目录
查询文档-快速入门
查询文档-match查询
查询文档-精确查询
查询文档-布尔查询
查询文档-排序和分页
查询文档-高亮显示
-
查询文档-快速入门
- 文档的查询基本步骤包括:
- (1)准备Request对象
- (2)准备请求参数,构建查询条件
- (3)发起请求,得到结果
- (4)解析结果(参考JSON结果,从外到内,逐层解析)
- 以match_all查询为例
- 发起查询请求,解析响应
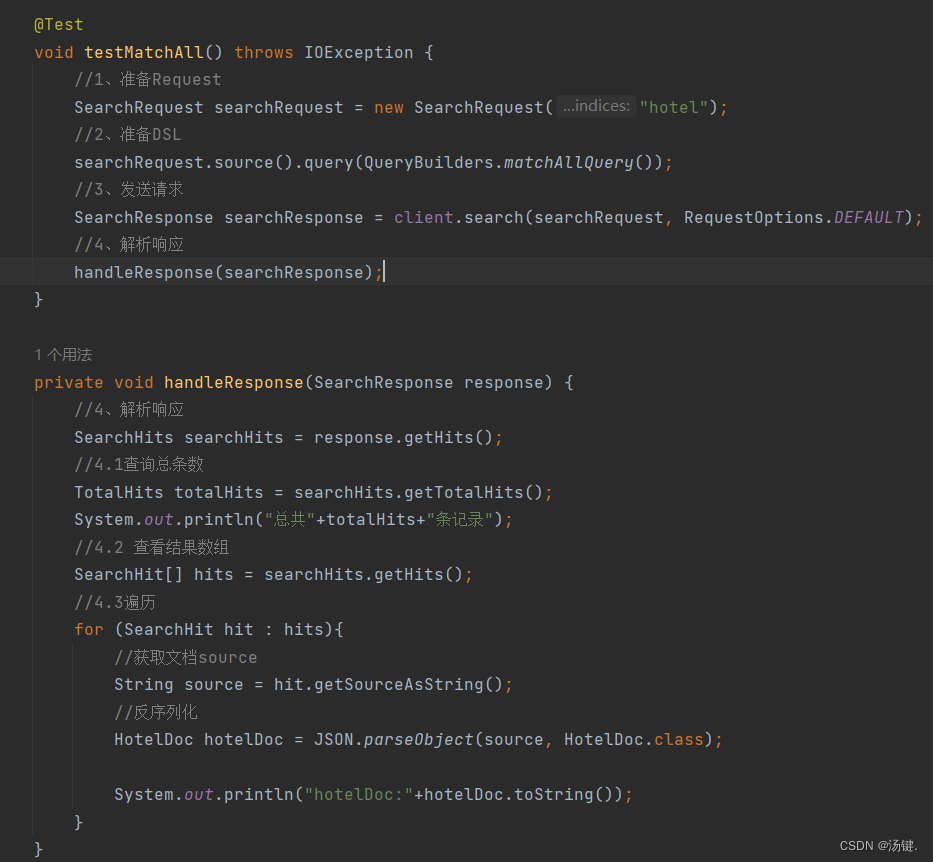
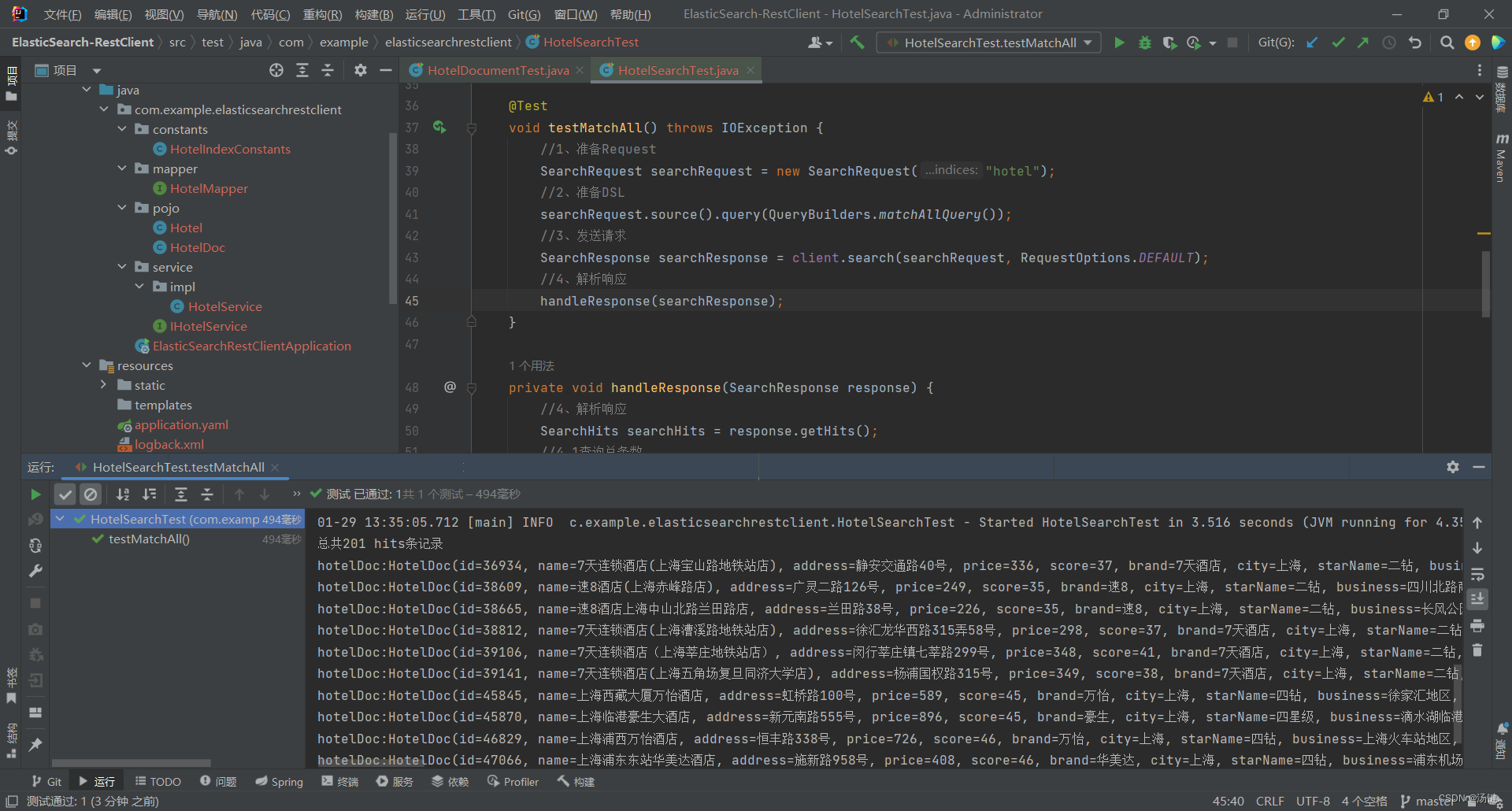
- 代码解读:
- 第一步,创建SearchRequest对象,指定索引库名
- 第二步,利用request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等
- query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
- 第三步,利用client.search()发送请求,得到响应
- 这里关键的API有两个:
- 一个是request.source(),其中包含了查询、排序、分页、高亮等所有功能
- 另一个是QueryBuilders,其中包含match、term、function_score、bool等各种查询
- elasticsearch返回的结果是一个JSON字符串,结构包含:
- hits:命中的结果
- total:总条数,其中的value是具体的总条数值
- max_score:所有结果中得分最高的文档的相关性算分
- hits:搜索结果的文档数组,其中的每个文档都是一个json对象
- _source:文档中的原始数据,也是json对象
- 因此,解析响应结果,就是逐层解析JSON字符串,流程如下:
- SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果
- SearchHits#getTotalHits().value:获取总条数信息
- SearchHits#getHits():获取SearchHit数组,也就是文档数组
- SearchHit#getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
-
查询文档-match查询
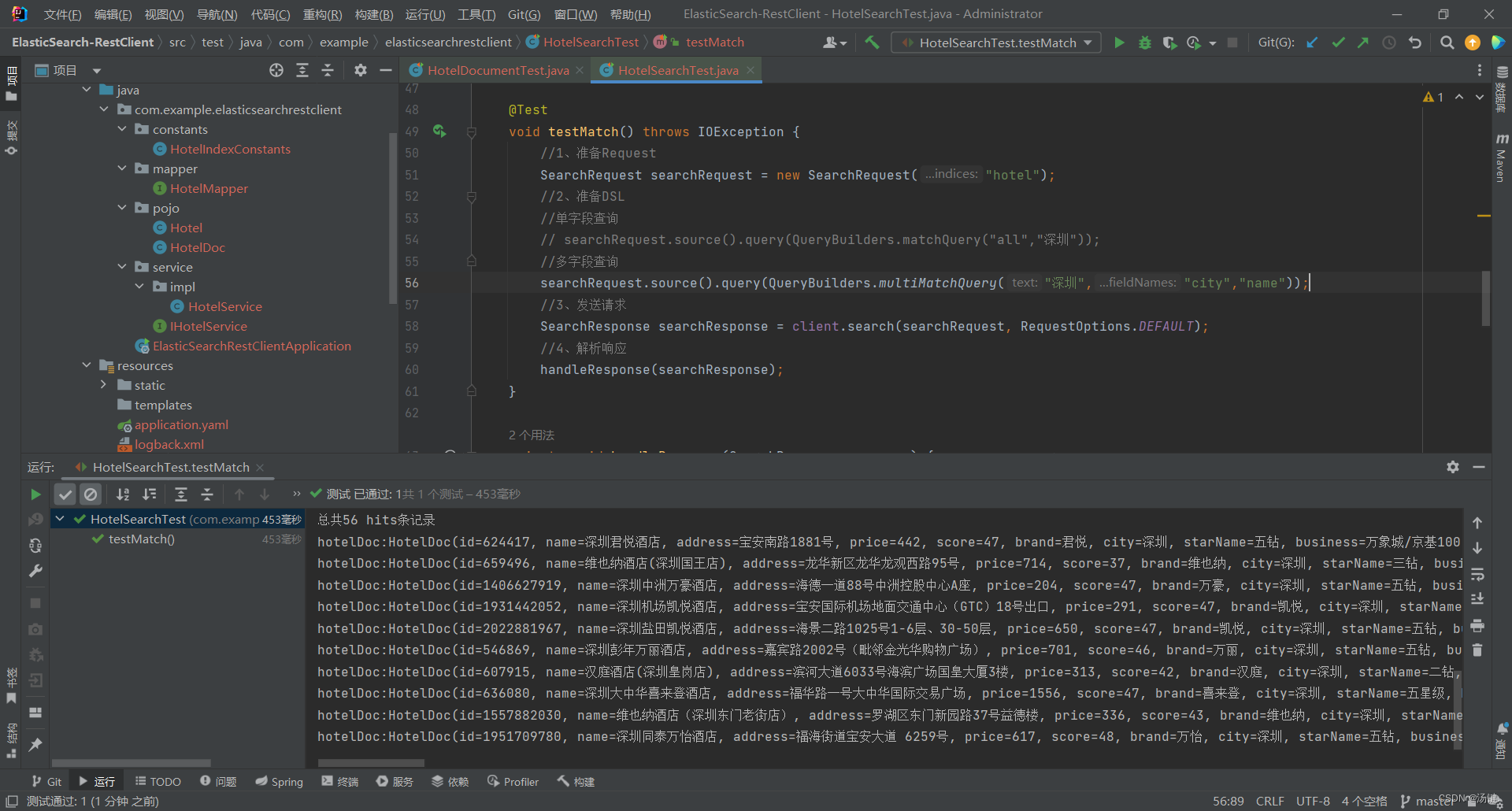
- 全文检索的match和multi_match查询与match_all的API基本一致
- 差别是查询条件,也就是query的部分
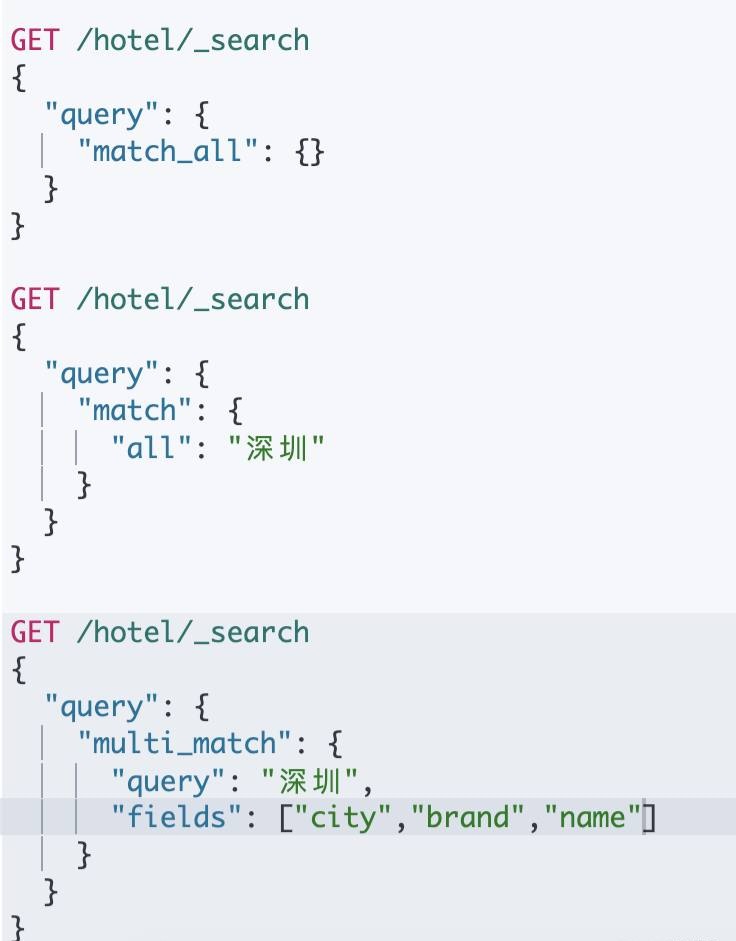
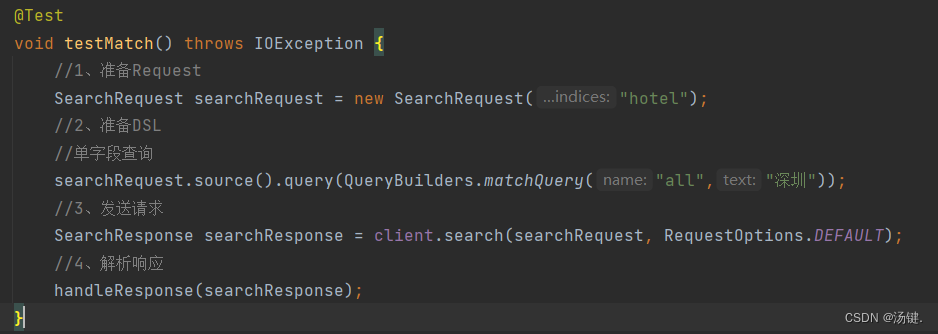
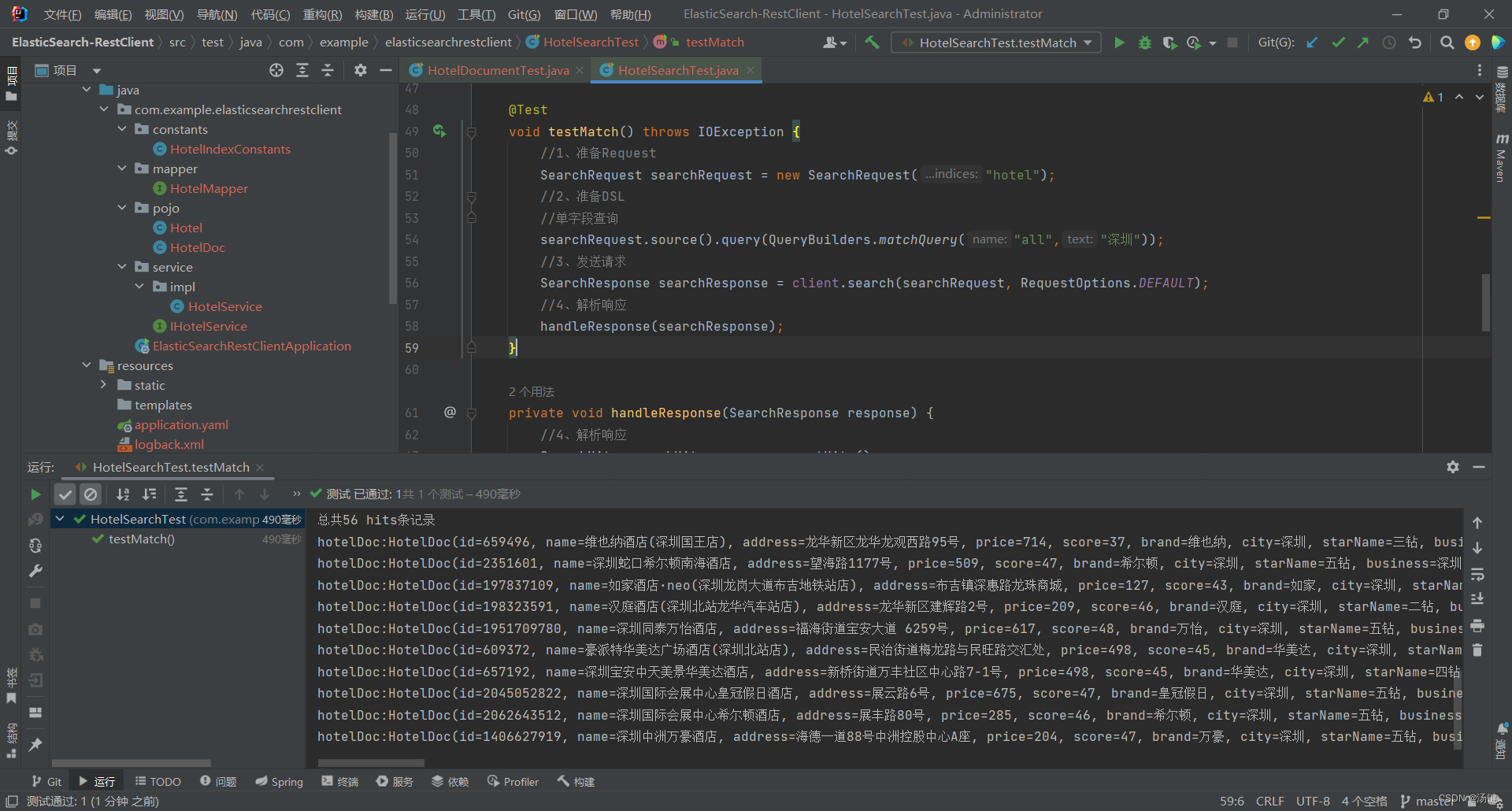
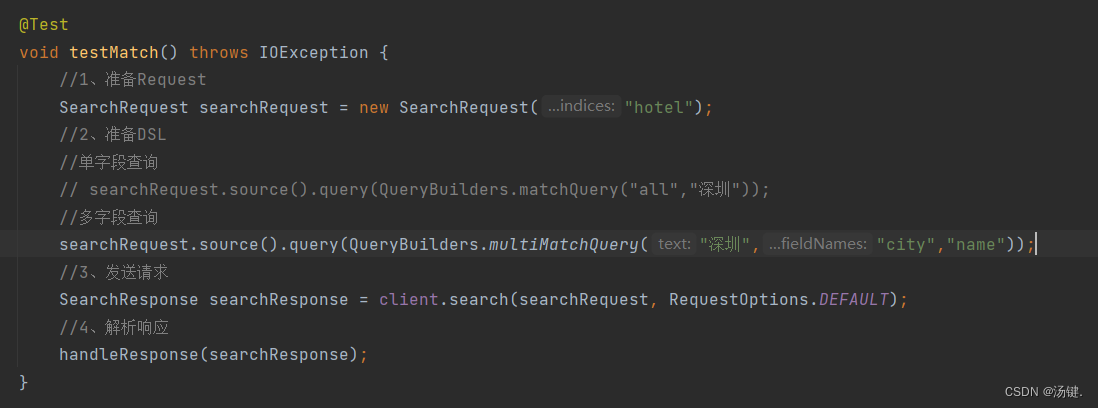
- 因此,Java代码上的差异主要是request.source().query()中的参数
- 同样是利用QueryBuilders提供的方法
-
查询文档-精确查询
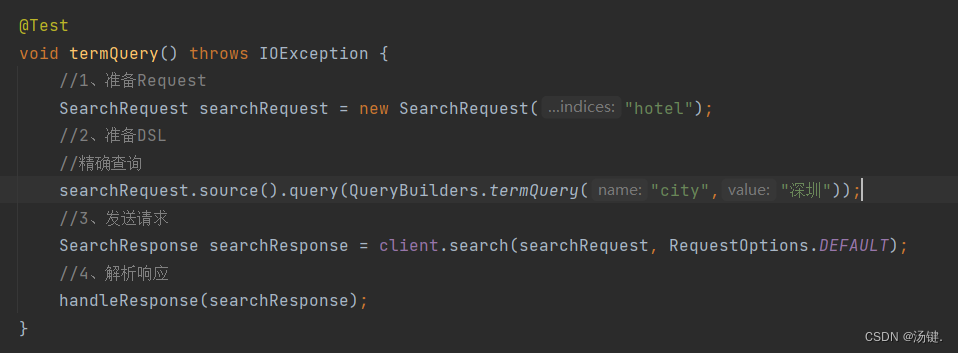
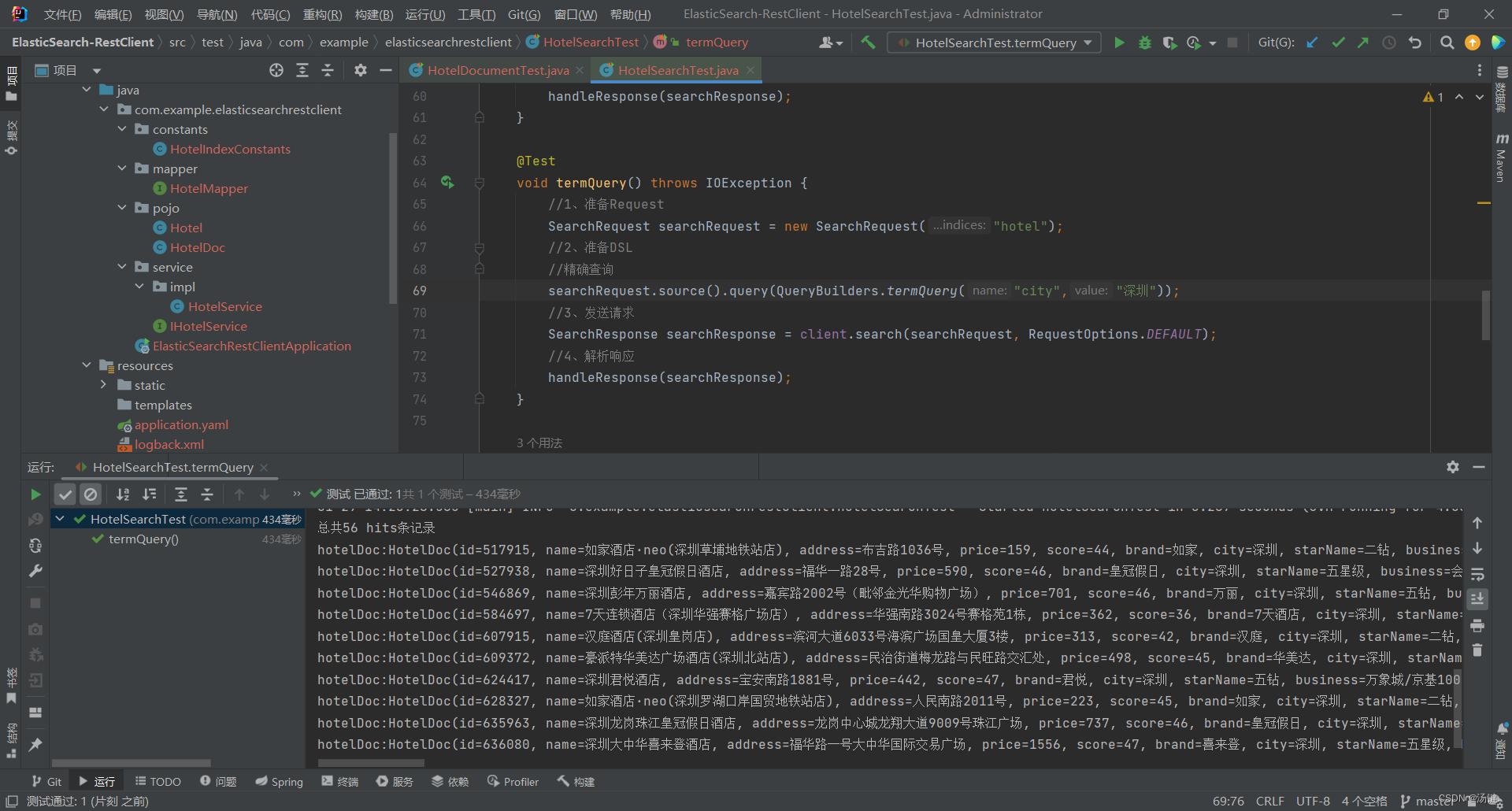
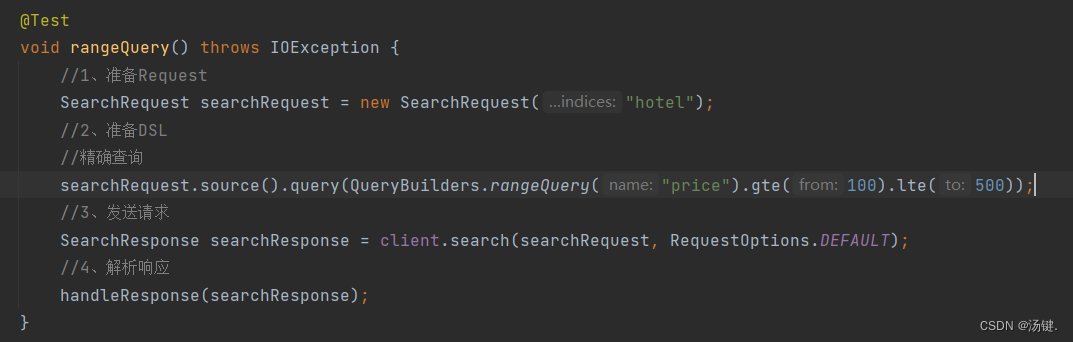
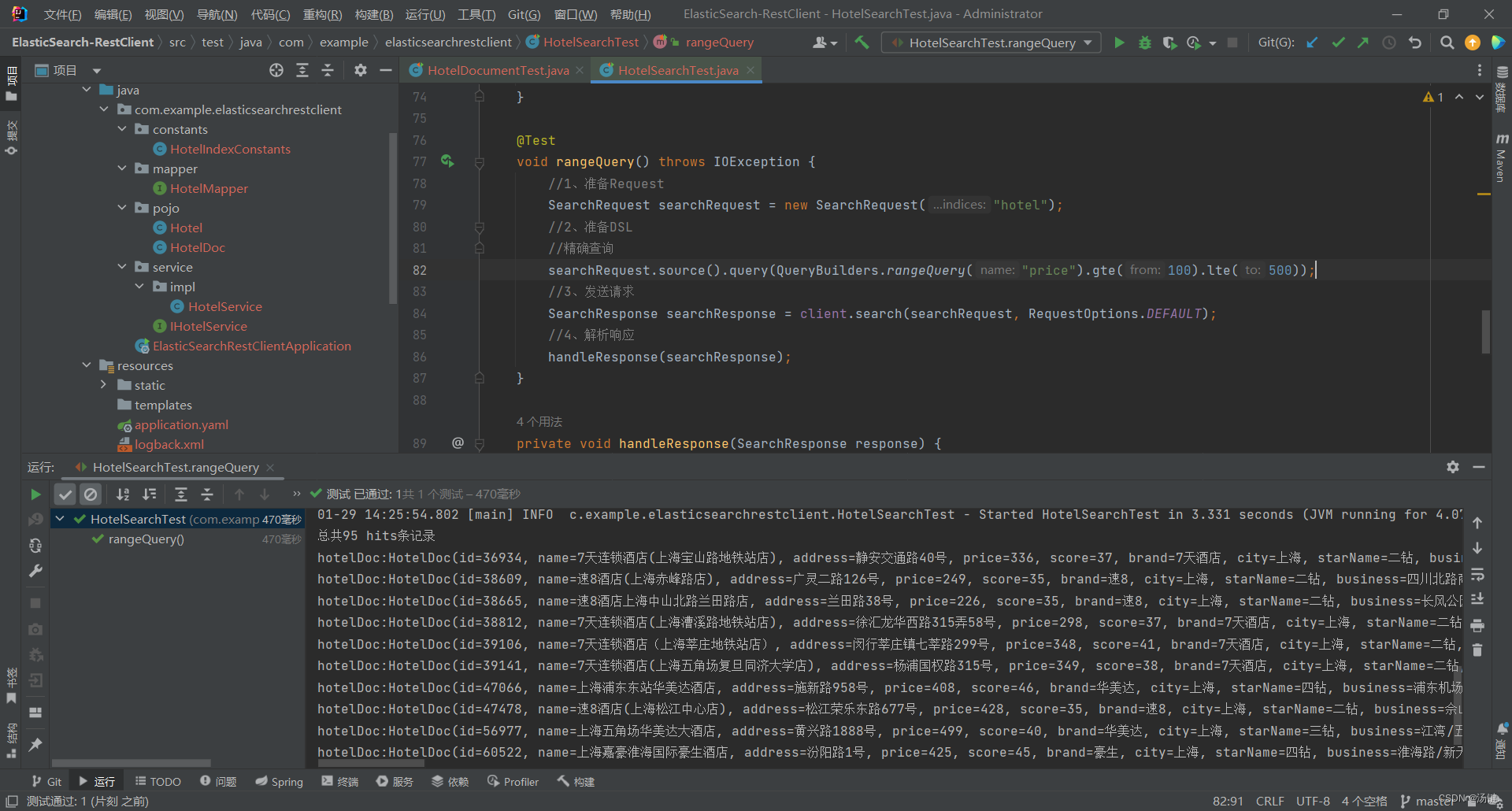
- 精确查询主要是两者:
- term:词条精确匹配
- range:范围查询
- 与之前的查询相比,差异同样在查询条件,其它都一样
-
查询文档-布尔查询
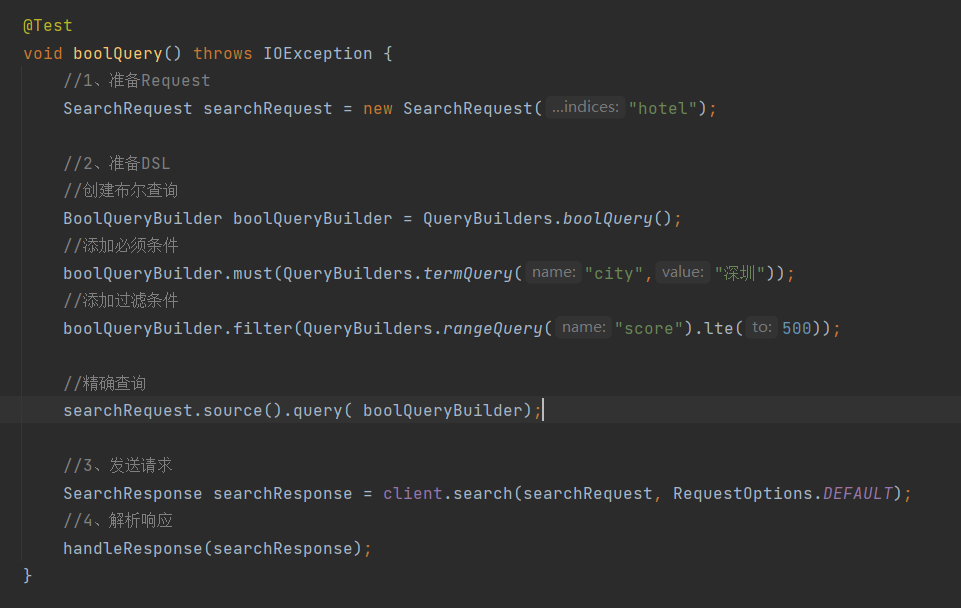
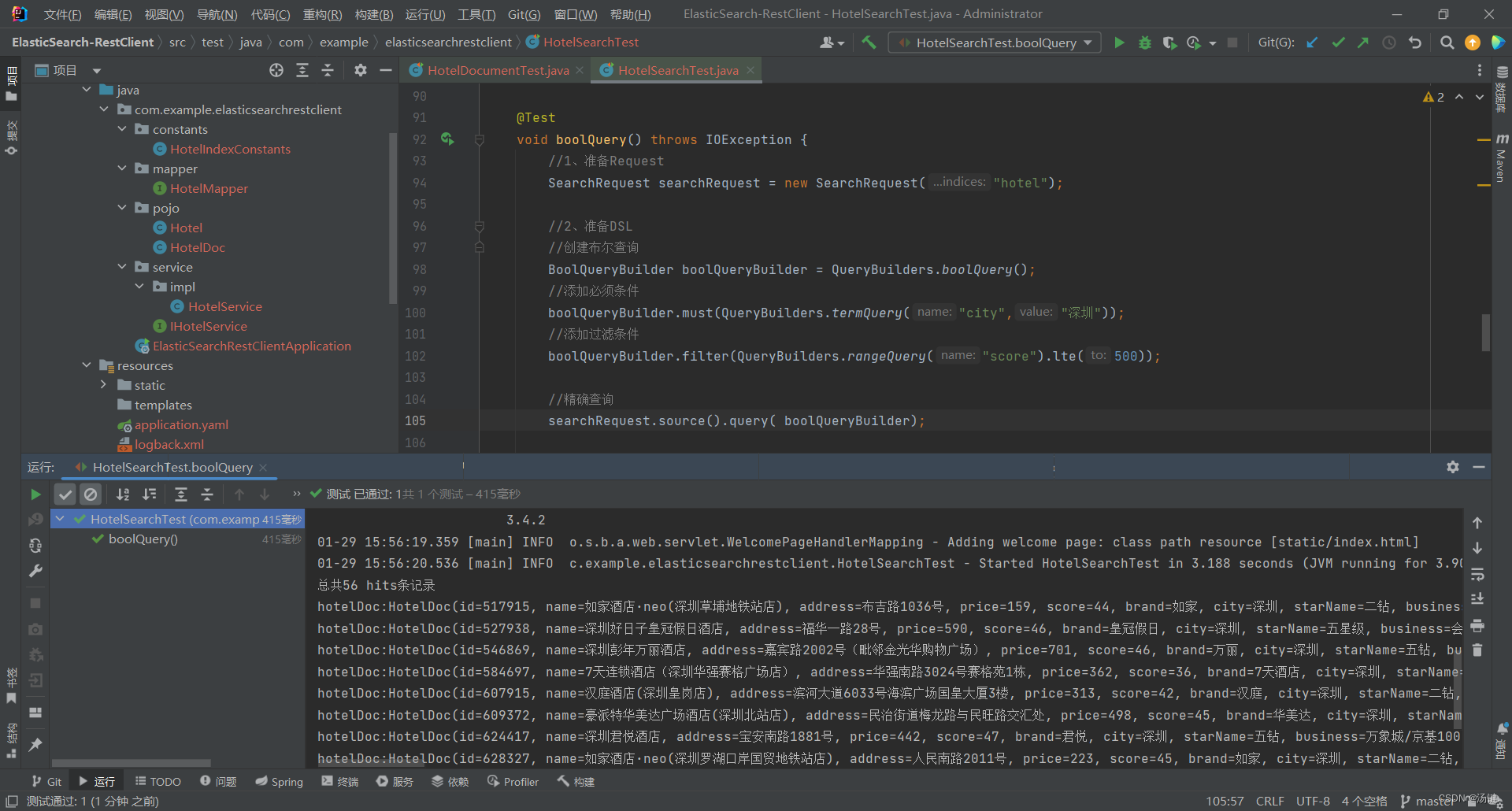
- 布尔查询是用must、must_not、filter等方式组合其它查询
-
查询文档-排序和分页
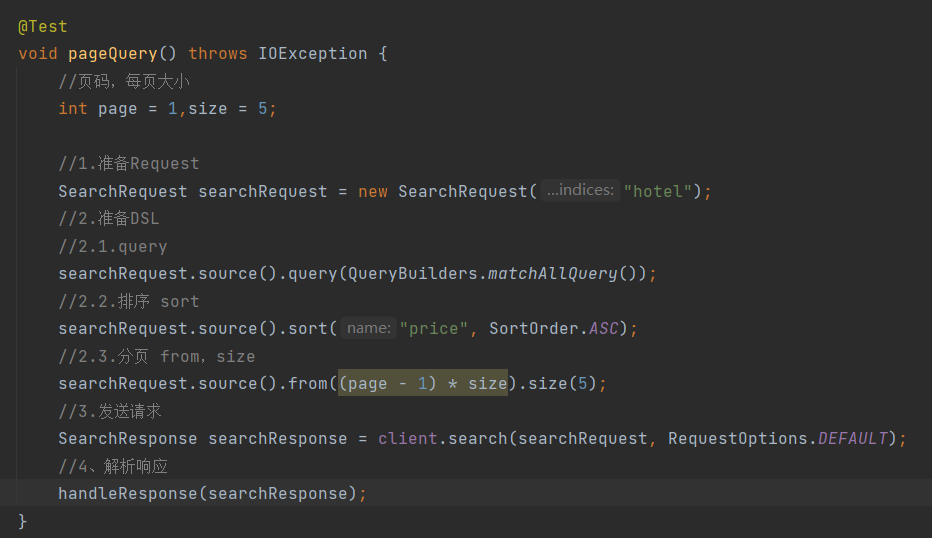
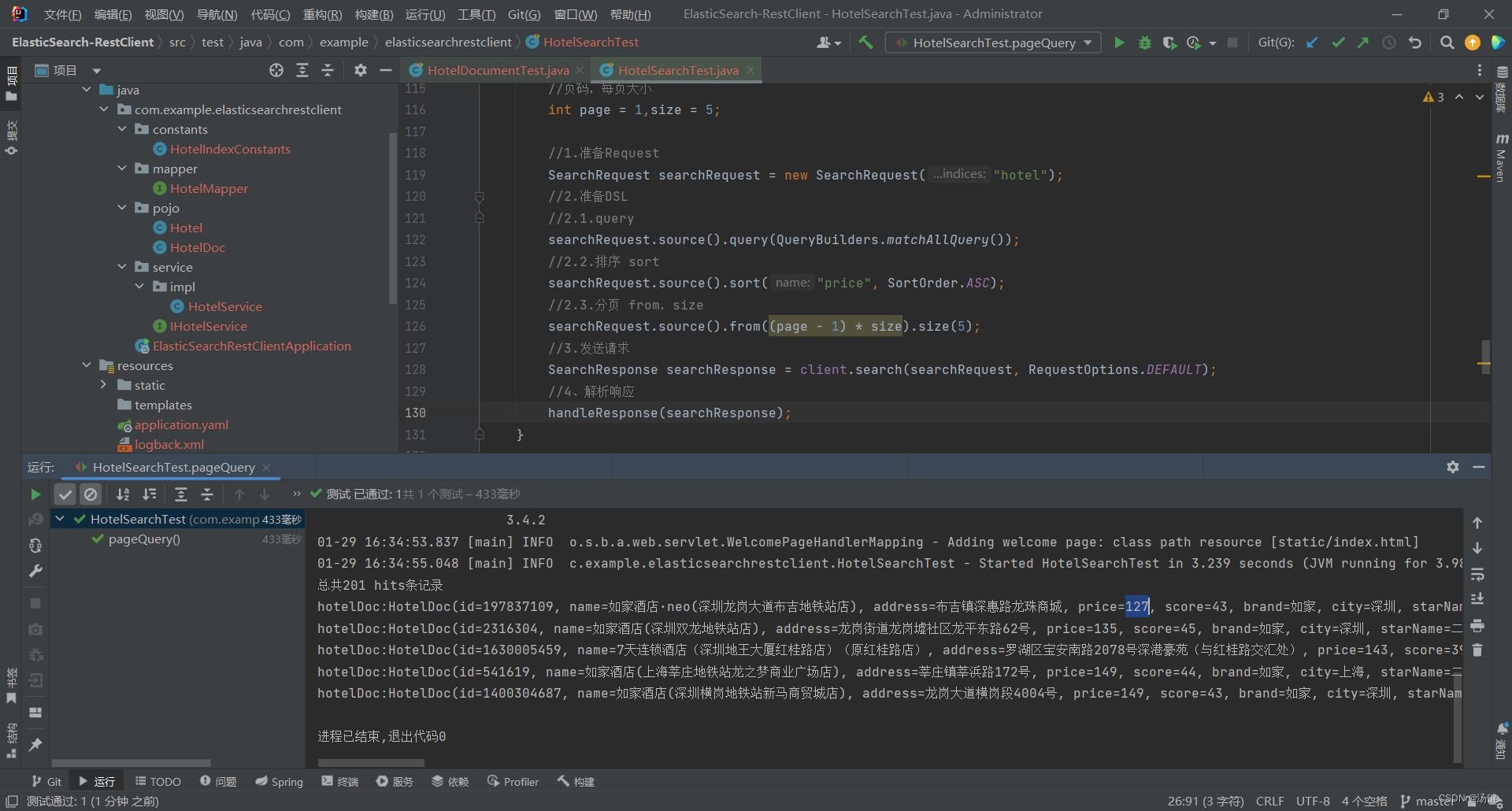
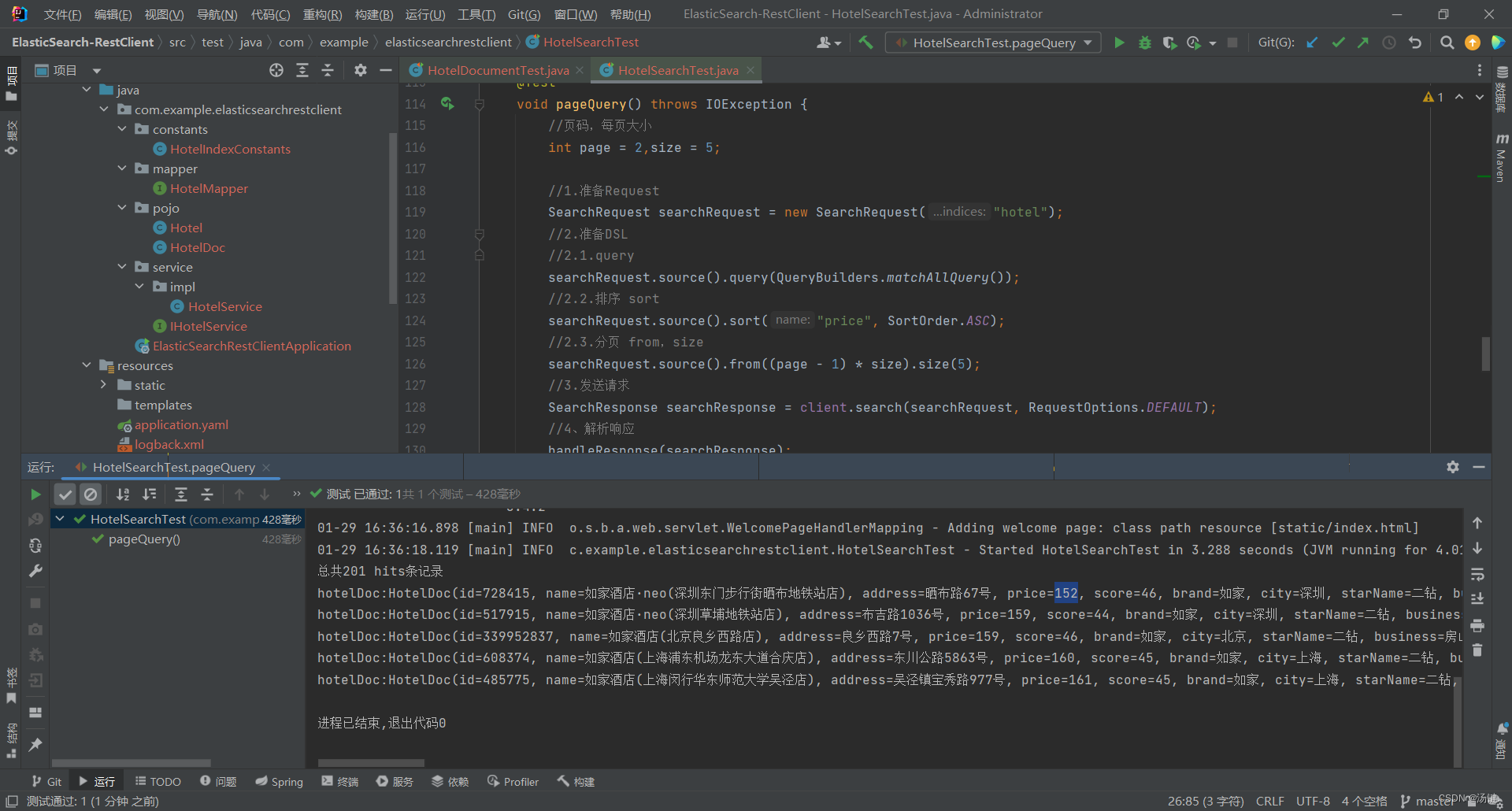
- 搜索结果的排序和分页是与query同级的参数
- 因此同样是使用request.source()来设置
-
查询文档-高亮显示
- 高亮的代码与之前代码差异较大,有两点:
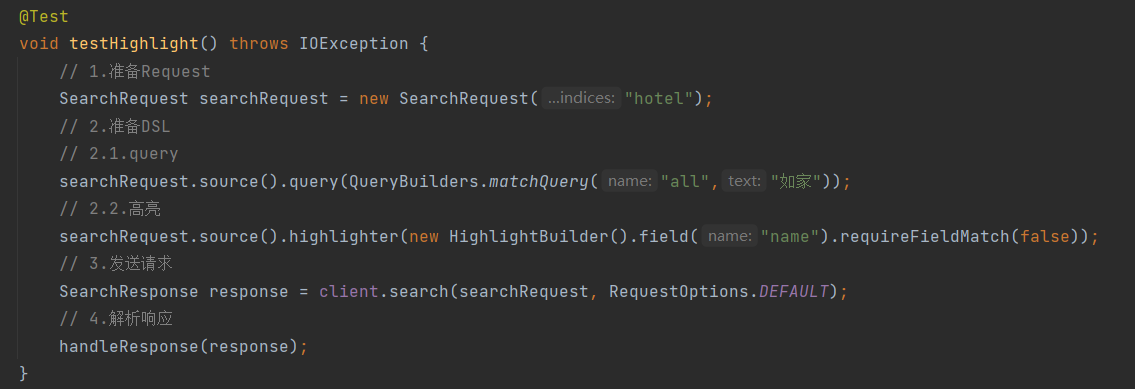
- 查询的DSL:其中除了查询条件,还需要添加高亮条件,同样是与query同级
- 结果解析:结果除了要解析_source文档数据,还要解析高亮结果
- 高亮请求构建
- 高亮结果解析

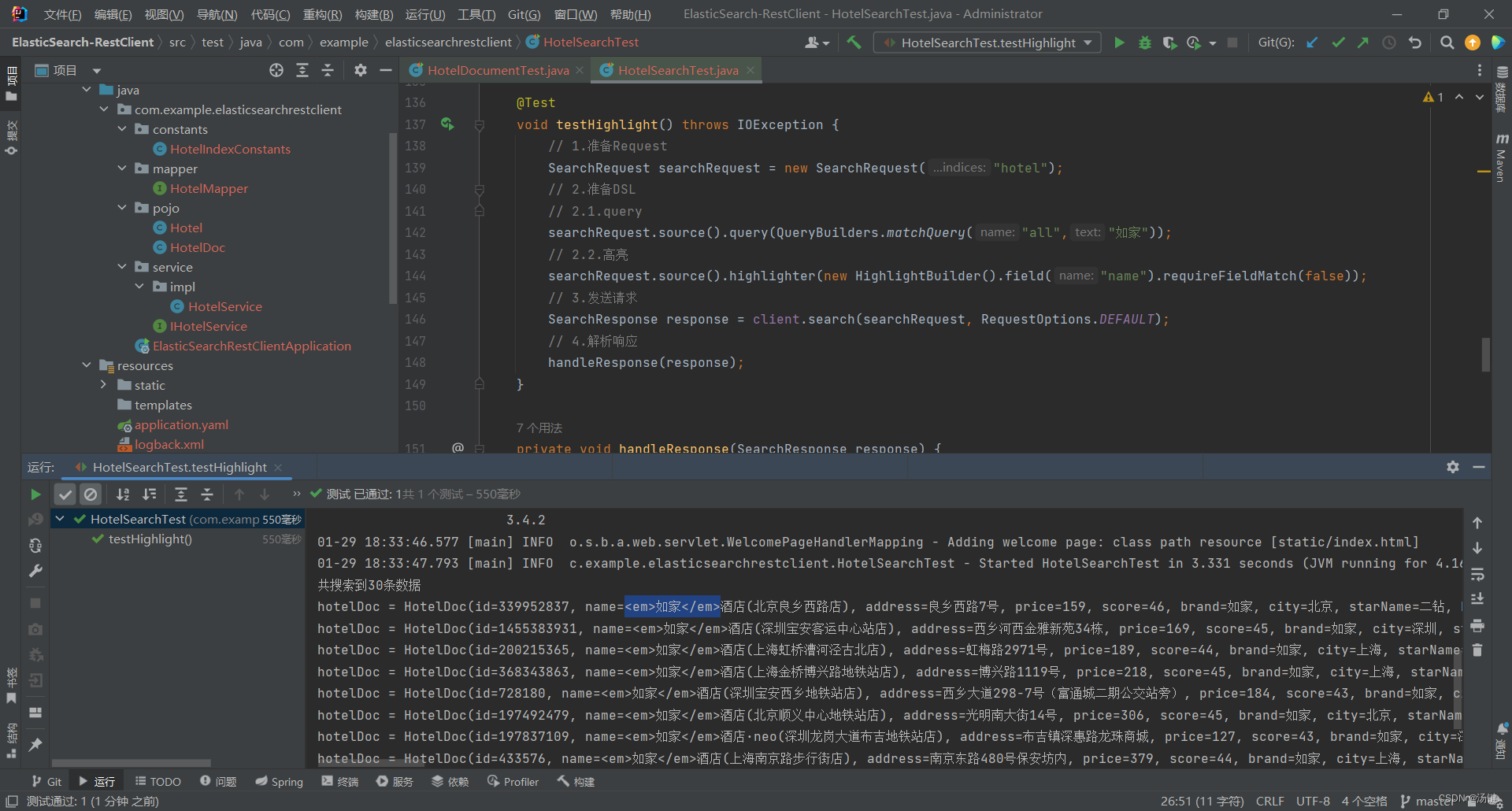
- 高亮的结果与查询的文档结果默认是分离的,并不在一起
- 因此解析高亮的代码需要额外处理
- 代码解读:
- 第一步:从结果中获取source;hit.getSourceAsString(),这部分是非高亮结果,json字符串;还需要反序列为HotelDoc对象
- 第二步:获取高亮结果;hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值
- 第三步:从map中根据高亮字段名称,获取高亮字段值对象HighlightField
- 第四步:从HighlightField中获取Fragments,并且转为字符串;这部分就是真正的高亮字符串了
- 第五步:用高亮的结果替换HotelDoc中的非高亮结果