系统评估与优化
- 一.LLM应用评估思路
- 1.人工评估
- 准则一 量化评估
- 准则二 多维评估
- 2.自动评估
- 方法一. 构造客观题
- 方法二. 计算答案相似度
- 3.使用大模型评估
- 4.混合评估
- 二.评估并优化生成部分
- 1. 提升直观回答质量
- 2.标明知识来源,提高可信度
- 3. 构造思维链
- 4.增加一个指令解析
- 三.评估并优化检索部分
- 1. 评估检索效果
- 2.优化检索的思路
- 知识片段被割裂导致答案丢失
- query 提问需要长上下文概括回答
- 关键词误导
- 匹配关系不合理
一.LLM应用评估思路
在构建LLM应用程序时,会经历以下流程:
①少样本调整Prompt
②Bad Case定向优化;
③模型性能与开发成本的权衡
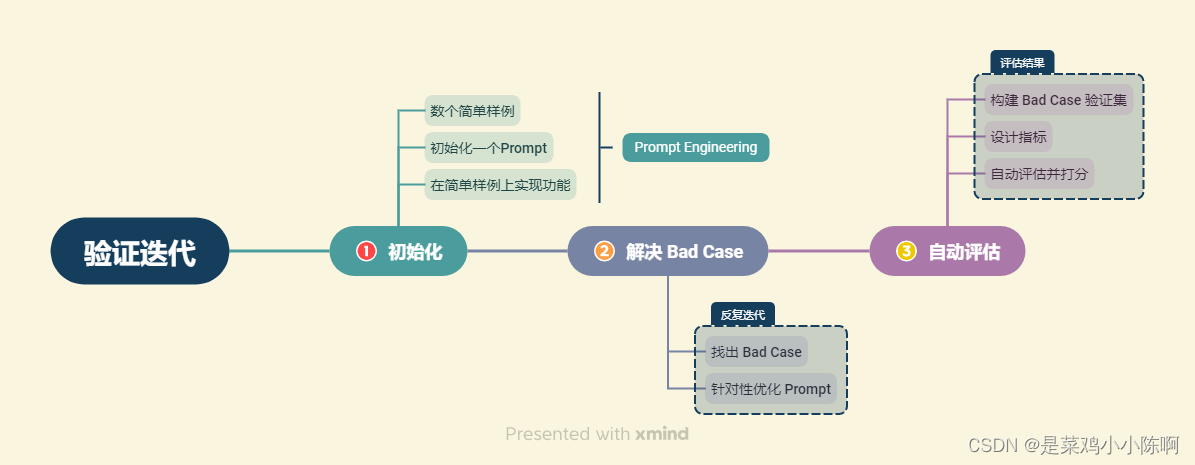
2.评估方法
在具体的大模型应用开发中,我们可以找到 Bad Cases,并不断针对性优化 Prompt 或检索架构来解决 Bad Cases,从而优化系统的表现。
发现Bad Case并将每个Bad Case加入验证集。
针对性调整对应的Prompt并检索架构。
每次优化后重新验证整个验证集,确保原有Good Case不受影响。
对于:
- 小验证集,采用人工评估;
- 大验证集,则采用自动化评估,以降低成本和时间消耗。
1.人工评估
准则一 量化评估
# import sys
# sys.path.append(".") 将父目录放入系统路径中
from zhipuai_embedding import ZhipuAIEmbeddings
from zhipuai_llm import ZhipuAILLM
from langchain.vectorstores.chroma import Chroma
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = '../../data_base/vector_db/chroma' # 修改自己的库路径
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
llm = ZhipuAILLM(model="chatglm_std", temperature=0, api_key=zhipuai_api_key)
版本A Prompt
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
template_v1 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v1)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
print("问题一:")
question = "南瓜书和西瓜书有什么关系?"
result = qa_chain({"query": question})
print(result["result"])
print("问题二:")
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
print(result["result"])
问题一:
南瓜书和西瓜书都是关于机器学习的书籍,它们之间的关系是南瓜书是对西瓜书中的部分难理解公式进行解析和补充推导细节的书籍。南瓜书适合在阅读西瓜书时作为参考,以便更好地理解书中涉及的公式和概念。谢谢你的提问!
问题二:
使用南瓜书的方法是:首先以西瓜书为主线,在学习过程中遇到自己推导不出来或者看不懂的公式时,再来查阅南瓜书。南瓜书的内容是以西瓜书的内容为前置知识进行表述的,所以建议在学有余力的时候再回来啃。如果南瓜书中没有你想要查阅的公式,或者你发现南瓜书有错误,可以毫不犹豫地去GitHub的Issues进行反馈,我们通常会在24小时以内给您回复。
版本B Prompt
template_v2 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v2)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
print("问题一:")
question = "南瓜书和西瓜书有什么关系?"
result = qa_chain({"query": question})
print(result["result"])
print("问题二:")
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
print(result["result"])
问题一:
南瓜书和西瓜书都是关于机器学习的书籍,它们之间存在一定的关系。南瓜书是对西瓜书中的部分难理解公式进行解析和补充推导细节的书籍,它旨在帮助读者更好地理解西瓜书中的内容。因此,南瓜书可以作为西瓜书的补充资料,供读者在学习过程中查阅。两本书的作者和编委会成员都有所不同,但它们在内容上都关注机器学习领域。总的来说,南瓜书和西瓜书的关系是互补的,它们共同为读者提供了一个学习机器学习的资源。
问题二:
使用南瓜书的方法如下:
1. 以西瓜书为主线:南瓜书的内容是以西瓜书为基础的,因此在学习过程中应以西瓜书为主线,将南瓜书作为辅助资料。在学习西瓜书的过程中,如果遇到自己推导不出来或者看不懂的公式,可以查阅南瓜书相应的章节进行补充学习。
2. 简单浏览第1章和第2章的公式:对于初学机器学习的小白,南瓜书第1章和第2章的公式建议简单浏览一下,了解大致内容即可。当你学习到一定程度,对机器学习有了一定了解后,可以回来再深入研究这些公式。
3. 查阅超纲数学知识:南瓜书的编写原则是以本科数学基础的视角进行讲解,因此对于一些超纲的数学知识,南瓜书会以附录和参考文献的形式给出。如果你对这些内容感兴趣,可以根据南瓜书提供的资料进行深入学习。
4. 反馈和勘误:如果在南瓜书中没有找到你想要查阅的公式,或者发现南瓜书中有错误,请毫不犹豫地去GitHub的Issues进行反馈,提交你希望补充的公式编号或者勘误信息。我们通常会在24小时以内给您回复。
5. 参考视频教程:为了更好地理解南瓜书的内容,可以参考配套的视频教程:https://www.bilibili.com/video/BV1Mh411e7VU。
6. 加入读者交流群:扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群”,与其他读者一起交流学习心得,互相帮助。
总之,南瓜书的使用方法应以西瓜书为主线,遇到难以理解的内容时再参考南瓜书进行补充学习。在学习过程中,可以利用视频教程和读者交流群来提高学习效果。同时,南瓜书的编委会也非常欢迎读者提出反馈和勘误,共同完善南瓜书的内容。
可以看到,版本 A 的 prompt 在案例①上有着更好的效果,但版本 B 的 prompt 在案例②上效果更佳。如果我们不量化评估指标,仅使用相对优劣的评估的话,我们无法判断版本 A 与版本 B 哪一个 prompt 更好,从而要找到一个 prompt 在所有案例上表现都更优才能进一步迭代;然而,这很明显是非常困难且不利于我们迭代优化的。
我们可以给每个答案赋予 1~5 的打分。例如,在上述案例中,我们给版本 A 的答案①打分为4,答案②打分为2,给版本 B 的答案①打分为3,答案②打分为5;那么,版本 A 的平均得分为3分,版本 B 的平均得分为4分,则版本 B 优于版本 A。
准则二 多维评估
大模型的回答需要在多个维度上进行回答的结果进行评估,每个维度都应设计相应的评估指标和量纲;下面是评价维度,取值区间默认为[0,1]:
- 知识查找正确性
- 回答幻觉比例
- 回答正确性
- 逻辑性
- 通顺性
- 智能性
print("问题:")
question = "应该如何使用南瓜书?"
print(question)
print("模型回答:")
result = qa_chain({"query": question})
print(result["result"])
回答结果为:
问题:
应该如何使用南瓜书?
模型回答:
使用南瓜书的方法如下:
1. 以西瓜书为主线:南瓜书的内容是以西瓜书为基础的,因此在学习过程中应以西瓜书为主线,将南瓜书作为辅助资料。在学习西瓜书的过程中,如果遇到自己推导不出来或者看不懂的公式,可以查阅南瓜书相应的章节进行补充学习。
2. 简单浏览第1章和第2章的公式:对于初学机器学习的小白,南瓜书第1章和第2章的公式建议简单浏览一下,了解大致内容即可。当你学习到一定程度,对机器学习有了一定了解后,可以回来再深入研究这些公式。
3. 查阅超纲数学知识:南瓜书的编写原则是以本科数学基础的视角进行讲解,因此对于一些超纲的数学知识,南瓜书会以附录和参考文献的形式给出。如果你对这些内容感兴趣,可以根据南瓜书提供的资料进行深入学习。
4. 反馈和勘误:如果在南瓜书中没有找到你想要查阅的公式,或者发现南瓜书中有错误,请毫不犹豫地去GitHub的Issues进行反馈,提交你希望补充的公式编号或者勘误信息。我们通常会在24小时以内给您回复。
5. 参考视频教程:为了更好地理解南瓜书的内容,可以参考配套的视频教程:https://www.bilibili.com/video/BV1Mh411e7VU。
6. 加入读者交流群:扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群”,与其他读者一起交流学习心得,互相帮助。
总之,南瓜书的使用方法应以西瓜书为主线,遇到难以理解的内容时再参考南瓜书进行补充学习。在学习过程中,可以利用视频教程和读者交流群来提高学习效果。同时,南瓜书的编委会也非常欢迎读者提出反馈和勘误,共同完善南瓜书的内容。
查询结果:
print(result["source_documents"])
[Document(page_content='为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;\n• 对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建议深究,简单过一下即可,等你学得\n有点飘的时候再回来啃都来得及;\n• 每个公式的解析和推导我们都力(zhi) 争(neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识\n我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;\n• 若南瓜书里没有你想要查阅的公式,\n或者你发现南瓜书哪个地方有错误,\n请毫不犹豫地去我们GitHub 的\nIssues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应版块\n提交你希望补充的公式编号或者勘误信息,我们通常会在24 小时以内给您回复,超过24 小时未回复的\n话可以微信联系我们(微信号:at-Sm1les)\n;\n配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU', metadata={'author': '', 'creationDate': "D:20230303170709-00'00'", 'creator': 'LaTeX with hyperref', 'file_path': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'format': 'PDF 1.5', 'keywords': '', 'modDate': '', 'page': 1, 'producer': 'xdvipdfmx (20200315)', 'source': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'subject': '', 'title': '', 'total_pages': 196, 'trapped': ''}), Document(page_content='在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1 版)\n最新版PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/releases\n编委会\n主编:Sm1les、archwalker、jbb0523\n编委:juxiao、Majingmin、MrBigFan、shanry、Ye980226\n封面设计:构思-Sm1les、创作-林王茂盛\n致谢\n特别感谢awyd234、\nfeijuan、\nGgmatch、\nHeitao5200、\nhuaqing89、\nLongJH、\nLilRachel、\nLeoLRH、\nNono17、\nspareribs、sunchaothu、StevenLzq 在最早期的时候对南瓜书所做的贡献。\n扫描下方二维码,然后回复关键词“南瓜书”\n,即可加入“南瓜书读者交流群”\n版权声明\n本作品采用知识共享署名-非商业性使用-相同方式共享4.0 国际许可协议进行许可。', metadata={'author': '', 'creationDate': "D:20230303170709-00'00'", 'creator': 'LaTeX with hyperref', 'file_path': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'format': 'PDF 1.5', 'keywords': '', 'modDate': '', 'page': 1, 'producer': 'xdvipdfmx (20200315)', 'source': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'subject': '', 'title': '', 'total_pages': 196, 'trapped': ''}), Document(page_content='\x01本\x03:1.9.9\n发布日期:2023.03\n南 ⽠ 书\nPUMPKIN\nB O O K\nDatawhale', metadata={'author': '', 'creationDate': "D:20230303170709-00'00'", 'creator': 'LaTeX with hyperref', 'file_path': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'format': 'PDF 1.5', 'keywords': '', 'modDate': '', 'page': 0, 'producer': 'xdvipdfmx (20200315)', 'source': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'subject': '', 'title': '', 'total_pages': 196, 'trapped': ''}), Document(page_content='前言\n“周志华老师的《机器学习》\n(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读\n者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推\n导细节的读者来说可能“不太友好”\n,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充\n具体的推导细节。\n”\n读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周\n老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书\n中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”\n。所以...... 本南瓜书只能算是我\n等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二\n下学生”\n。\n使用说明\n• 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书\n为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;', metadata={'author': '', 'creationDate': "D:20230303170709-00'00'", 'creator': 'LaTeX with hyperref', 'file_path': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'format': 'PDF 1.5', 'keywords': '', 'modDate': '', 'page': 1, 'producer': 'xdvipdfmx (20200315)', 'source': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'subject': '', 'title': '', 'total_pages': 196, 'trapped': ''})]
我们做出相应评估:
① 知识查找正确性——1
② 回答一致性——0.8(解答了问题,但是类似于“反馈”的话题偏题了)
③ 回答幻觉比例——1
④ 回答正确性——0.8(理由同上)
⑤ 逻辑性——0.7(后续内容与前面逻辑连贯性不强)
⑥ 通顺性——0.6(最后总结啰嗦且无效)
⑦ 智能性——0.5(具有 AI 回答的显著风格)
2.自动评估
大模型评估之所以复杂,一个重要原因在于生成模型的答案很难判别,即客观题评估判别很简单,主观题评估判别则很困难。尤其是对于一些没有标准答案的问题,实现自动评估就显得难度尤大。但是,在牺牲一定评估准确性的情况下,我们可以将复杂的没有标准答案的主观题进行转化,从而变成有标准答案的问题,进而通过简单的自动评估来实现。此处介绍两种方法:构造客观题与计算标准答案相似度。
方法一. 构造客观题
主观题的评估是非常困难的,但是客观题可以直接对比系统答案与标准答案是否一致,从而实现简单评估。我们可以将部分主观题构造为多项或单项选择的客观题,进而实现简单评估。例如,对于问题:
【问答题】南瓜书的作者是谁?
可以将该主观题构造为如下客观题:
【多选择题】南瓜书的作者是谁? A 周志明 B 谢文睿 C 秦州 D 贾彬彬
要求模型回答该客观题,定标准答案为 BCD,将模型给出答案与标准答案对比即可实现评估打分。根据以上思想,我们可以构造出一个 Prompt 问题模板:
prompt_template = '''
请你做如下选择题:
题目:南瓜书的作者是谁?
选项:A 周志明 B 谢文睿 C 秦州 D 贾彬彬
你可以参考的知识片段:
```
{}
```
请仅返回选择的选项
如果你无法做出选择,请返回空
'''
当然,由于大模型的不稳定性,即使要求其只给出选择选项,系统可能也会返回一大堆文字,其中详细解释了为什么选择如下选项。因此,需要将选项从模型回答中抽取出来。同时,需要设计一个打分策略。一般情况下,可以使用多选题的一般打分策略:全选1分,漏选0.5分,错选不选不得分:
def multi_select_score_v1(true_answer : str, generate_answer : str) -> float:
# true_anser : 正确答案,str 类型,例如 'BCD'
# generate_answer : 模型生成答案,str 类型
true_answers = list(true_answer)
'''为便于计算,我们假设每道题都只有 A B C D 四个选项'''
# 先找出错误答案集合
false_answers = [item for item in ['A', 'B', 'C', 'D'] if item not in true_answers]
# 如果生成答案出现了错误答案
for one_answer in false_answers:
if one_answer in generate_answer:
return 0
# 再判断是否全选了正确答案
if_correct = 0
for one_answer in true_answers:
if one_answer in generate_answer:
if_correct += 1
continue
if if_correct == 0:
# 不选
return 0
elif if_correct == len(true_answers):
# 全选
return 1
else:
# 漏选
return 0.5
基于上述打分函数,我们可以测试四个回答:
① B C
② 除了 A 周志华之外,其他都是南瓜书的作者
③ 应该选择 B C D
④ 我不知道
answer1 = 'B C'
answer2 = '西瓜书的作者是 A 周志华'
answer3 = '应该选择 B C D'
answer4 = '我不知道'
true_answer = 'BCD'
print("答案一得分:", multi_select_score_v1(true_answer, answer1))
print("答案二得分:", multi_select_score_v1(true_answer, answer2))
print("答案三得分:", multi_select_score_v1(true_answer, answer3))
print("答案四得分:", multi_select_score_v1(true_answer, answer4))
答案一得分: 0.5
答案二得分: 0
答案三得分: 1
答案四得分: 0
在上述打分策略中,错选和不选均为0分,这样其实鼓励了模型的幻觉回答,因此我根据情况调整打分策略,让错选扣一分:
def multi_select_score_v2(true_answer : str, generate_answer : str) -> float:
# true_anser : 正确答案,str 类型,例如 'BCD'
# generate_answer : 模型生成答案,str 类型
true_answers = list(true_answer)
'''为便于计算,我们假设每道题都只有 A B C D 四个选项'''
# 先找出错误答案集合
false_answers = [item for item in ['A', 'B', 'C', 'D'] if item not in true_answers]
# 如果生成答案出现了错误答案
for one_answer in false_answers:
if one_answer in generate_answer:
return -1
# 再判断是否全选了正确答案
if_correct = 0
for one_answer in true_answers:
if one_answer in generate_answer:
if_correct += 1
continue
if if_correct == 0:
# 不选
return 0
elif if_correct == len(true_answers):
# 全选
return 1
else:
# 漏选
return 0.5
再次测试打分结果
答案一得分: 0.5
答案二得分: -1
答案三得分: 1
答案四得分: 0
方法二. 计算答案相似度
针对一些不能构造为客观题或构造为客观题会导致题目难度骤降的情况,使用计算答案相似度。
例如,对问题:
南瓜书的目标是什么?
可以首先人工构造一个标准回答:
周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充具体的推导细节。
接着对模型回答计算其与该标准回答的相似程度,越相似则认为答案正确程度越高。
计算相似度方法:一般可以使用 BLEU
知乎|BLEU详解
调用 nltk 库中的 bleu 打分函数来计算
from nltk.translate.bleu_score import sentence_bleu
import jieba
def bleu_score(true_answer : str, generate_answer : str) -> float:
# true_anser : 标准答案,str 类型
# generate_answer : 模型生成答案,str 类型
true_answers = list(jieba.cut(true_answer))
# print(true_answers)
generate_answers = list(jieba.cut(generate_answer))
# print(generate_answers)
bleu_score = sentence_bleu(true_answers, generate_answers)
return bleu_score
测试
true_answer = '周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充具体的推导细节。'
print("答案一:")
answer1 = '周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充具体的推导细节。'
print(answer1)
score = bleu_score(true_answer, answer1)
print("得分:", score)
print("答案二:")
answer2 = '本南瓜书只能算是我等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二下学生”'
print(answer2)
score = bleu_score(true_answer, answer2)
print("得分:", score)
返回结果
Building prefix dict from the default dictionary ...
答案一:
周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充具体的推导细节。
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.470 seconds.
Prefix dict has been built successfully.
得分: 1.2705543769116016e-231
答案二:
本南瓜书只能算是我等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二下学生”
得分: 1.1935398790363042e-231
但是,该种方法同样存在几个问题:
① 需要人工构造标准答案。
② 通过相似度来评估,可能存在问题。例如,如果生成回答与标准答案高度一致但在核心的几个地方恰恰相反导致答案完全错误,bleu 得分仍然会很高;
③ 通过计算与标准答案一致性灵活性很差,如果模型生成了比标准答案更好的回答,但评估得分反而会降低;
④ 无法评估回答的智能性、流畅性。如果回答是各个标准答案中的关键词拼接出来的,可能回答是不可用无法理解的,但 bleu 得分会较高。
3.使用大模型评估
可以通过构造 Prompt Engineering 让大模型充当一个评估者的角色,从而替代人工评估的评估员;同时大模型可以给出类似于人工评估的结果,因此可以采取人工评估中的多维度量化评估的方式,实现快速全面的评估。
例如,我们可以构造如下的 Prompt Engineering,让大模型进行打分:
prompt = '''
你是一个模型回答评估员。
接下来,我将给你一个问题、对应的知识片段以及模型根据知识片段对问题的回答。
请你依次评估以下维度模型回答的表现,分别给出打分:
① 知识查找正确性。评估系统给定的知识片段是否能够对问题做出回答。如果知识片段不能做出回答,打分为0;如果知识片段可以做出回答,打分为1。
② 回答一致性。评估系统的回答是否针对用户问题展开,是否有偏题、错误理解题意的情况,打分分值在0~1之间,0为完全偏题,1为完全切题。
③ 回答幻觉比例。该维度需要综合系统回答与查找到的知识片段,评估系统的回答是否出现幻觉,打分分值在0~1之间,0为全部是模型幻觉,1为没有任何幻觉。
④ 回答正确性。该维度评估系统回答是否正确,是否充分解答了用户问题,打分分值在0~1之间,0为完全不正确,1为完全正确。
⑤ 逻辑性。该维度评估系统回答是否逻辑连贯,是否出现前后冲突、逻辑混乱的情况。打分分值在0~1之间,0为逻辑完全混乱,1为完全没有逻辑问题。
⑥ 通顺性。该维度评估系统回答是否通顺、合乎语法。打分分值在0~1之间,0为语句完全不通顺,1为语句完全通顺没有任何语法问题。
⑦ 智能性。该维度评估系统回答是否拟人化、智能化,是否能充分让用户混淆人工回答与智能回答。打分分值在0~1之间,0为非常明显的模型回答,1为与人工回答高度一致。
你应该是比较严苛的评估员,很少给出满分的高评估。
用户问题:
```
{}
```
待评估的回答:
```
{}
```
给定的知识片段:
```
{}
```
你应该返回给我一个可直接解析的 Python 字典,字典的键是如上维度,值是每一个维度对应的评估打分。
不要输出任何其他内容。
'''
测试代码
from zhipuai import ZhipuAI
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
client = ZhipuAI(
api_key=zhipuai_api_key
)
def gen_glm_params(prompt):
'''
构造 GLM 模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
def get_completion(prompt, model="chatglm_std", temperature = 0):
'''
获取 GPT 模型调用结果
请求参数:
prompt: 对应的提示词
model: 调用的模型,默认为 gpt-3.5-turbo,也可以按需选择 gpt-4 等其他模型
temperature: 模型输出的温度系数,控制输出的随机程度,取值范围是 0~2。温度系数越低,输出内容越一致。
'''
response = client.chat.completions.create(
model=model,
messages=gen_glm_params(prompt),
temperature=temperature,
)
if len(response.choices) > 0:
return response.choices[0].message.content
return "generate answer error"
question = "应该如何使用南瓜书?"
result = qa_chain({"query": question})
answer = result["result"]
knowledge = result["source_documents"]
response = get_completion(prompt.format(question, answer, knowledge))
response
返回结果
' {\n "知识查找正确性": 1,\n "回答一致性": 1,\n "回答幻觉比例": 0.333333333333333,\n "回答正确性": 1,\n "逻辑性": 1,\n "通顺性": 1,\n "智能性": 0.666666666666666\n}'
使用大模型进行评估仍然存在问题:
① 所选用的评估大模型需要有优于所使用的大模型基座的性能
② 问题与回答太复杂或是要求评估维度太多
改进方法:
- 改进 Prompt Engineering。
- 拆分评估维度。
- 合并评估维度。
- 提供详细的评估规范。
- 提供少量示例。
4.混合评估
事实上,上述评估方法都不是孤立、对立的,相较于独立地使用某一种评估方法,、更推荐将多种评估方法混合起来,对于每一种维度选取其适合的评估方法,兼顾评估的全面、准确和高效。
例如,针对本项目个人知识库助手,我们可以设计以下混合评估方法:
- 客观正确性。客观正确性指对于一些有固定正确答案的问题,模型可以给出正确的回答。
- 主观正确性。主观正确性指对于没有固定正确答案的主观问题,模型可以给出正确的、全面的回答。、
- 智能性。智能性指模型的回答是否足够拟人化。由于智能性与问题本身弱相关,与模型、Prompt 强相关,且模型判断智能性能力较弱,可以少量抽样进行人工评估其智能性。
- 知识查找正确性。知识查找正确性指对于特定问题,从知识库检索到的知识片段是否正确、是否足够回答问题。知识查找正确性推荐使用大模型进行评估,即要求模型判别给定的知识片段是否足够回答问题。同时,该维度评估结果结合主观正确性可以计算幻觉情况,即如果主观回答正确但知识查找不正确,则说明产生了模型幻觉。
使用上述评估方法,基于已得到的验证集示例,可以对项目做出合理评估。
二.评估并优化生成部分
先加载向量数据库与检索链
from zhipuai_embedding import ZhipuAIEmbeddings # zhipuai_embedding.py
from zhipuai_llm import ZhipuAILLM # zhipuai_llm.py
from langchain.vectorstores.chroma import Chroma
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
# OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = '../../data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
# 使用 OpenAI GPT-3.5 模型
llm = ZhipuAILLM(model="chatglm_std", temperature=0, api_key=zhipuai_api_key)
先使用初始化的 Prompt 创建一个基于模板的检索链
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
template_v1 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v1)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
question = "什么是南瓜书"
result = qa_chain({"query": question})
print(result["result"])
测试返回输出
南瓜书是一本针对机器学习初学者的学习资料,以周志华老师的《机器学习》(西瓜书)为前置知识,对其中的难点和难以理解的公式进行解析和补充推导细节。编委会成员包括Sm1les、archwalker、jbb0523、juxiao、Majingmin、MrBigFan、shanry、Ye980226等。南瓜书的在线阅读地址为https://datawhalechina.github.io/pumpkin-book,最新版PDF获取地址为https://github.com/datawhalechina/pumpkin-book/releases。
1. 提升直观回答质量
寻找 Bad Case 的思路有很多,最直观也最简单的就是评估直观回答的质量,结合原有资料内容,判断在什么方面有所不足。
上述的测试可以构造成一个 Bad Case:
问题:什么是南瓜
初始回答:略
存在不足:回答太简略,需要回答更具体;谢谢你的提问感觉比较死板,可以去掉
再针对性地修改 Prompt 模板,加入要求其回答具体,并去掉“谢谢你的提问”的部分:
template_v2 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v2)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
question = "什么是南瓜书"
result = qa_chain({"query": question})
print(result["result"])
改进后输出
南瓜书是一本针对机器学习初学者的学习资料,它的主要目的是对西瓜书(周志华老师的《机器学习》)中较难理解的公式进行解析,以及补充部分公式的具体推导细节。南瓜书的编写团队力图以本科数学基础的视角进行讲解,对于超纲的数学知识,通常以附录和参考文献的形式给出。南瓜书的最佳使用方法是以西瓜书为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书。
改进后的 v2 版本能够给出更具体、详细的回答。
question = "使用大模型时,构造 Prompt 的原则有哪些"
result = qa_chain({"query": question})
print(result["result"])
返回结果
使用大模型时,构造 Prompt 的原则包括:
1. 清晰、具体:Prompt 需要清晰明确地表达需求,提供充足上下文,使语言模型准确理解我们的意图,就像向一个外星人详细解释人类世界一样。
2. 逐步推理:Prompt 应加入逐步推理的要求,给模型留出充分思考时间,这样生成的结果才更准确可靠。
Bad Case:
问题:使用大模型时,构造 Prompt 的原则有哪些
初始回答:略
存在不足:没有重点,模糊不清
针对该 Bad Case,我们可以改进 Prompt,要求其对有几点的答案进行分点标号,让答案清晰具体:
template_v3 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
如果答案有几点,你应该分点标号回答,让答案清晰具体
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v3)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
question = "使用大模型时,构造 Prompt 的原则有哪些"
result = qa_chain({"query": question})
print(result["result"])
返回结果
使用大模型时,构造 Prompt 的原则包括:
1. 清晰、具体:Prompt 需要清晰明确地表达需求,提供充足上下文,使语言模型准确理解我们的意图,就像向一个外星人详细解释人类世界一样。过于简略的 Prompt 往往使模型难以把握所要完成的具体任务。
2. 使用分隔符:通过使用分隔符(如空格、换行等)清晰地表示输入的不同部分,有助于模型更准确地理解意图。
3. 逐步推理:让语言模型有充足时间推理,避免匆忙得出结论。Prompt 应加入逐步推理的要求,给模型留出充分思考时间,这样生成的结果才更准确可靠。
4. 充足上下文:在 Prompt 中提供足够的上下文和细节,有助于模型更准确地把握所需的操作和响应方式。
5. 简洁明了:尽管复杂的 Prompt 提供了更丰富的上下文和细节,但过于冗长的 Prompt 可能会让模型难以理解。因此,在保持清晰、具体的同时,也要力求简洁明了。
总之,在使用大模型时,构造 Prompt 的原则是让模型尽可能地发挥潜力,完成复杂的推理和生成任务,从而实现高效、准确的语言模型交互。
2.标明知识来源,提高可信度
由于大模型存在幻觉问题,有时我们会怀疑模型回答并非源于已有知识库内容,这对一些需要保证真实性的场景来说尤为重要,例如:
question = "强化学习的定义是什么"
result = qa_chain({"query": question})
print(result["result"])
输出结果
强化学习是一种机器学习方法,其主要目标是通过学习一个智能体在与环境的交互过程中如何做出最佳决策来获得最大化的累积奖赏。在强化学习中,智能体在某个状态下采取某个动作后,会获得一个奖赏信号,这个信号会告诉智能体它的决策是好还是不好。智能体通过不断尝试和接收奖赏信号来学习如何在不同状态下采取最佳动作,以实现长期的最优化目标。
修改prompt,要求模型在生成回答时注明知识来源,这样可以避免模型杜撰并不存在于给定资料的知识,同时,也可以提高我们对模型生成答案的可信度
template_v4 = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
如果答案有几点,你应该分点标号回答,让答案清晰具体。
请你附上回答的来源原文,以保证回答的正确性。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v4)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
question = "强化学习的定义是什么"
result = qa_chain({"query": question})
print(result["result"])
输出结果
强化学习是一种机器学习方法,旨在让智能体通过与环境的交互学习如何做出一系列好的决策。在这个过程中,智能体会根据环境的反馈(奖励)来调整自己的行为,以最大化长期奖励的总和。强化学习的目标是在不确定的情况下做出最优的决策,类似于让一个小孩通过不断尝试来学会走路的过程。强化学习的交互过程由智能体和环境两部分组成,智能体根据环境的状态选择动作,环境根据智能体的动作输出下一个状态和奖励。强化学习的应用非常广泛,包括游戏玩法、机器人控制、交通管理等领域。【来源:蘑菇书一语二语二强化学习教程】。
3. 构造思维链
大模型往往可以很好地理解并执行指令,但模型本身还存在一些能力的限制,例如大模型的幻觉、无法理解较为复杂的指令、无法执行复杂步骤等。我们可以通过构造思维链,将 Prompt 构造成一系列步骤来尽量减少其能力限制,例如,我们可以构造一个两步的思维链,要求模型在第二步做出反思,以尽可能消除大模型的幻觉问题。
Bad Case:
问题:我们应该如何去构造一个 LLM 项目
初始回答:略
存在不足:事实上,知识库中中关于如何构造LLM项目的内容是使用 LLM API 去搭建一个应用,模型的回答看似有道理,实则是大模型的幻觉,将部分相关的文本拼接得到,存在问题
question = "我们应该如何去构造一个LLM项目"
result = qa_chain({"query": question})
print(result["result"])
输出
构建一个LLM项目需要考虑以下几个步骤:
1. 确定项目目标和需求:首先要明确你的项目是为了解决什么问题或实现什么目标,确定需要使用LLM的具体场景和任务。
2. 收集和准备数据:根据项目需求,收集和准备适合的数据集,确保数据的质量和多样性,以提高LLM的性能和效果。
3. 设计Prompt和指令微调:根据项目需求设计合适的Prompt,确保指令清晰明确,可以引导LLM生成符合预期的文本。
4. 进行模型训练和微调:使用基础LLM或指令微调LLM对数据进行训练和微调,以提高模型在特定任务上的表现和准确性。
5. 测试和评估模型:在训练完成后,对模型进行测试和评估,检查其在不同场景下的表现和效果,根据评估结果进行必要的调整和优化。
6. 部署和应用模型:将训练好的LLM模型部署到实际应用中,确保其能够正常运行并实现预期的效果,持续监测和优化模型的性能。
来源:根据提供的上下文内容进行总结。
对此,我们可以优化 Prompt,将之前的 Prompt 变成两个步骤,要求模型在第二个步骤中做出反思:
template_v4 = """
请你依次执行以下步骤:
① 使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。
你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
如果答案有几点,你应该分点标号回答,让答案清晰具体。
上下文:
{context}
问题:
{question}
有用的回答:
② 基于提供的上下文,反思回答中有没有不正确或不是基于上下文得到的内容,如果有,回答你不知道
确保你执行了每一个步骤,不要跳过任意一个步骤。
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v4)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
question = "我们应该如何去构造一个LLM项目"
result = qa_chain({"query": question})
print(result["result"])
输出结果
根据上下文中提供的信息,构造一个LLM项目需要考虑以下几个步骤:
1. 确定项目目标:首先要明确你的项目目标是什么,是要进行文本摘要、情感分析、实体提取还是其他任务。根据项目目标来确定LLM的使用方式和调用API接口的方法。
2. 设计Prompt:根据项目目标设计合适的Prompt,Prompt应该清晰明确,指导LLM生成符合预期的结果。Prompt的设计需要考虑到任务的具体要求,比如在文本摘要任务中,Prompt应该包含需要概括的文本内容。
3. 调用API接口:根据设计好的Prompt,通过编程调用LLM的API接口来生成结果。确保API接口的调用方式正确,以获取准确的结果。
4. 分析结果:获取LLM生成的结果后,进行结果分析,确保结果符合项目目标和预期。如果结果不符合预期,可以调整Prompt或者其他参数再次生成结果。
5. 优化和改进:根据分析结果的反馈,不断优化和改进LLM项目,提高项目的效率和准确性。可以尝试不同的Prompt设计、调整API接口的参数等方式来优化项目。
通过以上步骤,可以构建一个有效的LLM项目,利用LLM的强大功能来实现文本摘要、情感分析、实体提取等任务,提高工作效率和准确性。如果有任何不清楚的地方或需要进一步的指导,可以随时向相关领域的专家寻求帮助。
4.增加一个指令解析
我们往往会面临一个需求,即我们需要模型以我们指定的格式进行输出。但是,由于我们使用了 Prompt Template 来填充用户问题,用户问题中存在的格式要求往往会被忽略,例如:
question = "LLM的分类是什么?给我返回一个 Python List"
result = qa_chain({"query": question})
print(result["result"]
问题:LLM的分类是什么?给我返回一个 Python List
初始回答:根据提供的上下文,LLM的分类可以分为基础LLM和指令微调LLM。
存在不足:没有按照指令中的要求输出
template_v4 = """
请你依次执行以下步骤:
① 使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答案。
你应该使答案尽可能详细具体,但不要偏题。如果答案比较长,请酌情进行分段,以提高答案的阅读体验。
如果答案有几点,你应该分点标号回答,让答案清晰具体。
上下文:
{context}
问题:
{question}
有用的回答:
② 基于提供的上下文,反思回答中有没有不正确或不是基于上下文得到的内容,如果有,回答你不知道
确保你执行了每一个步骤,不要跳过任意一个步骤。
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template_v4)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
question = "我们应该如何去构造一个LLM项目"
result = qa_chain({"query": question})
print(result["result"])
三.评估并优化检索部分
1. 评估检索效果
针对用户输入的一个 query,系统会将其转化为向量并在向量数据库中匹配最相关的文本段,然后根据我们的设定选择 3~5 个文本段落和用户的 query 一起交给大模型,再由大模型根据检索到的文本段落回答用户 query 中提出的问题。
将向量数据库检索相关文本段落的部分称为检索部分
将大模型根据检索到的文本段落进行答案生成的部分称为生成部分。
检索部分的核心功能是找到存在于知识库中、能够正确回答用户 query 中的提问的文本段落
定义一个最直观的准确率在评估检索效果:对于 N 个给定 query,保证每一个 query 对应的正确答案都存在于知识库中。假设对于每一个 query,系统找到了 K 个文本片段,如果正确答案在 K 个文本片段之一,那么我们认为检索成功;如果正确答案不在 K 个文本片段之一,任务检索失败。那么,系统的检索准确率可以被简单地计算为:
a
c
c
u
r
a
c
y
=
M
N
accuracy = \frac{M}{N}
accuracy=NM
其中,M 是成功检索的 query 数。
2.优化检索的思路
知识片段被割裂导致答案丢失
该问题一般表现为,对于一个用户 query,我们可以确定其问题一定是存在于知识库之中的,但是我们发现检索到的知识片段将正确答案分割开了,导致不能形成一个完整、合理的答案。该种问题在需要较长回答的 query 上较为常见。
该类问题的一般优化思路是,优化文本切割方式。
-
对于一些格式统一、组织清晰的知识文档,可以针对性构建更合适的分割规则;
-
对于格式混乱、无法形成统一的分割规则的文档,可以考虑纳入一定的人力进行分割。
-
训练一个专用于文本分割的模型,来实现根据语义和主题的 chunk 切分。
query 提问需要长上下文概括回答
部分 query 提出的问题需要检索部分跨越很长的上下文来做出概括性回答,也就是需要跨越多个 chunk 来综合回答问题。但是由于模型上下文限制,往往很难给出足够的 chunk 数。
该类问题的一般优化思路是,优化知识库构建方式。
针对可能需要此类回答的文档
- 可以增加一个步骤,通过使用 LLM 来对长文档进行概括总结
- 预设提问让 LLM 做出回答,从而将此类问题的可能答案预先填入知识库作为单独的 chunk,来一定程度解决该问题。
关键词误导
该问题一般表现为,对于一个用户 query,系统检索到的知识片段有很多与 query 强相关的关键词,但知识片段本身并非针对 query 做出的回答。这种情况一般源于 query 中有多个关键词,其中次要关键词的匹配效果影响了主要关键词。
该类问题的一般优化思路是,对用户 query 进行改写,这也是目前很多大模型应用的常用思路。
即对于用户输入 query
- 首先通过 LLM 来将用户 query 改写成一种合理的形式,去除次要关键词以及可能出现的错字、漏字的影响。具体改写成什么形式根据具体业务而定,可以要求 LLM 对 query 进行提炼形成 Json 对象
- 可以要求 LLM 对 query 进行扩写等。
匹配关系不合理
该问题是较为常见的,即匹配到的强相关文本段并没有包含答案文本。该问题的核心问题在于,我们使用的向量模型和我们一开始的假设不符。很多向量模型其实构建的是“配对”的语义相似度而非“因果”的语义相似度,例如对于 query-“今天天气怎么样”,会认为“我想知道今天天气”的相关性比“天气不错”更高。
该类问题的一般优化思路是,优化向量模型或是构建倒排索引。
-
我们可以选择效果更好的向量模型,或是收集部分数据,在自己的业务上微调一个更符合自己业务的向量模型。
-
考虑构建倒排索引,即针对知识库的每一个知识片段,构建一个能够表征该片段内容但和 query 的相对相关性更准确的索引,在检索时匹配索引和 query 的相关性而不是全文,从而提高匹配关系的准