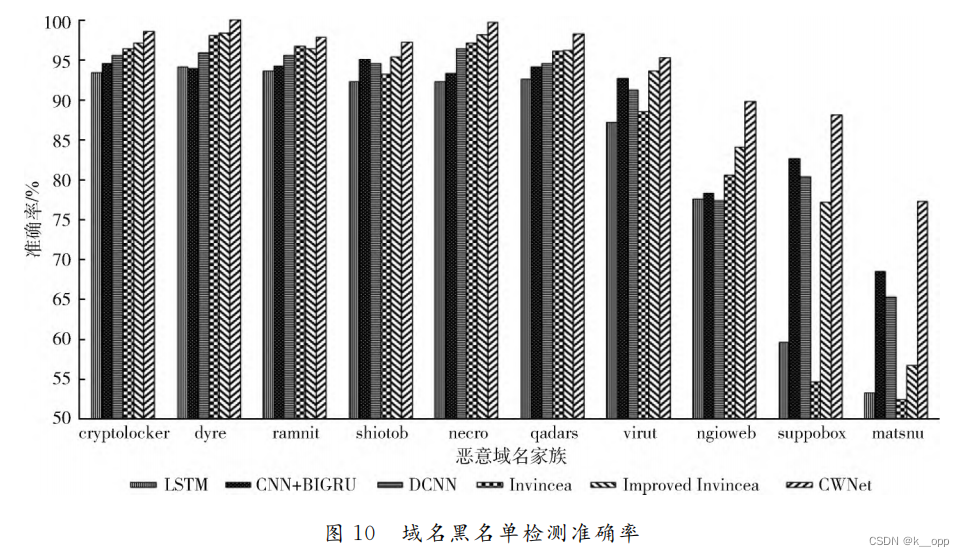
研究者构建了10个黑名单数据集,这些数据集包括7个由随机字符组成的DGA家族(如cryptolocker、dyre、ramnit、shuibot、necro、qadars、virt)以及3个由随机单词组成的较难检测的DGA家族(如ngioweb、suppoobox、matsnu)。CWNet模型在所有10个黑名单数据集中均展现出最高的准确率。特别地,在"dyre"家族的检测中达到了100%的准确率。
总结
CWNet模型是基于字符级和词级特征融合的检测模型,这种融合方法能够更全面地提取域名中的特征信息。模型通过提取域名中的字符特征和词级特征,并进行特征融合,以捕获域名字符串中的深层信息。与现有模型相比,CWNet模型对域名字符串所提供的信息利用度更高,这表明其在特征提取和利用方面更为有效。
通过在开源数据集上进行测试,实验结果验证了CWNet模型的有效性。模型表明,利用字符和词融合特征可以显著提高对DGA(域名生成算法)域名的检测性能,尤其是对那些由随机单词组成的DGA域名。尽管CWNet模型在性能上取得了良好的结果,但模型由于采用了并行卷积神经网络,参数较多,导致应用难度较大。
设计更加轻量化的恶意域名检测模型,以降低模型的复杂性和提高实用性。
[1]赵宏,申宋彦,韩力毅,等.基于字符和词特征融合的恶意域名检测[J].计算机工程与设计,2024,45(05):1549-1556.DOI:10.16208/j.issn1000-7024.2024.05.035.