python爬虫之scrapy框架基本使用
1、环境安装:pip install scrapy
2、创建一个工程:scrapy startproject xxxPro
3、cd xxxPro
4、在spiders子目录中创建一个爬虫文件:scrapy genspider spiderName www.xxx.com
5、执行工程:scrapy crawl spiderName
基本使用实例如下:
1、pycharm终端输入:scrapy startproject firstBlood,创建一个firstBlood文件夹。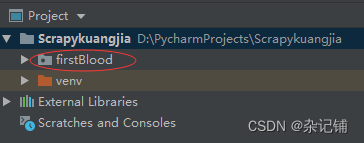
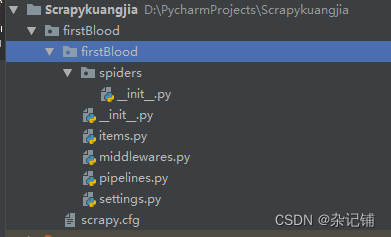
firstBlood文件夹下存放文件展示如下,包括firstBlood同名文件夹和scrapy.cfg文件。其中:
scrapy.cfg:当前工程的配置文件。
spider:爬虫文件夹/爬虫目录,存放爬虫源文件。
settings.py:工程相关配置,经常使用。
2、进入firstBlood文件夹下。
终端输入:cd firstBlood
3、在firstBlood子目录中创建一个first爬虫文件。爬取网站www.xxx.com,之后可修改。
终端输入:scrapy genspider first www.xxx.com
创建的first爬虫文件如下所示:
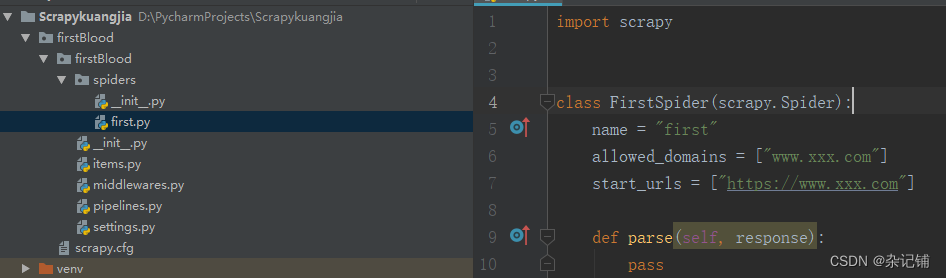
first.py相关代码解释和扩展如下所示:
import scrapy
class FirstSpider(scrapy.Spider):
#爬虫文件的名称:就是爬虫源文件的一个唯一标识
name = "first"
#允许的域名:用来限定start_urls列表中哪些url可以进行请求发送,通常情况下不用
# all的url会被scrapy自动进行请求的发送
start_urls = ["https://www.baidu.com","https://www.sogou.com"]
#用作于数据解析:response参数表示的就是请求成功后对应的响应对象,请求了多少网站,response就存放了多少响应对象
def parse(self, response):
print(response)
4、first.py代码保存后,终端输入:scrapy crawl first运行first.py
输出许多日志信息,其中部分如下所示。其中红线配置导致运行输出后没有输出运行结果。
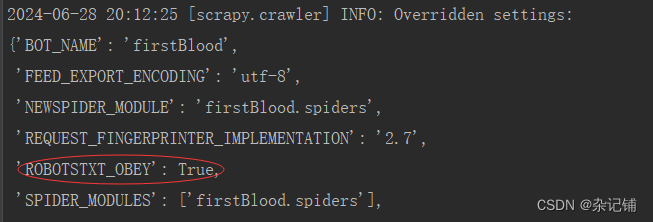
可通过打开settings.py配置文件,将ROBOTSTXT_OBEY = True改为ROBOTSTXT_OBEY = False,再次运行first.py,可得到如下示图。

补充:
1、scrapy crawl first --nolog可不输出日志。但如果程序出错,观察不到错误信息。

2、在settings.py文件中任意位置添加如下代码块,可只输出结果和错误日志,方便调试代码。
#显示指定类型的日志信息
LOG_LEVEL = "ERROR"
`