论文:CM-UNet: Hybrid :CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
代码:https://github.com/XiaoBuL/CM-UNet
Abstrcat:
由于大规模图像尺寸和对象变化,当前基于 CNN 和 Transformer 的遥感图像语义分割方法对于捕获远程依赖性不是最佳的,或者受限于复杂的计算复杂性。在本文中,我们提出了 CM-UNet,包括用于提取局部图像特征的基于 CNN 的编码器和用于聚合和集成全局信息的基于 Mamba 的解码器,促进遥感图像的高效语义分割。具体来说,引入 CSMamba 块来构建核心分割解码器,该解码器采用通道和空间注意力作为 vanilla Mamba 的门激活条件,以增强特征交互和全局局部信息融合。此外,为了进一步细化 CNN 编码器的输出特征,采用多尺度注意力聚合(MSAA)模块来合并不同尺度的特征。 通过集成CSMamba模块和MSAA模块,CM-UNet有效捕获大规模遥感图像的长距离依赖关系和多尺度全局上下文信息。 在三个基准上获得的实验结果表明,所提出的 CM-UNet 在各种性能指标上都优于现有方法。
Introduction
在本文中,我们提出了 CM-UNet,一种用于 RS(遥感) 图像语义分割的新颖框架。 CM-UNet 利用 Mamba 架构聚合来自 CNN 编码器的多尺度信息。 它由一个 U 形网络和一个解码器组成,其中的 CNN 编码器提取多尺度文本信息,解码器采用设计的 CSMamba 块,可实现高效的语义信息聚合。 CSMamba 模块利用 Mamba 模块以线性时间复杂度捕获长程依赖性,并采用通道和空间注意力进行特征选择。CSMamba 块作为之前的自注意力转换器块的替代方案,提高了 RS 语义分割的效率。 此外,引入了多尺度注意力聚合(MSAA)模块来集成来自 CNN 编码器不同级别的特征,通过跳过连接帮助 CSMamba 解码器。 最后,CM-UNet 在各个解码器级别结合了多输出监督,以逐步生成 RS 图像的语义分割。 贡献总结如下:
1)我们提出了一个名为 CM-UNet 的基于 mamba 的框架,以有效地集成局部全局信息以进行 RS 图像语义分割。
2)我们设计了一个 CSMamba 块,将通道和空间注意力信息包含到 mamba 块中以提取全局上下文信息。 此外,我们采用多尺度注意力聚合模块来辅助跳跃连接和多输出损失来逐步监督语义分割。
3)在三个著名的公开RS数据集(ISPRS Potsdam、ISPRS Vaihingen和LoveDA)上进行的广泛实验表明了所提出的CM-UNet的优越性。
Methodology
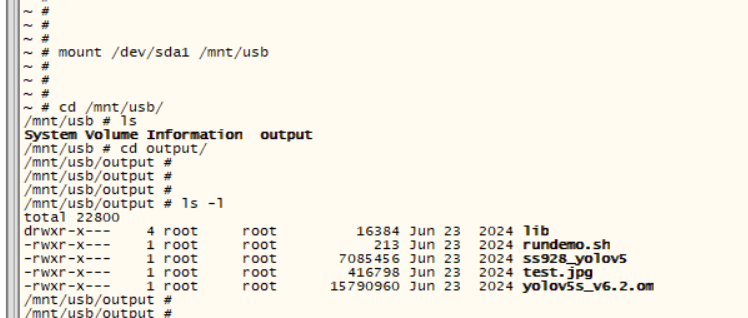
我们的 CM-UNet 框架如图 2 (a) 所示,包含三个核心组件:基于 CNN 的编码器、MSAA 模块和基于 CSMamba 的解码器。 编码器采用 ResNet 提取多级特征,而 MSAA 模块融合这些特征,取代 UNet 的普通跳过连接并增强解码器的能力。 在 CSMamba 解码器中,CSMamba 块的组装聚合了本地文本特征以建立全面的语义理解。
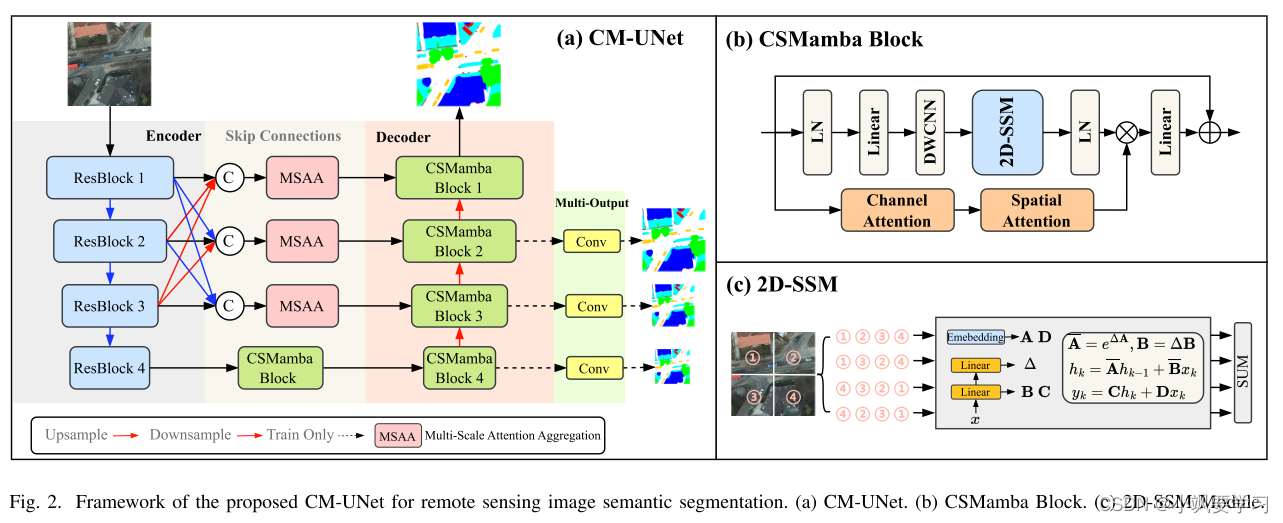
A、CSMamba Block
受 Mamba 在线性复杂度远程建模方面取得成功的激励,我们将视觉状态空间模块引入 RS 语义分割领域。 按照[10],输入特征
X
∈
R
H
×
W
×
C
X\in\mathbb{R}^{H\times W\times C}
X∈RH×W×C 将经过两个并行分支。在第一个分支中,特征通道通过线性层扩展至 λC,其中 λ 是预定义的通道扩展因子,随后是深度卷积、SiLU 激活函数以及 2D-SSM 层和 Layernorm。在第二个分支中,特征通过通道和空间注意力(CS)以及随后的 SiLU 激活函数进行集成。之后,将两个分支的特征与 Hadamard product(哈达玛积)进行聚合。 最后,将通道号投影回 C 以生成与输入形状相同的输出 Xout:
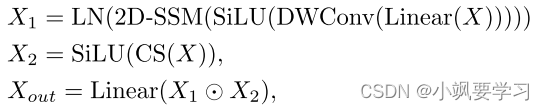
其中DWConv表示深度卷积,CS表示通道和空间注意模块,2D-SSM表示2D选择性扫描模块,⊙表示Hadamard积。原始的 Mamba 模型通过顺序选择性扫描处理一维数据,这适合 NLP 任务,但对图像等非因果数据形式提出了挑战。继[10]之后,我们结合了 2D 选择性扫描模块(2D-SSM)来进行图像语义分割。 如图2©所示,2D-SSM将图像特征展平为一维序列,并在四个方向上扫描:左上到右下、右下到左上、右上到左下。 ,以及从左下角到右上角。 这种方法通过选择性状态空间模型捕获每个方向的远程依赖性。 然后合并方向序列以恢复二维结构。
Multi-Scale Attention Aggregation多尺度注意力聚合
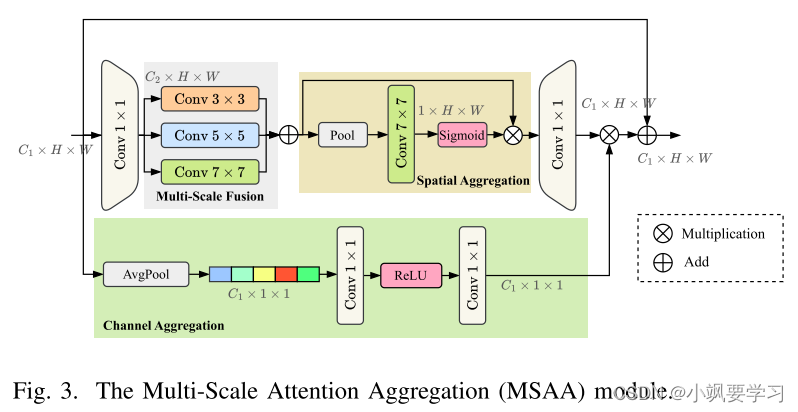
图 3 描述了用于细化 RS 图像特征的多尺度注意力聚合 (MSAA) 模块。 ResNet 编码器阶段 F1、F2 和 F3 的输出被连接为
F
^
i
=
C
o
n
c
a
t
(
F
i
,
F
i
−
1
,
F
i
+
1
)
\hat{F}_{i}=\mathrm{Concat}(F_{i},F_{i-1},F_{i+1})
F^i=Concat(Fi,Fi−1,Fi+1)。组合特征
F
^
∈
R
C
1
×
H
×
W
\hat{F} \in \mathcal{R}^{C_{1}\times H\times W}
F^∈RC1×H×W被馈送到 MSAA 中进行细化。 在 MSAA 中,双路径(空间路径和通道路径)用于特征聚合。 空间细化从通道投影开始,通过 1×1 卷积将通道 C1 减少到 C2,其中
C
2
=
C
1
α
C_{2}=\frac{C_{1}}{\alpha}
C2=αC1。多尺度融合涉及对不同内核大小(例如 3 × 3、5 × 5、7 × 7)的卷积进行求和。随后,使用均值和最大池化来聚合空间特征,然后进行 7 × 7 卷积和与 sigmoid 激活的特征图。
同时,通道聚合使用全局平均池化将维度降低至 C1 × 1 × 1,然后通过 1 × 1 卷积和 ReLU 激活来生成通道注意力图。 该图经过扩展以匹配输入的尺寸,并与空间细化的图相结合。 因此,MSAA 增强了后续网络层的空间和通道特征。 通过合并 MSAA 模块,生成的特征图丰富了精细的空间和通道信息。
Multi-Output Supervision (多输出监督)
为了有效地监督解码器逐步生成 RS 图像的语义分割图,我们的 CM-UNet 架构在每个 CSMamba 块上结合了中间监督。 这确保了网络的每个阶段都对最终的分割结果做出贡献,从而促进更精细和准确的输出。 对于第 i 个 CSMamba 块的中间输出是
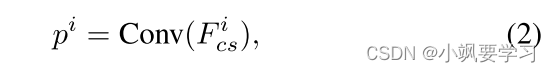
其中 Fcs 是第 i 个 CSMamba 块的特征。 Conv 模块用于将特征映射到输出 C 通道类别预测图。 总体而言,网络是使用标准交叉熵损失和 Dice 损失的组合进行训练的。
Conclusion
在本文中,我们介绍了 CM-UNet,这是一个利用最新 Mamba 架构进行 RS 语义分割的高效框架。 我们的设计通过采用新颖的 UNet 形结构来解决大规模 RS 图像中的显着目标变化。 编码器利用 ResNet 提取文本信息,而解码器利用 CSMamba 块有效捕获全局远程依赖关系。 此外,我们还集成了多尺度注意力聚合(MSAA)模块和多输出增强功能,以进一步支持多尺度特征学习。 CM-UNet 已在三个 RS 语义分割数据集上进行了验证,实验结果证明了我们方法的优越性。
![[数据库原理]关系范式总结(自用)](https://img-blog.csdnimg.cn/direct/ef1db0fe89f34de7959e76445a551884.jpeg)
![this.$refs[tab.$attrs.id].scrollIntoView is not a function](https://img-blog.csdnimg.cn/direct/9e23c60d80104bc89df5a32d498cdc98.png)