#GPT3
文章目录
- 前言
- 正文
- 摘要
- 介绍
- 方法
- 模型结构
- 训练数据集
- 训练过程
- 评估
- 小结
前言
OpenAI在放出GPT2后,并没有引起业界太大的影响和关注,究其原因,并不是zero-shot这种想法不够吸引人,而是GPT2表现出来的效果依然差强人意,仍然属于“人工智障”的阶段,然而OpenAI认为他们的方向没有问题,不在特定领域上做太多的微调,甚至不做微调(这样就能避免1.人工标注数据和2.重新训练模型)才是大规模语言模型的未来,因此在不久之后他们又提出了GPT-3,这也就是chatGPT的前生了。
正文
摘要
最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调,在许多NLP任务和基准方面取得了实质性进展。但这种方法仍然需要对数千或数万个示例的特定于任务的标注数据集进行微调。相比之下,人类通常只需要几个例子或简单的指令就能完成一项新的语言任务——这是当前NLP系统仍难以做到的。在这里,我们证明了扩展语言模型能大大提高了任务不可知、few-shot的性能,有时甚至达到了与现有最先进的微调方法相比的竞争力。
具体来说,我们训练GPT-3,这是一个具有1750亿个参数的自回归语言模型,比之前的任何非稀疏语言模型大至少10倍,并在few-shot设置下测试其性能。对于所有任务,GPT-3都是在没有任何梯度更新或微调的情况下应用的,仅通过与模型的文本交互来指定任务和少数镜头演示。GPT-3在许多NLP数据集上都有很强的性能,包括翻译、问题解答和完形填空任务,以及一些需要动态推理或领域适应的任务,如解译单词、在句子中使用一个新单词或执行三位数算术。同时,我们还确定了GPT-3的few-shot学习仍然困难的一些数据集,以及GPT-3面临与大型网络语料库上的训练相关的方法问题的一些数据集中。最后,我们发现GPT-3可以生成新闻文章样本,人类评估人员很难将其与人类撰写的文章区分开来。我们讨论了这一发现和GPT-3的更广泛的社会影响。
介绍
如上面提到的,目前主流的语言模型都是采用的pre-train+fine-tune的模式,虽然以BERT为首的这类模型已经在众多NLP任务中取得了出色甚至是sota的效果,但这种模式仍然存在许多问题和限制:
- 在fine-tune阶段需要大量的标注数据集,很多时候这是难以获得的
- 我们预训练模型的时候,为了使用更多更广的预训练数据,往往会把模型设计得更大。但在预训练阶段使用的数据分布往往十分“狭窄”。大模型和“狭窄”数据集之间显然容易过拟合,使得fine-tune过后的大模型泛化能力很差。
- 对于大多数语言任务,人类并不需要很多的“监督数据”就能学习,比如“here are two examples of people acting brave; please give a third example of bravery”通常就足够一个人类理解并完成该任务。除了指出我们当前NLP技术在概念上的局限性之外,这种适应性还具有实际优势——它允许人类无缝地混合在一起或在许多任务和技能之间切换,例如在长时间对话中执行加法。为了广泛使用,我们希望有一天我们的NLP系统具有相同的流动性和通用性。
解决这些问题的一个潜在途径是meta-learning——在语言模型的背景下,这意味着该模型在训练时培养了广泛的技能和模式识别能力,然后在推理时使用这些能力来快速适应或识别期望的任务(如图1所示)。最近的工作试图通过我们所称的“in-context learning”来实现这一点,使用预先训练的语言模型的文本输入作为任务规范的形式:该模型以自然语言指令和/或任务的一些演示为条件,然后通过预测下一步将发生什么来完成任务。尽管它已经显示出一些初步的希望,但这种方法仍然取得了远不如微调的结果——例如[RWC+19]在自然问题上仅取得了4%的成绩,甚至其55 F1 CoQa的成绩现在也落后于最先进水平35分以上。元学习显然需要大幅改进,才能成为解决语言任务的实用方法。
语言建模的另一个最新趋势可能提供了前进的方向。近年来,变压器语言模型的容量大幅增加,从1亿个参数[RNSS18],到3亿个参数[DCLT18],到15亿个参数/RWC+19],到80亿个参数[SSP+19],110亿个参数RSR+19],最后是170亿个参数[Tur20]。每一次增加都带来了文本合成和/或下游NLP任务的改进,有证据表明,log loss与许多下游任务密切相关,随着规模的增长,log loss呈现平稳的改善趋势[KMH+20]。由于in-context learning在模型的参数范围内吸收许多技能和任务,因此,in-context learning能力可能会随着规模的增长而表现出同样强大的增益。
在本文中,我们通过训练一个1750亿参数的自回归语言模型(我们称之为GPT-3)并测量其in-context learning能力来检验这一假设。具体来说,我们在20多个NLP数据集上评估GPT-3,以及几个不太可能直接包含在训练集中的新任务(验证模型的快速适应性)。对于每项任务,我们在3个条件下评估GPT-3:
- “few-shot learning”,或在in-context learning中,我们允许尽可能多的演示,以适应模型的上下文窗口(通常为10到100);
- “one-shot learning”(仅允许一次演示);
- “zero-shot learning”,其中不允许演示,只向模型提供自然语言指令。
GPT-3原则上也可以在传统的微调设置中进行评估,但我们将这留给未来的工作。
图1说明了我们研究的条件,并显示了需要模型从单词中删除多余符号的简单任务的少量学习。随着自然语言任务描述的增加以及模型上下文中的示例数量的增加,模型性能得到了改善。few-shot学习也随着模型大小的增加而显著提高。尽管本案例中的结果特别引人注目,但模型大小和上下文中示例数量的总体趋势适用于我们研究的大多数任务。再次强调,这些“学习”曲线不涉及梯度更新或微调,只是增加了作为条件的演示次数。
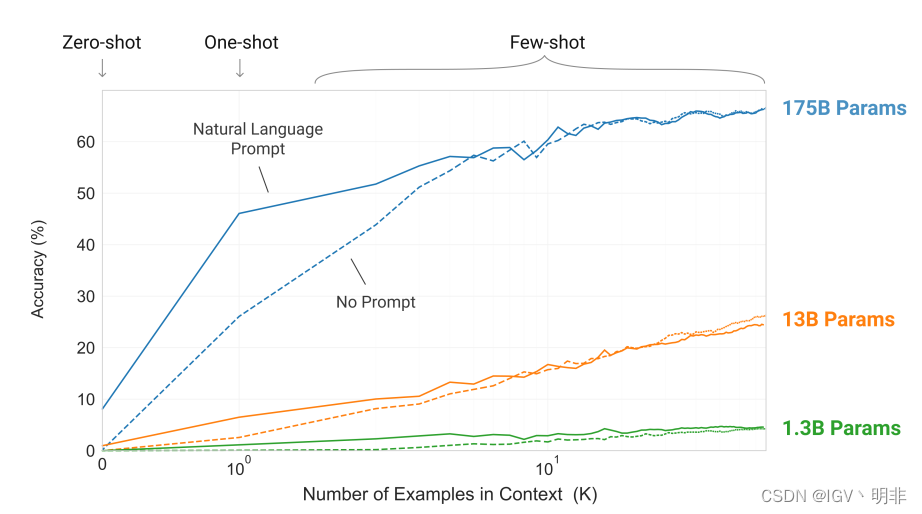
总体而言,在NLP任务中,GPT-3在zero-shot和one-shot设置中取得了令人满意的结果,在few-shot设置中与sota模型相比具有竞争力,甚至有时超越当前fine-tune的sota模型。
方法
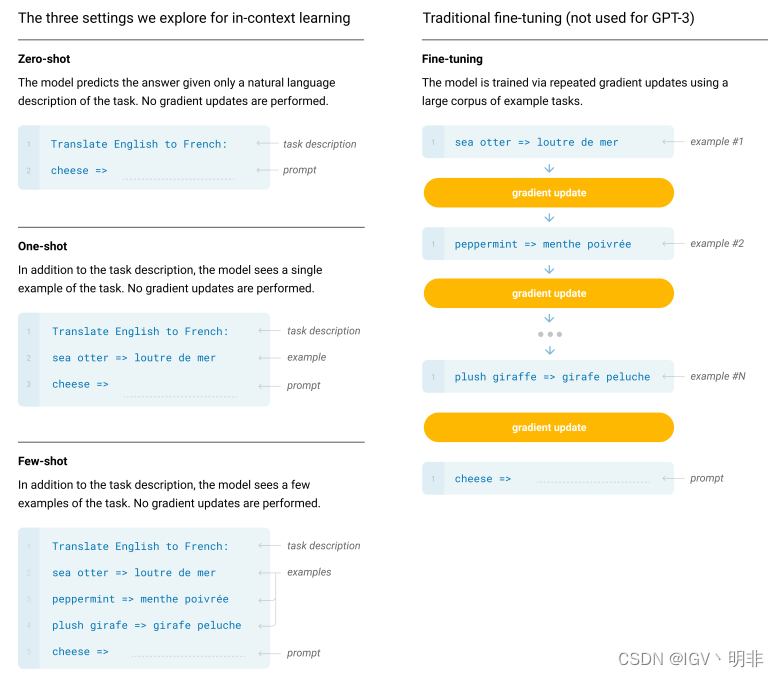
我们的基本预训练方法,包括模型、数据和训练,与GPT2中所述的过程类似,模型大小、数据集大小和多样性以及训练长度的扩展相对简单。但在这项工作中,我们系统地探索了不同设置。因此,我们通过明确定义和对比我们将要评估GPT-3或原则上可以评估GPT-3的不同设置来开始本节。这些设置可以被视为取决于他们倾向于依赖多少特定任务的数据。具体来说,我们有四种设置:
1.Fine-Tuning;2.Few-Shot; 3.One-Shot; 4.Zero-Shot;
我们用一幅图就可以很形象地说明这四种设置的主要特点和具体使用方法:
模型结构
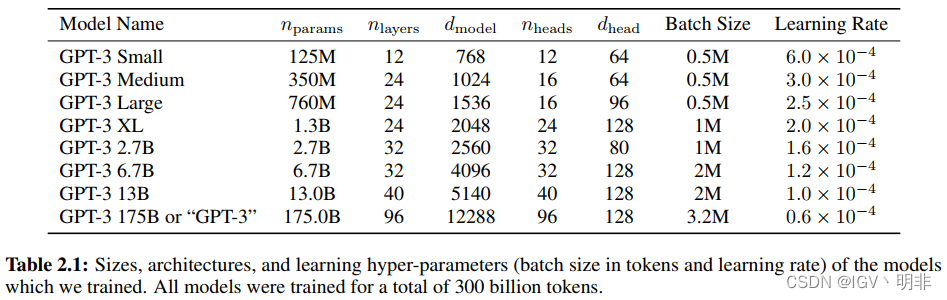
我们使用与GPT-2相同的模型和架构,除了alternating dense and locally banded sparse attention patterns in the layers of the transformer,,类似于Sparse Transformer[CGRS19]。为了研究ML性能对模型大小的依赖性,我们训练了8种不同大小的模型,从1.25亿个参数到1750亿个参数的三个数量级,最后一个是我们称为GPT-3的模型。先前的工作[KMH+20]表明,如果有足够的训练数据,验证损失的缩放应该近似于平滑幂律;这些不同大小的训练模型允许我们测试验证损失和下游语言任务的假设。
下表是不同模型大小的参数,所有模型的文本窗口
n
c
t
x
=
2048
n_{ctx}=2048
nctx=2048:
训练数据集
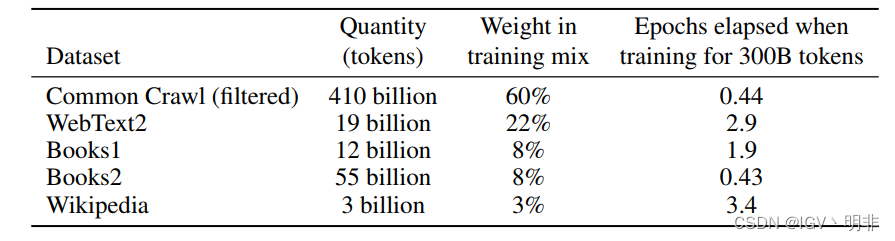
语言模型的数据集迅速扩展,最终形成了近万亿个单词的Common Crawl数据集2[RSR+19]。这种数据集足以在一个epoch下训练我们最大的模型。然而,未过滤或轻度过滤的Common Crawl版本的质量往往低于更精确的数据集。因此,我们采取了3个步骤来提高数据集的平均质量:(1)我们基于一系列高质量参考语料库的相似性对CommonCrawl语料过滤;(2) 我们在文档级别、数据集内部和数据集之间执行了模糊重复数据消除,以防止冗余,并保持我们所持验证集的完整性,作为过度拟合的准确度量(3)我们还将已知的高质量参考语料库添加到训练组合中,以增强CommonCrawl并增加其多样性。
表2显示了我们在训练中使用的数据集的最终混合。注意,在训练期间,数据集的采样不与其大小成比例,而是我们认为质量更高的数据集采样频率更高,因此CommonCrawl和Books2数据集在训练期间采样频率少于1,但其他数据集采样频率为2-3次。这是以少量的过拟合,以换取更高质量的训练数据。
训练过程
如[KMH+20,MKAT18]所示,较大的模型通常可以使用较大的batch-size,但需要较小的学习率。我们在训练期间测量梯度噪声等级,并使用它来指导batch-size的选择[MKAT18]。表1显示了我们使用的参数设置。为了在不耗尽内存的情况下训练更大的模型,我们混合使用了每个矩阵乘法中的模型并行性和网络各层之间的模型并行度。所有模型都在V100 GPU上进行了训练,这是微软提供的高带宽集群的一部分。附录B中描述了训练过程和超参数设置的详细信息。
评估
对于Few-shot学习,我们通过从该任务的训练集中随机抽取K个示例作为条件来评估验证集中的每个示例。对于LAMBADA和故事完形填空,没有可用的监督训练集,因此我们从验证集集中提取条件示例,并在测试集上进行评估。对于Winograd(原始版本,而非SuperGLUE版本),只有一个数据集,因此我们直接从中提取条件示例。
这里K可以是从0到模型上下文窗口允许的最大值(
n
c
t
x
n_{ctx}
nctx)的任何值,通常适合10到100个示例。较大的K值并不总是更好,因此当单独的开发集和测试集可用时,我们在开发集上尝试一些K值,然后在测试集上运行最佳值。对于某些任务(参见附录G),除了演示,我们还使用自然语言提示。
对不同的任务,GPT3都能够去适应。比如对于二分类任务,我们可把选项设置成有意义的名字(True False)。
小结
GPT3虽然用的模型结构和GPT2几乎一样,但是在有很多各种各样的细节,感兴趣的建议阅读原文。另外,原文中使用了大量篇幅来讲GPT3在一些典型任务上的关键结果,后续有时间的话会继续基于原文来介绍GPT3的这些关键结果。
总之,GPT3让人们认识到语言模型还具有很多的可能性,虽然离人们预想的人工智能还很遥远,但毫无疑问逐渐开始脱离人工智障的范畴,在NLP发展的道路上迈下了坚实的一步。