文章目录
- 一、 06.26 周三
- 1.1)问题01:怎么在mysql的命令行中查询出来 python能使用的元祖结果集
- 1.2)问题02:python中 set()是什么,怎么使用
- 二、06.27 周四
- 2.1)问题01:shell 并发执行
- 2.2)问题02:python 并发执行一段程序
- 2.2.1)遇到的问题及解决:
- 2.3)问题03:python中运行 shell命令
- 三、06.29 周六
- 3.1)问题01:Python运行报错处理
- 重现错误
- 修复方法
- 正确使用示例
- 3.2)问题02:python3 list转字符串
- 假设有一个数字列表
- 先将数字列表中的元素转换为字符串,然后用join方法连接,用逗号分隔
- 3.3)问题03:Python中的异常处理是怎样的?
- 四、06.30 周日
- 4.1)问题01: Spring框架中Bean的注解有哪些?
- 4.2) 问题02: Python3中的函数入参中的 一个*,两个*代表什么含义
- 一个星号 (`*args`)
- 示例
- 两个星号 (`**kwargs`)
- 示例
- 综合示例
- 总结
一、 06.26 周三
1.1)问题01:怎么在mysql的命令行中查询出来 python能使用的元祖结果集
在 MySQL 的命令行中,您可以执行查询并使用SELECT语句来检索数据。如果您想要获取一个 Python 可以使用的元组结果集,可以使用 MySQL 命令行客户端的--skip-column-names选项来禁用列名,并且使用\G选项来以垂直方式显示结果。
下面是一个示例,假设您有一个名为users的表,其中包含id和name列:
SELECT id, name FROM users;
如果您想要以元组形式显示结果集,可以这样做:
mysql -u your_username -p your_database -e "SELECT id, name FROM users;" --skip-column-names | sed 's/\t/,/g' | sed 's/^/(/' | sed 's/$/)/' | sed 's/\n/,/g' | sed 's/,,/),(/g'
这将以元组形式显示结果集,例如(1, 'Alice'),(2, 'Bob'),(3, 'Charlie')。您可以将这些结果集复制到 Python 代码中并将其用作元组。
1.2)问题02:python中 set()是什么,怎么使用
在Python中,set()是一个内置函数,用于创建集合对象。集合是一种无序、不重复的数据结构。你可以使用set()函数来创建空集合或从其他可迭代对象(如列表、元组等)创建集合。
以下是一些示例用法:
- 创建空集合:
my_set = set()
- 从列表创建集合:
my_list = [1, 2, 3, 1, 2]
my_set = set(my_list)
print(my_set) # 输出: {1, 2, 3}
- 添加元素到集合:
my_set.add(4)
print(my_set) # 输出: {1, 2, 3, 4}
- 从字符串创建集合:
my_string = "hello"
my_set = set(my_string)
print(my_set) # 输出: {'o', 'h', 'e', 'l'}
通过set()函数,你可以方便地操作集合对象,进行集合运算(如并集、交集、差集等)。
二、06.27 周四
2.1)问题01:shell 并发执行
在Shell脚本中,可以使用&符号来实现并发执行多个命令或任务。这样可以让多个命令同时运行,而不必等待一个命令执行完毕后再执行下一个命令。下面是一个简单的示例:
#!/bin/bash
# Command 1 runs in the background
command1 &
# Command 2 runs in the background
command2 &
# Wait for all background processes to finish
wait
在这个示例中,command1 和 command2 是两个要并发执行的命令。通过在命令末尾加上&符号,可以让它们在后台同时运行。wait命令用于等待所有后台进程执行完毕。
2.2)问题02:python 并发执行一段程序
在 Python 中,可以使用多线程或多进程来实现并发执行一段程序。以下是使用 concurrent.futures 模块中的 ThreadPoolExecutor 和 ProcessPoolExecutor 实现并发执行的示例:
使用 ThreadPoolExecutor 实现多线程并发执行:
import concurrent.futures
def your_function():
# Your code here
print("Executing your function")
# Create a ThreadPoolExecutor with 5 threads
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Submit your function to the executor
future = executor.submit(your_function)
# Get the result (this will block until the function is done)
result = future.result()
使用 ProcessPoolExecutor 实现多进程并发执行:
import concurrent.futures
def your_function():
# Your code here
print("Executing your function")
# Create a ProcessPoolExecutor with 5 processes
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
# Submit your function to the executor
future = executor.submit(your_function)
# Get the result (this will block until the function is done)
result = future.result()
这些示例展示了如何使用 ThreadPoolExecutor 和 ProcessPoolExecutor 来实现并发执行一段程序。根据需要选择线程或进程执行模式。
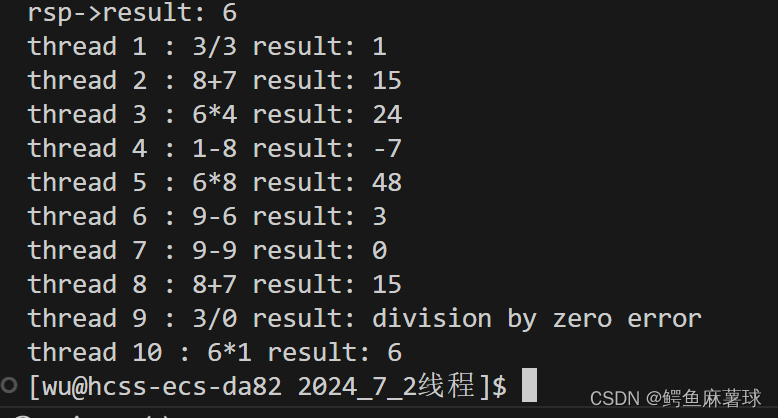
2.2.1)遇到的问题及解决:
ModuleNotFoundError: No module named ‘concurrent.futures’; ‘concurrent’ is not a package
这错误通常是由于在Python 2中引入的concurrent.futures模块在Python 3中被删除导致的。
确保你正在使用Python 3,并尝试以下修复方法:
-
使用Python 3: 确保你的Python环境是Python 3。
-
尝试使用ThreadPoolExecutor和ProcessPoolExecutor的替代方法:如果
concurrent.futures不可用,你可以尝试使用threading模块来实现多线程,并使用multiprocessing模块来实现多进程。这两个模块是Python标准库的一部分,应该可以在任何Python环境中使用。
下面是一个使用threading模块的示例:
import threading
def your_function():
print("Executing your function")
# 创建并启动5个线程
threads = []
for _ in range(5):
thread = threading.Thread(target=your_function)
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
这种方法可以在不使用concurrent.futures的情况下实现并发执行。
2.3)问题03:python中运行 shell命令
在Python中,你可以使用subprocess模块来运行Shell命令
当你需要将命令和参数组合成一个字符串时,你可以使用shell=True参数来运行Shell命令。这样可以让你直接将命令和参数组合成一个字符串作为参数传递给subprocess.run()函数。下面是一个示例:
import subprocess
# 组合命令和参数成一个字符串
command = "ls -l"
# 运行Shell命令
result = subprocess.run(command, shell=True, stdout=subprocess.PIPE, text=True)
# 打印命令的输出
print(result.stdout)
在这个示例中,我们将命令和参数组合成一个字符串"ls -l",然后将shell=True传递给subprocess.run()函数,以便直接运行这个命令。这样就可以将命令和参数放在一起。
三、06.29 周六
3.1)问题01:Python运行报错处理
>>> range_obj = range(3)
>>> list1= list(ra)
raise range( range_obj
>>> list1= list(range_obj)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list' object is not callable
解决办法:
出现 TypeError: 'list' object is not callable 错误,通常是因为在代码的其他地方已经定义了一个名为 list 的变量,并且该变量的值是一个列表。这会覆盖内置的 list 函数,从而导致无法调用内置的 list 函数。
要解决这个问题,请检查你的代码,确保没有定义一个名为 list 的变量。以下是一个示例说明了这个问题以及如何修复它:
重现错误
# 误定义一个名为 list 的变量
list = [1, 2, 3]
# 尝试使用 list() 函数会引发错误
range_obj = range(3)
list1 = list(range_obj) # TypeError: 'list' object is not callable
修复方法
- 重命名变量:避免使用
list作为变量名,以免覆盖内置的list函数。
# 避免使用 list 作为变量名
my_list = [1, 2, 3]
# 使用内置的 list() 函数将 range 对象转换为列表
range_obj = range(3)
list1 = list(range_obj)
print(list1) # 输出:[0, 1, 2]
- 删除错误的变量定义:如果已经定义了
list变量,可以通过del关键字删除它,以恢复对内置list函数的访问。
# 删除误定义的 list 变量
del list
# 使用内置的 list() 函数将 range 对象转换为列表
range_obj = range(3)
list1 = list(range_obj)
print(list1) # 输出:[0, 1, 2]
正确使用示例
确保没有覆盖 list 函数,并正确使用它将 range 对象转换为列表。
# 确保没有覆盖内置的 list 函数
# 不要定义变量名为 list
range_obj = range(3)
list1 = list(range_obj)
print(list1) # 输出:[0, 1, 2]
通过确保不使用内置函数的名称作为变量名,可以避免这种错误并正确使用 Python 的内置函数。
3.2)问题02:python3 list转字符串
假设有一个数字列表
num_list = [1, 2, 3, 4, 5]
先将数字列表中的元素转换为字符串,然后用join方法连接,用逗号分隔
result = ', '.join(map(str, num_list))
print(result)
3.3)问题03:Python中的异常处理是怎样的?

try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')
主动抛异常,使用 raise
x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
四、06.30 周日
4.1)问题01: Spring框架中Bean的注解有哪些?
Spring 框架提供了多种 Bean 注解,下面列举了一些常用的注解:
-
@Component:用于标注普通的 Spring Bean。它是一种通用的构造型注解,可以用于任何 Spring Bean。 -
@Repository:用于标注数据访问层(DAO)的 Bean。这个注解是@Component的特化版本,用于标注数据访问组件。 -
@Service:用于标注业务层的 Bean。这个注解是@Component的特化版本,用于标注业务层组件。 -
@Controller:用于标注 Web 层的 Bean。这个注解是@Component的特化版本,用于标注控制器组件。 -
@Configuration:用于标注配置类。被标注的类会被 Spring 容器当作配置类,并用于生成 Bean 实例。 -
@Bean:用于标注方法,该方法会返回一个要纳入 Spring 容器管理的 Bean 实例。通常与@Configuration注解一起使用。 -
@Scope:用于指定 Bean 的作用域,如 singleton、prototype 等。 -
@Qualifier:用于为 Bean 提供限定符,以区分多个同类型的 Bean。 -
@Value:用于注入外部的属性值,如配置文件中的值。 -
@Autowired:用于自动装配 Bean 依赖关系。
这些是 Spring 框架中常用的 Bean 注解,它们可以帮助我们更加便捷地管理 Spring Bean 的生命周期和依赖关系。当然,还有一些其他的注解也很有用,具体可以根据实际需求进行选择和使用。
4.2) 问题02: Python3中的函数入参中的 一个*,两个*代表什么含义
在Python中,函数参数前的一个星号 (*) 和两个星号 (**) 有特殊的含义,用于处理不定数量的参数。
一个星号 (*args)
一个星号用于传递可变数量的位置参数。参数名前的一个星号 * 会将传递给函数的所有位置参数收集到一个元组中。
示例
def example_function(*args):
for arg in args:
print(arg)
example_function(1, 2, 3, 4)
输出:
1
2
3
4
在这个例子中,*args 收集了所有传递的位置参数 (1, 2, 3, 4) 并将其作为一个元组传递给函数。
两个星号 (**kwargs)
两个星号用于传递可变数量的关键字参数。参数名前的两个星号 ** 会将传递给函数的所有关键字参数收集到一个字典中。
示例
def example_function(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
example_function(name="Alice", age=30, city="New York")
输出:
name: Alice
age: 30
city: New York
在这个例子中,**kwargs 收集了所有传递的关键字参数并将其作为一个字典传递给函数。
综合示例
你也可以在同一个函数中同时使用 *args 和 **kwargs,它们可以一起处理位置参数和关键字参数。
def example_function(*args, **kwargs):
print("args:", args)
print("kwargs:", kwargs)
example_function(1, 2, 3, name="Alice", age=30)
输出:
args: (1, 2, 3)
kwargs: {'name': 'Alice', 'age': 30}
总结
*args用于接收任意数量的位置参数,并将其作为一个元组传递。**kwargs用于接收任意数量的关键字参数,并将其作为一个字典传递。
这些特性使得Python函数能够更灵活地处理不同数量和类型的参数。