Sharding-JDBC从入门到精通(6)-- Sharding-JDBC 水平分库 和 垂直分库。
一、Sharding-JDBC 水平分库-分片策略配置
1、分库策略定义方式如下
# 分库策略,如何将一个逻辑表映射到多个数据源
spring.shardingsphere.sharding.tables.<逻辑表名称>.qatabase-strategy.<分片策略>.<分片策略属性名>= #分片策略属性值
# 分表策略,如何将一个逻辑表映射为多个实际表
spring.shardingsphere.sharding.tables.<逻辑表名称>.table-strategy.<分片策略>.<分片策略属性名>= #分片策略属性值
# 分库策略:以 user_id 为分片键,分片策略为 user_id % 2 + 1,user_id 为偶数操作 m1 数据源,否则操作 m2
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1}
2、分片规则修改:
由于数据库需要拆分了两个,这里需要配置两个数据源。
分库需要配置分库的策略,和分表策略的意义类似,通过分库策略实现数据操作针对分库的数据库进行操作。
# 配置 sharding-jdbc 分片规则(2024-6-29 分片规则修改)
# 定义数据源(定义 多个 数据源名为 m1, m2)
spring.shardingsphere.datasource.names = m1,m2
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12311
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/order_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 12311
3、在 sharding_jdbc_simple 子工程(子模块)中,修改 application.properties 配置文件,添加配置分库策略。
# dbsharding\sharding_jdbc_simple\src\main\resources\application.properties
server.port = 56081
spring.application.name = sharding-jdbc-simple-demo
server.servlet.context-path = /sharding-jdbc-simple-demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = utf-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
# 配置 sharding-jdbc 分片规则(2024-6-29 分片规则修改)
# 定义数据源(定义 多个 数据源名为 m1, m2)
spring.shardingsphere.datasource.names = m1,m2
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12311
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/order_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 12311
# 分库策略:以 user_id 为分片键,分片策略为 user_id % 2 + 1,user_id 为偶数操作 m1 数据源,否则操作 m2
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1}
# 指定 t_order 表的数据分布情况,配置数据节点(t_order 映射到 t_order_1 或者 t_order_2)
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}
# 指定 t_order 表的主键生成策略为 SNOWFLAKE(雪花算法)
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
# 指定 t_order 表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.djh.it.dbsharding = debug
logging.level.druid.sql = debug
4、Sharding-JDBC 支持以下几种分片策略:
不管理分库还是分表,策略基本一样。
-
standard: 标准分片策略,对应 Standardshardingstrategy。提供对 SQL 语句中的 =,IN 和 BETWEEN AND 的分片操作支持。StandardShardingStrategy 只支持单分片键,提供 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理 BETWEEN AND 分片,如果不配置 RangeshardingAlgorithm,SQL 中的 BETWEEN AND 将按照全库路由处理。
-
complex: 符合分片策略,对应 ComplexshardingStrategy。复合分片策略。提供对 SQL 语句中的 =,IN 和 BETWEEN AND 的分片操作支持。ComplexshardingStrategy 支持多分片键,由于多分片键之间的关系复杂因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
-
inline: 行表达式分片策略,对应 InlineshardingStrategy。使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的 Java 代码开发,如:t_user_$->{u id % 8} 表示 t_user 表根据u_id 模8,而分成8张表,表名称为 t_user_0 到 t_user_7。
-
hint: Hint 分片策略,对应 HintShardingStrategy。通过 Hint 而非 SQL 解析的方式分片的策略。对于分片字段非 SQL决 定,而由其他外置条件决定的场景,可使用 SQLHint 灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint 支持通过 Java API 和 SQL 注释(待实现)两种方式使用。
-
none : 不分片策略,对应 NoneShardingStrategy。不分片的策略。
5、创建两个数据库:order_db_1, order_db_2
CREATE DATABASE `order_db_1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
CREATE DATABASE `order_db_2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
6、在 order_db_1, order_db_2 中分别 创建 t_order_1 和 t_order_2 两个表:
# 在 数据库 order_db_1 中,创建两张表。
USE `order_db_1`;
# 创建 t_order_1 表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
# 创建 t_order_2 表
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
# 在 数据库 order_db_2 中,创建两张表。
USE `order_db_2`;
# 创建 t_order_1 表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
# 创建 t_order_2 表
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
二、Sharding-JDBC 水平分库-插入订单
1、在 sharding_jdbc_simple 子工程(子模块)中,修改 application.properties 配置文件,添加配置分库策略。
# dbsharding\sharding_jdbc_simple\src\main\resources\application.properties
server.port = 56081
spring.application.name = sharding-jdbc-simple-demo
server.servlet.context-path = /sharding-jdbc-simple-demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = utf-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
# 配置 sharding-jdbc 分片规则(2024-6-29 分片规则修改)
# 定义数据源(定义 多个 数据源名为 m1, m2)
spring.shardingsphere.datasource.names = m1,m2
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12311
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/order_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 12311
# 分库策略:以 user_id 为分片键,分片策略为 user_id % 2 + 1,user_id 为偶数操作 m1 数据源,否则操作 m2
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1}
# 指定 t_order 表的数据分布情况,配置数据节点(t_order 映射到 t_order_1 或者 t_order_2)
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}
# 指定 t_order 表的主键生成策略为 SNOWFLAKE(雪花算法)
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
# 指定 t_order 表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.djh.it.dbsharding = debug
logging.level.druid.sql = debug
2、在 sharding_jdbc_simple 子工程(子模块)中,测试类 OrderDao 的测试类 OrderDaoTest.java 进行测试
/**
* dbsharding\sharding_jdbc_simple\src\test\java\djh\it\dbsharding\simple\dao\OrderDaoTest.java
*
* 2024-6-28 创建 接口 OrderDao 的测试类 OrderDaoTest.java 进行测试
*
* 快速生成 接口 OrderDao 类的测试类:
* 1)右键 接口 OrderDao 选择 【Generate...】
* 2)选择【Test..】
* 3)Testing library : JUnit4
* Class name : OrderDaoTest
* SUPERCLASS : 空
* Destination package : djh.it.dbsharding.simple.dao
* 4)点击 OK。
*/
package djh.it.dbsharding.simple.dao;
import djh.it.dbsharding.simple.ShardingJdbcSimpleBootstrap;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleBootstrap.class})
public class OrderDaoTest {
@Autowired
OrderDao orderDao;
@Test //查询
public void testSelectOrderByIds(){
List<Long> ids = new ArrayList<>();
ids.add(1013467489922711552L); //此order_id 在 mysql 数据库的 t_order_1 表中,
ids.add(1013465458055053313L); //此order_id 在 mysql 数据库的 t_order_2 表中,
List<Map> maps = orderDao.selectOrderByIds(ids);
System.out.println(maps);
}
@Test //插入数据
public void testInsertOrder(){
// // 1)此数据会插入到 m1 数据库: 1L % 2 + 1 = 2 得到 M2,由此可得 向 order_db_2 数据库中插入 20 条数据。
// orderDao.insertOrder(new BigDecimal(i ),1L, "success2");
// 2)此数据会插入到 m1 数据库: 4L % 2 + 1 = 1 得到 M1,由此可得 向 order_db_1 数据库中插入 20 条数据。
for(int i=1; i<20; i++){
orderDao.insertOrder(new BigDecimal(i ),4L, "success2");
}
}
}
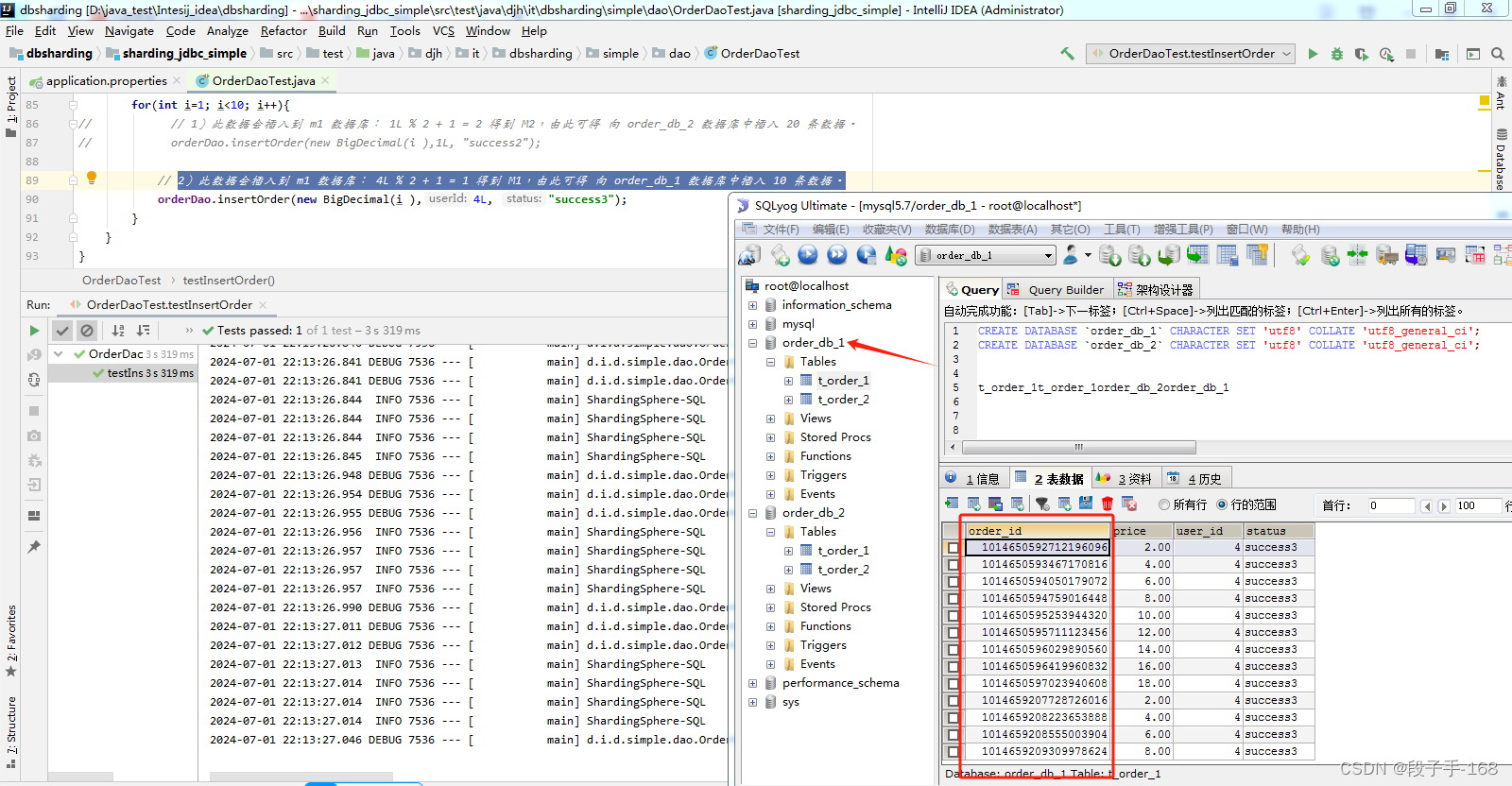
3、运行测试类 OrderDaoTest.java 插入数据 testInsertOrder 方法,进行测试。
1)1L % 2 + 1 = 2 得到 M2,由此可得 向 t_order_2 数据库中插入 20 条数据。
2)此数据会插入到 m1 数据库: 4L % 2 + 1 = 1 得到 M1,由此可得 向 order_db_1 数据库中插入 10 条数据。
三、Sharding-JDBC 水平分库-查询订单
1、在 sharding_jdbc_simple 子工程(子模块)中,修改 application.properties 配置文件,添加配置分库策略。
# dbsharding\sharding_jdbc_simple\src\main\resources\application.properties
server.port = 56081
spring.application.name = sharding-jdbc-simple-demo
server.servlet.context-path = /sharding-jdbc-simple-demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = utf-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
# 配置 sharding-jdbc 分片规则(2024-6-29 分片规则修改)
# 定义数据源(定义 多个 数据源名为 m1, m2)
spring.shardingsphere.datasource.names = m1,m2
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12311
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/order_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 12311
# 分库策略:以 user_id 为分片键,分片策略为 user_id % 2 + 1,user_id 为偶数操作 m1 数据源,否则操作 m2
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1}
# 指定 t_order 表的数据分布情况,配置数据节点(t_order 映射到 t_order_1 或者 t_order_2): 只能路由到 m1 数据库
#spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}
# 指定 t_order 表的数据分布情况,配置数据节点(t_order 映射到 t_order_1 或者 t_order_2): 动态路由到 m1 数据库 或 m2 数据库。
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m$->{1..2}.t_order_$->{1..2}
# 指定 t_order 表的主键生成策略为 SNOWFLAKE(雪花算法)
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
# 指定 t_order 表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.djh.it.dbsharding = debug
logging.level.druid.sql = debug
2、在 sharding_jdbc_simple 子工程(子模块)中,修改 dao 接口类 OrderDao.java 添加 //查询数据:根据订单ID 和 用户 id 查询订单 方法。
/**
* dbsharding\sharding_jdbc_simple\src\main\java\djh\it\dbsharding\simple\dao\OrderDao.java
*
* 2024-5-28 创建 dao 接口类 OrderDao.java
*/
package djh.it.dbsharding.simple.dao;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
@Mapper
@Component
public interface OrderDao {
//查询数据:根据订单ID 和 用户 id 查询订单
// ( SELECT * FROM t_order_1 WHERE user_id = 4 AND order_id IN (1014650592712196096, 1014650593467170816); )
@Select( "<script>" +
"select" +
" * " +
" from t_order t " +
" where t.order_id in " +
" <foreach collection=' orderIds' open='(' separator=',' close=')' item='id'>" +
" #{id} " +
" </foreach>" +
" and user_id = ${userId}" +
"</script>" )
List<Map> selectOrderByIdsAndUserId(@Param("userId") Long userId, @Param("orderIds") List<Long> orderIds);
//查询数据:根据订单ID ( SQL 语句:SELECT * FROM t_order_1 WHERE order_id IN (1013467489922711552, 1013467489960460288); )
@Select( "<script>" +
"select" +
" * " +
" from t_order t " +
" where t.order_id in " +
" <foreach collection=' orderIds' open='(' separator=',' close=')' item='id'>" +
" #{id} " +
" </foreach>" +
"</script>" )
List<Map> selectOrderByIds(@Param("orderIds") List<Long> orderIds);
//插入数据
@Insert("insert into t_order(price, user_id, status) values(#{price}, #{userId}, #{status})")
int insertOrder(@Param("price") BigDecimal price, @Param("userId")Long userId, @Param("status")String status);
}
3、在 sharding_jdbc_simple 子工程(子模块)中,修改 测试类 OrderDao 的测试类 查询方法,进行多次查询测试。添加 根据订单ID 和 用户 id 查询订单 的方法。
/**
* dbsharding\sharding_jdbc_simple\src\test\java\djh\it\dbsharding\simple\dao\OrderDaoTest.java
*
* 2024-6-28 创建 接口 OrderDao 的测试类 OrderDaoTest.java 进行测试
*
* 快速生成 接口 OrderDao 类的测试类:
* 1)右键 接口 OrderDao 选择 【Generate...】
* 2)选择【Test..】
* 3)Testing library : JUnit4
* Class name : OrderDaoTest
* SUPERCLASS : 空
* Destination package : djh.it.dbsharding.simple.dao
* 4)点击 OK。
*/
package djh.it.dbsharding.simple.dao;
import djh.it.dbsharding.simple.ShardingJdbcSimpleBootstrap;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleBootstrap.class})
public class OrderDaoTest {
@Autowired
OrderDao orderDao;
@Test //查询--根据订单ID 和 用户 id 查询订单
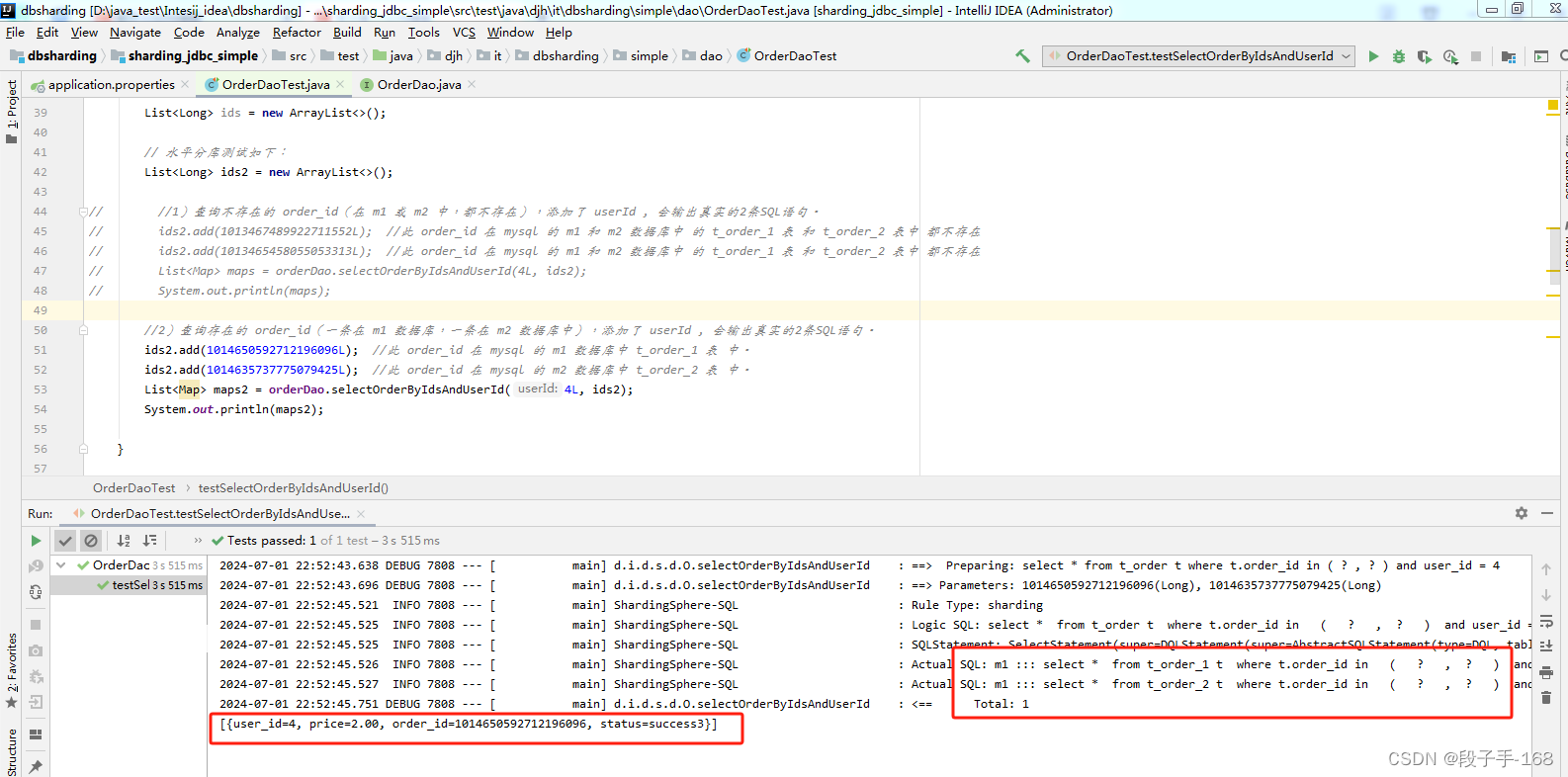
public void testSelectOrderByIdsAndUserId(){
List<Long> ids = new ArrayList<>();
// 水平分库测试如下:
List<Long> ids2 = new ArrayList<>();
// //1)查询不存在的 order_id(在 m1 或 m2 中,都不存在),添加了 userId , 会输出真实的2条SQL语句。
// ids2.add(1013467489922711552L); //此 order_id 在 mysql 的 m1 和 m2 数据库中 的 t_order_1 表 和 t_order_2 表中 都不存在
// ids2.add(1013465458055053313L); //此 order_id 在 mysql 的 m1 和 m2 数据库中 的 t_order_1 表 和 t_order_2 表中 都不存在
// List<Map> maps = orderDao.selectOrderByIdsAndUserId(4L, ids2);
// System.out.println(maps);
//2)查询存在的 order_id(一条在 m1 数据库,一条在 m2 数据库中),添加了 userId , 会输出真实的2条SQL语句。
ids2.add(1014650592712196096L); //此 order_id 在 mysql 的 m1 数据库中 t_order_1 表 中。
ids2.add(1014635737775079425L); //此 order_id 在 mysql 的 m2 数据库中 t_order_2 表 中。
List<Map> maps2 = orderDao.selectOrderByIdsAndUserId(4L, ids2);
System.out.println(maps2);
}
@Test //查询
public void testSelectOrderByIds(){
List<Long> ids = new ArrayList<>();
// //查询数据库 order_db 中的数据 order_id(水平分表)
// ids.add(1013467489922711552L); //此order_id 在 mysql 数据库的 t_order_1 表中,
// ids.add(1013465458055053313L); //此order_id 在 mysql 数据库的 t_order_2 表中,
// List<Map> maps = orderDao.selectOrderByIds(ids);
// System.out.println(maps);
// 水平分库测试如下:
List<Long> ids2 = new ArrayList<>();
//1)查询不存在的 order_id(在 m1 或 m2 中,都不存在),会输出真实的4条SQL语句。
ids2.add(1013467489922711552L); //此 order_id 在 mysql 的 m1 和 m2 数据库中 的 t_order_1 表 和 t_order_2 表中 都不存在
ids2.add(1013465458055053313L); //此 order_id 在 mysql 的 m1 和 m2 数据库中 的 t_order_1 表 和 t_order_2 表中 都不存在
List<Map> maps = orderDao.selectOrderByIds(ids2);
System.out.println(maps);
// //2)查询存在的 order_id(一条在 m1 数据库,一条在 m2 数据库中),会输出真实的4条SQL语句。
// ids2.add(1014650592712196096L); //此 order_id 在 mysql 的 m1 数据库中 t_order_1 表 中。
// ids2.add(1014635737775079425L); //此 order_id 在 mysql 的 m2 数据库中 t_order_2 表 中。
// List<Map> maps2 = orderDao.selectOrderByIds(ids2);
// System.out.println(maps2);
// //3)查询存在的 order_id(2条都在 m1 数据库,不同表中),会输出真实的4条SQL语句。
// ids2.add(1014650592712196096L); //此 order_id 在 mysql 的 m1 数据库中 t_order_1 表 中。
// ids2.add(1014635737775079425L); //此 order_id 在 mysql 的 m1 数据库中 t_order_2 表 中。
// List<Map> maps2 = orderDao.selectOrderByIds(ids2);
// System.out.println(maps2);
// //4)查询存在的 order_id(2条都在 m1 数据库,同一表中),会输出真实的2条SQL语句。
// ids2.add(1014650592712196096L); //此 order_id 在 mysql 的 m1 数据库中 t_order_1 表 中。
// ids2.add(1014635742883741696L); //此 order_id 在 mysql 的 m1 数据库中 t_order_1 表 中。
// List<Map> maps2 = orderDao.selectOrderByIds(ids2);
// System.out.println(maps2);
// //5)查询存在的 order_id(1条都在 m2 数据库),会输出真实的2条SQL语句。
// ids2.add(1014635741851942912L); //此 order_id 在 mysql 的 m2 数据库中 t_order_1 表 中。
// List<Map> maps2 = orderDao.selectOrderByIds(ids2);
// System.out.println(maps2);
}
@Test //插入数据
public void testInsertOrder(){
//orderDao.insertOrder(new BigDecimal(11 ),1L, "SUCCESS");
for(int i=1; i<10; i++){
// // 1)此数据会插入到 m1 数据库: 1L % 2 + 1 = 2 得到 M2,由此可得 向 order_db_2 数据库中插入 20 条数据。
// orderDao.insertOrder(new BigDecimal(i ),1L, "success2");
// 2)此数据会插入到 m1 数据库: 4L % 2 + 1 = 1 得到 M1,由此可得 向 order_db_1 数据库中插入 10 条数据。
orderDao.insertOrder(new BigDecimal(i ),4L, "success3");
}
}
}
4、运行测试类 OrderDaoTest.java 查询数据 testSelectOrderByIds 方法,进行测试。
1)查询不存在的 order_id(在 m1 或 m2 中,都不存在),会输出真实的4条SQL语句。
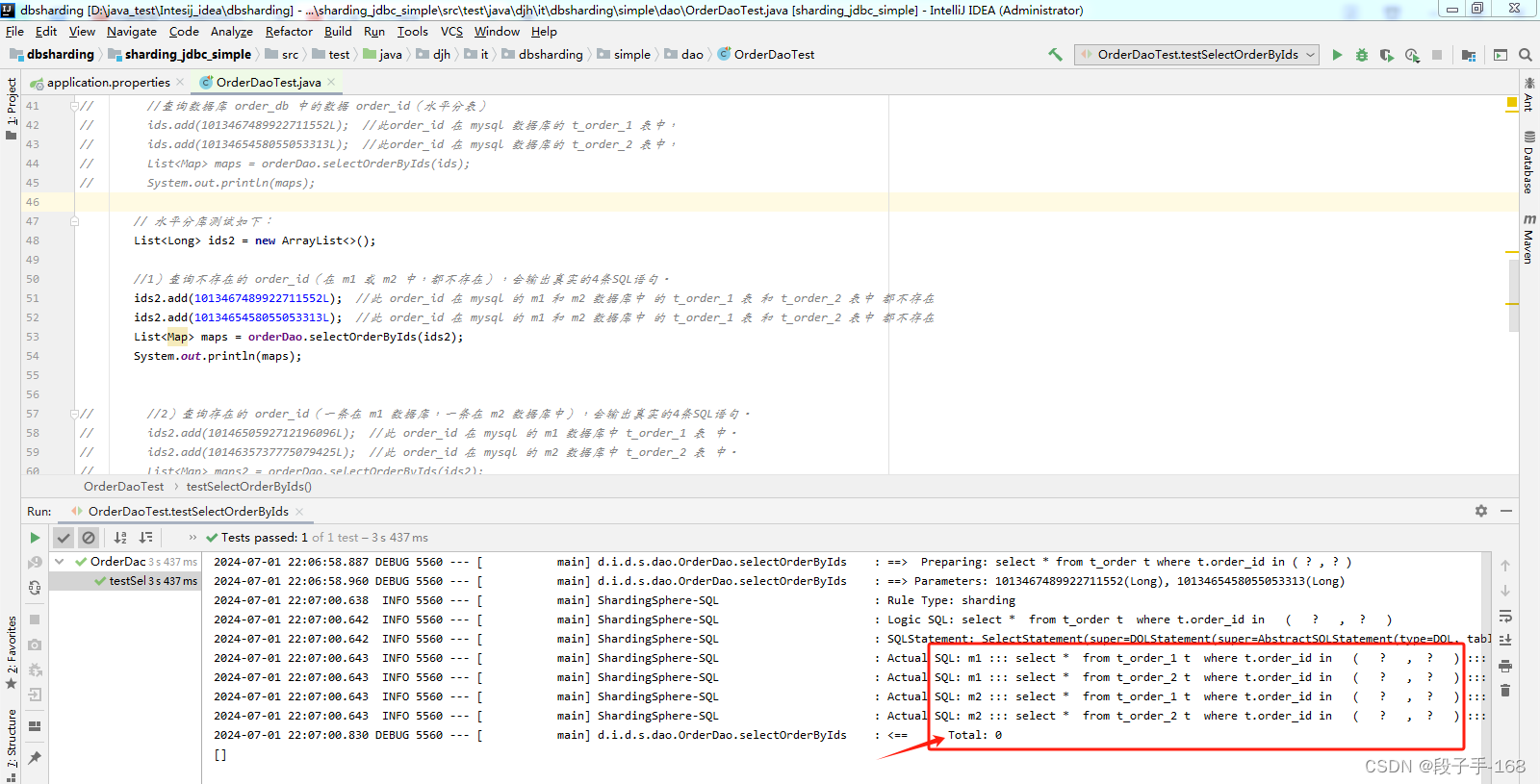
2)查询存在的 order_id(一条在 m1 数据库,一条在 m2 数据库中),会输出真实的4条SQL语句。
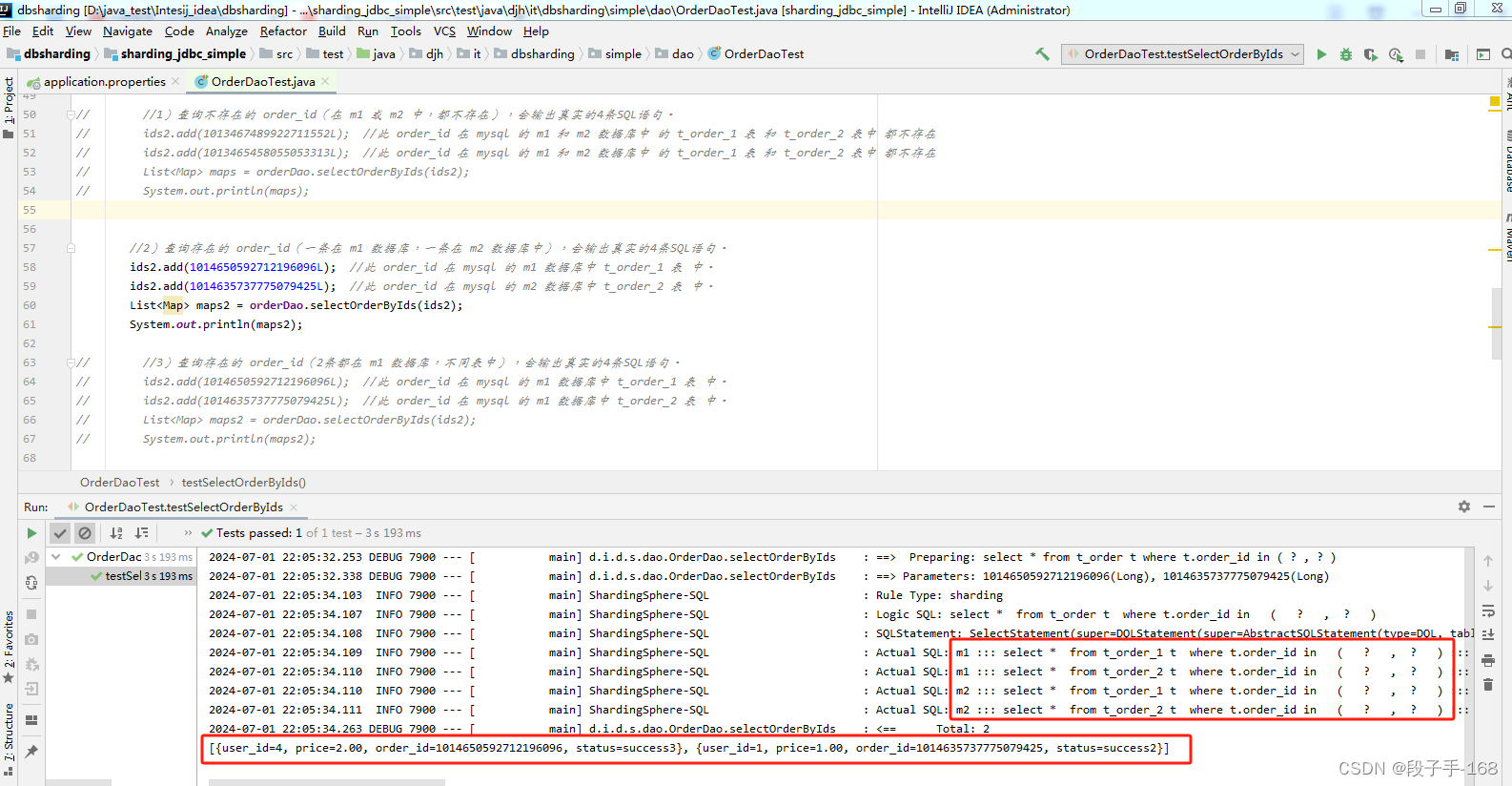
3)查询存在的 order_id(2条都在 m1 数据库,不同表中),会输出真实的4条SQL语句。
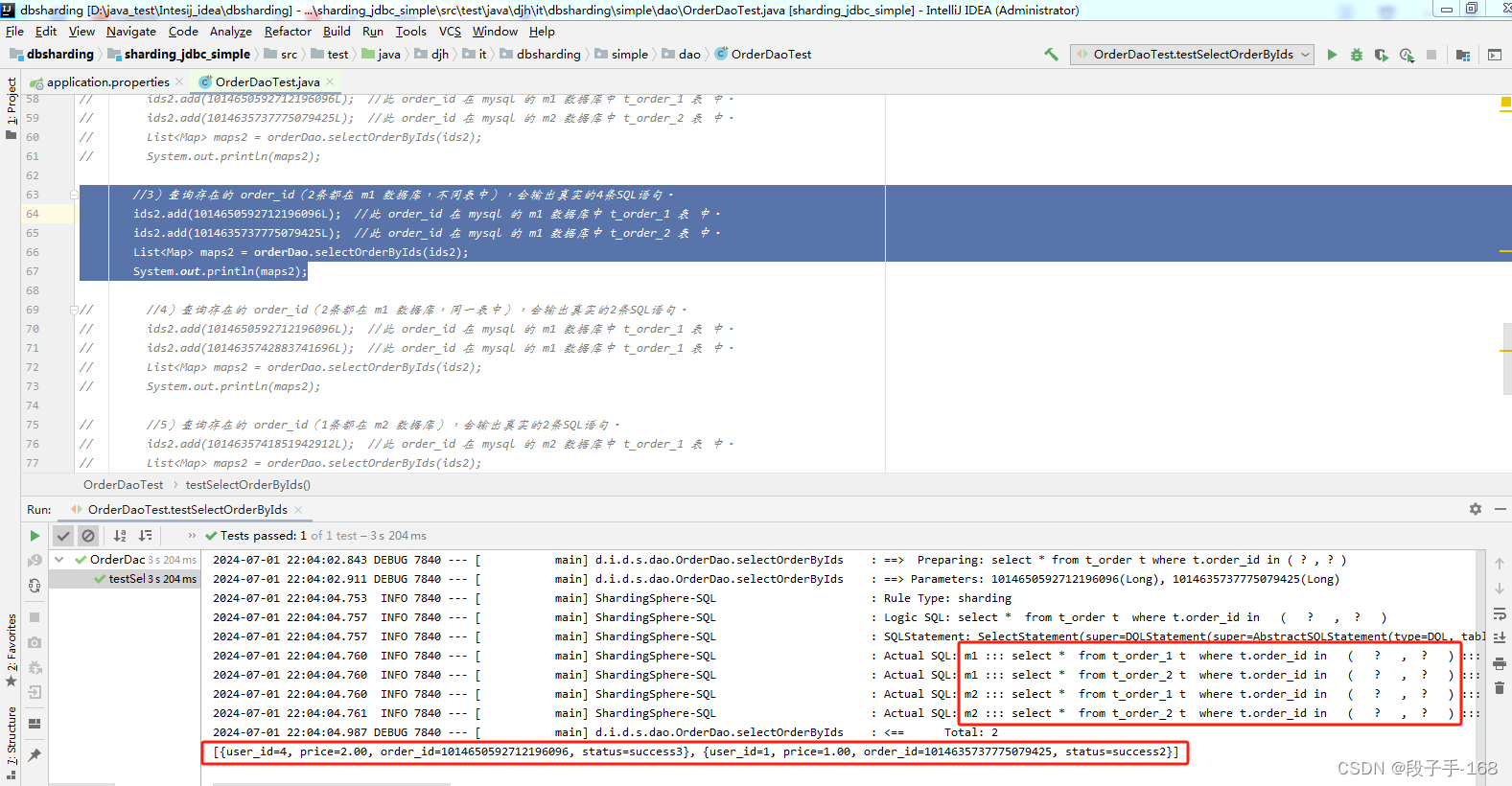
4)查询存在的 order_id(2条都在 m1 数据库 同一表中),会输出真实的2条SQL语句。
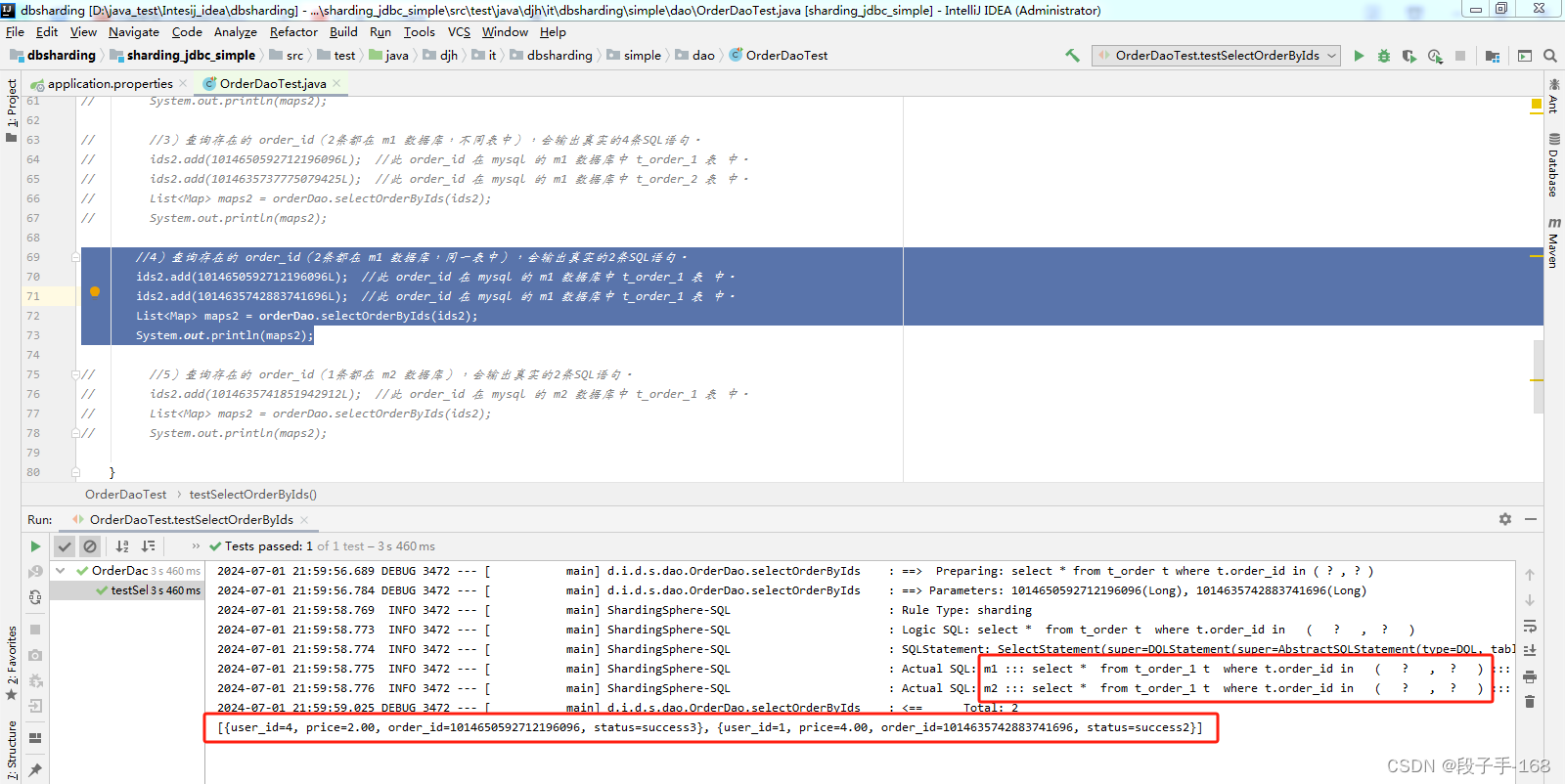
5)查询存在的 order_id(1条都在 m2 数据库),会输出真实的2条SQL语句。

6)查询不存在的 order_id(在 m1 或 m2 中,都不存在),添加了 userId ,
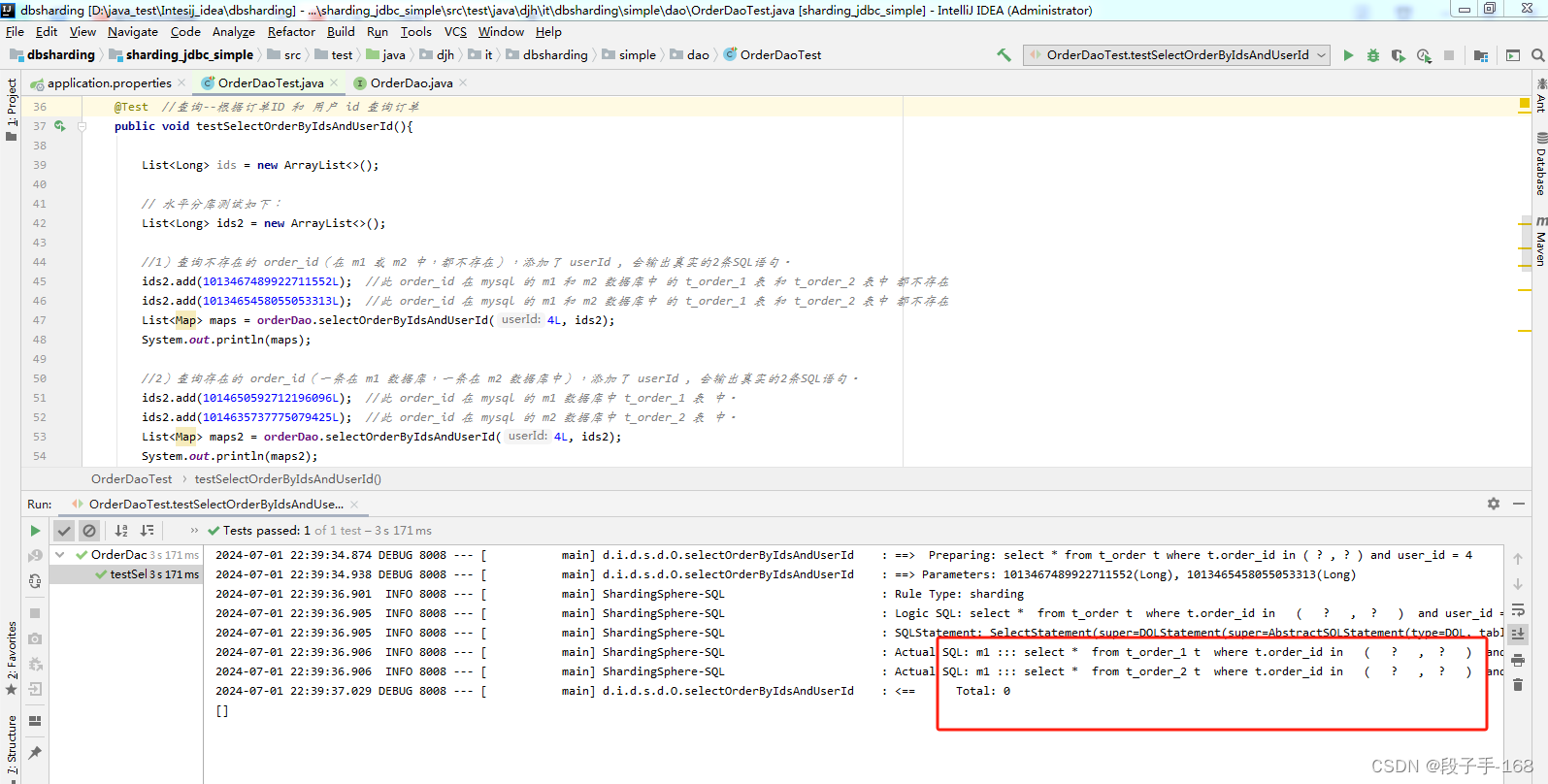
7)查询存在的 order_id(一条在 m1 数据库,一条在 m2 数据库中),添加了 userId , 会输出真实的2条SQL语句。
四、Sharding-JDBC 垂直分库-分片策略配置
1、创建数据库:user_db
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
2、在 suer_db 中分别 创建 t_user 表:
# 在 数据库 order_db_1 中,创建两张表。
USE `user_db`;
# 创建 t_user 表
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` BIGINT(20) NOT NULL COMMENT '用户id',
`fullname` VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户姓名',
`user_type` char(1) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY(`user_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
3、在 application.properties 配置文件中,配置数据源,
spring.shardingsphere.datasource.names = m0,m1,m2
spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/user_db?useUnicode=true
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = 12311
# 分库策略:以 user_id 为分片键,分片策略为 user_id % 2 + 1,user_id 为偶数操作 m1 数据源,否则操作 m2
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1}
# 配置 user_db 数据节点
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = m0.t_user
# 指定 t_user 表的分片策略,分片策略包括分片键和分片算法(未分库分表也需要配置)
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression = t_user
五、Sharding-JDBC 垂直分库-插入和查询测试
1、在 sharding_jdbc_simple 子工程(子模块)中,修改 application.properties 配置文件,添加 user_db 数据库的 配置分库分表策略。
# dbsharding\sharding_jdbc_simple\src\main\resources\application.properties
server.port = 56081
spring.application.name = sharding-jdbc-simple-demo
server.servlet.context-path = /sharding-jdbc-simple-demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = utf-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
# 配置 sharding-jdbc 分片规则(2024-6-29 分片规则修改)
# 定义数据源(定义 多个 数据源名为 m1, m2)
spring.shardingsphere.datasource.names = m0,m1,m2
spring.shardingsphere.datasource.m0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m0.url = jdbc:mysql://localhost:3306/user_db?useUnicode=true
spring.shardingsphere.datasource.m0.username = root
spring.shardingsphere.datasource.m0.password = 12311
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12311
spring.shardingsphere.datasource.m2.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url = jdbc:mysql://localhost:3306/order_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username = root
spring.shardingsphere.datasource.m2.password = 12311
# 分库策略:以 user_id 为分片键,分片策略为 user_id % 2 + 1,user_id 为偶数操作 m1 数据源,否则操作 m2
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression = m$->{user_id % 2 + 1}
# 指定 t_order 表的数据分布情况,配置数据节点(t_order 映射到 t_order_1 或者 t_order_2): 只能路由到 m1 数据库
#spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}
# 指定 t_order 表的数据分布情况,配置数据节点(t_order 映射到 t_order_1 或者 t_order_2): 动态路由到 m1 数据库 或 m2 数据库。
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m$->{1..2}.t_order_$->{1..2}
# 配置 user_db 数据节点
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes = m$->{0}.t_user
# 指定 t_order 表的主键生成策略为 SNOWFLAKE(雪花算法)
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
# 指定 t_order 表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
# 指定 t_user 表的分片策略,分片策略包括分片键和分片算法(未分库分表也需要配置)
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column = user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression = t_user
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.djh.it.dbsharding = debug
logging.level.druid.sql = debug
2、在 sharding_jdbc_simple 子工程(子模块)中,创建 接口类 UserDao.java
/**
* dbsharding\sharding_jdbc_simple\src\main\java\djh\it\dbsharding\simple\dao\UserDao.java
*
* 2024-7-1 创建 接口类 UserDao.java
*/
package djh.it.dbsharding.simple.dao;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.Map;
@Mapper
@Component
public interface UserDao {
//新增用户
@Insert("insert into t_user(user_id, fullname) value(#{userId}, #{fullname})")
int insertUser(@Param("userId") Long userId, @Param("fullname") String fullname);
//根据id列表查询多个用户
@Select({ "<script>" ,
" select" ,
" * " ,
" from t_user t " ,
" where t.user_id in ",
" <foreach collection=' userIds' open='(' separator=',' close=')' item='id'>" +
" #{id} " ,
" </foreach>" ,
"</script>" })
List<Map> selectUserId(@Param("userIds") List<Long> userIds);
}
3、在 sharding_jdbc_simple 子工程(子模块)中,创建 接口类 UserDao.java 的测试类 UserDaoTest.java 进行插入数据 和 查询数据测试。
/**
* dbsharding\sharding_jdbc_simple\src\test\java\djh\it\dbsharding\simple\dao\UserDaoTest.java
*
* 2024-7-1 创建 接口类 UserDao.java 的测试类 UserDaoTest.java 进行插入数据 和 查询数据测试 UserDaoTest.java
*/
package djh.it.dbsharding.simple.dao;
import djh.it.dbsharding.simple.ShardingJdbcSimpleBootstrap;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleBootstrap.class})
public class UserDaoTest {
@Autowired
UserDao userDao;
@Test
public void testInsertUser() {
for(int i=0; i<10; i++){
Long id = i + 1L;
userDao.insertUser(id, "姓名" + id);
}
}
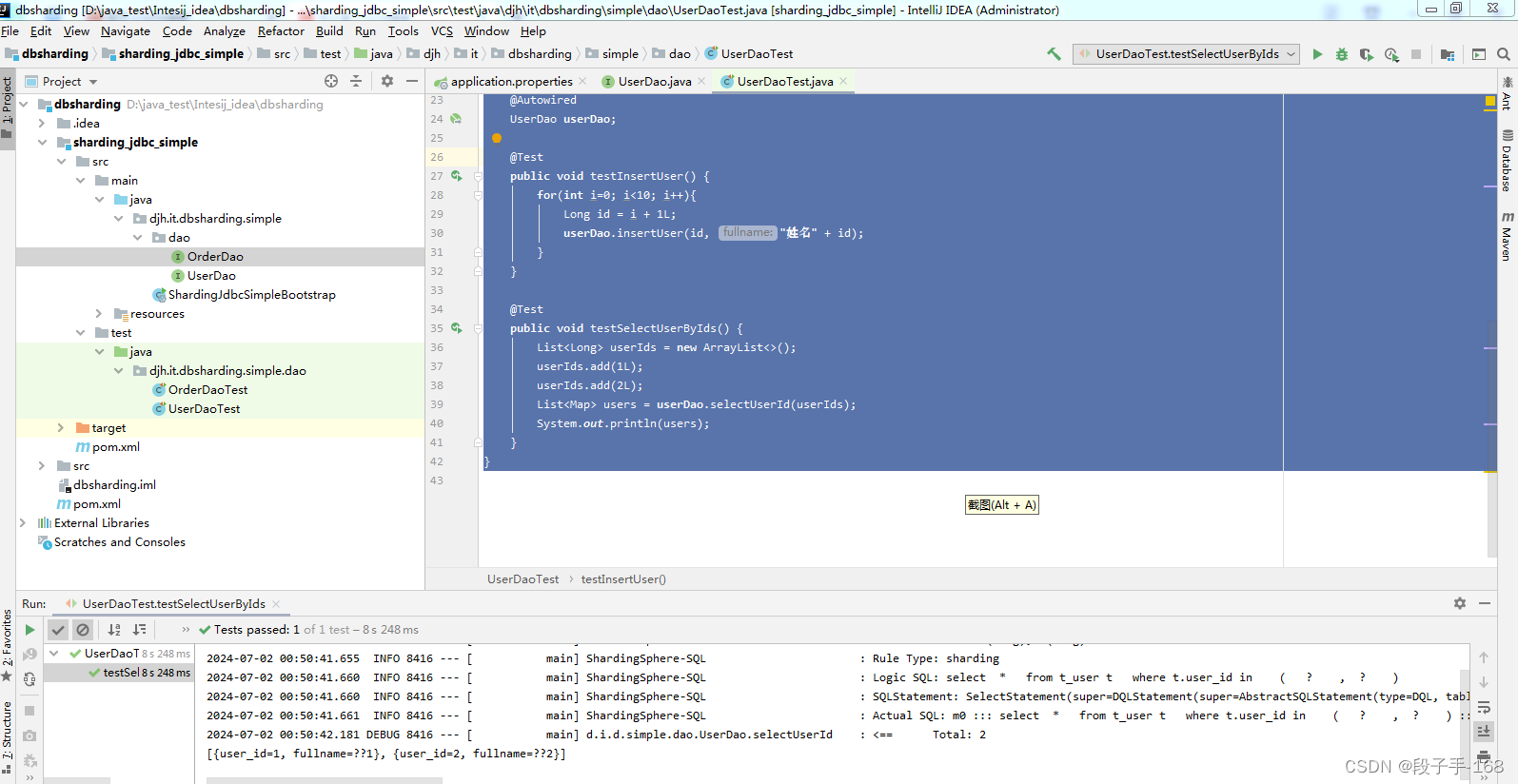
@Test
public void testSelectUserByIds() {
List<Long> userIds = new ArrayList<>();
userIds.add(1L);
userIds.add(2L);
List<Map> users = userDao.selectUserId(userIds);
System.out.println(users);
}
}
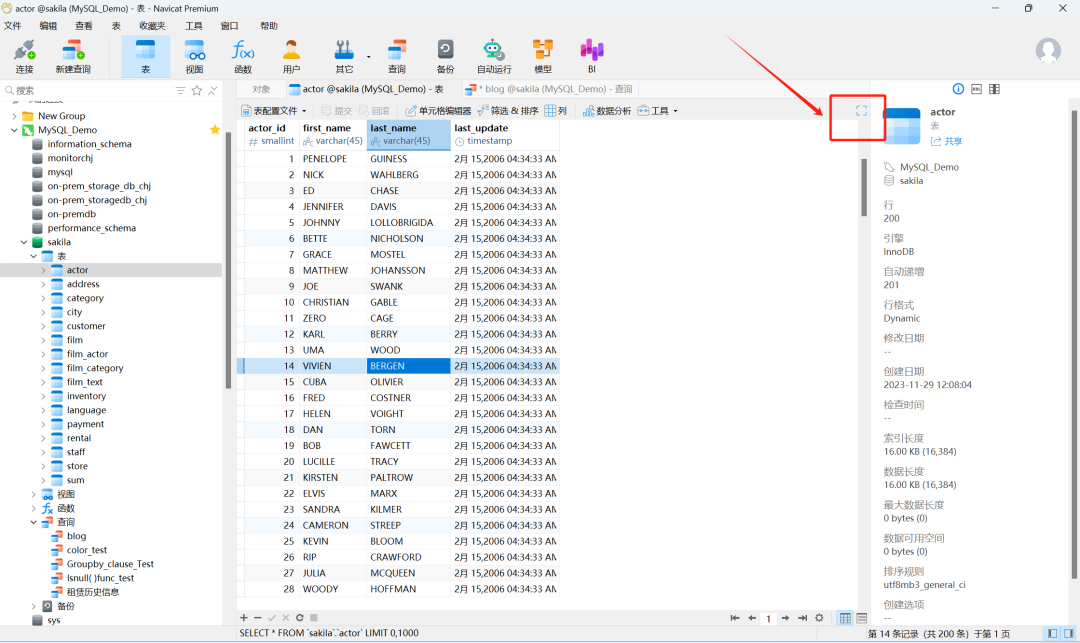
4、运行测试类 UserDaoTest.java,查看结果。
Sharding-JDBC垂直分库-插入和查询测试.png
上一节关联链接请点击
# Sharding-JDBC从入门到精通(5)-- Sharding-JDBC 执行原理