Python中使用对话框批量打开文件时出现乱序问题的解决方法
- 一、问题描述
- 二、os.listdir读取文件乱序问题解决方法
欢迎学习交流!
邮箱: z…@1…6.com
网站: https://zephyrhours.github.io/
一、问题描述
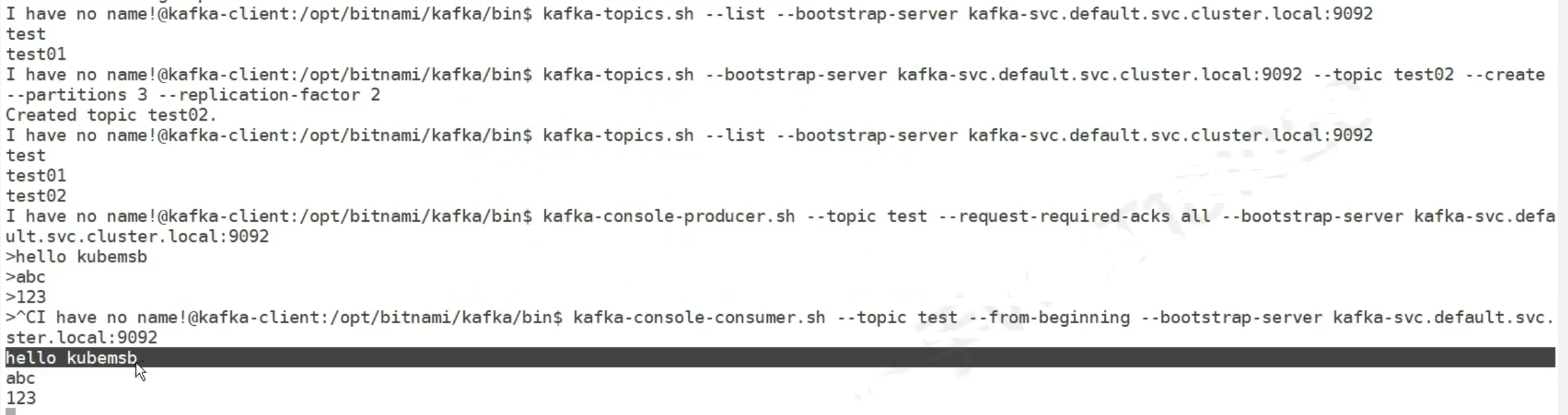
有时候为了方便,我们在进行程序编写时,会使用对话框来批量打开文件,但是使用os.listdir读取文件时,会出现文件乱序问题,此时直接使用sorted命令可能无法解决问题,尤其是遇到一些文件名称编码复杂时。具体如下;
- 下图是我们在window文件夹中打开时,文件排序方式;
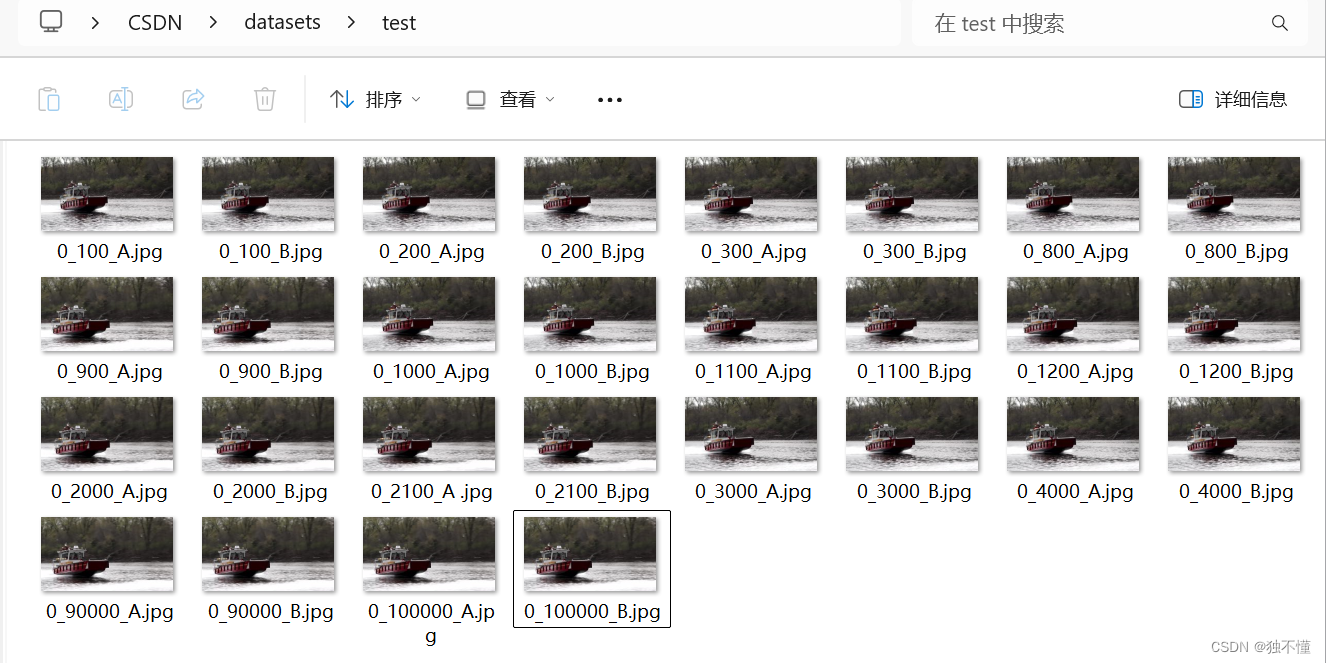
- 下面是我们使用os.listdir命令获取的文件命名方式输出,具体代码和结果如下:
from tkinter import filedialog
import os
# 打开文件夹
folder_path = filedialog.askdirectory(title='Open the folder')
img_list = os.listdir(folder_path)
print('img_list:', img_list)

可以看到,此处的图像名称的排序方式是乱序的,这种情况下往往不方便我们后续的图像处理任务:
D:\anaconda3\envs\csdn\python.exe
C:\Users\zephy\Documents\Python\CSDN\demo_20240702.py
img_list:
[‘0_100000_A.jpg’,
‘0_100000_B.jpg’,
‘0_1000_A.jpg’,
‘0_1000_B.jpg’,
‘0_100_A.jpg’,
‘0_100_B.jpg’,
‘0_1100_A.jpg’,
‘0_1100_B.jpg’,
‘0_1200_A.jpg’,
‘0_1200_B.jpg’,
‘0_2000_A.jpg’,
‘0_2000_B.jpg’,
‘0_200_A.jpg’,
‘0_200_B.jpg’,
‘0_2100_A .jpg’,
‘0_2100_B.jpg’,
‘0_3000_A.jpg’,
‘0_3000_B.jpg’,
‘0_300_A.jpg’,
‘0_300_B.jpg’,
‘0_4000_A.jpg’,
‘0_4000_B.jpg’,
‘0_800_A.jpg’,
‘0_800_B.jpg’,
‘0_90000_A.jpg’,
‘0_90000_B.jpg’,
‘0_900_A.jpg’,
‘0_900_B.jpg’]Process finished with exit code 0
二、os.listdir读取文件乱序问题解决方法
下面笔者提供一种解决方式,可以实现读取的文件顺序与文件夹浏览顺序保持一致。
from tkinter import filedialog
import os
# 打开文件夹
folder_path = filedialog.askdirectory(title='Open the folder')
img_list = os.listdir(folder_path)
# 以下命令中lambda表达式为解决问题关键
img_paths = sorted(img_list, key=lambda x: (len(x), x), reverse=False)
print('img_paths:', img_paths)
此次的输出结果如下:
D:\anaconda3\envs\csdn\python.exe C:\Users\zephy\Documents\Python\CSDN\demo_20240702.py
img_paths:
[‘0_100_A.jpg’,
‘0_100_B.jpg’,
‘0_200_A.jpg’,
‘0_200_B.jpg’,
‘0_300_A.jpg’,
‘0_300_B.jpg’,
‘0_800_A.jpg’,
‘0_800_B.jpg’,
‘0_900_A.jpg’,
‘0_900_B.jpg’,
‘0_1000_A.jpg’,
‘0_1000_B.jpg’,
‘0_1100_A.jpg’,
‘0_1100_B.jpg’,
‘0_1200_A.jpg’,
‘0_1200_B.jpg’,
‘0_2000_A.jpg’,
‘0_2000_B.jpg’,
‘0_2100_B.jpg’,
‘0_3000_A.jpg’,
‘0_3000_B.jpg’,
‘0_4000_A.jpg’,
‘0_4000_B.jpg’,
‘0_2100_A .jpg’,
‘0_90000_A.jpg’,
‘0_90000_B.jpg’,
‘0_100000_A.jpg’,
‘0_100000_B.jpg’]
Process finished with exit code 0

此时可以看到,输出的文件名称与我们所期望的(window文件夹中打开时默认的排序)保持了一致。
下面还可以通过设置,实现需求数据的筛选,详细代码如下:
from tkinter import filedialog
import os
# 打开文件夹
folder_path = filedialog.askdirectory(title='Open the folder')
img_list = os.listdir(folder_path)
# print('img_list:', img_list)
filter_str = '_A.jpg'
img_names = []
img_paths = sorted(img_list, key=lambda x: (len(os.path.basename(x)),os.path.basename(x)), reverse=False)
# print('img_paths:', img_paths)
for i in range(len(img_paths)):
if img_paths[i].find(filter_str) != -1:
img_names.append(img_paths[i])
img_names = [os.path.join(folder_path, img_names[i]) for i in range(len(img_names))]
print('img_names:', img_names)
具体结果如下:
D:\anaconda3\envs\csdn\python.exe
C:\Users\zephy\Documents\Python\CSDN\demo_20240702.py img_names: [
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_100_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_200_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_300_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_800_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_900_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_1000_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_1100_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_1200_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_2000_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_3000_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_4000_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_90000_A.jpg’,
‘C:/Users/zephy/Desktop/CSDN/datasets/test\0_100000_A.jpg’] Process
finished with exit code 0