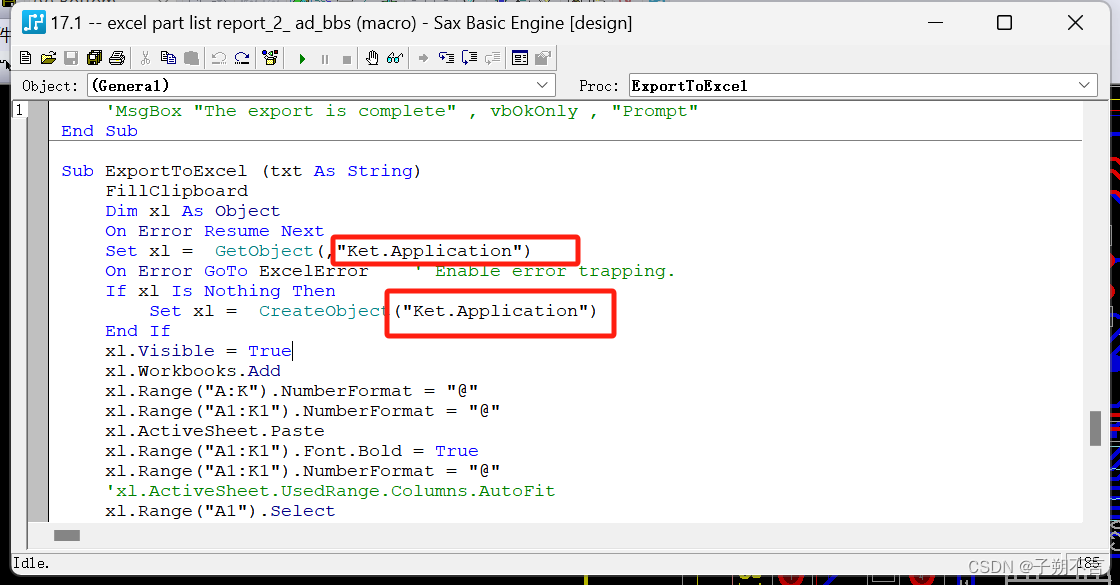
大模型的奥林匹克竞赛来了!
最近,上交构建了一个全面、极具挑战性的奥赛级别的基准——OlympicArena,从来自62个不同奥林匹克竞赛中筛选出11,163个问题,涵盖数学、物理、化学、生物、地理、天文学和计算机科学等七个学科,细分为34个专业领域。除了8类逻辑推理任务外,还有5类视觉推理能力,分为13种答案类型(如表达式、区间)。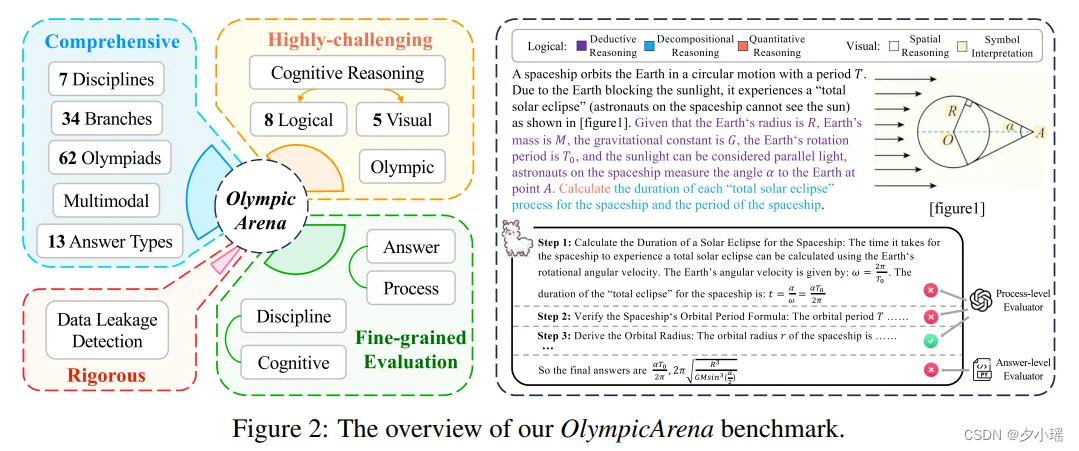
论文标题:
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
论文链接:
https://arxiv.org/pdf/2406.12753

奥林匹克竞赛,作为选拔拔尖青少年人才的竞赛,其难度与挑战性不言而喻。在奥赛中获得优异成绩的同学可以获得保送名牌大学和参加自主招生考试的资格。
那么大模型在奥赛中的表现如何呢?
作者提供了一套全面的资源来支持AI研究,包括基准数据集、开源标注平台、详细的评估工具和带有自动提交功能的排行榜:
https://github.com/GAIR-NLP/OlympicArena
数据提取与标注
该基准的数据来源于各种竞赛的URL,支持以PDF格式公开下载。作者使用Mathpix4工具将PDF文档转换为Markdown格式,以便与模型的输入要求兼容。对于计算机科学的编程问题,还额外收集了相应的测试用例。然后聘请了约30名具有科学和工程背景的学生进行标注。并开发了一个多模态数据标注界面:
https://github.com/GAIR-NLP/OlympicArena/tree/main/annotation
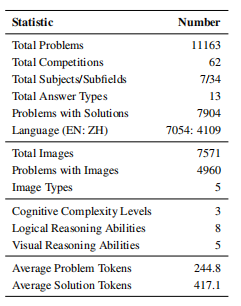
最终基准统计情况如下表所示:
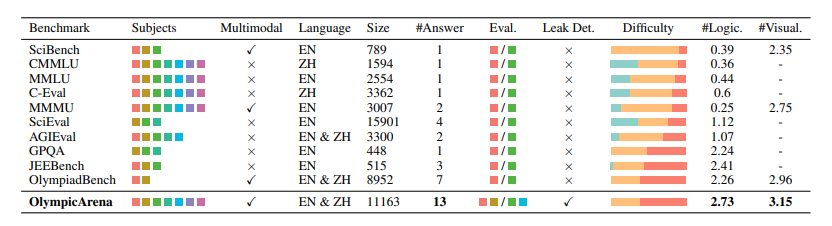
作者使用GPT-4V作为标注器对问题进行难度分类,分为知识回忆、概念应用和认知推理三级,并与相关基准对比,该基准第三级难度(认知推理)的问题占大多数,而其他基准相对较少。
在简单了解了该基准的规模,我们进入正题,看一看大模型在奥赛上的表现吧!
GPT-4o的整体准确率仅为39.97%

目前最强大模型GPT-4o的整体准确率仅为39.97%,而其他开源模型更是只有20%左右。
在不同学科的任务中,数学和物理仍然是最具有挑战性的两个学科。另外计算机编程竞赛的难度同样不容忽视,部分开源模型的准确率甚至为0,反映出当前模型在复杂算法设计上的不足。
大模型在逻辑推理和视觉推理上表现各不相同
为了进行更好的细粒度分析,作者从逻辑和视觉两个角度对认知推理能力进行了分类。逻辑推理能力包括: 演绎推理(DED)、归纳推理(IND)、假设推理(ABD)、类比推理(ANA)、因果推理(CAE)、批判性思维(CT)、分解推理(DEC)和定量推理(QUA)。视觉推理能力包括模式识别(PR)、空间推(SPA)、图表推理(DIA)、符号解释(SYB)和比较可视化(COM)。

从图中来看,几乎所有模型在各类逻辑推理能力上展现相似的表现趋势——即在归纳和因果推理方面表现出色,能准确识别信息中的因果关系;但在演绎和分解推理上则稍显不足,这主要由于奥赛级别问题的多样性和复杂性,非常需要分解问题的能力,而这也是大模型的短板。
对视觉推理,模型在模式识别和可视化比较上表现良好,但在处理空间和几何推理以及理解抽象符号的任务时则面临挑战。
大多数LMMs无法熟练利用视觉信息
如下图a所示,只有少数LMM(如GPT-4o和Qwen-VL-Chat)在有图像输入时相对于其文本版有显著提升。许多LMM在处理图像输入时并未表现出增强效果,甚至不升反降。
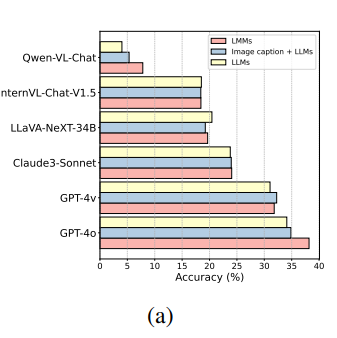
可能有以下原因:
-
LMM在处理文本和图像时可能过度关注文本,忽略了图像信息。
-
某些LMM在通过文本模型训练视觉能力时,可能丧失部分固有的语言能力(如推理能力)。
-
鉴于问题中复杂的文本与图像交错格式,部分模型难以有效处理和理解嵌入在文本中的图像位置信息。
大模型虽不能得出正确答案,但能正确执行部分中间步骤。
为了深入研究推理步骤的正确性, 确保对模型认知能力的严格评估, 作者还进行了过程级评估。从OlympicArena中随机选取96个有参考解法的问题。我们使用GPT-4将参考解(即黄金解法)和模型生成的解法转换为结构化的逐步解答格式。然后将这些解法提供给GPT-4V,对每个步骤的正确性打分,范围从0到1。
从下图b中,可以看到过程级评估与答案级评估通常高度一致。这说明当模型产生正确答案时,推理过程的质量大多较高。
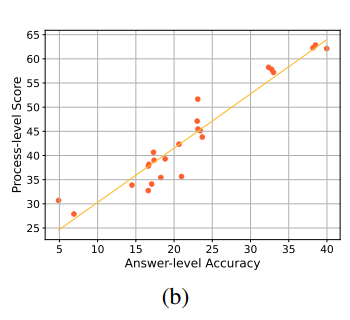
另外过程层面的准确性通常高于答案层面。即使面对非常复杂的问题,模型也能正确执行部分中间步骤。 因此,模型在认知推理方面可能有大量未开发的潜力。
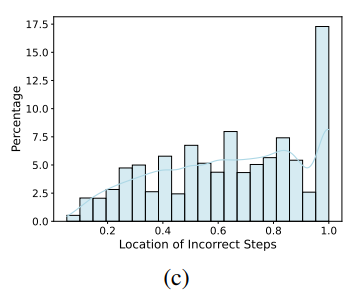
此外,作者对错误步骤的位置进行了统计分析,如下图。结果显示,错误容易出现在后期。这表明随着推理的深入,模型更容易出错,因此需要在处理逻辑推理的长链上进行改进。
错误分析:推理错误比例最高
为了具体评估模型的表现,作者从GPT-4V的回答中随机选取错误回答,让人类分析并标注这些错误的原因。

推理错误(包括逻辑和视觉上的)比例最高,该基准有效地突显了当前模型在认知推理能力上的不足。
此外,相当一部分错误源于知识匮乏,表明当前模型仍然缺乏专家级的领域知识以及利用这些知识进行推理的能力。另一种类型的错误源于理解偏差,这可能是由于模型对上下文理解有误,或是整合复杂语言结构和多模态信息时遇到了困难。
数据泄露检测
随着预训练数据集规模的扩大,有必要检测基准数据是否已经泄露。
作者引入了N-gram预测准确率这一实例级泄漏检测指标。该指标为每个实例均匀采样多个起始点,预测每个起始点的下一个n-gram,并检查所有预测的n-gram,如果都正确,则表明模型可能已经遇到了这个实例,该实例已经被泄露。

从统计数据来看,尽管数量相对较少,但一些模型确实可能已经看过了基准实例。
既然数据已经被泄露了,那么模型能否正确回答这些实例?有趣的是,能回答正确的非常少。
这些结果表明,该基准数据泄漏风险极低,且对模型来说具有足够的挑战性。
结论
本文提出了一个用于评估大模型在奥赛级别问题上的认知推理能力的基准——OlympicArena。目前最强大的模型GPT-4o在运用认知推理解决复杂问题时都表现不佳,大模型在复杂推理和多模态整合方面仍存在局限性。该基准有望推动大模型向超级智能迈进!