文章目录
- 学习内容
- 0.大模型应用的流程
- 1.构建任务/领域的数据集
- 2.寻找备选模型
- 3.调整模型
- Prompt
- Fine-tuning
- PEFT
- RLHF
学习内容
- 根据自己的经验和课程的学习,系统的记录一下大模型落地的流程。
0.大模型应用的流程
- 构建任务/领域问题数据集
- 使用对应任务的语料测试效果,找到备选模型。
- 尝试调整模型:1.Prompt 2.Fine-tuning(SFT) 3.对齐人类反馈(使用多个答案返回哪个模型更好,PPO,DPO)
- 评估模型
- 应用:RAG,量化,压缩,剪枝,推理。
1.构建任务/领域的数据集
- 数据准备
- 最好是客观数据:书籍、期刊、研报、核实后的新闻等
- 数据量大小应按模型对应推荐大小准备,训练6b左右模型的经验:单任务最好是100-1000条数据进行LoRA微调,3-5个EPOCH就可以。领域数据最少1-2G + 通用领域的纯文本语料进行全量微调,1-2个EPOCH就可以。
- bench集的构建
- 从语料中寻找问题,知识方面由简单,中等,困难三个方面准备,逻辑方面由简单,复杂两个方面准备,再加入行业内常用问题,共计100-200个问答就可以了。一般来说,未经微调时,对于简单的领域问答集合ChatGLM的效果有60%左右,GPT一般是75-80%,我认为微调后能达到80%就算合格了。
- 获取Instruction DATA
- 已经存在的数据集 问答、翻译、摘要
- 人类提供答案
- 最优的大模型生成答案(人工筛选数据)
- 最优的大模型根据人的结果生成答案
2.寻找备选模型
- 就是一个一个试,一般对于中文任务微调来说ChatGLM和LLaMA好一些;阿里的模型我没试过,据说是分数机器,但是泛化性能一般;在企业的师兄说百川好用……存疑,可能只对特定数据有效。
3.调整模型
Prompt
方法:
- zero-shot:直接描述任务,给出问题就可以了。
- context few-shot:在上下文加入1-3个问答样例,一般不加入超过20个,但是可以尝试一下20左右的示例。
问题:
- context few-shot:
- 会让成本变高
- 利用太多上下文窗口(虽然模型支持的窗口越来越长,但是会占用跟多显存?)
- 只能做一个任务,泛化性能极差
Fine-tuning
- 一般可以做多任务微调
- 最好构建Instruction DATA:
- 构建任务描述(类似zero-shot)
- 改写label,例如评论分类中: 差评 -->这个产品不好用、这个产品难用、不好用、垃圾等。但在摘要等任务中不需要改写回答。
- 问答最好都具有多样性
- 遗忘:fine-tune之后只能按训练的格式、内容输出,原本可以做好的任务做不好了。表现形式:直接提现就是提高了一方面的能力,但其他方面能力下降了。
- 减少遗忘的方法:
- 加入通用数据训练,对专用模型可以做多任务训练,针对所需的能力增加数据
- LoRA,冻结层等方式减少对模型的改动,也可以使用动态学习率(尽量小一点的的学习率)
- 使用更大的模型(模型越小,遗忘越严重:这也是6B模型普遍不推荐微调的原因)
PEFT
高效参数训练方法:
-
LoRA
-
Prefix-tuning
-
Adapters
-
量化
-
微调GPT3所需的性能:96*V100,海量的存储(这之前经常被忽略),启动服务时间长(读取加载)
-
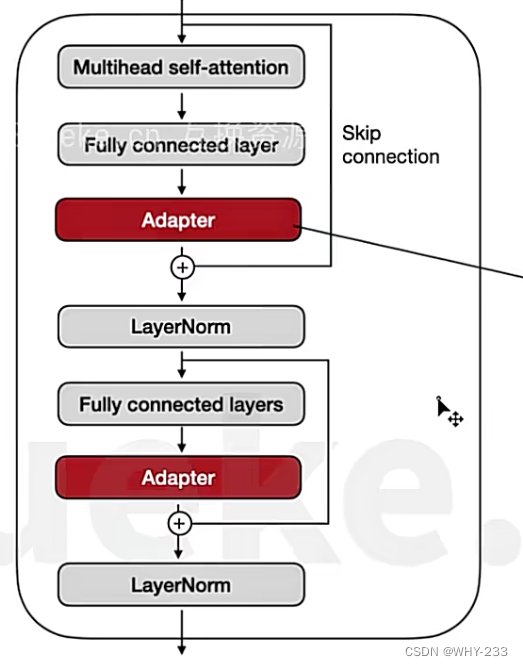
Adaptor Tuning:通过在TransformerFFN后增加额外的Adaptor层,只训练额外的Adaptor层。但是会增加推理时的成本。
-
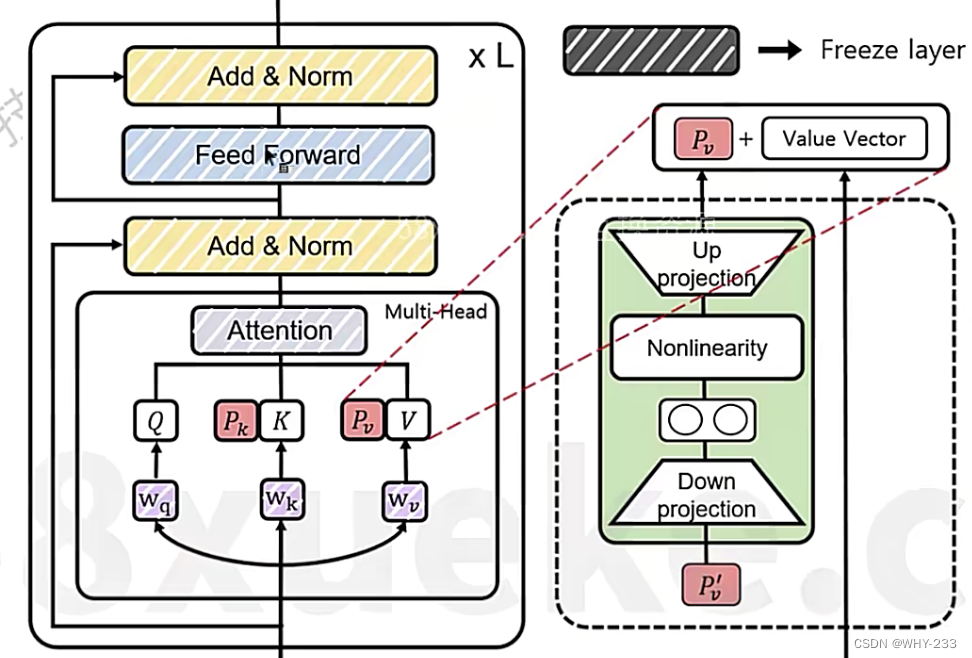
P-tuning:通过改变输入,对输入增强前缀token,帮助模型理解我们想要什么。由于添加了token,优化存在困难,性能无法通过增加更多token的方法提升,还占用了更多的窗口。
-
LoRA:模型本身不改变,新的模型通过加法进入原模型向量。
-
这部分是个人的一些想法,不是原论文中严谨的数学解释,仅用于帮助理解。
-
高效微调的核心思想:在不大幅度改变模型参数的同时,训练入新的知识。微调的本质就是较少改变预训练模型的基础上,使其适应新任务、新领域对向量的调整理论上应该远低于预训练模型本身的信息量。
w ′ = Δ w + w w' = \Delta w + w w′=Δw+w -
也就是说 Δ w \Delta w Δw相较于 w w w所含信息量较少,通过较少的改变量,使得权重达到所需效果。
-
简单而言,由于包含信息量少,微调所需的 Δ w \Delta w Δw并不需要一个较大的模型,在 Δ w \Delta w Δw的RANK较小时,也能达到要求。

-
Δ w \Delta w Δw的参数量为 dim * dim;A,B的参数量为dim * rank * 2,故LoRA模型的参数量较少
-
初始化的方式:A使用高斯分布,B为全0。
-
初始化的原因:1.为了让训练开始时的 Δ w \Delta w Δw为0
-
问题: 训练哪一个矩阵?
总所周知,Transformer模型大致由6类矩阵组成,注意力中的Q、K、V、Out矩阵和FFN中的两个线性变换矩阵。原论文作者中表示,仅对Q和V做LoRA就可以了,K没什么用。 -
问题: rank选择多少?
作者表示使用4-8效果不错,我个人的想法是,一个模型参数可以存储2bit信息,LoRA的可更改参数量和可解决问题相关,没有很大的信息量,选择更大的rank会导致过拟合,选择过小的rank会导致LoRA模型的容量不足。 -
实现方式:通过继承预训练模型层,然后对Q和V做线性变换,冻结原模型即可。
-
RLHF
- 以后再说