样例pdf
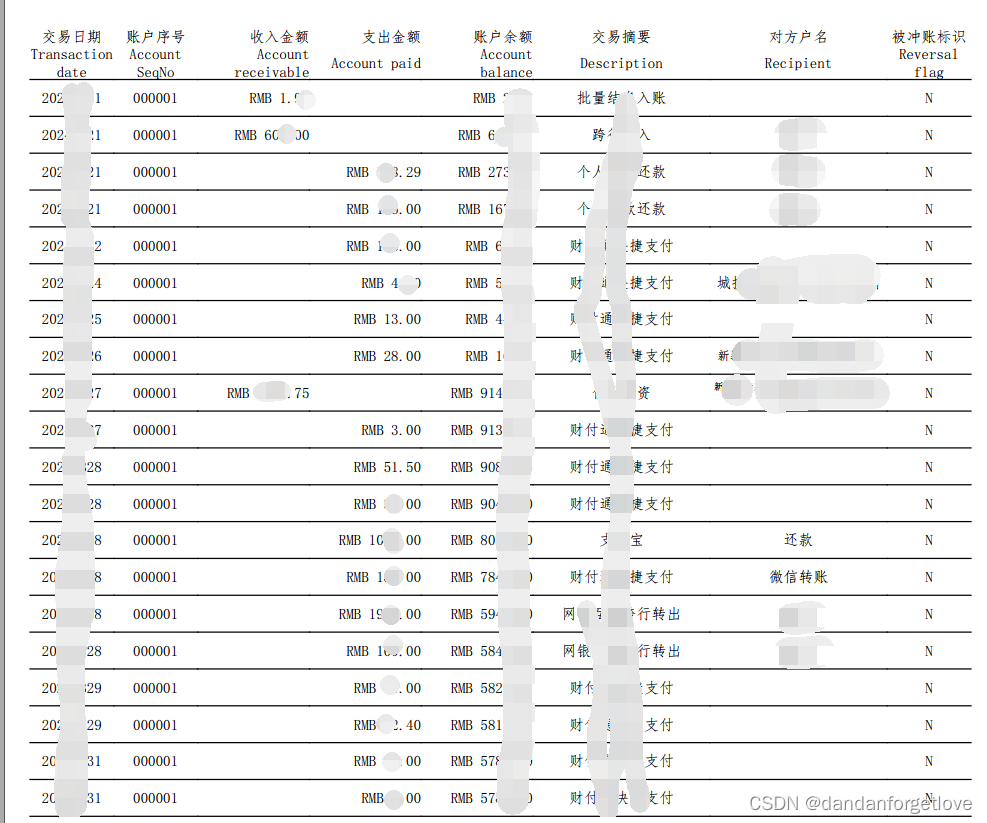
直接使用文本提取效果:
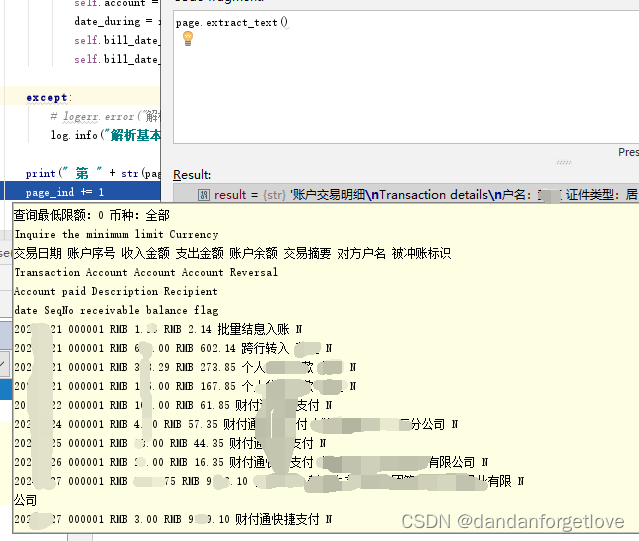
使用表格提取
根据提取的文本信息是没办法获取到表格数据的,太乱了。尤其是 3 4列。
解决:
自行画线,根据画线进行提取。
效果:
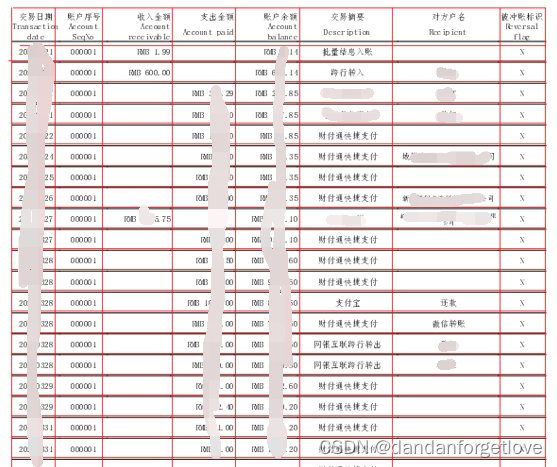
思路:
1.根据表头进行画竖线
2.根据行坐标画横线
3.根据坐标放入单元格的list中
4.拼接单元格文字。
问题:
根据表头画竖线,可能内容超出表头左右坐标。
解决办法:根据内容进行特殊匹配。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import re
import pdfplumber
import logging as log
class PDF(object):
file_path = None
config = {}
bill_date_begin = None
bill_date_end = None
parse_data = []
unit = None
trans_during = None
def __new__(cls, *args, **kwargs):
return super().__new__(cls)
def parse(self):
try:
with pdfplumber.open(self.file_path) as pdf:
page_ind = 1
log.info(" 发现总页数:{}".format(str(page_ind)))
for index, page in enumerate(pdf.pages):
print(" 第 " + str(page_ind) + " 页: ")
page_ind += 1
explicit_vertical_lines = []
explicit_horizontal_lines = []
explicit_horizontal_lines_y_line = []
explicit_horizontal_lines_h_line = []
explicit_horizontal_lines_keys = []
lines_dict = {}
table_begin = False
ts_y_list = {"jyzy": {"y": [-1, -1]}}
table_top = None
for ind, char in enumerate(page.chars):
next3Text = ""
if ind <= (len(page.chars) - 3):
next3Text = page.chars[ind]["text"] + page.chars[ind + 1]["text"] + page.chars[ind + 2]["text"]
if next3Text.find("交易日") > -1:
table_begin = True
if table_begin is False:
continue
if ind >= 2:
text = page.chars[ind - 2]["text"] + page.chars[ind - 1]["text"] + page.chars[ind]["text"]
if text.find("易日期") > -1 or text.find("出金额") > -1 or text.find("入金额") > -1 or text.find("户余额") > -1 or text.find("账标识") > -1 or text.find("户序号") > -1:
# print(text)
lines_dict = char
explicit_vertical_lines.append({
"x0": lines_dict["x1"] + 2,
"x1": lines_dict["x1"] + 2,
"y0": lines_dict["y0"],
"top": lines_dict["top"] - 5,
"bottom": lines_dict["bottom"] + 700,
"height": lines_dict["height"],
"orientation": "v",
"object_type": "line",
"page_number": index
})
table_top = lines_dict["top"] - 5
explicit_horizontal_lines_h_line.append(lines_dict["x1"] + 2)
elif text.find("交易日") > -1:
# print(text)
lines_dict = page.chars[ind - 2]
put_dic = {
"x0": lines_dict["x0"] - 8,
"x1": lines_dict["x0"] - 8,
"y0": lines_dict["y0"],
"top": lines_dict["top"] - 5,
"bottom": lines_dict["bottom"] + 700,
"height": lines_dict["height"],
"orientation": "v",
"object_type": "line",
"page_number": index
}
explicit_vertical_lines.append(put_dic)
explicit_horizontal_lines_h_line.append(lines_dict["x0"] - 8)
elif text.find("被冲账") > -1:
# print(text)
lines_dict = page.chars[ind - 2]
explicit_vertical_lines.append({
"x0": lines_dict["x0"] - 1,
"x1": lines_dict["x0"] - 1,
"y0": lines_dict["y0"],
"top": lines_dict["top"] - 5,
"bottom": lines_dict["bottom"] + 700,
"height": lines_dict["height"],
"orientation": "v",
"object_type": "line",
"page_number": index
})
explicit_horizontal_lines_h_line.append(lines_dict["x0"] - 8)
# 竖线修复
if text.find("易摘要") > -1 or text.find("对方户") > -1:
if text.find("易摘要") > -1:
ts_y_list["jyzy"]["y"][0] = char["x1"] + 2
# ts_y_list["jyzy"]["y"][0] = char["x1"] + char["x1"] - char["x0"]
elif text.find("对方户") > -1:
ts_y_list["jyzy"]["y"][1] = page.chars[ind-2]["x0"] - 1
ts_y_list["jyzy"]["mid"] = page.chars[ind-2]
# 判断是否添加过该横线
if char["y0"] not in explicit_horizontal_lines_keys:
text = page.chars[ind - 2]["text"] + page.chars[ind - 1]["text"] + page.chars[ind]["text"]
if text.find("标识T") > -1 or text.find("leA") > -1:
explicit_horizontal_lines_keys.append(char["y0"])
continue
# 特殊竖线,根据表头坐标和内容坐标对比,取最左的那一个作为竖线的坐标
if ts_y_list["jyzy"]["y"][0] != -1 and ts_y_list["jyzy"]["y"][1] != -1 and char["x0"] > ts_y_list["jyzy"]["y"][0] and char["x1"] < ts_y_list["jyzy"]["y"][1]:
if "mid" in ts_y_list["jyzy"].keys():
if ts_y_list["jyzy"]["mid"]["x0"] > char["x0"]:
ts_y_list["jyzy"]["mid"] = char
else:
ts_y_list["jyzy"]["mid"] = char
lines_dict_h = char
if text.find("ag2") > -1:
explicit_horizontal_lines.append({
"x0": 579,
"x1": lines_dict_h["x1"] - 15,
"y0": lines_dict_h["y0"],
"y1": lines_dict_h["y1"],
"top": lines_dict_h["bottom"] + 5,
"bottom": lines_dict_h["bottom"] + 5,
"height": lines_dict_h["height"],
"width": lines_dict_h["width"],
"orientation": "h",
"object_type": "line",
"page_number": index
})
explicit_horizontal_lines_y_line.append(lines_dict_h["bottom"] + 5)
elif next3Text.find("交易日") > -1 or (text.find("交易日") > -1 and index > 0):
explicit_horizontal_lines.append({
"x0": 579,
"x1": lines_dict_h["x1"] - 15,
"y0": lines_dict_h["y0"] if index == 0 else (lines_dict_h["y0"] - 5),
"y1": lines_dict_h["y1"],
"top": lines_dict_h["top"] - 5,
"bottom": lines_dict_h["top"] - 5,
"height": lines_dict_h["height"],
"width": lines_dict_h["width"],
"orientation": "h",
"object_type": "line",
"page_number": index
})
explicit_horizontal_lines_y_line.append(lines_dict_h["top"] + 5)
else:
if lines_dict_h["x1"] > 200:
continue
# 正常行数据添加横线
explicit_horizontal_lines.append({
"x0": 579, # 横线长度
"x1": lines_dict_h["x1"] - 12,
"y0": lines_dict_h["y0"],
"y1": lines_dict_h["y1"],
"top": lines_dict_h["bottom"] + 5,
"bottom": lines_dict_h["bottom"] + 5,
"height": lines_dict_h["height"],
"width": lines_dict_h["width"],
"orientation": "h",
"object_type": "line",
"page_number": index
})
explicit_horizontal_lines_y_line.append(lines_dict_h["bottom"] + 5)
explicit_horizontal_lines_keys.append(char["y0"])
for k, v in ts_y_list.items():
if "mid" in v.keys() and v["mid"]["x0"] != -1:
lines_dict = v["mid"]
explicit_vertical_lines.append({
"x0": lines_dict["x0"] -8,
"x1": lines_dict["x0"] -8,
"y0": lines_dict["y0"],
"top": table_top,
"bottom": lines_dict["bottom"] + 700,
"height": lines_dict["height"],
"orientation": "v",
"object_type": "line",
"page_number": index
})
explicit_horizontal_lines_h_line.append(lines_dict["x0"] - 1)
page.curves.clear()
page.lines.clear()
# 赋值画线
page.objects['line'] = explicit_vertical_lines + explicit_horizontal_lines
explicit_horizontal_lines_h_line.sort()
line_text = []
# 根据横线坐标 & 纵线坐标 ,判断单元格
for ind, y in enumerate(explicit_horizontal_lines_y_line):
if (ind + 1) == len(explicit_horizontal_lines_y_line):
continue
# 单元格内容组装
def get_this_cell_text(y, next_y):
this_y_line = []
for char in page.chars:
if char["bottom"] > y and char["bottom"] < next_y:
this_y_line.append(char)
cell_list = []
for ind_h, h in enumerate(explicit_horizontal_lines_h_line):
if (ind_h + 1) == len(explicit_horizontal_lines_h_line):
continue
next_h = explicit_horizontal_lines_h_line[ind_h+1]
cell_text = ""
for char in this_y_line:
if char["x0"] > h and char["x0"] < next_h:
cell_text += char["text"]
cell_list.append(cell_text)
return cell_list
next_y = explicit_horizontal_lines_y_line[ind + 1]
this_cell_text = get_this_cell_text(y, next_y=next_y)
line_text.append(this_cell_text)
# im = page.to_image()
# im.draw_rects(page.extract_words())
# im.draw_vline(location, stroke={color}, stroke_width=1)
# im.save("aa.png')
# 合并解析的数据
self.parse_data = self.parse_data + line_text
# 开始进行数据格式化
data_list = []
head_index = {'交易日期': -1, '账户序号': -1, '收入金额': -1, '支出金额': -1, '账户余额': -1, '交易摘要': -1, '对方户名': -1,
'被冲账标识': -1}
isTableRow = True
for ind, line in enumerate(self.parse_data):
if ind == 0:
for ind_c, cell in enumerate(line):
for k, v in head_index.items():
if cell.find(k) > -1:
head_index[k] = ind_c
continue
if "".join(s for s in line).find("第") > -1 and "".join(s for s in line).find("页") > -1:
continue
if "".join(s for s in line).find("交易日期Transactiodate") > -1 and "".join(s for s in line).find("账户序号nAccountSeqNo") > -1:
continue
if line[0] == "":
continue
if "".join(s for s in line).find("声明:") > -1:
isTableRow = False
if isTableRow is False:
continue
value_dict = {}
for k, v in head_index.items():
value_dict[k] = line[head_index[k]]
# print(value_dict)
currency = ""
amount = value_dict["收入金额"].replace(" ", "") if value_dict["收入金额"] != "" else value_dict["支出金额"].replace(" ", "")
balance_v = value_dict["账户余额"].replace(" ", "")
if balance_v is not None and len(balance_v) > 0:
balance_v = balance_v.replace(currency, "")
amount = amount.replace(currency, "")
data_one = {"trans_remark": value_dict["交易摘要"],
"currency": self.unit,
"trans_date":value_dict["交易日期"],
"trans_amount": amount,
"balance": balance_v,
"trans_place": '',
"opponent_mess": value_dict["对方户名"]}
data_list.append(data_one)
import json
print(json.dumps(data_list, ensure_ascii=False))
self.parse_data = data_list
except FileNotFoundError:
raise FileNotFoundError
except:
raise Exception
PDF(None, "3.pdf", "123432", {}).parse()