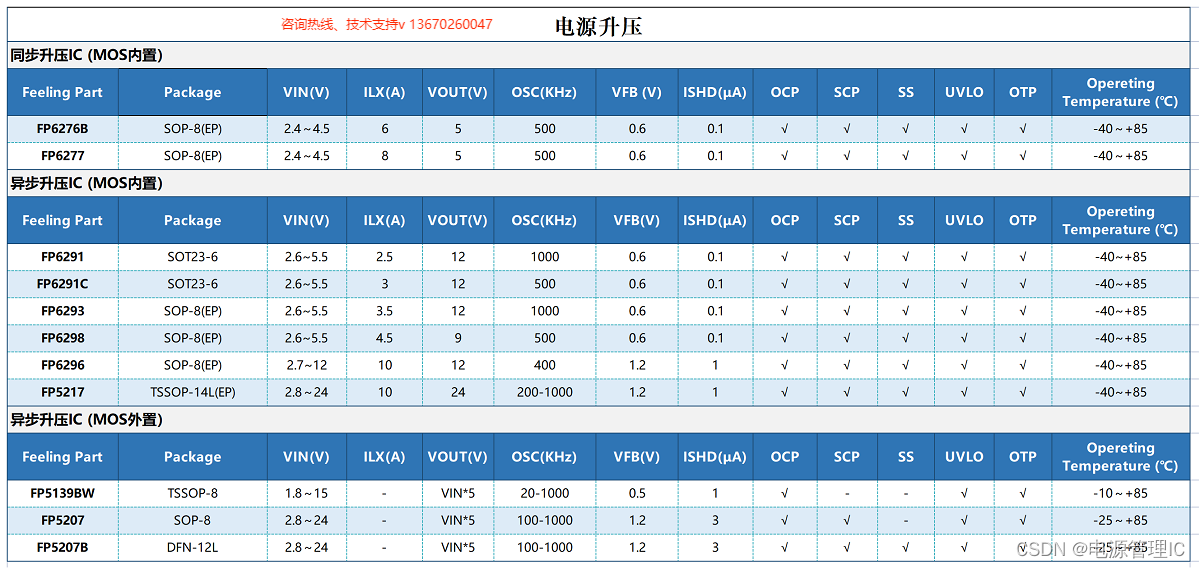
慢病精准预测:大模型 + 多模态融合
- 慢病预测算法拆解
- 子解法1:多模态数据集成
- 子解法2:实时数据处理与更新
- 子解法3:采用大型语言多模态模型(LLMMs)进行深度学习分析
- 慢病预测更多模态
论文:https://arxiv.org/pdf/2406.18087
演示:https://www.youtube.com/watch?v=oqmL9DEDFgA
传统的慢性病诊断涉及与医生面对面的咨询以识别疾病。然而,缺乏研究集中在使用临床笔记和血液测试值预测和开发应用系统。
我们收集了台湾医院数据库2017至2021年的五年电子健康记录(EHRs)作为人工智能数据库。
开发了一个基于大型语言多模态模型(LLMMs)的慢性病预测平台。
这个平台可以与前端网页和移动应用集成,还能连接到医院的后端数据库,提供实时的风险评估诊断。
我们使用多种模态数据,来处理常见的慢性疾病,如糖尿病、心脏病和高血压,进行多模态模型训练。
- 临床笔记:这些文本数据包含医生的详细观察和患者的病历描述,能够提供患者的历史病情和症状信息。
- 实验室测试结果:包括血液检测等生化指标,这些是量化数据,提供了关于患者当前健康状况的重要信息。
- 历史电子健康记录(EHR):可能包括患者过去的医疗记录、药物使用记录、手术历史等,这些数据有助于模型理解患者的整体健康轨迹。
以及使用了大模型,如BERT 、BiomedBERT、Flan-T5-large-770M 和 GPT-2 作为文本特征提取器。
-
在高血压的预测中,所有模型的表现都相对较低,其中BERT和BiomedBERT的精确度和F1分数均为0.35和0.32,而GPT-2的表现最差,精确度为0.29,F1分数为0.25。
-
对于心脏病的预测,GPT-2表现最好,精确度为0.81,召回率为0.85,F1分数为0.83。BiomedBERT也表现良好,其精确度、召回率和F1分数分别为0.76、0.75和0.75。
-
在糖尿病分类上,GPT-2与BiomedBERT表现较好,GPT-2的精确度为0.70,召回率为0.71,F1分数也为0.70;而BiomedBERT的召回率达到0.72,F1分数为0.67。
-
结论是,在临床记录,文本特征提取器,每个大模型在不同慢病上,效果都不同。最好是专门子领域微调过的。
接下来,我们将单一模态的临床笔记作为输入到LLMMs中,提取文本特征嵌入,并使用注意力模块将它们融合,用于最终的预测任务。
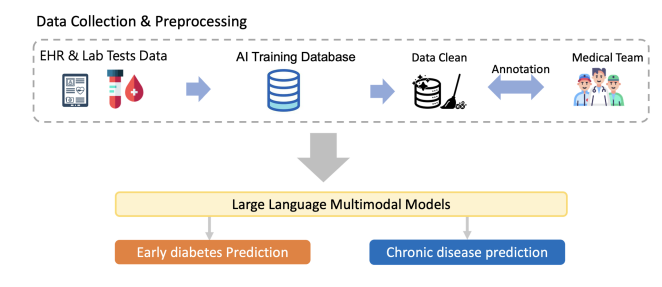
- 数据收集与预处理:从EHR和实验室测试数据开始,收集必要的信息。
- AI训练数据库的建立:包括数据清洗和医疗团队的注解,以确保数据的质量和适用性。
- 大型语言多模态模型(LLMMs):展示了如何使用LLMMs来从处理过的数据中提取特征,并用于预测如早期糖尿病和其他慢性疾病。

Web平台的四个主要界面:
- (a) 疾病风险界面:展示患者的糖尿病、高血压和心脏病风险评估。
- (b) 早期疾病预测界面:展示患者未来90、180、270和360天的糖尿病风险。
- © SHAP值解释界面:使用SHAP值来标识临床笔记中的关键风险因素。
- (d) 实验室数据提交界面:允许医生上传患者的血液测试数据。
慢病预测算法拆解
开发一个能够实时预测和警报慢性病风险的医疗诊断系统,以提高患者管理效率并支持临床决策。
解法涉及整合多模态数据以提高慢性病预测的准确性。
子解法1:多模态数据集成
特征:慢性病的预测需要综合多种数据源(如临床笔记、实验室测试结果)来增强预测模型的信息丰度。
- 原因:之所以采用多模态数据集成,是因为慢性病的表现和影响因素多样,需要多维度的数据支持以提高预测的全面性和准确性。
- 例子:通过结合EHR中的文本数据(如医生的临床笔记)和量化数据(如血液检测结果),LLMMs能够更全面地分析患者的健康状态,预测疾病发展。
对于血液测试数据,构建了一个深度神经网络(DNN)来获取血液表示。
为了更好地整合这两种模态,我们使用了多头注意力层来计算来自两个领域的嵌入的注意力得分和矩阵。
最后,采用全连接层来预测多种疾病。
子解法2:实时数据处理与更新
特征:慢性病管理需求对数据的时效性极高,需要系统能够实时处理和更新数据。
- 原因:之所以需要实时数据处理与更新,是因为慢性病状的快速变化需要及时调整治疗方案,以防病情恶化。
- 例子:系统通过实时同步最新的健康检查结果和临床记录到数据库,并即时进行数据分析,以便快速反馈给医生和患者潜在的健康风险。
子解法3:采用大型语言多模态模型(LLMMs)进行深度学习分析
特征:LLMMs能够处理和理解大规模和复杂的数据集,适用于提取临床文本和实验室数据中的关键特征。
- 原因:之所以使用LLMMs,是因为它们在处理复杂和大量的医疗数据方面具有优越性,可以捕捉深层次的模式和关联,提供精确的病症风险预测。
- 例子:LLMMs分析患者的历史数据和最新测试结果,使用深度学习技术识别出可能导致疾病恶化的关键指标,从而提前警告医生和患者采取预防措施。
在阅读和理解了文章内容之后,可以看到背后的模式是通过技术集成和数据智能处理来增强医疗预测系统的效能。
体现了医疗信息技术领域中对实时、精确医疗决策支持系统的需求增长。
例如,将实时数据处理与多模态数据分析相结合,可以实现更为动态和精准的疾病管理,这在处理慢性病如糖尿病或心血管疾病时尤为重要。
慢病预测更多模态
在慢性病预测中,考虑多模态数据是非常有益的,因为这可以显著增加预测的精确度和全面性。
以下是一些重要的数据模态,它们在慢性病预测中可以提供关键信息:
-
临床笔记和医疗记录:这些文本数据提供了患者的详细病史,包括症状描述、治疗反应、以及医生的观察和推论。
-
实验室测试结果:血液、尿液等生化检测结果提供了关于患者生理状况的具体量化数据,如血糖、胆固醇、肝功能指标等。
-
影像医学数据:包括X光、MRI、CT扫描等影像资料,这些图像数据能帮助评估器官的结构和功能状况,对于诊断如癌症、心脏病等疾病尤为重要。
-
生理监测数据:如心电图、血压监测、血糖监测等连续的生理参数监测,可以提供关于患者状况的实时数据。
-
可穿戴设备数据:随着技术的发展,越来越多的健康相关数据可以通过可穿戴设备收集,如活动量、心率、睡眠质量等,这些数据有助于理解患者的生活习惯和日常健康状况。
-
遗传信息:基因数据可以揭示个体对特定疾病的易感性,对于预测遗传性疾病或评估疾病风险具有重要价值。