文章目录
- what(是什么)
- where(用在哪)
- How(原理&&怎么用)
- 原理以及推导过程
- pytorch中的反向传播
what(是什么)
反向传播算法(Backpropagation)是一种用于训练人工神经网络的常见方法。它通过计算网络预测与实际结果之间的误差,然后反向传播这个误差来调整网络中每个权重的值,从而逐步优化网络的学习过程

where(用在哪)
绝大多数的神经网络都会使用反向传播算法进行网络权重以及阈值的更新,简单列举部分典型的使用场景如下
How(原理&&怎么用)
原理以及推导过程
下面重点介绍反向传播算法的推导流程

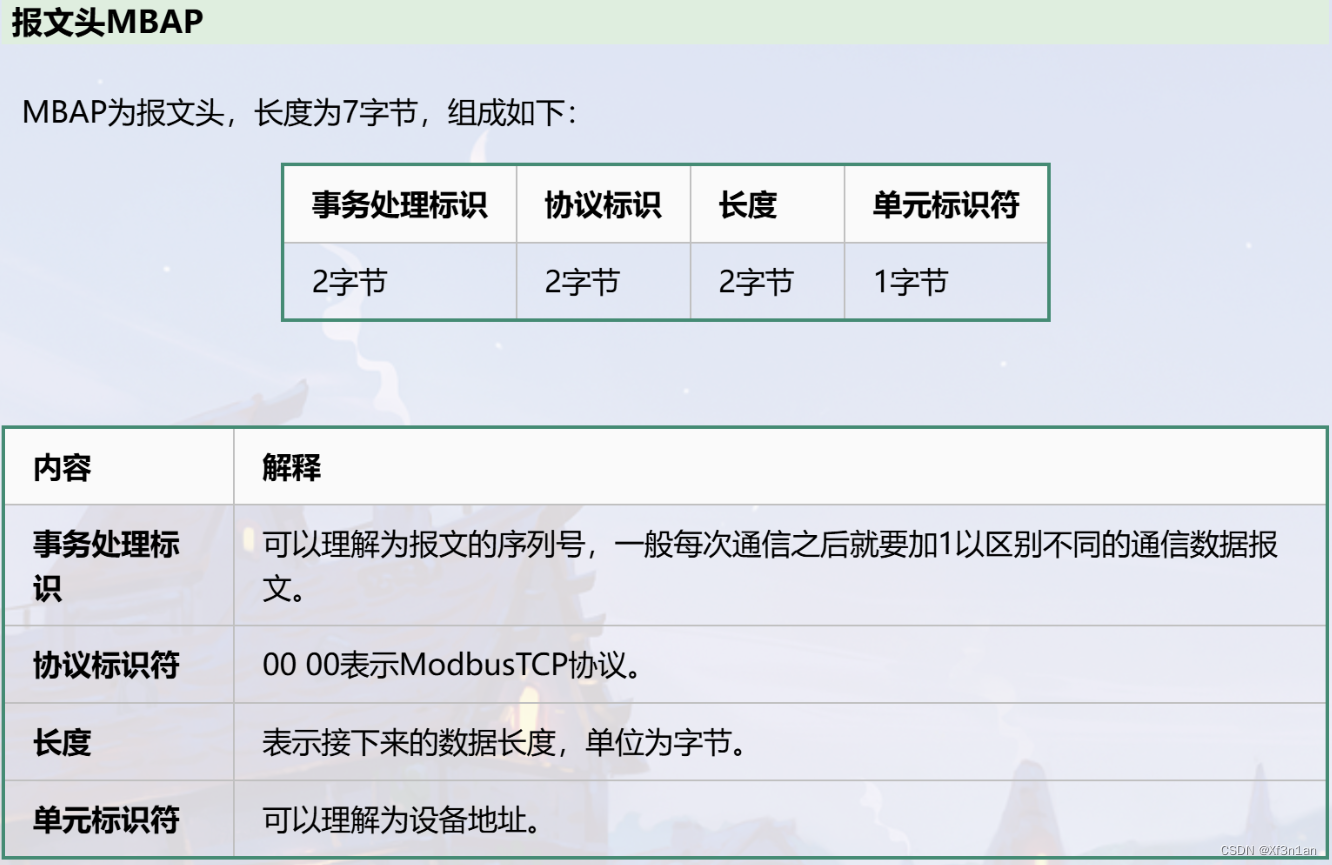
假设有以上简单的神经网路模型,分为输入层、隐藏层、输出层。其中隐藏层包括4个神经元、输出层包括2个神经元。
假设输出层的两个神经元为
y
1
y_1
y1,
y
2
y_2
y2,其激活阈值分别为
β
\beta
β,
γ
\gamma
γ,两个神经元的输入分别为
y
1
i
n
y_{1in}
y1in,
y
2
i
n
y_{2in}
y2in,输出分别为
y
1
^
\hat{y_1}
y1^和
y
2
^
\hat{y_2}
y2^。
假设隐藏层四个神经元为
h
1
h_1
h1,
h
2
h_2
h2,
h
3
h_3
h3,
h
4
h_4
h4,其中
h
1
h_1
h1的激活阈值为
δ
\delta
δ,神经元
h
1
h_1
h1的输入值为
h
i
n
h_{in}
hin,输出值为
h
o
u
t
h_{out}
hout。
假设输入层两个神经元为
x
1
x_1
x1,
x
2
x_2
x2,其中神经元
x
1
x_1
x1的输出为
x
o
u
t
x_{out}
xout。
假设神经元
x
1
x_1
x1到神经元
h
1
h_1
h1的连接权重为
W
11
W_{11}
W11,神经元
h
1
h_1
h1到神经元
y
1
y_1
y1、
y
2
y_2
y2的连接权重分别为
W
21
W_{21}
W21、
W
22
W_{22}
W22。
假设神经元的激活函数为sigmoid函数,sigmoid激活函数的表达式:
f
(
x
)
=
1
1
−
e
−
x
f(x)=\frac{1}{1-e^{-x}}
f(x)=1−e−x1
该激活函数有一个非常好的性质:
f
′
(
x
)
=
f
(
x
)
(
1
−
f
(
x
)
)
f'(x)=f(x)(1-f(x))
f′(x)=f(x)(1−f(x))
下面,详细介绍连接权重
W
W
W以及激活阈值的更新过程。
首先,给出
W
21
W_{21}
W21以及
β
\beta
β的更新公式,其中,
W
21
W_{21}
W21更新公式为:
W
21
=
W
21
+
η
∗
Δ
W
21
W_{21}=W_{21}+\eta*\Delta W_{21}
W21=W21+η∗ΔW21
同理,
β
\beta
β更新公式为:
β
=
β
+
η
∗
Δ
β
\beta=\beta+\eta*\Delta \beta
β=β+η∗Δβ
在以上公式中,只有
Δ
W
21
\Delta W_{21}
ΔW21以及
Δ
β
\Delta \beta
Δβ未知,需要计算。而已知的是样本,也就是
(
x
,
y
)
(x,y)
(x,y),那么我们将通过样本数据来表达出上述
Δ
W
21
\Delta W_{21}
ΔW21以及
Δ
β
\Delta \beta
Δβ。
根据反向传播算法,
Δ
W
21
\Delta W_{21}
ΔW21以及
Δ
β
\Delta \beta
Δβ分别为最终的误差对
W
21
W_{21}
W21以及
β
\beta
β的偏导数。假设采用的损失函数为:
L
o
s
s
=
1
2
(
y
1
−
y
1
^
)
2
+
1
2
(
y
2
−
y
2
^
)
2
Loss=\frac{1}{2}(y_1-\hat{y_1})^2+\frac{1}{2}(y_2-\hat{y_2})^2
Loss=21(y1−y1^)2+21(y2−y2^)2
扩展到输出层有k个神经元的情况:
L
o
s
s
=
1
2
Σ
1
k
(
y
i
−
y
i
^
)
2
Loss=\frac{1}{2}\Sigma_1^k(y_i-\hat{y_i})^2
Loss=21Σ1k(yi−yi^)2
而从输出端看,能得到以下表达式:
y
1
^
=
f
(
y
1
i
n
−
β
)
=
f
(
W
21
h
o
u
t
−
β
)
\hat{y_1}=f(y_{1in}-\beta)=f(W_{21}h_{out}-\beta)
y1^=f(y1in−β)=f(W21hout−β)
将
y
1
^
\hat{y_1}
y1^带入到损失函数中,也就是:
L
o
s
s
=
1
2
(
y
1
−
f
(
W
21
h
o
u
t
−
β
)
)
2
+
1
2
(
y
2
−
f
(
W
22
h
o
u
t
−
γ
)
)
2
Loss = \frac{1}{2}(y_1-f(W_{21}h_{out}-\beta))^2+\frac{1}{2}(y_2-f(W_{22}h_{out}-\gamma))^2
Loss=21(y1−f(W21hout−β))2+21(y2−f(W22hout−γ))2
如此,便得出损失和
W
21
W_{21}
W21之间的代数关系式,接下来只需要对该表达式求导即可得到
Δ
W
21
\Delta W_{21}
ΔW21以及
Δ
β
\Delta \beta
Δβ。
首先,
∂
L
o
s
s
∂
W
21
\frac{\partial Loss}{\partial W_{21}}
∂W21∂Loss的计算公式为:
∂
L
o
s
s
∂
W
21
=
[
y
1
−
f
(
W
21
h
o
u
t
−
β
)
]
∗
[
−
f
′
(
W
21
h
o
u
t
−
β
)
]
∗
h
o
u
t
=
−
[
y
1
−
f
(
W
21
h
o
u
t
−
β
)
]
∗
f
(
W
21
h
o
u
t
−
β
)
[
1
−
(
f
(
W
21
h
o
u
t
−
β
)
)
]
∗
h
o
u
t
=
−
(
y
1
−
y
1
^
)
∗
y
1
^
∗
(
1
−
y
1
^
)
∗
h
o
u
t
\begin{aligned} \frac{\partial Loss}{\partial W_{21}} & = [y_1-f(W_{21}h_{out}-\beta)]*[-f'(W_{21}h_{out}-\beta)]*h_{out} \\ & =- [y_1-f(W_{21}h_{out}-\beta)]*f(W_{21}h_{out}-\beta)[1-(f(W_{21}h_{out}-\beta))]*h_{out} \\ & = -(y_1-\hat{y_1})*\hat{y_1}*(1-\hat{y_1})*h_{out} \end{aligned}
∂W21∂Loss=[y1−f(W21hout−β)]∗[−f′(W21hout−β)]∗hout=−[y1−f(W21hout−β)]∗f(W21hout−β)[1−(f(W21hout−β))]∗hout=−(y1−y1^)∗y1^∗(1−y1^)∗hout
同样地,
∂
L
o
s
s
∂
β
\frac{\partial Loss}{\partial \beta}
∂β∂Loss的计算公式为:
∂
L
o
s
s
∂
β
=
[
y
1
−
f
(
W
21
h
o
u
t
−
β
)
]
∗
[
−
f
′
(
W
21
h
o
u
t
−
β
)
]
∗
(
−
1
)
=
[
y
1
−
f
(
W
21
h
o
u
t
−
β
)
]
∗
f
(
W
21
h
o
u
t
−
β
)
[
1
−
(
f
(
W
21
h
o
u
t
−
β
)
)
]
=
(
y
1
−
y
1
^
)
∗
y
1
^
∗
(
1
−
y
1
^
)
\begin{aligned} \frac{\partial Loss}{\partial \beta} & = [y_1-f(W_{21}h_{out}-\beta)]*[-f'(W_{21}h_{out}-\beta)]*(-1) \\ & = [y_1-f(W_{21}h_{out}-\beta)]*f(W_{21}h_{out}-\beta)[1-(f(W_{21}h_{out}-\beta))] \\ & = (y_1-\hat{y_1})*\hat{y_1}*(1-\hat{y_1}) \end{aligned}
∂β∂Loss=[y1−f(W21hout−β)]∗[−f′(W21hout−β)]∗(−1)=[y1−f(W21hout−β)]∗f(W21hout−β)[1−(f(W21hout−β))]=(y1−y1^)∗y1^∗(1−y1^)
由于梯度下降法,需要沿着负梯度方向,所以,
Δ
W
21
=
−
∂
L
o
s
s
∂
W
21
\Delta W_{21}=-\frac{\partial Loss}{\partial W_{21}}
ΔW21=−∂W21∂Loss,
Δ
β
=
−
∂
L
o
s
s
∂
β
\Delta \beta=-\frac{\partial Loss}{\partial \beta}
Δβ=−∂β∂Loss,从而得出
W
21
,
β
W_{21},\beta
W21,β的更新公式为:
W
21
=
W
21
+
η
∗
Δ
W
21
=
W
21
−
η
∗
∂
L
o
s
s
∂
W
21
=
W
21
+
η
∗
(
y
1
−
y
1
^
)
∗
y
1
^
∗
(
1
−
y
1
^
)
∗
h
o
u
t
\begin{aligned} W_{21} &= W_{21} + \eta*\Delta W_{21} \\ & = W_{21}-\eta * \frac{\partial Loss}{\partial W_{21}} \\ & =W_{21}+\eta *(y_1-\hat{y_1})*\hat{y_1}*(1-\hat{y_1})*h_{out} \end{aligned}
W21=W21+η∗ΔW21=W21−η∗∂W21∂Loss=W21+η∗(y1−y1^)∗y1^∗(1−y1^)∗hout
β = β + η ∗ Δ β = β − η ∗ ∂ L o s s ∂ β = β − η ∗ ( y 1 − y 1 ^ ) ∗ y 1 ^ ∗ ( 1 − y 1 ^ ) \begin{aligned} \beta & = \beta+\eta*\Delta \beta \\ & = \beta-\eta* \frac{\partial Loss}{\partial \beta} \\ & = \beta-\eta *(y_1-\hat{y_1})*\hat{y_1}*(1-\hat{y_1}) \end{aligned} β=β+η∗Δβ=β−η∗∂β∂Loss=β−η∗(y1−y1^)∗y1^∗(1−y1^)
使用同样的方式,可以对 W 11 , δ W_{11},\delta W11,δ的梯度公式进行计算和更新。
pytorch中的反向传播
下面举例说明在pytorch中,如何使用反向传播算法来更新权重以及阈值。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义一个复杂的神经网络
class ComplexNet(nn.Module):
def __init__(self):
super(ComplexNet, self).__init__()
self.fc1 = nn.Linear(10, 50) # 输入大小为10,输出大小为50
self.fc2 = nn.Linear(50, 20) # 输入大小为50,输出大小为20
self.fc3 = nn.Linear(20, 1) # 输入大小为20,输出大小为1
def forward(self, x):
x = F.relu(self.fc1(x)) # 使用ReLU作为激活函数
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 创建网络实例
model = ComplexNet()
# 定义损失函数
criterion = nn.MSELoss()
# 随机生成一些输入和目标输出数据
input_data = torch.randn((32, 10)) # 32个样本,每个样本特征数为10
target_output = torch.randn((32, 1)) # 对应的32个目标输出
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
model.train() # 设置模型为训练模式
epochs = 1000
for epoch in range(epochs):
# 梯度清零
optimizer.zero_grad()
# 前向传播
output = model(input_data)
# 计算损失
loss = criterion(output, target_output)
# 反向传播
loss.backward()
# 更新模型参数
optimizer.step()
# 每隔一段时间输出一下损失值
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
# 打印模型结构
print(model)
在pythrch中,输入在流经每一个神经元时,会构建一个动态计算图(与tensorflow不同,tensorflow为静态计算图),记录了每个神经元的输入输出信息。在反向传播时, loss.backward()会根据已知的样本数据以及神经元的输入输出信息,计算连接权重以及阈值的梯度,然后optimizer.step()来实现对权重和阈值的更新。需要注意的是,在每一个mini-batch开始前,需要使用optimizer.zero_grad()对梯度置零。

![[ROS 系列学习教程] 建模与仿真 - 使用 ros_control 控制差速轮式机器人](https://img-blog.csdnimg.cn/direct/5878cc3a6b6d4a58930e1f15be32b924.gif#pic_center)