1. 概述
1.1 为什么要流控?
流控主要是为了防止生产者生产消息速度过快,超过 Broker 可以处理的速度。这时需要暂时限制生产者的生产速度,让 Broker 的处理能够跟上生产速度。
Erlang进程之间不共享内存,每个进程都有自己的进程邮箱,进程间只通过消息来通信。Erlang没有对进程邮箱的大小进行限制,所以当有大量消息持续发往某个进程时,会导致该进程邮箱过大,最终内存溢出并崩溃。如果没有流控,可能会导致内部进程邮箱的大小很快达到内存阈值。
1.2 RabbitMQ 的多种流控机制
1.2.1 全局流控(内存高水位、磁盘低水位)
RabbitMQ 可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被完全阻塞(处于block状态) ,直到对应项恢复正常。
内存和磁盘的流控相当于全局流控,流控时发送消息被完全阻塞,通常会阻塞较长时间(几分钟以上)才恢复。
全局流控时,从Web UI可以观察到 Connection 处于blocked状态。
在 rabbitmq-java-client 中,可以用给 Connection 添加 blockedListener 的方式监听阻塞和阻塞解除的事件,用以在客户端应对可能的阻塞情况。
connection.addBlockedListener(
reason -> {
try {
unblock();
} catch (InterruptedException e) {
e.printStackTrace();
}
},
() -> latch.countDown()
);
1.2.2 进程内流控
进程内流控是针对 Erlang 进程的流控,与全局流控不是一个概念。又可称作 Per-Connection Flow Control。
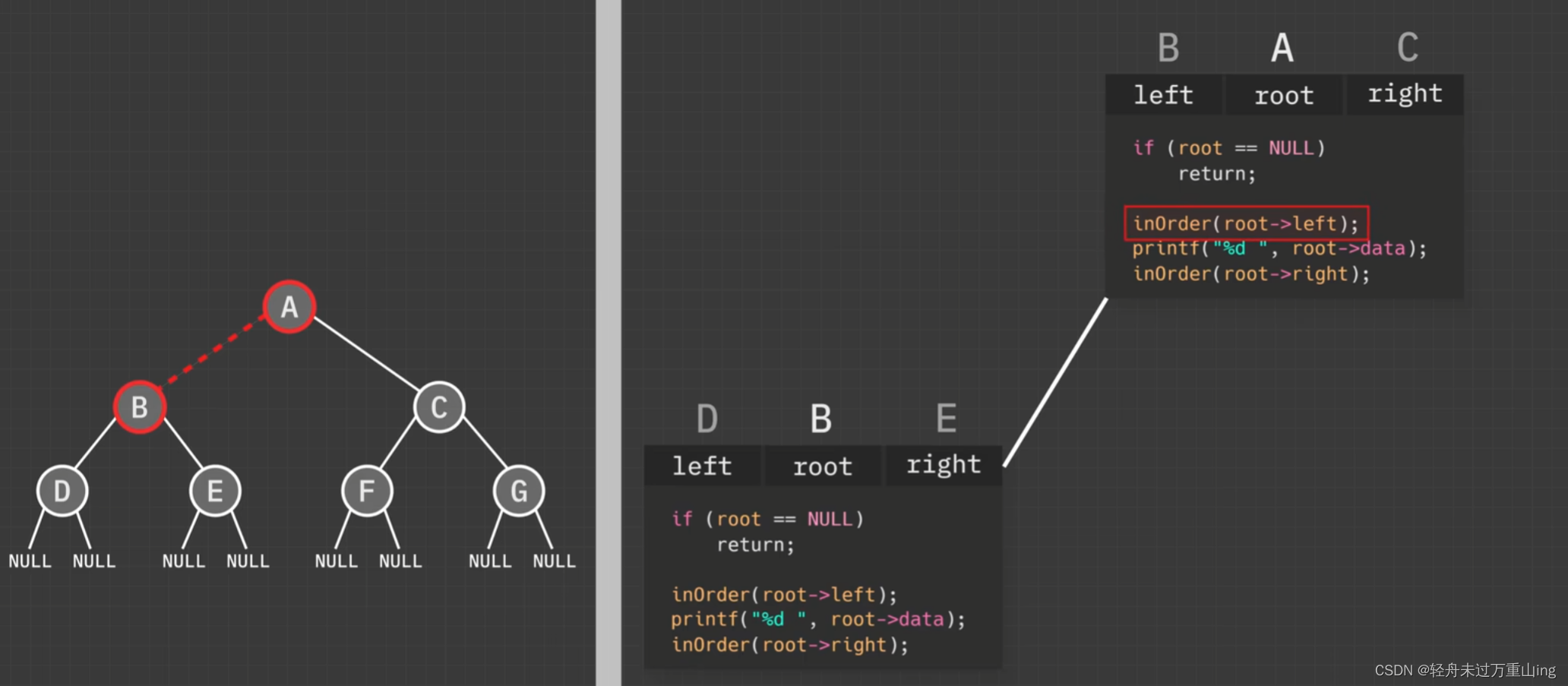
在 RabbitMQ Broker 中使用多种进程来处理消息,进程的处理顺序如下。

A simplified depiction of message flows
reader -> channel -> queue process -> message store
进程内流控指的是这4种进程之间的流控。
进程内流控不会影响到消费端。
某进程处于流控状态时,从 Web UI 可以观察到该进程的状态为黄色flow,此时该进程会暂时阻塞消息的生产。
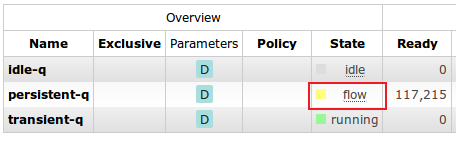
A queue in flow state
进程内流控的阻塞时间通常很短,在1秒之内。但是也有长至几分钟的。
进程内流控是阻塞在 Broker 端的 socket 接收方法中,client 端无法监听和做出处理。
从 RabbitMQ 3.5.5 版本开始,引入了一套基于信用证的流控实现。
本文主要讨论基于信用证的进程内流控实现。
1.2.3 发送方确认
这其实并不属于流控机制,但是通过生产者确认的方式可以让发送消息不丢失,并且控制发送消息的速度。
未开启发送方确认时,消息可能未达到服务器就发送完毕。
发送方确认开启后,消息在投递到匹配的队列后会给发送方返回一个确认请求,至此发送消息的动作才执行完毕。
1.2.4 消费者预取
通过Channel#basicQos(int prefetchCount)方法设置消费者允许存在的的最大未Ack消息数量,可以达到预取一批消息到消费者进行消费的目的。
2. 概要流程
从 RabbitMQ 3.5.5 版本开始,引入了一套基于信用证的流控实现。
2.1 信用证配置
信用证流控的两个参数可以通过查询环境变量的方式找到
rabbitmqctl eval 'application:get_all_env(rabbit).'
# ...
{credit_flow_default_credit,{400,200}} # {InitialCredit, MoreCreditAfter}
# ...
其中400表示每个进程初始的信用值,200表示下游进程处理200个消息后会一次性给上游进程加200信用值。
这两个参数在老一点的版本中为{200, 50}。
2.2 基于信用证的流控
Erlang 进程与操作系统的进程不同,是一种轻量级进程。
简单来说,RabbitMQ中有四种进程。
reader -> channel -> queue process -> message store
400 400 400
在初始化时,会为前三种进程分配信用值,分配的值为InitialCredit,默认400。
当进程处理一条消息并且发给下游进程时,它自己的信用值会减一。
下游进程处理完一条消息时,会给上有进程发一个Ack消息。但是此时并不会直接让上游进程的信用值加一,而是等到处理完MoreCreditAfter条消息(默认200)时,才将上游进程的信用值加200。
当进程的信用值将为1时,就会阻塞上游进程向它发送消息。
3. 详细流程
3.1 流控详细流程
下图每个橙色组件都是一个 Erlang 进程。
每个RabbitMQ broker在内部都是通过actor模式实现的,不同组件之间通过消息传递(有时是本地的)进行通信。

A simplified depiction of message flows
下面我们把这个模型简化,然后分析基于信用证的流控机制。
-
rabbit_reader:Connection 的处理进程。负责接收、解析 AMQP 协议数据包,将消息发送到 Channel -
rabbit_channel:Channel 的处理进程,负责处理 AMQP 协议的各种方法、进行路由解析;进行安全和协调的处理等 -
rabbit_amqqueue_process:Queue 的处理进程,负责将消息存入内存、将队列索引持久化 -
rabbit_msg_store:Store 的处理进程,负责消息的持久化
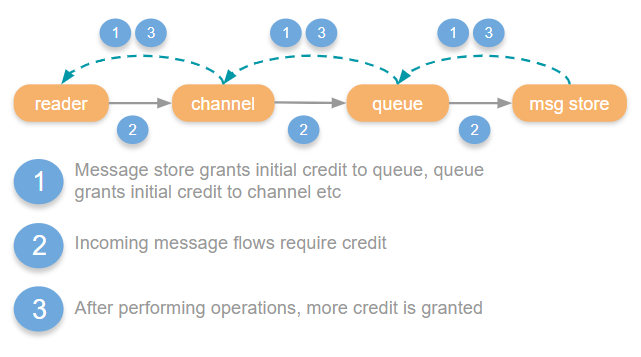
Credit based flow control with classic queues、
-
信用证初始化时,下游进程分别为前三个进程 reader、channel、queue 分配初始信用值 InitialCredit(400)(图中1) -
当 reader 进程开始处理一条消息,它会先将自己的信用值-1,然后将消息处理完后发给 channel 进程(图中2) -
channel 进程接收 reader 发过来的消息时,会在信用证系统种进行 ack 操作。channel 进程会持续追踪它从 reader 进程 ack 了多少条消息。当累计接收并 ack 的消息数达到 MoreCreditAfter(200)后,会给 reader 分配新的MoreCreditAfter(200)信用值。(图中3) -
当进程字典中的信用值降为0时,该进程会被阻塞。它不会接收消息也不会发送消息,直到获得新的信用值。 -
最终,TCP 读取进程被阻塞,从 socket 读取的操作被停止。
3.2 如何识别性能瓶颈
在管理 UI 中,你可能看到 Connection、Channel、Queue 处于flow状态,说明它们最近处于流控状态。这意味着它们暂时耗尽了信用值,等待下游进程授予更多信用。进程内流控可能在1秒钟内触发多次。
如何通过flow状态识别进程的性能瓶颈?
简单来说,一个进程的flow状态会导致它的上游进程进入flow状态。而该进程进入flow状态的原因是因为它的下游进程成为了性能瓶颈。
例如,在下图中,Queue 进程成为性能瓶颈:
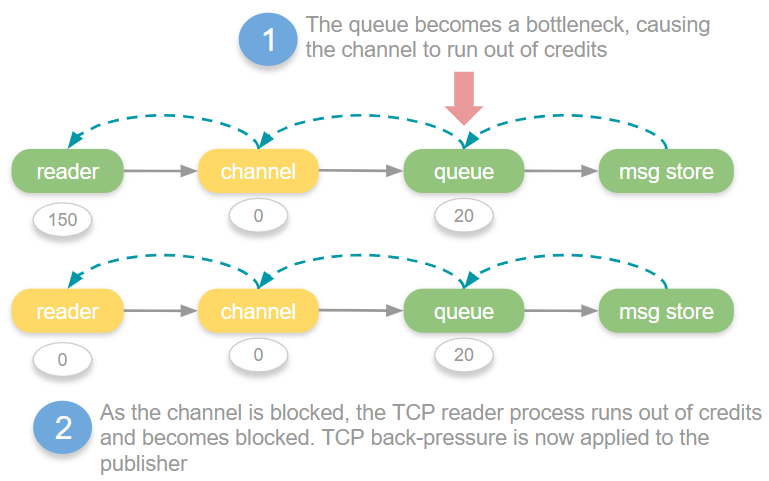
Credit exhaustion.
上图中,Queue 处理缓慢,这就意味着 Queue 可能在较长时间内都没有授予 Channel 新的信用值。Channel 处理比 Queue 快,这样 Channel 的信用值就会先一步耗尽。
Channel 信用值耗尽后,Channel 被阻塞,不会接受消息也不会处理消息,这样 Reader 的信用值也将会耗尽。
也就是说,Queue 如果是性能瓶颈,最终会导致它的上游,即 Channel 和 Reader 处于flow状态。
下面可以总结出判断性能瓶颈在何处的结论:
-
当某个 Connection 处于 flow状态,但这个 Connection 中没有一个 Channel 处于flow状态时,这就意味这个 Connection 中有一个或者多个 Channel 出现了性能瓶颈。某些 Channel 进程的运作(比如处理路由逻辑)会使得服务器 CPU 的负载过高从而导致了此种情形。尤其是在发送 大量较小的非持久化消息时,此种情形最易显现。 -
当某个 Connection 处于 flow状态 ,并且这个 Connection 中也有若干个 Channel 处于flow状态,但没有任何一个对应的队列处于flow状态时,这就意味着有一个或者多个队列出现了性能瓶颈。这可能是由于将消息存入队列的过程中引起服务器 CPU 负载过高,或者是将队列中的消息存入磁盘的过程中引起服务器 I/O 负载过高而引起的此种情形。尤其是在发送 大量较小的持久化消息时,此种情形最易显现。 -
当某个 Connection 处于 flow状态,同时这个 Connection 中也有若干个 Channel 处于flow状态,井且也有若干个对应的队列处于flow状态时,这就意味着在消息持久化时出现了性能瓶颈。在将队列中的消息存入磁盘的过程中引起服务器 I/O 负载过高而引起的此种情形。尤其是在 发送大量较大的持久化消息时,此种情形最易显现。
4. 源码解析
在 Erlang 中,每个进程都保存为一个.erl文件。这里的进程与操作系统的进程不同,是一个由 Erlang 系统管理的轻量级进程。而信用证流控的逻辑都位于credit_flow.erl文件中。
下面我们以rabbit_reader(Connection 进程)和rabbit_channel进程为例,看一下源码中如何处理信用的流动和消息的阻塞。
4.1 处理消息,减少信用
当rabbit_reader处理一个有内容的命令(比如basic.publish),会执行如下加粗逻辑
% rabbit_reader.erl
process_frame(Frame, Channel, State) ->
ChKey = {channel, Channel},
case (case get(ChKey) of
undefined -> create_channel(Channel, State);
Other -> {ok, Other, State}
end) of
{error, Error} ->
handle_exception(State, Channel, Error);
{ok, {ChPid, AState}, State1} ->
case rabbit_command_assembler:process(Frame, AState) of
{ok, NewAState} ->
put(ChKey, {ChPid, NewAState}),
post_process_frame(Frame, ChPid, State1);
{ok, Method, NewAState} ->
rabbit_channel:do(ChPid, Method),
put(ChKey, {ChPid, NewAState}),
post_process_frame(Frame, ChPid, State1);
**{ok, Method, Content, NewAState} ->
rabbit_channel:do_flow(ChPid, Method, Content),
put(ChKey, {ChPid, NewAState}),
post_process_frame(Frame, ChPid, control_throttle(State1));**
{error, Reason} ->
handle_exception(State1, Channel, Reason)
end
end.
可以看到会先执行rabbit_channel:doflow/3,再看一下这个方法
% rabbit_channel_common.erl
do_flow(Pid, Method, Content) ->
%% Here we are tracking messages sent by the rabbit_reader
%% process. We are accessing the rabbit_reader process dictionary.
credit_flow:send(Pid),
gen_server2:cast(Pid, {method, Method, Content, flow}).
可以看到在rabbit_channel中会调用credit_flow:send/1方法。这里的Pid是 Channel 的进程号。
这里的逻辑是:rabbit_reader通过credit_flow模块来追踪它已经向rabbit_channel进程发送的消息数,每发一条消息就会将自己的信用值减一。被追踪的信息保存在rabbit_reader的进程字典中。
注意,尽管这里是在rabbit_channel模块中调用credit_flow:send/1方法,但是此处仍处于rabbit_reader进程中,只有在执行完gen_server2:cast/2方法后才会进入到rabbit_channel进程的内存空间。因此,当credit_flow:send/1方法被调用时,信用值减一的操作仍然在rabbit_reader进程中被追踪。
见下面credit_flow:send/2和credit_flow:UPDATE的定义,通过调用get/1和put/2方法获取并更新进程字典的值。
% credit_flow.erl
send(From, {InitialCredit, _MoreCreditAfter}) ->
?UPDATE({credit_from, From}, InitialCredit, C,
if C == 1 -> block(From),
0;
true -> C - 1
end).
% credit_flow.erl
%% process dict update macro - eliminates the performance-hurting
%% closure creation a HOF would introduce
-define(UPDATE(Key, Default, Var, Expr),
begin
%% We deliberately allow Var to escape from the case here
%% to be used in Expr. Any temporary var we introduced
%% would also escape, and might conflict.
Var = case get(Key) of
undefined -> Default;
V -> V
end,
put(Key, Expr)
end).
来看一下进程字典中关于信用证的信息

用来保存信用值信息的 key 是{credit_from, From},From表示消息接受者的进程号(这里是rabbit_channel)。当这个 key 对应的值达到 0,拥有该进程字典的进程会被阻塞(调用credit_flow:block/1)方法
4.2 进程阻塞,停止接收信息
上面说到,当进程字典中的信用值达到 0 时,会调用credit_flow:block/1方法,我们来看看这个方法中做了什么。
% credit_flow.erl
block(From) ->
?TRACE_BLOCKED(self(), From),
case blocked() of
false -> put(credit_blocked_at, erlang:monotonic_time());
true -> ok
end,
?UPDATE(credit_blocked, [], Blocks, [From | Blocks]).
这里更新了进程字典中credit_blocked的值,将阻塞这个进程的下游进程ID(这里是rabbit_channel)加入到credit_blocked中。
注意,因为rabbit_reader可能会将消息发送给多个进程,所以它也可能被多个进程阻塞。因此credit_blocked的值是一个进程ID列表。
credit_blocked -> [pid()]
那么进程阻塞之后,如何停止信息接收?我们来分析一下rabbit_reader接收消息的入口,recvloop方法。
% rabbit_reader.erl
recvloop(Deb, Buf, BufLen, State = #v1{pending_recv = true}) ->
mainloop(Deb, Buf, BufLen, State);
recvloop(Deb, Buf, BufLen, State = #v1{connection_state = blocked}) ->
mainloop(Deb, Buf, BufLen, State);
recvloop(Deb, Buf, BufLen, State = #v1{connection_state = {become, F}}) ->
throw({become, F(Deb, Buf, BufLen, State)});
recvloop(Deb, Buf, BufLen, State = #v1{sock = Sock, recv_len = RecvLen})
when BufLen < RecvLen ->
case rabbit_net:setopts(Sock, [{active, once}]) of
ok -> mainloop(Deb, Buf, BufLen,
State#v1{pending_recv = true});
{error, Reason} -> stop(Reason, State)
end;
其中mainloop会调用recvloop函数,达成无限循环的效果。
rabbit_reader每接收一个包,就设置套接字属性为{active, once},若当前连接处于blocked状态,则不设置{active, once},这个接收进程就阻塞在receive方法上。
4.3 增加信用值
rabbit_channel每处理一条消息,都会向rabbit_reader进行一次确认(credit_flow:ack)。
当rabbit_channel累计处理的消息数达到MoreCreditAfter值时,会授予rabbit_reader新的MoreCreditAfter点信用值。
我们先来看一下ack函数的实现
% credit_flow.erl
ack(To, {_InitialCredit, MoreCreditAfter}) ->
?UPDATE({credit_to, To}, MoreCreditAfter, C,
if C == 1 -> grant(To, MoreCreditAfter),
MoreCreditAfter;
true -> C - 1
end).
rabbit_channel进程会记录它向特定的发送者(rabbit_reader)ack了多少条消息。在进程字典中用来保存ack消息数的 key 是{credit_to, To},这里To是发送者(rabbit_reader)的进程号。
当MoreCreditAfter条消息被ack,会调用grant方法授予rabbit_reader更多的信用值。
% credit_flow.erl
grant(To, Quantity) ->
Msg = {bump_credit, {self(), Quantity}},
case blocked() of
false -> To ! Msg;
true -> ?UPDATE(credit_deferred, [], Deferred, [{To, Msg} | Deferred])
end.
在这里,rabbit_channel将会发送一条{bump_credit, {self(), Quantity}}的消息给rabbit_reader来授予信用。其中self()指向rabbit_channel。
当rabbit_reader进程收到bump_credit消息后,它需要将消息传入并调用credit_flow:handle_bump_msg/1方法来处理新增信用值。
% credit_flow.erl
handle_bump_msg({From, MoreCredit}) ->
?UPDATE({credit_from, From}, 0, C,
if C =< 0 andalso C + MoreCredit > 0 -> unblock(From),
C + MoreCredit;
true -> C + MoreCredit
end).
我们访问rabbit_reader的进程字典,更新{credit_from, From}这个 key。如果信用值大于0,那么进程会解除阻塞。
4.4 进程解除阻塞
% credit_flow.erl
unblock(From) ->
?TRACE_UNBLOCKED(self(), From),
?UPDATE(credit_blocked, [], Blocks, Blocks -- [From]),
case blocked() of
false -> case erase(credit_deferred) of
undefined -> ok;
Credits -> _ = [To ! Msg || {To, Msg} <- Credits],
ok
end;
true -> ok
end.
调用credit_flow:unblock/1会更新credit_blocked列表,将其清空。随后进程可以继续发送消息。
同时,credit_flow:unblock/1将负责发送在credit_deferred列表中保存的所有消息。
当unblock/1被调用时,rabbit_channel进程的ID将从credit_blocked的列表中删除。
%% We are operating on process A dictionary.
get(credit_blocked) => [B, C].
unblock(B).
get(credit_blocked) => [C].
在这种情况下,A 仍然被阻塞,直到 C 授予它更多信用。当 A 的阻塞解除,它将处理它的 credit_deferred列表,发送bump_credit消息给列表中的进程。
5. 参考资料
-
Flow Control -
Finding bottlenecks with RabbitMQ 3.3 -
New Credit Flow Settings on RabbitMQ 3.5.5 -
RABBITMQ INTERNALS - CREDIT FLOW FOR ERLANG PROCESSES -
Quorum Queues and Flow Control - The Concepts -
RabbitMQ实战指南 -
RabbitMQ流量控制机制分析
本文由 mdnice 多平台发布